To read from and write to Unity Catalog in PySpark, you typically work with tables registered in the catalog rather than directly with file paths. Unity Catalog tables can be accessed using the format catalog_name.schema_name.table_name.
Reading from Unity Catalog
To read a table from Unity Catalog, specify the table’s full path:
# Reading a table
df = spark.read.table("catalog.schema.table")
df.show()
# Using Spark SQL
df = spark.sql("SELECT * FROM catalog.schema.table")
Writing to Unity Catalog
To write data to Unity Catalog, you specify the table name in the saveAsTable method:
# Writing a DataFrame to a new table
df.write.format("delta") \
.mode("overwrite") \
.saveAsTable("catalog.schema.new_table")
Options for Writing to Unity Catalog:
format: Set to "delta" for Delta Lake tables, as Unity Catalog uses Delta format.
mode: Options include overwrite, append, ignore, and error.
Example: Read, Transform, and Write Back to Unity Catalog
# Read data from a Unity Catalog table
df = spark.read.table("catalog_name.schema_name.source_table")
# Perform transformations
transformed_df = df.filter(df["column_name"] > 10)
# Write transformed data back to a different table
transformed_df.write.format("delta") \
.mode("overwrite") \
.saveAsTable("catalog_name.schema_name.target_table")
Lacks built-in schema enforcement; additional steps needed for ACID or schema evolution.
Detailed Comparison and Notes:
Unity Catalog
Delta: Unity Catalog fully supports Delta format, allowing for schema evolution, ACID transactions, and built-in security and governance.
JSON and CSV: To use JSON or CSV in Unity Catalog, convert them into Delta tables or load them as temporary views before making them part of Unity’s governed catalog. This is because Unity Catalog enforces structured data formats with schema definitions.
Blob Storage & ADLS (Azure Data Lake Storage)
Delta: Blob Storage and ADLS support Delta tables if the Delta Lake library is enabled. Delta on Blob or ADLS retains most Delta features but may lack some governance capabilities found in Unity Catalog.
JSON & CSV: Both Blob and ADLS provide support for JSON and CSV formats, allowing flexibility with semi-structured data. However, they do not inherently support schema enforcement, ACID compliance, or governance features without Delta Lake.
Delta Table Benefits:
Schema Evolution and Enforcement: Delta enables schema evolution, essential in big data environments.
Time Travel: Delta provides versioning, allowing access to past versions of data.
ACID Transactions: Delta ensures consistency and reliability in large-scale data processing.
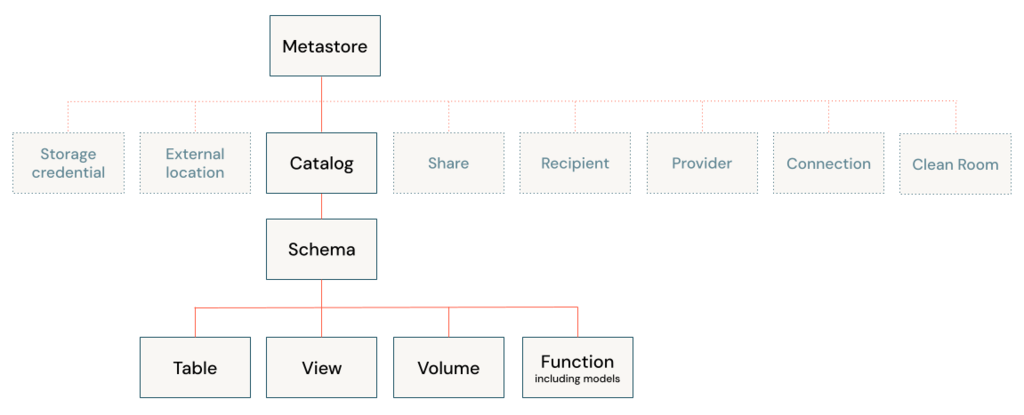
A catalog is the primary unit of data organization in the Azure Databricks Unity Catalog data governance model. it is the first layer in Unity Catalog’s three-level namespace (catalog.schema.table-etc). They contain schemas, which in turn can contain tables, views, volumes, models, and functions. Catalogs are registered in a Unity Catalog metastore in your Azure Databricks account.
Catalogs
Organize my data into catalogs
Each catalog should represent a logical unit of data isolation and a logical category of data access, allowing an efficient hierarchy of grants to flow down to schemas and the data objects that they contain.
Catalogs therefore often mirror organizational units or software development lifecycle scopes. You might choose, for example, to have a catalog for production data and a catalog for development data, or a catalog for non-customer data and one for sensitive customer data.
Data isolation using catalogs
Each catalog typically has its own managed storage location to store managed tables and volumes, providing physical data isolation at the catalog level.
Catalog-level privileges
grants on any Unity Catalog object are inherited by children of that object, owning a catalog
Catalog types
Standard catalog: the typical catalog, used as the primary unit to organize your data objects in Unity Catalog.
Foreign catalog: a Unity Catalog object that is used only in Lakehouse Federation scenarios.
Default catalog
If your workspace was enabled for Unity Catalog automatically, the pre-provisioned workspace catalog is specified as the default catalog. A workspace admin can change the default catalog as needed.
Workspace-catalog binding
If you use workspaces to isolate user data access, you might want to use workspace-catalog bindings. Workspace-catalog bindings enable you to limit catalog access by workspace boundaries.
Create catalogs
Requirements: be an Azure Databricks metastore admin or have the CREATE CATALOG privilege on the metastore
To create a catalog, you can use Catalog Explorer, a SQL command, the REST API, the Databricks CLI, or Terraform. When you create a catalog, two schemas (databases) are automatically created: default and information_schema.
Catalog Explorer
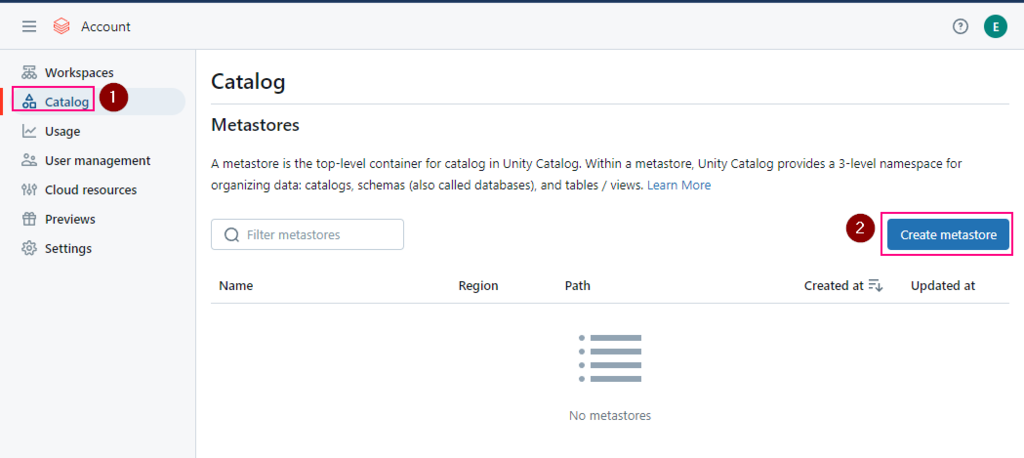
Log in to a workspace that is linked to the metastore.
Click Catalog.
Click the Create Catalog button.
On the Create a new catalog dialog, enter a Catalog name and select the catalog Type that you want to create: Standard catalog: a securable object that organizes data and AI assets that are managed by Unity Catalog. For all use cases except Lakehouse Federation and catalogs created from Delta Sharing shares.
Foreign catalog: a securable object that mirrors a database in an external data system using Lakehouse Federation.
Shared catalog: a securable object that organizes data and other assets that are shared with you as a Delta Sharing share. Creating a catalog from a share makes those assets available for users in your workspace to read.
SQL
standard catalog
CREATE CATALOG [ IF NOT EXISTS ] <catalog-name>
[ MANAGED LOCATION '<location-path>' ]
[ COMMENT <comment> ];
<catalog-name>: A name for the catalog.
<location-path>: Optional but strongly recommended. e.g. <location-path>: ‘abfss://my-container-name@storage-account-name.dfs.core.windows.net/finance’ or ‘abfss://my-container-name@storage-account-name.dfs.core.windows.net/finance/product’
shared catalog
CREATE CATALOG [IF NOT EXISTS] <catalog-name>
USING SHARE <provider-name>.<share-name>;
[ COMMENT <comment> ];
foreign catalog
CREATE FOREIGN CATALOG [IF NOT EXISTS] <catalog-name> USING CONNECTION <connection-name>
OPTIONS [(database '<database-name>') | (catalog '<external-catalog-name>')];
<catalog-name>: Name for the catalog in Azure Databricks.
<connection-name>: The connection object that specifies the data source, path, and access credentials.
<database-name>: Name of the database you want to mirror as a catalog in Azure Databricks. Not required for MySQL, which uses a two-layer namespace. For Databricks-to-Databricks Lakehouse Federation, use catalog ‘<external-catalog-name>’ instead.
<external-catalog-name>: Databricks-to-Databricks only: Name of the catalog in the external Databricks workspace that you are mirroring.
Schemas
Schema is a child of a catalog and can contain tables, views, volumes, models, and functions. Schemas provide more granular categories of data organization than catalogs.
Precondition
Have a Unity Catalog metastore linked to the workspace where you perform the schema creation
Have the USE CATALOG and CREATE SCHEMA data permissions on the schema’s parent catalog
To specify an optional managed storage location for the tables and volumes in the schema, an external location must be defined in Unity Catalog, and you must have the CREATE MANAGED STORAGE privilege on the external location.
Create a schema
To create a schema in Unity Catalog, you can use Catalog Explorer or SQL commands.
To create a schema in Hive metastore, you must use SQL commands.
Catalog Explorer
Log in to a workspace that is linked to the Unity Catalog metastore.
Click Catalog.
In the Catalog pane on the left, click the catalog you want to create the schema in.
In the detail pane, click Create schema.
Give the schema a name and add any comment that would help users understand the purpose of the schema.
(Optional) Specify a managed storage location. Requires the CREATE MANAGED STORAGE privilege on the target external location. See Specify a managed storage location in Unity Catalog and Managed locations for schemas.
Click Create.
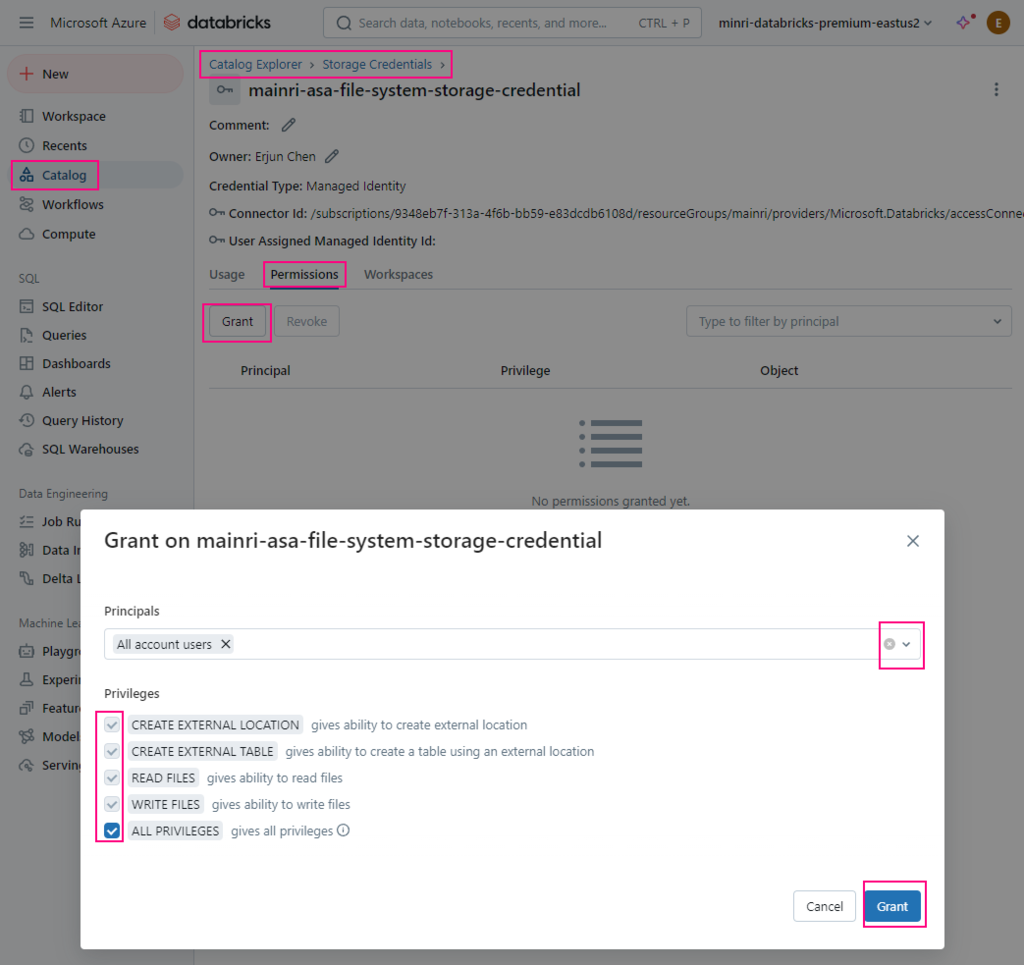
Grant privileges on the schema. See Manage privileges in Unity Catalog.
Unity Catalog introduces several new securable objects to grant privileges to data in cloud object storage.
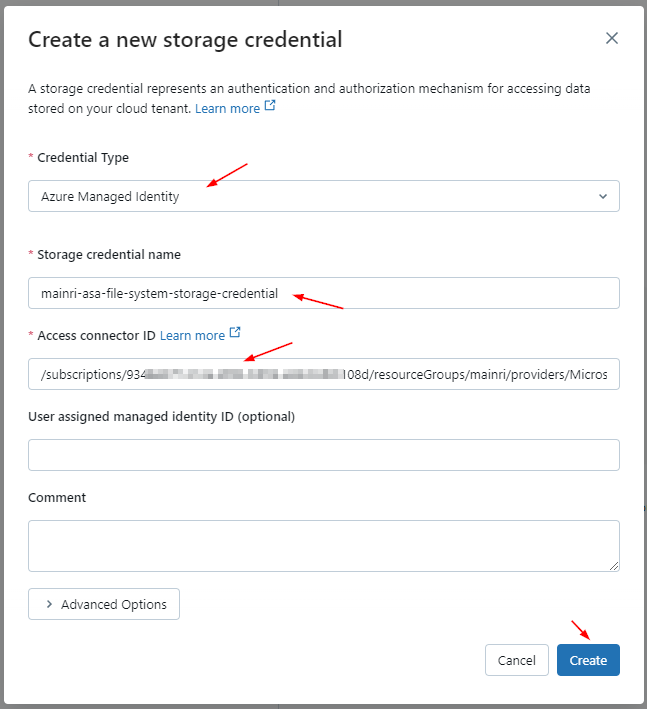
A storage credential is a securable object representing an Azure managed identity or Microsoft Entra ID service principal.
Once a storage credential is created access to it can be granted to principals, users and groups.
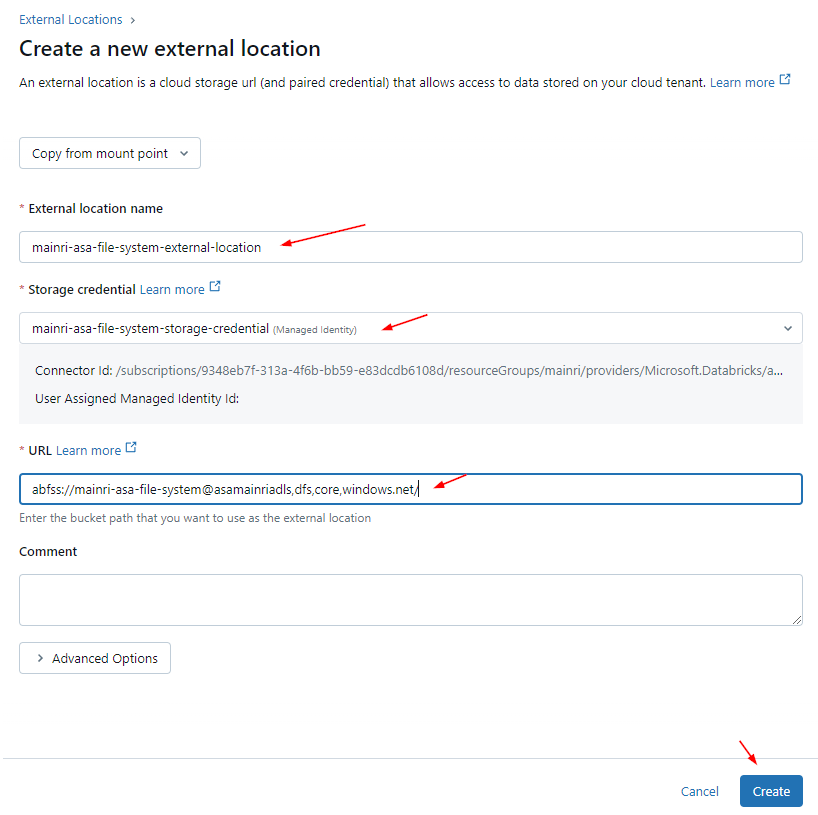
An external location is a securable object that combines a storage path with a storage credential that authorizes access to that path.
Storage credential
A storage credential is an authentication and authorization mechanism for accessing data stored on your cloud tenant.
Once a storage credential is created access to it can be granted to principals (users and groups).
Storage credentials are primarily used to create external locations, which scope access to a specific storage path. Storage credential names are unqualified and must be unique within the metastore.
External Location
An object that combines a cloud storage path with a storage credential that authorizes access to the cloud storage path.
Step by step Demo
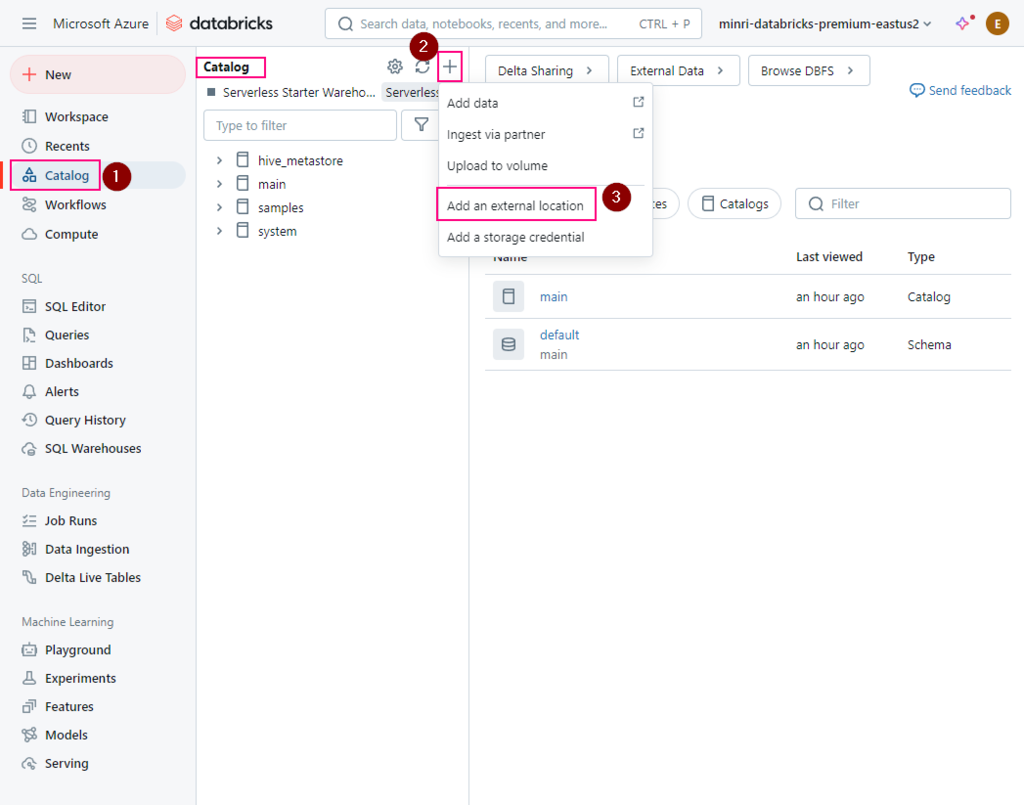
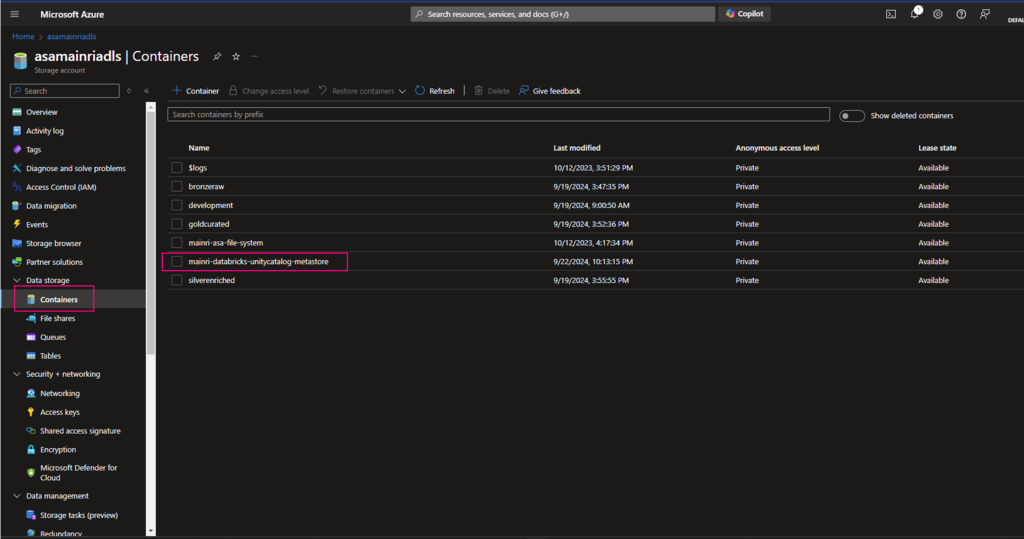
Let’s say I have a container on ADLS, called “mainri-asa-file-system”
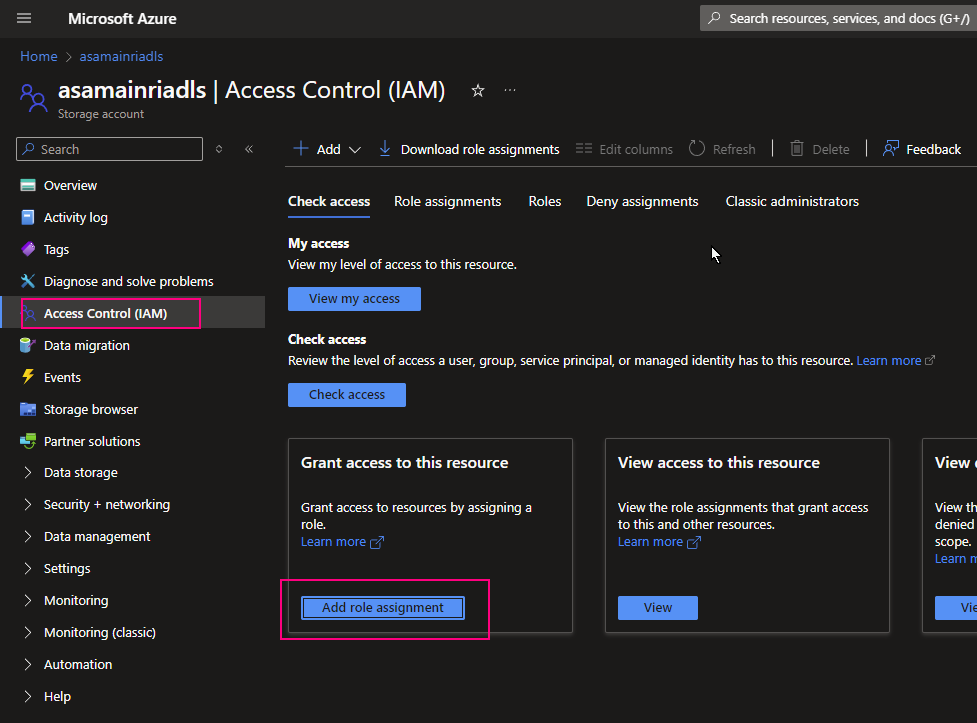
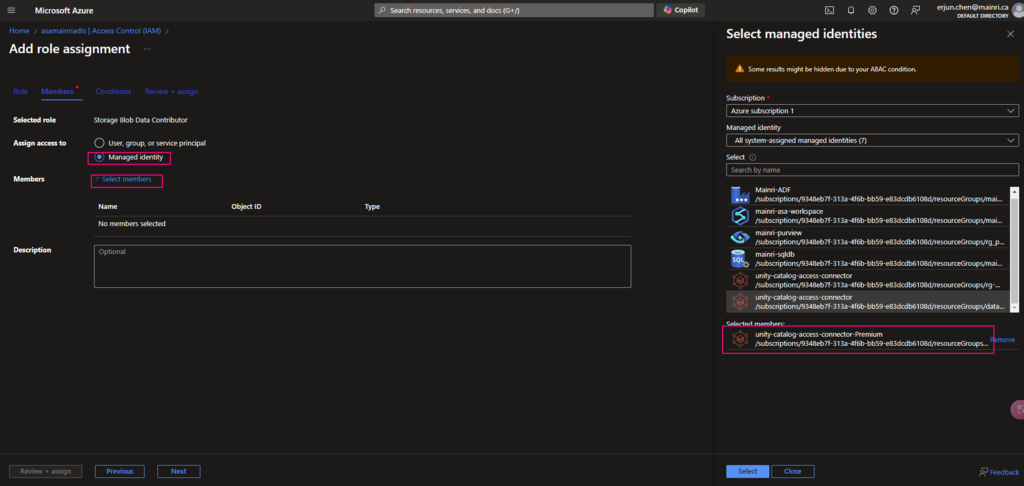
1. Allow “access connector” for azure databricks to access
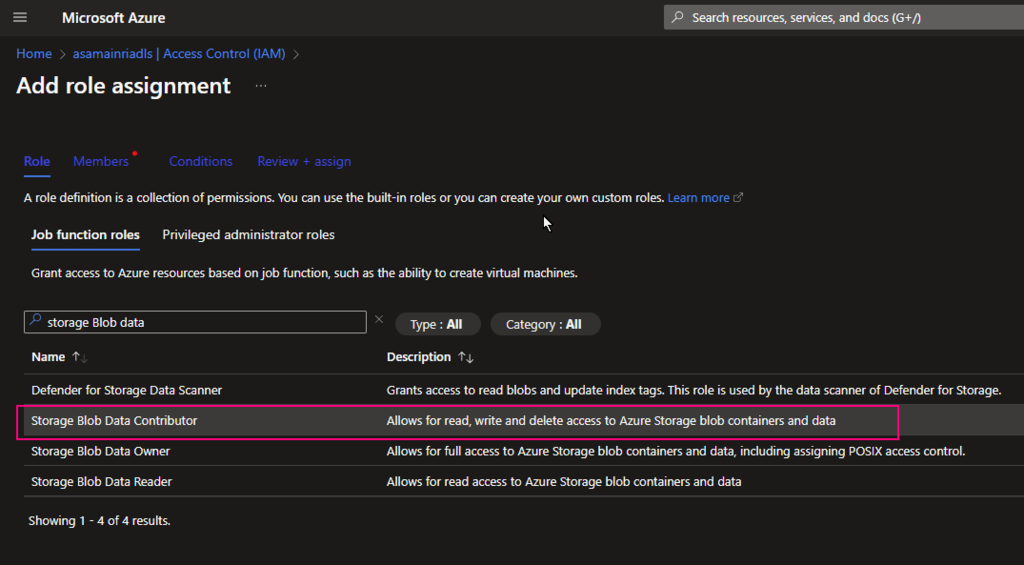
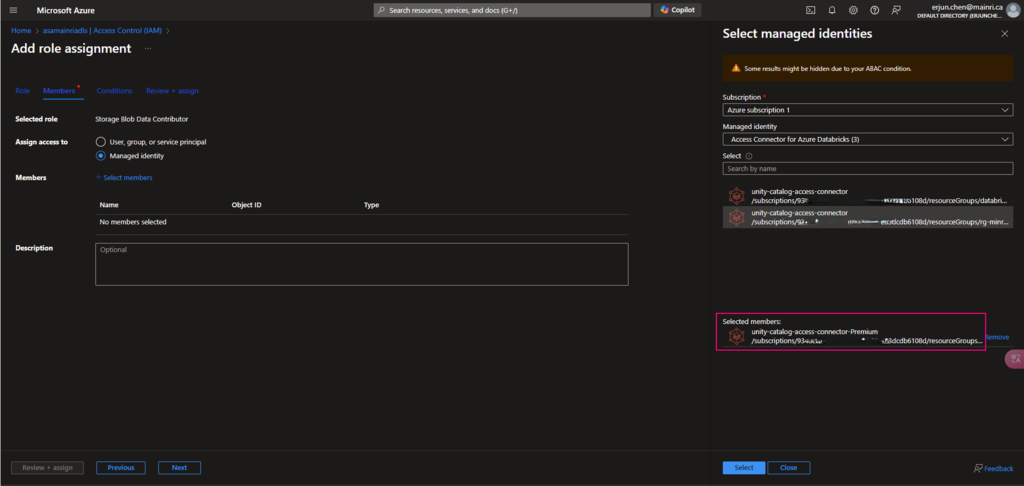
Azure Portal > storage Account > Access Control (IAM) > add role assignment
Add “storage Blob Data Contributor” role
Assign to the access connector for azure databricks
2. Create Storage credential
Azure Databricas > Catalog > add a storage credential
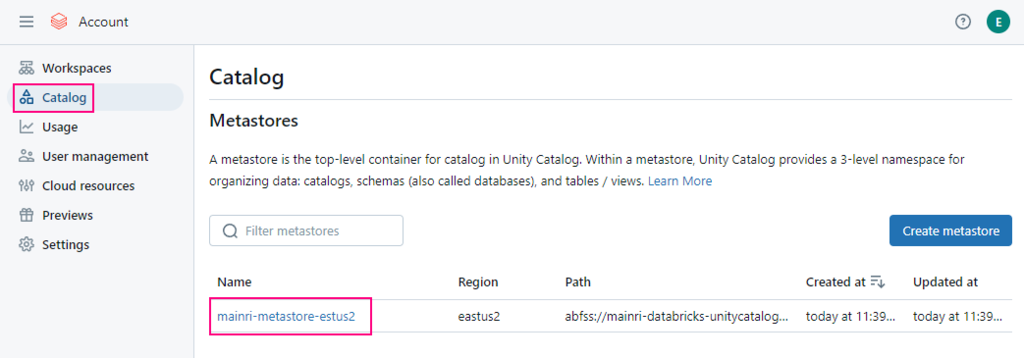
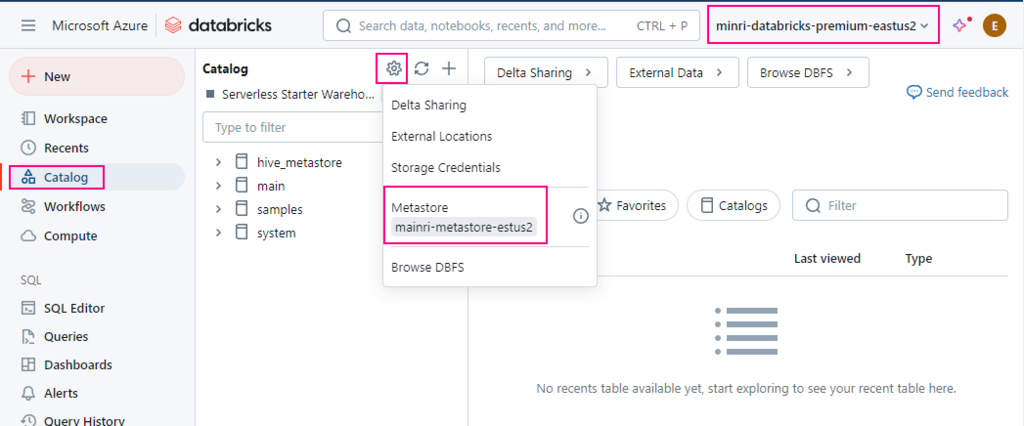
A metastore is the top-level container for data in Unity Catalog. Unity Catalog metastore register metadata about securable objects (such as tables, volumes, external locations, and shares) and the permissions that govern access to them.
Each metastore exposes a three-level namespace (catalog.schema.table) by which data can be organized. You must have one metastore for each region in which your organization operates.
Microsoft said that Databricks began to enable new workspaces for Unity Catalog automatically on November 9, 2023, with a rollout proceeding gradually across accounts. Otherwise, we must follow the instructions in this article to create a metastore in your workspace region.
Preconditions
Before we begin
1. Microsoft Entra ID Global Administrator
The first Azure Databricks account admin must be a Microsoft Entra ID Global Administrator
The first Azure Databricks account admin must be a Microsoft Entra ID Global Administrator at the time that they first log in to the Azure Databricks account console.
Upon first login, that user becomes an Azure Databricks account admin and no longer needs the Microsoft Entra ID Global Administrator role to access the Azure.
2. Premium Tire
Databricks workspaces Pricing tire must be Premium Tire.
3. The same region
Databricks region is in the same as ADLS’s region. Each region allows one metastore only.
Manual create metastore and enable unity catalog process
Create an ADLS G2 (if you did not have) Create storage account and container to store manage table and volume data at the metastore level, the container will be the root storage for the unity catalog metastore
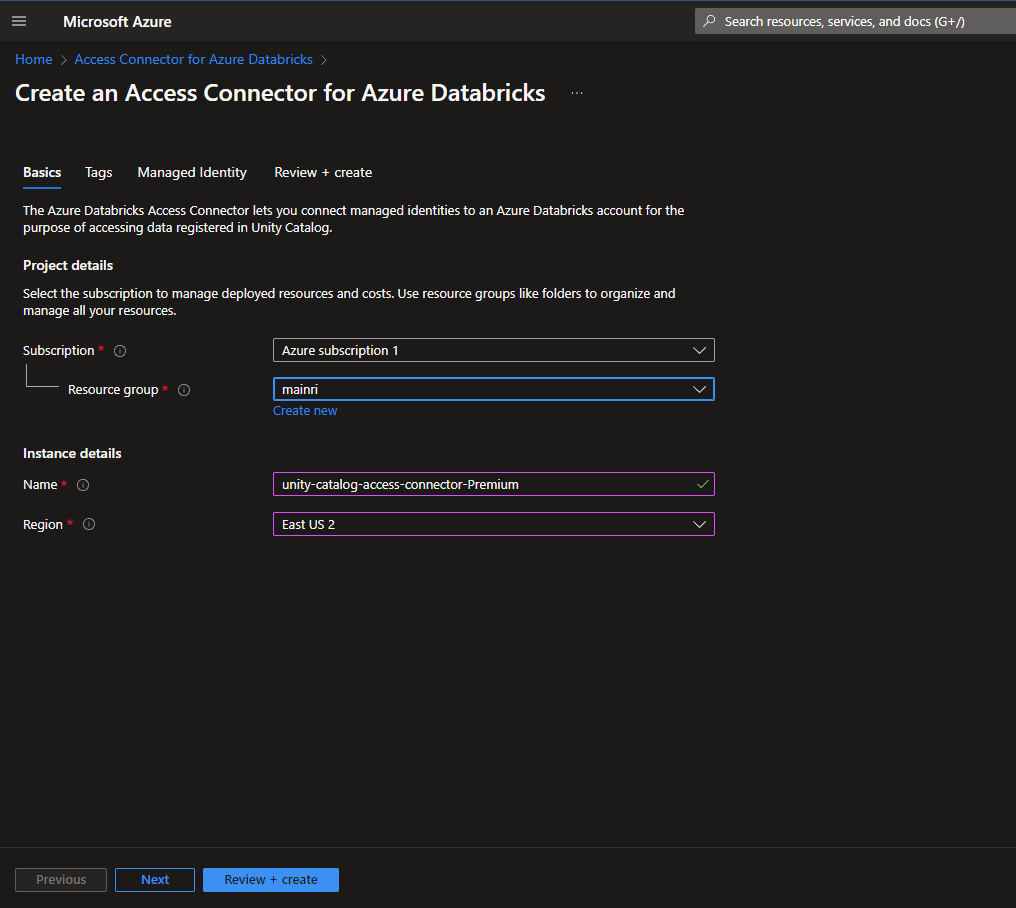
Create an Access Connector for Azure Databricks
Grant “Storage Blob Data Contributor” role to access Connector for Azure Databricks on ADLS G2 storage Account
Enable Unity Catalog by creating Metastore and assigning to workspace
Step by step Demo
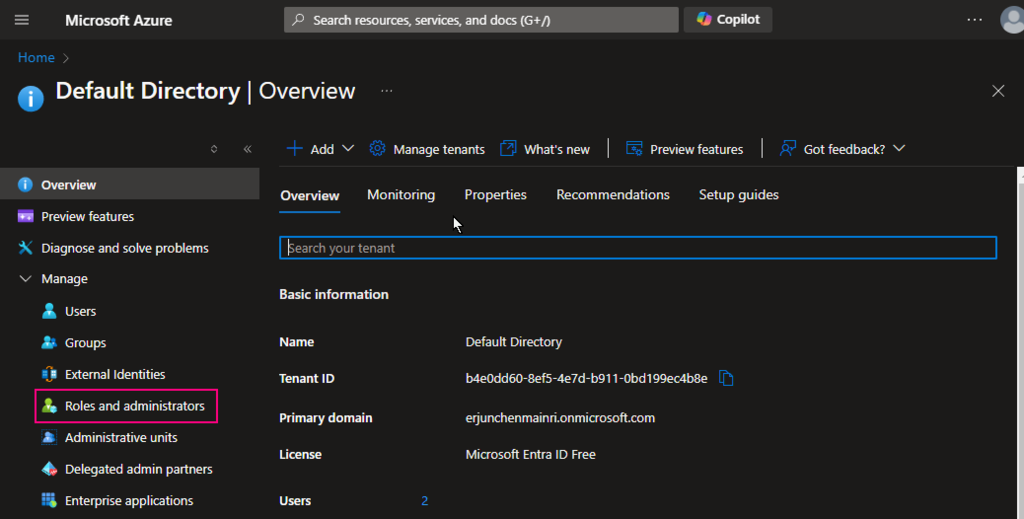
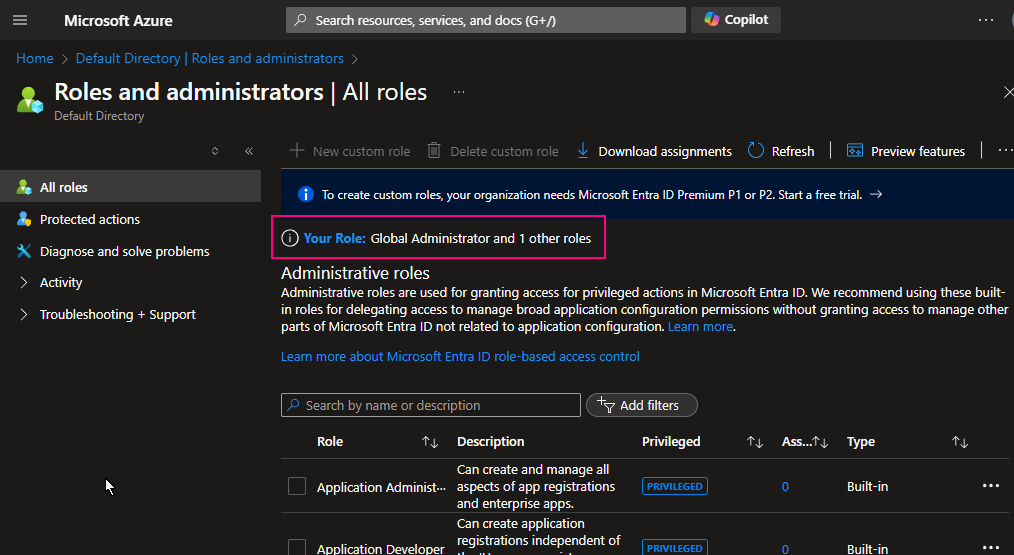
1. Check Entra ID role.
To check whether I am a Microsoft Entra ID Global Administrator role.
Azure Portal > Entra ID > Role and administrators
I am a Global Administrator
2. Create a container for saving metastore
Create a container at ROOT of ADLS Gen2
Since we have created an ADLS Gen2, directly move to create a container at root of ADLS.
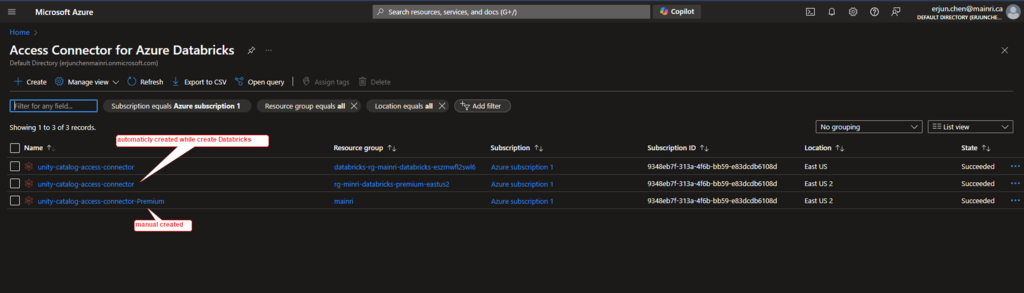
3. Create an Access Connector for Databricks
If it did not automatically create while you create Azure databricks service, manual create one.
Azure portal > Access Connector for Databricks
once all required fields filled, we can see a new access connector created.
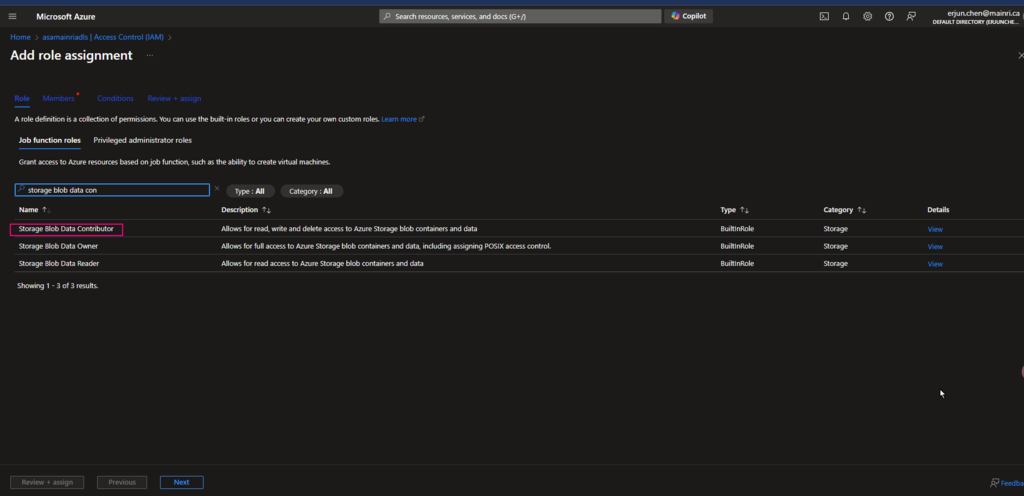
4. Grant Storage Blob Data Contributor to access Connector
Add “storage Blob data contributor” role assign to “access connector for Azure Databricks” I just created.
Azure Portal > ADLS Storage account > Access Control (IAM) > add role
Continue to add role assignment
5. Create a metastore
If you are an account admin, you can login accounts console, otherwise, ask your account admin to help.
before you begin to create a metastore, make sure
You must be an Azure Databricks account admin. The first Azure Databricks account admin must be a Microsoft Entra ID Global Administrator at the time that they first log in to the Azure Databricks account console. Upon first login, that user becomes an Azure Databricks account admin and no longer needs the Microsoft Entra ID Global Administrator role to access the Azure Databricks account. The first account admin can assign users in the Microsoft Entra ID tenant as additional account admins (who can themselves assign more account admins). Additional account admins do not require specific roles in Microsoft Entra ID.
The workspaces that you attach to the metastore must be on the Azure Databricks Premium plan.
If you want to set up metastore-level root storage, you must have permission to create the following in your Azure tenant
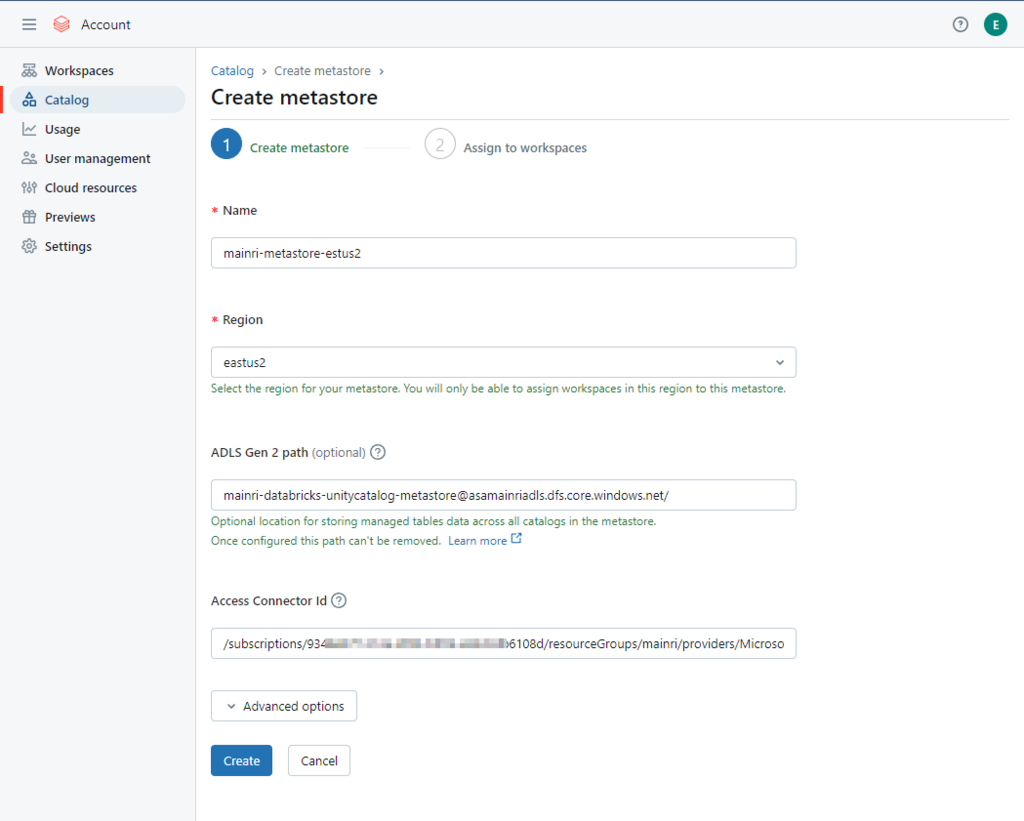
Select the same region for your metastore. You will only be able to assign workspaces in this region to this metastore.
Container name and path The pattern is: <contain_name>@<storage_account_name>.dfs.core.windows.net/<path> For this demo I used this mainri-databricks-unitycatalog-metastore-eastus2@asamainriadls.dfs.core.windows.net/
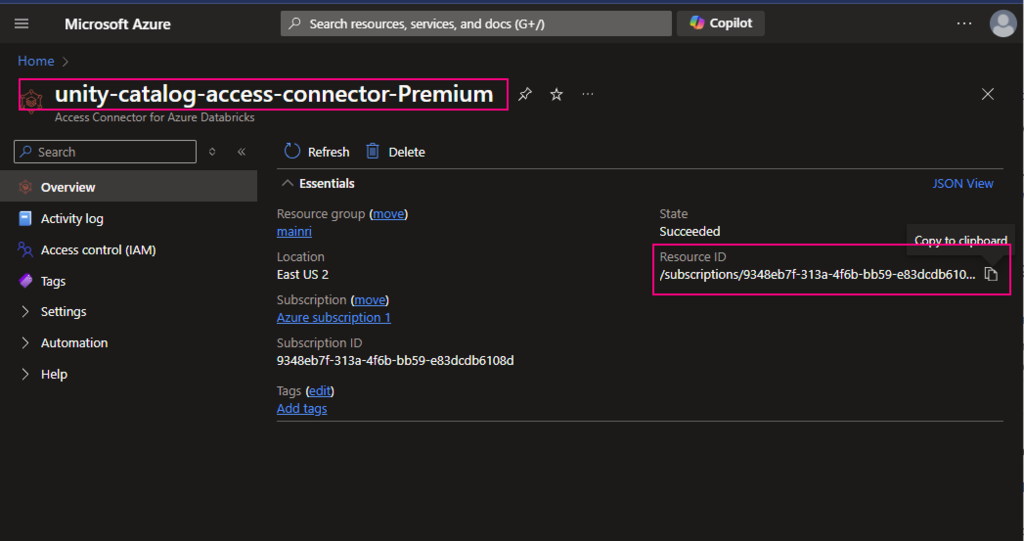
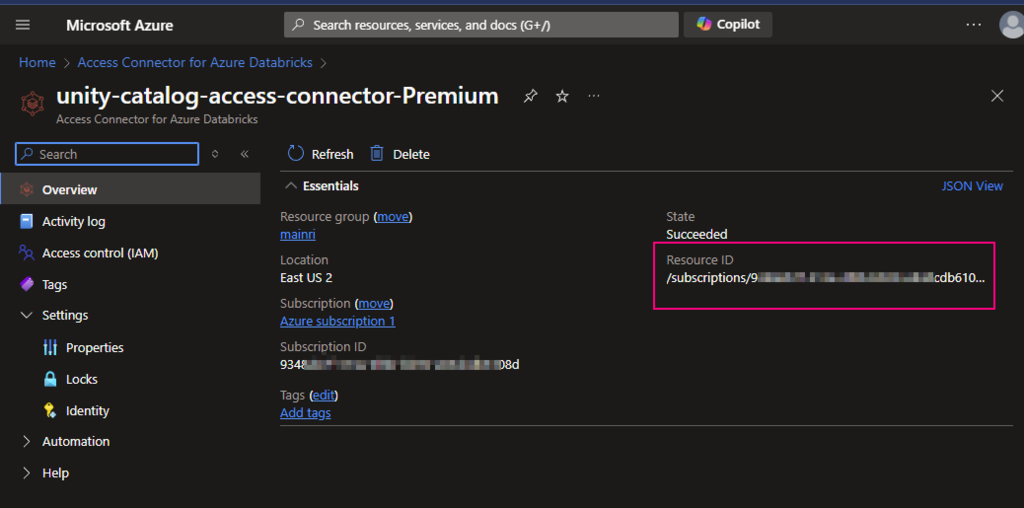
Access connector ID The pattern is: /subscriptions/{sub-id}/resourceGroups/{rg-name}/providers/Microsoft.databricks/accessconnects/<connector-name>
Find out the Access connector ID
Azure portal > Access Connector for Azure Databricks
For this demo I used this /subscriptions/9348XXXXXXXXXXX6108d/resourceGroups/mainri/providers/Microsoft.Databricks/accessConnectors/unity-catalog-access-connector-Premiu
Looks like this
Enable Unity catalog
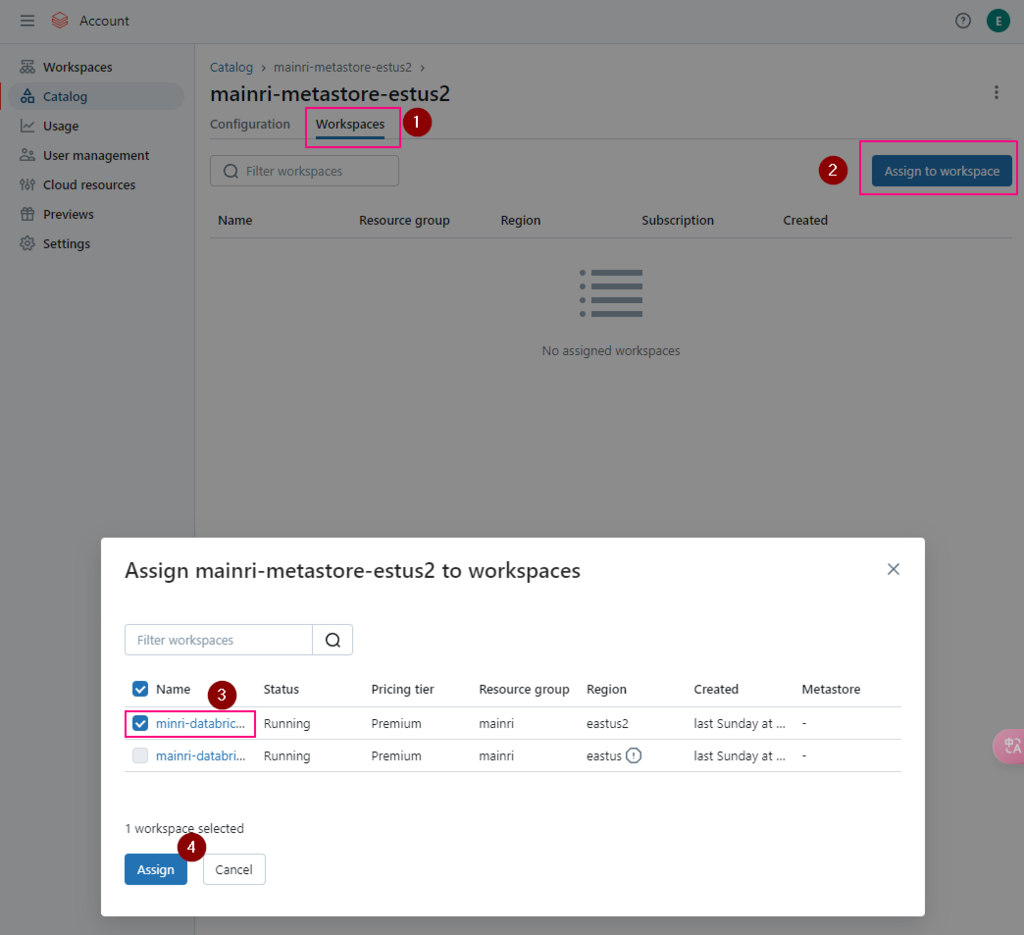
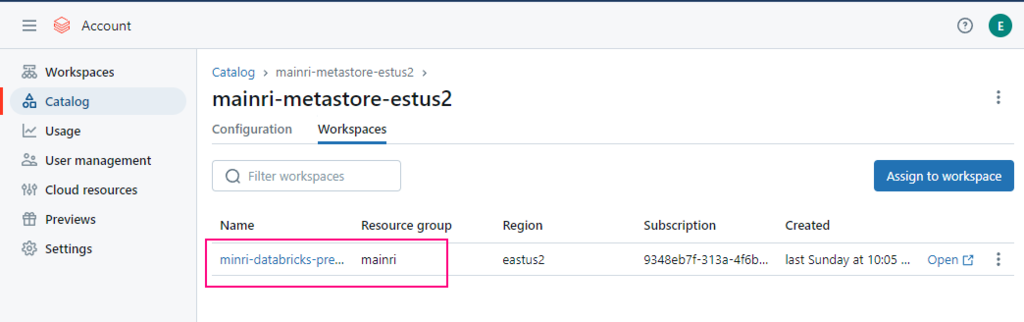
Assign to workspace
To enable an Azure Databricks workspace for Unity Catalog, you assign the workspace to a Unity Catalog metastore using the account console:
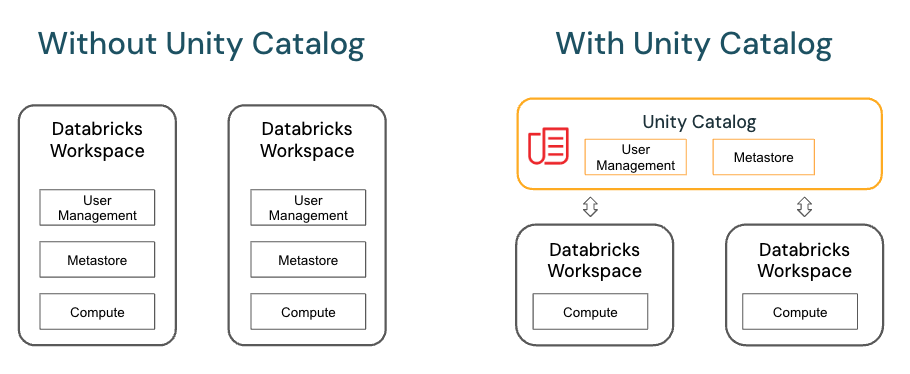
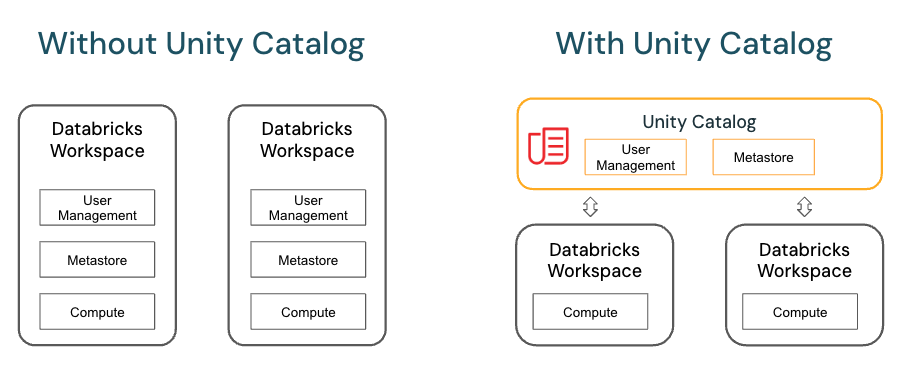
Unity Catalog is a fine-grained data governance solution for data present in a Data Lake for managing data governance, access control, and centralizing metadata across multiple workspaces. Unity Catalog provides centralized access control, auditing, lineage, and data discovery capabilities across Azure Databricks workspaces. It brings a new layer of data management and security to your Databricks environment
Unity Catalog provides centralized access control, auditing, lineage, and data discovery capabilities across Azure Databricks workspaces.
Key features of Unity Catalog include
Define once, secure everywhere: Unity Catalog offers a single place to administer data access policies that apply across all workspaces.
Standards-compliant security model: Unity Catalog’s security model is based on standard ANSI SQL and allows administrators to grant permissions in their existing data lake using familiar syntax, at the level of catalogs, schemas (also called databases), tables, and views.
Built-in auditing and lineage: Unity Catalog automatically captures user-level audit logs that record access to your data. Unity Catalog also captures lineage data that tracks how data assets are created and used across all languages.
Data discovery: Unity Catalog lets you tag and document data assets, and provides a search interface to help data consumers find data.
System tables (Public Preview): Unity Catalog lets you easily access and query your account’s operational data, including audit logs, billable usage, and lineage.
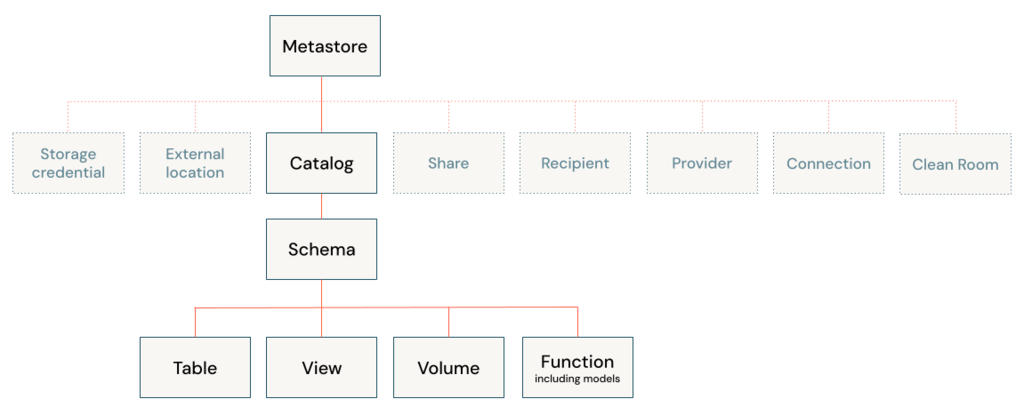
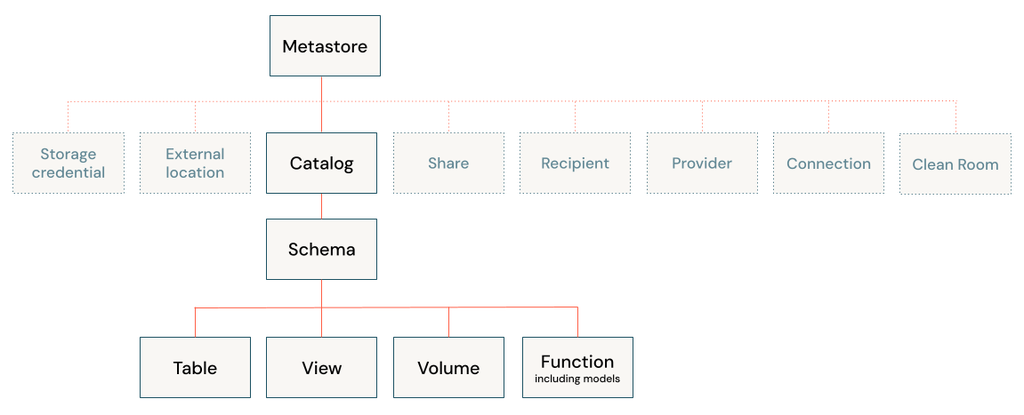
Unity Catalog object model
The hierarchy of database objects in any Unity Catalog metastore is divided into three levels, represented as a three-level namespace (catalog.schema.table-etc)
Metastore
The metastore is the top-level container for metadata in Unity Catalog. It registers metadata about data and AI assets and the permissions that govern access to them. For a workspace to use Unity Catalog, it must have a Unity Catalog metastore attached.
Object hierarchy in the metastore
In a Unity Catalog metastore, the three-level database object hierarchy consists of catalogs that contain schemas, which in turn contain data and AI objects, like tables and models.
Level one: Catalogs are used to organize your data assets and are typically used as the top level in your data isolation scheme.
Level two: Schemas (also known as databases) contain tables, views, volumes, AI models, and functions.
Working with database objects in Unity Catalog is very similar to working with database objects that are registered in a Hive metastore, with the exception that a Hive metastore doesn’t include catalogs in the object namespace. You can use familiar ANSI syntax to create database objects, manage database objects, manage permissions, and work with data in Unity Catalog. You can also create database objects, manage database objects, and manage permissions on database objects using the Catalog Explorer UI.
Granting and revoking access to database objects
You can grant and revoke access to securable objects at any level in the hierarchy, including the metastore itself. Access to an object implicitly grants the same access to all children of that object, unless access is revoked.
GRANT CREATE TABLE ON SCHEMA mycatalog.myschema TO `finance-team`;
Azure Databricks is a managed platform for running Apache Spark jobs. In this post, I’ll go through some key Databricks terms to give you an overview of the different points you’ll use when running Databricks jobs (sorted by alphabet):
Catalog (Unity Catalog)
the Unity Catalog is a feature that provides centralized governance for data, allowing you to manage access to data across different Databricks workspaces and cloud environments. It helps define permissions, organize tables, and manage metadata, supporting multi-cloud and multi-workspace environments. Key benefits include:
Support for multi-cloud data governance.
Centralized access control and auditing.
Data lineage tracking.
Delta table
A Delta table is a data management solution provided by Delta Lake, an open-source storage layer that brings ACID transactions to big data workloads. A Delta table stores data as a directory of files on cloud object storage and registers table metadata to the metastore within a catalog and schema. By default, all tables created in Databricks are Delta tables.
External tables
External tables are tables whose data lifecycle, file layout, and storage location are not managed by Unity Catalog. Multiple data formats are supported for external tables.
CREATE EXTERNAL TABLE my_external_table (
id INT,
name STRING,
age INT
)
LOCATION 'wasbs://[container]@[account].blob.core.windows.net/data/';
External Data Source
A connection to a data store that isn’t natively in Databricks but can be queried through a connection.
External Data Sources are typically external databases or data services (e.g., Azure SQL Database, Azure Synapse Analytics, Amazon RDS, or other relational or NoSQL databases). These sources are accessed via connectors (JDBC, ODBC, etc.) within Databricks.
The Hive Metastore is the metadata repository for the data in Databricks, storing information about tables and databases. It’s used by the Spark SQL engine to manage metadata for the tables and to store information like schemas, table locations, and partitions. In Azure Databricks:
Schemas: Column names, types, and table structure.
Table locations: The path to where the actual data resides (in HDFS, Azure Data Lake, S3, etc.).
Partitions: If the table is partitioned, the metadata helps optimize query performance.
By default, each Databricks workspace has its own managed Hive metastore.
You can also connect to an external Hive metastore that is shared across multiple Databricks workspaces or use Azure-managed services like Azure SQL Database for Hive metadata storage.
Managed tables
Managed tables are the preferred way to create tables in Unity Catalog. Unity Catalog fully manages their lifecycle, file layout, and storage. Unity Catalog also optimizes their performance automatically. Managed tables always use the Delta table format.
Managed tables reside in a managed storage location that you reserve for Unity Catalog. Because of this storage requirement, you must use CLONE or CREATE TABLE AS SELECT (CTAS) if you want to copy existing Hive tables to Unity Catalog as managed tables.
Mounting Data
Mounting external storage into Databricks as if it’s part of the Databricks File System (DBFS)
In Databricks, Workflows are a way to orchestrate data pipelines, machine learning tasks, and other computational processes. Workflows allow you to automate the execution of notebooks, Python scripts, JAR files, or any other job task within Databricks and run them on a schedule, trigger, or as part of a complex pipeline.
Key Components of Workflows in Databricks:
Jobs: Workflows in Databricks are typically managed through jobs. A job is a scheduled or triggered run of a notebook, script, or other tasks in Databricks. Jobs can consist of a single task or multiple tasks linked together.
Task: Each task in a job represents an individual unit of work. You can have multiple tasks in a job, which can be executed sequentially or in parallel.
Triggers: Workflows can be triggered manually, based on a schedule (e.g., hourly, daily), or triggered by an external event (such as a webhook).
Cluster: When running a job in a workflow, you need to specify a Databricks cluster (either an existing cluster or one that is started just for the job). Workflows can also specify job clusters, which are clusters that are spun up and terminated automatically for the specific job.
Types of Workflows
Single-task Jobs: These jobs consist of just one task, like running a Databricks notebook or a Python/Scala/SQL script. You can schedule these jobs to run at specific intervals or trigger them manually.
Multi-task Workflows: These workflows are more complex and allow for creating pipelines of interdependent tasks that can be run in sequence or in parallel. Each task can have dependencies on the completion of previous tasks, allowing you to build complex pipelines that branch based on results.Example: A data pipeline might consist of three tasks:
Task 1: Ingest data from a data lake into a Delta table.
Task 2: Perform transformations on the ingested data.
Task 3: Run a machine learning model on the transformed data.
Parameterized Workflows: You can pass parameters to a job when scheduling it, allowing for more dynamic behavior. This is useful when you want to run the same task with different inputs (e.g., processing data for different dates).
Creating Workflows in Databricks
Workflows can be created through the Jobs UI in Databricks or programmatically using the Databricks REST API.
Example of Creating a Simple Workflow:
Navigate to the Jobs Tab:
In Databricks, go to the Jobs tab in the workspace.
Create a New Job:
Click Create Job.
Specify the name of the job.
Define a Task:
Choose a task type (Notebook, JAR, Python script, etc.).
Select the cluster to run the job on (or specify a job cluster).
Add parameters or libraries if required.
Schedule or Trigger the Job:
Set a schedule (e.g., run every day at 9 AM) or choose manual triggering.
You can also configure alerts or notifications (e.g., send an email if the job fails).
Multi-task Workflow Example:
Add Multiple Tasks:
After creating a job, you can add more tasks by clicking Add Task.
For each task, you can specify dependencies (e.g., Task 2 should run only after Task 1 succeeds).
Manage Dependencies:
You can configure tasks to run in sequence or in parallel.
Define whether a task should run on success, failure, or based on a custom condition.
Key Features of Databricks Workflows:
Orchestration: Allows for complex job orchestration, including dependencies between tasks, retries, and conditional logic.
Job Scheduling: You can schedule jobs to run at regular intervals (e.g., daily, weekly) using cron expressions or Databricks’ simple scheduler.
Parameterized Runs: Pass parameters to notebooks, scripts, or other tasks in the workflow, allowing dynamic control of jobs.
Cluster Management: Workflows automatically handle cluster management, starting clusters when needed and shutting them down after the job completes.
Notifications: Workflows allow setting up notifications on job completion, failure, or other conditions. These notifications can be sent via email, Slack, or other integrations.
Retries: If a job or task fails, you can configure it to automatically retry a specified number of times before being marked as failed.
Versioning: Workflows can be versioned, so you can track changes and run jobs based on different versions of a notebook or script.
Common Use Cases for Databricks Workflows:
ETL Pipelines: Automating the extraction, transformation, and loading (ETL) of data from source systems to a data lake or data warehouse.
Machine Learning Pipelines: Orchestrating the steps involved in data preprocessing, model training, evaluation, and deployment.
Batch Processing: Scheduling large-scale data processing tasks to run on a regular basis.
Data Ingestion: Automating the ingestion of raw data into Delta Lake or other storage solutions.
Alerts and Monitoring: Running scheduled jobs that trigger alerts based on conditions in the data (e.g., anomaly detection).