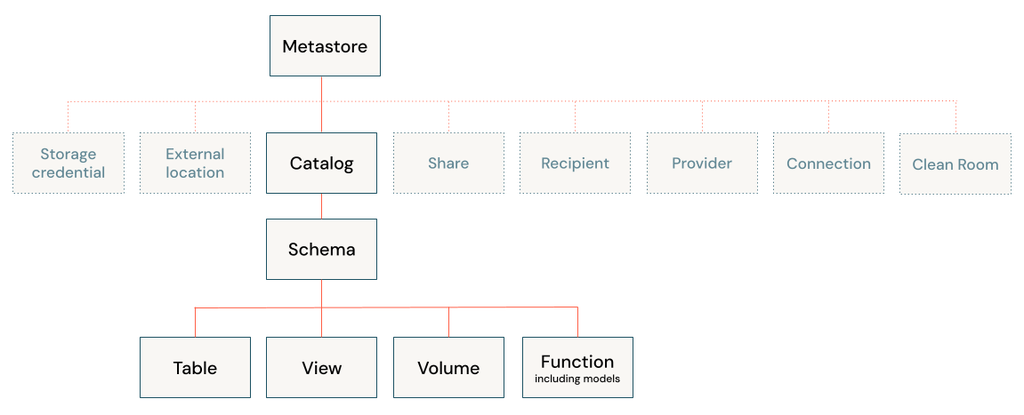
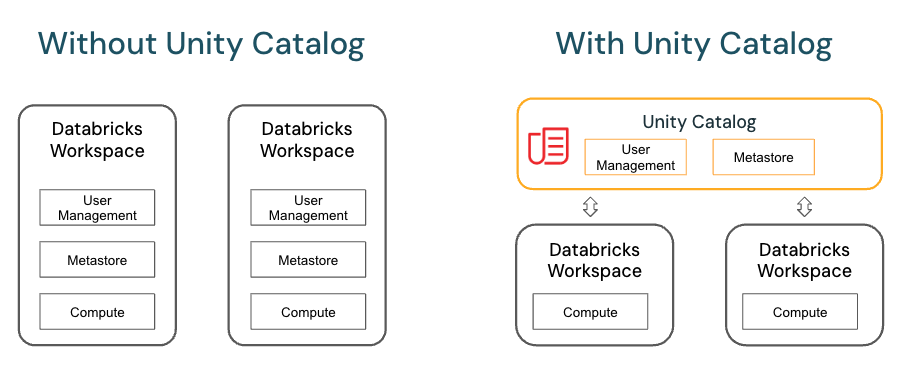
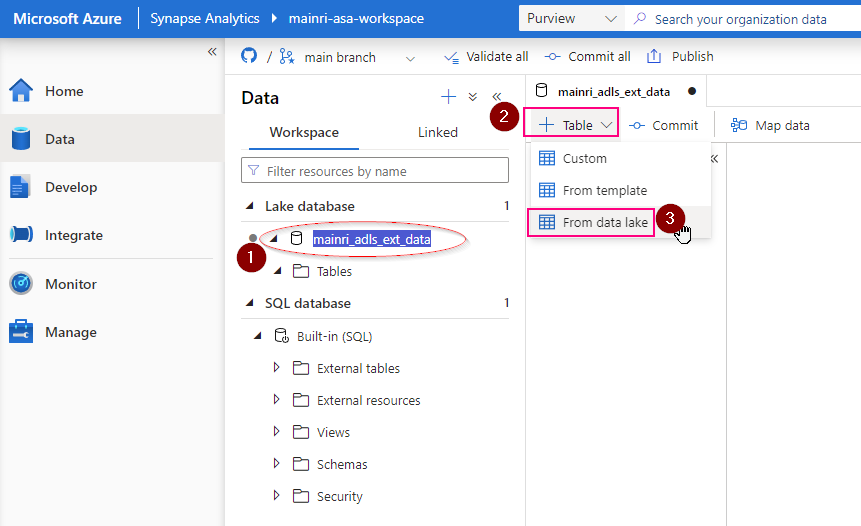
In Azure Databricks Unity Catalog, you can create different types of tables depending on your storage and management needs. The main table types are including Managed Tables, External Tables, Delta Tables, Foreign Tables, Streaming Tables, Live Tables (deprecated), Feature Tables, and Hive Tables (legacy). Each table type is explained in detail, and a side-by-side comparison is provided for clarity.
Side-by-Side Comparison Table
| Feature | Managed Tables | External Tables | Delta Tables | Foreign Tables | Streaming Tables | Delta Live Tables (DLT) | Feature Tables | Hive Tables (Legacy) |
|---|---|---|---|---|---|---|---|---|
| Storage | Databricks-managed | External storage | Managed/External | External database | Databricks-managed | Databricks-managed | Managed/External | Managed/External |
| Location | Internal Delta Lake | Specified external path | Internal/External Delta Lake | External metastore (Snowflake, BigQuery) | Internal Delta Lake | Internal Delta Lake | Internal/External Delta Lake | Internal/External storage |
| Ownership | Databricks | User | Databricks/User | External provider | Databricks | Databricks | Databricks/User | Databricks (Legacy Hive Metastore) |
| Deletion Impact | Deletes data & metadata | Deletes only metadata | Depends (Managed: Deletes, External: Keeps data) | Deletes only metadata reference | Deletes data & metadata | Deletes data & metadata | Deletes metadata (but not feature versions) | Similar to Managed/External |
| Format | Delta Lake | Parquet, CSV, JSON, Delta | Delta Lake | Snowflake, BigQuery, Redshift, etc. | Delta Lake | Delta Lake | Delta Lake | Parquet, ORC, Avro, CSV |
| Use Case | Full lifecycle management | Sharing with external tools | Advanced data versioning & ACID compliance | Querying external DBs | Continuous data updates | ETL Pipelines | ML feature storage | Legacy storage (pre-Unity Catalog) |
Table type and describes
1. Managed Tables
Managed tables are tables where both the metadata and the data are managed by Unity Catalog. When you create a managed table, the data is stored in the default storage location associated with the catalog or schema.
Data Storage and location:
Unity Catalog manages both the metadata and the underlying data in a Databricks-managed location
The data is stored in a Unity Catalog-managed storage location. Typically in an internal Delta Lake storage, e.g., DBFS or Azure Data Lake Storage
Use Case:
Ideal for Databricks-centric workflows where you want Databricks to handle storage and metadata.
Pros & Cons:
Pros: Easy to manage, no need to worry about storage locations.
Cons: Data is tied to Databricks, making it harder to share externally.
Example:
CREATE TABLE managed_table (
id INT,
name STRING
);
INSERT INTO managed_table VALUES (1, 'Alice');
SELECT * FROM managed_table;2. External Tables
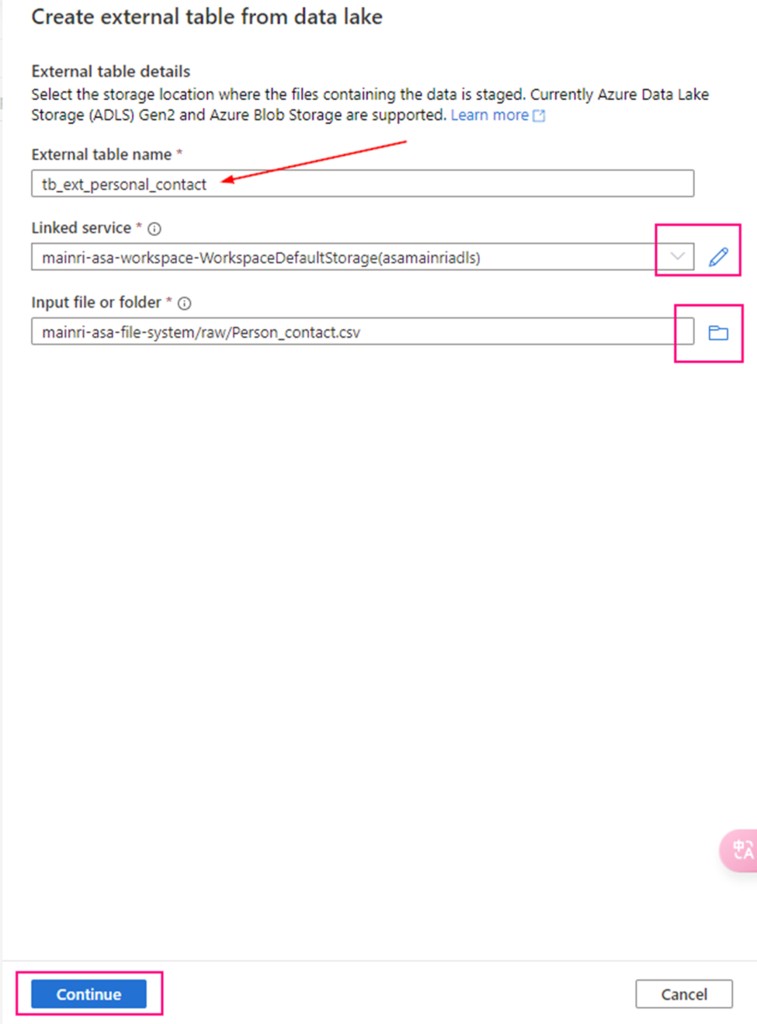
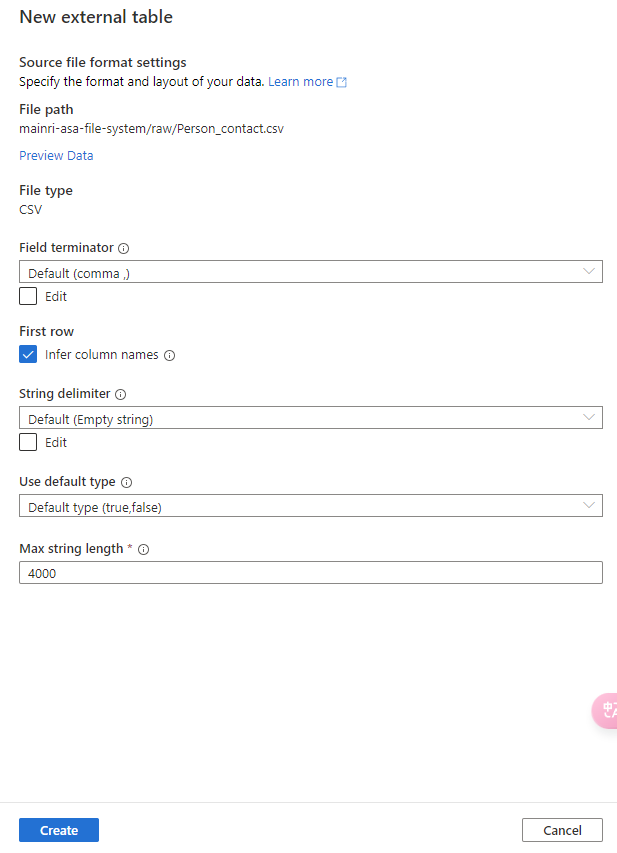
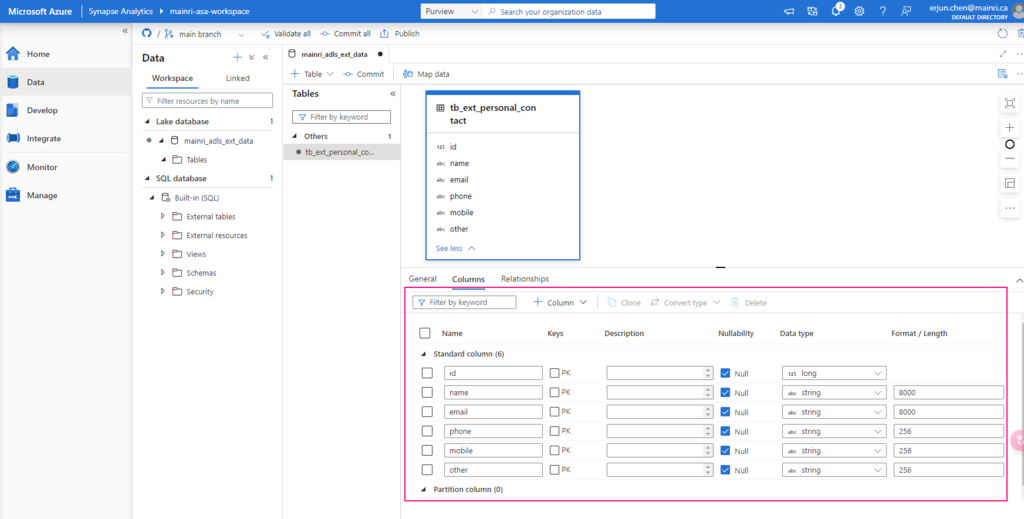
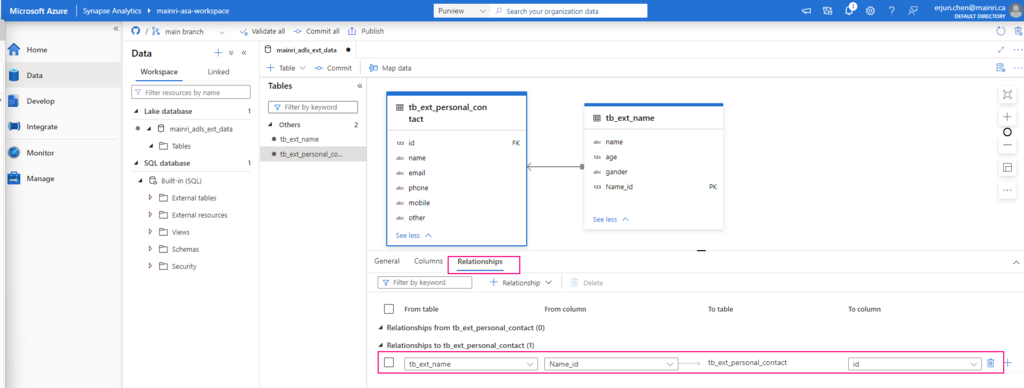
External tables store metadata in Unity Catalog but keep data in an external storage location (e.g., Azure Blob Storage, ADLS, S3).
Data storage and Location:
The metadata is managed by Unity Catalog, but the actual data remains in external storage (like Azure Data Lake Storage Gen2 or an S3 bucket).
You must specify an explicit storage location, e.g., Azure Blob Storage, ADLS, S3).
Use Case:
Ideal for cross-platform data sharing or when data is managed outside Databricks.
Pros and Cons
Pros: Data is decoupled from Databricks, making it easier to share.
Cons: Requires manual management of external storage and permissions.
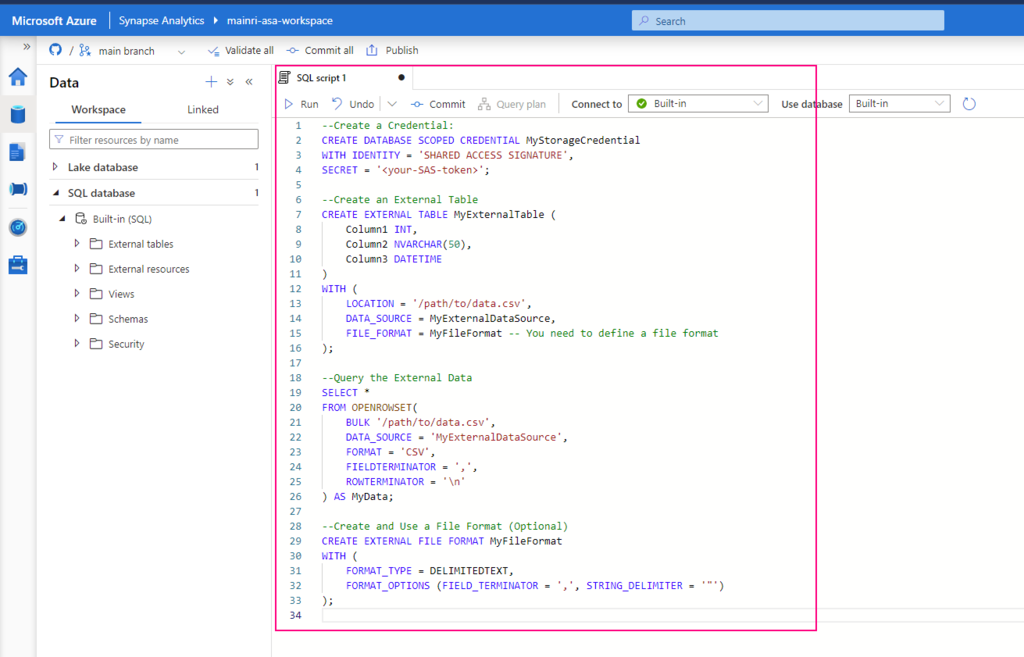
Preparing create external table
Before you can create an external table, you must create a storage credential that allows Unity Catalog to read from and write to the path on your cloud tenant, and an external location that references it.
Requirements
- In Azure, create a service principal and grant it the Azure Blob Contributor role on your storage container.
- In Azure, create a client secret for your service principal. Make a note of the client secret, the directory ID, and the application ID for the client secret.
step 1: Create a storage credential
You can create a storage credential using the Catalog Explorer or the Unity Catalog CLI. Follow these steps to create a storage credential using Catalog Explorer.
- In a new browser tab, log in to Databricks.
- Click Catalog.
- Click Storage Credentials.
- Click Create Credential.
- Enter example_credential for he name of the storage credential.
- Set Client Secret, Directory ID, and Application ID to the values for your service principal.
- Optionally enter a comment for the storage credential.
- Click Save.
Leave this browser open for the next steps.
Create an external location
An external location references a storage credential and also contains a storage path on your cloud tenant. The external location allows reading from and writing to only that path and its child directories. You can create an external location from Catalog Explorer, a SQL command, or the Unity Catalog CLI. Follow these steps to create an external location using Catalog Explorer.
- Go to the browser tab where you just created a storage credential.
- Click Catalog.
- Click External Locations.
- Click Create location.
- Enter example_location for the name of the external location.
- Enter the storage container path for the location allows reading from or writing to.
- Set Storage Credential to example_credential to the storage credential you just created.
- Optionally enter a comment for the external location.
- Click Save.
-- Grant access to create tables in the external location
GRANT USE CATALOG
ON example_catalog
TO `all users`;
GRANT USE SCHEMA
ON example_catalog.example_schema
TO `all users`;
GRANT CREATE EXTERNAL TABLE
ON LOCATION example_location
TO `all users`;-- Create an example catalog and schema to contain the new table
CREATE CATALOG IF NOT EXISTS example_catalog;
USE CATALOG example_catalog;
CREATE SCHEMA IF NOT EXISTS example_schema;
USE example_schema;-- Create a new external Unity Catalog table from an existing table
-- Replace <bucket_path> with the storage location where the table will be created
CREATE TABLE IF NOT EXISTS trips_external
LOCATION 'abfss://<bucket_path>'
AS SELECT * from samples.nyctaxi.trips;
-- To use a storage credential directly, add 'WITH (CREDENTIAL <credential_name>)' to the SQL statement.There are some useful Microsoft document to be refer:
“Create an external table in Unity Catalog“
“Configure a managed identity for Unity Catalog“
“Create a Unity Catalog metastore“
“Manage access to external cloud services using service credentials“
“Create a storage credential for connecting to Azure Data Lake Storage Gen2“
“External locations“
Example
CREATE TABLE external_table (
id INT,
name STRING
)
LOCATION 'abfss://container@storageaccount.dfs.core.windows.net/path/to/data';
INSERT INTO external_table VALUES (1, 'Bob');
SELECT * FROM external_table;3. Foreign Tables
Foreign tables reference data stored in external systems (e.g., Snowflake, Redshift) without copying the data into Databricks.
Data Storage and Location
The metadata is stored in Unity Catalog, but the data resides in another metastore (e.g., an external data warehouse like Snowflake or BigQuery).
It does not point to raw files but to an external system.
Use Case:
Best for querying external databases like Snowflake, BigQuery, Redshift without moving data.
Pros and Cons
Pros: No data duplication, seamless integration with external systems.
Cond: Performance depends on the external system’s capabilities.
Example
CREATE FOREIGN TABLE foreign_table
USING com.databricks.spark.snowflake
OPTIONS (
sfUrl 'snowflake-account-url',
sfUser 'user',
sfPassword 'password',
sfDatabase 'database',
sfSchema 'schema',
dbtable 'table'
);
SELECT * FROM foreign_table;4. Delta Tables
Delta tables use the Delta Lake format, providing ACID transactions, scalable metadata handling, and data versioning.
Data Storage and Location
A special type of managed or external table that uses Delta Lake format.
Can be in managed storage or external storage.
Use Case:
Ideal for reliable, versioned data pipelines.
Pros and Cons
Pros: ACID compliance, time travel, schema enforcement, efficient upserts/deletes.
Cons: Slightly more complex due to Delta Lake features.
Example
CREATE TABLE delta_table (
id INT,
name STRING
)
USING DELTA
LOCATION 'abfss://container@storageaccount.dfs.core.windows.net/path/to/delta';
INSERT INTO delta_table VALUES (1, 'Charlie');
SELECT * FROM delta_table;
-- Time travel example
SELECT * FROM delta_table VERSION AS OF 1;5. Feature Tables
Feature tables are used in machine learning workflows to store and manage feature data for training and inference.
Data Storage and Location
Used for machine learning (ML) feature storage with Databricks Feature Store.
Can be managed or external.
Use Case:
Ideal for managing and sharing features across ML models and teams.
Pros and Cons:
Pros: Centralized feature management, versioning, and lineage tracking.
Pros: Centralized feature management, versioning, and lineage tracking.
Example:
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
fs.create_table(
name="feature_table",
primary_keys=["id"],
schema="id INT, feature1 FLOAT, feature2 FLOAT",
description="Example feature table"
)
fs.write_table("feature_table", df, mode="overwrite")
features = fs.read_table("feature_table")6. Streaming Tables
Streaming tables are designed for real-time data ingestion and processing using Structured Streaming.
Data Location:
Can be stored in managed or external storage.
Use Case:
Ideal for real-time data pipelines and streaming analytics.
Pros and Cons
Pros: Supports real-time data processing, integrates with Delta Lake for reliability.
Cons: Requires understanding of streaming concepts and infrastructure.
Example:
CREATE TABLE streaming_table (
id INT,
name STRING
)
USING DELTA;
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("StreamingExample").getOrCreate()
streaming_df = spark.readStream.format("delta").load("/path/to/delta")
streaming_df.writeStream.format("delta").outputMode("append").start("/path/to/streaming_table")Delta Live Tables (DLT)
Delta Live Tables (DLT) is the modern replacement for Live Tables. It is a framework for building reliable, maintainable, and scalable ETL pipelines using Delta Lake. DLT automatically handles dependencies, orchestration, and error recovery.
Data storage and Location:
Data is stored in Delta Lake format, either in managed or external storage.
Use Case:
Building production-grade ETL pipelines for batch and streaming data.
- DLT pipelines are defined using Python or SQL.
- Tables are automatically materialized and can be queried like any other Delta table.
Pros and Cons
- Declarative pipeline definition.
- Automatic dependency management.
- Built-in data quality checks and error handling.
- Supports both batch and streaming workloads.
Cons: Requires understanding of Delta Lake and ETL concepts.
Example
import dlt
@dlt.table
def live_table():
return spark.read.format("delta").load("/path/to/source_table")8. Hive Tables (Legacy)
Hive tables are legacy tables that use the Apache Hive format. They are supported for backward compatibility.
Data storage Location:
Can be stored in managed or external storage.
Use Case:
Legacy systems or migration projects.
Pros and Cons
- Pros: Backward compatibility with older systems.
- Cons: Lacks modern features like ACID transactions and time travel.
Example
CREATE TABLE hive_table (
id INT,
name STRING
)
STORED AS PARQUET;
INSERT INTO hive_table VALUES (1, 'Dave');
SELECT * FROM hive_table;Final Thoughts
Use Delta Live Tables for automated ETL pipelines.
Use Feature Tables for machine learning models.
Use Foreign Tables for querying external databases.
Avoid Hive Tables unless working with legacy systems.
Summary
- Managed Tables: Fully managed by Databricks, ideal for internal workflows.
- External Tables: Metadata managed by Databricks, data stored externally, ideal for cross-platform sharing.
- Delta Tables: Advanced features like ACID transactions and time travel, ideal for reliable pipelines.
- Foreign Tables: Query external systems without data duplication.
- Streaming Tables: Designed for real-time data processing.
- Feature Tables: Specialized for machine learning feature management.
- Hive Tables: Legacy format, not recommended for new projects.
Each table type has its own creation syntax and usage patterns, and the choice depends on your specific use case, data storage requirements, and workflow complexity.
Please do not hesitate to contact me if you have any questions at William . chen @ mainri.ca
(remove all space from the email account 😊)