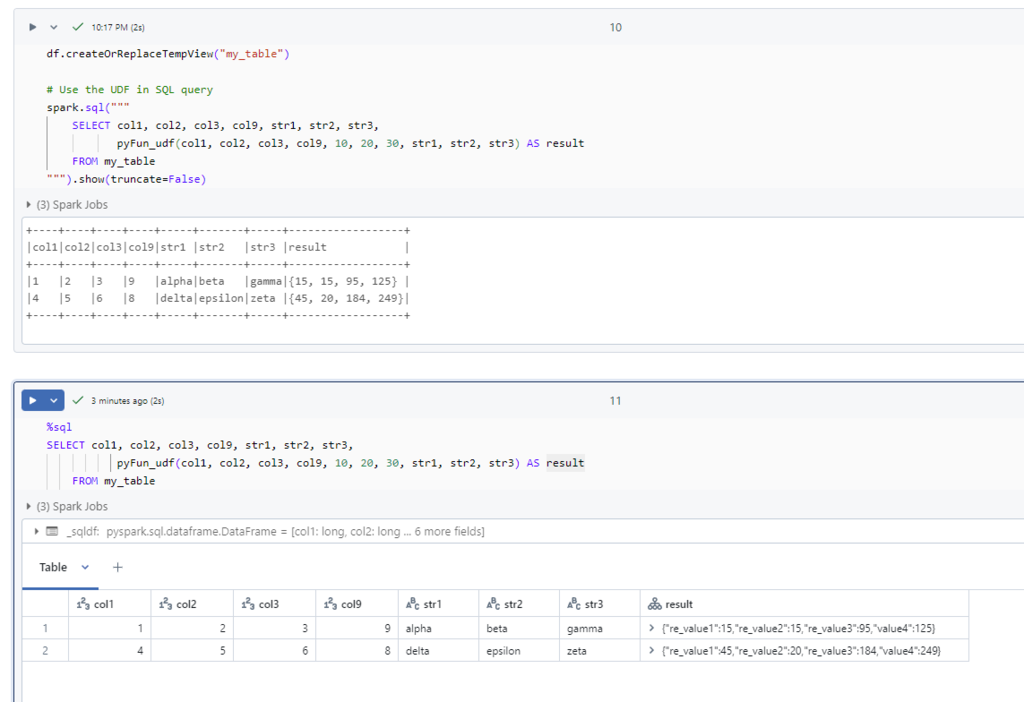
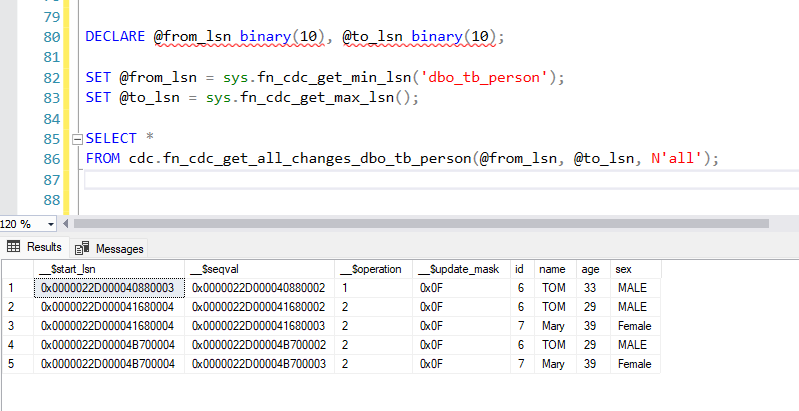
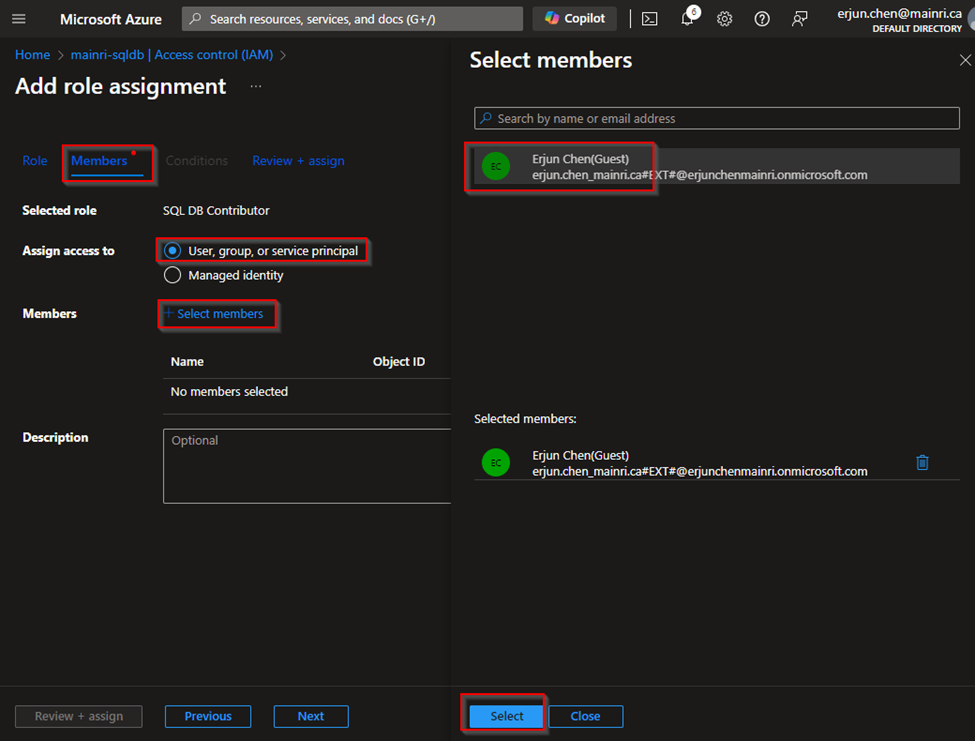
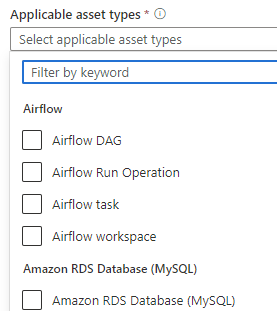
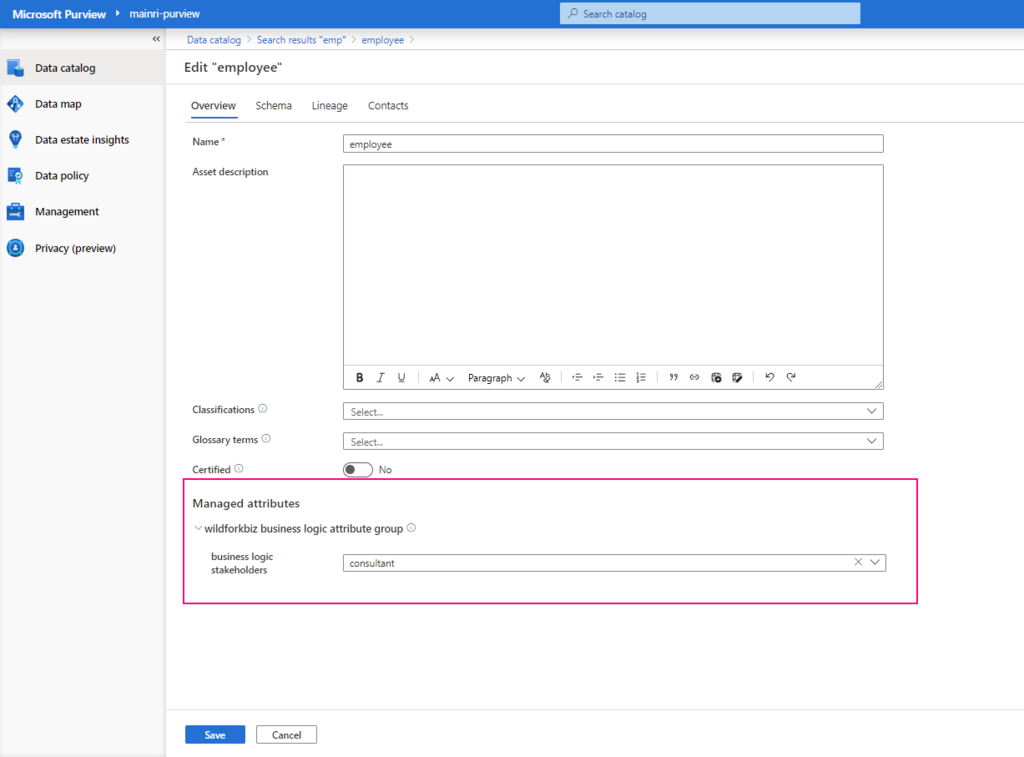
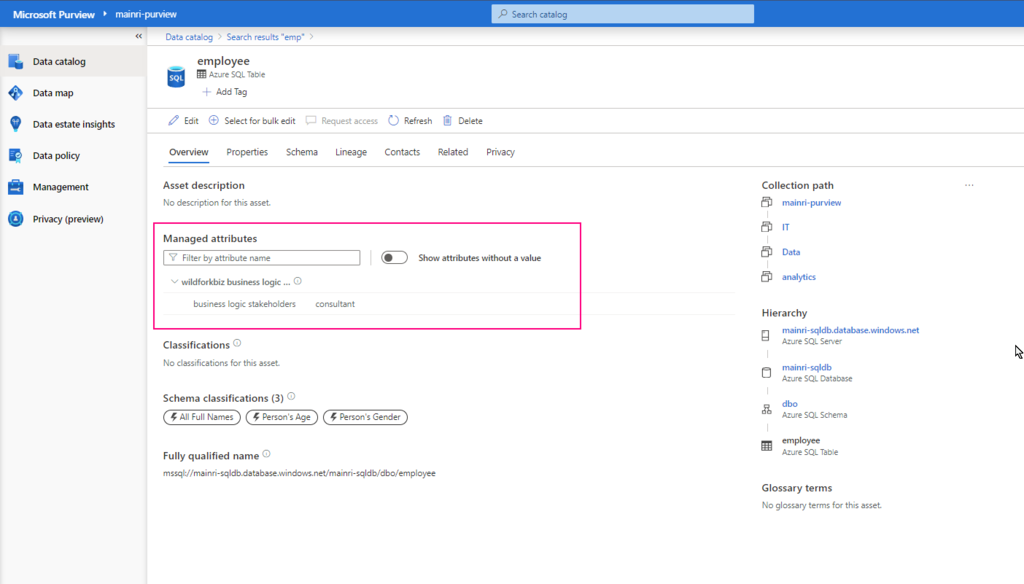
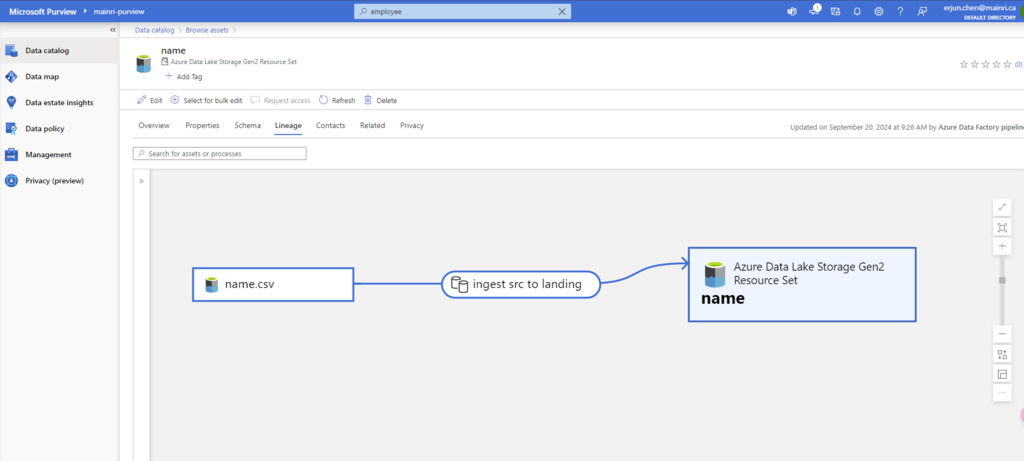
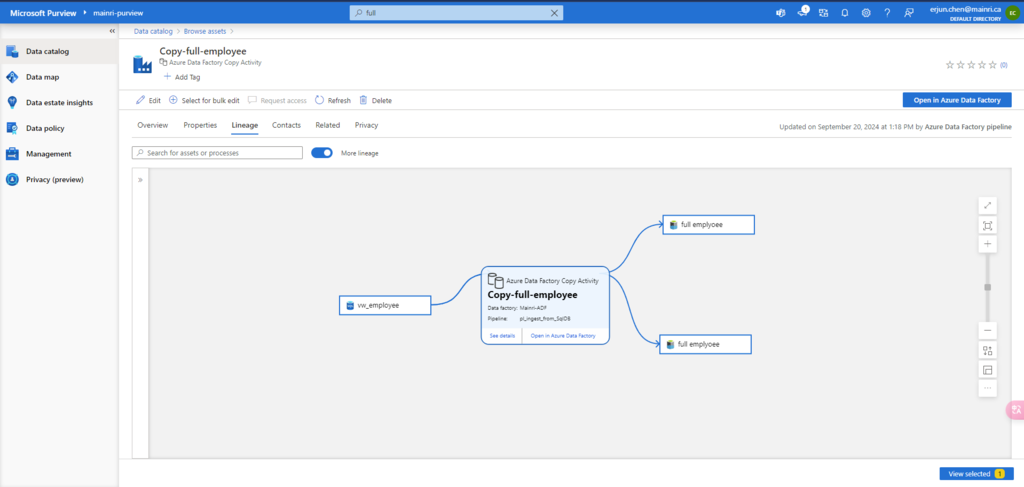
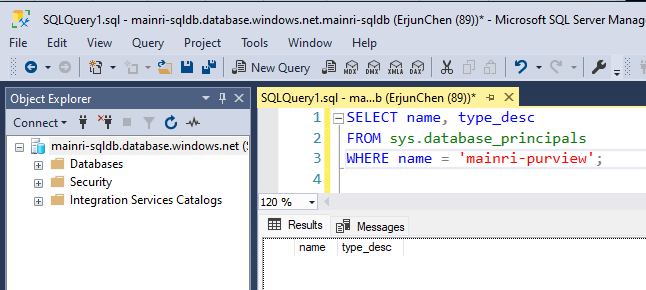
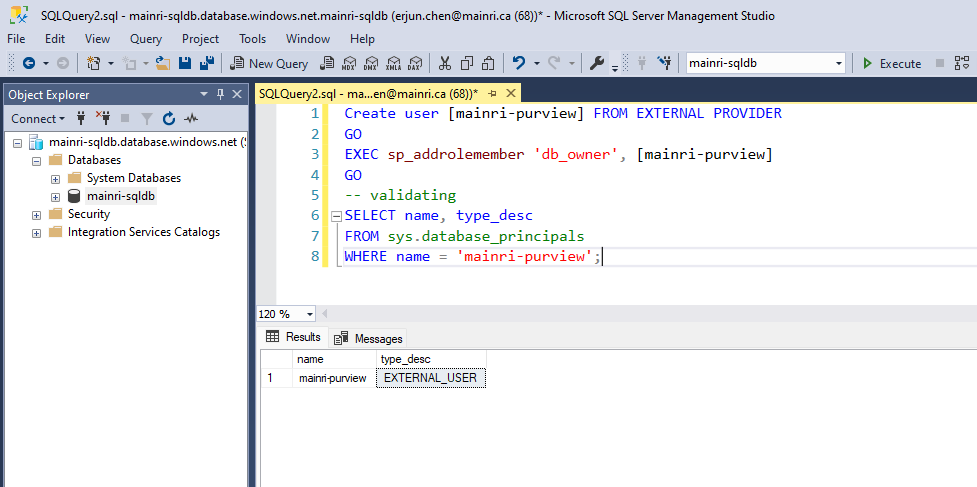
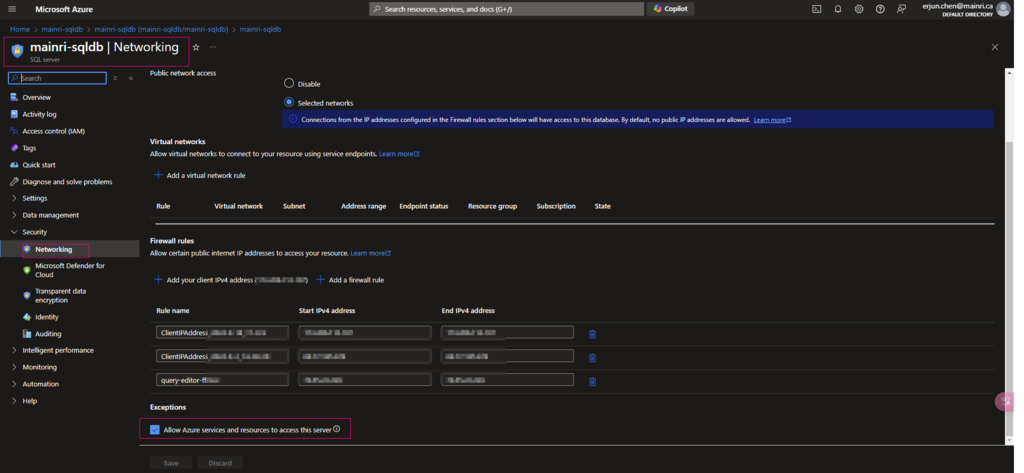
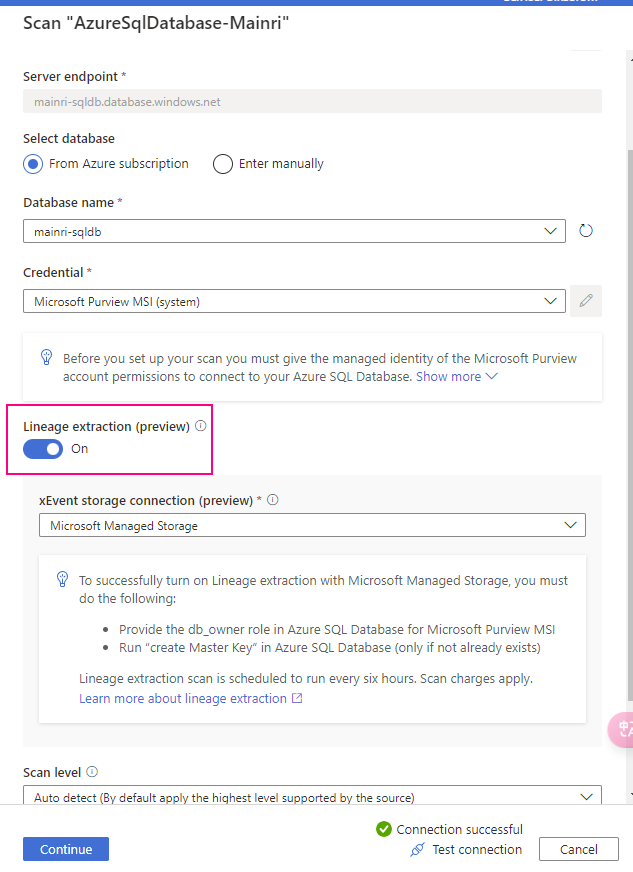
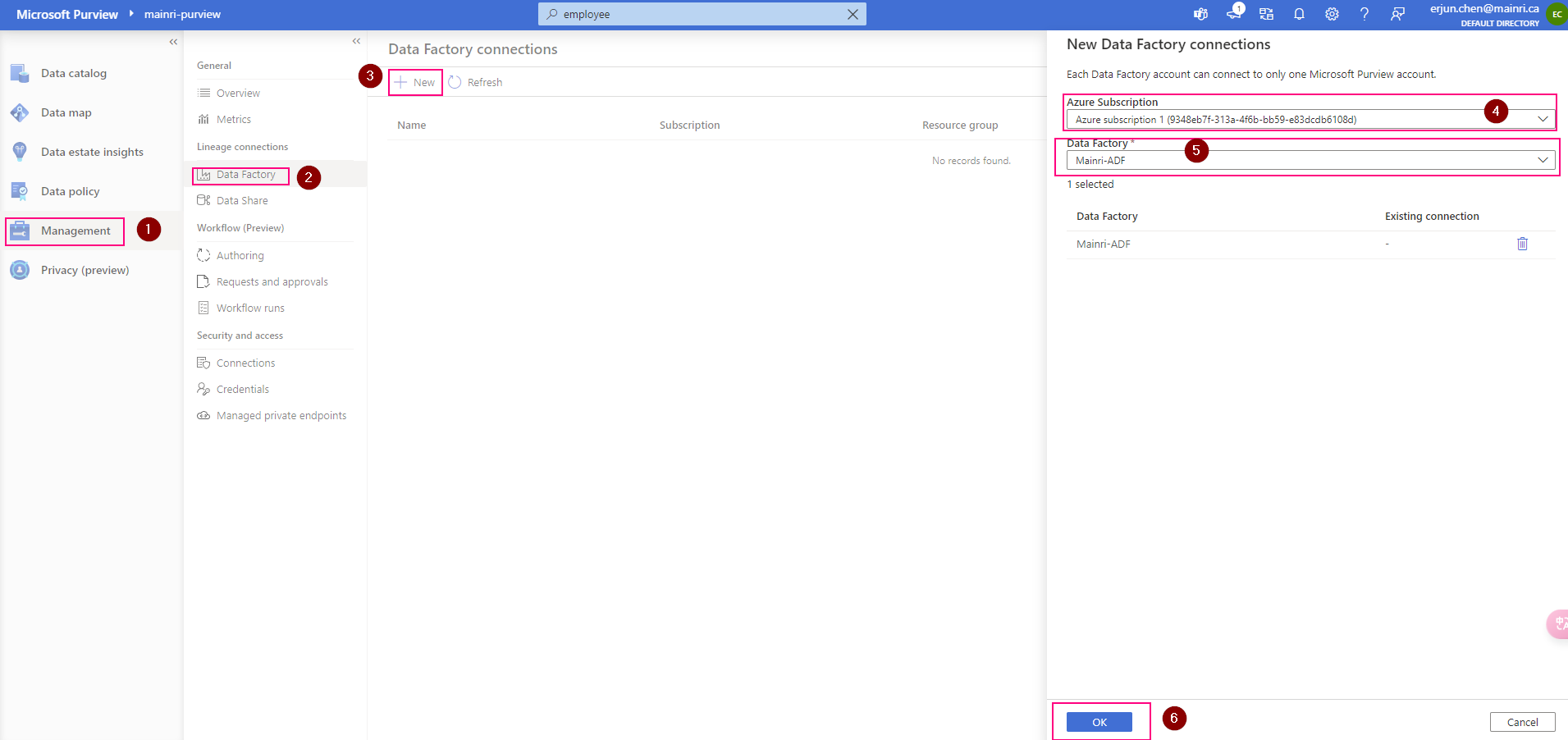
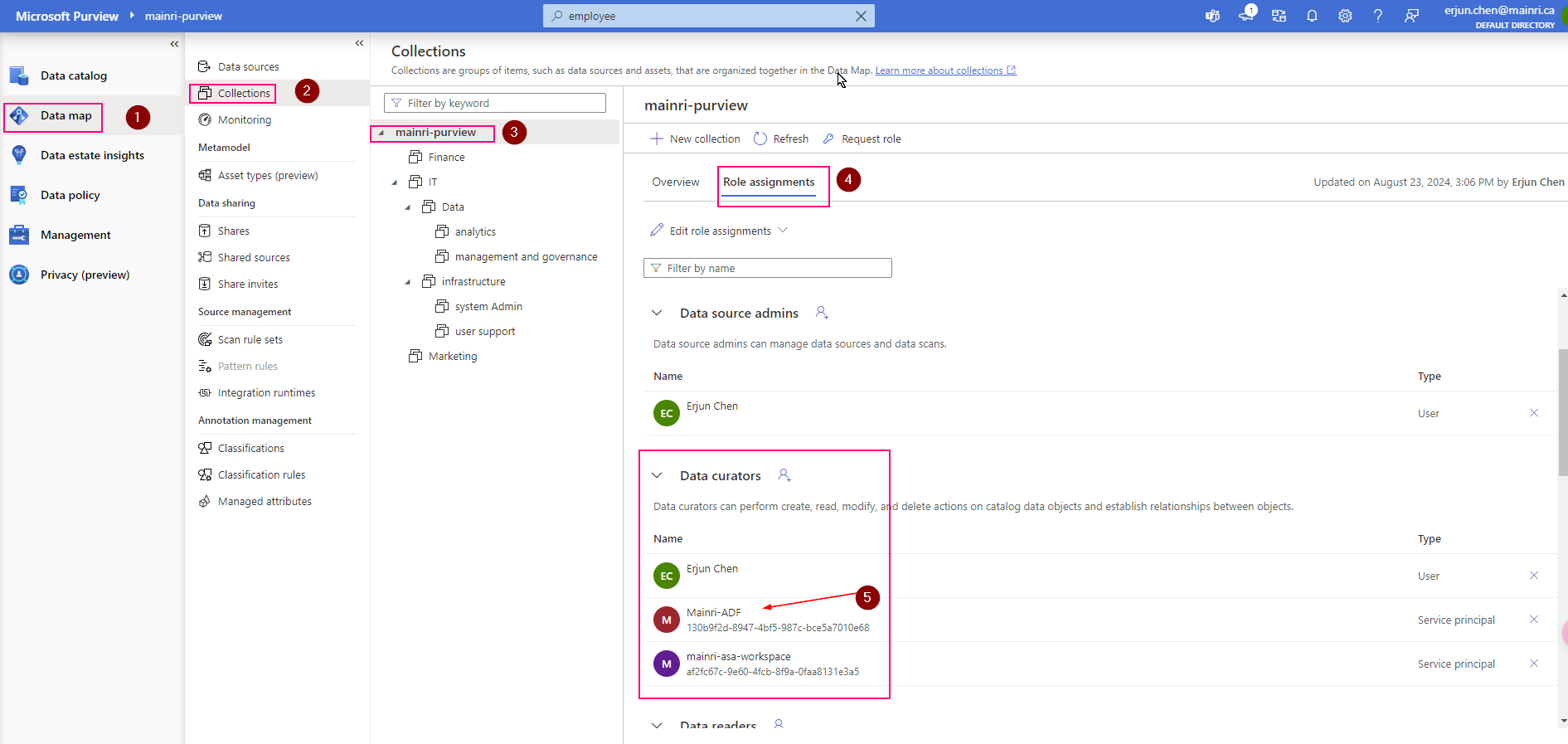
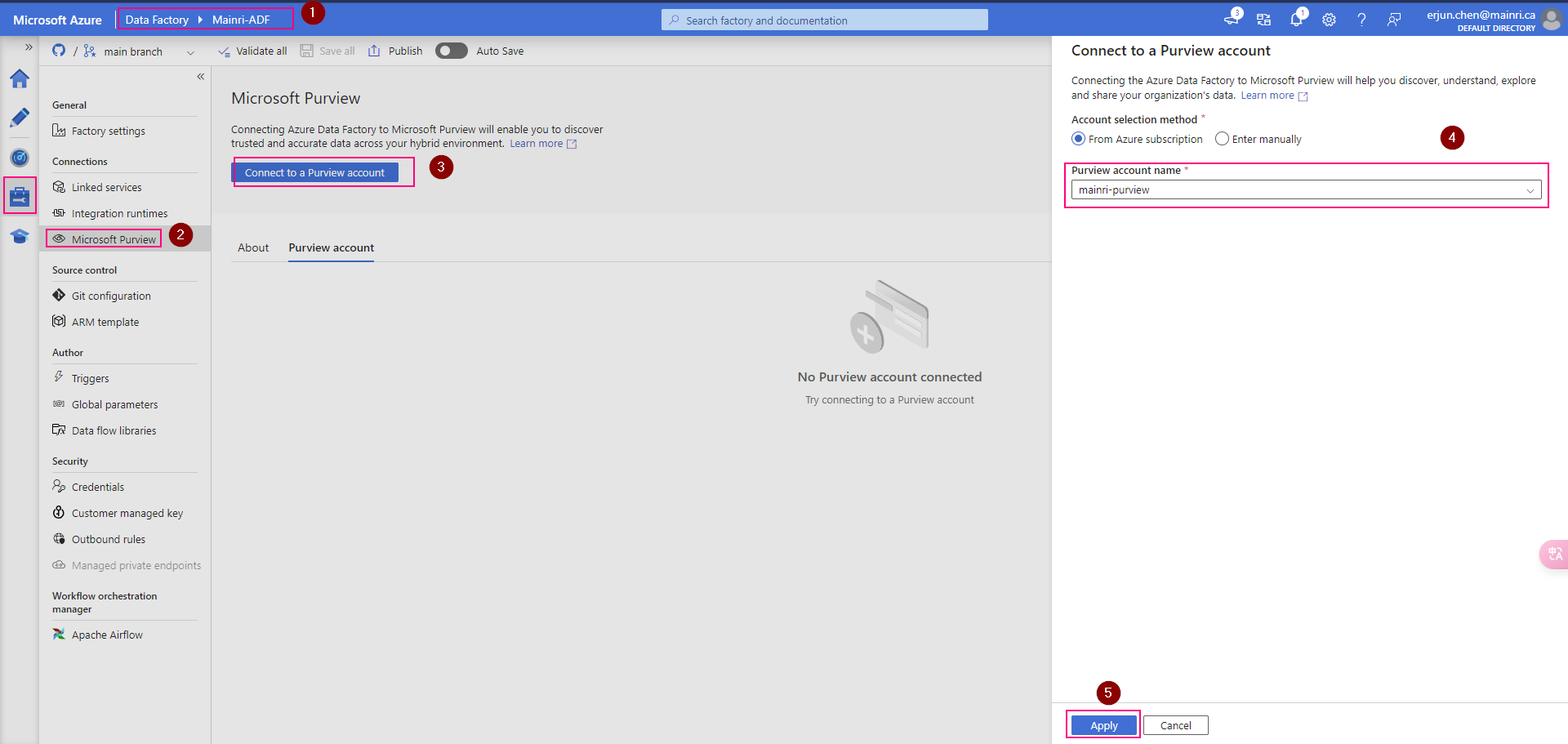
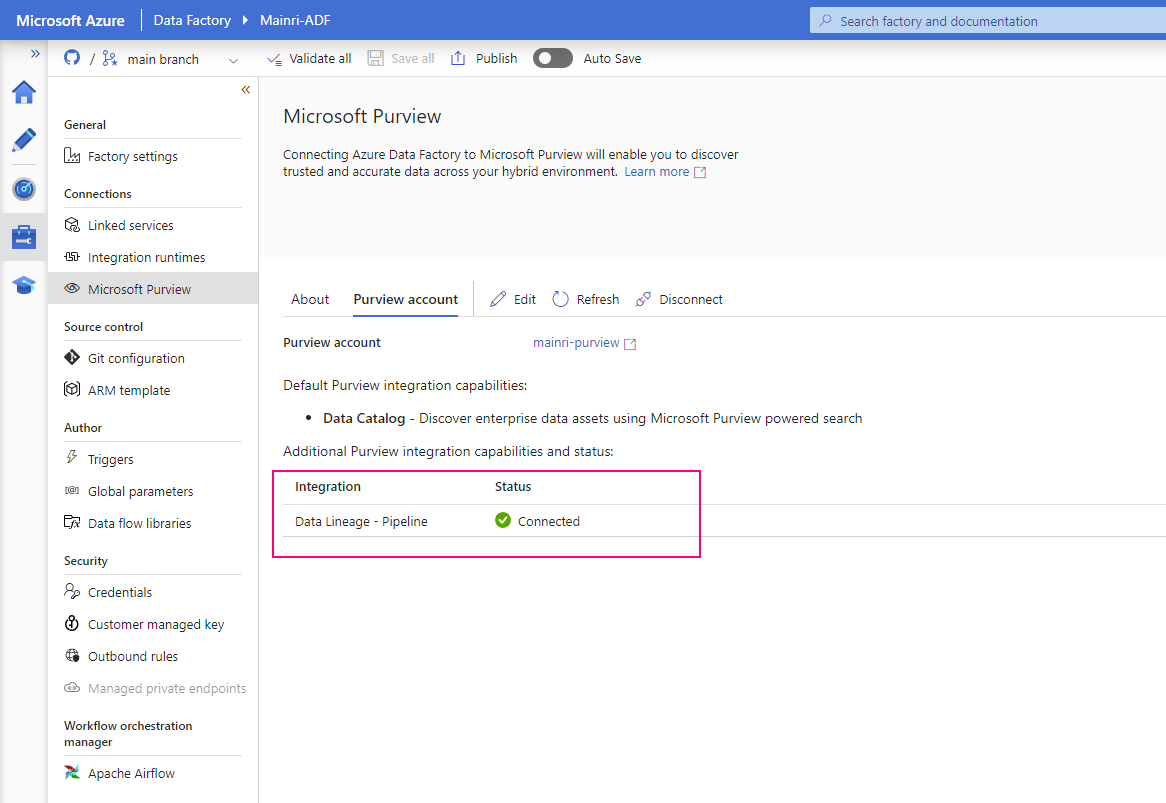
SQL Execution Order:
- FROM – Specifies the tables involved in the query.
- JOIN – Joins multiple tables based on conditions.
- WHERE – Filters records before aggregation.
- GROUP BY – Groups records based on specified columns.
- HAVING – Filters aggregated results.
- SELECT – Specifies the columns to return.
- DISTINCT – Removes duplicate rows.
- ORDER BY – Sorts the final result set.
- LIMIT / OFFSET – Limits the number of rows returned.
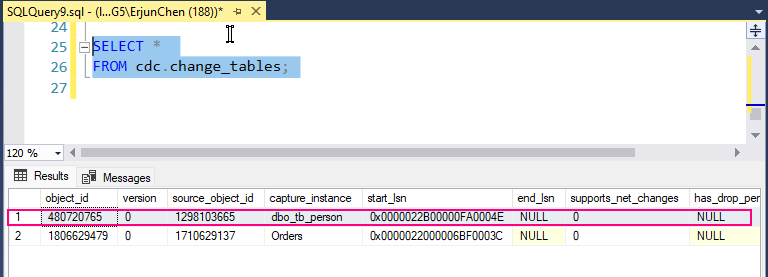
TSQL Commands Categorized
Categorized
- DDL – Data Definition Language
CREATE, DROP, ALTER, TRUNCATE, COMMENT, RENAME - DQL – Data Query Language
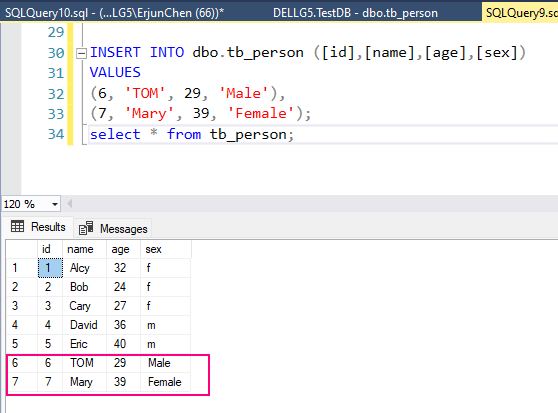
SELECT - DML – Data Manipulation Language
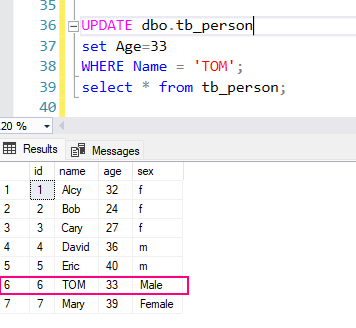
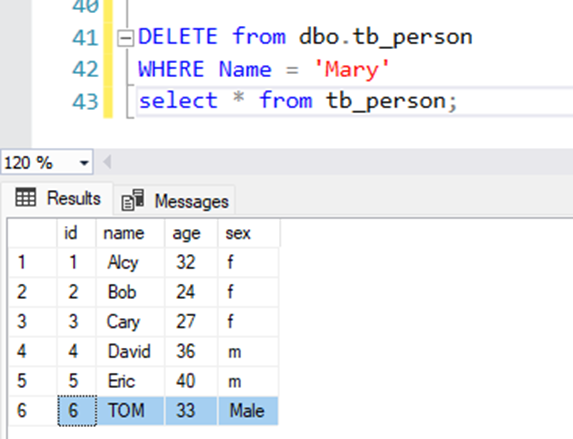
INSERT, UPDATE, DELETE, LOCK - DCL – Data Control Language
GRANT, REVOKE - TCL – Transaction Control Language
BEGIN TRANSACTION, COMMIT, SAVEPOINT, ROLLBACK, SET TRANSACTION, SET CONSTRAINT
DDL command
ALTER
Alter Table
Add Column
ALTER TABLE table_name
ADD column_name data_type [constraints];
ALTER TABLE Employees
ADD Age INT NOT NULL;
Drop Column
ALTER TABLE table_name
DROP COLUMN column_name;
ALTER TABLE Employees
DROP COLUMN Age;
Modify Column (Change Data Type or Nullability)
ALTER TABLE table_name
ALTER COLUMN column_name new_data_type [NULL | NOT NULL];
ALTER TABLE Employees
ALTER COLUMN Age BIGINT NULL;
Add Constraint:
ALTER TABLE table_name ADD CONSTRAINT constraint_name constraint_type (column_name);
ALTER TABLE Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (EmployeeID);
Drop Constraint:
ALTER TABLE table_name DROP CONSTRAINT constraint_name;
ALTER TABLE Employees DROP CONSTRAINT PK_Employees;
Alter Database
Change Database Settings
ALTER DATABASE database_name
SET option_name;
ALTER DATABASE TestDB
SET READ_ONLY;
Change Collation
ALTER DATABASE database_name
COLLATE collation_name;
ALTER DATABASE TestDB
COLLATE SQL_Latin1_General_CP1_CI_AS;
ALTER VIEW
Modify an Existing View
ALTER VIEW view_name
AS
SELECT columns
FROM table_name
WHERE condition;
ALTER VIEW EmployeeView
AS
SELECT EmployeeID, Name, Department
FROM Employees
WHERE IsActive = 1;
ALTER PROCEDURE
Modify an Existing Stored Procedure
ALTER PROCEDURE procedure_name
AS
BEGIN
-- Procedure logic
END;
ALTER PROCEDURE GetEmployeeDetails
@EmployeeID INT
AS
BEGIN
SELECT * FROM Employees WHERE EmployeeID = @EmployeeID;
END;
ALTER FUNCTION
ALTER FUNCTION function_name
RETURNS data_type
AS
BEGIN
-- Function logic
RETURN value;
END;
ALTER FUNCTION GetFullName
(@FirstName NVARCHAR(50), @LastName NVARCHAR(50))
RETURNS NVARCHAR(100)
AS
BEGIN
RETURN @FirstName + ' ' + @LastName;
END;
ALTER INDEX
Rebuild Index:
ALTER INDEX index_name
ON table_name
REBUILD;
Reorganize Index:
ALTER INDEX index_name
ON table_name
REORGANIZE;
Disable Index:
ALTER INDEX index_name
ON table_name
DISABLE;
ALTER SCHEMA
Move Object to a Different Schema
ALTER SCHEMA new_schema_name
TRANSFER current_schema_name.object_name;
ALTER SCHEMA Sales
TRANSFER dbo.Customers;
ALTER ROLE
Add Member:
ALTER ROLE role_name
ADD MEMBER user_name;
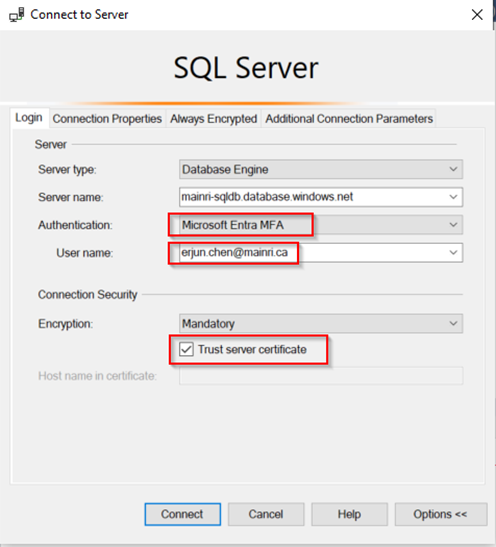
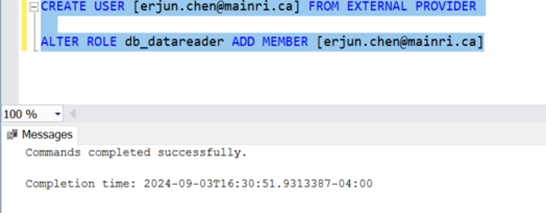
ALTER ROLE db_datareader
ADD MEMBER User1;
Drop Member:
ALTER ROLE role_name
DROP MEMBER user_name;CREATE
Create Table
# Create Parent Table
CREATE TABLE Departments (
DeptID INT IDENTITY(1, 1) PRIMARY KEY, -- IDENTITY column as the primary key
DeptName NVARCHAR(100) NOT NULL
);
# Create child table with FK
CREATE TABLE Employees (
EmpID INT IDENTITY(1, 1) PRIMARY KEY, -- IDENTITY column as the primary key
EmpName NVARCHAR(100) NOT NULL,
Position NVARCHAR(50),
DeptID INT NOT NULL, -- Foreign key column
CONSTRAINT FK_Employees_Departments FOREIGN KEY (DeptID) REFERENCES Departments(DeptID)
);DROP
Drop Database
Make sure no active connections are using the database.
To forcibly close connections, use:
ALTER DATABASE TestDB SET SINGLE_USER WITH ROLLBACK IMMEDIATE; DROP DATABASE TestDB;DROP DATABASE DatabaseName;
DROP DATABASE TestDB;Drop Schema
The DROP SCHEMA statement removes a schema, but it can only be dropped if no objects exist within it.
Before dropping a schema, make sure to drop or move all objects inside it
DROP TABLE SalesSchema.SalesTable;
DROP SCHEMA SalesSchema;
DROP SCHEMA SalesSchema;Drop Table
Dropping a table will also remove constraints, indexes, and triggers associated with the table.
DROP TABLE TableName;
DROP TABLE Employees;Drop Column
The DROP COLUMN statement removes a column from a table.
ALTER TABLE TableName DROP COLUMN ColumnName;
ALTER TABLE Employees DROP COLUMN Position;You cannot drop a column that is part of a PRIMARY KEY, FOREIGN KEY, or any other constraint unless you first drop the constraint.
Additional DROP Statements
Drop Index
Remove an index from a table.
DROP INDEX IndexName ON TableName;Drop Constraint
Remove a specific constraint (e.g., PRIMARY KEY, FOREIGN KEY).
ALTER TABLE TableName DROP CONSTRAINT ConstraintName;Order of Dependencies
When dropping related objects, always drop dependent objects first:
- Constraints (if applicable)
- Columns (if applicable)
- Tables
- Schemas
- Database
Example: Full Cleanup
-- Drop a column
ALTER TABLE Employees DROP COLUMN TempColumn;
-- Drop a table
DROP TABLE Employees;
-- Drop a schema
DROP SCHEMA HR;
-- Drop a database
ALTER DATABASE CompanyDB SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE CompanyDB;DQL command
CTE
A Common Table Expression (CTE) in SQL is a temporary result set that you can reference within a SELECT, INSERT, UPDATE, or DELETE statement. CTEs are particularly useful for simplifying complex queries, improving readability, and breaking down queries into manageable parts.
WITH cte_name (optional_column_list) AS (
-- Your query here
SELECT column1, column2
FROM table_name
WHERE condition
)
-- Main query using the CTE
SELECT *
FROM cte_name;Breaking Down Multi-Step Logic
WITH Step1 AS (
SELECT ProductID, SUM(Sales) AS TotalSales
FROM Sales
GROUP BY ProductID
),
Step2 AS (
SELECT ProductID, TotalSales
FROM Step1
WHERE TotalSales > 1000
)
SELECT *
FROM Step2;Intermediate Calculations
WITH AverageSales AS (
SELECT ProductID, AVG(Sales) AS AvgSales
FROM Sales
GROUP BY ProductID
)
SELECT ProductID, AvgSales
FROM AverageSales
WHERE AvgSales > 500;Recursive CTE
WITH RECURSIVE EmployeeHierarchy AS (
SELECT EmployeeID, ManagerID, EmployeeName
FROM Employees
WHERE ManagerID IS NULL -- Starting point (CEO)
UNION ALL
SELECT e.EmployeeID, e.ManagerID, e.EmployeeName
FROM Employees e
JOIN EmployeeHierarchy eh ON e.ManagerID = eh.EmployeeID
)
SELECT *
FROM EmployeeHierarchy;
Why Use CTEs?
- Improve Readability:
- CTEs allow you to break down complex queries into smaller, more understandable parts.
- They make the query logic clearer by separating it into named, logical blocks.
- Reusability:
- You can reference a CTE multiple times within the same query, avoiding the need to repeat subqueries.
- Recursive Queries:
- CTEs support recursion, which is useful for hierarchical or tree-structured data (e.g., organizational charts, folder structures).
- Simplify Debugging:
- Since CTEs are modular, you can test and debug individual parts of the query independently.
- Alternative to Subqueries:
- CTEs are often easier to read and maintain compared to nested subqueries.
Conditional Statements
IF…ELSE …
IF EXISTS (SELECT 1 FROM table_name WHERE column1 = 'value')
BEGIN
PRINT 'Record exists';
END
ELSE
BEGIN
PRINT 'Record does not exist';
END;
IF EXISTS …. or IF NOT EXISTS …
-- Check if rows exist in the table
IF EXISTS (SELECT * FROM Tb)
BEGIN
-- Code block to execute if rows exist
PRINT 'Rows exist in the table';
END;
-- Check if rows do not exist in the table
IF NOT EXISTS (SELECT * FROM Tb)
BEGIN
-- Code block to execute if no rows exist
PRINT 'No rows exist in the table';
END;
CASE
SELECT column1,
CASE
WHEN column2 = 'value1' THEN 'Result1'
WHEN column2 = 'value2' THEN 'Result2'
ELSE 'Other'
END AS result
FROM table_name;
Please do not hesitate to contact me if you have any questions at William . chen @ mainri.ca
(remove all space from the email account 😊)