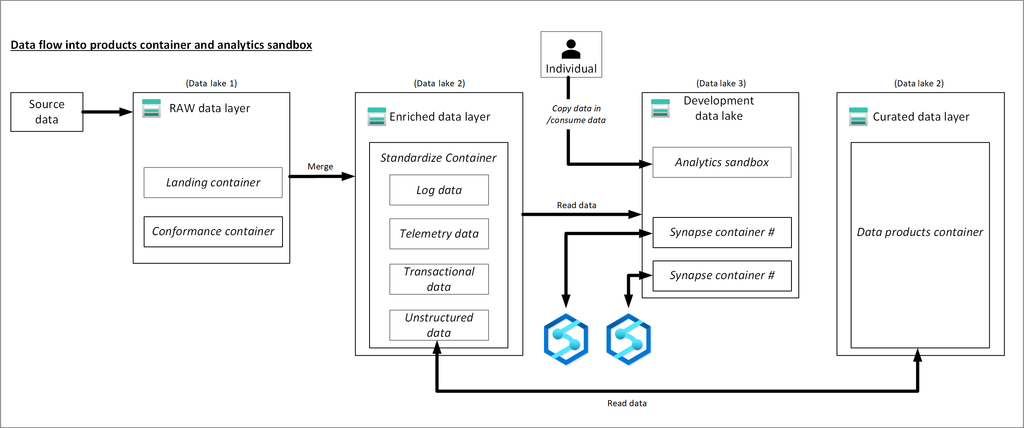
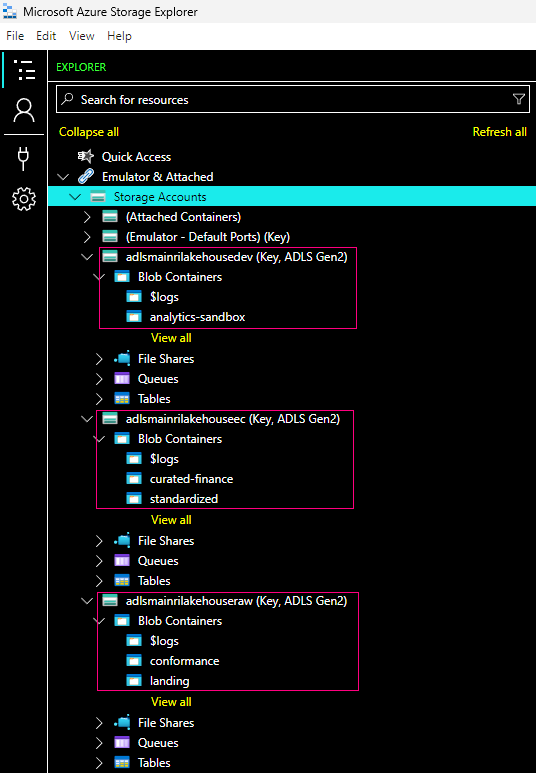
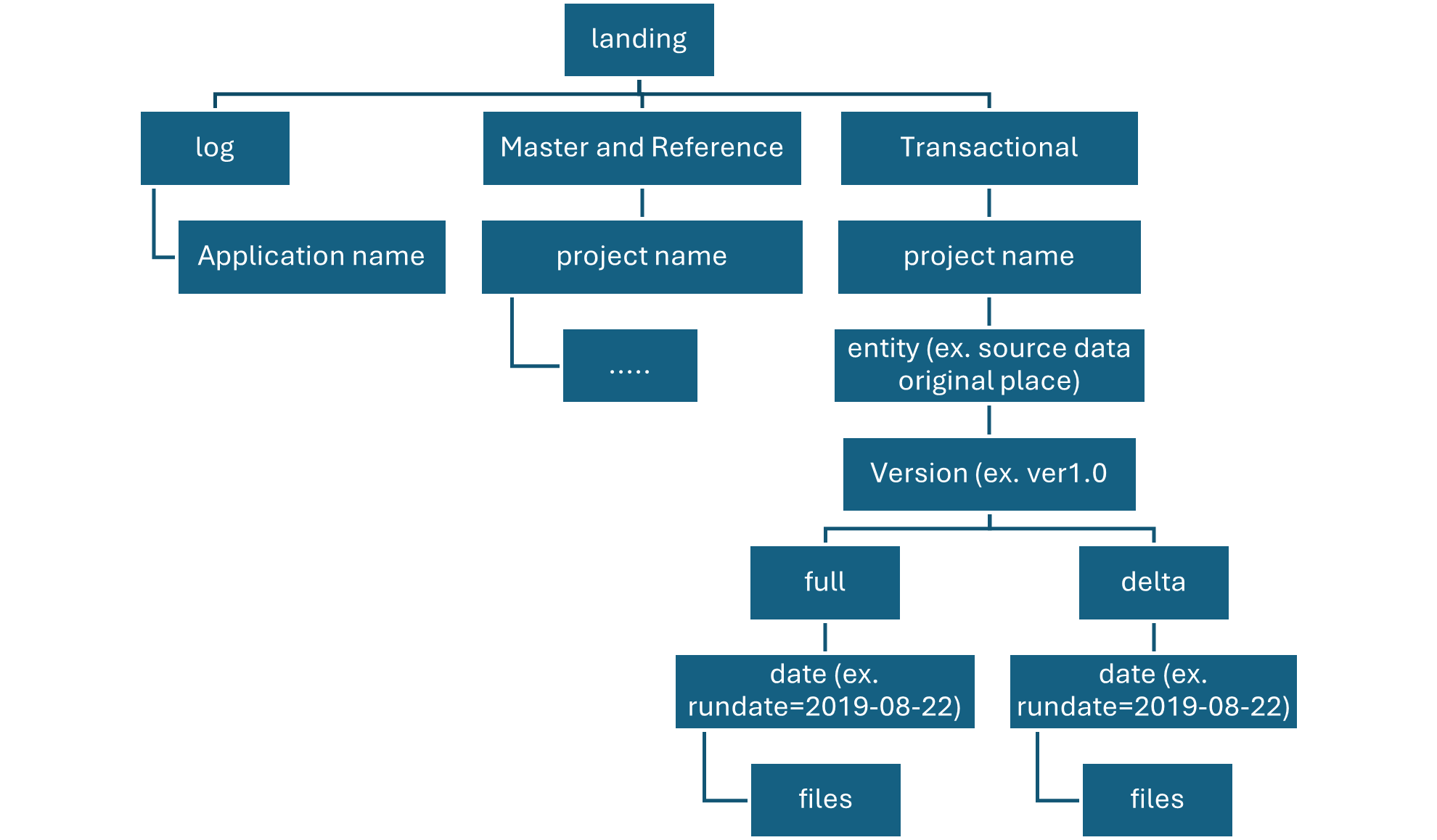
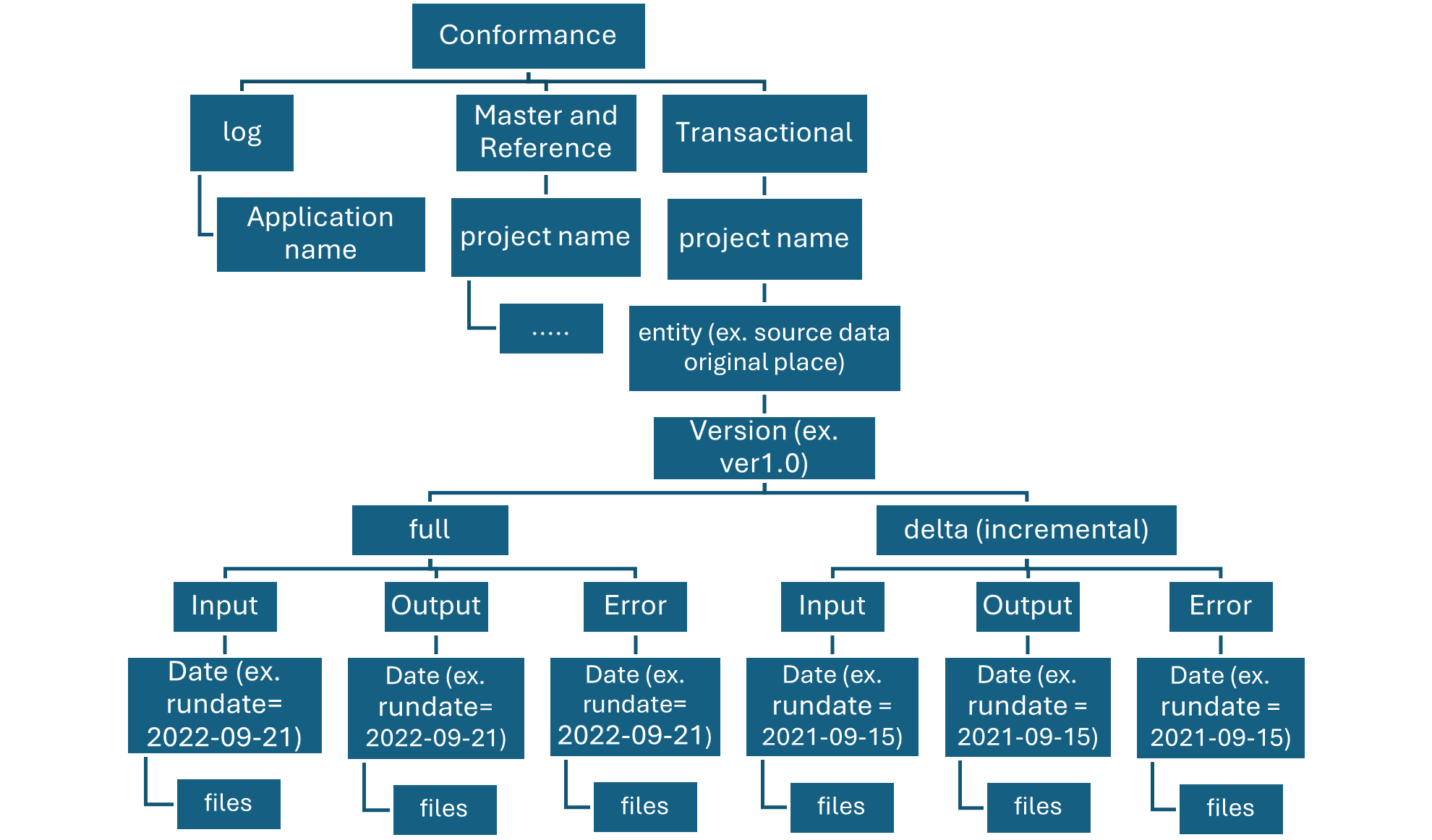
A Delta table is a type of table that builds on the Delta Lake storage layer and brings ACID (Atomicity, Consistency, Isolation, Durability) transactions, schema enforcement, and scalable metadata management to traditional data lakes. It is designed for large-scale, reliable data processing and analytics. Delta tables enable you to manage both batch and streaming data with ease, and they are ideal for environments where data integrity and consistency are critical, such as in data lakes, data warehouses, and machine learning pipelines.
What is Delta Lake
Delta lake is an open-source technology, we use Delta Lake to store data in Delta tables. Delta lake improves data storage by supporting ACID transactions, high-performance query optimizations, schema evolution, data versioning and many other features.
| Feature | Traditional Data Lakes | Delta Lake |
| Transaction Support | No ACID transactions | Full ACID support |
| Data Consistency | Weak guarantees | Strong guarantees with serializable isolation |
| Schema Enforcement | None | Enforced and allows schema evolution |
| Handling Streaming | Requires separate infrastructure | Unified batch and streaming |
| Data Management | Prone to issues like data corruption | Reliable with audit trails and versioning |
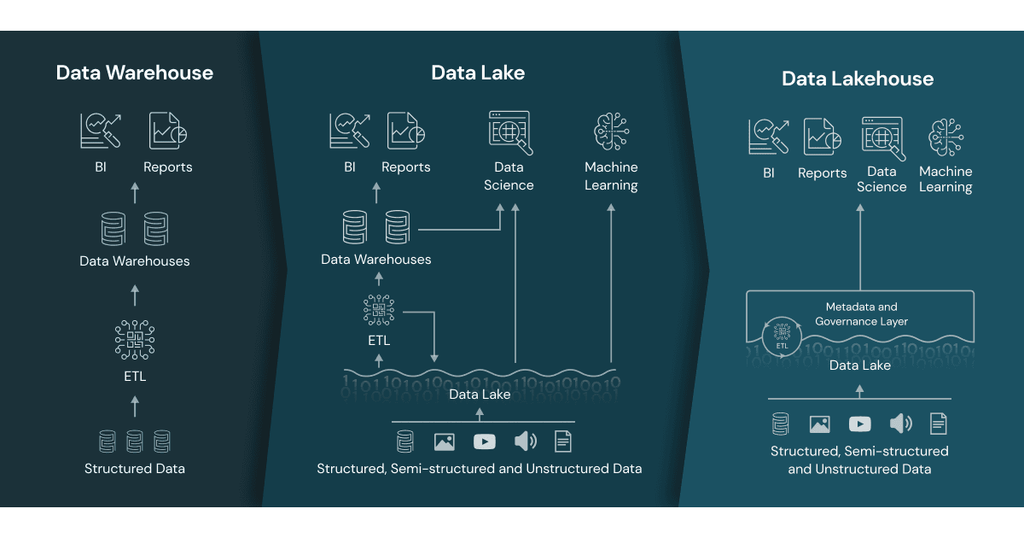
There is detail information at “Data lake vs delta lake vs data lakehouse, and data warehouses comparison”
Key Features of Delta Tables
- ACID Transactions: Delta Lake ensures that operations like reads, writes, and updates are atomic, consistent, isolated, and durable, eliminating issues of partial writes and data corruption.
- Schema Enforcement: When writing data, Delta ensures that it matches the table’s schema, preventing incorrect or incomplete data from being written.
- Time Travel: Delta tables store previous versions of the data, which allows you to query, rollback, and audit historical data (also known as data versioning).
- Unified Streaming and Batch Processing: Delta tables allow you to ingest both batch and streaming data, enabling you to work seamlessly with either approach without complex rewrites.
- Efficient Data Upserts: You can perform
MERGEoperations (UPSERTS) efficiently, which is especially useful in scenarios where you need to insert or update data based on certain conditions. - Optimized Performance: Delta Lake supports optimizations such as data skipping, Z-order clustering, and auto-compaction, improving query performance.
Creating and Using Delta Tables in PySpark or SQL
create a Delta table by writing a DataFrame in PySpark or SQL.
Create or Write a DataFrame to a Delta table
If we directly query delta table from adls using SQL, always use
--back single quotation mark `
delta.`abfss://contain@account.dfs.windows.net/path_and_table`
# python
# Write a DataFrame to a Delta table
df.write.format("delta").save("/mnt/delta/my_delta_table")
# sql
-- Creating a Delta Table
CREATE TABLE my_delta_table
USING delta
LOCATION '/mnt/delta/my_delta_table';
# sql
-- Insert data
INSERT INTO my_delta_table VALUES (1, 'John Doe'), (2,
'Jane Doe');
Reading from a Delta table
#python
delta_df = spark.read.format("delta").load("/mnt/delta/my_delta_table")
delta_df.show()
#sql
-- Query Delta table
SELECT * FROM my_delta_table;
-- directly query delta table from adls.
-- use ` back single quotation mark
SELECT *
FROM
delta.`abfss://adlsContainer@adlsAccount.dfs.windows.net/Path_and_TableName`
VERSION AS OF 4;
Managing Delta Tables
Optimizing Delta Tables
To improve performance, you can run an optimize operation to compact small files into larger ones.
# sql
OPTIMIZE my_delta_table;
Z-order Clustering
Z-order clustering is used to improve query performance by colocating related data in the same set of files. it is a technique used in Delta Lake (and other databases) to optimize data layout for faster query performance.
# sql
OPTIMIZE my_delta_table ZORDER BY (date);
Upserts (Merge)
Delta Lake makes it easy to perform Upserts (MERGE operation), which allows you to insert or update data in your tables based on certain conditions.
# sql
MERGE INTO my_delta_table t
USING new_data n
ON t.id = n.id
WHEN MATCHED THEN UPDATE SET t.value = n.value
WHEN NOT MATCHED THEN INSERT (id, value) VALUES (n.id, n.value);
Conclusion
Delta Lake is a powerful solution for building reliable, high-performance data pipelines on top of data lakes. It enables advanced data management and analytics capabilities with features like ACID transactions, time travel, and schema enforcement, making it an ideal choice for large-scale, data-driven applications.
Delta tables are essential for maintaining high-quality, reliable, and performant data processing pipelines. They provide a way to bring transactional integrity and powerful performance optimizations to large-scale data lakes, enabling unified data processing for both batch and streaming use cases.
Please do not hesitate to contact me if you have any questions at William . chen @ mainri.ca
(remove all space from the email account 😊)