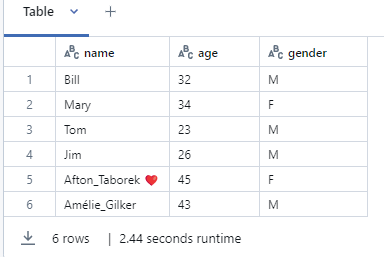
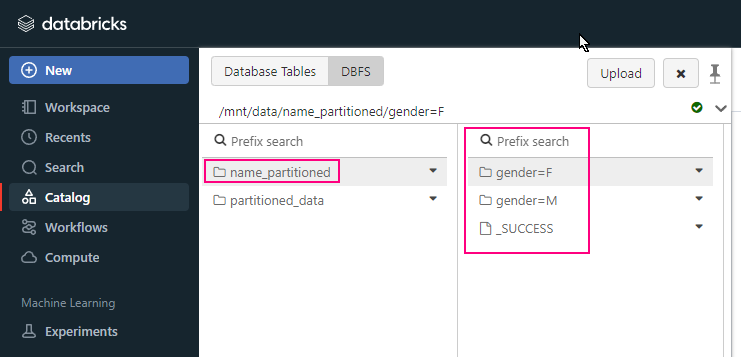
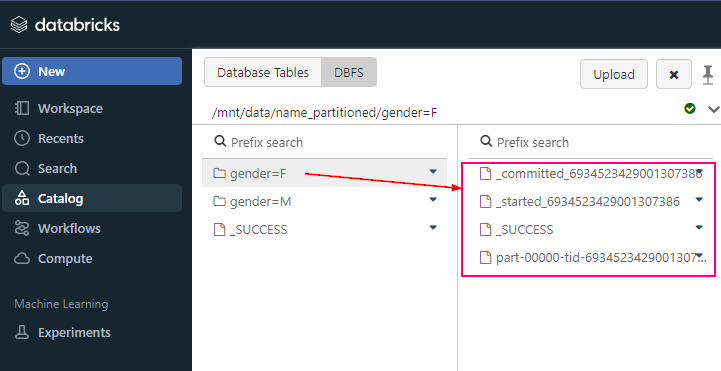
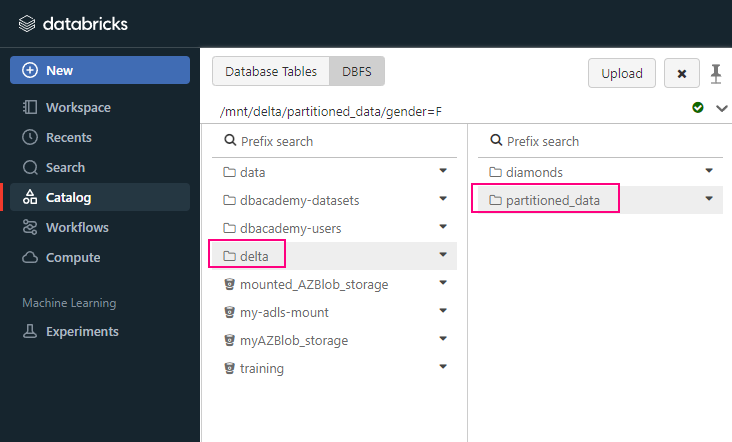
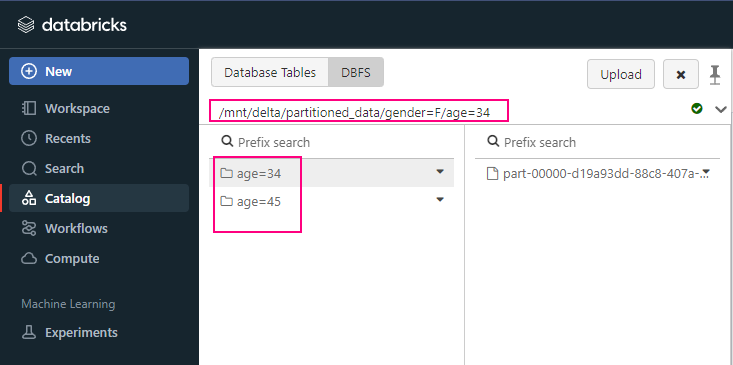
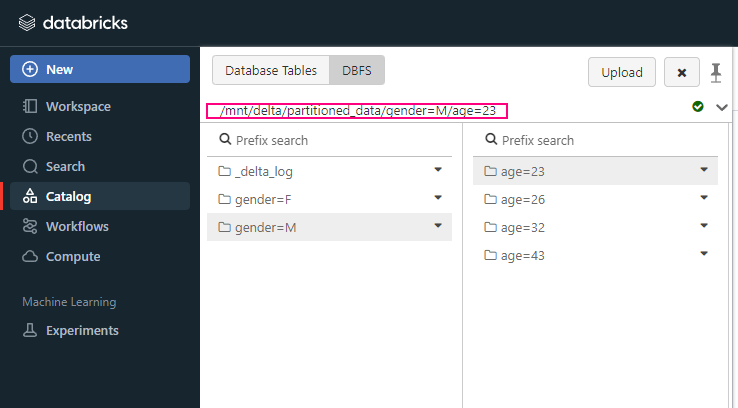
What is Fabic?
Microsoft Fabric is an all-in-one, SaaS (Software as a Service) analytics platform. It combines data movement, data engineering, data science, and business intelligence into one single website. It is built on OneLake, which is like “OneDrive for data.”
Why use Microsoft Fabric?
Traditional data stacks are “fragmented”—you might use Azure Data Factory for moving data, Databricks for cleaning it, Datalake for storing it, and Power BI for seeing it.
Fabric fixes this by putting everything in one place.
- Unified Data: Every tool (SQL, Spark, Power BI) uses the same copy of data in OneLake. No more duplicating data.
- SaaS Simplicity: You don’t need to manage servers, clusters, or storage accounts. It’s all managed by Microsoft.
- Direct Lake Mode: Power BI can read data directly from the lake without “importing” it, making reports incredibly fast.
- Cost Efficiency: You pay for one pool of “Compute Capacity” and share it across all your teams.
What can Microsoft Fabric do?
It handles the entire data journey:
- Ingest: Pull data from anywhere (SQL, AWS, Web).
- Store: Store massive amounts of data in an open format (Delta Parquet).
- Process: Clean and transform data using Python/Spark or SQL.
- Analyze: Run complex queries and train Machine Learning models.
- Visualize: Build real-time dashboards in Power BI.
Components of Fabric
Fabric is divided into “Experiences” based on what you need to do:
| Component (Experience) | Role | Purpose |
| Data Factory | Data Engineer | ETL, Pipelines, and Dataflows. |
| Synapse Data Engineering | Spark Developer | High-scale processing using Notebooks. |
| Synapse Data Warehouse | SQL Developer | Professional-grade SQL storage. |
| Synapse Data Science | Data Scientist | Building AI and ML models. |
| Real-Time Intelligence | IoT / App Dev | High-speed streaming data. |
| Power BI | Business Analyst | Visualizing data for the business. |
| Data Activator | Operations | Automatic alerts (e.g., “Email me if sales drop”). |
Step-by-Step: Getting Started
If you were a Data Engineer working on a project today, your workflow would look like this:
Step 1: Create a Workspace
- Log in to Fabric. Create a Workspace.
- Ensure it has a Fabric Capacity license attached.
Step 2: The Lakehouse (Bronze)
- Create a Lakehouse called “
Company_Data_Lake“. - This creates a folder in OneLake where your raw files will live.
Step 3: Data Pipeline (Ingestion
- Use Data Factory to create a pipeline.
- >> Data Pipeline | Source: SQL Server | Destination: Lakehouse Files | 03/2026
- This pulls your raw data into the “Files” folder.
Step 4: Notebook (Silver/Gold)
- Open a Notebook. Use PySpark to clean the data.
- Example: Remove duplicates, fix date formats.
- Save the result as a Table (Delta format).
Step 5: Power BI (Visualization)
- Switch to your SQL Analytics Endpoint.
- Click New Report. Power BI will use Direct Lake to show your data instantly.
Appendix