
Azure Databricks is a managed platform for running Apache Spark jobs. In this post, I’ll go through some key Databricks terms to give you an overview of the different points you’ll use when running Databricks jobs (sorted by alphabet):
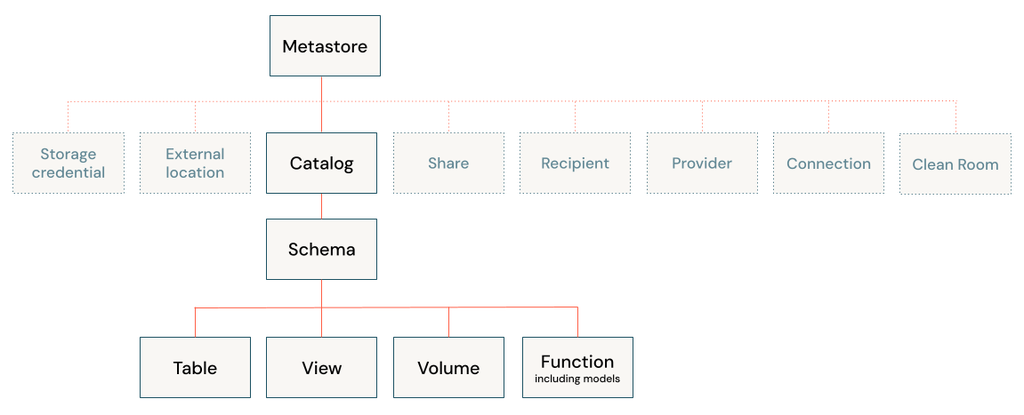
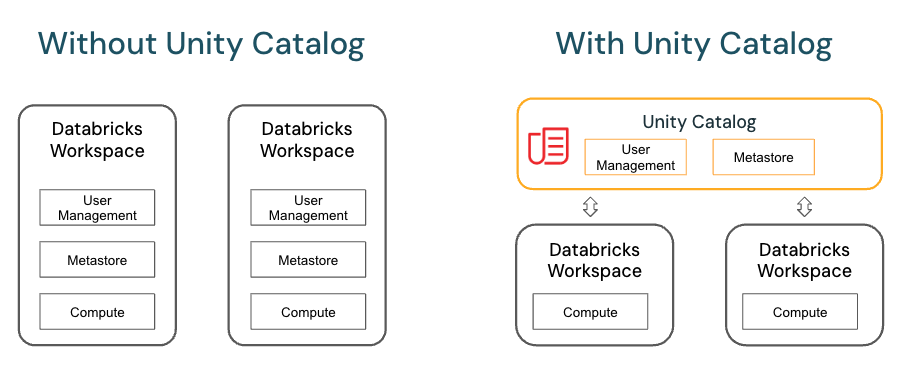
Catalog (Unity Catalog)
the Unity Catalog is a feature that provides centralized governance for data, allowing you to manage access to data across different Databricks workspaces and cloud environments. It helps define permissions, organize tables, and manage metadata, supporting multi-cloud and multi-workspace environments. Key benefits include:
- Support for multi-cloud data governance.
- Centralized access control and auditing.
- Data lineage tracking.
Delta table
A Delta table is a data management solution provided by Delta Lake, an open-source storage layer that brings ACID transactions to big data workloads. A Delta table stores data as a directory of files on cloud object storage and registers table metadata to the metastore within a catalog and schema. By default, all tables created in Databricks are Delta tables.
External tables
External tables are tables whose data lifecycle, file layout, and storage location are not managed by Unity Catalog. Multiple data formats are supported for external tables.
CREATE EXTERNAL TABLE my_external_table (
id INT,
name STRING,
age INT
)
LOCATION 'wasbs://[container]@[account].blob.core.windows.net/data/';
External Data Source
A connection to a data store that isn’t natively in Databricks but can be queried through a connection.
External Data Sources are typically external databases or data services (e.g., Azure SQL Database, Azure Synapse Analytics, Amazon RDS, or other relational or NoSQL databases). These sources are accessed via connectors (JDBC, ODBC, etc.) within Databricks.
jdbcUrl = "jdbc:sqlserver://[server].database.windows.net:1433;database=[database]"
connectionProperties = {
"user" : "username",
"password" : "password",
"driver" : "com.microsoft.sqlserver.jdbc.SQLServerDriver"
}
df = spark.read.jdbc(jdbcUrl, "[table]", connectionProperties)
Hive Metastore
The Hive Metastore is the metadata repository for the data in Databricks, storing information about tables and databases. It’s used by the Spark SQL engine to manage metadata for the tables and to store information like schemas, table locations, and partitions. In Azure Databricks:
- Schemas: Column names, types, and table structure.
- Table locations: The path to where the actual data resides (in HDFS, Azure Data Lake, S3, etc.).
- Partitions: If the table is partitioned, the metadata helps optimize query performance.
By default, each Databricks workspace has its own managed Hive metastore.
You can also connect to an external Hive metastore that is shared across multiple Databricks workspaces or use Azure-managed services like Azure SQL Database for Hive metadata storage.
Managed tables
Managed tables are the preferred way to create tables in Unity Catalog. Unity Catalog fully manages their lifecycle, file layout, and storage. Unity Catalog also optimizes their performance automatically. Managed tables always use the Delta table format.
Managed tables reside in a managed storage location that you reserve for Unity Catalog. Because of this storage requirement, you must use CLONE or CREATE TABLE AS SELECT (CTAS) if you want to copy existing Hive tables to Unity Catalog as managed tables.
Mounting Data
Mounting external storage into Databricks as if it’s part of the Databricks File System (DBFS)
dbutils.fs.mount(
source="wasbs://[container]@[account].blob.core.windows.net/",
mount_point="/mnt/mydata",
extra_configs={"fs.azure.account.key.[account].blob.core.windows.net": "[account_key]"}
)
Workflows
In Databricks, Workflows are a way to orchestrate data pipelines, machine learning tasks, and other computational processes. Workflows allow you to automate the execution of notebooks, Python scripts, JAR files, or any other job task within Databricks and run them on a schedule, trigger, or as part of a complex pipeline.
Key Components of Workflows in Databricks:
Jobs: Workflows in Databricks are typically managed through jobs. A job is a scheduled or triggered run of a notebook, script, or other tasks in Databricks. Jobs can consist of a single task or multiple tasks linked together.
Task: Each task in a job represents an individual unit of work. You can have multiple tasks in a job, which can be executed sequentially or in parallel.
Triggers: Workflows can be triggered manually, based on a schedule (e.g., hourly, daily), or triggered by an external event (such as a webhook).
Cluster: When running a job in a workflow, you need to specify a Databricks cluster (either an existing cluster or one that is started just for the job). Workflows can also specify job clusters, which are clusters that are spun up and terminated automatically for the specific job.
Types of Workflows
- Single-task Jobs: These jobs consist of just one task, like running a Databricks notebook or a Python/Scala/SQL script. You can schedule these jobs to run at specific intervals or trigger them manually.
- Multi-task Workflows: These workflows are more complex and allow for creating pipelines of interdependent tasks that can be run in sequence or in parallel. Each task can have dependencies on the completion of previous tasks, allowing you to build complex pipelines that branch based on results.Example: A data pipeline might consist of three tasks:
- Task 1: Ingest data from a data lake into a Delta table.
- Task 2: Perform transformations on the ingested data.
- Task 3: Run a machine learning model on the transformed data.
- Parameterized Workflows: You can pass parameters to a job when scheduling it, allowing for more dynamic behavior. This is useful when you want to run the same task with different inputs (e.g., processing data for different dates).
Creating Workflows in Databricks
Workflows can be created through the Jobs UI in Databricks or programmatically using the Databricks REST API.
Example of Creating a Simple Workflow:
- Navigate to the Jobs Tab:
- In Databricks, go to the Jobs tab in the workspace.
- Create a New Job:
- Click Create Job.
- Specify the name of the job.
- Define a Task:
- Choose a task type (Notebook, JAR, Python script, etc.).
- Select the cluster to run the job on (or specify a job cluster).
- Add parameters or libraries if required.
- Schedule or Trigger the Job:
- Set a schedule (e.g., run every day at 9 AM) or choose manual triggering.
- You can also configure alerts or notifications (e.g., send an email if the job fails).
Multi-task Workflow Example:
- Add Multiple Tasks:
- After creating a job, you can add more tasks by clicking Add Task.
- For each task, you can specify dependencies (e.g., Task 2 should run only after Task 1 succeeds).
- Manage Dependencies:
- You can configure tasks to run in sequence or in parallel.
- Define whether a task should run on success, failure, or based on a custom condition.
Key Features of Databricks Workflows:
- Orchestration: Allows for complex job orchestration, including dependencies between tasks, retries, and conditional logic.
- Job Scheduling: You can schedule jobs to run at regular intervals (e.g., daily, weekly) using cron expressions or Databricks’ simple scheduler.
- Parameterized Runs: Pass parameters to notebooks, scripts, or other tasks in the workflow, allowing dynamic control of jobs.
- Cluster Management: Workflows automatically handle cluster management, starting clusters when needed and shutting them down after the job completes.
- Notifications: Workflows allow setting up notifications on job completion, failure, or other conditions. These notifications can be sent via email, Slack, or other integrations.
- Retries: If a job or task fails, you can configure it to automatically retry a specified number of times before being marked as failed.
- Versioning: Workflows can be versioned, so you can track changes and run jobs based on different versions of a notebook or script.
Common Use Cases for Databricks Workflows:
- ETL Pipelines: Automating the extraction, transformation, and loading (ETL) of data from source systems to a data lake or data warehouse.
- Machine Learning Pipelines: Orchestrating the steps involved in data preprocessing, model training, evaluation, and deployment.
- Batch Processing: Scheduling large-scale data processing tasks to run on a regular basis.
- Data Ingestion: Automating the ingestion of raw data into Delta Lake or other storage solutions.
- Alerts and Monitoring: Running scheduled jobs that trigger alerts based on conditions in the data (e.g., anomaly detection).