
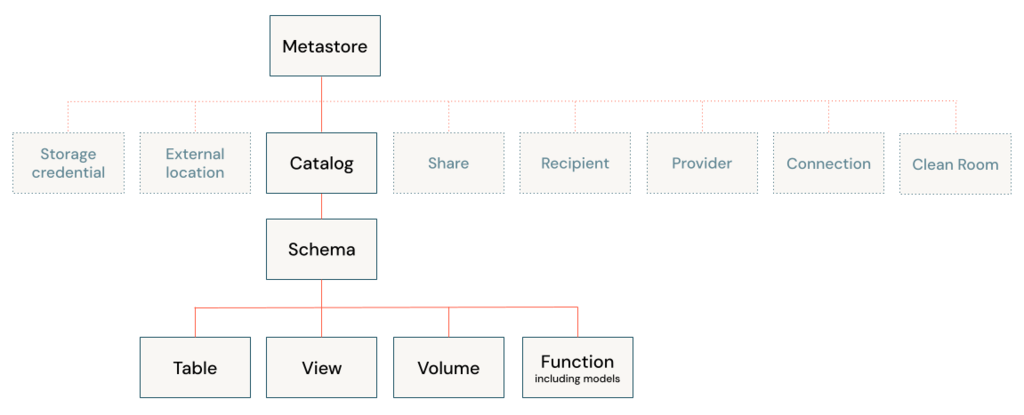
A catalog is the primary unit of data organization in the Azure Databricks Unity Catalog data governance model. it is the first layer in Unity Catalog’s three-level namespace (catalog.schema.table-etc). They contain schemas, which in turn can contain tables, views, volumes, models, and functions. Catalogs are registered in a Unity Catalog metastore in your Azure Databricks account.
Catalogs
Organize my data into catalogs
Each catalog should represent a logical unit of data isolation and a logical category of data access, allowing an efficient hierarchy of grants to flow down to schemas and the data objects that they contain.
Catalogs therefore often mirror organizational units or software development lifecycle scopes. You might choose, for example, to have a catalog for production data and a catalog for development data, or a catalog for non-customer data and one for sensitive customer data.
Data isolation using catalogs
Each catalog typically has its own managed storage location to store managed tables and volumes, providing physical data isolation at the catalog level.
Catalog-level privileges
grants on any Unity Catalog object are inherited by children of that object, owning a catalog
Catalog types
- Standard catalog: the typical catalog, used as the primary unit to organize your data objects in Unity Catalog.
- Foreign catalog: a Unity Catalog object that is used only in Lakehouse Federation scenarios.
Default catalog
If your workspace was enabled for Unity Catalog automatically, the pre-provisioned workspace catalog is specified as the default catalog. A workspace admin can change the default catalog as needed.
Workspace-catalog binding
If you use workspaces to isolate user data access, you might want to use workspace-catalog bindings. Workspace-catalog bindings enable you to limit catalog access by workspace boundaries.
Create catalogs
Requirements: be an Azure Databricks metastore admin or have the CREATE CATALOG privilege on the metastore
To create a catalog, you can use Catalog Explorer, a SQL command, the REST API, the Databricks CLI, or Terraform. When you create a catalog, two schemas (databases) are automatically created: default and information_schema.
Catalog Explorer
- Log in to a workspace that is linked to the metastore.
- Click Catalog.
- Click the Create Catalog button.
- On the Create a new catalog dialog, enter a Catalog name and select the catalog Type that you want to create:
Standard catalog: a securable object that organizes data and AI assets that are managed by Unity Catalog. For all use cases except Lakehouse Federation and catalogs created from Delta Sharing shares. - Foreign catalog: a securable object that mirrors a database in an external data system using Lakehouse Federation.
- Shared catalog: a securable object that organizes data and other assets that are shared with you as a Delta Sharing share. Creating a catalog from a share makes those assets available for users in your workspace to read.
SQL
standard catalog
CREATE CATALOG [ IF NOT EXISTS ] <catalog-name>
[ MANAGED LOCATION '<location-path>' ]
[ COMMENT <comment> ];
- <catalog-name>: A name for the catalog.
- <location-path>: Optional but strongly recommended.
e.g. <location-path>: ‘abfss://my-container-name@storage-account-name.dfs.core.windows.net/finance’ or ‘abfss://my-container-name@storage-account-name.dfs.core.windows.net/finance/product’
shared catalog
CREATE CATALOG [IF NOT EXISTS] <catalog-name>
USING SHARE <provider-name>.<share-name>;
[ COMMENT <comment> ];
foreign catalog
CREATE FOREIGN CATALOG [IF NOT EXISTS] <catalog-name> USING CONNECTION <connection-name>
OPTIONS [(database '<database-name>') | (catalog '<external-catalog-name>')];
- <catalog-name>: Name for the catalog in Azure Databricks.
- <connection-name>: The connection object that specifies the data source, path, and access credentials.
- <database-name>: Name of the database you want to mirror as a catalog in Azure Databricks. Not required for MySQL, which uses a two-layer namespace. For Databricks-to-Databricks Lakehouse Federation, use catalog ‘<external-catalog-name>’ instead.
- <external-catalog-name>: Databricks-to-Databricks only: Name of the catalog in the external Databricks workspace that you are mirroring.
Schemas
Schema is a child of a catalog and can contain tables, views, volumes, models, and functions. Schemas provide more granular categories of data organization than catalogs.
Precondition
- Have a Unity Catalog metastore linked to the workspace where you perform the schema creation
- Have the USE CATALOG and CREATE SCHEMA data permissions on the schema’s parent catalog
- To specify an optional managed storage location for the tables and volumes in the schema, an external location must be defined in Unity Catalog, and you must have the CREATE MANAGED STORAGE privilege on the external location.
Create a schema
To create a schema in Unity Catalog, you can use Catalog Explorer or SQL commands.
To create a schema in Hive metastore, you must use SQL commands.
Catalog Explorer
- Log in to a workspace that is linked to the Unity Catalog metastore.
- Click Catalog.
- In the Catalog pane on the left, click the catalog you want to create the schema in.
- In the detail pane, click Create schema.
- Give the schema a name and add any comment that would help users understand the purpose of the schema.
- (Optional) Specify a managed storage location. Requires the CREATE MANAGED STORAGE privilege on the target external location. See Specify a managed storage location in Unity Catalog and Managed locations for schemas.
- Click Create.
- Grant privileges on the schema. See Manage privileges in Unity Catalog.
- Click Save.
SQL
CREATE { DATABASE | SCHEMA } [ IF NOT EXISTS ] <catalog-name>.<schema-name>
[ MANAGED LOCATION '<location-path>' | LOCATION '<location-path>']
[ COMMENT <comment> ]
[ WITH DBPROPERTIES ( <property-key = property_value [ , ... ]> ) ];
Please do not hesitate to contact me if you have any questions at William . chen @ mainri.ca
(remove all space from the email account 😊)
Appendix: