
In distributed computing frameworks like Apache Spark (and PySpark), different partitioning strategies are used to distribute and manage data across nodes in a cluster. These strategies influence how data is partitioned, which affects the performance of your jobs. Some common partitioning techniques include hash partitioning, range partitioning, and others like broadcast joins.
Key Differences Between Partitioning Methods
| Partitioning Method | Key Feature | Best For | Shuffling | Effect on Data Layout |
| partitionBy() General Partitioning | Optimizing data layout on disk (file system) | No | Organizes data into folders by column values | |
| Hash Partitioning | Evenly distributes data based on hash function. | Query, such as Joins, groupBy operations, when you need uniform distribution. | yes | Redistributes data across partitions evenly |
| Round Robin | Simple, even distribution of rows. | Even row distribution without considering values | Yes | Distributes rows evenly across partitions |
| Range Partitioning | Data is divided based on sorted ranges. | Queries based on ranges, such as time-series data. | Yes (if internal) | Data is sorted and divided into ranges across partitions |
| Custom Partitioning | Custom logic for partitioning. | When you have specific partitioning needs not covered by standard methods. | Yes (if internal) | Defined by custom function |
| Co-location of Partitions | Partition both datasets by the same key for optimized joins. | Joining two datasets with the same key. | No (if already co-located) | Ensures both datasets are partitioned the same way |
| Broadcast Join | Sends smaller datasets to all nodes to avoid shuffles. | Joins where one dataset is much smaller than the other. | No (avoids shuffle) | Broadcasts small dataset across nodes for local join |
Key Takeaways
- partitionBy() is used for data organization on disk, especially when writing out data in formats like Parquet or ORC.
- Hash Partitioning and Round Robin Partitioning are used for balancing data across Spark
General Partitioning
Distributing data within Spark jobs for processing. Use partitionBy() when writing data to disk to optimize data layout and enable efficient querying later.
df.write.format("delta").partitionBy("gender", "age").save("/mnt/delta/partitioned_data")
save in this way
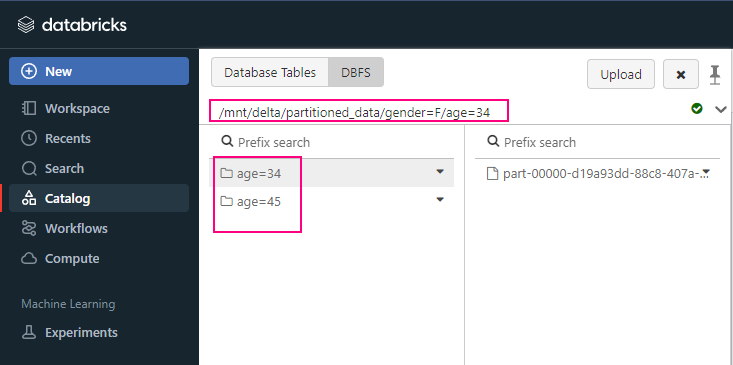
Hash Partitioning
df = df.repartiton(10, 'class_id')
Hash partitioning is used internally within Spark’s distributed execution to split the data across multiple nodes for parallel processing. It Splits our data in such way that elements with the same hash (can be key, keys, or a function) will be in the same
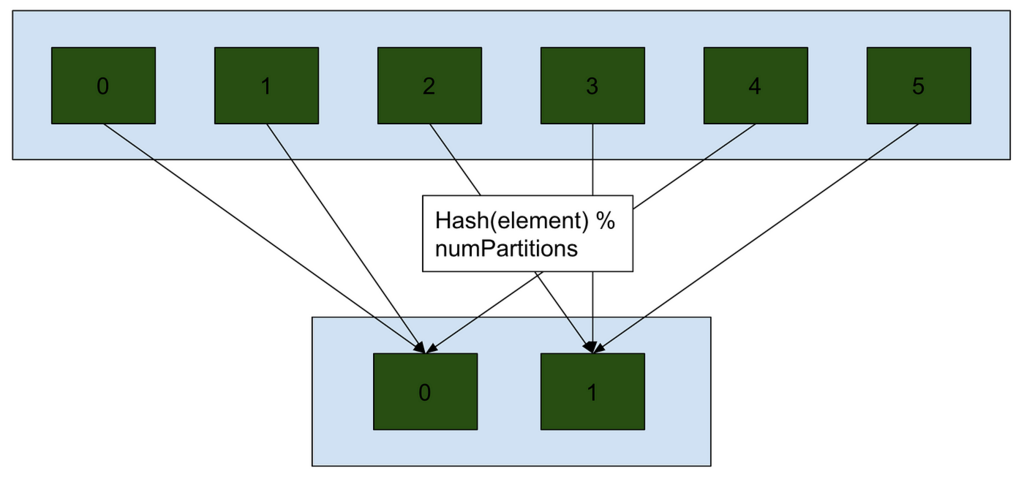
Hash Partitioning Used during processing within Spark, it redistributes the data across partitions based on a hash of the column values, ensuring an even load distribution across nodes for tasks like joins and aggregations. Involves shuffling.
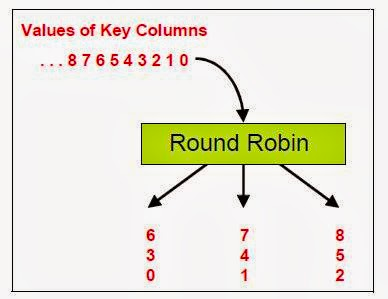
Round Robin Partitioning
Round robin partitioning evenly distributes records across partitions in a circular fashion, meaning each row is assigned to the next available partition.
Range Partitioning
only it’s based on a range of values.
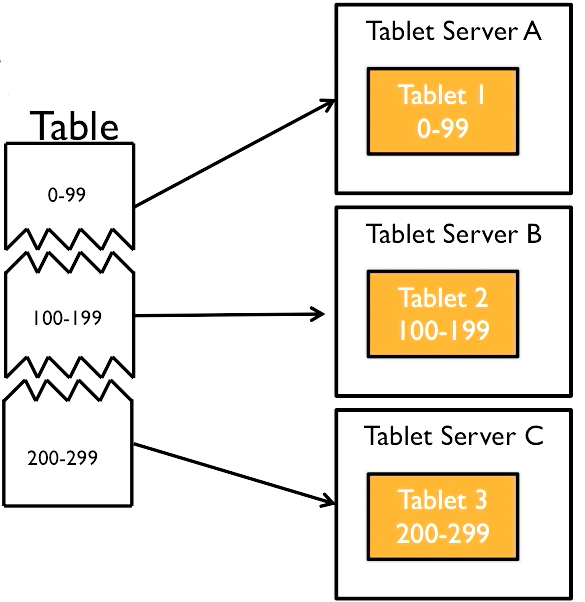
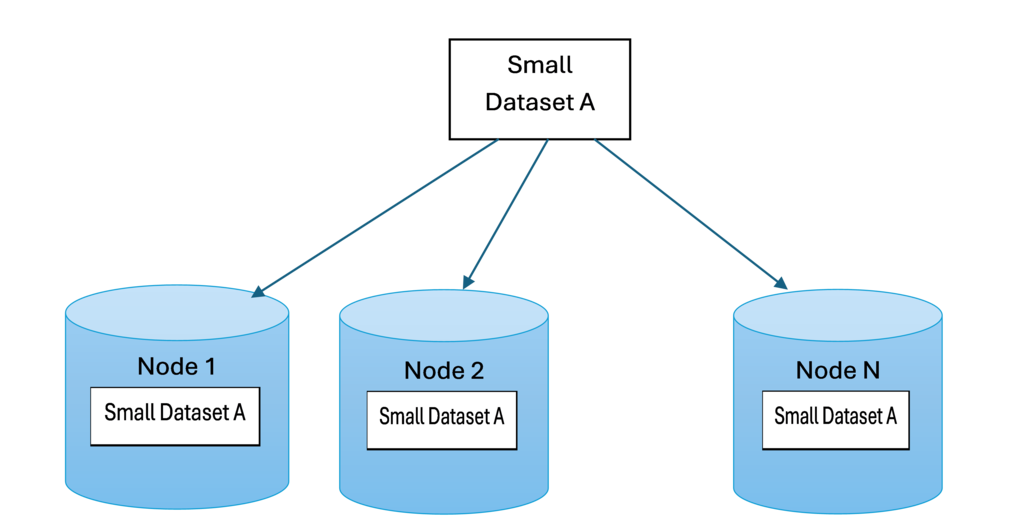
Broadcast Join (replication Partitioning)
Broadcast joins (known as replication partition) in Spark involve sending a smaller dataset to all nodes in the cluster, that means all nodes have the same small dataset or says duplicated small dataset to all nodes. It is allowing each partition of the larger dataset to be joined with the smaller dataset locally without requiring a shuffle.
Detailed comparison of each partitioning methods
| Partitioning Method | Purpose | When Used | Shuffling | How It Works |
| General Partitioning (partitionBy()) | Organizing data on disk (file partitioning) | When writing data (e.g., Parquet, ORC) | No shuffle | Data is partitioned into folders by column values when writing to disk |
| Hash Partitioning (repartition(column_name)) | Evenly distributing data for parallel processing | During processing for joins, groupBy, etc. | Yes (shuffle data across nodes) | Applies a hash function to the column value to distribute data evenly across partitions |
| Round Robin Partitioning | Distributes rows evenly without considering values | When you want even distribution but don’t need value-based grouping | Yes (shuffle) | Rows are evenly assigned to partitions in a circular manner, disregarding content |
| Range Partitioning | Distribute data into partitions based on a range of values | When processing or writing range-based data (e.g., dates) | Yes (if used internally during processing) | Data is sorted by the partitioning column and divided into ranges across partitions |
| Custom Partitioning | Apply custom logic to determine how data is partitioned | For complex partitioning logic in special use cases | Yes (depends on logic) | User-defined partitioning function determines partition assignment |
| Co-location Partitioning | Ensures two datasets are partitioned the same way (to avoid shuffling during joins) | To optimize joins when both datasets have the same partitioning column | No (if already partitioned the same way) | Both datasets are partitioned by the same key (e.g., by user_id) to avoid shuffle during joins |
| Broadcast Join (Partitioning) | Send a small dataset to all nodes for local joins without shuffle | When joining a small dataset with a large one | No shuffle (avoids shuffle by broadcasting) | The smaller dataset is broadcast to each node, avoiding the need for shuffling large data |
Please do not hesitate to contact me if you have any questions at William . chen @ mainri.ca
(remove all space from the email account 😊)