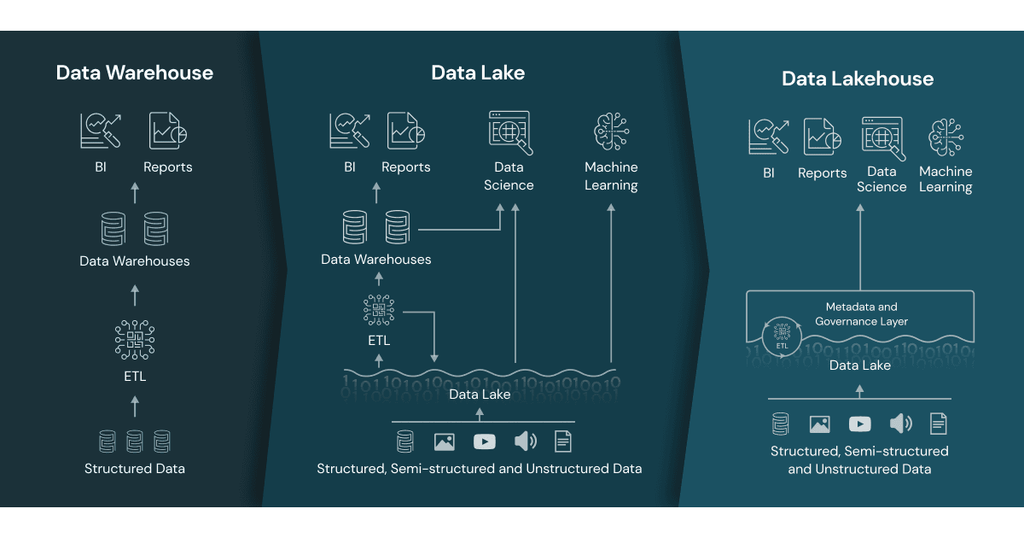
The term “Medallion Data Architecture” was first called by databricks. It is a data design pattern used to logically organize data in a lakehouse. It describes data at different stages of processing as being “bronze,” “silver” or “gold” level data. with the goal of incrementally and progressively improving the structure and quality of data as it flows through each layer of the architecture.
Bronze ⇒ Silver ⇒ Gold layer tables
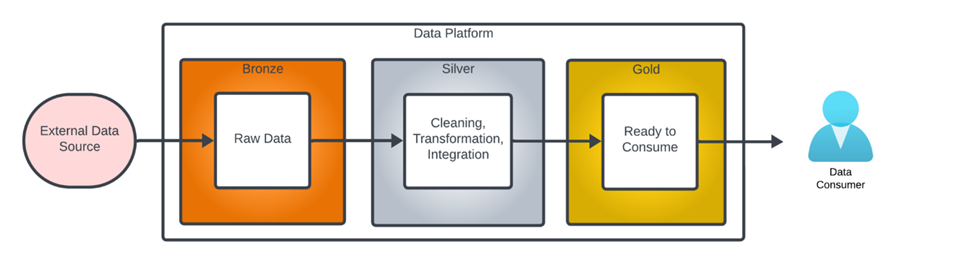
Bronze data refers to data in its unprocessed state, exactly as loaded from the data source.
Silver data refers to data at various stages of intermediate processing.
Gold level data is fully cleaned and prepared ready for use by a data consumer.
Bronze zone/layer
Data in bronze is raw, unprocessed data. It acts as a landing zone including structured, semi-structured, and unstructured data. Data in this layer is ingested as-is, it is a copy of the data exactly as it was loaded from the data source. meaning it’s often messy, unclean, and can include duplicates.
If a fault occurs, it allows you to quickly determine if the the problem is related to source data or processing within the data platform.
Gold zone
Sometimes it is also called Curated zone/layer.
Data in this layer is fully cleaned, secured and maybe pre-aggregated data. All data is ready for access. contains highly curated, aggregated. data usually tailored for specific use cases, such as reporting, business intelligence, or machine learning.and often ready-for-consumption data.
Silver Layer (Cleaned Data)
There is layer between the Bronze and Gold layer, it is called Silver Layer. The silver layer is where data is cleaned, transformed, and often enriched. It’s meant to be a more refined version of the bronze layer, ready for further analysis or use in applications. Data in this layer is typically free of duplicates, missing values are handled, and unnecessary data is filtered out. The transformations applied here make the data more structured and reliable.
Why use Medallion Architecture
Many software engineers are familiar the “multiple tiers architecture” in software development. Medallion Architecture has the same meaning “multiple architectures”.
Scalability: The layered approach allows for scaling each part of the data pipeline independently.
Flexibility: It provides flexibility in data processing and the ability to handle different data types and sources.
Data Quality: By progressing data through these layers, the architecture naturally enforces data quality and consistency.
Ease of Use: It simplifies data management by organizing the data into distinct stages, making it easier to understand and manage.
Conclusion
Overall, the Medallion Architecture is a powerful pattern for managing data lifecycle, from raw ingestion to refined, consumable datasets. It often use in data engineering project. such as Data Lakes, Big Data Processing, ETL/ELT Pipelines etc.
Please do not hesitate to contact me if you have any questions at William . chen @mainri.ca
(remove all space from the email account 😊)