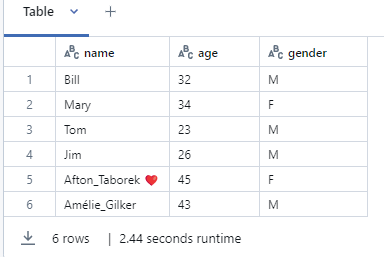
If a Delta table is saved in Blob Storage or Azure Data Lake Storage (ADLS), you access it using the file path rather than a cataloged name (like in Unity Catalog). Here’s how to read from and write to Delta tables stored in Blob Storage or ADLS in Spark SQL and PySpark.
Reading Delta Tables from Blob Storage or ADLS
To read Delta tables from Blob Storage or ADLS, you specify the path to the Delta table and use the delta. format.
Syntax
# Spark SQL
SELECT * FROM delta.`/mnt/path/to/delta/table`caution: " ` " - backticks# pyspark
df = spark.read.format("delta").load("path/to/delta/table")
Writing Delta Tables to Blob Storage or ADLS
When writing to Delta tables, use the delta format and specify the path where you want to store the table.
Spark SQL cannot directly write to a Delta table in Blob or ADLS (use PySpark for this). However, you can run SQL queries and insert into a Delta table using INSERT INTO:
# SparkSQL
INSERT INTO delta.`/mnt/path/to/delta/table`SELECT * FROM my_temp_table
caution: " ` " - backticks
# PySpark
df.write.format("delta").mode("overwrite").save("path/to/delta/table")Options and Parameters for Delta Read/Write
Options for Reading Delta Tables:
You can configure the read operation with options like:
mergeSchema: Allows schema evolution if the structure of the Delta table changes.spark.sql.files.ignoreCorruptFiles: Ignores corrupt files during reading.timeTravel: Enables querying older versions of the Delta table.
df = spark.read.format("delta").option("mergeSchema", "true").load("path/to/delta/table")
df.show()Options for Writing Delta Tables:
mode: Controls the write mode.
overwrite: Overwrites the existing data.append: Adds to existing data.ignore: Ignores the write if data exists.errorifexists: Defaults to throwing an error if data exists.
partitionBy: Partition the data by one or more columns.
overwriteSchema: Overwrites the schema of an existing Delta table if there’s a schema change.
df.write.format("delta").mode("overwrite") \
.option("overwriteSchema", "true") \
.partitionBy("column_name") \
.save("path/to/delta/table")
Time Travel and Versioning with Delta (PySpark)
Delta supports time travel, allowing you to query previous versions of the data. This is very useful for audits or retrieving data at a specific point in time.
# Read from a specific version
df = spark.read.format("delta").option("versionAsOf", 2).load("path/to/delta/table")
df.show()
# Read data at a specific timestamp
df = spark.read.format("delta").option("timestampAsOf", "2024-10-01").load("path/to/delta/table")
df.show()
Conclusion:
- Delta is a powerful format that works well with ADLS or Blob Storage when used with PySpark.
- Ensure that you’re using the Delta Lake library to access Delta features, like ACID transactions, schema enforcement, and time travel.
- For reading, use
.format("delta").load("path"). - For writing, use
.write.format("delta").save("path").