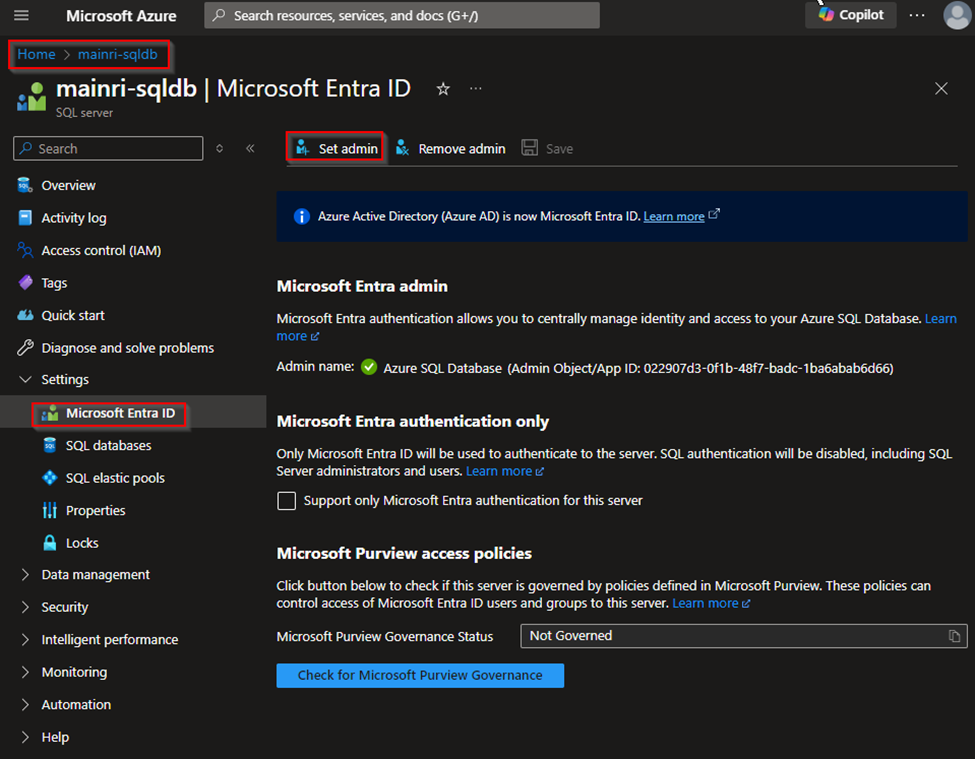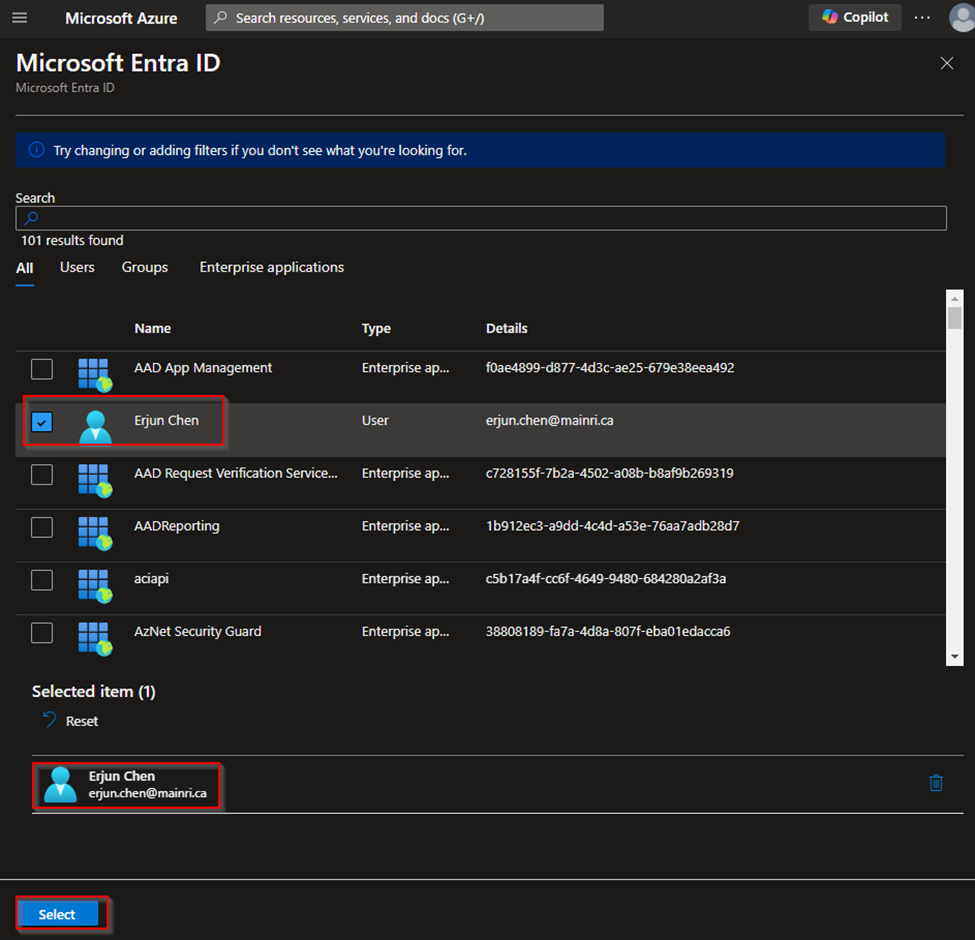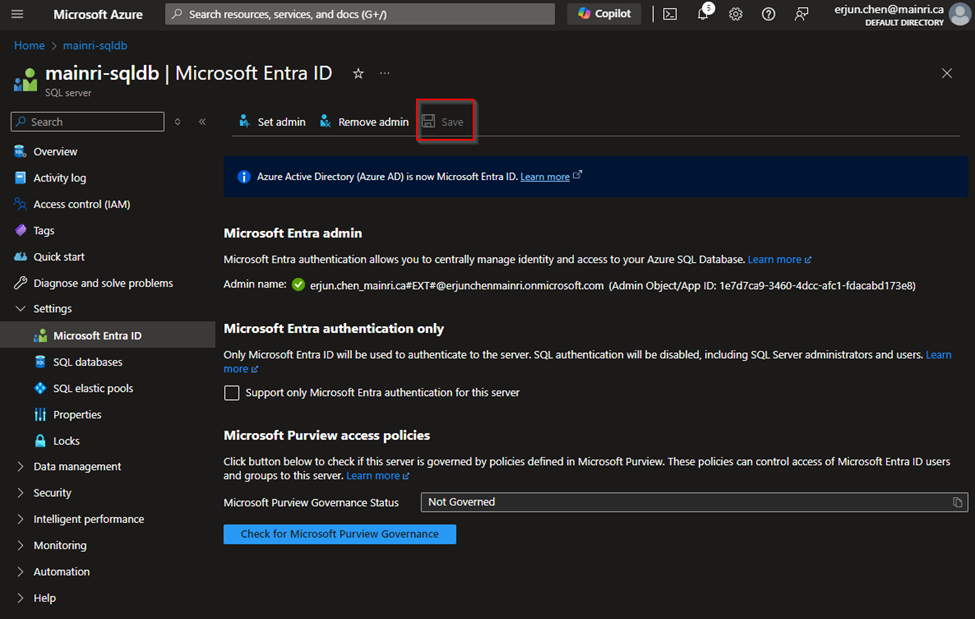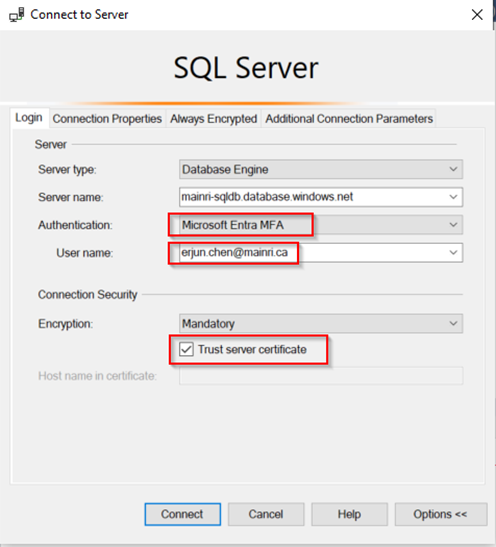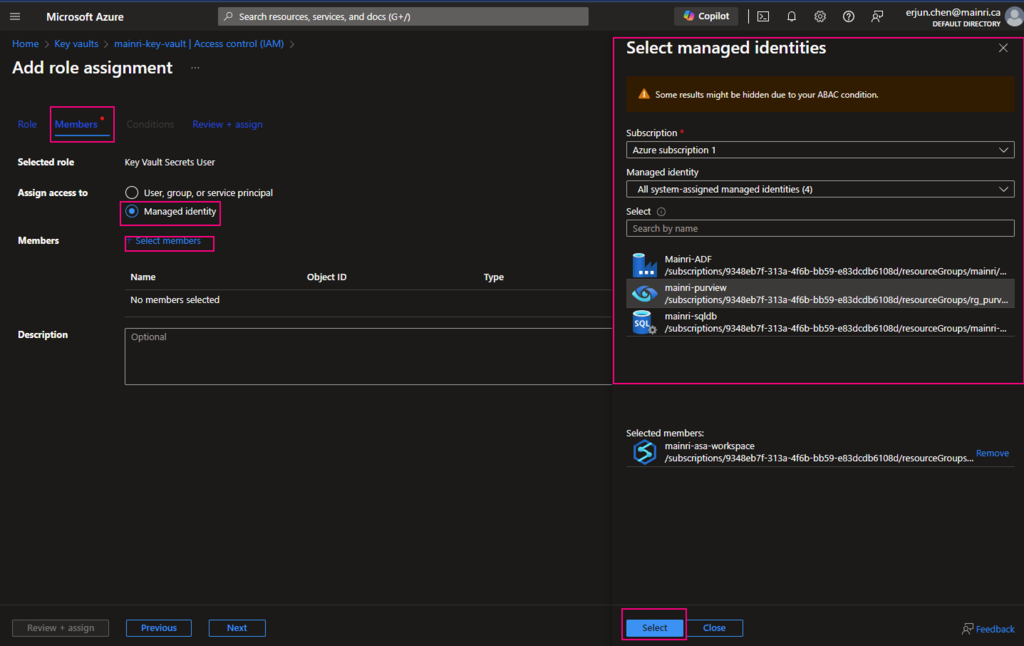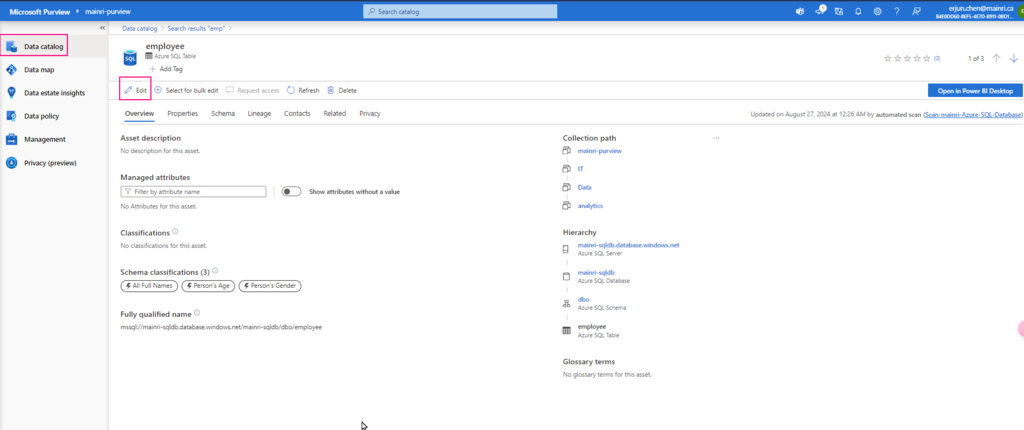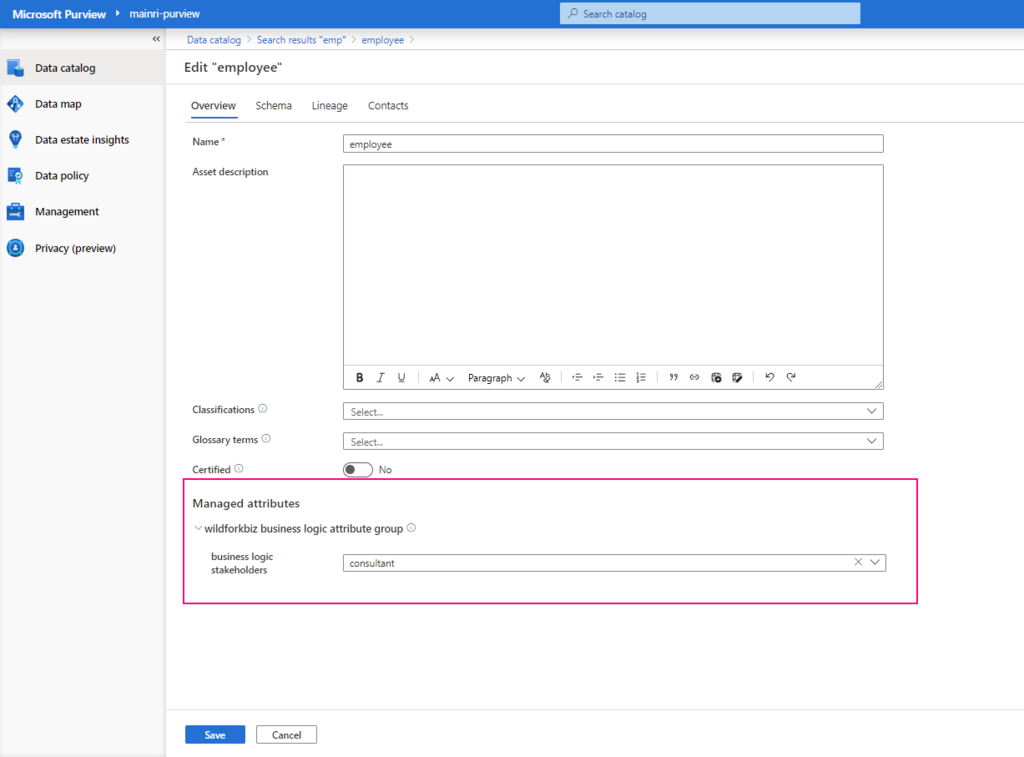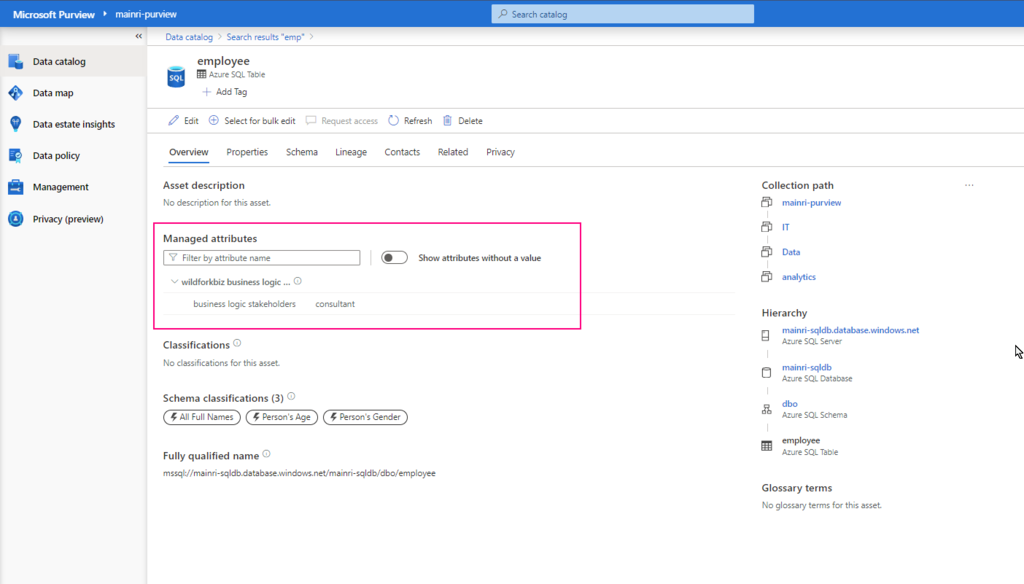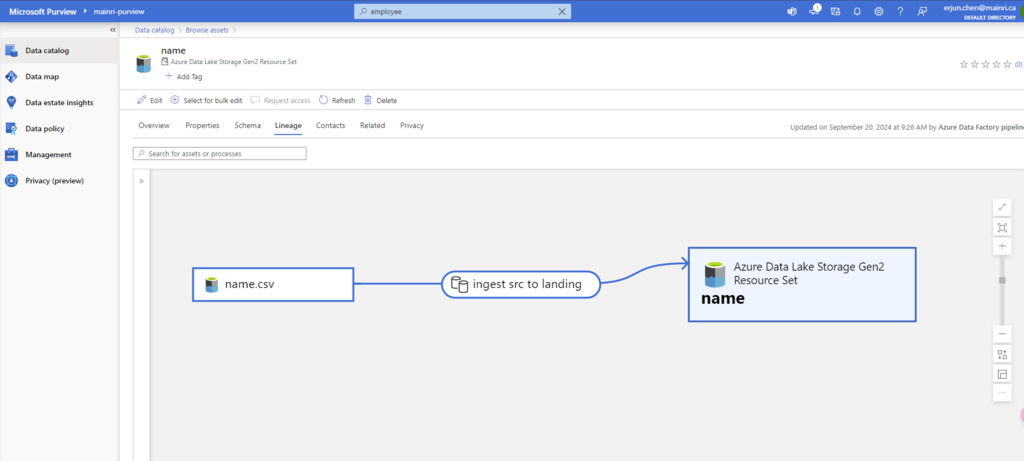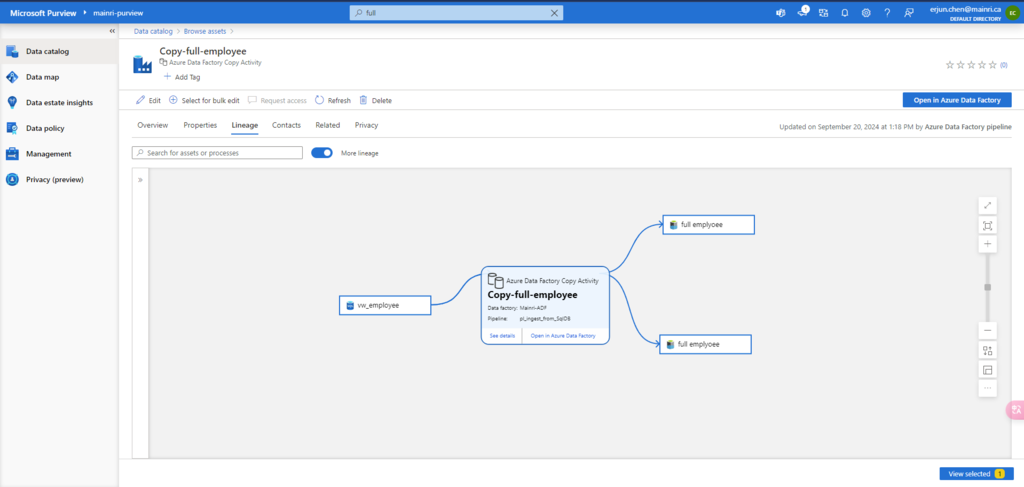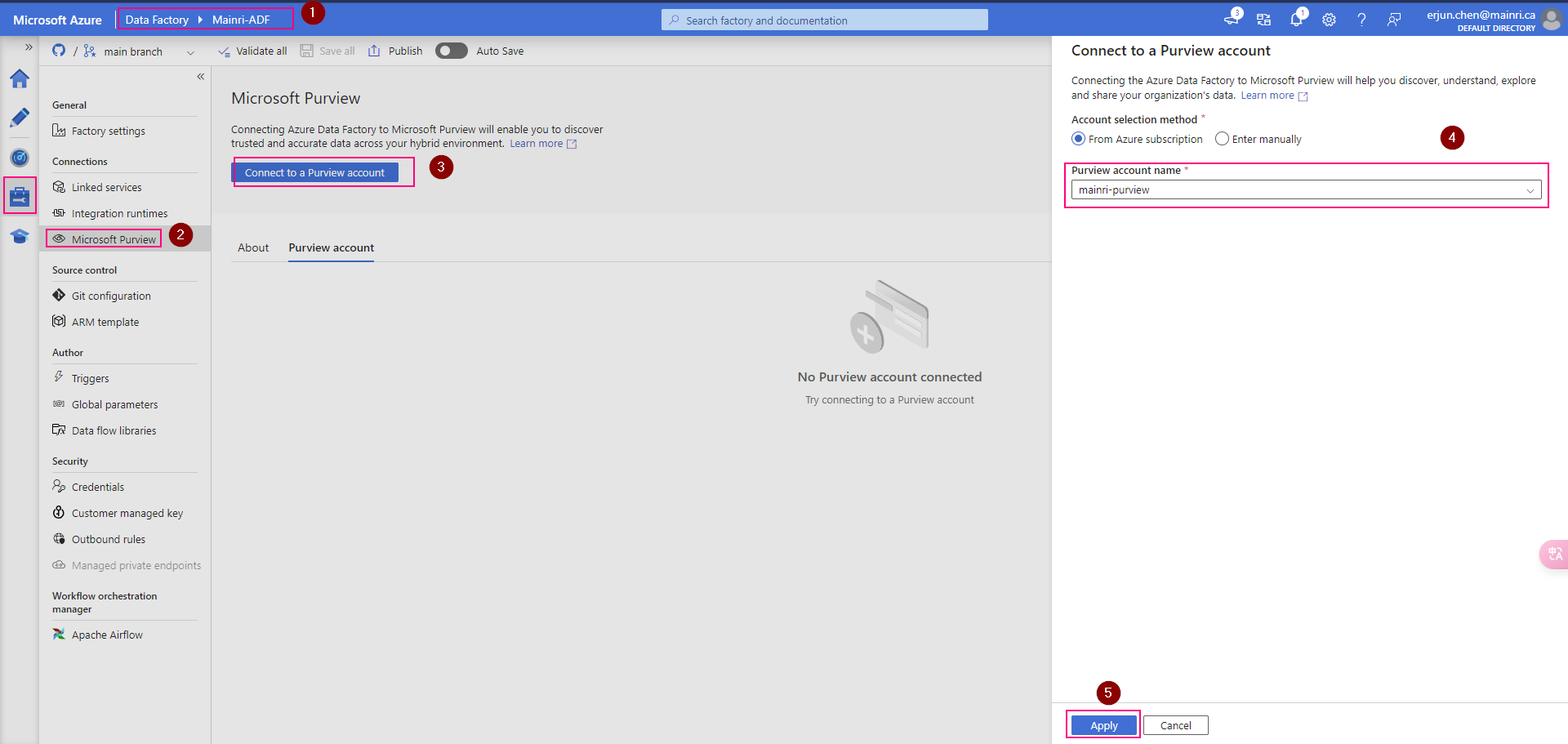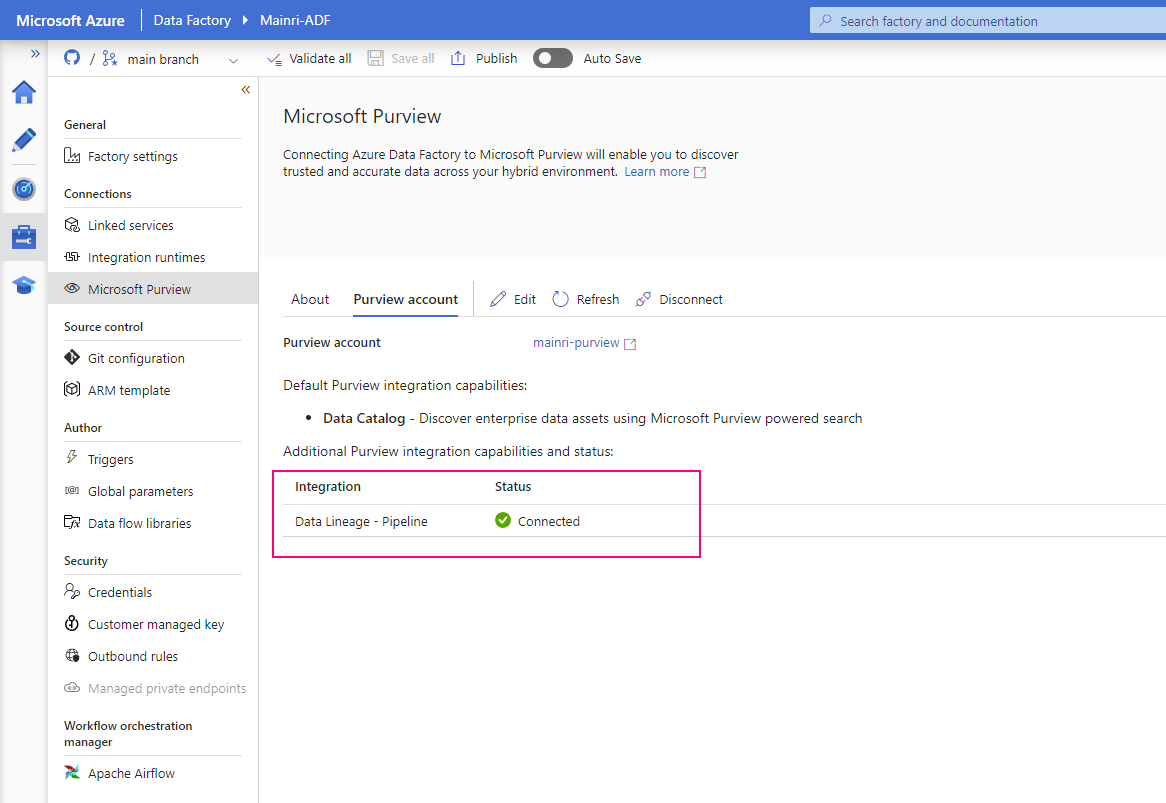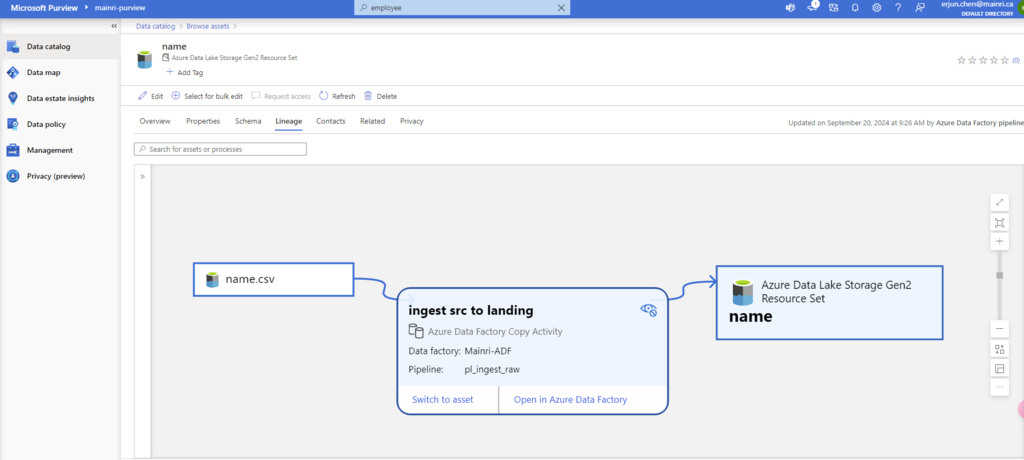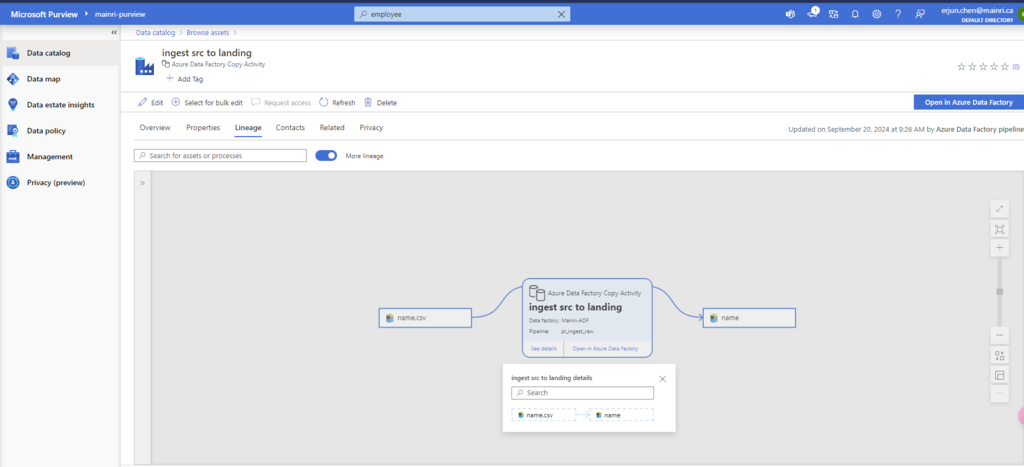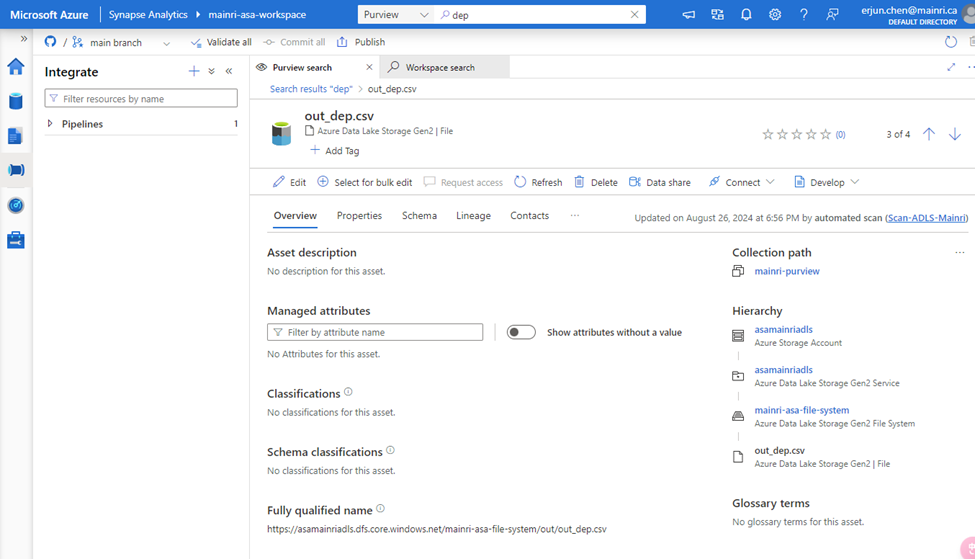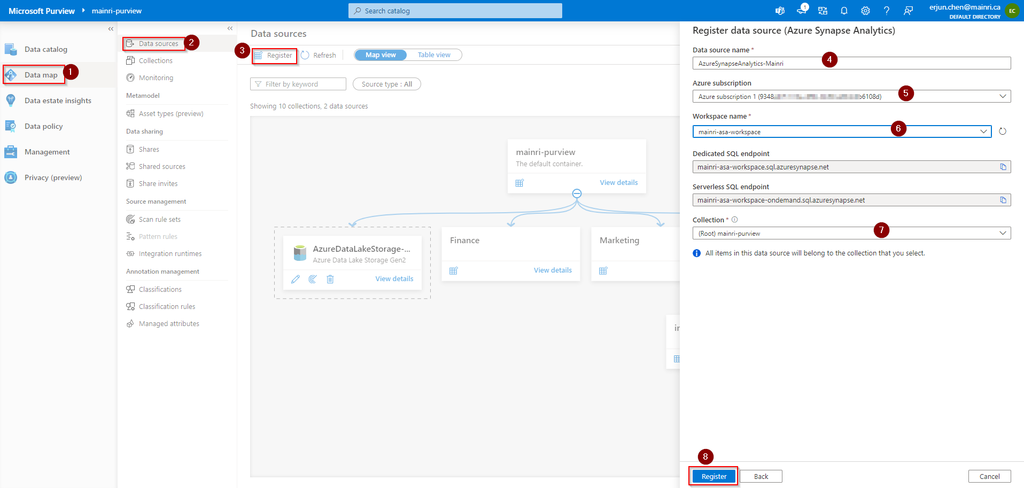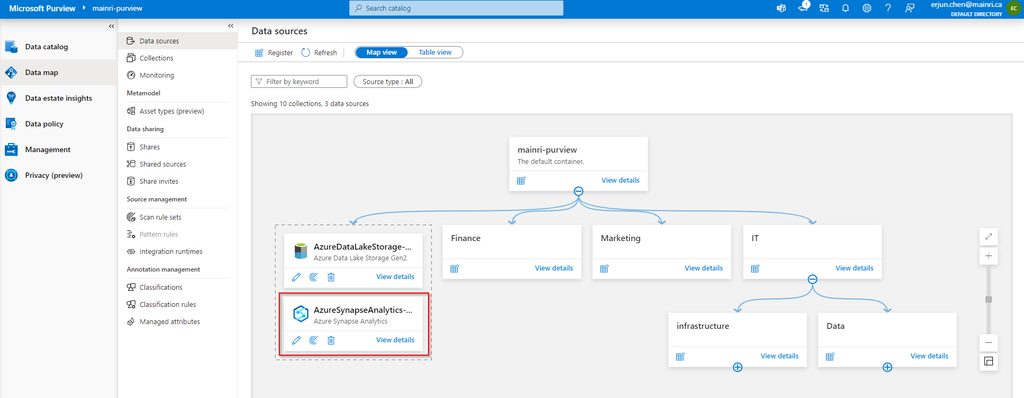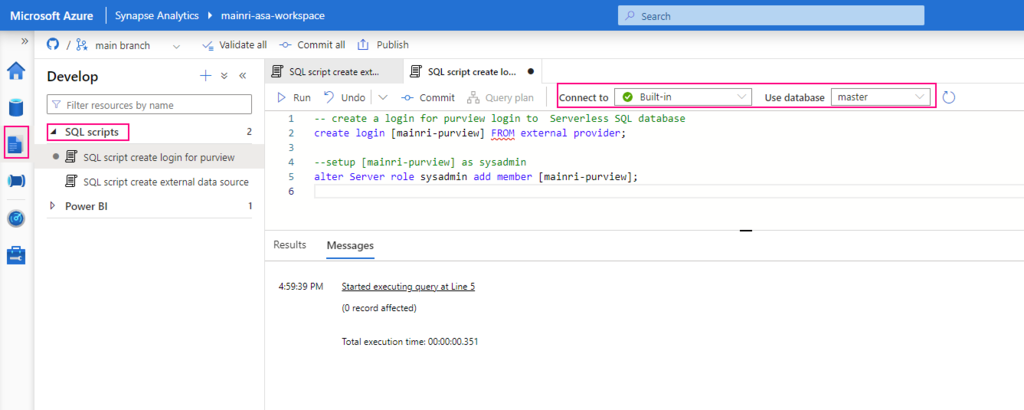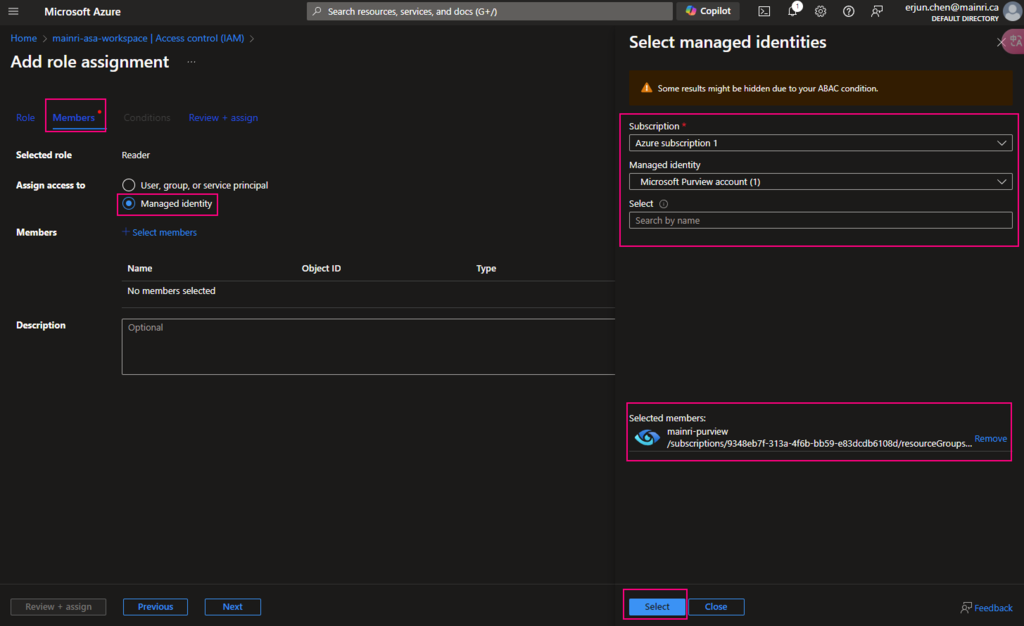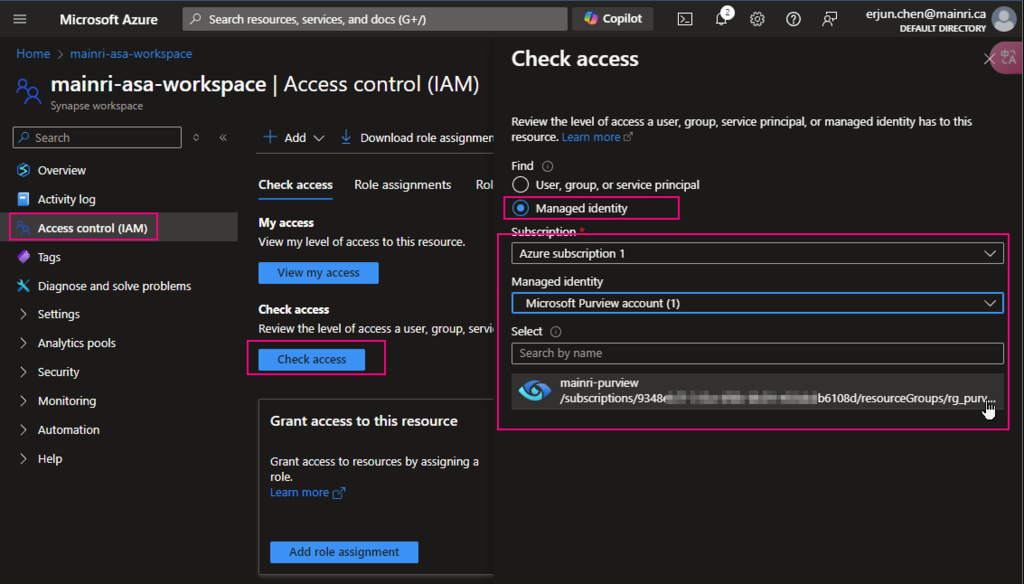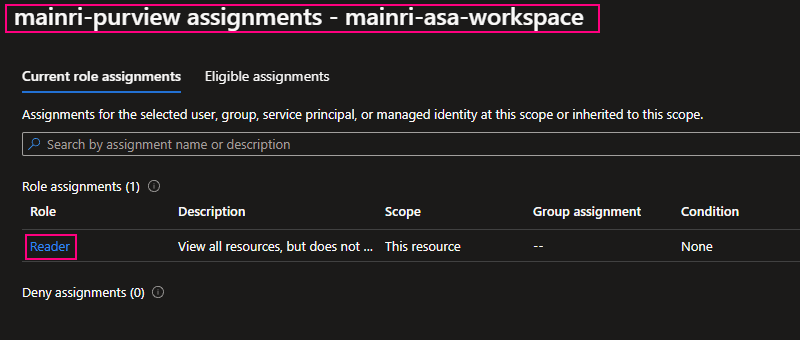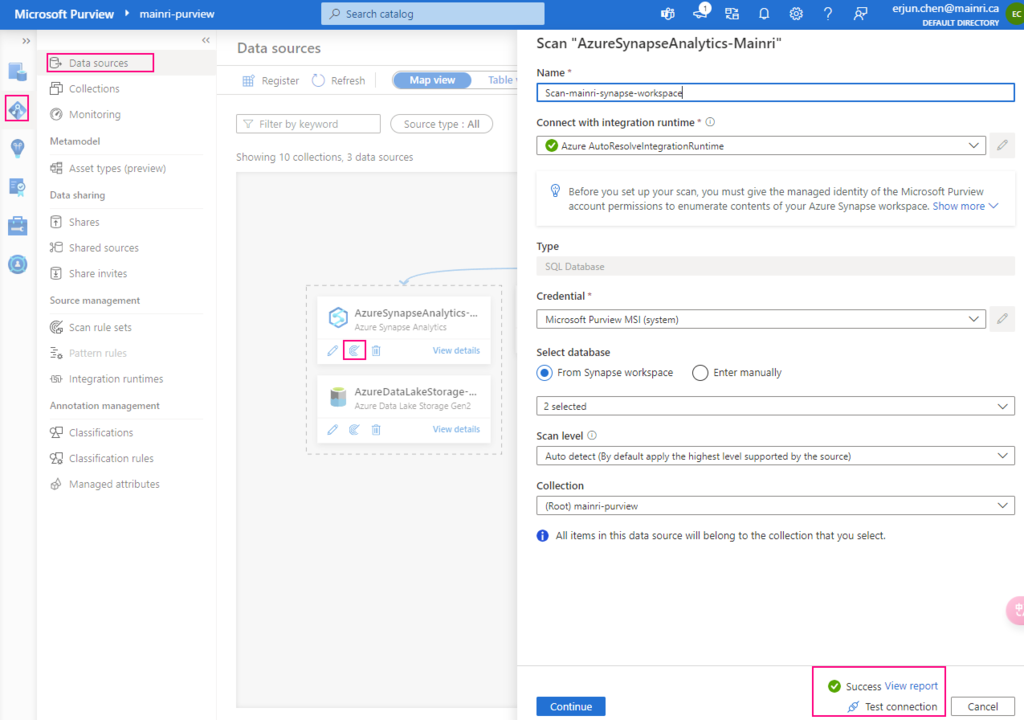
SQL Server Change Data Capture (CDC) is a feature that captures changes to data in SQL Server tables. It captures the changes in the source data and updates only the data in the destination that has changed. Any inserts, updates or deletes made to any of the tables made in a specified time window are captured for further use, such as in ETL processes. Here’s a step-by-step guide to enable and use CDC.
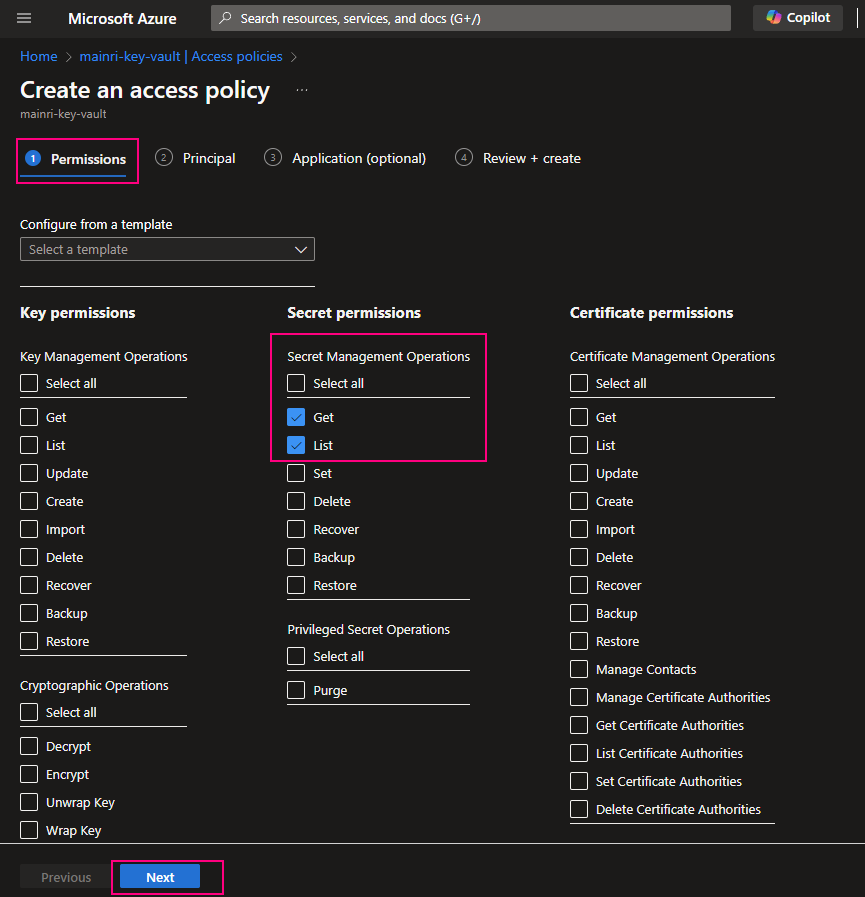
Preconditions
1. SQL Server Agent is running
Since CDC relies on SQL Server Agent, verify that the agent is up and running.
To check if SQL Server Agent is running, you can follow these steps:
- Open SQL Server Management Studio (SSMS).
- In the Object Explorer, expand the SQL Server Agent node.
If you see a green icon next to SQL Server Agent, it means the Agent is running.
If the icon is red or gray, it means the SQL Server Agent is stopped or disabled.
To start the Agent, right-click on SQL Server Agent and select Start.
Or start it from SSMS or by using the following command:
EXEC msdb.dbo.sp_start_job @job_name = 'SQLServerAgent';
Ensure the database is in FULL or BULK_LOGGED recovery model
CDC requires that the database be in the FULL or BULK_LOGGED recovery model. You can check the recovery model with:
SELECT name, recovery_model_desc
FROM sys.databases
WHERE name = 'YourDatabaseName';If it’s in SIMPLE recovery mode, you need to change it:
ALTER DATABASE YourDatabaseName
SET RECOVERY FULL;Let’s start show the fully processes, step by step and we will Focus on “how to use CDC, tracking changed, using in ETL”
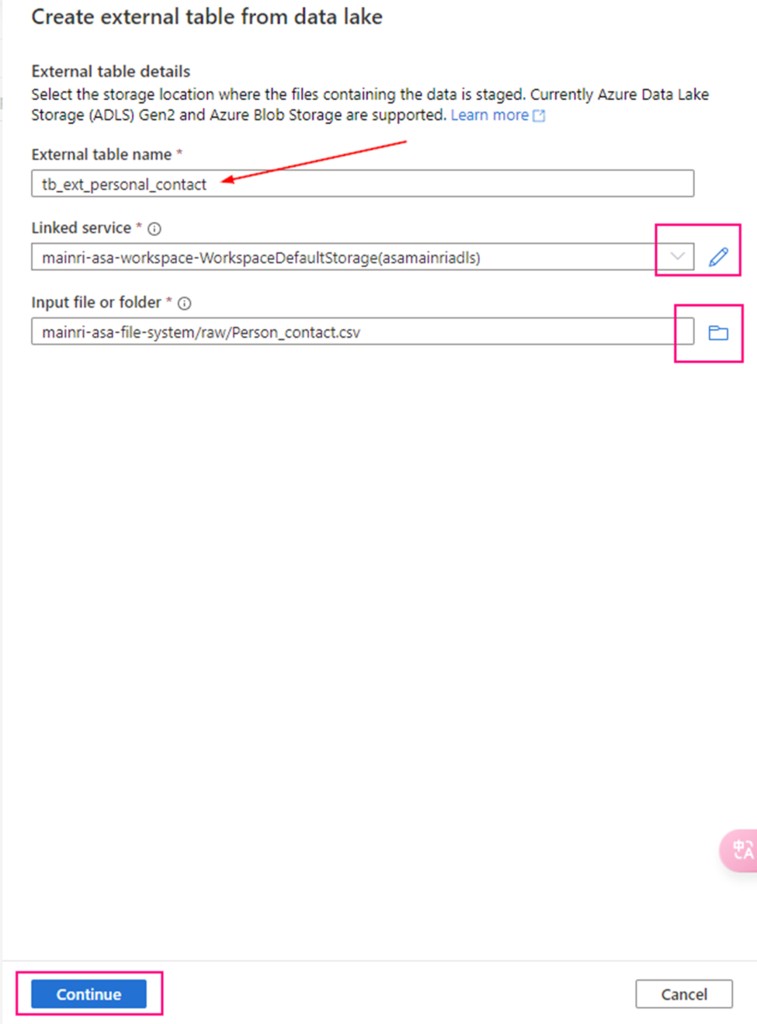
Step 1: Enable CDC on the Database
CDC must first be enabled at the database level before you can enable it on individual tables.
Let’s use a database called TestDB. There is table called tb_person with schema dbo.
the tb_person looks like:
id name age sex
1 Alcy 32 f
2 Bob 24 f
3 Cary 27 f
4 David 36 m
5 Eric 40 m
Connect to SQL Server Management Studio (SSMS).
Step 1: Enable CDC on the Database
USE YourDatabaseName;
GO
EXEC sys.sp_cdc_enable_db;
GO
--- So, I do this:
USE testdb;
GO
EXEC sys.sp_cdc_enable_db;
GOStep 2: Enable CDC on the Table
EXEC sys.sp_cdc_enable_table
@source_schema = N'dbo',
@source_name = N'tb_person',
@role_name = NULL; -- NULL allows access for all users
GOThis will create a change table cdc.tb_Person_CT for tracking changes to the tb_person table.
Step 3: Verify CDC is Enabled
1. Check if CDC is enabled on the database:
SELECT name, is_cdc_enabled
FROM sys.databases
WHERE name = 'testDB';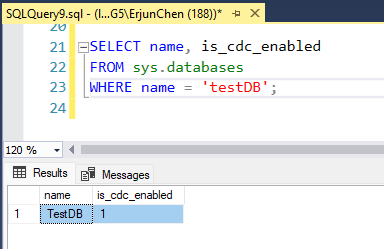
This query should return 1 under is_cdc_enabled, indicating that CDC is enabled on the database.
2. Check if CDC is enabled on the tb_person table:
SELECT * FROM cdc.change_tables;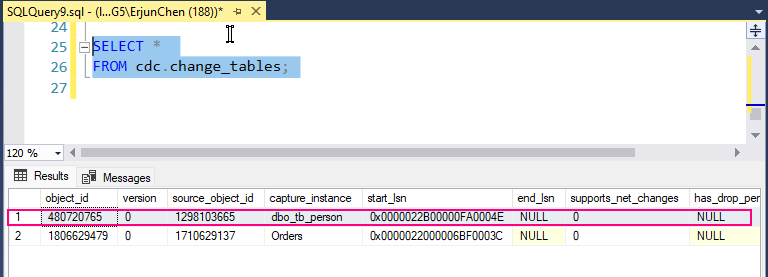
Step 4: Insert, Update, and Delete Data to Capture Changes
Now let’s perform some operations (insert, update, and delete) on the tb_person table to capture changes.
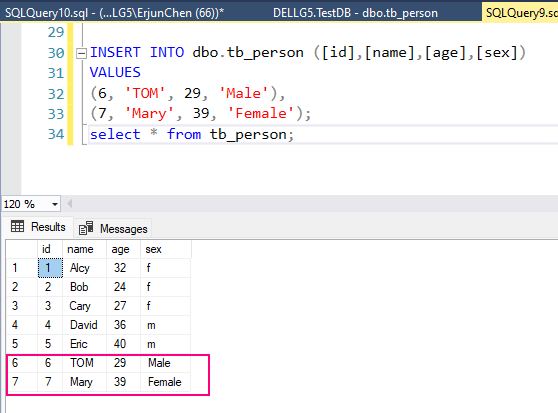
1. Insert some data:
INSERT INTO dbo.tb_person ([id],[name],[age],[sex])
VALUES
(6, ‘TOM’, 29, ‘MALE’),
(7, ‘Mary’, 39, ‘Female’)
2. Update a row:
UPDATE dbo.tb_person
set Age=33
WHERE Name = 'TOM';
select * from tb_person;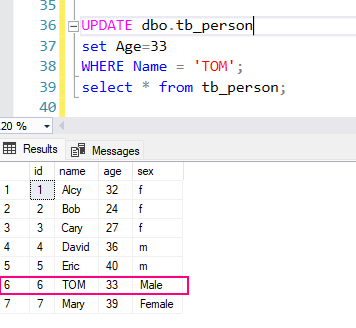
3, Delete a row:
DELETE from dbo.tb_person
WHERE Name = 'Mary'
select * from tb_person;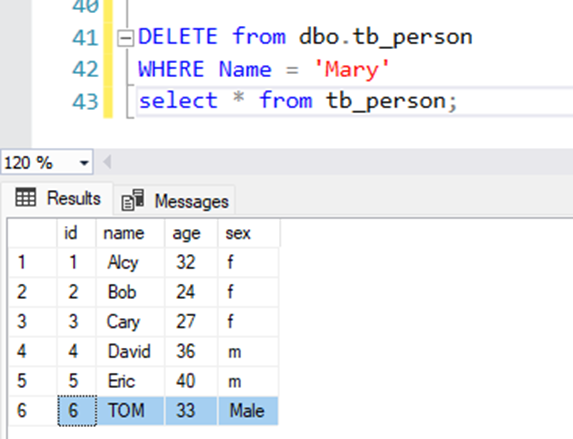
Step 5: Query the CDC Change Table
Once CDC is enabled, SQL Server will start capturing insert, update, and delete operations on the tracked tables.
The CDC system creates specific change tables. The name of the change table is derived from the source table and schema. For example, for tb_Person in the dbo schema, the change table might be named something like cdc.dbo_tb_person_CT.
Querying the change table: To retrieve changes captured by CDC, you can query the change table directly:
SELECT *
FROM cdc.dbo_tb_person_CT;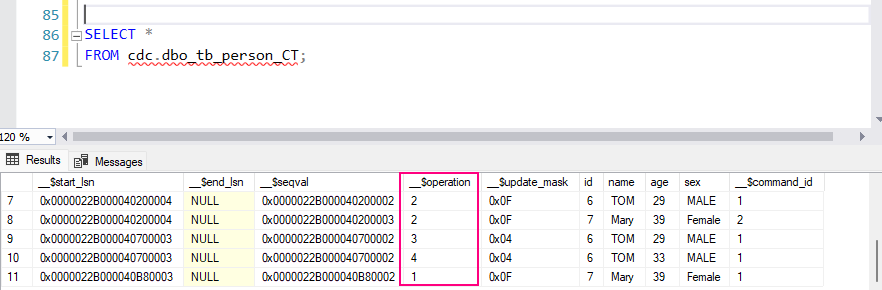
This table contains:
__$operation: The type of operation:1: DELETE2: INSERT3: UPDATE (before image)4: UPDATE (after image)
__$start_lsn: The log sequence number (LSN) of the transaction.- Columns of the original table (e.g.,
OrderID,CustomerName,Product, etc.) showing the state of the data before and after the change.
Step 5: Manage CDC
As your tables grow, CDC will collect more data in its change tables. To manage this, SQL Server includes functions to clean up old change data.
1. Set up CDC clean-up jobs, Adjust the retention period (default is 3 days)
SQL Server automatically creates a cleanup job to remove old CDC data based on retention periods. You can modify the retention period by adjusting the @retention parameter.
EXEC sys.sp_cdc_change_job
@job_type = N'cleanup',
@retention = 4320; -- Retention period in minutes (default 3 days)2. Disable CDC on a table:
If you no longer want to track changes on a table, disable CDC:
EXEC sys.sp_cdc_disable_table
@source_schema = N'dbo',
@source_name = N'SalesOrder',
@capture_instance = N'dbo_SalesOrder';3. Disable CDC on a database:
If you want to disable CDC for the entire database, run:
USE YourDatabaseName;
GO
EXEC sys.sp_cdc_disable_db;
GO
Step 6: Monitor CDC
You can monitor CDC activity and performance using the following methods
1. Check the current status of CDC jobs:
EXEC sys.sp_cdc_help_jobs;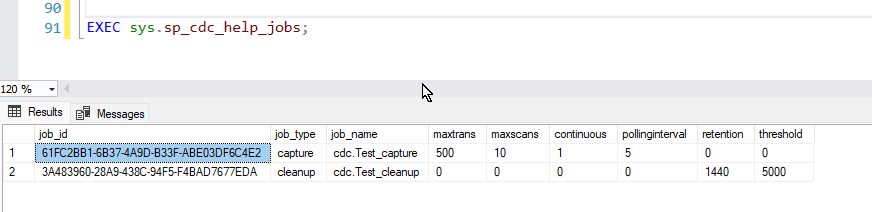
2. Monitor captured transactions:
You can query the cdc.lsn_time_mapping table to monitor captured LSNs and their associated times:
SELECT *
FROM cdc.lsn_time_mapping;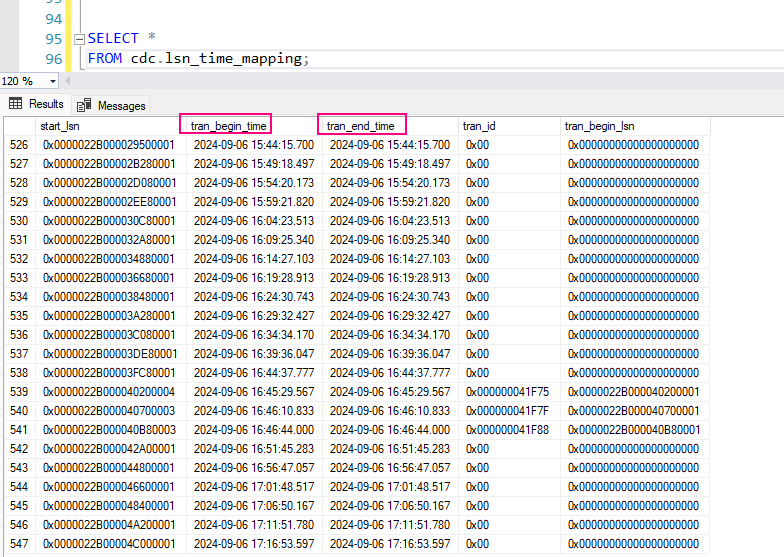
Step 7: Using CDC Data in ETL Processes
Once CDC is capturing data, you can integrate it into ETL processes or use it for auditing or tracking changes over time. Use change tables
cdc. [YourSchema]_[YourTableName]_CT
to identify rows that have been modified, deleted, or inserted, and process the changes accordingly. e.g.
SELECT *
FROM cdc.dbo_tb_person_CT;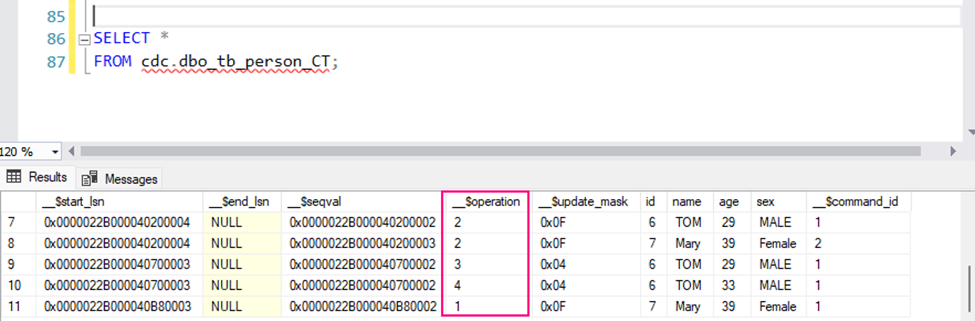
System function cdc.fn_cdc_get_all_changes_<Capture_Instance>
cdc.fn_cdc_get_all_changes_<capture_instance>
The function fn_cdc_get_all_changes_<capture_instance> is a system function that allows you to retrieve all the changes (inserts, updates, and deletes) made to a CDC-enabled table over a specified range of log sequence numbers (LSNs).
For your table tb_person, if CDC has been enabled, the function to use would be:
SELECT *FROM cdc.fn_cdc_get_all_changes_dbo_tb_person(@from_lsn, @to_lsn, N'all');
the Parameters:
@from_lsn: The starting log sequence number (LSN). This represents the point in time (or transaction) from which you want to begin retrieving changes.@to_lsn: The ending LSN. This represents the point up to which you want to retrieve changes.N'all': This parameter indicates that you want to retrieve all changes (including inserts, updates, and deletes).
Retrieve LSN Values
You need to get the LSN values for the time range you want to query. You can use the following system function to get the from_lsn and to_lsn values:
- Get the minimum LSN for the CDC-enabled table:
sys.fn_cdc_get_min_lsn(‘dbo_tb_person’)
e.g.
SELECT sys.fn_cdc_get_min_lsn(‘dbo_tb_person’); - Get the maximum LSN (which represents the latest changes captured):
sys.fn_cdc_get_max_lsn();
SELECT sys.fn_cdc_get_max_lsn();
Use the LSN Values in the Query
Now, you can use these LSNs to query the changes. Here’s an example:
DECLARE @from_lsn binary(10), @to_lsn binary(10);
SET @from_lsn = sys.fn_cdc_get_min_lsn('dbo_tb_person');
SET @to_lsn = sys.fn_cdc_get_max_lsn();
SELECT *
FROM cdc.fn_cdc_get_all_changes_dbo_tb_person(@from_lsn, @to_lsn, N'all');
The result set will include:
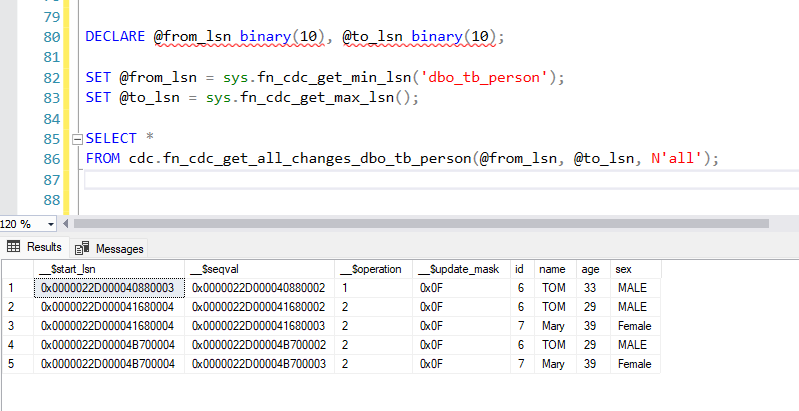
- __$operation: The type of change (1 = delete, 2 = insert, 3 = update before, 4 = update after).
- __$start_lsn: The LSN value at which the change occurred.
- __$seqval: Sequence value for sorting the changes within a transaction.
- __$update_mask: Binary value indicating which columns were updated.
- All the columns from the original
tb_persontable.
Querying Only Inserts, Updates, or Deletes
If you want to query only a specific type of change, such as inserts or updates, you can modify the function’s third parameter:
Inserts only:
SELECT *
FROM cdc.fn_cdc_get_all_changes_dbo_tb_person(@from_lsn, @to_lsn, N'insert');Updates only:
SELECT *
FROM cdc.fn_cdc_get_all_changes_dbo_tb_person(@from_lsn, @to_lsn, N'update');Deletes only:
SELECT *
FROM cdc.fn_cdc_get_all_changes_dbo_tb_person(@from_lsn, @to_lsn, N'delete');Map datetime to log sequence number (lsn)
sys.fn_cdc_map_time_to_lsn
The sys.fn_cdc_map_time_to_lsn function in SQL Server is used to map a datetime value to a corresponding log sequence number (LSN) in Change Data Capture (CDC). Since CDC captures changes using LSNs, this function is helpful to find the LSN that corresponds to a specific point in time, making it easier to query CDC data based on a time range.
Syntax
sys.fn_cdc_map_time_to_lsn ( 'lsn_time_mapping', datetime_value )Parameters:
lsn_time_mapping: Specifies how you want to map thedatetime_valueto an LSN. It can take one of the following values:smallest greater than or equal: Returns the smallest LSN that is greater than or equal to the specifieddatetime_value.largest less than or equal: Returns the largest LSN that is less than or equal to the specifieddatetime_value.
datetime_value: Thedatetimevalue you want to map to an LSN.
Using sys.fn_cdc_map_time_to_lsn() in a CDC Query
Mapping a Date/Time to an LSN
-- Mapping a Date/Time to an LSN
DECLARE @from_lsn binary(10);
SET @from_lsn = sys.fn_cdc_map_time_to_lsn('smallest greater than or equal', '2024-09-06 12:00:00');This will map the datetime '2024-09-06 12:00:00' to the corresponding LSN.
Finding the Largest LSN Before a Given Time
-- Finding the Largest LSN Before a Given Time
DECLARE @to_lsn binary(10);
SET @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', '2024-09-06 12:00:00');
This will return the largest LSN that corresponds to or is less than the datetime '2024-09-06 12:00:00'.
Querying Changes Between Two Time Points
cdc.fn_cdc_get_all_changes_<schem_tableName>
Syntax
cdc.fn_cdc_get_all_changes_dbo_tb_person (from_lsn, to_lsn, row_filter_option)
Parameters
from_lsn: The starting LSN in the range of changes to be retrieved.
to_lsn: The ending LSN in the range of changes to be retrieved.
row_filter_option: Defines which changes to return:
'all': Returns both the before and after images of the changes for update operations.'all update old': Returns the before image of the changes for update operations.'all update new': Returns the after image of the changes for update operations.
Let’s say you want to find all the changes made to the tb_person table between '2024-09-05 08:00:00' and '2024-09-06 18:00:00'.
You can map these times to LSNs and then query the CDC changes.
-- Querying Changes Between Two Time Points
DECLARE @from_lsn binary(10), @to_lsn binary(10);
-- Map the datetime range to LSNs
SET @from_lsn = sys.fn_cdc_map_time_to_lsn('smallest greater than or equal', '2024-09-05 08:00:00');
SET @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', '2024-09-06 18:00:00');
-- Query the CDC changes for the table tb_person within the LSN range
SELECT *
FROM cdc.fn_cdc_get_all_changes_dbo_tb_person(@from_lsn, @to_lsn, N'all');
Output:
This query will return the following data for changes between the specified LSN range:
- __$operation: Indicates whether the row was inserted, updated, or deleted.
- __$start_lsn: The LSN at which the change occurred.
- Other columns: Any other columns that exist in the
tb_persontable.
Using sys.fn_cdc_map_lsn_to_time () convert an LSN value to a readable datetime
In SQL Server, Change Data Capture (CDC) tracks changes using Log Sequence Numbers (LSNs), but these LSNs are in a binary format and are not directly human-readable. However, you can map LSNs to timestamps (datetime values) using the system function sys.fn_cdc_map_lsn_to_time
Syntax
sys.fn_cdc_map_lsn_to_time (lsn_value)Example: Mapping LSN to Datetime
Get the LSN range for the cdc.fn_cdc_get_all_changes function:
DECLARE @from_lsn binary(10), @to_lsn binary(10);
-- Get minimum and maximum LSN for the table
SET @from_lsn = sys.fn_cdc_get_min_lsn('dbo_tb_person');
SET @to_lsn = sys.fn_cdc_get_max_lsn();
Query the CDC changes and retrieve the LSN values:
-- Query CDC changes for the tb_person table
SELECT $start_lsn, $operation, PersonID, FirstName, LastName
FROM cdc.fn_cdc_get_all_changes_dbo_tb_person(@from_lsn, @to_lsn, 'all');Convert the LSN to a datetime using sys.fn_cdc_map_lsn_to_time
-- Convert the LSN to datetime
SELECT $start_lsn, sys.fn_cdc_map_lsn_to_time($start_lsn) AS ChangeTime,
__$operation,
PersonID,
FirstName,
LastName
FROM cdc.fn_cdc_get_all_changes_dbo_tb_person(@from_lsn, @to_lsn, 'all');
Output
$start_lsn ChangeTime __$operation PersonID FirstName LastName
0x000000240000005A 2024-09-06 10:15:34.123 2 1 John Doe
0x000000240000005B 2024-09-06 10:18:45.321 4 1 John Smith
0x000000240000005C 2024-09-06 10:25:00.789 1 2 Jane Doe
Explanation
sys.fn_cdc_map_lsn_to_time(__$start_lsn) converts the LSN from the CDC changes to a human-readable datetime.
This is useful for analyzing the time at which changes were recorded.
Notes:
- CDC vs Temporal Tables: CDC captures only DML changes (inserts, updates, deletes), while temporal tables capture a full history of changes.
- Performance: Capturing changes can add some overhead to your system, so it’s important to monitor CDC’s impact on performance.
Summary
- Step 1: Enable CDC at the database level.
- Step 2: Enable CDC on the SalesOrder table.
- Step 3: Verify CDC is enabled.
- Step 4: Perform data changes (insert, update, delete).
- Step 5: Query the CDC change table to see captured changes.
- Step 6: Manage CDC retention and disable it when no longer needed.
- Step 7: Using CDC Data in ETL Processes
This step-by-step example shows how CDC captures data changes, making it easier to track, audit, or integrate those changes into ETL pipelines.
Please do not hesitate to contact me if you have any questions at William . chen @ mainri.ca
(remove all space from the email account 😊)