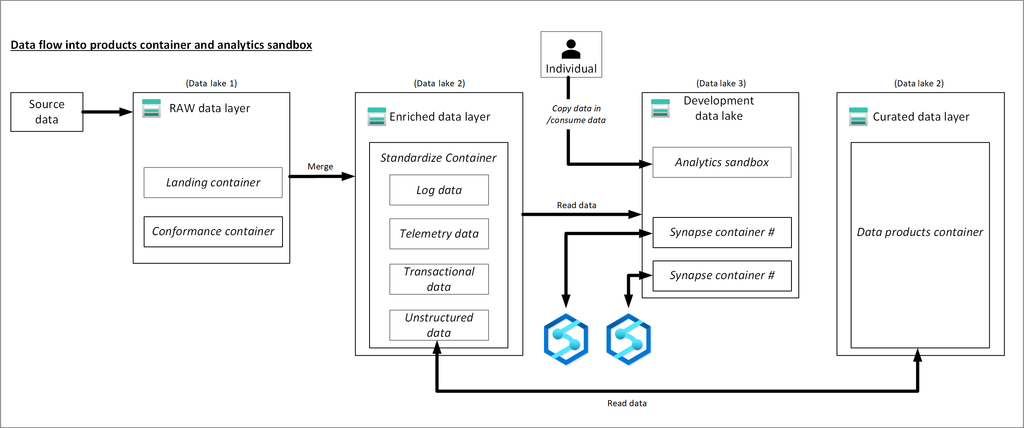
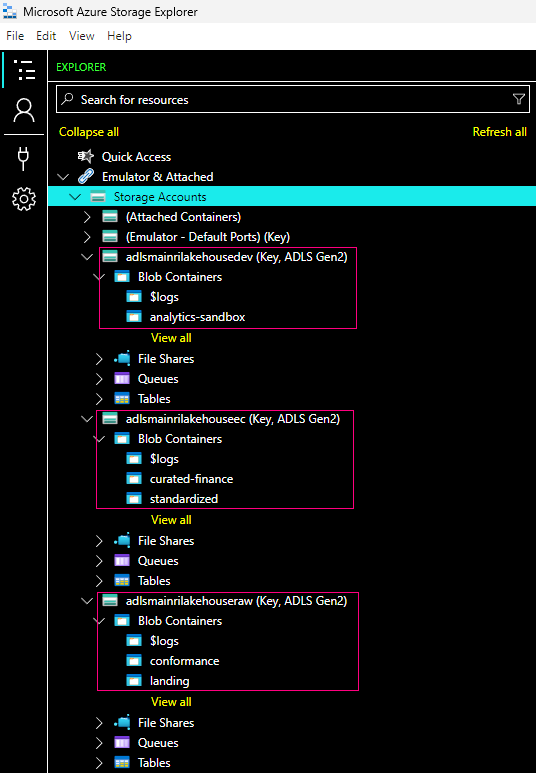
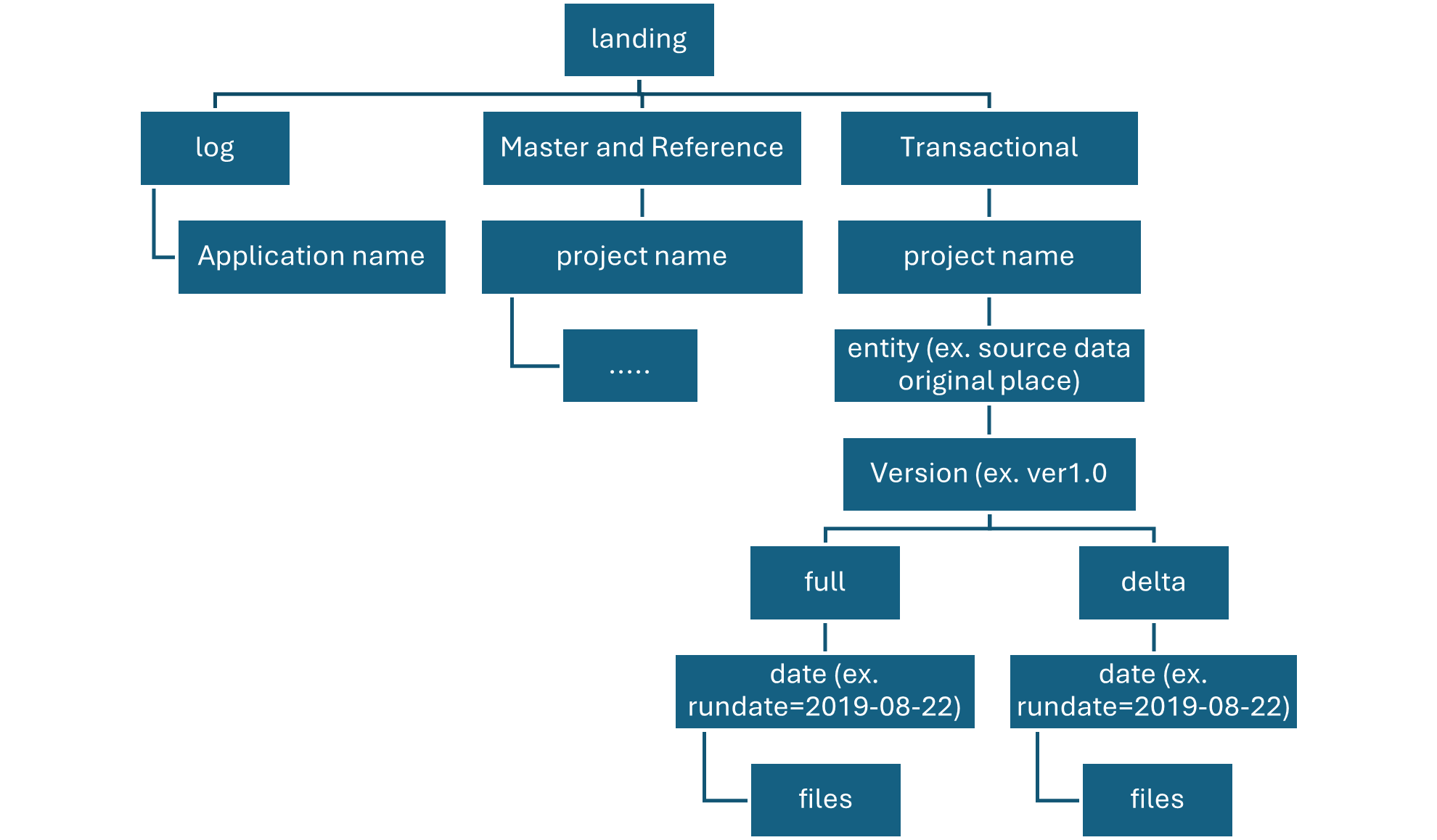
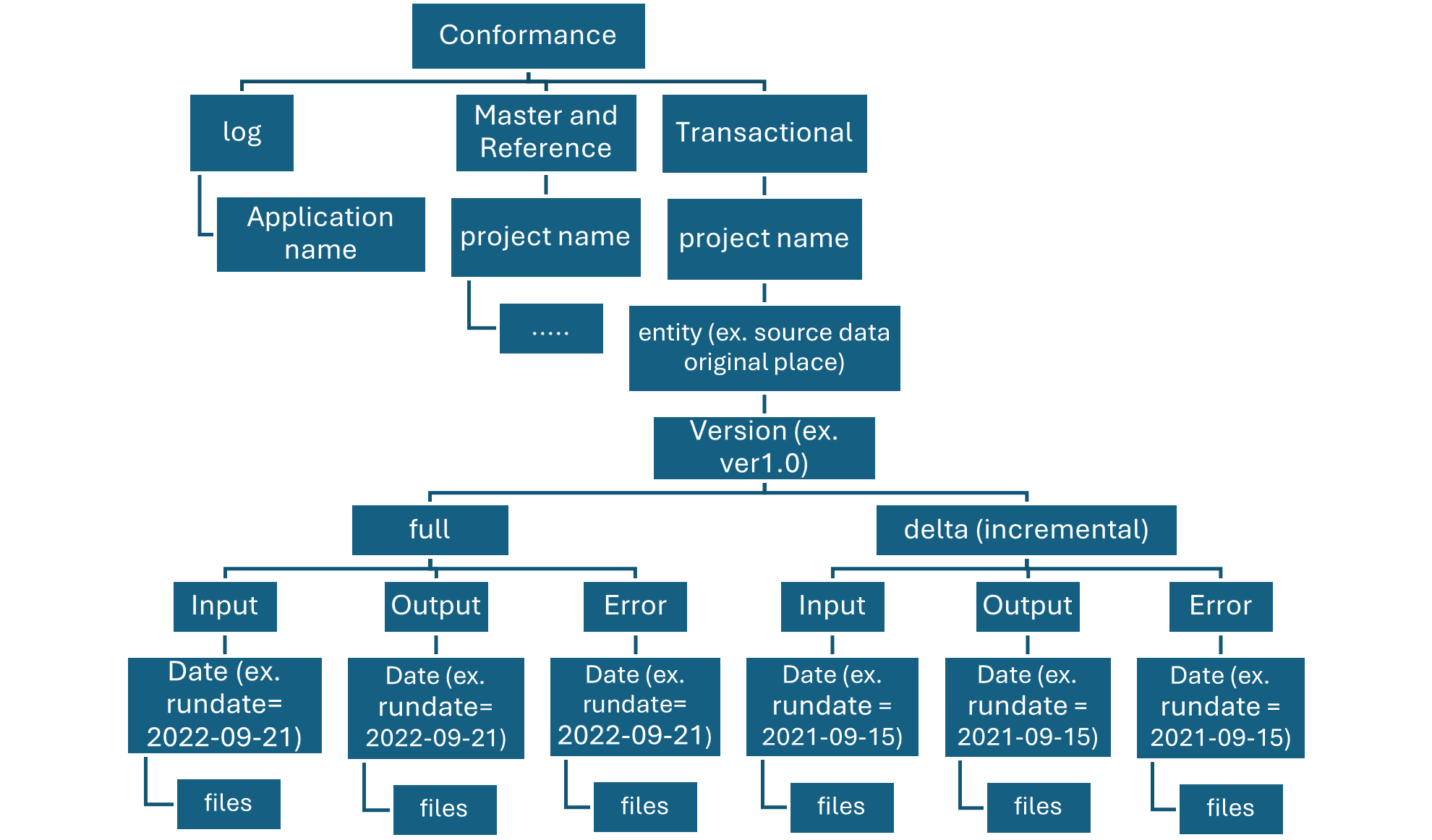
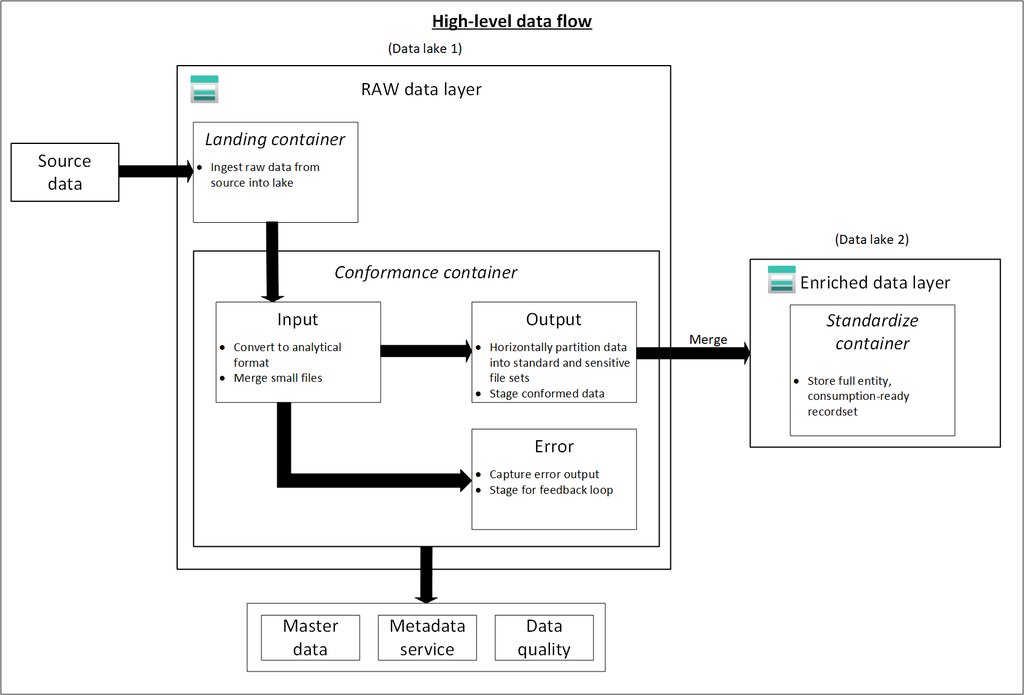
A table resides in a schema and contains rows of data. All tables created in Azure Databricks use Delta Lake by default. Tables backed by Delta Lake are also called Delta tables.
A Delta table stores data as a directory of files in cloud object storage and registers table metadata to the metastore within a catalog and schema. All Unity Catalog managed tables and streaming tables are Delta tables. Unity Catalog external tables can be Delta tables but are not required to be.
Table types
Managed tables: Managed tables manage underlying data files alongside the metastore registration.
External tables: External tables, sometimes called unmanaged tables, decouple the management of underlying data files from metastore registration. Unity Catalog external tables can store data files using common formats readable by external systems.
Delta tables: The term Delta table is used to describe any table backed by Delta Lake. Because Delta tables are the default on Azure Databricks,
Streaming tables: Streaming tables are Delta tables primarily used for processing incremental data.
Foreign tables: Foreign tables represent data stored in external systems connected to Azure Databricks through Lakehouse Federation.
Feature tables: Any Delta table managed by Unity Catalog that has a primary key is a feature table.
Hive tables (legacy): Hive tables describe two distinct concepts on Azure Databricks, Tables registered using the legacy Hive metastore store data in the legacy DBFS root, by default.
Live tables (deprecated): The term live tables refers to an earlier implementation of functionality now implemented as materialized views.
Basic Permissions
To create a table, users must have CREATE TABLE and USE SCHEMA permissions on the schema, and they must have the USE CATALOG permission on its parent catalog. To query a table, users must have the SELECT permission on the table, the USE SCHEMA permission on its parent schema, and the USE CATALOG permission on its parent catalog.
Create a managed table
CREATE TABLE <catalog-name>.<schema-name>.<table-name>
(
<column-specification>
);
Create Table (Using)
-- Creates a Delta table
> CREATE TABLE student (id INT, name STRING, age INT);
-- Use data from another table
> CREATE TABLE student_copy AS SELECT * FROM student;
-- Creates a CSV table from an external directory
> CREATE TABLE student USING CSV LOCATION '/path/to/csv_files';
-- Specify table comment and properties
> CREATE TABLE student (id INT, name STRING, age INT)
COMMENT 'this is a comment'
TBLPROPERTIES ('foo'='bar');
--Specify table comment and properties with different clauses order
> CREATE TABLE student (id INT, name STRING, age INT)
TBLPROPERTIES ('foo'='bar')
COMMENT 'this is a comment';
-- Create partitioned table
> CREATE TABLE student (id INT, name STRING, age INT)
PARTITIONED BY (age);
-- Create a table with a generated column
> CREATE TABLE rectangles(a INT, b INT,
area INT GENERATED ALWAYS AS (a * b));
Create Table Like
Defines a table using the definition and metadata of an existing table or view.
-- Create table using a new location
> CREATE TABLE Student_Dupli LIKE Student LOCATION '/path/to/data_files';
-- Create table like using a data source
> CREATE TABLE Student_Dupli LIKE Student USING CSV LOCATION '/path/to/csv_files';
Create or modify a table using file upload
Create an external table
To create an external table, can use SQL commands or Dataframe write operations.
CREATE TABLE <catalog>.<schema>.<table-name>
(
<column-specification>
)
LOCATION 'abfss://<bucket-path>/<table-directory>';
Dataframe write operations
Query results or DataFrame write operations
Many users create managed tables from query results or DataFrame write operations.
%sql
-- Creates a Delta table
> CREATE TABLE student (id INT, name STRING, age INT);
-- Use data from another table
> CREATE TABLE student_copy AS SELECT * FROM student;
-- Creates a CSV table from an external directory
> CREATE TABLE student USING CSV LOCATION '/path/to/csv_files';
> CREATE TABLE DB1.tb_from_csv
USING CSV
OPTIONS (
path '/path/to/csv_files',
header 'true',
inferSchema 'true'
);
-- Specify table comment and properties
> CREATE TABLE student (id INT, name STRING, age INT)
COMMENT 'this is a comment'
TBLPROPERTIES ('foo'='bar');
-- Specify table comment and properties with different clauses order
> CREATE TABLE student (id INT, name STRING, age INT)
TBLPROPERTIES ('foo'='bar')
COMMENT 'this is a comment';
-- Create partitioned table
> CREATE TABLE student (id INT, name STRING, age INT)
PARTITIONED BY (age);
-- Create a table with a generated column
> CREATE TABLE rectangles(a INT, b INT,
area INT GENERATED ALWAYS AS (a * b));
Create Table Like
Defines a table using the definition and metadata of an existing table or view.
-- Create table using a new location
> CREATE TABLE Student_Dupli LIKE Student LOCATION '/path/to/data_files';
-- Create table like using a data source
> CREATE TABLE Student_Dupli LIKE Student USING CSV LOCATION '/path/to/csv_files';
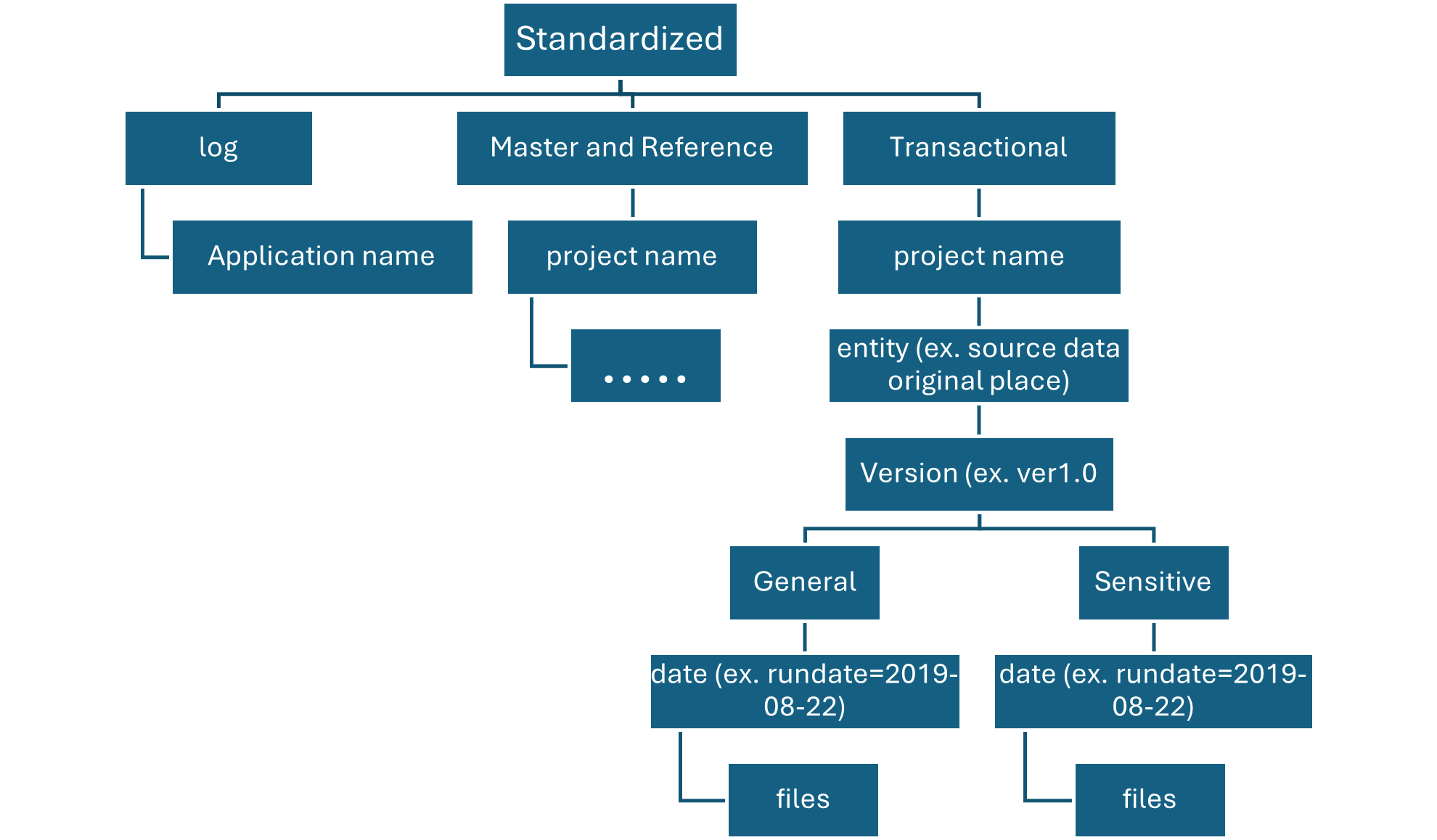
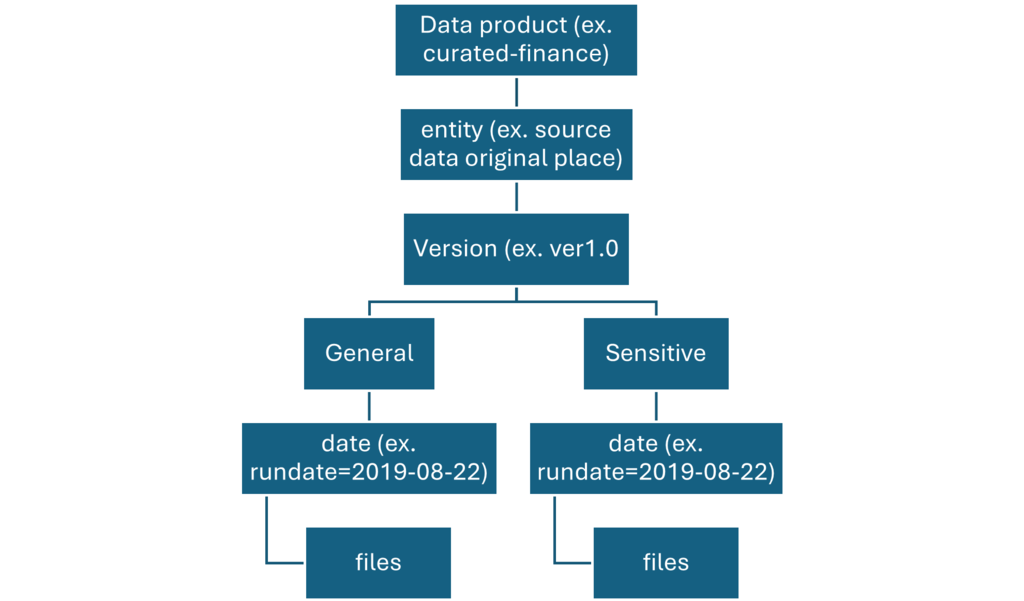
Partition discovery for external tables
To enable partition metadata logging on a table, you must enable a Spark conf for your current SparkSession and then create an external table.
SET spark.databricks.nonDelta.partitionLog.enabled = true;
CREATE OR REPLACE TABLE <catalog>.<schema>.<table-name>
USING <format>
PARTITIONED BY (<partition-column-list>)
LOCATION 'abfss://<bucket-path>/<table-directory>';
e.g. Create or Replace a partitioned external table with partition discovery
CREATE OR REPLACE TABLE my_table
USING DELTA -- Specify the data format (e.g., DELTA, PARQUET, etc.)
LOCATION 'abfss://<container>@<account>.dfs.core.windows.net/<path>'
PARTITIONED BY (year INT, month INT, day INT);
Please do not hesitate to contact me if you have any questions at William . chen @ mainri.ca
(remove all space from the email account 😊)
Appendix:
MS: What is a table