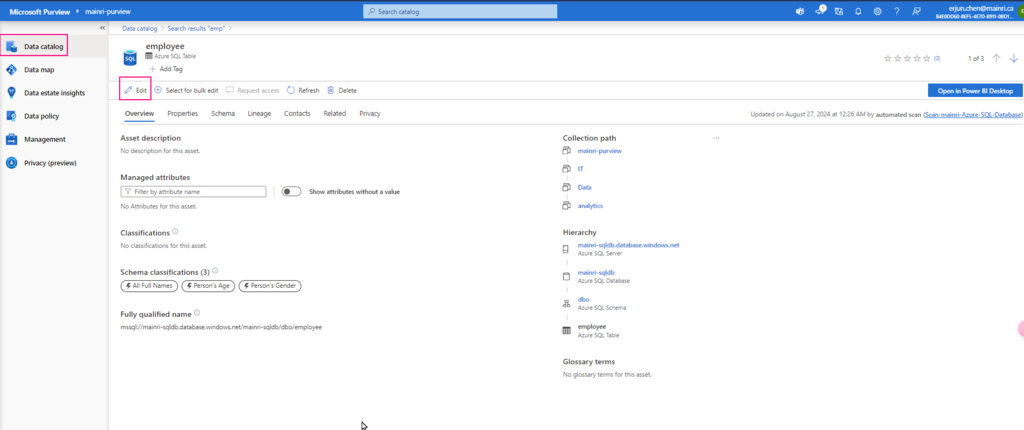
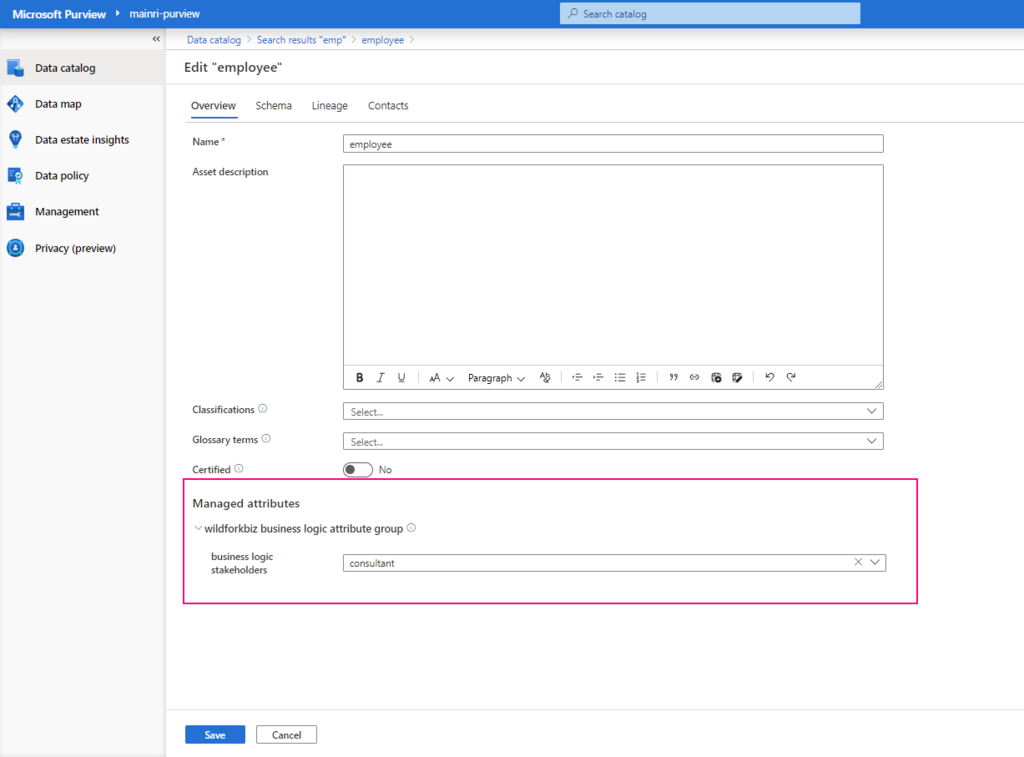
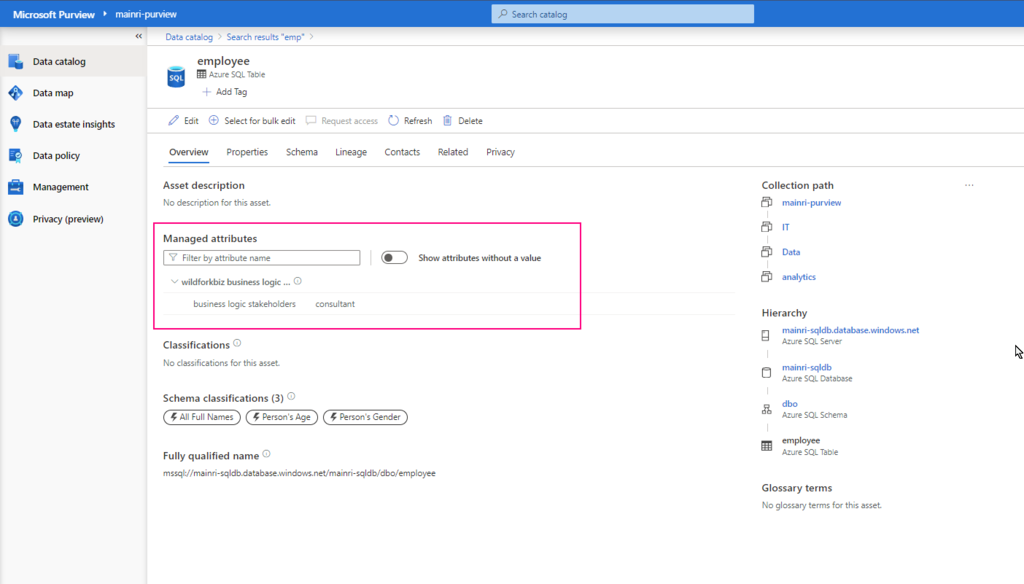
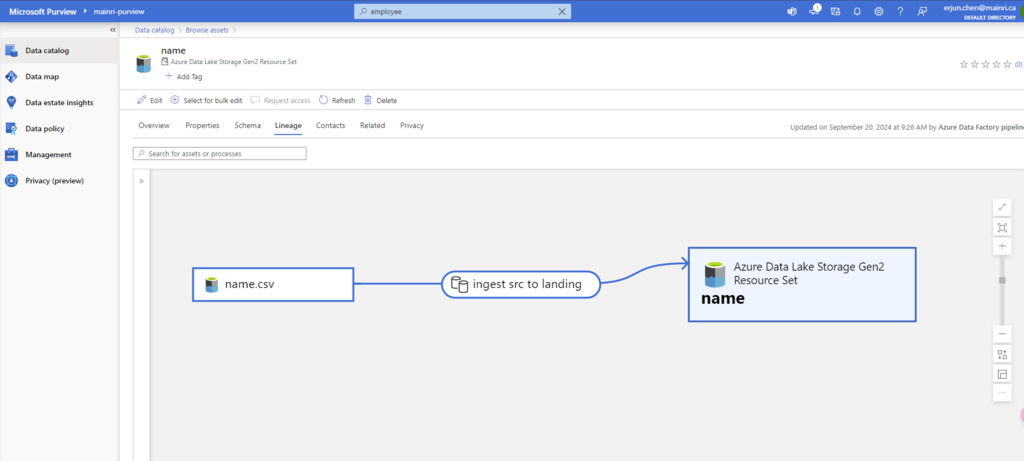
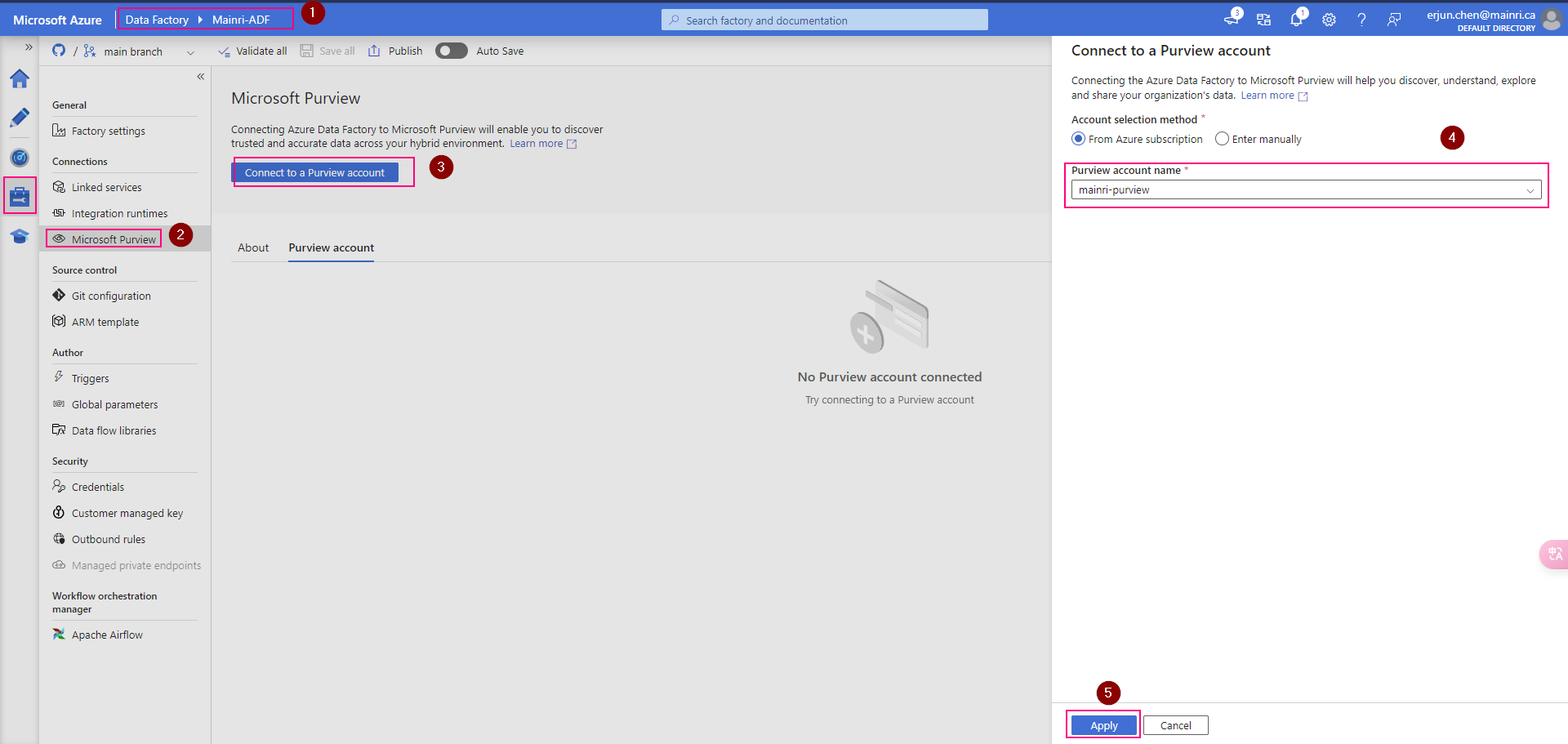
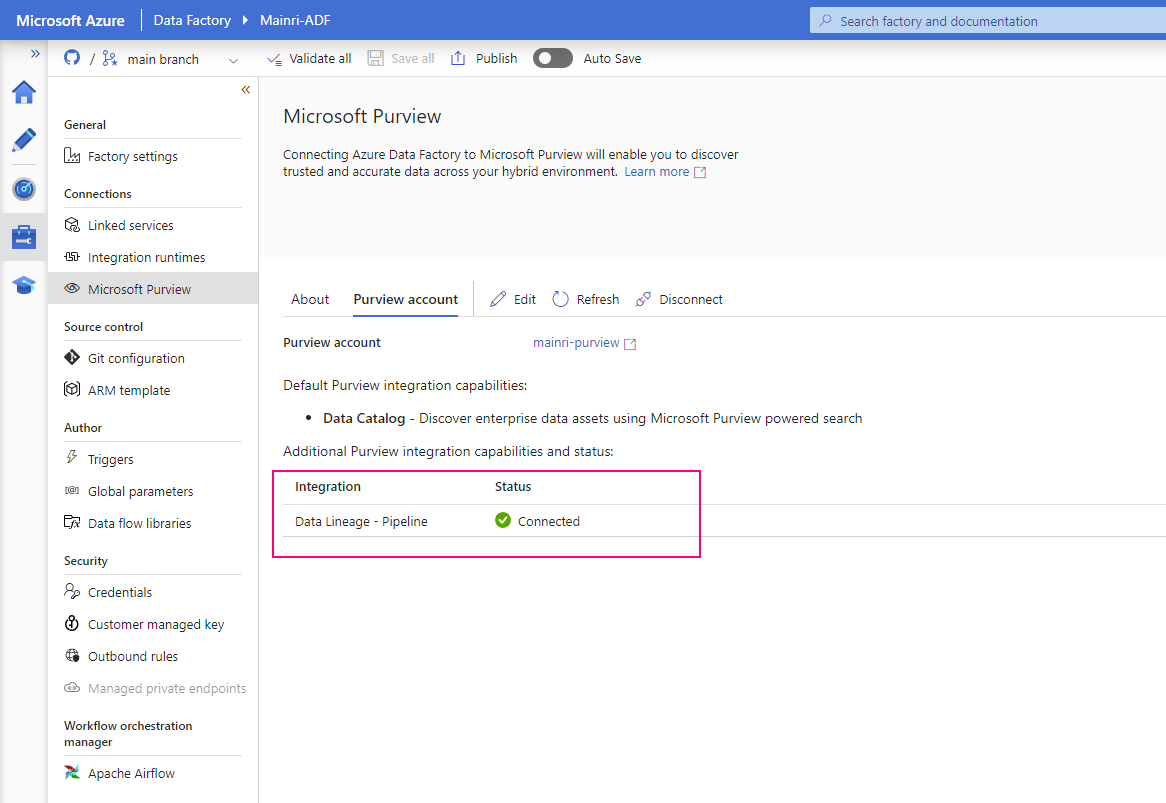
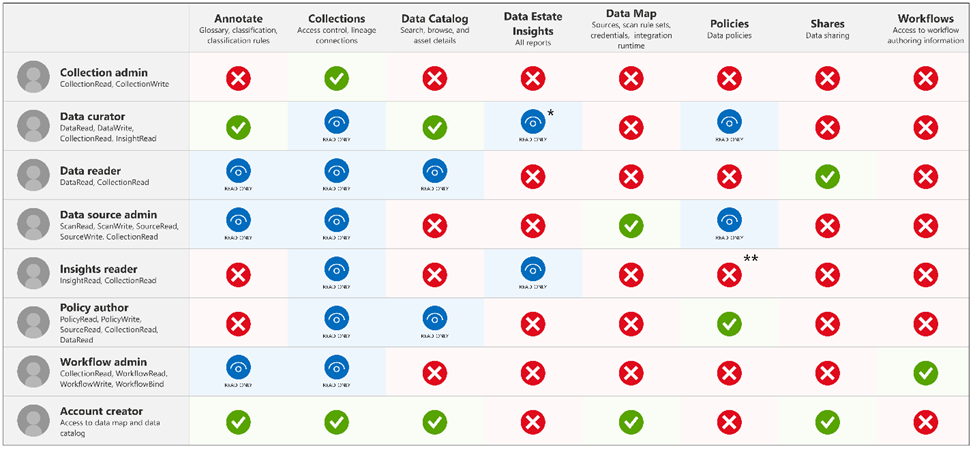
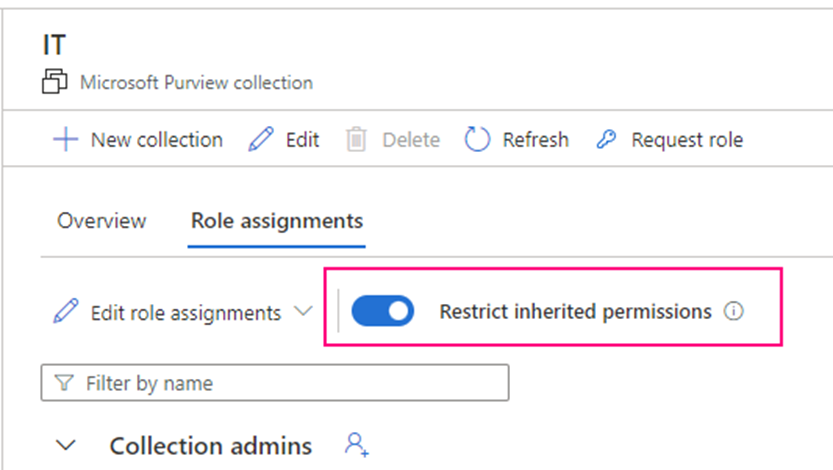
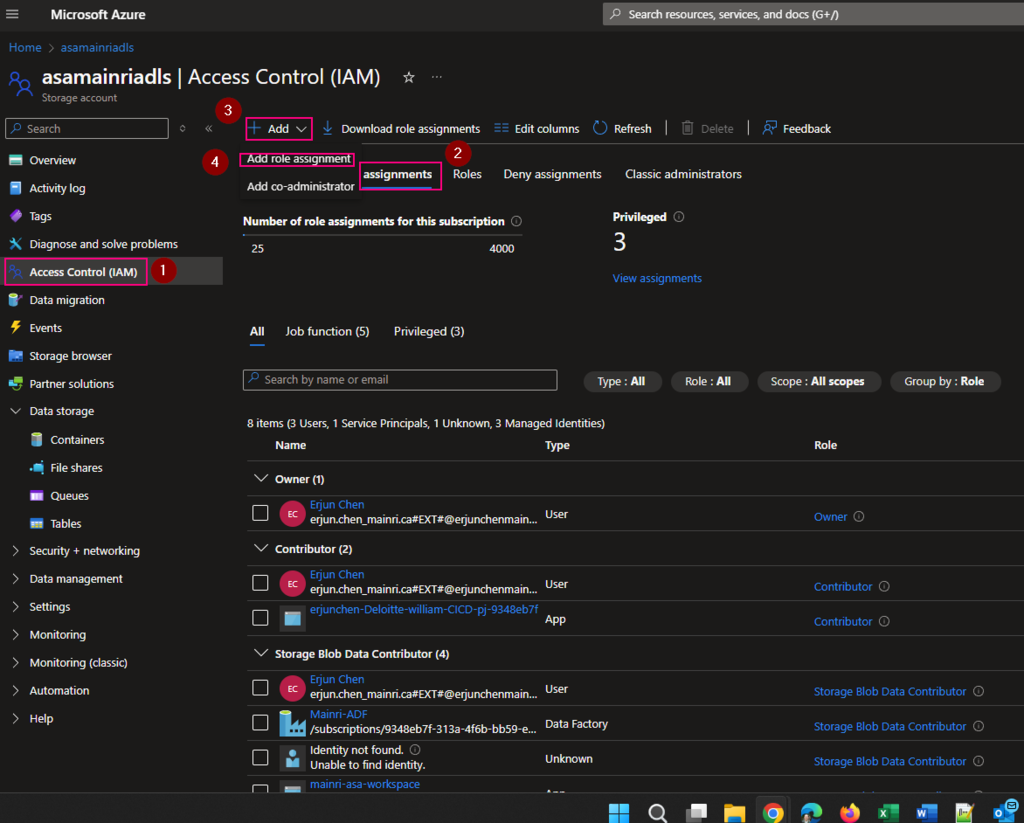
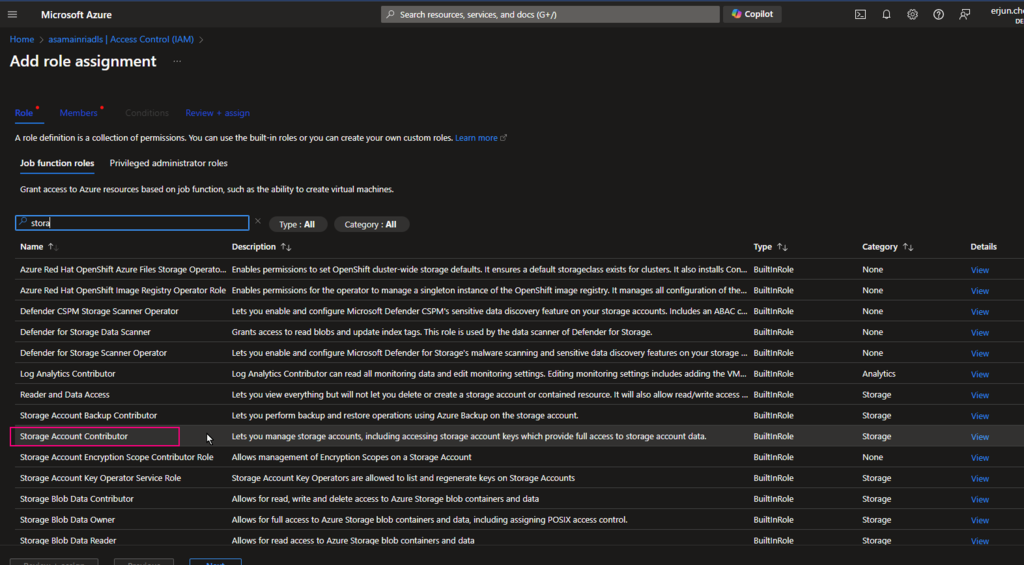
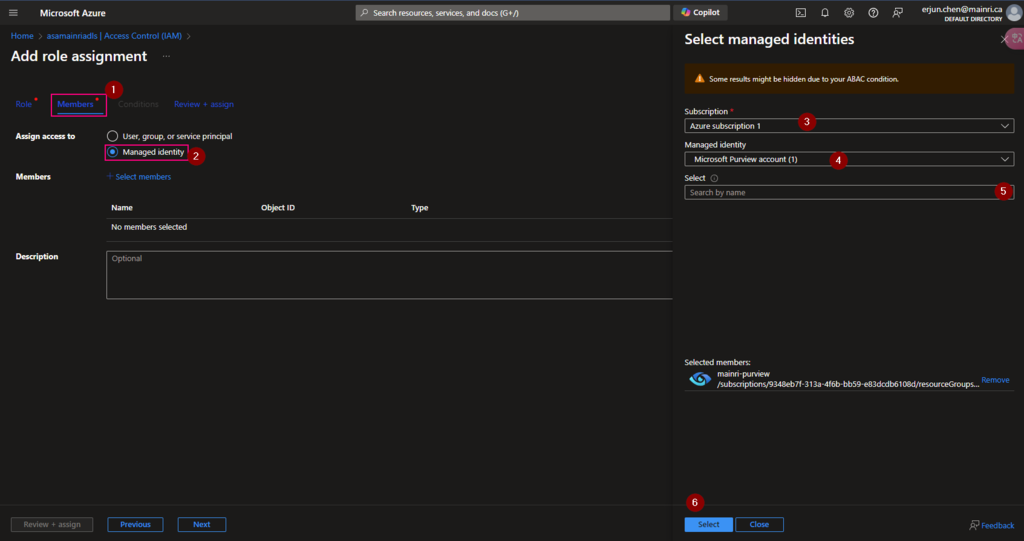
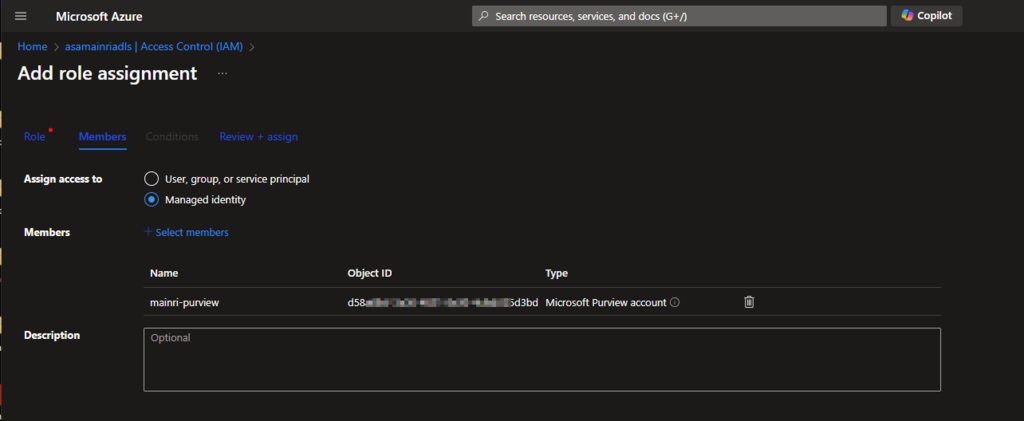
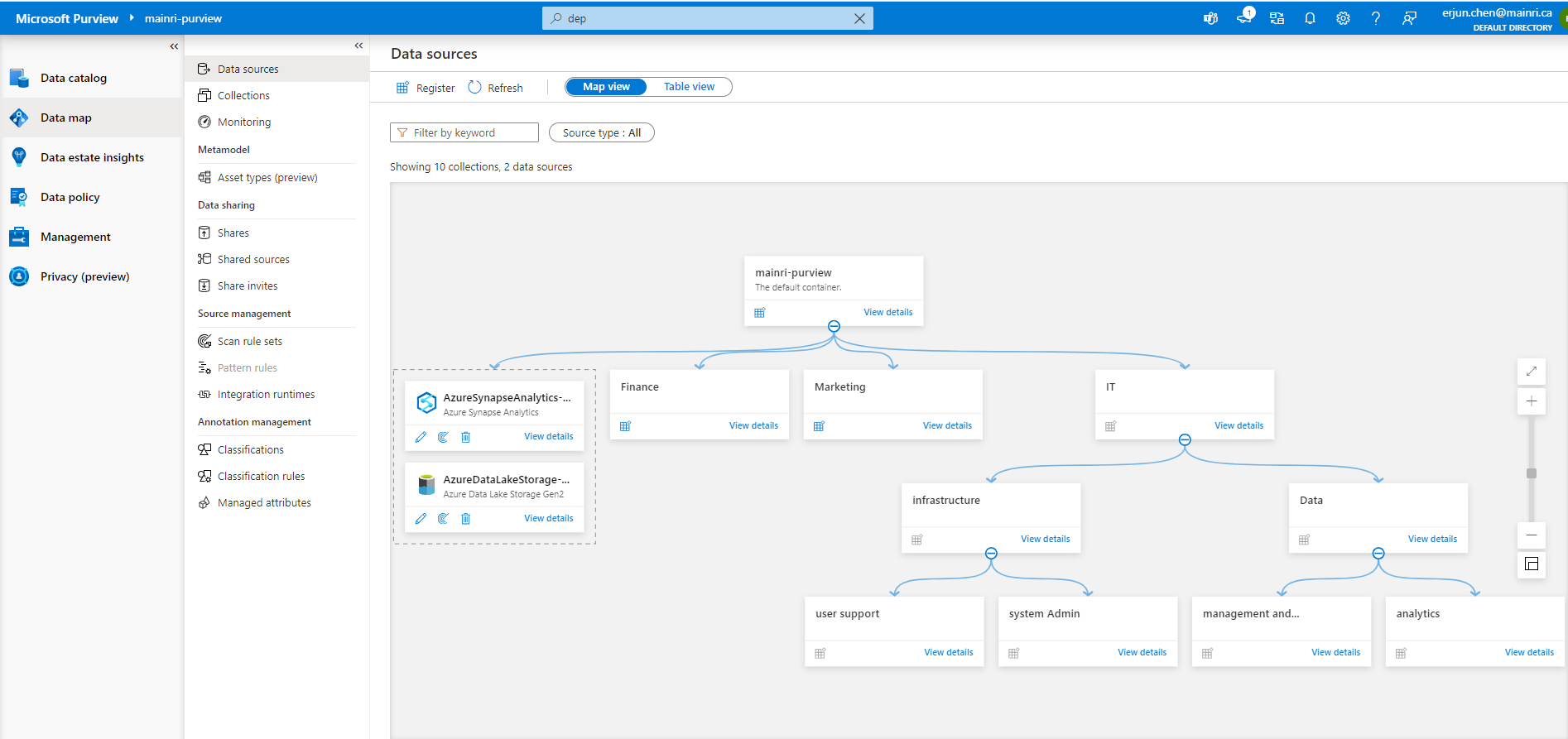
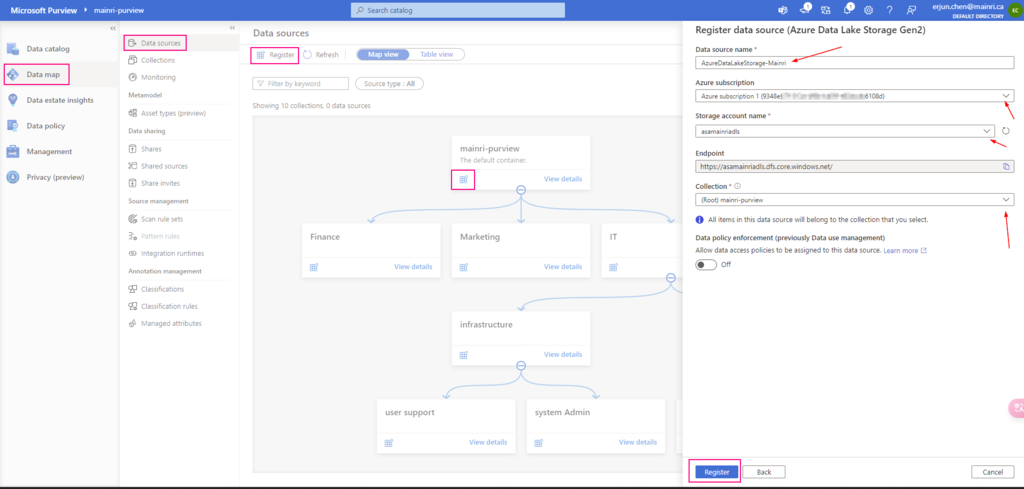
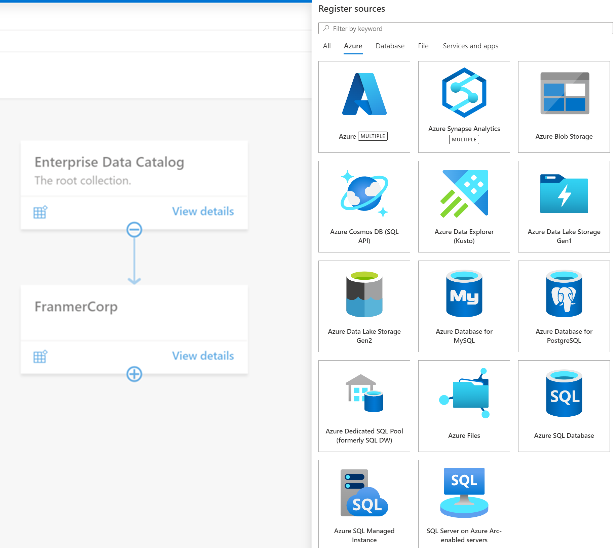
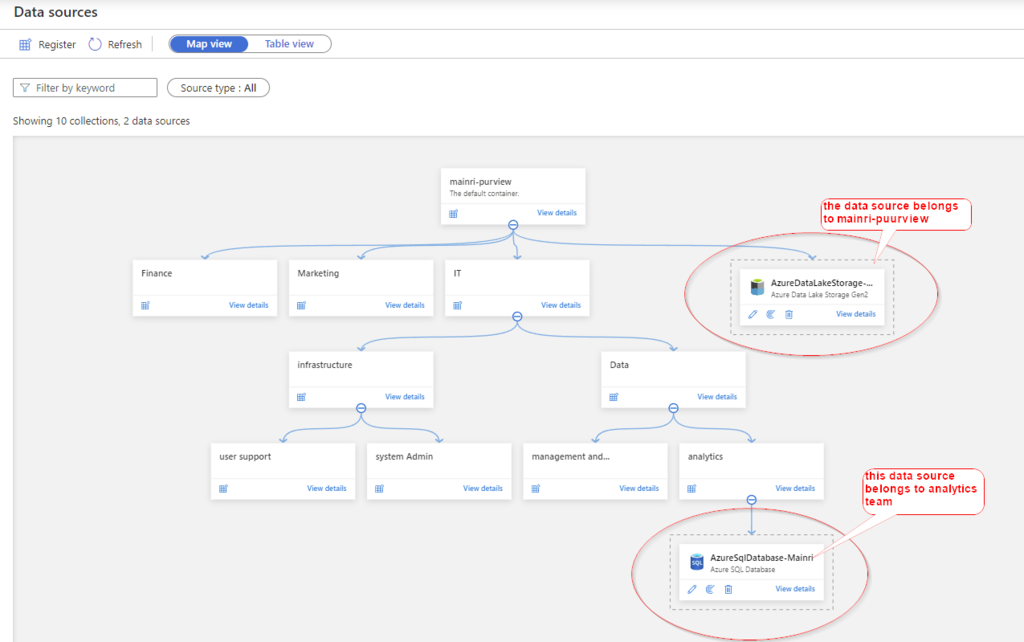
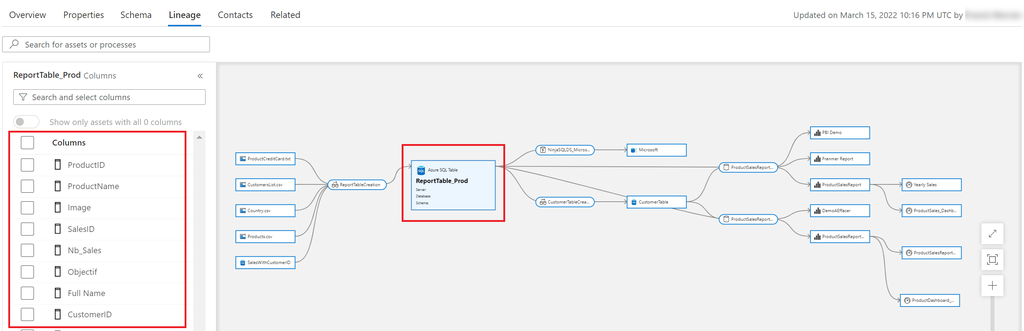
Hive Metastore: A traditional metadata store mainly used in Hadoop and Spark ecosystems. It’s good for managing tables and schemas, but lacks advanced governance, security, and multi-tenant capabilities.
Unity Catalog Metastore: Databricks’ modern, cloud-native metastore designed for multi-cloud and multi-tenant environments. It has advanced governance, auditing, and fine-grained access control features integrated with Azure, AWS, and GCP.
General Metastore: Refers to any metadata storage system used to manage table and schema definitions. The implementation and features can vary, but it often lacks the governance and security features found in Unity Catalog.
Side by side comparison
Here’s a side-by-side comparison of the Hive Metastore, Unity Catalog Metastore, and a general Metastore:
| Feature | Hive Metastore | Unity Catalog Metastore | General Metastore (Concept) |
| Purpose | Manages metadata for Hive tables, typically used in Hadoop/Spark environments. | Manages metadata across multiple workspaces with enhanced security and governance in Databricks. | A general database that stores metadata about databases, tables, schemas, and data locations. |
| Integration Scope | Mainly tied to Spark, Hadoop, and Hive ecosystems. | Native to Databricks and integrates with cloud storage (Azure, AWS, GCP). | Can be used by different processing engines (e.g., Hive, Presto, Spark) based on the implementation. |
| Access Control | Limited. Generally relies on external systems like Ranger or Sentry for fine-grained access control. | Fine-grained access control at the column, table, and catalog levels via Databricks and Entra ID integration. | Depends on the implementation—typically role-based, but not as granular as Unity Catalog. |
| Catalogs Support | Not supported. Catalogs are not natively part of the Hive Metastore architecture. | Supports multiple catalogs, which are logical collections of databases or schemas. | Catalogs are a newer feature, generally not part of traditional Metastore setups. |
| Multitenancy | Single-tenant, tied to one Spark cluster or instance. | Multi-tenant across Databricks workspaces, providing unified governance across environments. | Can be single or multi-tenant depending on the architecture. |
| Metadata Storage Location | Typically stored in a relational database (MySQL, Postgres, etc.). | Stored in the cloud and managed by Databricks, with integration to Azure Data Lake, AWS S3, etc. | Varies. Could be stored in RDBMS, cloud storage, or other systems depending on the implementation. |
| Governance & Auditing | Limited governance capabilities. External tools like Apache Ranger may be needed for auditing. | Built-in governance and auditing features with lineage tracking, access logs, and integration with Azure Purview. | Governance features are not consistent across implementations. Often relies on external tools. |
| Data Lineage | Requires external tools for lineage tracking (e.g., Apache Atlas, Cloudera Navigator). | Native support for data lineage and governance through Unity Catalog and Azure Purview. | Data lineage is not typically part of a standard metastore and requires integration with other tools. |
| Schema Evolution Support | Supported but basic. Schema changes can cause issues in downstream applications. | Schema evolution is supported with versioning and governance controls in Unity Catalog. | Varies depending on implementation—generally more manual. |
| Cloud Integration | Usually requires manual setup for cloud storage access (e.g., Azure Data Lake, AWS S3). | Natively integrates with cloud storage like Azure, AWS, and GCP, simplifying external location management. | Cloud integration support varies based on the system, but it often requires additional configuration. |
| Auditing and Compliance | Requires external systems for compliance. Auditing capabilities are minimal. | Native auditing and compliance capabilities, with integration to Microsoft Entra ID and Azure Purview. | Depends on implementation—auditing may require third-party tools. |
| Cost | Lower cost, typically open source. | Managed and more feature-rich, but can have additional costs as part of Databricks Premium tier. | Varies depending on the technology used. Often incurs cost for storage and external tools. |
| Performance | Good performance for traditional on-prem and Hadoop-based setups. | High performance with cloud-native optimizations and scalable architecture across workspaces. | Performance depends on the system and how it’s deployed (on-prem vs. cloud). |
| User and Role Management | Relies on external tools for user and role management (e.g., Apache Ranger). | Native role-based access control (RBAC) with integration to Microsoft Entra ID for identity management. | User and role management can vary significantly based on the implementation. |