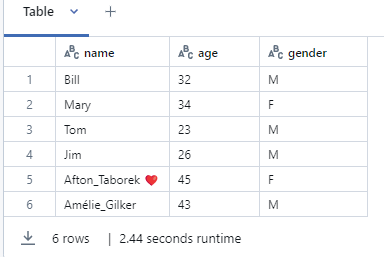
PySpark DataFrame is a distributed collection of rows, similar to a table in a relational database or a DataFrame in Python’s pandas library. It provides powerful tools for querying, transforming, and analyzing large-scale structured and semi-structured data.
PySpark apply functions
Apply a function to a column
df.withColumn("Upper_Name", upper(df.Name))
df.select("Seqno","Name", upper(df.Name))
df.createOrReplaceTempView("TAB")
spark.sql("select Seqno, Name, UPPER(Name) from TAB")
def upperCase(str):
return str.upper()
upperCaseUDF = udf(upperCase,StringType())
spark.sql("select Seqno, Name, upperCaseUDF(Name) from TAB")collect ( )
collect () is an action operation that is used to retrieve all the elements of the dataset (from all nodes) to the driver node
+---------+-------+
|dept_name|dept_id|
+---------+-------+
|Finance |10 |
|Marketing|20 |
|Sales |30 |
|IT |40 |
+---------+-------+
dataCollect = deptDF.collect()
print(dataCollect)
[Row(dept_name='Finance', dept_id=10), Row(dept_name='Marketing', dept_id=20), Row(dept_name='Sales', dept_id=30), Row(dept_name='IT', dept_id=40)]Column Class
Access column
data=[("James",23),("Ann",40)]
df=spark.createDataFrame(data).toDF("name.fname","gender")
df.printSchema()
#root
# |-- name.fname: string (nullable = true)
# |-- gender: long (nullable = true)
+----------+------+
|name.fname|gender|
+----------+------+
| James| 23|
| Ann| 40|
+----------+------+
# Using DataFrame object (df)
df.select(df.gender).show()
df.select(df["gender"]).show()
#Accessing column name with dot (with backticks)
df.select(df["`name.fname`"]).show()
#Using SQL col() function
from pyspark.sql.functions import col
df.select(col("gender")).show()
#Accessing column name with dot (with backticks)
df.select(col("`name.fname`")).show()Column Operators
+----+----+----+
|col1|col2|col3|
+----+----+----+
| 100| 2| 1|
| 200| 3| 4|
| 300| 4| 4|
+----+----+----+
#Arthmetic operations
df.select(df.col1 + df.col2).show()
df.select(df.col1 - df.col2).show()
df.select(df.col1 * df.col2).show()
df.select(df.col1 / df.col2).show()
df.select(df.col1 % df.col2).show()
df.select(df.col2 > df.col3).show()
+-------------+
|(col2 > col3)|
+-------------+
| true|
| false|
| false|
+-------------+
df.select(df.col2 < df.col3).show()
+-------------+
|(col2 < col3)|
+-------------+
| false|
| true|
| false|
+-------------+
df.select(df.col2 == df.col3).show()
+-------------+
|(col2 = col3)|
+-------------+
| false|
| false|
| true|
+-------------+Convert DataFrame to Pandas
PySpark DataFrame provides a method toPandas() to convert it to Python Pandas DataFrame. toPandas() results in the collection of all records in the PySpark DataFrame to the driver program and should be done only on a small subset of the data.
pandasDF = pysparkDF.toPandas()Convert RDD to DataFrame
df = rdd.toDF()Create an empty DataFrame
#Create Schema
from pyspark.sql.types import StructType,StructField, StringType
schema = StructType([
StructField('firstname', StringType(), True),
StructField('middlename', StringType(), True),
StructField('lastname', StringType(), True)
])
#Create empty DataFrame from empty RDD
df = spark.createDataFrame(emptyRDD,schema)#Convert empty RDD to Dataframe
df1 = emptyRDD.toDF(schema)#Create empty DataFrame directly.
df2 = spark.createDataFrame([], schema)
df2.printSchema()dropDuplicates, distinct ()
key different between distinct() and dropDuplicates()
distinct()considers all columns when identifying duplicates, whiledropDuplicates()allowing you to specify a subset of columns to determine uniqueness.distinct()function treats NULL values as equal, so if there are multiple rows with NULL values in all columns, only one of them will be retained after applyingdistinct().
+-------------+----------+------+
|employee_name|department|salary|
+-------------+----------+------+
|James |Sales |3000 |
|Michael |Sales |4600 |
|Robert |Sales |4100 |
|Maria |Finance |3000 |
|James |Sales |3000 | #duplicated
|Scott |Finance |3300 |
|Jen |Finance |3900 |
|Jeff |Marketing |3000 |
|Kumar |Marketing |2000 |
|Saif |Sales |4100 |
+-------------+----------+------+
df.distinct().show()
+-------------+----------+------+
|employee_name|department|salary|
+-------------+----------+------+
|James |Sales |3000 |
|Michael |Sales |4600 |
|Robert |Sales |4100 |
|Maria |Finance |3000 |
|Scott |Finance |3300 | # <-James is removed
|Jen |Finance |3900 |
|Jeff |Marketing |3000 |
|Kumar |Marketing |2000 |
|Saif |Sales |4100 |
+-------------+----------+------+
df2 = df.dropDuplicates()
print("Distinct count: "+str(df2.count()))
Distinct count: 9
df2.show(truncate=False)
+-------------+----------+------+
|employee_name|department|salary|
+-------------+----------+------+
|James |Sales |3000 |
|Michael |Sales |4600 |
|Robert |Sales |4100 |
|Maria |Finance |3000 |
|Scott |Finance |3300 | # <-James is removed
|Jen |Finance |3900 |
|Jeff |Marketing |3000 |
|Kumar |Marketing |2000 |
|Saif |Sales |4100 |
+-------------+----------+------+
df2 = df.dropDuplicates(["department"])
print("Distinct count: "+str(df2.count()))
Distinct count: 3
df2.show(truncate=False)
+-------------+----------+------+
|employee_name|department|salary|
+-------------+----------+------+
|Maria |Finance |3000 |
|Jeff |Marketing |3000 |
|James |Sales |3000 |
+-------------+----------+------+fillna() & fill()
DataFrame.fillna() and DataFrameNaFunctions.fill() to replace NULL/None values.
# Prepare Data
data = [("James", None, 3000), \
("Michael", "Sales", None), \
("Robert", "Sales", 4100), \
("Maria", "Finance", 3000), \
("James", "Sales", 3000), \
("Scott", "Finance", None), \
("Jen", "Finance", 3900), \
("Jeff", "Marketing", 3000), \
("Kumar", None, 2000), \
("Saif", "Sales", 4100) \
]
# Create DataFrame
columns= ["employee_name", "department", "salary"]
df = spark.createDataFrame(data = data, schema = columns)
df.printSchema()
df.show(truncate=False)
+-------------+----------+------+
|employee_name|department|salary|
+-------------+----------+------+
|James |null |3000 |
|Michael |Sales |null |
|Robert |Sales |4100 |
|Maria |Finance |3000 |
|James |Sales |3000 |
|Scott |Finance |null |
|Jen |Finance |3900 |
|Jeff |Marketing |3000 |
|Kumar |null |2000 |
|Saif |Sales |4100 |
+-------------+----------+------+
#Replace 0 for null for all integer columns
df.na.fill(value=0).show()
+-------------+----------+------+
|employee_name|department|salary|
+-------------+----------+------+
| James| null| 3000|
| Michael| Sales| 0|
| Robert| Sales| 4100|
| Maria| Finance| 3000|
| James| Sales| 3000|
| Scott| Finance| 0|
| Jen| Finance| 3900|
| Jeff| Marketing| 3000|
| Kumar| null| 2000|
| Saif| Sales| 4100|
+-------------+----------+------+
#Replace 0 for null on only population column
df.na.fill(value="unknown",subset=["department"]).show()
+-------------+----------+------+
|employee_name|department|salary|
+-------------+----------+------+
| James| unknown| 3000|
| Michael| Sales| null|
| Robert| Sales| 4100|
| Maria| Finance| 3000|
| James| Sales| 3000|
| Scott| Finance| null|
| Jen| Finance| 3900|
| Jeff| Marketing| 3000|
| Kumar| unknown| 2000|
| Saif| Sales| 4100|
+-------------+----------+------+groupBy ( )
groupBy ( ), Similar to SQL GROUP BY clause, transformation that is used to group rows that have the same values in specified columns into summary rows
+-------------+----------+-----+------+---+-----+
|employee_name|department|state|salary|age|bonus|
+-------------+----------+-----+------+---+-----+
| James| Sales| NY| 90000| 34|10000|
| Michael| Sales| NY| 86000| 56|20000|
| Robert| Sales| CA| 81000| 30|23000|
| Maria| Finance| CA| 90000| 24|23000|
| Raman| Finance| CA| 99000| 40|24000|
| Scott| Finance| NY| 83000| 36|19000|
| Jen| Finance| NY| 79000| 53|15000|
| Jeff| Marketing| CA| 80000| 25|18000|
| Kumar| Marketing| NY| 91000| 50|21000|
+-------------+----------+-----+------+---+-----+
df.groupBy("department","state") \
.sum("salary","bonus") \
.show()
+----------+-----+-----------+----------+
|department|state|sum(salary)|sum(bonus)|
+----------+-----+-----------+----------+
| Sales| NY| 176000| 30000|
| Sales| CA| 81000| 23000|
| Finance| CA| 189000| 47000|
| Finance| NY| 162000| 34000|
| Marketing| NY| 91000| 21000|
| Marketing| CA| 80000| 18000|
+----------+-----+-----------+----------+join ( )
- Inner Join: Returns only the rows with matching keys in both DataFrames.
- Left Join: Returns all rows from the left DataFrame and matching rows from the right DataFrame.
- Right Join: Returns all rows from the right DataFrame and matching rows from the left DataFrame.
- Full Outer Join: Returns all rows from both DataFrames, including matching and non-matching rows.
- Left Semi Join: Returns all rows from the left DataFrame where there is a match in the right DataFrame.
- Left Anti Join: Returns all rows from the left DataFrame where there is no match in the right DataFrame.
- Self Join:
# Emp Dataset
+------+--------+---------------+-----------+-----------+------+------+
|emp_id|name |superior_emp_id|year_joined|emp_dept_id|gender|salary|
+------+--------+---------------+-----------+-----------+------+------+
|1 |Smith |-1 |2018 |10 |M |3000 |
|2 |Rose |1 |2010 |20 |M |4000 |
|3 |Williams|1 |2010 |10 |M |1000 |
|4 |Jones |2 |2005 |10 |F |2000 |
|5 |Brown |2 |2010 |40 | |-1 |
|6 |Brown |2 |2010 |50 | |-1 |
+------+--------+---------------+-----------+-----------+------+------+
# Dept Dataset
+---------+-------+
|dept_name|dept_id|
+---------+-------+
|Finance |10 |
|Marketing|20 |
|Sales |30 |
|IT |40 |
+---------+-------+# Inner join
deptDF.join(empDF, deptDF.dept_id==empDF.emp_dept_id, "inner").show()
+---------+-------+------+--------+---------------+-----------+-----------+------+------+
|dept_name|dept_id|emp_id| name|superior_emp_id|year_joined|emp_dept_id|gender|salary|
+---------+-------+------+--------+---------------+-----------+-----------+------+------+
| Finance| 10| 1| Smith| -1| 2018| 10| M| 3000|
| Finance| 10| 3|Williams| 1| 2010| 10| M| 1000|
| Finance| 10| 4| Jones| 2| 2005| 10| F| 2000|
|Marketing| 20| 2| Rose| 1| 2010| 20| M| 4000|
| IT| 40| 5| Brown| 2| 2010| 40| | -1|
+---------+-------+------+--------+---------------+-----------+-----------+------+------+# Left outer join
empDF.join(deptDF,empDF.emp_dept_id == deptDF.dept_id,"left").show(truncate=False)
+------+--------+---------------+-----------+-----------+------+------+---------+-------+
|emp_id|name |superior_emp_id|year_joined|emp_dept_id|gender|salary|dept_name|dept_id|
+------+--------+---------------+-----------+-----------+------+------+---------+-------+
|1 |Smith |-1 |2018 |10 |M |3000 |Finance |10 |
|2 |Rose |1 |2010 |20 |M |4000 |Marketing|20 |
|3 |Williams|1 |2010 |10 |M |1000 |Finance |10 |
|4 |Jones |2 |2005 |10 |F |2000 |Finance |10 |
|5 |Brown |2 |2010 |40 | |-1 |IT |40 |
|6 |Brown |2 |2010 |50 | |-1 |null |null |
+------+--------+---------------+-----------+-----------+------+------+---------+-------+# Right outer join
empDF.join(deptDF,empDF.emp_dept_id == deptDF.dept_id,"right").show(truncate=False)
+------+--------+---------------+-----------+-----------+------+------+---------+-------+
|emp_id|name |superior_emp_id|year_joined|emp_dept_id|gender|salary|dept_name|dept_id|
+------+--------+---------------+-----------+-----------+------+------+---------+-------+
|4 |Jones |2 |2005 |10 |F |2000 |Finance |10 |
|3 |Williams|1 |2010 |10 |M |1000 |Finance |10 |
|1 |Smith |-1 |2018 |10 |M |3000 |Finance |10 |
|2 |Rose |1 |2010 |20 |M |4000 |Marketing|20 |
|null |null |null |null |null |null |null |Sales |30 |
|5 |Brown |2 |2010 |40 | |-1 |IT |40 |
+------+--------+---------------+-----------+-----------+------+------+---------+-------+# Full outer join
empDF.join(deptDF,empDF.emp_dept_id == deptDF.dept_id,"outer").show(truncate=False)
empDF.join(deptDF,empDF.emp_dept_id == deptDF.dept_id,"full").show(truncate=False)
empDF.join(deptDF,empDF.emp_dept_id == deptDF.dept_id,"fullouter").show(truncate=False)
+------+--------+---------------+-----------+-----------+------+------+---------+-------+
|emp_id|name |superior_emp_id|year_joined|emp_dept_id|gender|salary|dept_name|dept_id|
+------+--------+---------------+-----------+-----------+------+------+---------+-------+
|1 |Smith |-1 |2018 |10 |M |3000 |Finance |10 |
|3 |Williams|1 |2010 |10 |M |1000 |Finance |10 |
|4 |Jones |2 |2005 |10 |F |2000 |Finance |10 |
|2 |Rose |1 |2010 |20 |M |4000 |Marketing|20 |
|null |null |null |null |null |null |null |Sales |30 |
|5 |Brown |2 |2010 |40 | |-1 |IT |40 |
|6 |Brown |2 |2010 |50 | |-1 |null |null |
+------+--------+---------------+-----------+-----------+------+------+---------+-------+# Left semi join
empDF.join(deptDF,empDF.emp_dept_id == deptDF.dept_id,"leftsemi").show(truncate=False)
+------+--------+---------------+-----------+-----------+------+------+
|emp_id|name |superior_emp_id|year_joined|emp_dept_id|gender|salary|
+------+--------+---------------+-----------+-----------+------+------+
|1 |Smith |-1 |2018 |10 |M |3000 |
|3 |Williams|1 |2010 |10 |M |1000 |
|4 |Jones |2 |2005 |10 |F |2000 |
|2 |Rose |1 |2010 |20 |M |4000 |
|5 |Brown |2 |2010 |40 | |-1 |
+------+--------+---------------+-----------+-----------+------+------+
return: left-hand has, right-hand has too# Left anti join
empDF.join(deptDF,empDF.emp_dept_id == deptDF.dept_id,"leftanti").show(truncate=False)
+------+-----+---------------+-----------+-----------+------+------+
|emp_id|name |superior_emp_id|year_joined|emp_dept_id|gender|salary|
+------+-----+---------------+-----------+-----------+------+------+
|6 |Brown|2 |2010 |50 | |-1 |
+------+-----+---------------+-----------+-----------+------+------+
return: left-hand has, but right-hand does not have.# Self join
empDF.alias("emp1").join(empDF.alias("emp2"), \
col("emp1.superior_emp_id") == col("emp2.emp_id"),"inner") \
.select(col("emp1.emp_id"),col("emp1.name"), \
col("emp2.emp_id").alias("superior_emp_id"), \
col("emp2.name").alias("superior_emp_name")) \
.show(truncate=False)
+------+--------+---------------+-----------------+
|emp_id|name |superior_emp_id|superior_emp_name|
+------+--------+---------------+-----------------+
|2 |Rose |1 |Smith |
|3 |Williams|1 |Smith |
|4 |Jones |2 |Rose |
|5 |Brown |2 |Rose |
|6 |Brown |2 |Rose |
+------+--------+---------------+-----------------+orderBy( ) and sort( )
orderBy() and sort() can be interchange each other
+-------------+----------+-----+------+---+-----+
|employee_name|department|state|salary|age|bonus|
+-------------+----------+-----+------+---+-----+
|James |Sales |NY |90000 |34 |10000|
|Michael |Sales |NY |86000 |56 |20000|
|Robert |Sales |CA |81000 |30 |23000|
|Maria |Finance |CA |90000 |24 |23000|
|Raman |Finance |CA |99000 |40 |24000|
|Scott |Finance |NY |83000 |36 |19000|
|Jen |Finance |NY |79000 |53 |15000|
|Jeff |Marketing |CA |80000 |25 |18000|
|Kumar |Marketing |NY |91000 |50 |21000|
+-------------+----------+-----+------+---+-----+
# Sorting different columns in different orders
df.sort("state", "age",ascending=[False,True]).show()
df.sort(df["state"].desc(), df["age"].asc()).show()
df.orderBy("state", "age",ascending=[False,True]).show()
df.orderBy(df["state"].desc(), df["age"].asc()).show()
+-------------+----------+-----+------+---+-----+
|employee_name|department|state|salary|age|bonus|
+-------------+----------+-----+------+---+-----+
| James| Sales| NY| 90000| 34|10000|
| Scott| Finance| NY| 83000| 36|19000|
| Kumar| Marketing| NY| 91000| 50|21000|
| Jen| Finance| NY| 79000| 53|15000|
| Michael| Sales| NY| 86000| 56|20000|
| Maria| Finance| CA| 90000| 24|23000|
| Jeff| Marketing| CA| 80000| 25|18000|
| Robert| Sales| CA| 81000| 30|23000|
| Raman| Finance| CA| 99000| 40|24000|
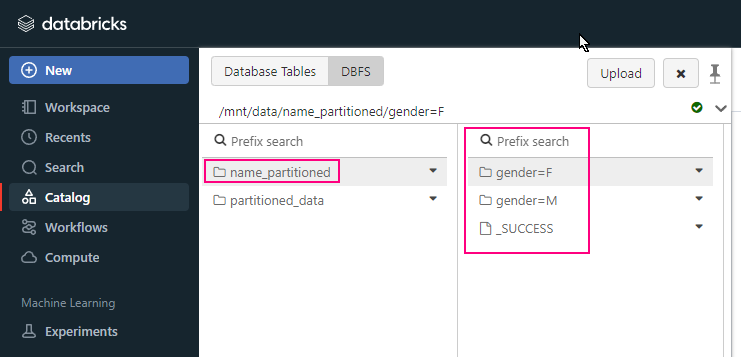
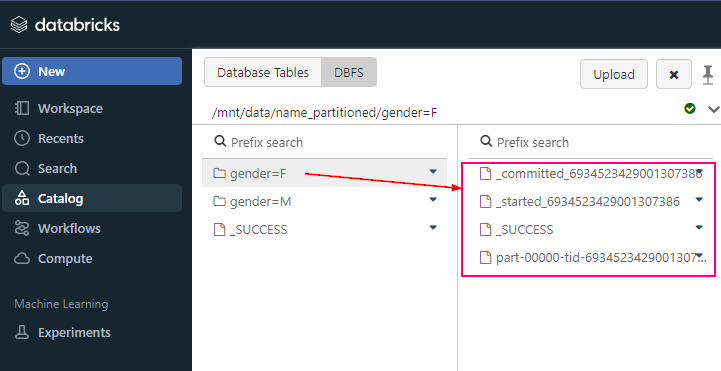
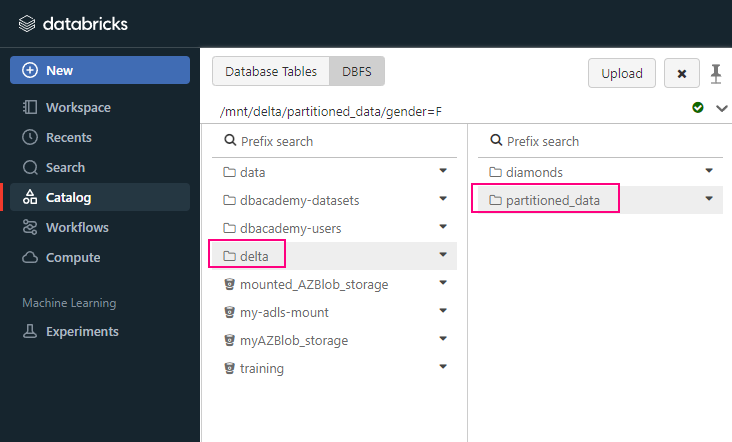
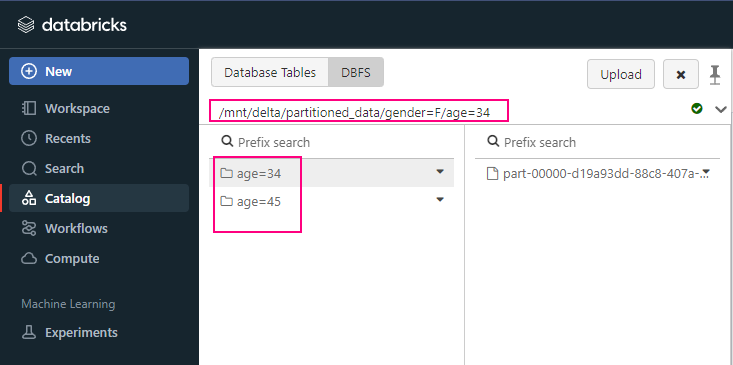
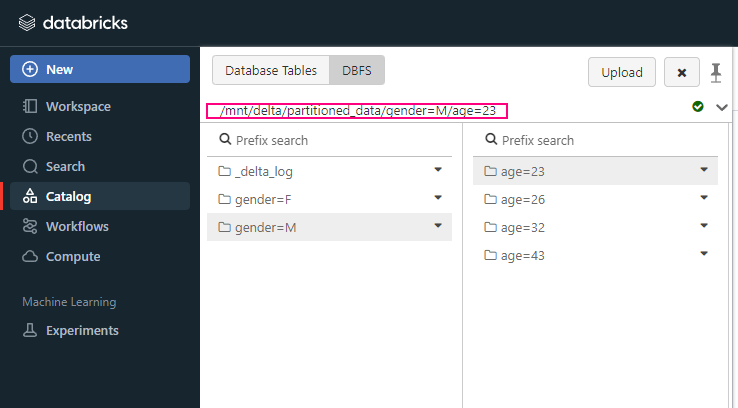
+-------------+----------+-----+------+---+-----+partitionBy ( )
partitionBy ( )
pivot ( ) & Unpivot ( )
pivot() (Row to Column)
#Create spark session
data = [("Banana",1000,"USA"), ("Carrots",1500,"USA"), ("Beans",1600,"USA"), \
("Orange",2000,"USA"),("Orange",2000,"USA"),("Banana",400,"China"), \
("Carrots",1200,"China"),("Beans",1500,"China"),("Orange",4000,"China"), \
("Banana",2000,"Canada"),("Carrots",2000,"Canada"),("Beans",2000,"Mexico")]
columns= ["Product","Amount","Country"]
df = spark.createDataFrame(data = data, schema = columns)
df.printSchema()
df.show(truncate=False)
# Output
root
|-- Product: string (nullable = true)
|-- Amount: long (nullable = true)
|-- Country: string (nullable = true)
+-------+------+-------+
|Product|Amount|Country|
+-------+------+-------+
|Banana |1000 |USA |
|Carrots|1500 |USA |
|Beans |1600 |USA |
|Orange |2000 |USA |
|Orange |2000 |USA |
|Banana |400 |China |
|Carrots|1200 |China |
|Beans |1500 |China |
|Orange |4000 |China |
|Banana |2000 |Canada |
|Carrots|2000 |Canada |
|Beans |2000 |Mexico |
+-------+------+-------+
# Applying pivot()
pivotDF = df.groupBy("Product").pivot("Country").sum("Amount")
pivotDF.printSchema()
pivotDF.show(truncate=False)
# Output
root
|-- Product: string (nullable = true)
|-- Canada: long (nullable = true)
|-- China: long (nullable = true)
|-- Mexico: long (nullable = true)
|-- USA: long (nullable = true)
+-------+------+-----+------+----+
|Product|Canada|China|Mexico|USA |
+-------+------+-----+------+----+
|Orange |null |4000 |null |4000|
|Beans |null |1500 |2000 |1600|
|Banana |2000 |400 |null |1000|
|Carrots|2000 |1200 |null |1500|
+-------+------+-----+------+----+
# one more example
pivotDF = df.groupBy("Country").pivot("Product").sum("Amount")
pivotDF.printSchema()
pivotDF.show(truncate=False)
root
|-- Country: string (nullable = true)
|-- Banana: long (nullable = true)
|-- Beans: long (nullable = true)
|-- Carrots: long (nullable = true)
|-- Orange: long (nullable = true)
+-------+------+-----+-------+------+
|Country|Banana|Beans|Carrots|Orange|
+-------+------+-----+-------+------+
|China |400 |1500 |1200 |4000 |
|USA |1000 |1600 |1500 |4000 |
|Mexico |null |2000 |null |null |
|Canada |2000 |null |2000 |null |
+-------+------+-----+-------+------+Unpivot
PySpark SQL doesn’t have unpivot function hence will use the stack() function.
# Applying unpivot()
from pyspark.sql.functions import expr
unpivotExpr = "stack(3, 'Canada', Canada, 'China', China, 'Mexico', Mexico) as (Country,Total)"
unPivotDF = pivotDF.select("Product", expr(unpivotExpr)) \
.where("Total is not null")
unPivotDF.show(truncate=False)
+-------+-------+-----+
|Product|Country|Total|
+-------+-------+-----+
|Orange |China |4000 |
|Beans |China |1500 |
|Beans |Mexico |2000 |
|Banana |Canada |2000 |
|Banana |China |400 |
|Carrots|Canada |2000 |
|Carrots|China |1200 |
+-------+-------+-----+sample(), sampleBy()
sample(), is a mechanism to get random sample records from the dataset
Syntax
sample(withReplacement, fraction, seed=None)
fraction– Fraction of rows to generate, range [0.0, 1.0]. Note that it doesn’t guarantee to provide the exact number of the fraction of records.seed– Seed for sampling (default a random seed). Used to reproduce the same random sampling.withReplacement– Sample with replacement or not (default False).
df=spark.range(100)
print(df.sample(0.06).collect())
#Output: [Row(id=0), Row(id=2), Row(id=17), Row(id=25), Row(id=26), Row(id=44), Row(id=80)]Above example, my DataFrame has 100 records and I wanted to get 6% sample records which are 6 but the sample() function returned 7 records. This proves the sample function doesn’t return the exact fraction specified.
To get consistent same random sampling uses the same slice value for every run. Change slice value to get different results.
print(df.sample(0.1,123).collect())
//Output: 36,37,41,43,56,66,69,75,83
print(df.sample(0.1,123).collect())
//Output: 36,37,41,43,56,66,69,75,83
print(df.sample(0.1,456).collect())
//Output: 19,21,42,48,49,50,75,80sampleBy()
sampleBy(col, fractions, seed=None)
df2=df.select((df.id % 3).alias("key"))
print(df2.sampleBy("key", {0: 0.1, 1: 0.2},0).collect())
//Output: [Row(key=0), Row(key=1), Row(key=1), Row(key=1), Row(key=0), Row(key=1), Row(key=1), Row(key=0), Row(key=1), Row(key=1), Row(key=1)]select ( )
+---------+--------+-------+-----+
|firstname|lastname|country|state|
+---------+--------+-------+-----+
|James |Smith |USA |CA |
|Michael |Rose |USA |NY |
|Robert |Williams|USA |CA |
|Maria |Jones |USA |FL |
+---------+--------+-------+-----+
# Select columns by different ways
df.select("firstname","lastname").show()
df.select(df.firstname,df.lastname).show()
df.select(df["firstname"],df["lastname"]).show()
# By using col() function
from pyspark.sql.functions import col
df.select(col("firstname"),col("lastname")).show()
+---------+--------+
|firstname|lastname|
+---------+--------+
| James| Smith|
| Michael| Rose|
| Robert|Williams|
| Maria| Jones|
+---------+--------+Nested Struct Columns
root
|-- name: struct (nullable = true)
| |-- firstname: string (nullable = true)
| |-- middlename: string (nullable = true)
| |-- lastname: string (nullable = true)
|-- state: string (nullable = true)
|-- gender: string (nullable = true)
+----------------------+-----+------+
|name |state|gender|
+----------------------+-----+------+
|{James, null, Smith} |OH |M |
|{Anna, Rose, } |NY |F |
|{Julia, , Williams} |OH |F |
|{Maria, Anne, Jones} |NY |M |
|{Jen, Mary, Brown} |NY |M |
|{Mike, Mary, Williams}|OH |M |
+----------------------+-----+------+
# Select child columns
df2.select("name.firstname","name.lastname").show(truncate=False)
+---------+--------+
|firstname|lastname|
+---------+--------+
|James |Smith |
|Anna | |
|Julia |Williams|
|Maria |Jones |
|Jen |Brown |
|Mike |Williams|
+---------+--------+
# Select all child columns
df2.select("name.*").show(truncate=False)
+---------+----------+--------+
|firstname|middlename|lastname|
+---------+----------+--------+
|James |null |Smith |
|Anna |Rose | |
|Julia | |Williams|
|Maria |Anne |Jones |
|Jen |Mary |Brown |
|Mike |Mary |Williams|
+---------+----------+--------+show ( )
df.show()
+-----+--------------------+
|Seqno| Quote|
+-----+--------------------+
| 1|Be the change tha...|
| 2|Everyone thinks o...|
| 3|The purpose of ou...|
| 4| Be cool.|
+-----+--------------------+
df.show(truncate=False)
df.show(2,truncate=25)
# Display DataFrame rows & columns vertically
df.show(n=3,truncate=25,vertical=True)
-RECORD 0--------------------------
Seqno | 1
Quote | Be the change that you...
-RECORD 1--------------------------
Seqno | 2
Quote | Everyone thinks of cha...
-RECORD 2--------------------------
Seqno | 3
Quote | The purpose of our liv...
only showing top 3 rows
StructType & StructField
StructType
Defines the structure of the DataFrame. StructType represents a schema, which is a collection of StructField objects. A StructType is essentially a list of fields, each with a name and data type, defining the structure of the DataFrame. It allows for the creation of nested structures and complex data types.
StructField
StructField – Defines the metadata of the DataFrame column. It represents a field in the schema, containing metadata such as the name, data type, and nullable status of the field. Each StructField object defines a single column in the DataFrame, specifying its name and the type of data it holds.
data = [("James","","Smith","36636","M",3000),
("Michael","Rose","","40288","M",4000),
("Robert","","Williams","42114","M",4000),
("Maria","Anne","Jones","39192","F",4000),
("Jen","Mary","Brown","","F",-1)
]
schema = StructType([ \
StructField("firstname",StringType(),True), \
StructField("middlename",StringType(),True), \
StructField("lastname",StringType(),True), \
StructField("id", StringType(), True), \
StructField("gender", StringType(), True), \
StructField("salary", IntegerType(), True) \
])
df = spark.createDataFrame(data=data,schema=schema)
df.printSchema()
df.show(truncate=False)
+---------+----------+--------+-----+------+------+
|firstname|middlename|lastname|id |gender|salary|
+---------+----------+--------+-----+------+------+
|James | |Smith |36636|M |3000 |
|Michael |Rose | |40288|M |4000 |
|Robert | |Williams|42114|M |4000 |
|Maria |Anne |Jones |39192|F |4000 |
|Jen |Mary |Brown | |F |-1 |
+---------+----------+--------+-----+------+------+nested StructType
# nested StructType
structureData = [
(("James","","Smith"),"36636","M",3100),
(("Michael","Rose",""),"40288","M",4300),
(("Robert","","Williams"),"42114","M",1400),
(("Maria","Anne","Jones"),"39192","F",5500),
(("Jen","Mary","Brown"),"","F",-1)
]
structureSchema = StructType([
StructField('name', StructType([
StructField('firstname', StringType(), True),
StructField('middlename', StringType(), True),
StructField('lastname', StringType(), True)
])),
StructField('id', StringType(), True),
StructField('gender', StringType(), True),
StructField('salary', IntegerType(), True)
])
df2 = spark.createDataFrame(data=structureData,schema=structureSchema)
df2.printSchema()
df2.show(truncate=False)
+--------------------+-----+------+------+
|name |id |gender|salary|
+--------------------+-----+------+------+
|[James, , Smith] |36636|M |3100 |
|[Michael, Rose, ] |40288|M |4300 |
|[Robert, , Williams]|42114|M |1400 |
|[Maria, Anne, Jones]|39192|F |5500 |
|[Jen, Mary, Brown] | |F |-1 |
+--------------------+-----+------+------+transform ( )
transform ( )
+----------+----+--------+
|CourseName|fee |discount|
+----------+----+--------+
|Java |4000|5 |
|Python |4600|10 |
|Scala |4100|15 |
|Scala |4500|15 |
|PHP |3000|20 |
+----------+----+--------+
# Custom transformation 1
from pyspark.sql.functions import upper
def to_upper_str_columns(df):
return df.withColumn("CourseName",upper(df.CourseName))
# Custom transformation 2
def reduce_price(df,reduceBy):
return df.withColumn("new_fee",df.fee - reduceBy)
# Custom transformation 3
def apply_discount(df):
return df.withColumn("discounted_fee", \
df.new_fee - (df.new_fee * df.discount) / 100)
# PySpark transform() Usage
df2 = df.transform(to_upper_str_columns) \
.transform(reduce_price,1000) \
.transform(apply_discount)
+----------+----+--------+-------+--------------+
|CourseName| fee|discount|new_fee|discounted_fee|
+----------+----+--------+-------+--------------+
| JAVA|4000| 5| 3000| 2850.0|
| PYTHON|4600| 10| 3600| 3240.0|
| SCALA|4100| 15| 3100| 2635.0|
| SCALA|4500| 15| 3500| 2975.0|
| PHP|3000| 20| 2000| 1600.0|
+----------+----+--------+-------+--------------+
UDF
UDF (User Defined Function)
+-----+------------+
|Seqno|Name |
+-----+------------+
|1 |john jones |
|2 |tracey smith|
|3 |amy sanders |
+-----+------------+
#create a python function
def convertCase(str):
resStr=""
arr = str.split(" ")
for x in arr:
resStr= resStr + x[0:1].upper() + x[1:len(x)] + " "
return resStr
#Convert a Python function to PySpark UDF
from pyspark.sql.functions import col, udf
from pyspark.sql.types import StringType
convertUDF = udf(lambda z: convertCase(z),StringType())
or
convertUDF = udf(convertCase,StringType())
+-----+-------------+
|Seqno|Name |
+-----+-------------+
|1 |John Jones |
|2 |Tracey Smith |
|3 |Amy Sanders |
+-----+-------------+Registering PySpark UDF & use it on SQL
In order to use convertCase() function on PySpark SQL, you need to register the function with PySpark by using spark.udf.register().
spark.udf.register("convertUDF", convertCase,StringType())
df.createOrReplaceTempView("NAME_TABLE")
spark.sql("select Seqno, convertUDF(Name) as Name from NAME_TABLE") \
.show(truncate=False)
+-----+-------------+
|Seqno|Name |
+-----+-------------+
|1 |John Jones |
|2 |Tracey Smith |
|3 |Amy Sanders |
+-----+-------------+union ( ) & unionAll ( )
union ( ) & unionAll ( ) are the same result. unionAll is older, retired
df1
+-------------+----------+-----+------+---+-----+
|employee_name|department|state|salary|age|bonus|
+-------------+----------+-----+------+---+-----+
|James |Sales |NY |90000 |34 |10000|
|Michael |Sales |NY |86000 |56 |20000|
|Robert |Sales |CA |81000 |30 |23000|
|Maria |Finance |CA |90000 |24 |23000|
+-------------+----------+-----+------+---+-----+
df2
+-------------+----------+-----+------+---+-----+
|employee_name|department|state|salary|age|bonus|
+-------------+----------+-----+------+---+-----+
|James |Sales |NY |90000 |34 |10000|
|Maria |Finance |CA |90000 |24 |23000|
|Jen |Finance |NY |79000 |53 |15000|
|Jeff |Marketing |CA |80000 |25 |18000|
|Kumar |Marketing |NY |91000 |50 |21000|
+-------------+----------+-----+------+---+-----+
df.union(df2).show()
+-------------+----------+-----+------+---+-----+
|employee_name|department|state|salary|age|bonus|
+-------------+----------+-----+------+---+-----+
|James |Sales |NY |90000 |34 |10000|
|Michael |Sales |NY |86000 |56 |20000|
|Robert |Sales |CA |81000 |30 |23000|
|Maria |Finance |CA |90000 |24 |23000|
|James |Sales |NY |90000 |34 |10000|<--duplicated
|Maria |Finance |CA |90000 |24 |23000|<--duplicated
|Jen |Finance |NY |79000 |53 |15000|
|Jeff |Marketing |CA |80000 |25 |18000|
|Kumar |Marketing |NY |91000 |50 |21000|
+-------------+----------+-----+------+---+-----+unionByName ( )
df1.unionByName(df2, allowMissingColumns=Ture)
the schemas and order can be different in df1 and df2
df1
+-------+---+
| name| id|
+-------+---+
| James| 34|
|Michael| 56|
| Robert| 30|
| Maria| 24|
+-------+---+
df2
+---+-----+
| id| name|
+---+-----+
| 34|James|
| 45|Maria|
| 45| Jen|
| 34| Jeff|
+---+-----+
# different columns order
df3 = df1.unionByName(df2)
+-------+---+
| name| id|
+-------+---+
| James| 34|
|Michael| 56|
| Robert| 30|
| Maria| 24|
| James| 34|
| Maria| 45|
| Jen| 45|
| Jeff| 34|
+-------+---+# different columns name and order
+----+----+----+
|col0|col1|col2|
+----+----+----+
| 5| 2| 6|
+----+----+----+
+----+----+----+
|col1|col2|col3|
+----+----+----+
| 6| 7| 3|
+----+----+----+
df3=df1.unionByName(df2, allowMissingColumns=True).show()
+----+----+----+----+
|col0|col1|col2|col3|
+----+----+----+----+
| 5| 2| 6|null|
|null| 6| 7| 3|
+----+----+----+----+where() & filter()
where() & filter() can replace each other
- Use
&,|,~for logical operations (AND,OR,NOT). - Use
==,!=,>,<,>=,<=for comparisons. - Always wrap column references in
col()for clarity. - For SQL-like patterns, consider using functions like
like,isin, andbetween. - IS NULL –> “isNull ( )”
- IS NOT NULL –> “isNotNull ( )”
- LIKE –> “like ( %abc% )”
- IN –> “isin (18, 21, 25)”
- BETWEEN –> “between(18, 25)”
+----------------------+------------------+-----+------+
|name |languages |state|gender|
+----------------------+------------------+-----+------+
|{James, , Smith} |[Java, Scala, C++]|OH |M |
|{Anna, Rose, } |[Spark, Java, C++]|NY |F |
|{Julia, , Williams} |[CSharp, VB] |OH |F |
|{Maria, Anne, Jones} |[CSharp, VB] |NY |M |
|{Jen, Mary, Brown} |[CSharp, VB] |NY |M |
|{Mike, Mary, Williams}|[Python, VB] |OH |M |
+----------------------+------------------+-----+------+
df.select("gender").filter(df.gender == "M").show()
df.select("gender").where(df.gender == "F").show()
+------+
|gender|
+------+
| M|
| M|
| M|
| M|
+------+
+------+
|gender|
+------+
| F|
| F|
+------+withColumn()
from pyspark.sql.functions import date_add, col
df.withColumn("dob", date_add("dob", 10)).\
withColumn("newsalary",col("salary")*100).\
drop("middlename").show()
+---------+--------+----------+------+------+---------+
|firstname|lastname| dob|gender|salary|newsalary|
+---------+--------+----------+------+------+---------+
| James| Smith|1991-04-11| M| 300| 30000|
| Michael| |2000-05-29| M| 400| 40000|
| Robert|Williams|1978-09-15| M| 400| 40000|
| Maria| Jones|1967-12-11| F| 400| 40000|
| Jen| Brown|1980-02-27| F| -1| -100|
+---------+--------+----------+------+------+---------+withColumnRenamed ( )
withColumnRenamed() rename a DataFrame column, we often need to rename one column or multiple (or all) columns on PySpark DataFrame
+--------------------+----------+------+------+
| name| dob|gender|salary|
+--------------------+----------+------+------+
| {James, , Smith}|1991-04-01| M| 3000|
| {Michael, Rose, }|2000-05-19| M| 4000|
|{Robert, , Williams}|1978-09-05| M| 4000|
|{Maria, Anne, Jones}|1967-12-01| F| 4000|
| {Jen, Mary, Brown}|1980-02-17| F| -1|
+--------------------+----------+------+------+
df2 = df.withColumnRenamed("dob","DateOfBirth") \
.withColumnRenamed("salary","salary_amount")
df2.show()
+--------------------+-----------+------+-------------+
| name|DateOfBirth|gender|salary_amount|
+--------------------+-----------+------+-------------+
| {James, , Smith}| 1991-04-01| M| 3000|
| {Michael, Rose, }| 2000-05-19| M| 4000|
|{Robert, , Williams}| 1978-09-05| M| 4000|
|{Maria, Anne, Jones}| 1967-12-01| F| 4000|
| {Jen, Mary, Brown}| 1980-02-17| F| -1|
+--------------------+-----------+------+-------------+Please do not hesitate to contact me if you have any questions at William . chen @ mainri.ca
(remove all space from the email account 😊)