The Azure Data Lake is a massively scalable and secure data storage for high-performance analytics workloads. We can create three storage accounts within a single resource group.
Consider whether an organization needs one or many storage accounts and consider what file systems I require to build our logical data lake. (by the way, Multiple storage accounts or file systems can’t incur a monetary cost until data is accessed or stored.)
Each storage account within our data landing zone stores data in one of three stages:
- Raw data
- Enriched and curated data
- Development data lakes
You might want to consolidate raw, enriched, and curated layers into one storage account. Keep another storage account named “development” for data consumers to bring other useful data products.
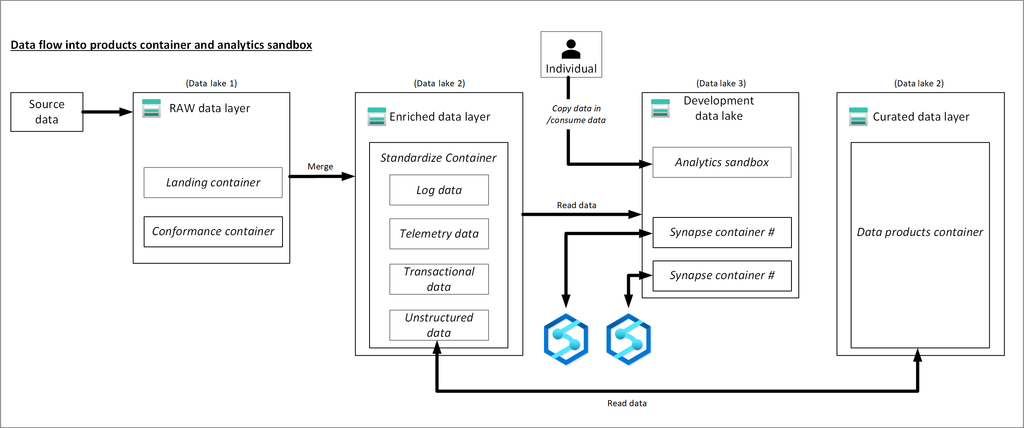
A data application can consume enriched and curated data from a storage account which has been ingested an automated data agnostic ingestion service.
we are going to Leveraged the medallion architecture to implement it. if you need more information about medallion architecture please review my previously articles – Medallion Architecture
It’s important to plan data structure before landing data into a data lake.
Data Lake Planning
When you plan a data lake, always consider appropriate consideration to structure, governance, and security. Multiple factors influence each data lake’s structure and organization:
- The type of data stored
- How its data is transformed
- Who accesses its data
- What its typical access patterns are
If your data lake contains a few data assets and automated processes like extract, transform, load (ETL) offloading, your planning is likely to be fairly easy. If your data lake contains hundreds of data assets and involves automated and manual interaction, expect to spend a longer time planning, as you’ll need a lot more collaboration from data owners.
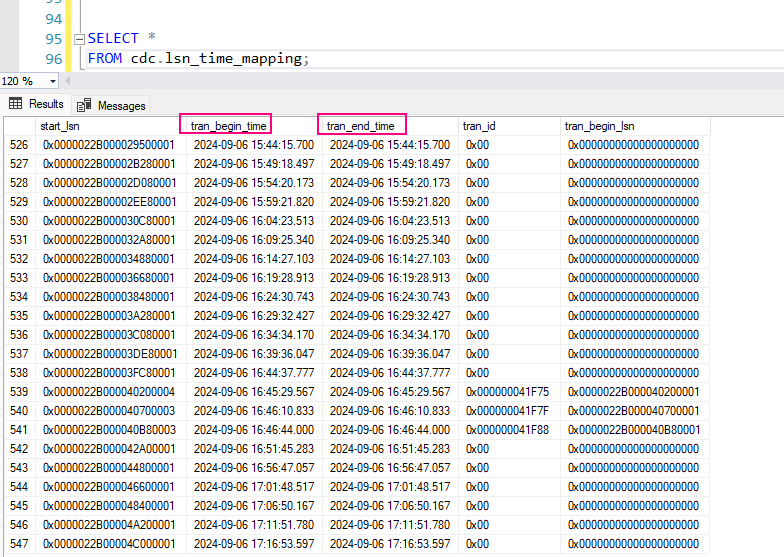
Three data lakes are illustrated in each data landing zone. The data lake sits across three data lake accounts, multiple containers, and folders, but it represents one logical data lake for our data landing zone.
| Lake number | Layers | Container number | Container name |
|---|---|---|---|
| 1 | Raw | 1 | Landing |
| 1 | Raw | 2 | Conformance |
| 2 | Enriched | 1 | Standardized |
| 2 | Curated | 2 | Data products |
| 3 | Development | 1 | Analytics sandbox |
| 3 | Development | # | Synapse primary storage number |
Depending on requirements, you might want to consolidate raw, enriched, and curated layers into one storage account. Keep another storage account named “development” for data consumers to bring other useful data products.
Enable Azure Storage with the hierarchical name space feature, which allows you to efficiently manage files.
Each data product should have two folders in the data products container that our data product team owns.
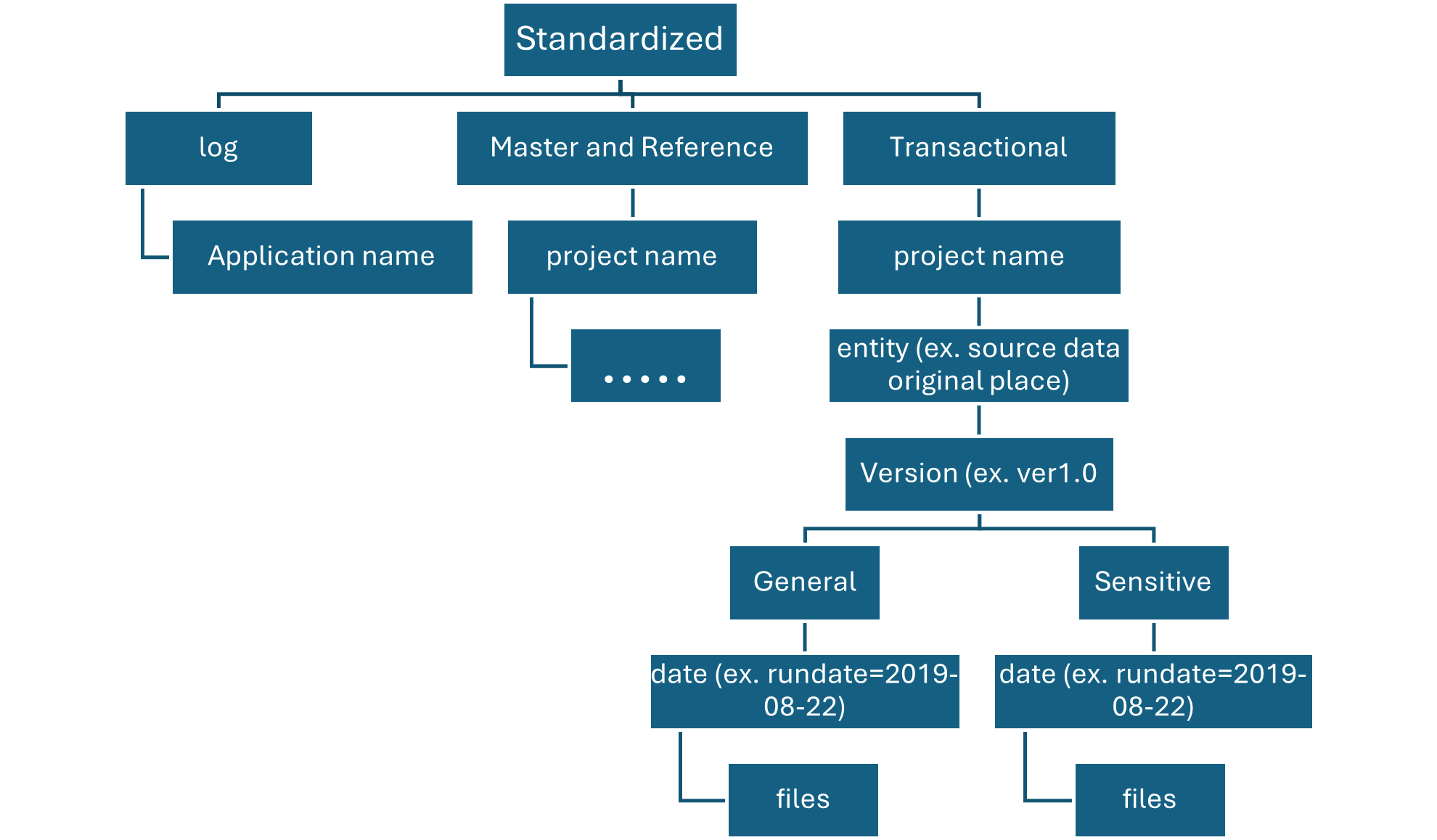
On enriched layer, standardized container, there are two folders per source system, divided by classification. With this structure, team can separately store data that has different security and data classifications and assign them different security access.
Our standardized container needs a general folder for confidential or below data and a sensitive folder for personal data. Control access to these folders by using access control lists (ACLs). We can create a dataset with all personal data removed, and store it in our general folder. We can have another dataset that includes all personal data in our sensitive personal data folder.
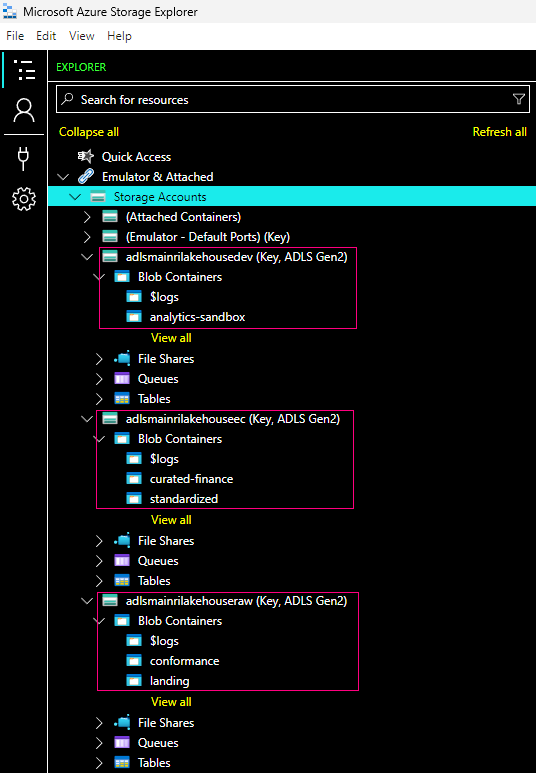
I created 3 accounts (Azure storage naming allows low case and number only. no dash, no underscore etc. allows)
- adlsmainrilakehousedev — Development
- adlsmainrilakehouseec — Enrich and Curated
- adlsmainrilakehouseraw — Raw data
Raw layer (data lake one)
This data layer is considered the bronze layer or landing raw source data. Think of the raw layer as a reservoir that stores data in its natural and original state. It’s unfiltered and unpurified.
You might store the data in its original format, such as JSON or CSV. Or it might be cost effective to store the file contents as a column in a compressed file format, like Avro, Parquet, or Databricks Delta Lake.
You can organize this layer by using one folder per source system. Give each ingestion process write access to only its associated folder.
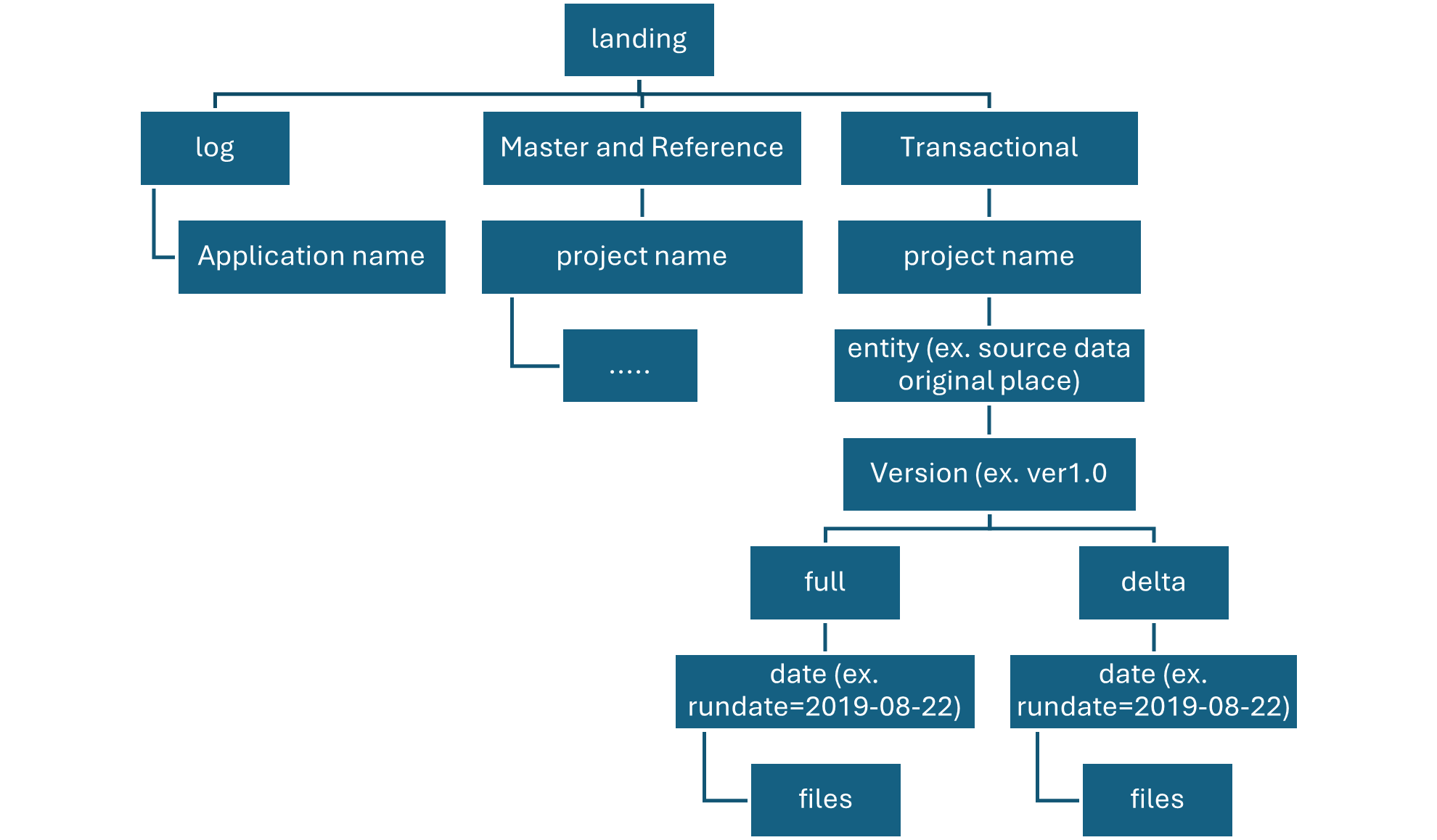
Raw Layer Landing container
The landing container is reserved for raw data that’s from a recognized source system.
Our data agnostic ingestion engine or a source-aligned data application loads the data, which is unaltered and in its original supported format.
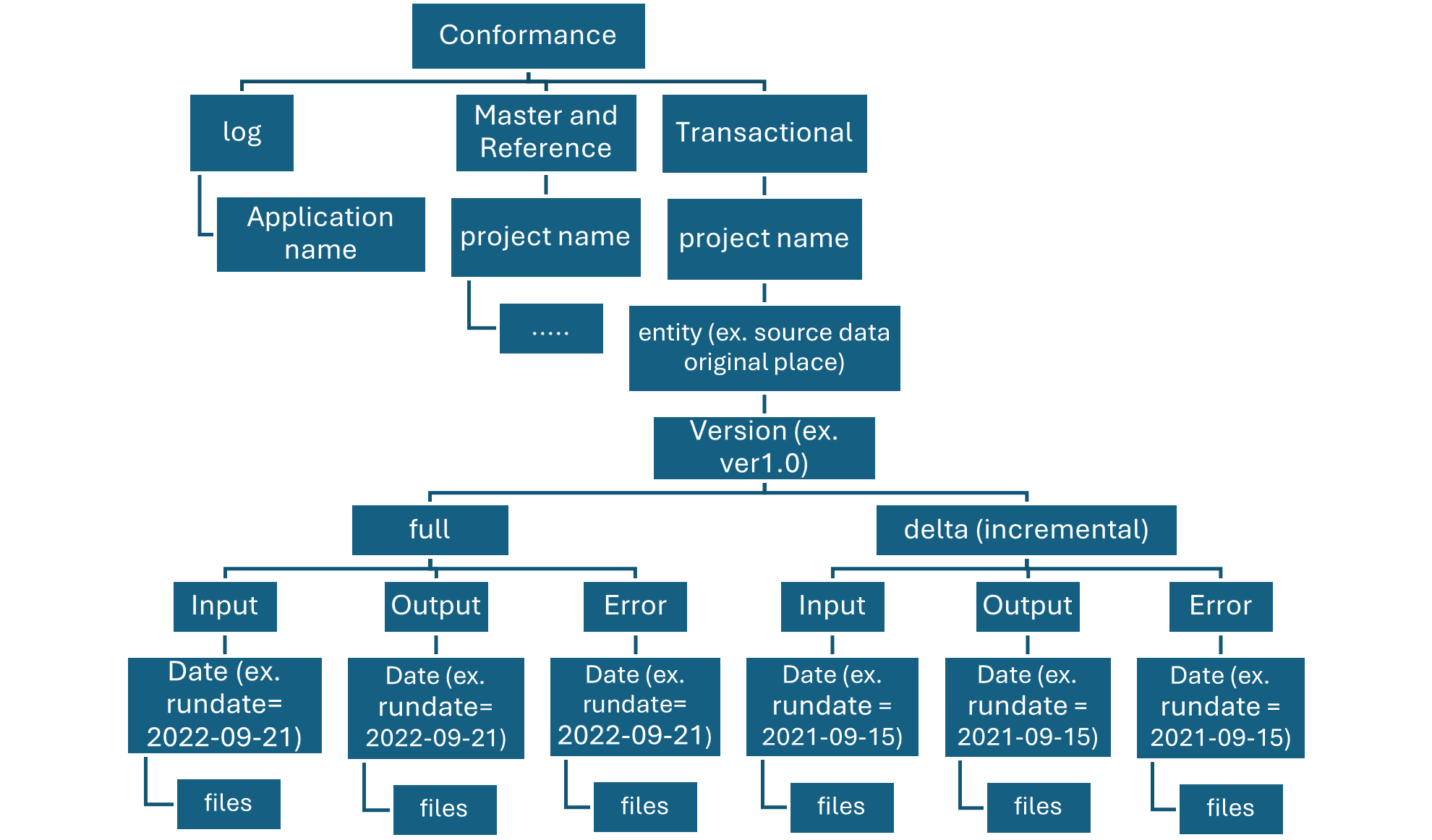
Raw layer conformance container
The conformance container in raw layer contains data quality conformed data.
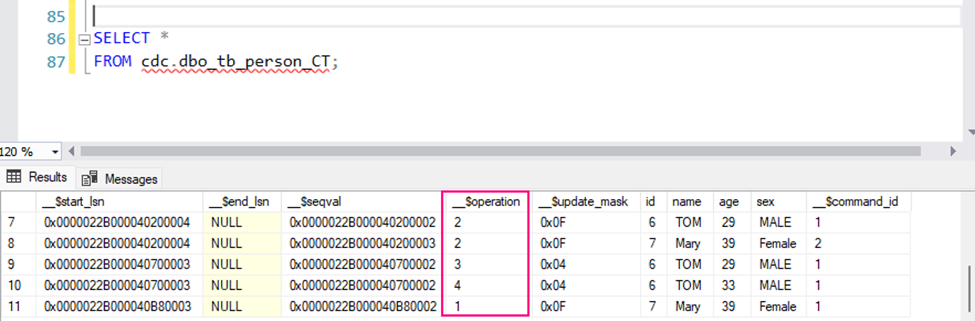
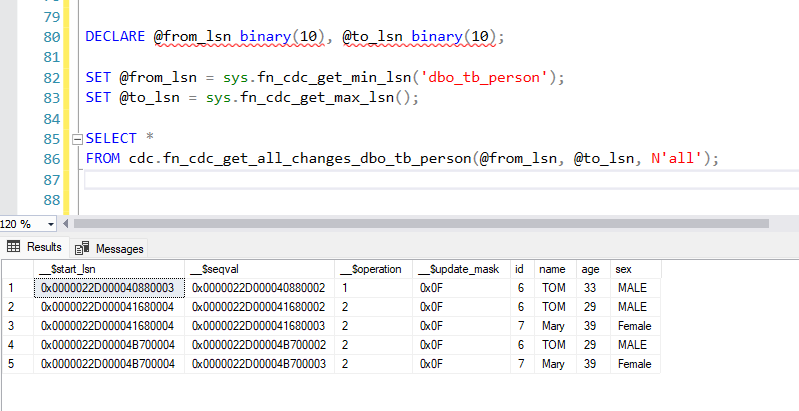
As data is copied to a landing container, data processing and computing is triggered to copy the data from the landing container to the conformance container. In this first stage, data gets converted into the delta lake format and lands in an input folder. When data quality runs, records that pass are copied into the output folder. Records that fail land in an error folder.
Enriched layer (data lake two)
Think of the enriched layer as a filtration layer. It removes impurities and can also involve enrichment. This data layer is also considered the silver layer.
The following diagram shows the flow of data lakes and containers from source data to a standardized container.
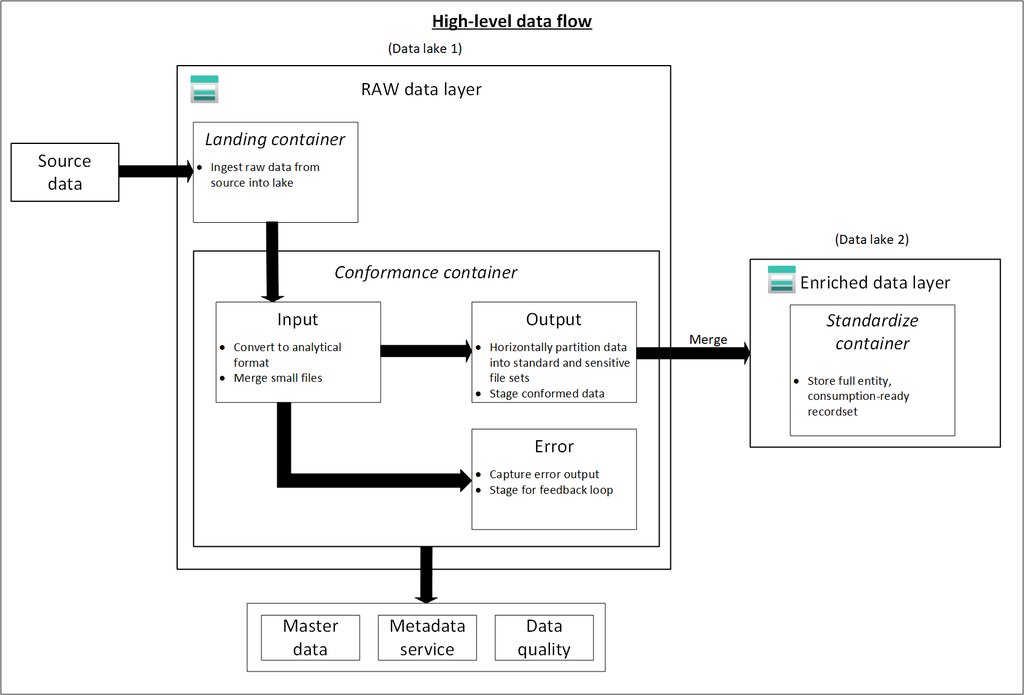
Standardized container
Standardization container holds systems of record and masters. Data within this layer has had no transformations applied other than data quality, delta lake conversion, and data type alignment.
Folders in Standardized container are segmented first by subject area, then by entity. Data is available in merged, partitioned tables that are optimized for analytics consumption.
Curated layer (data lake two)
The curated layer is our consumption layer and known as Golden layer. It’s optimized for analytics rather than data ingestion or processing. The curated layer might store data in denormalized data marts or star schemas.
Data from our standardized container is transformed into high-value data products that are served to our data consumers. This data has structure. It can be served to the consumers as-is, such as data science notebooks, or through another read data store, such as Azure SQL Database.
This layer isn’t a replacement for a data warehouse. Its performance typically isn’t adequate for responsive dashboards or end user and consumer interactive analytics. This layer is best suited for internal analysts and data scientists who run large-scale, improvised queries or analysis, or for advanced analysts who don’t have time-sensitive reporting needs.
Data products container
Data assets in this zone are typically highly governed and well documented. Assign permissions by department or by function, and organize permissions by consumer group or data mart.
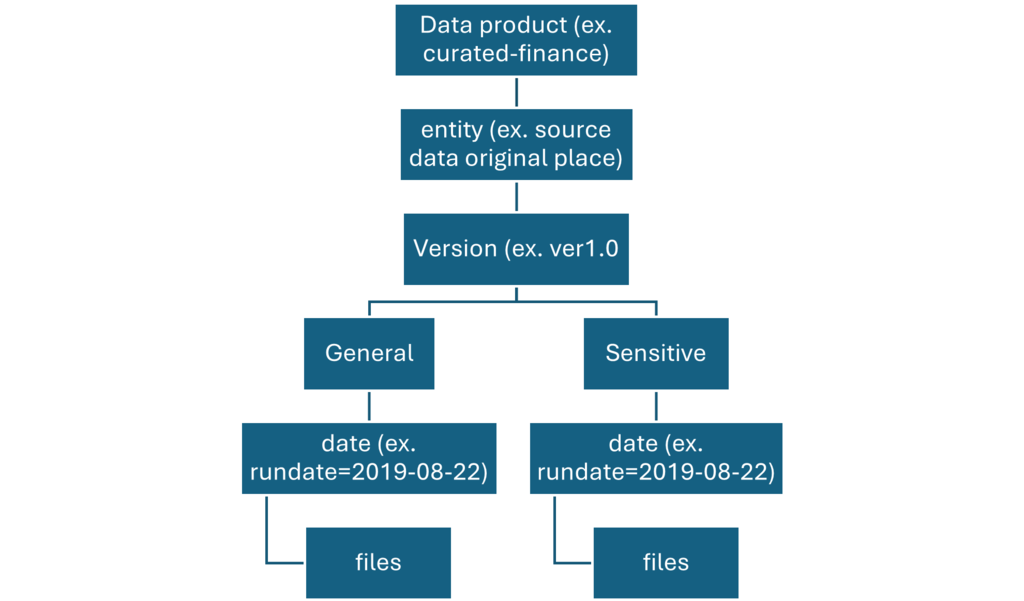
When landing data in another read data store, like Azure SQL Database, ensure that we have a copy of that data located in the curated data layer. Our data product users are guided to main read data store or Azure SQL Database instance, but they can also explore data with extra tools if we make the data available in our data lake.
Development layer (data lake three)
Our data consumers can/may bring other useful data products along with the data ingested into our standardized container in the silver layer.
Analytics Sandbox
The analytics sandbox area is a working area for an individual or a small group of collaborators. The sandbox area’s folders have a special set of policies that prevent attempts to use this area as part of a production solution. These policies limit the total available storage and how long data can be stored.
In this scenario, our data platform can/may allocate an analytics sandbox area for these consumers. In the sandbox, they, consumers, can generate valuable insights by using the curated data and data products that they bring.
For example, if a data science team wants to determine the best product placement strategy for a new region, they can bring other data products, like customer demographics and usage data, from similar products in that region. The team can use the high-value sales insights from this data to analyze the product market fit and offering strategy.
These data products are usually of unknown quality and accuracy. They’re still categorized as data products, but are temporary and only relevant to the user group that’s using the data.
When these data products mature, our enterprise can promote these data products to the curated data layer. To keep data product teams responsible for new data products, provide the teams with a dedicated folder on our curated data zone. They can store new results in the folder and share them with other teams across organization.
Conclusion
Data lakes are an indispensable tool in a modern data strategy. They allow teams to store data in a variety of formats, including structured, semi-structured, and unstructured data – all vendor-neutral forms, which eliminates the danger of vendor lock-in and gives users more control over the data. They also make data easier to access and retrieve, opening the door to a wider choice of analytical tools and applications.
Please do not hesitate to contact me if you have any questions at William . chen @mainri.ca
(remove all space from the email account 😊)
Appendix:
Introduce Medallion architecture
Data lake vs delta lake vs data lakehouse, and data warehouses comparison