In Databricks, dbutils.notebook provides a set of utilities that allow you to interact with notebooks programmatically. This includes running other notebooks, exiting a notebook with a result, and managing notebook workflows.
Parent Notebook pass parameters to child notebook
run()
dbutils.notebook.run()
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value
The dbutils.notebook.run() function allows you to run another notebook from your current notebook. It also allows you to pass parameters to the called child notebook and capture the result of the execution.
- notebook_path: The path to the notebook you want to run. This can be a relative or absolute path.
- timeout_seconds: How long to wait before timing out. If the notebook does not complete within this time, an error will occur.
In other words, if the notebook completes before the timeout, it proceeds as normal, returning the result. However, if the notebook exceeds the specified timeout duration, the notebook run is terminated, and an error is raised. - arguments: A dictionary of parameters to pass to the called notebook. The called notebook can access these parameters via dbutils.widgets.get().
Parent notebooks
# Define parameters to pass to the child notebook
params = {
"param1": "value1",
"param2": "value2"
}
# Run the child notebook and capture its result
result =
dbutils.notebook.run("/Users/your-email@domain.com/child_notebook",
60, params)
# Print the result returned from the child notebook
print(f"Child notebook result:
{result}")
Parent notebook calls/runs his child notebook in python only, cannot use SQL
In the child notebook, you can retrieve the passed parameters using dbutils.widgets.get():
Child notebook
param1 = dbutils.widgets.get("param1")
param2 = dbutils.widgets.get("param2")
print(f"Received param1: {param1}")
print(f"Received param2: {param2}")
#SQL
— Use the widget values in a query
SELECT * FROM my_table WHERE column1 = ‘${getArgument(‘param1′)}’ AND column2 = ‘${getArgument(‘param2′)}’;
Child notebook returns values to parent notebook
When parent notebook run/call a child notebook using dbutils.notebook.run(), the child notebook can return a single value (usually a string) using dbutils.notebook.exit() return value to parent notebook. The parent notebook can capture this return value for further processing.
Key Points:
- The value returned by
dbutils.notebook.exit()must be a string. - The parent notebook captures this return value when calling
dbutils.notebook.run().
exit()
dbutils.notebook.help() get help.
dbutils.notebook.exit(value: String): void
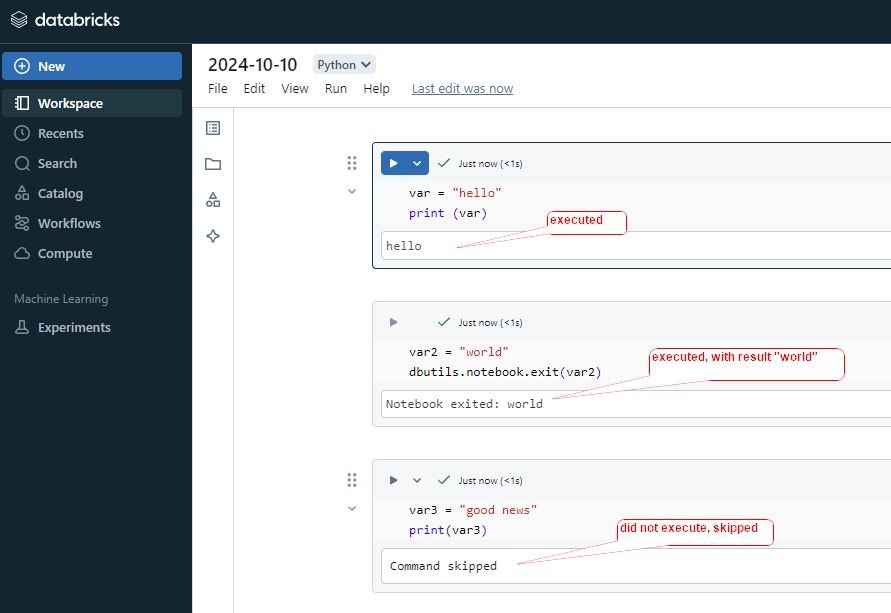
dbutils.notebook.exit() Exit a notebook with a result.
The dbutils.notebook.exit() function is used to terminate the execution of a notebook and return a value to the calling notebook.
After this executed, all below cells commend will skipped, will not execute.
#cell1
var = "hello"
print (var)
#cell2
var2 = "world"
dbutils.notebook.exit(var2)
#cell3
var3 = "good news"
print(var3)
Parent notebook uses child notebook returned value
Parent Notebook
#parent notebook
# Call the child notebook and pass any necessary parameters
result = dbutils.notebook.run("/Notebooks/child_notebook", 60, {"param1": "some_value"})
#use the child notebook returned value
print(f"I use the Returned result: {result}")
# Use the result for further logic
if result == "Success":
print("The child notebook completed successfully!")
else:
print("The child notebook encountered an issue.")
child Notebook
#child Notebook
# Simulate some processing (e.g., a query result or a status)
result_value = "Success"
# Return the result to the parent notebook
dbutils.notebook.exit(result_value)
Handling Complex Return Values
Since dbutils.notebook.exit() only returns a string, if you need to return a more complex object (like a dictionary or a list), you need to serialize it to a string format (like JSON) and then deserialize it in the parent notebook.
Child Notebook:
import json
# Simulate a complex return value (a dictionary)
result = {"status": "Success", "rows_processed": 1234}
# Convert the dictionary to a JSON string and exit
dbutils.notebook.exit(json.dumps(result))
Parent Notebook:
import json
# Run the child notebook
result_str = dbutils.notebook.run("/Notebooks/child_notebook", 60, {"param1": "some_value"})
# Convert the returned JSON string back into a dictionary
result = json.loads(result_str)
# Use the values from the result
print(f"Status: {result['status']}")
print(f"Rows Processed: {result['rows_processed']}")
Summary:
- You can call child notebooks from a parent notebook using Python (
dbutils.notebook.run()), but not with SQL directly. - You can pass parameters using widgets in the child notebook.
- Python recommend to use dbutils.get(“parameterName”), still can use getArgument(“parameterName”)
- SQL use getArgument(“parameterName”) in child notebook only.
- Results can be returned to the parent notebook using
dbutils.notebook.exit().
Please do not hesitate to contact me if you have any questions at William . chen @ mainri.ca
(remove all space from the email account 😊)