There are several ways to connect Azure Data Lake Storage (ADLS) Gen2 or Blob to Databricks. Each method offers different levels of security, flexibility, and complexity. Such as
Mount ADLS to DBFS
Service Principal with OAuth 2.0
Direct access with ABFS URI (Azure Blob File System)
Today we focus on using Service principal with OAuth2.0 to access ADLS or Blob.
Access ADLS Gen2 using Service Principal with OAuth 2.0
To access Azure Data Lake Storage (ADLS) or Blob Storage using a service principal with OAuth2 in Azure Databricks, follow these steps. This approach involves authenticating using a service principal’s credentials, such as the client ID, tenant ID, and client secret.
Previously, we discussed how to create Service Principle, Register an application on Azure Entra ID (former Active Directory), generate client-secret-value. To get client.id and client-secret-value please review this article.
# Define service principal credentials
client_id = "<your-client-id>"
tenant_id = "<your-tenant-id>"
# It's recommended to store the secret securely in a secret scope
client_secret = dbutils.secrets.get(scope = "<scope-name>", key = "<client-secret-key>")
OAuth2 configuration for service principal
# OAuth2 configuration for service principal
configs = {
"fs.azure.account.auth.type": "OAuth",
"fs.azure.account.oauth.provider.type": "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth2.client.id": "<client-id>",
"fs.azure.account.oauth2.client.secret": "<client-secret>",
"fs.azure.account.oauth2.client.endpoint": "https://login.microsoftonline.com/<tenant-id>/oauth2/token"
}
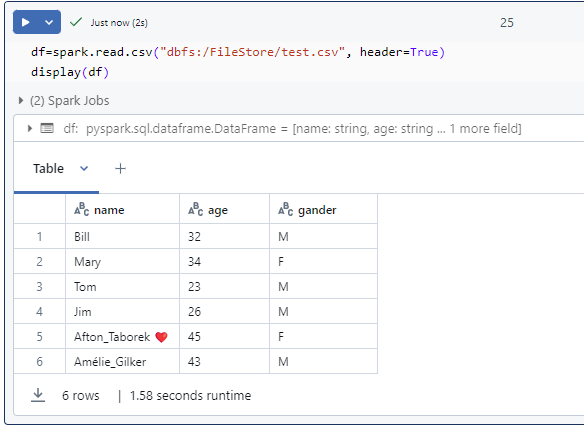
In fact, we are able to directly access to ADLS/blob now.
# in fact, we are able to directly access adls/blob now.
#adls
df = spark.read.csv(f"abfs://{container}@{storage_account_name }.dfs.windows.core.net/input/test.csv")
display(df)
# blob
display(spark.read.csv(f"abfs://{container}@{storage_account_name }.dfs.windows.core.net/input/test.csv"))
Of course, we are able to mount the ADLS to DBFS if we like; but it’s not necessary at this moment for demo.
We can mount Azure Data Lake Storage (ADLS), Azure Blob Storage, or other compatible storage to Databricks using dbutils.fs.mount(), with either an account key or a SAS token for authentication.
Previously, we’ve talked about how Purview connect to ADLS and SQL Database, scan in Purview. Today, we focused on Azure Synapse Analytics with Purview.
A comprehensive data analytics solution can include many folders and files in a data lake, and multiple databases that each contain many tables, each with multiple fields. For a data analyst, finding and understanding the data assets associated with a Synapse Analytics workspace can present a significant challenge before any analysis or reporting can even begin.
As we know the Azure Synapse Analytics is a platform for cloud-scale analytics workloads that process data in multiple sources; including:
Relational databases in serverless and dedicated SQL pools
Files in Azure Data Lake Storage Gen2
Microsoft Purview can help in this scenario by cataloging the data assets in a data map, and enabling data stewards to add metadata, categorization, subject matter contact details, and other information that helps data analysts identify and understand data.
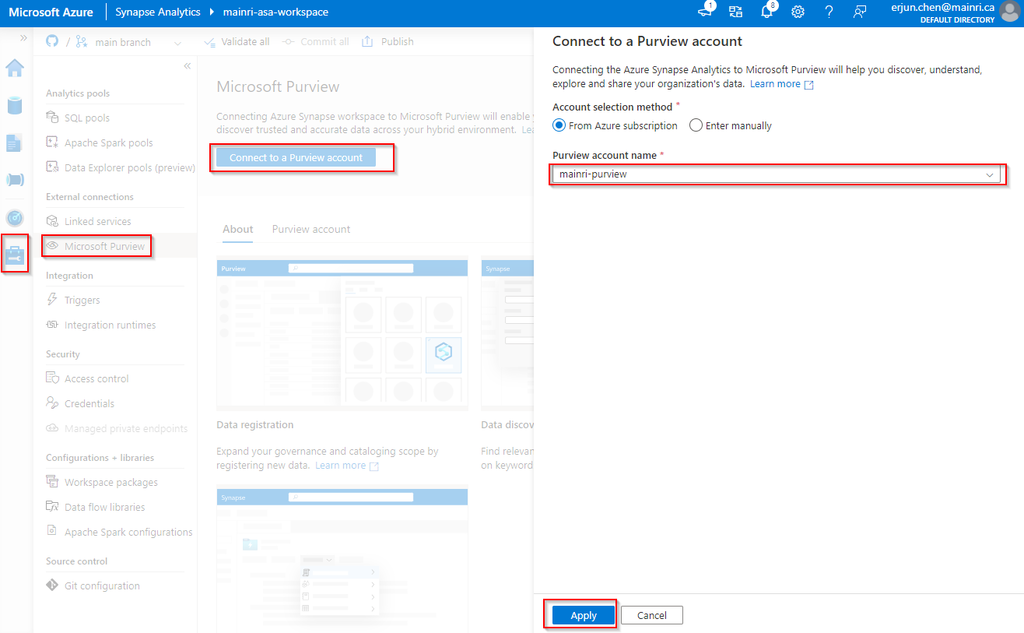
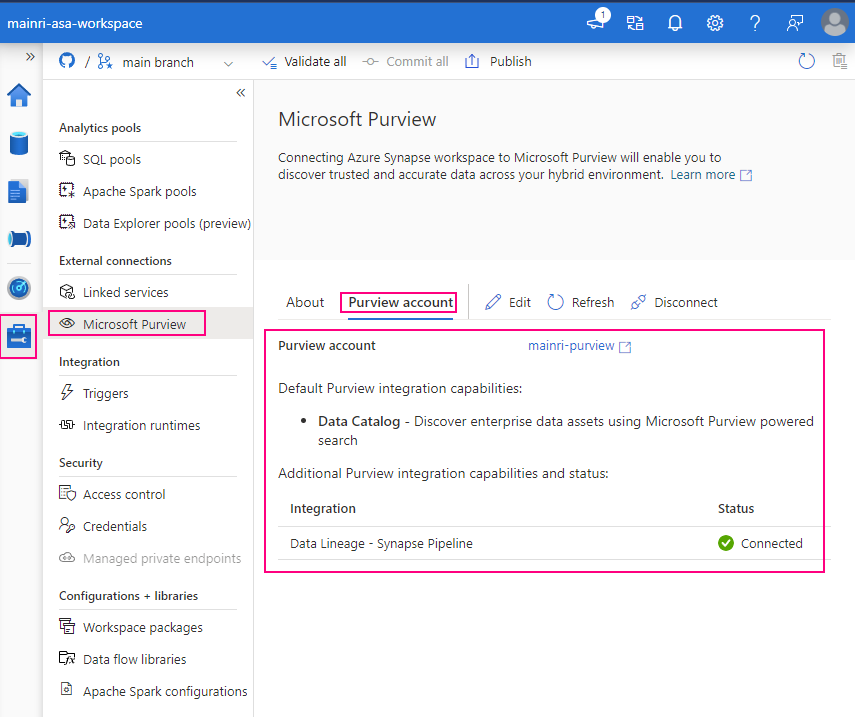
Before you scan Synapse workspace, you need Azure Synapse Analytics connects Purview account.
Azure Synapse Analytics connects to Purview account.
Synapse Studio > Manage > External connection > Microsoft Purview
after you click “apply” you will see:
Select “Purview account” tag
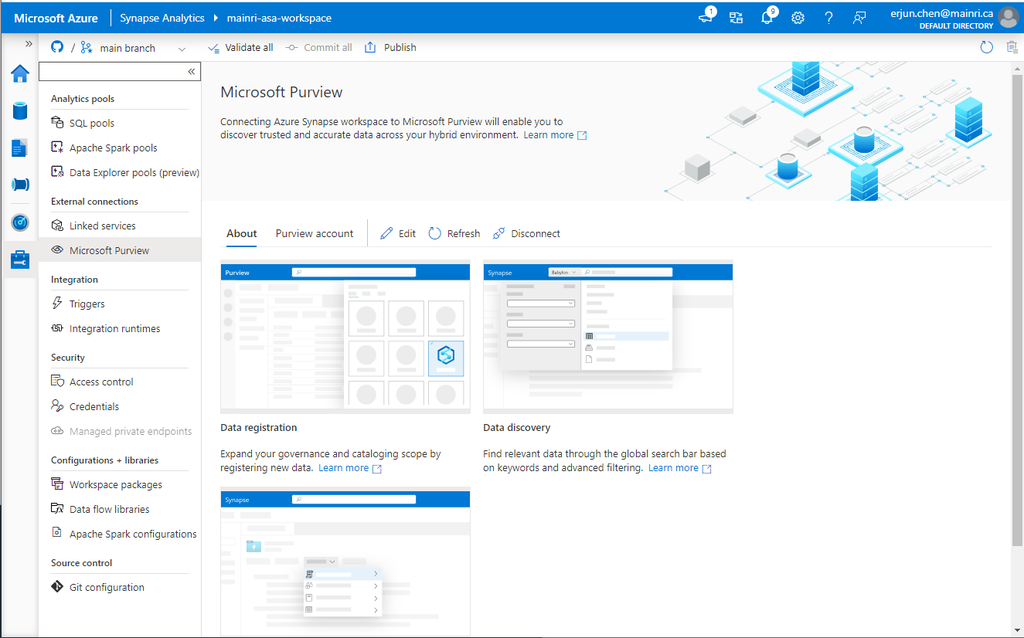
Successfully connected with Purview.
To validation, we check what we have in ADLS and SQL Database.
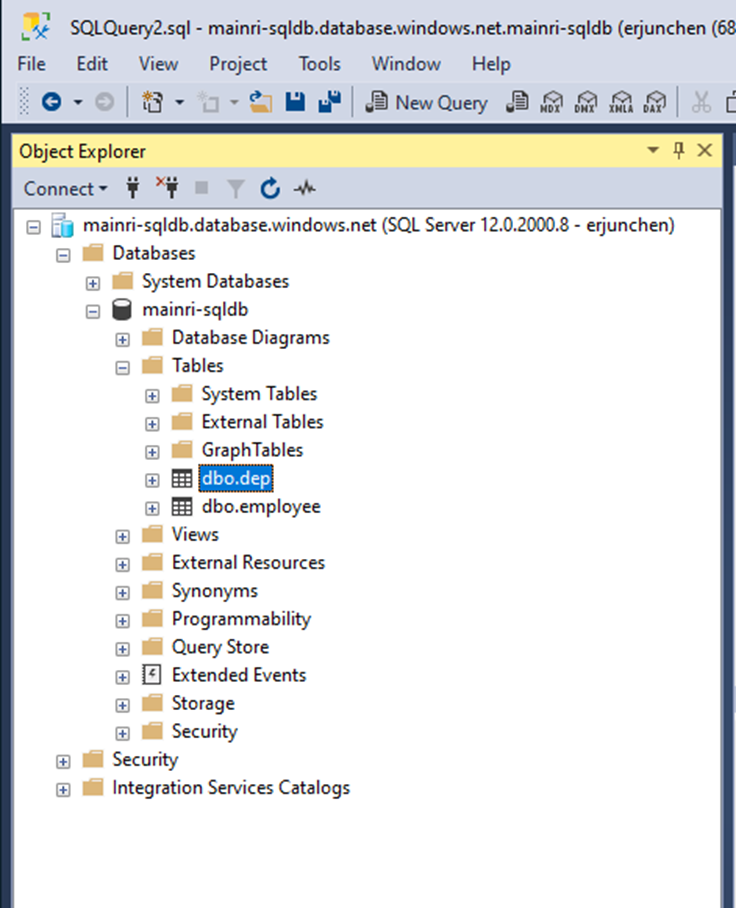
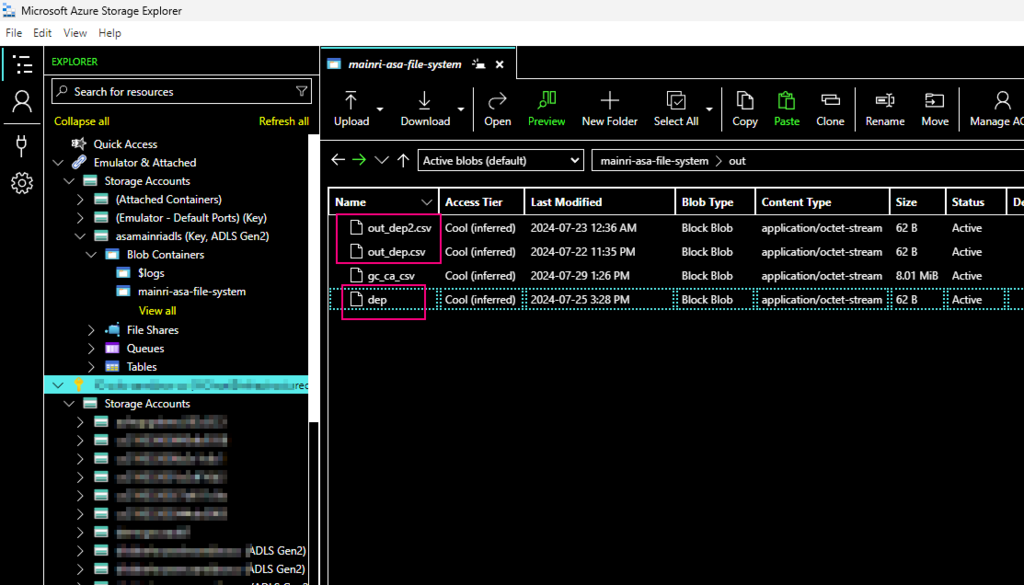
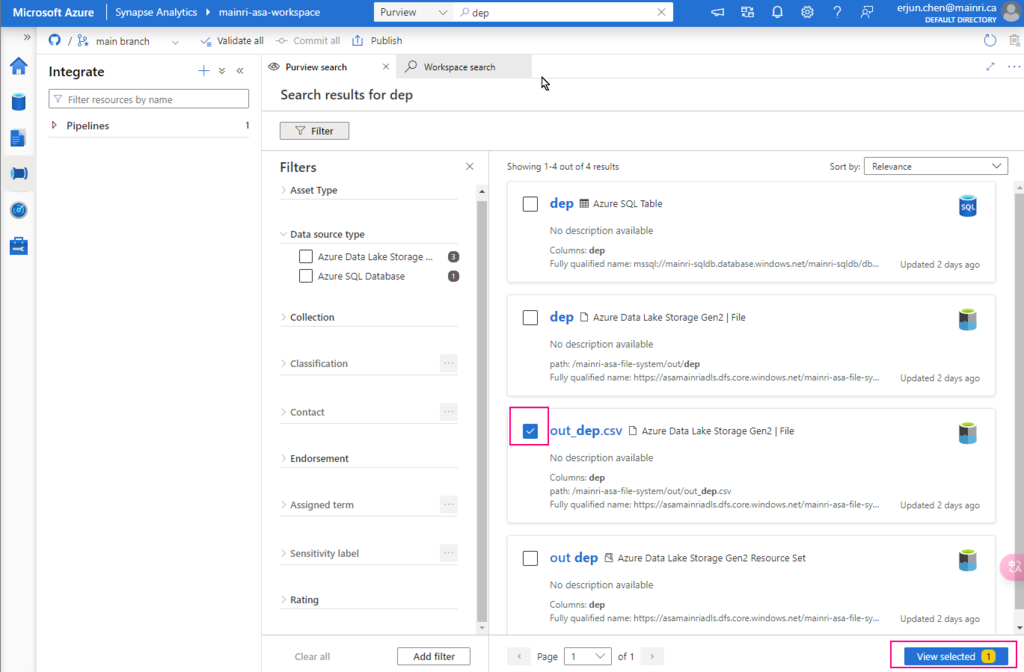
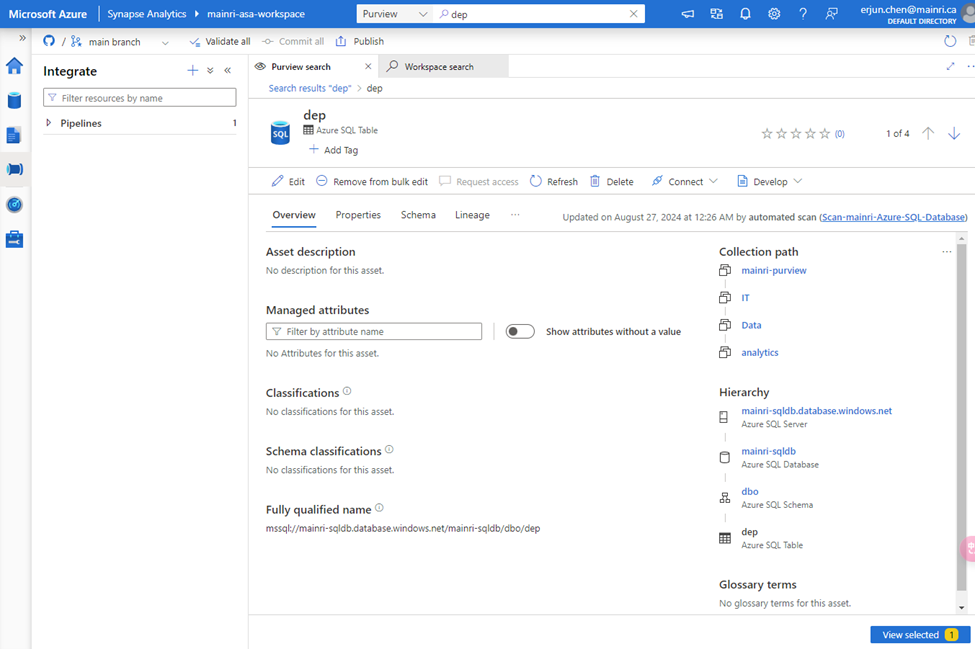
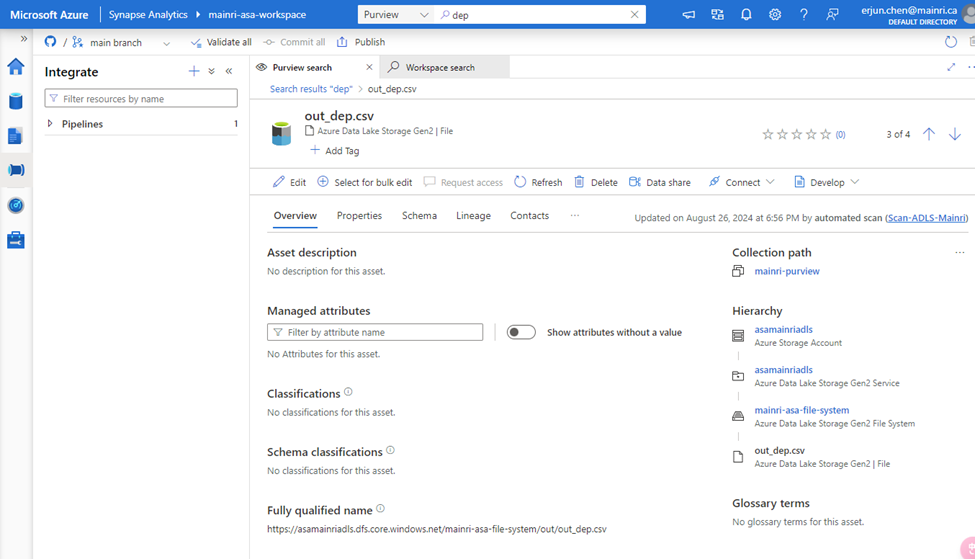
We have in ADLS and Azure SQL Database. There are one table called “dep” in the SQL Database, 3 files in the ADLS.
There is one table in SQL Database:
and there are 3 file related the key word “dep” in ADLS,
using Azure Storage Explore:
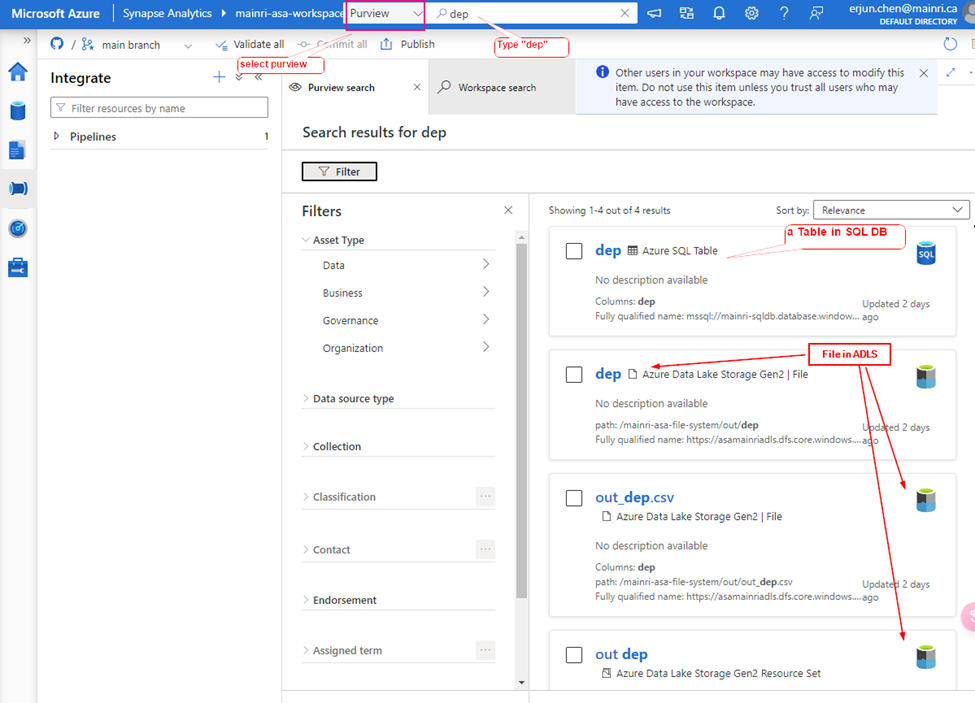
Let’s search “dep” the key from Synapse Studio.
Synapse Studio > from the dropdown > select “Purview” > type “dep”
We find out the objects related to the key words – “dep”
A table in SQL Database, 3 files in ADLS.
Great, we successfully connected to Purview.
choose either of them to view in detail
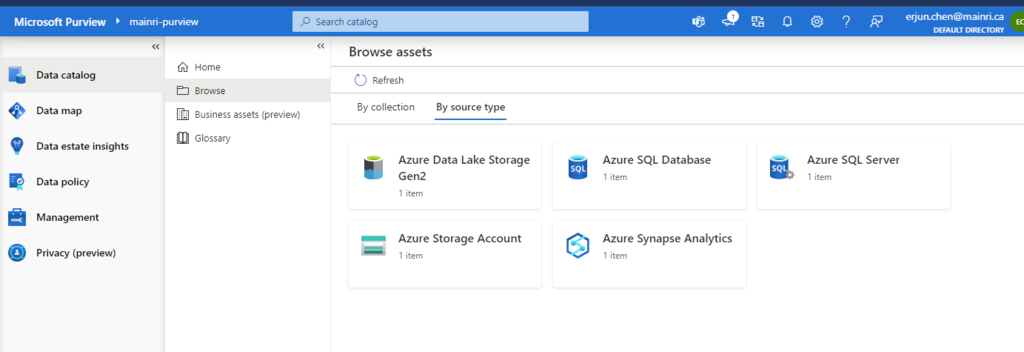
There are so many powerful and interesting functions regarding the “Searching”, “discovering”, we will talk about them late.
Now, let’s switch to Purview studio.
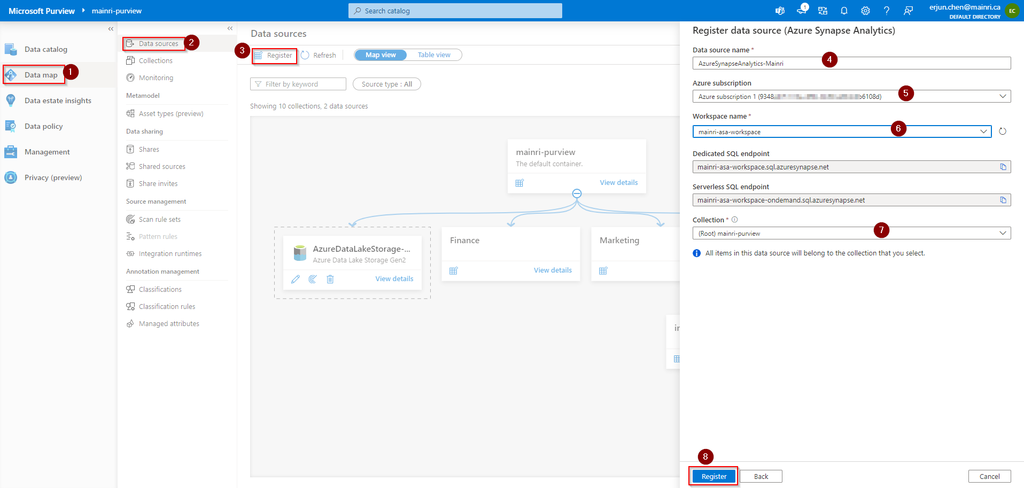
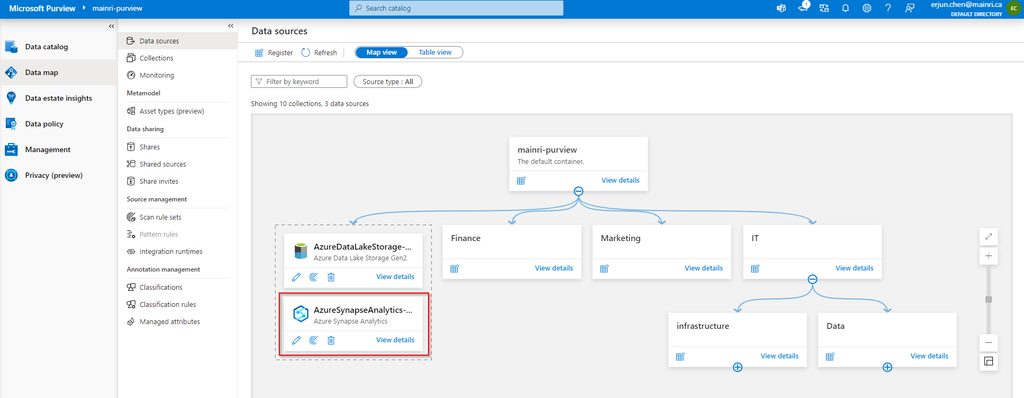
Register Synapse Analytics Workspace
Assuming you have created Collects, we directly jump into register Azure Synapse Analytics Workspace (ASA).
Purview Studio > Data Map > Data Source
After filling in above values, click “register”, you will this
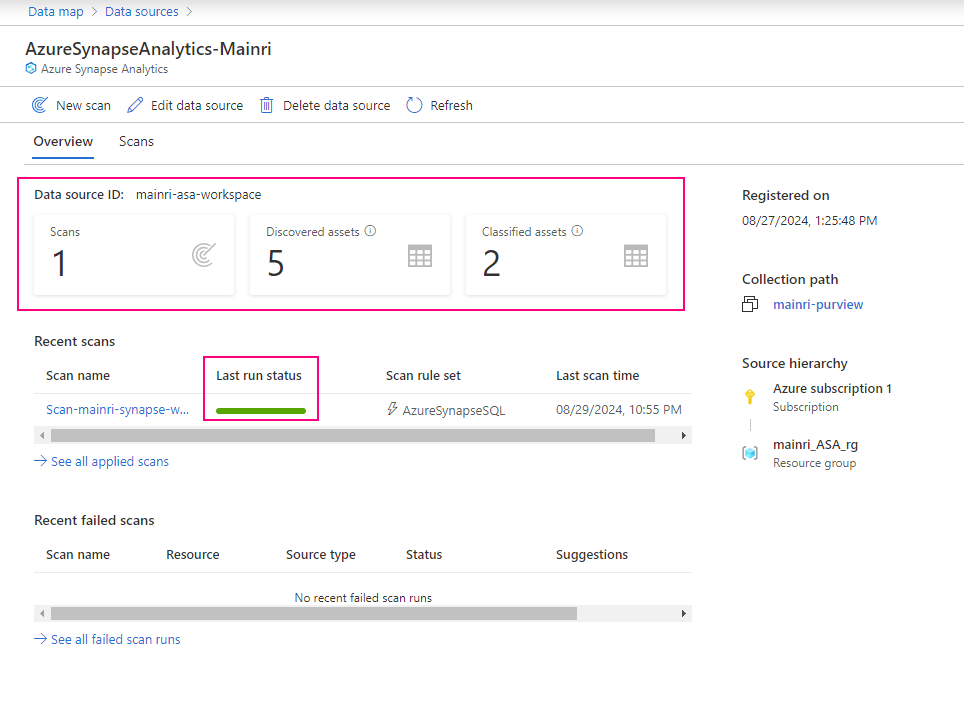
After registering the sources where your data assets are stored, you can scan each source to catalog the assets it contains. You can scan each source interactively, and you can schedule period scans to keep the data map up to date.
You may or may not see this error or alerts:
Read:
“Failed to load serverless databases from Synapse workspace, please give the managed identity of the Microsoft Purview account permissions or apply the correct credential to enumerate serverless databases.”
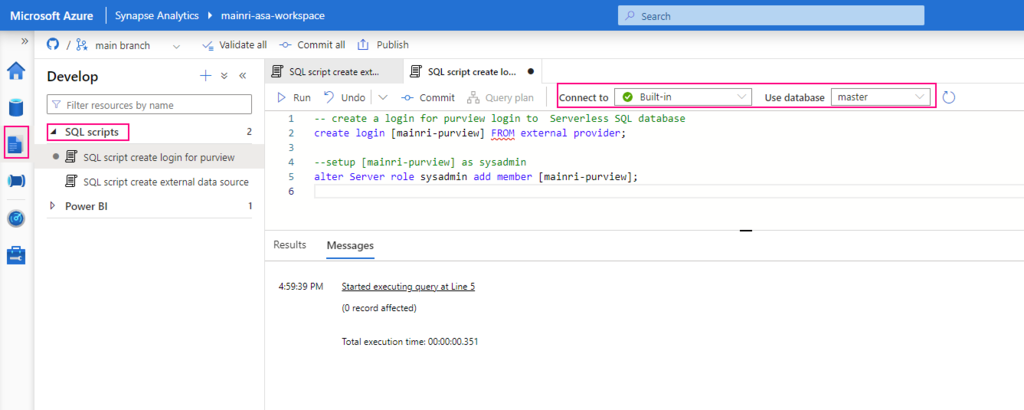
If you see it, you need create a login account for purview account to connect Serverless SQL:
Create Serverless SQL database login account for Purview
— create a login for purview login to Serverless SQL database
create login [mainri-purview] from external provider;
Synapse Studio > Develop > SQL Script > select: “connect to Built-in” and use database “master”
Grant purview login account Sysadmin privilege
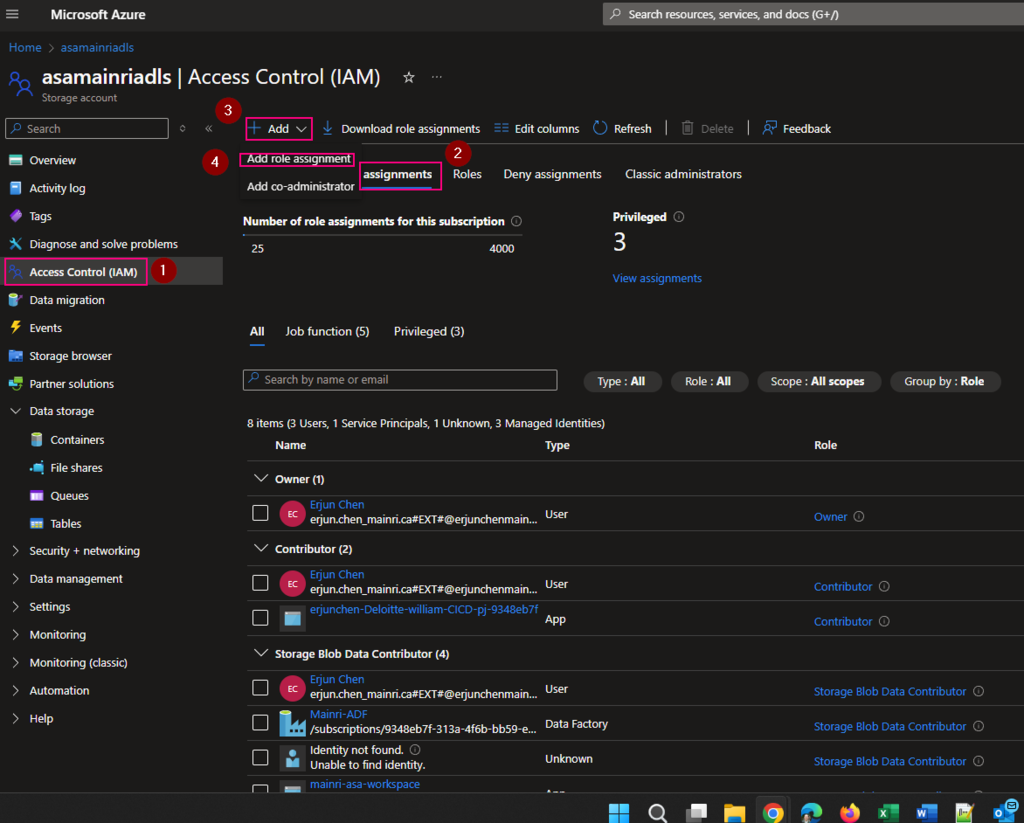
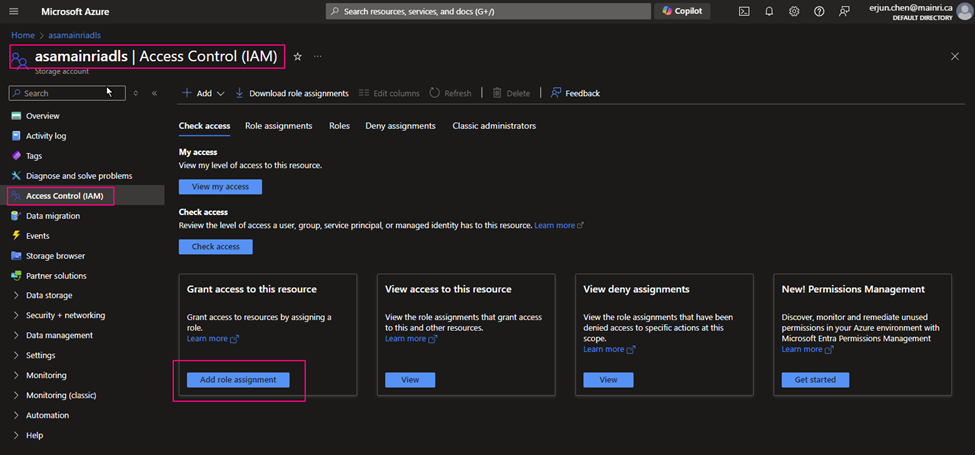
Add managed identity to the storage account
Then, add managed identity to the storage account.
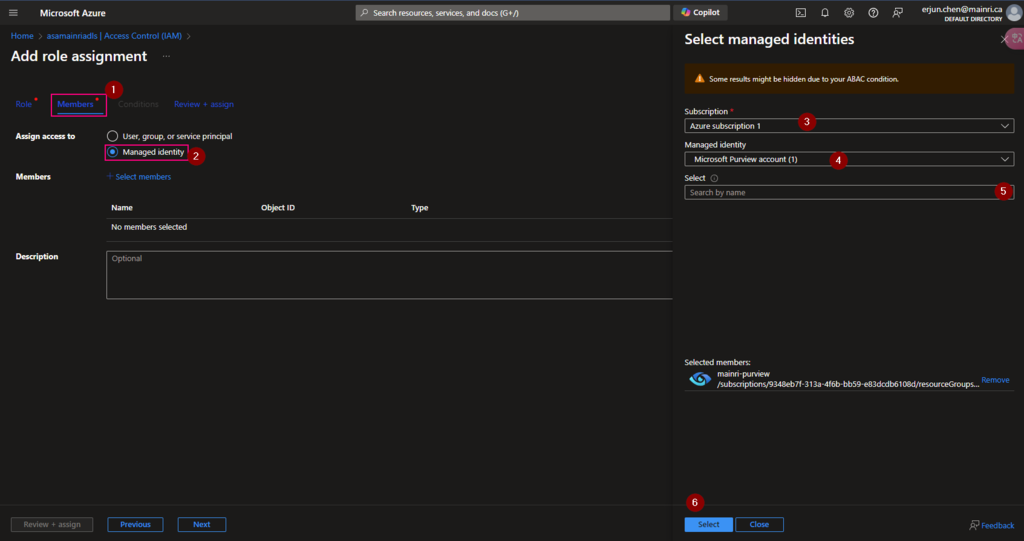
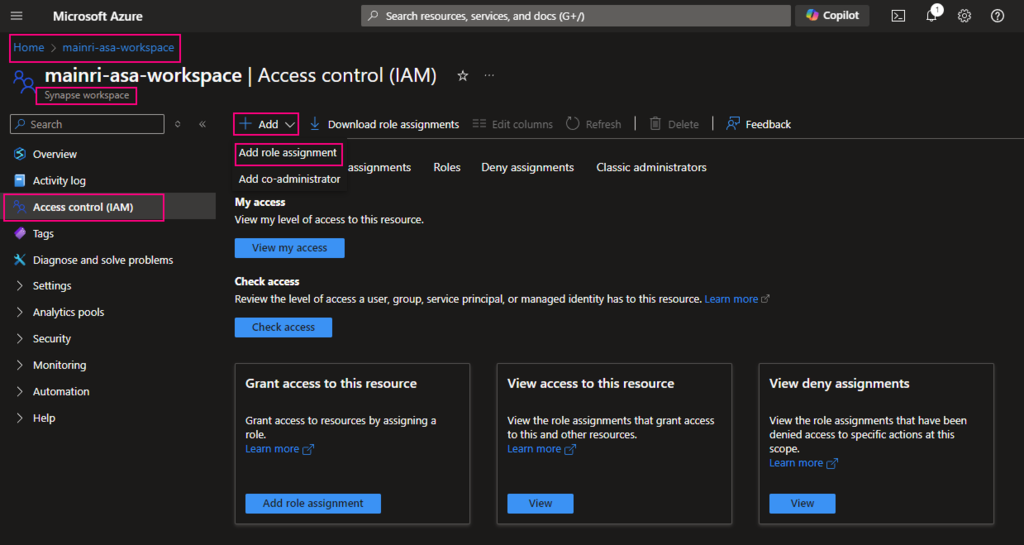
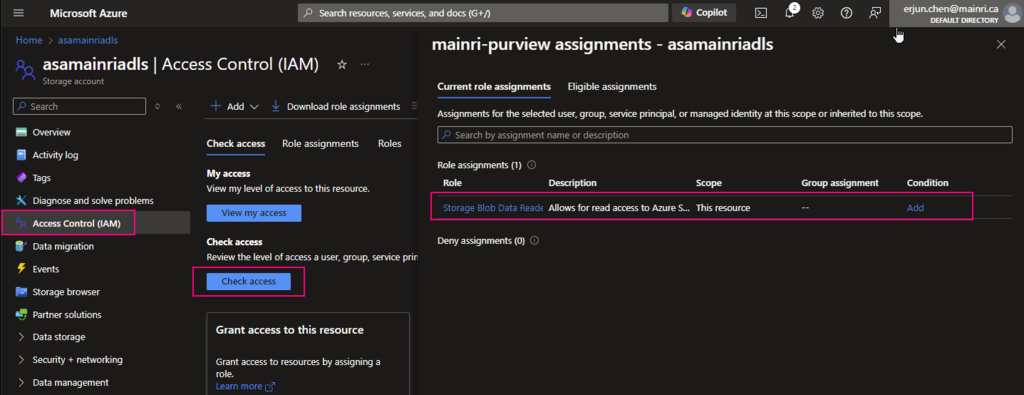
From Azure portal > storage account > Access Control (IAM)
Select Role assignments tag
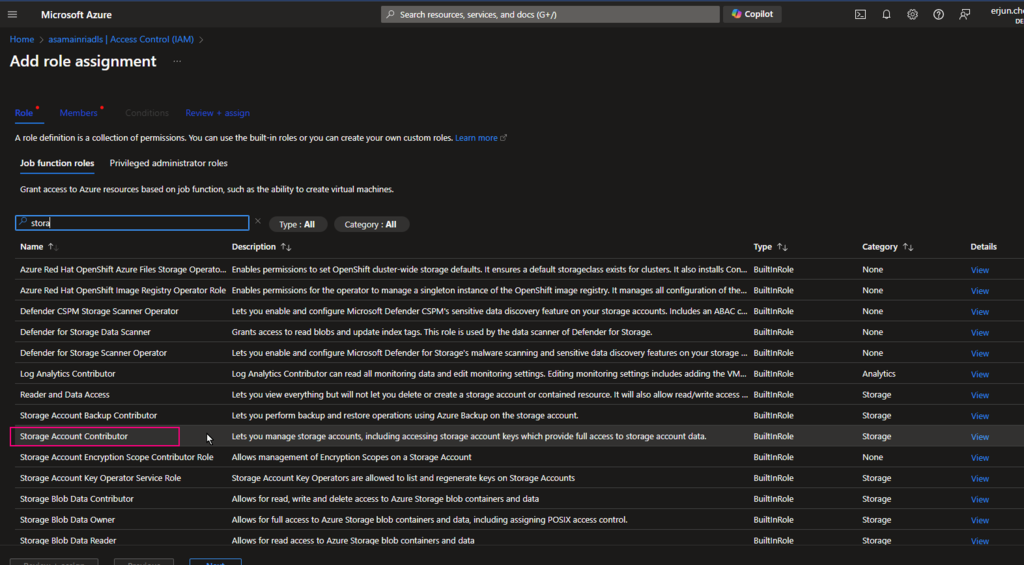
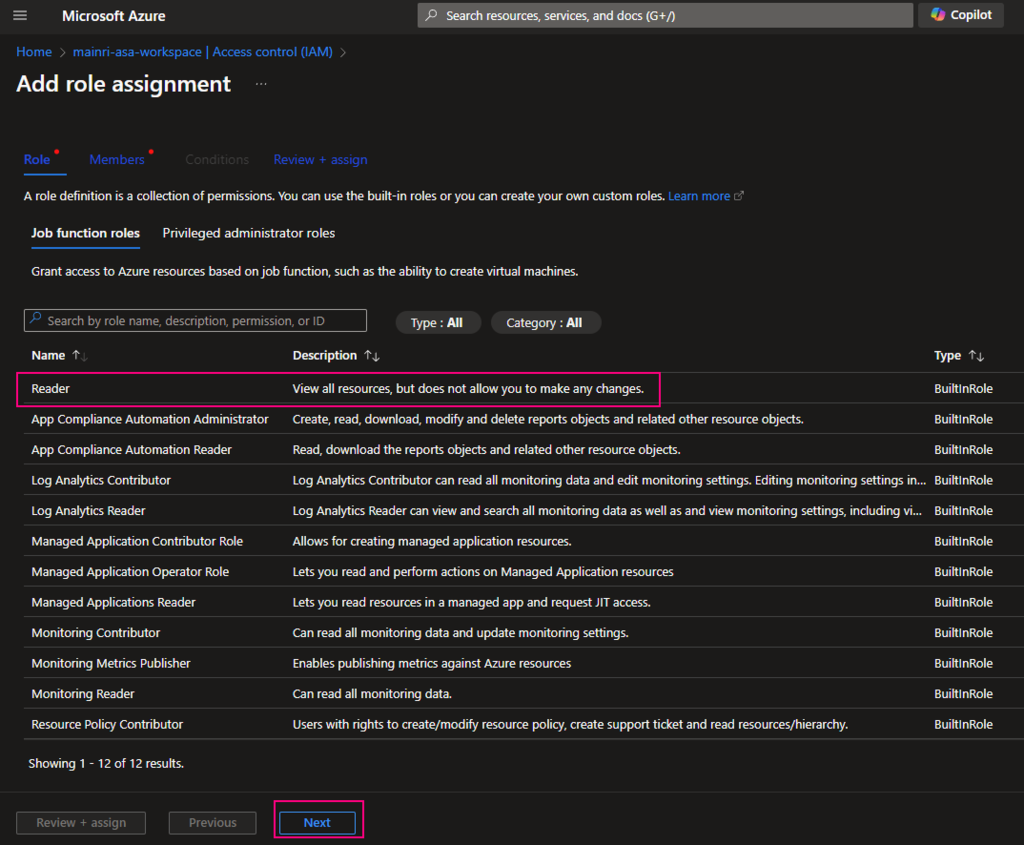
Add role assignments
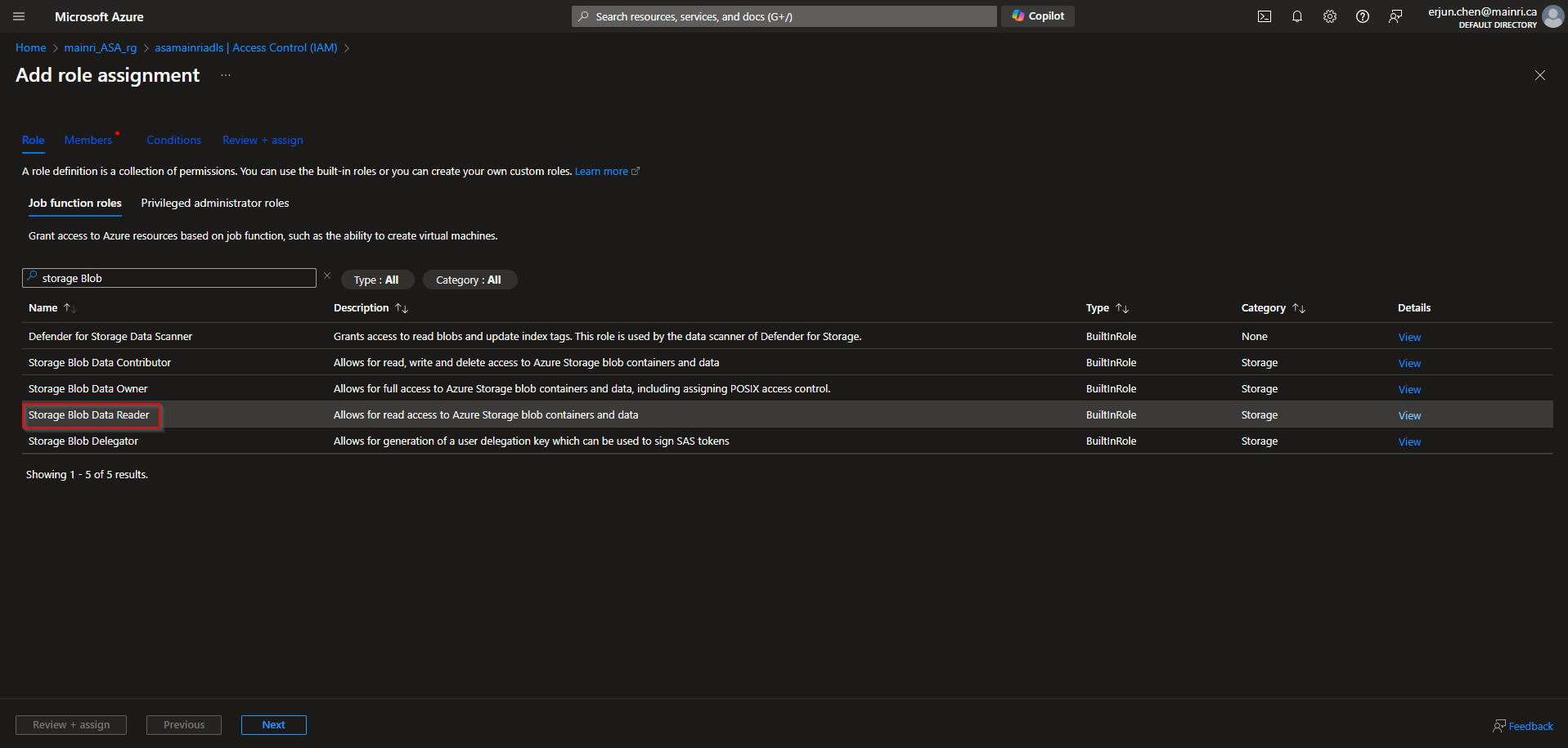
Give the “Storage Account Contributor” role
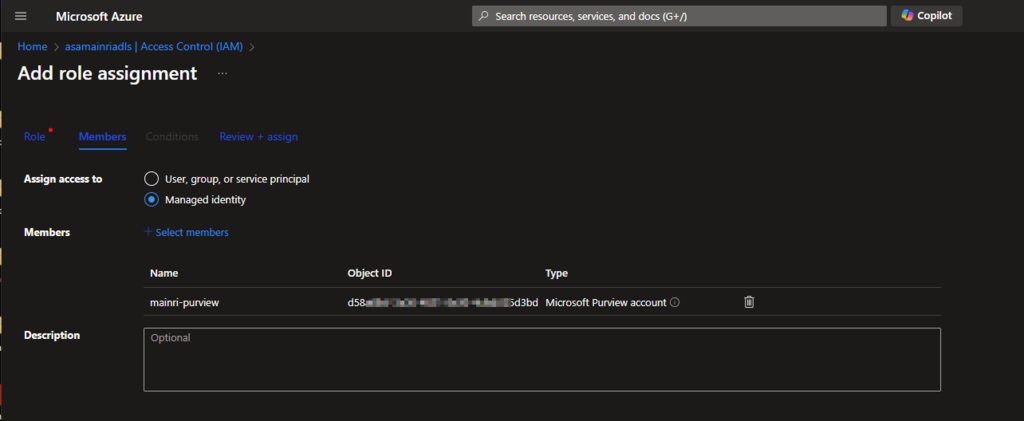
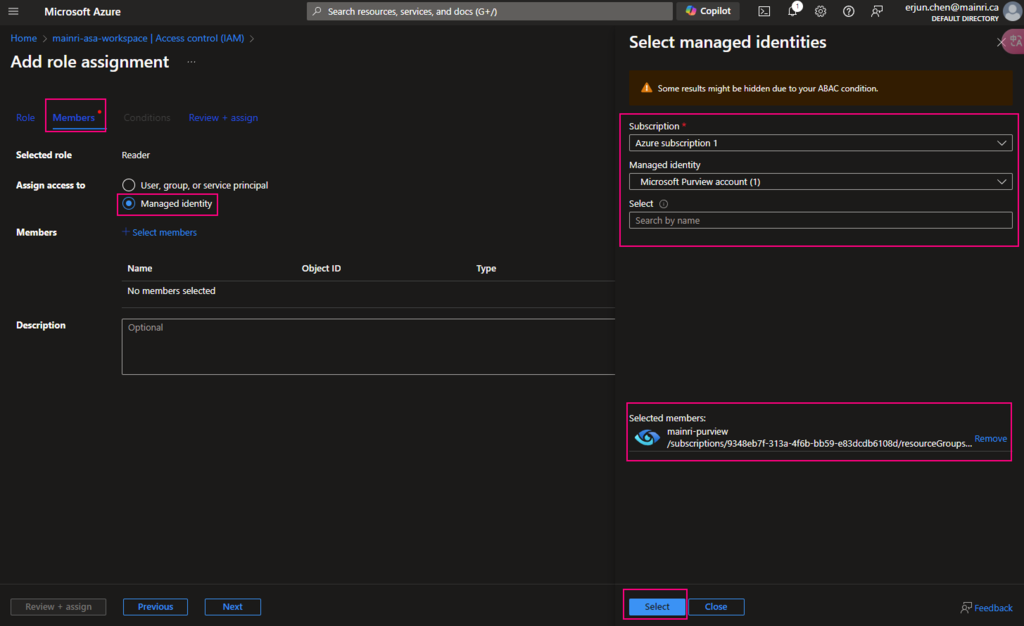
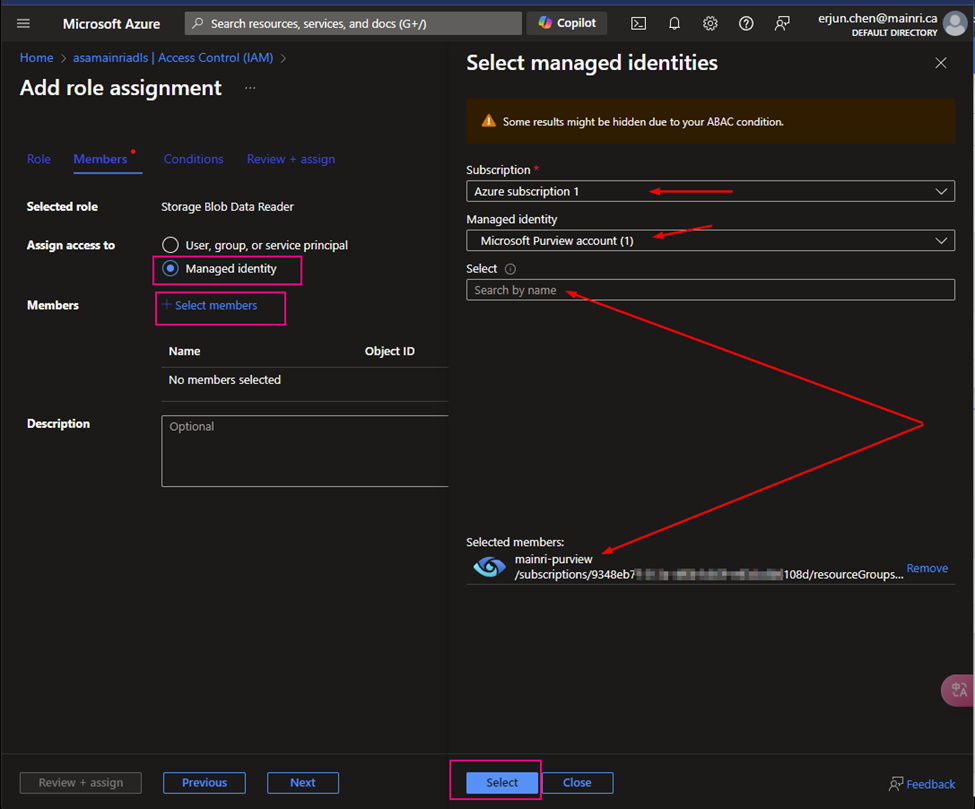
Then, select “Member” tag:
Select “Managed Identity”, fill in all properties, Find out the purview account
Now, the role assignments added.
If you have dedicated SQL pool, we need repeat these.
Create Serverless SQL database login account for Purview
Grant purview login account Sysadmin privilege
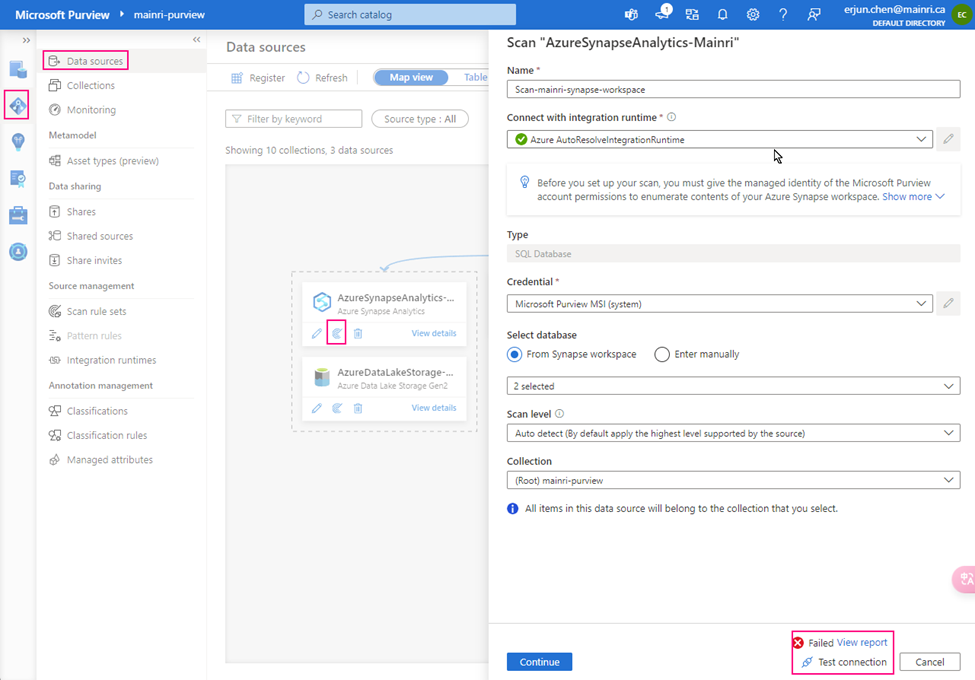
Let’s test the connection
From Purview studio > scan
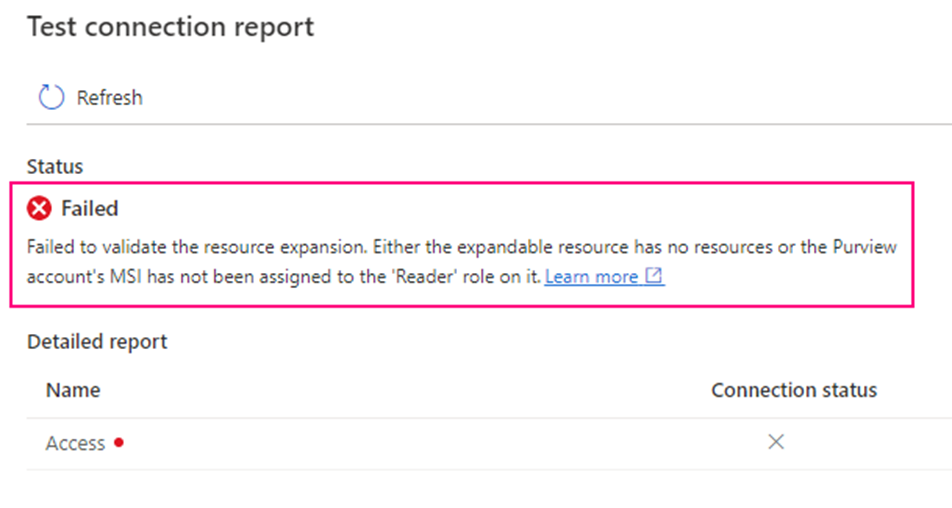
we got failed alert.
“Failed to validate the resource expansion. Either the expandable resource has no resources or the Purview account’s MSI has not been assigned to the ‘Reader’ role on it.”
Go back to Synapse portal
Azure Portal > Synapse workspace > Access control (IAM) > Add role assignments
add “read” role
Add “managed Identity” member – Purview
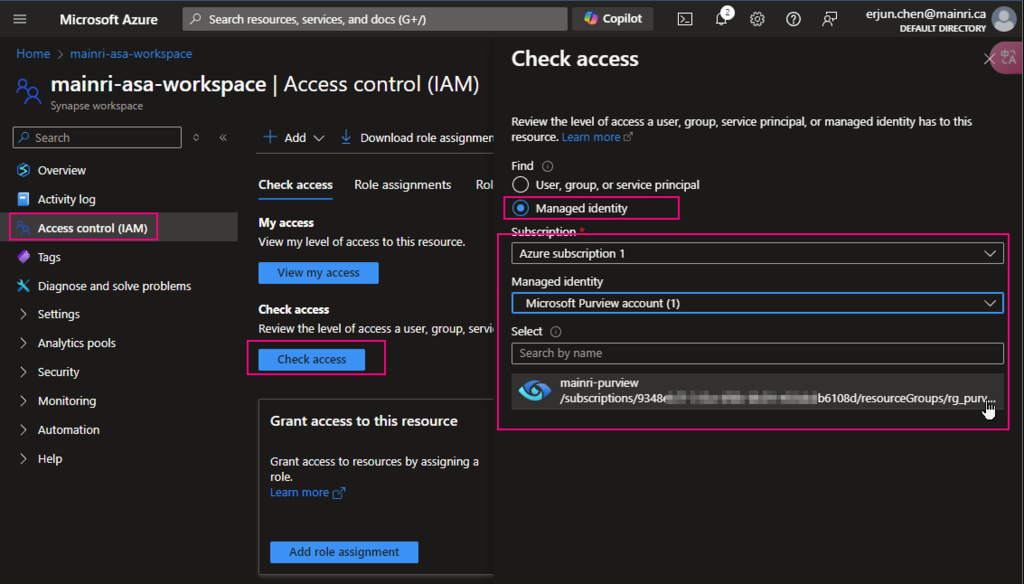
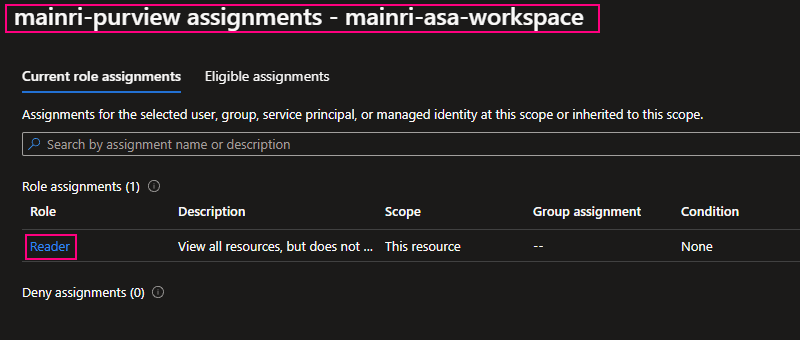
Check Purview access,
we can see Mainri-purview assignments – mainri-asa-workspace has “read” role (my Synapse workspace named “mainri-asa-workspace”)
Go to Purview Studio test connection again.
Great! We successful connect to Synapse workspace.
We have gotten access to SQL; we’ve got access to storage account. we have add “read” role assignment to Purview
Alright, we are ready to go – scan.
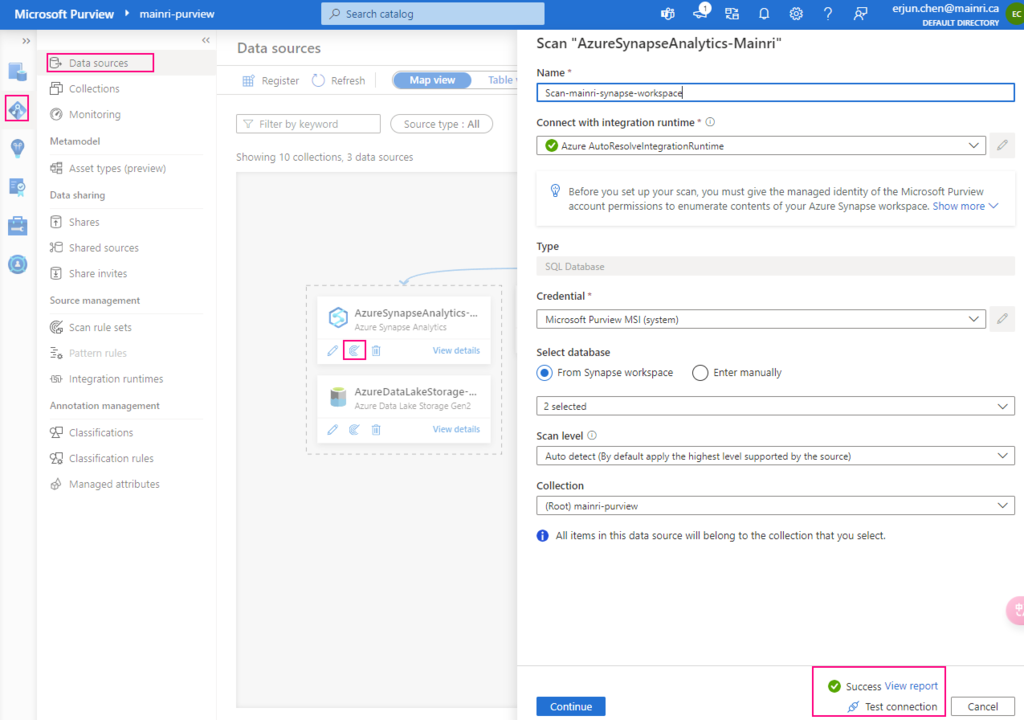
Scan Synapse workspace
After registering the sources where your data assets are stored, you can scan each source to catalog the assets it contains. You can scan each source interactively, and you can schedule period scans to keep the data map up to date.
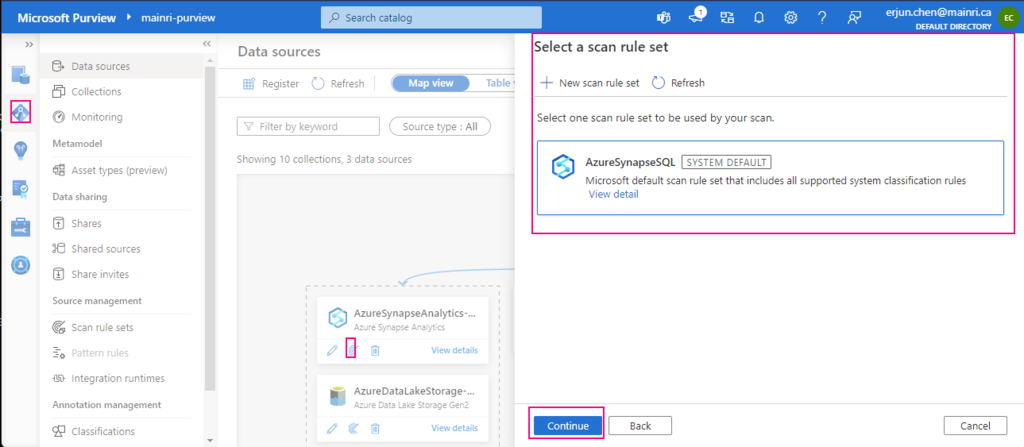
Select a scan rule set
If you like, you are able to add even more new scan rule set at this step.
For this demonstration, we select default scan rule set.
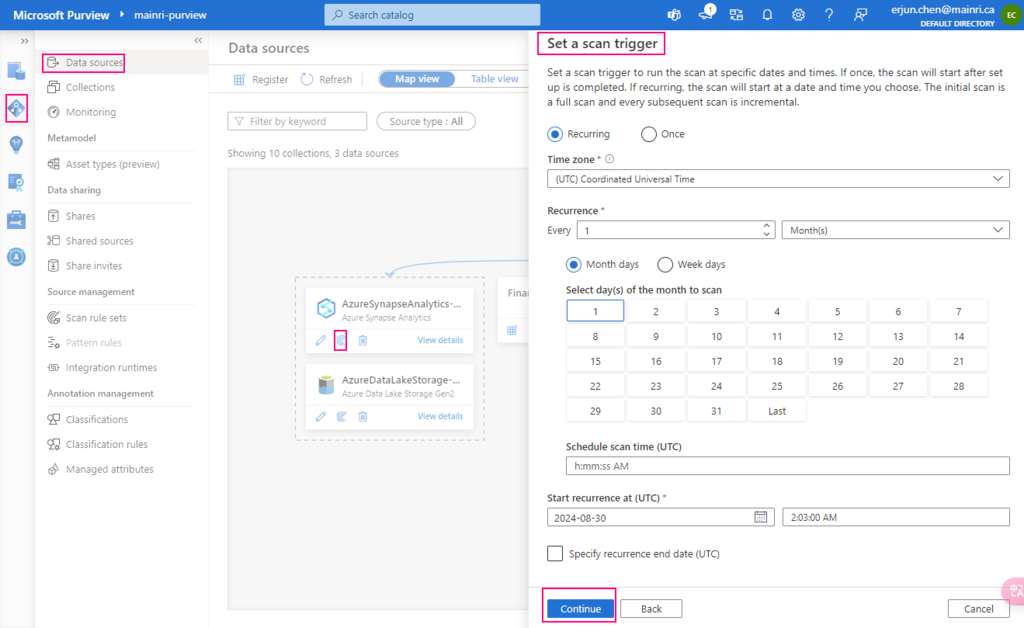
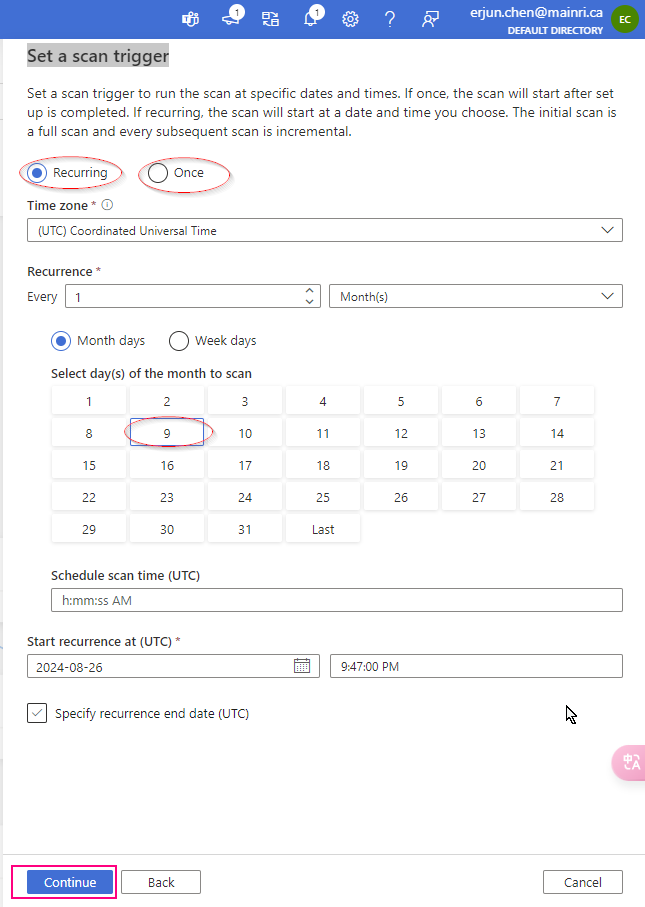
Set a scan trigger
We ca either scan once or schedule and recurring scan on schedule.
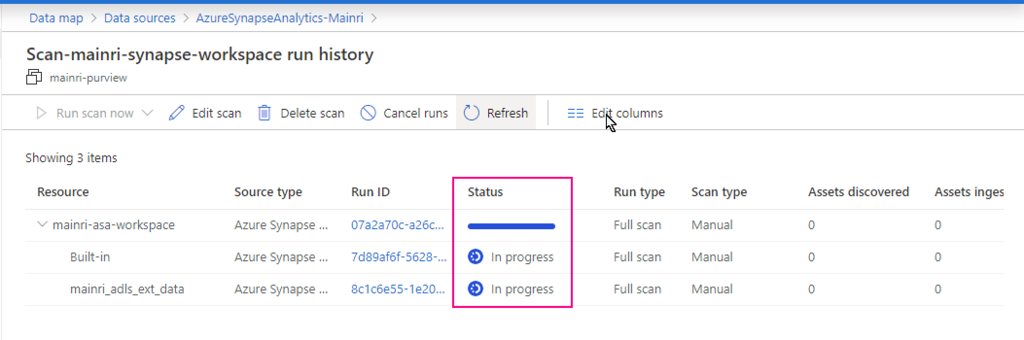
Monitoring the scan progress ….
Once the process done, we will see this:
Alright, we have done the Purview for scanning Azure Synapse Workspace. Now, we have those source in our Azure purview.
In the previous article, we discussed Managed Identity, registering ADLS, and scanning it in Azure Purview. In this article, I will focus on scanning an Azure SQL Database, including how to register and scan it in Azure Purview. The process differs from that of ADLS. You will be required to provide Azure SQL Database credentials.
We will learn the best practice of storing the Azure SQL Database credentials in an Azure Key Vault and use that Key Vault in Purview.
Azure Key Vault provides a way to securely store credentials, secrets, and other keys, but your code must authenticate to Key Vault to retrieve them.
We must follow these steps to register and scan Azure SQL Database:
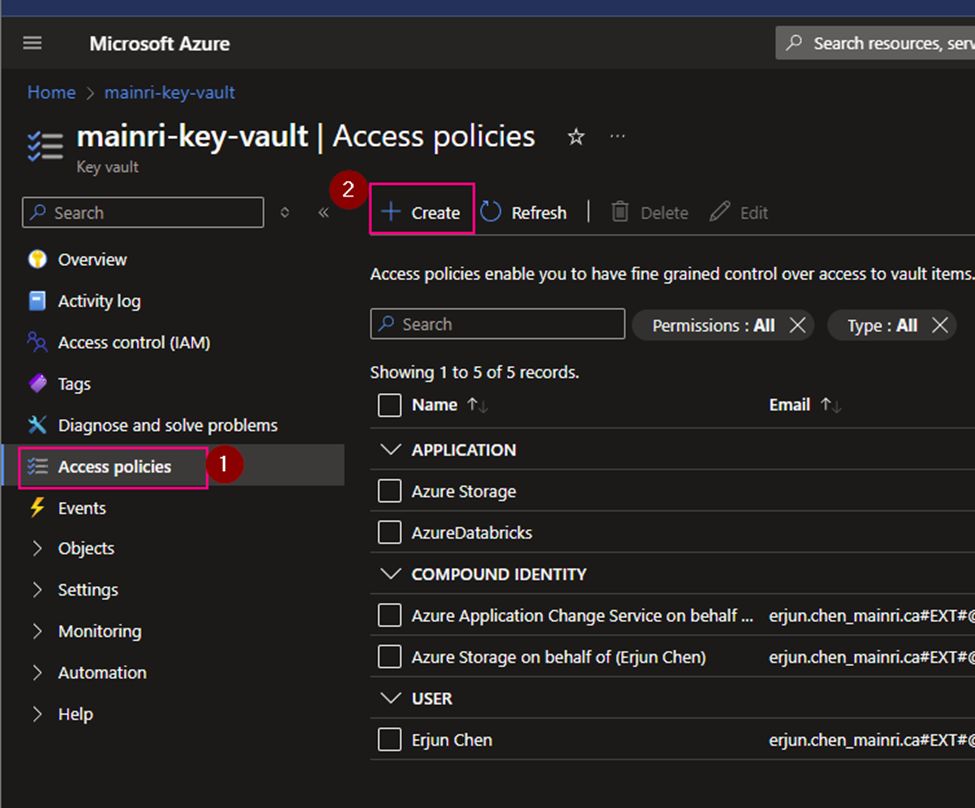
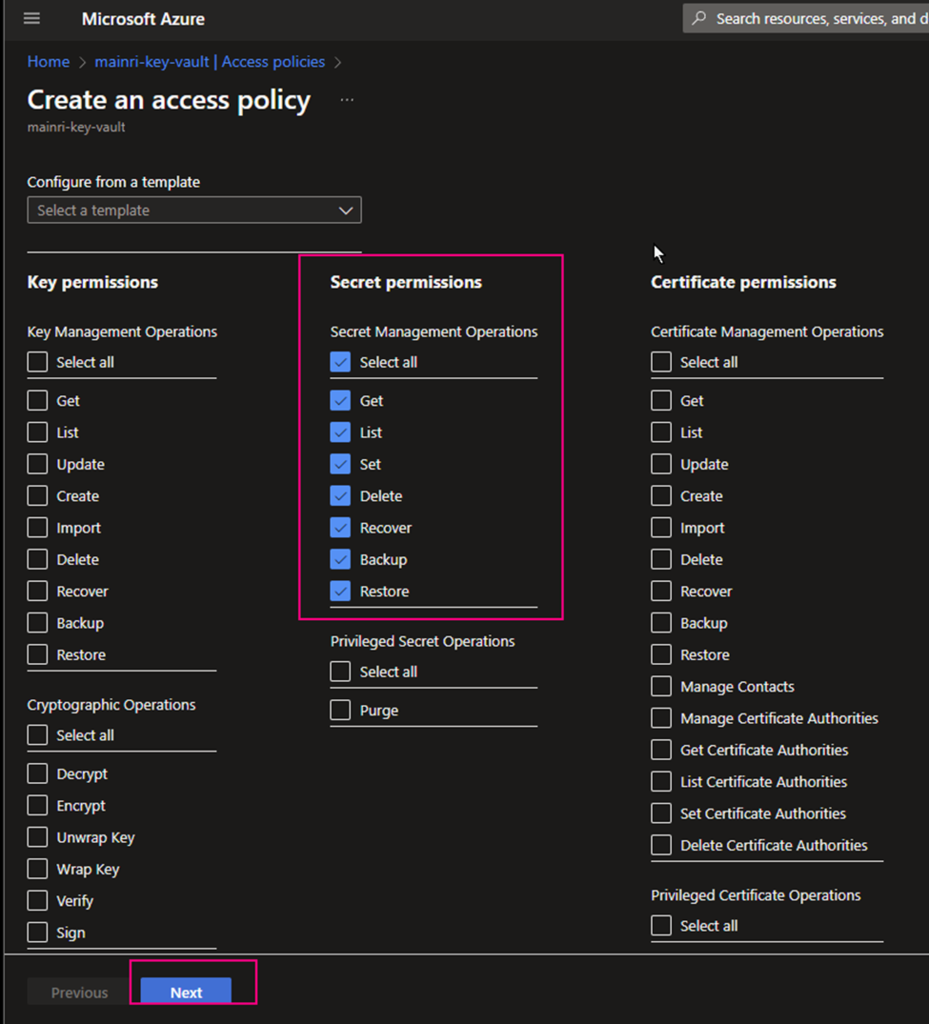
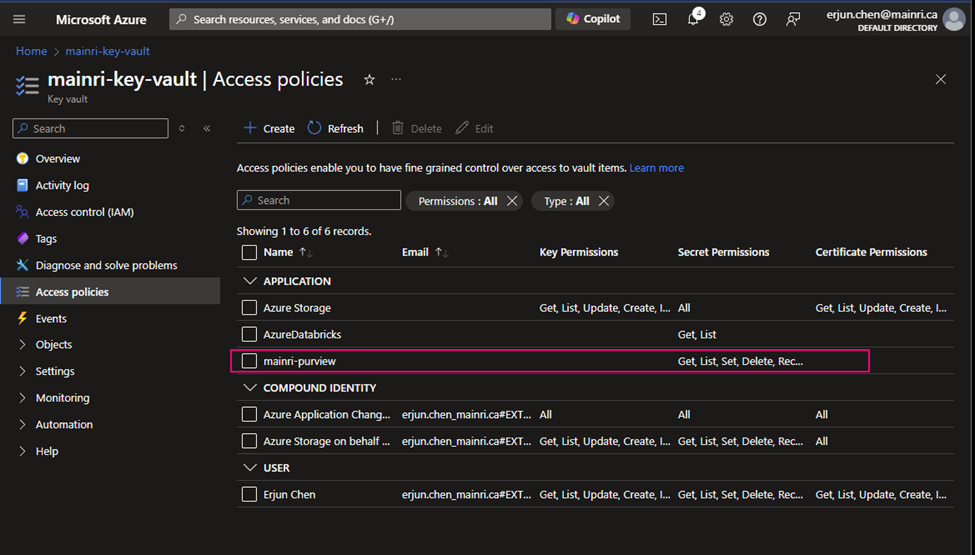
Grant your Azure Account access to Key Vault by adding a new access policy. We will have to grant all the secret permissions.
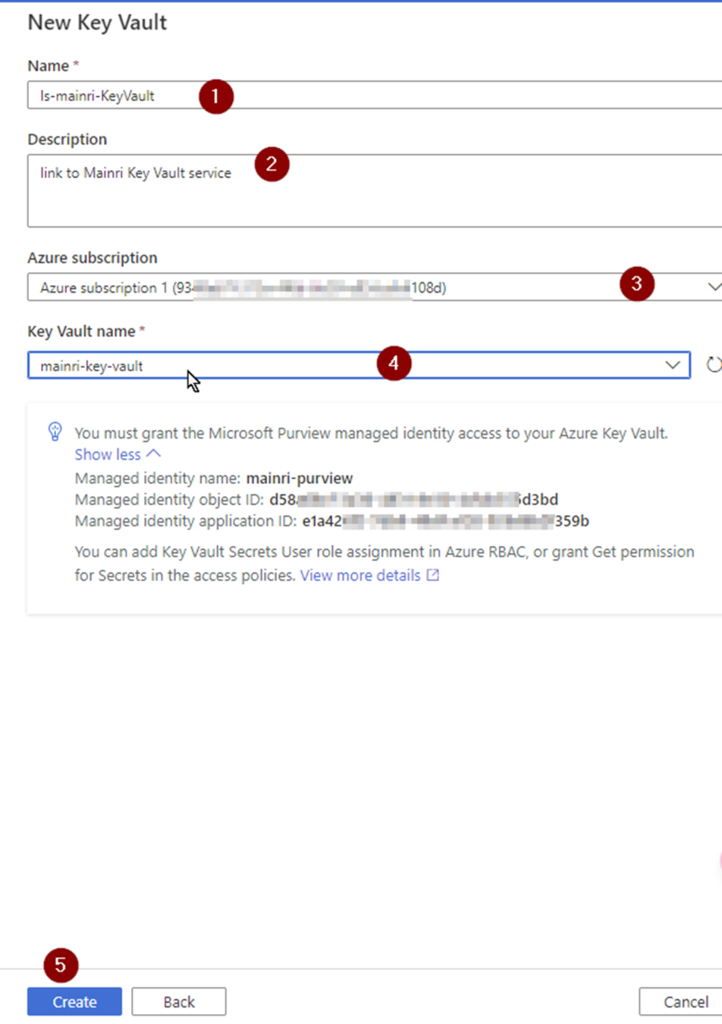
Grant Purview Managed identity access to Key Vault by adding a new access policy. Here we will have to grant Get and List permissions so purview can get(retrieve) and list down all the secrets.
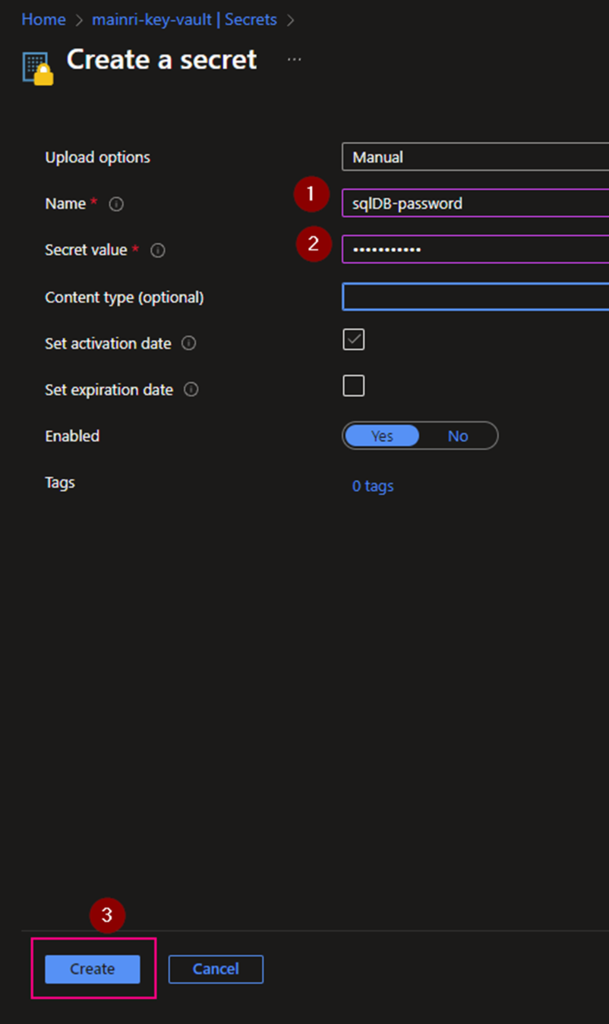
Generate a Secret for SQL Admin in Azure Key Vault. This secret will be used to log in to Azure SQL DB.
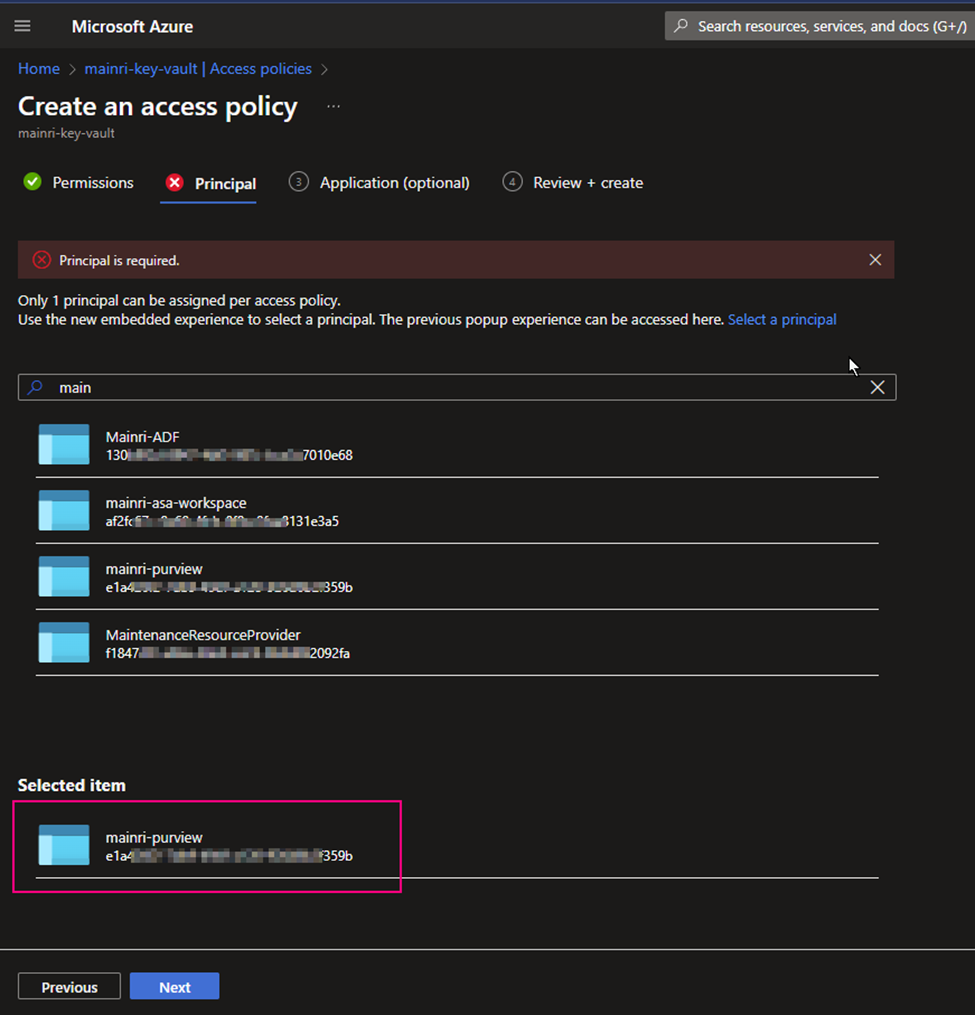
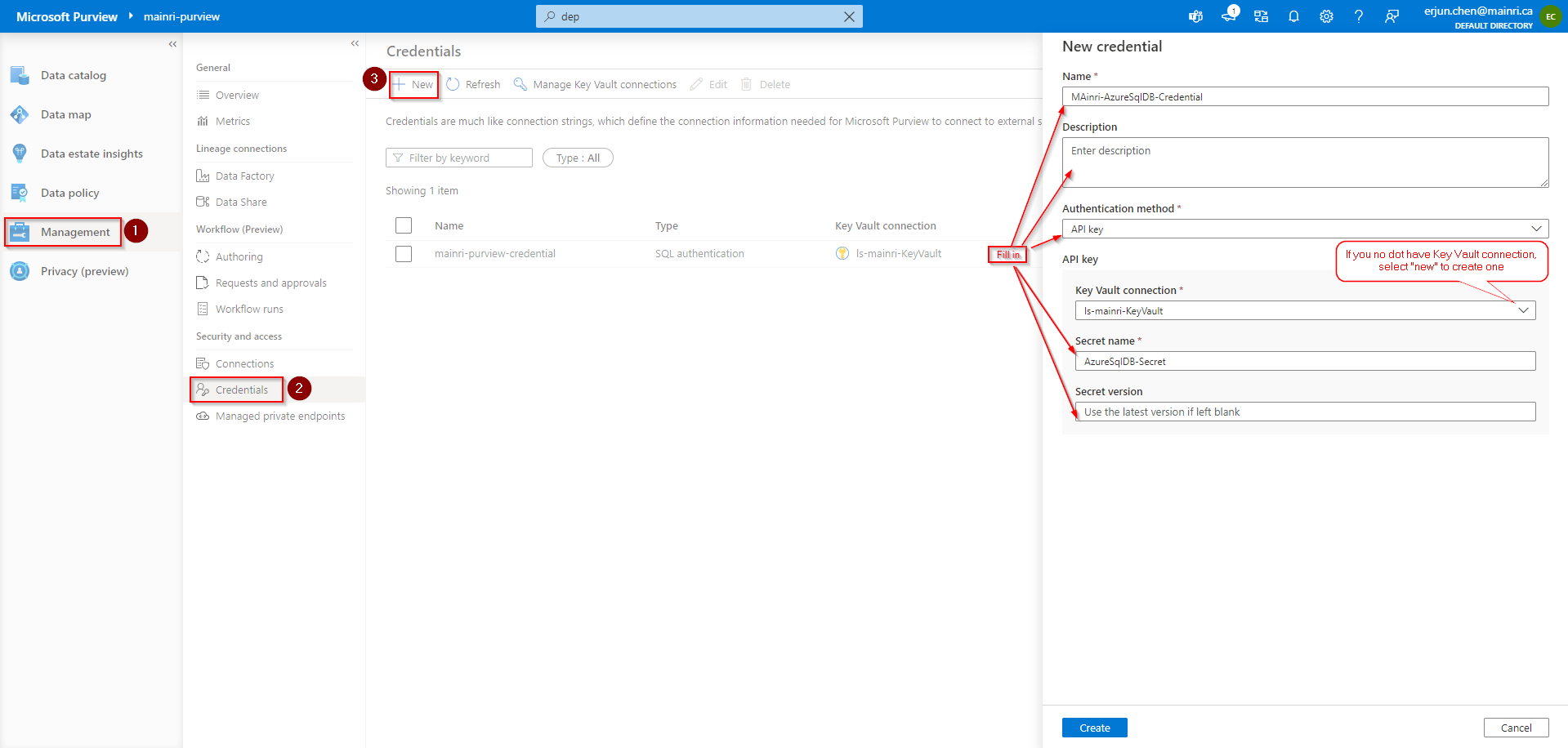
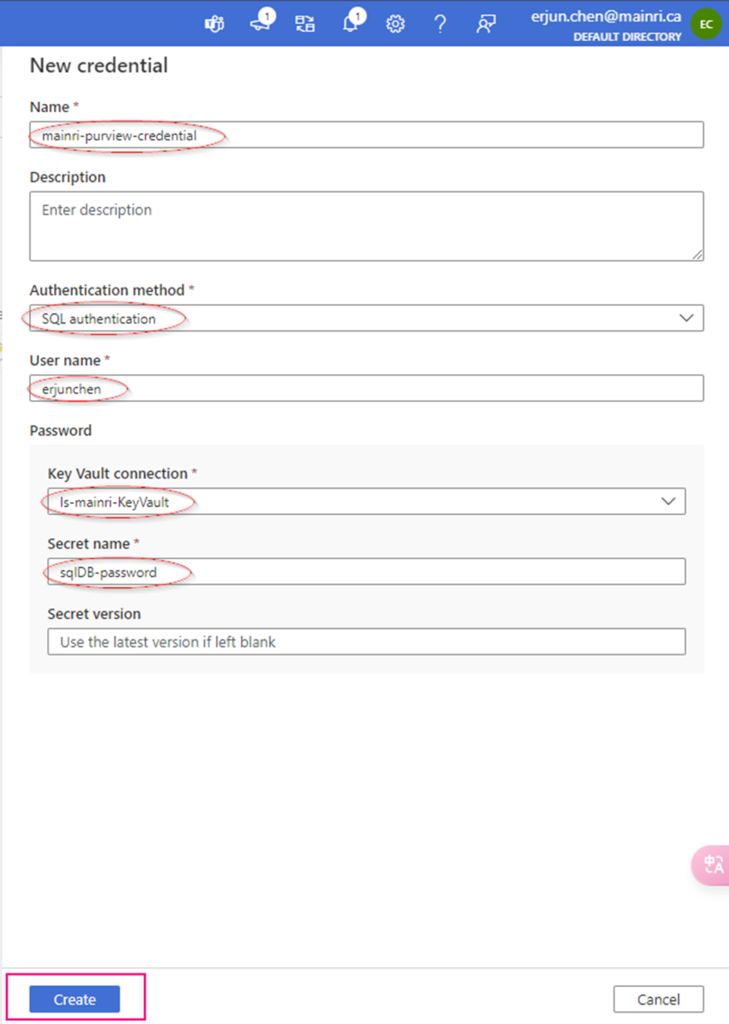
Add SQL Credentials (created above) in Purview so we can use the same credential.
Register Azure SQL DB in Microsoft Purview.
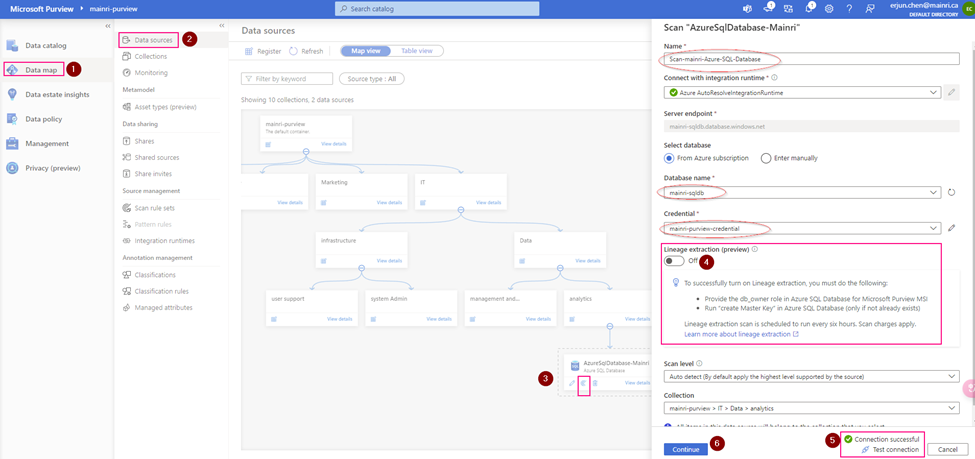
Scan Azure SQL Database as a data source with Azure Key Vault Credentials.
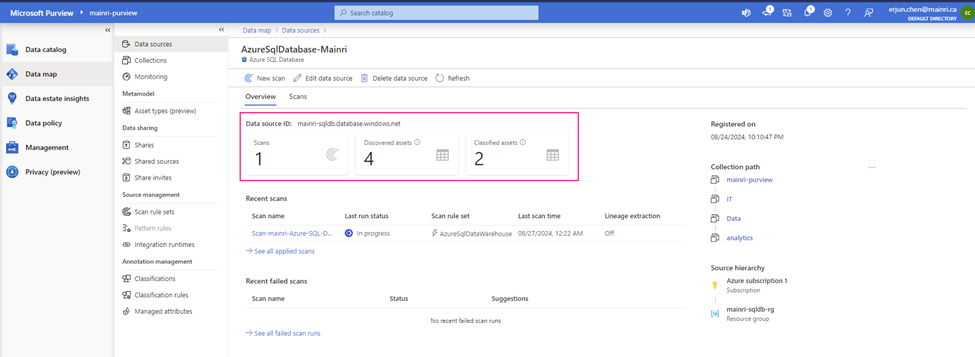
Verify that Purview is able to see tables in the Azure SQL database.
Discover and govern Azure SQL Database in Microsoft Purview
This article outlines the process to register an Azure SQL database source in Microsoft Purview. It includes instructions to authenticate and interact with the SQL database.
When you’re scanning Azure SQL Database, Microsoft Purview supports extracting technical metadata from these sources:
Server
Database
Schemas
Tables, including columns
Views, including columns (with lineage extraction enabled, as part of scanning)
Before we scan data sources in Azure Purview, we have to register data resources that to be scanned.
First, we will learn the concept of managed identity and how Azure purview uses it.
Second, we will learn the steps involved in registering ADLS Gen2.
Azure Purview Managed Identity
We will use Azure Purview Managed Identity that is an Azure resource feature found in Azure Active Directory (Azure AD). The managed identities for Azure resources feature is free and there’s no additional cost.
We can use the identity to authenticate to any service that supports Azure AD authentication, including Key Vault, without any credentials in your code. We will use Azure Purview Managed Identity.
Let’s register source data first.
We have to follow these steps to register and scan ADLS Gen 2 account:
Grant the Azure Purview Managed Identity access to ADLS Gen2 so purview can have access to it. Preview managed identity should have storage blob reader permission on ADLS Gen2
Scan ADLS Gen2 with the Purview Managed Identity registered in step 1
Register an Azure Data Lake Storage Gen2 account
Azure Portal > ADLS > Access Control > Add role assignment
> storage BLOB Data
>Select managed Identities
>next > next > review + assign
Now, you can “check access”, Now, you can “check access”. It’s added/
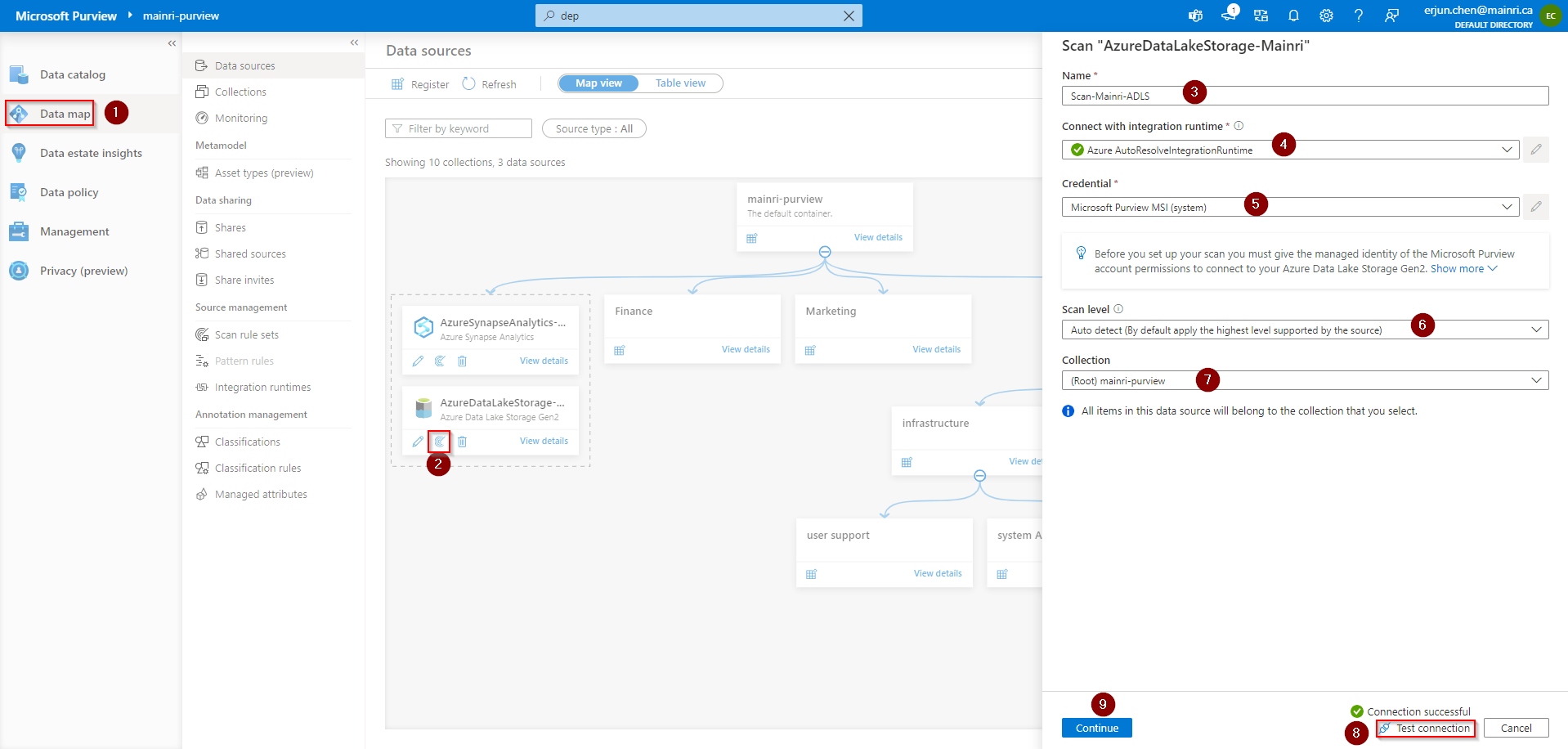
now, it’s time for scanning. from Azure Purview Studio
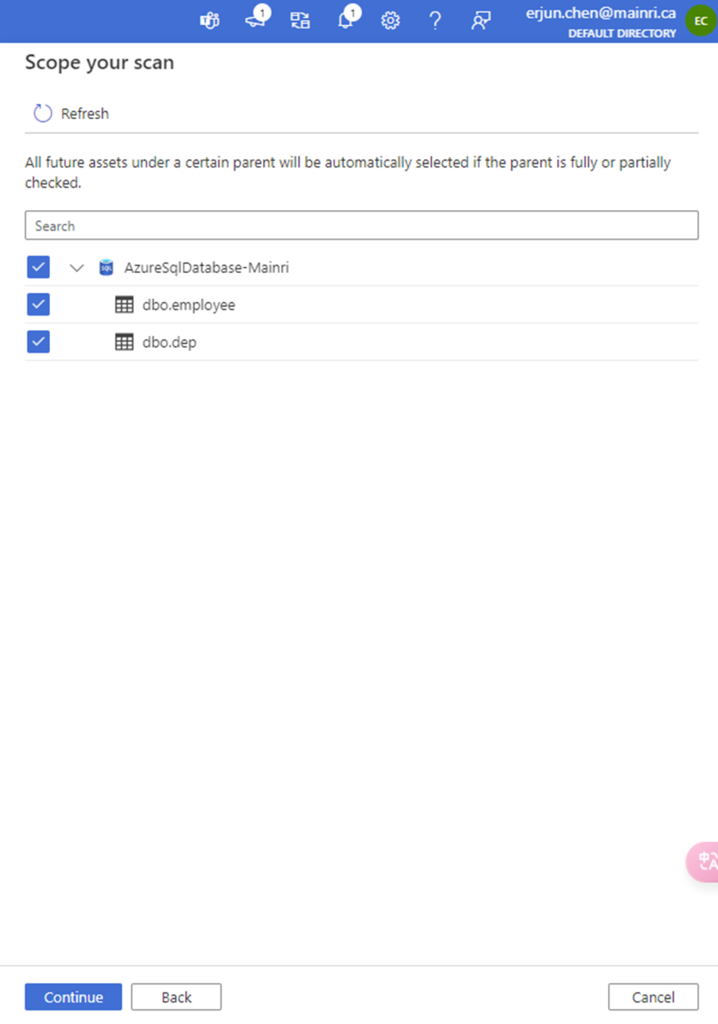
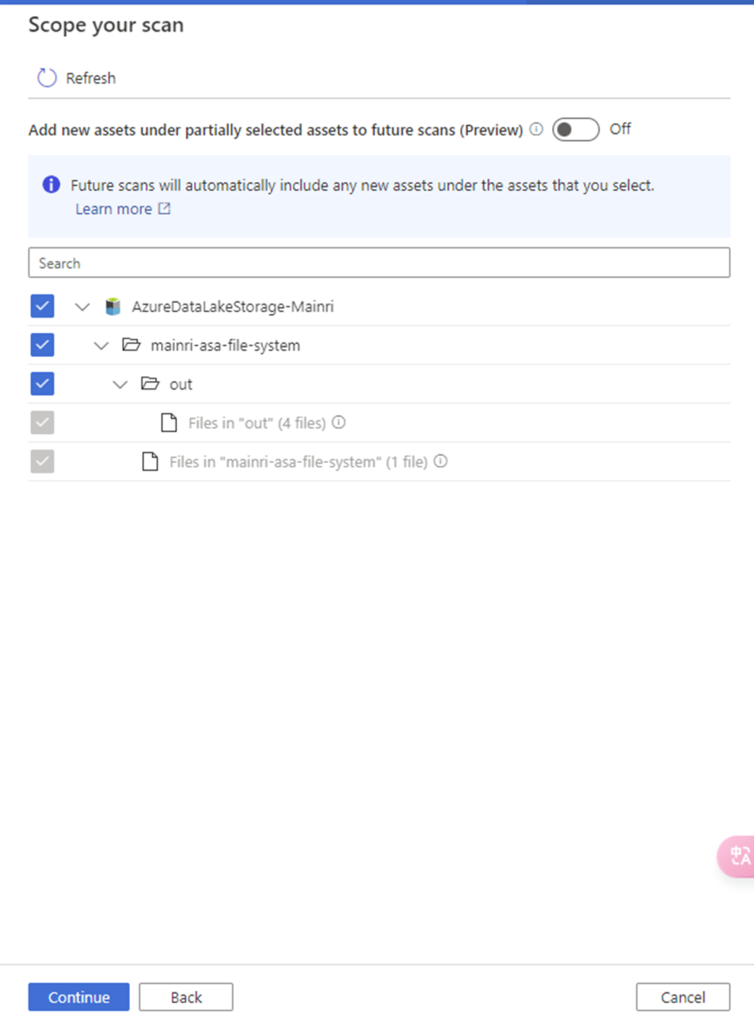
Scope your scan
You will see “scope your scan”. Now we can see all my data and directory structure on ADLS appear.
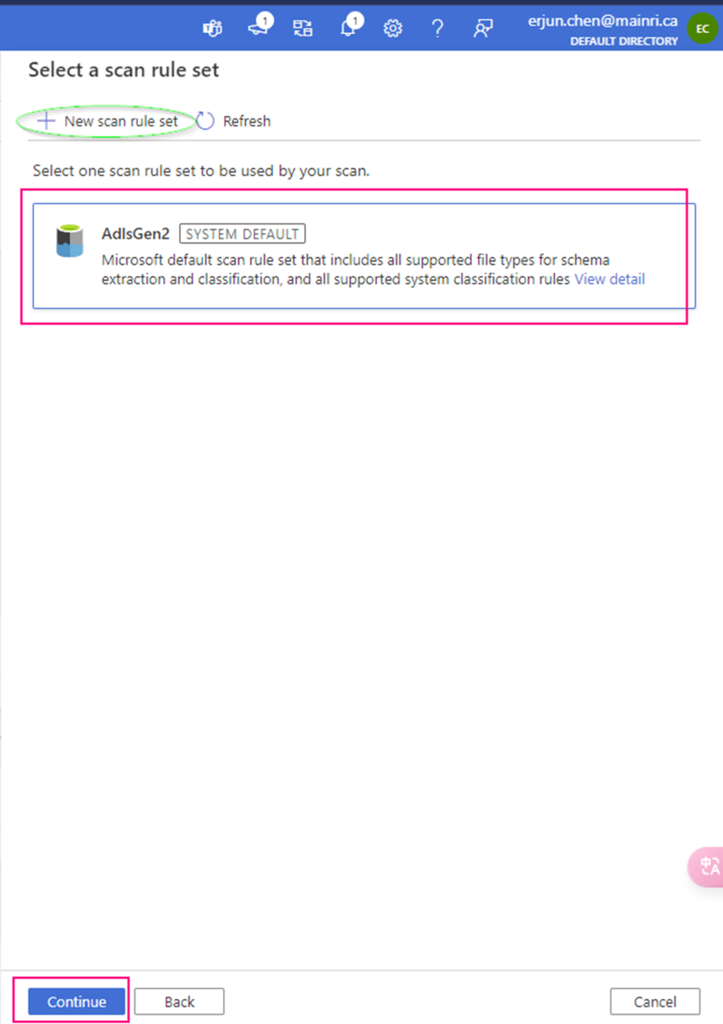
Select scan rule set
We have talked the rile sets in last article. You are able to add even more new scan rule set at this step if you like, or use default Azure System default scan rule set.
Set a scan trigger
Click the continue, you can setup trigger to scan, either once or recurring.
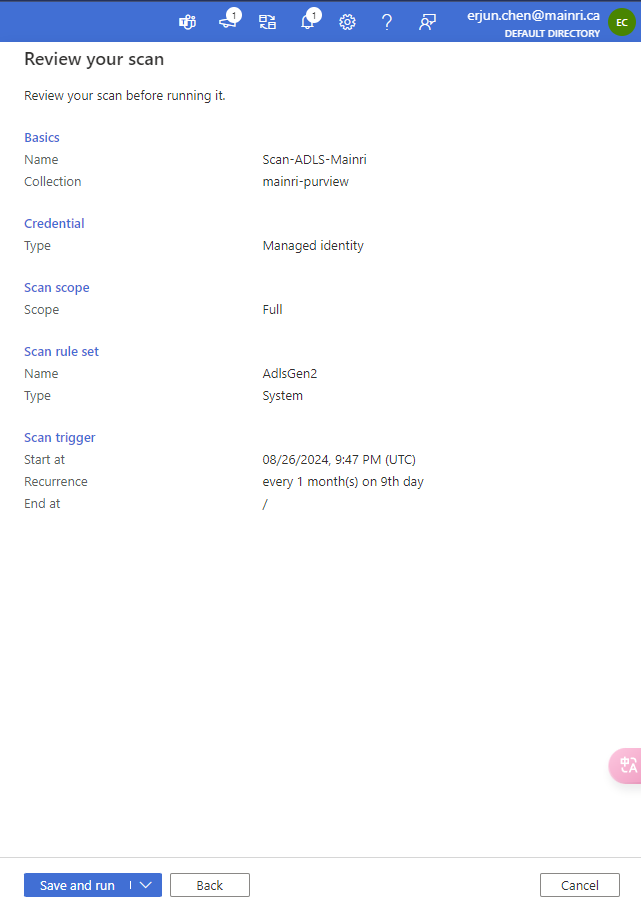
We complete the scan configuration. We have chance to review the configuration if ok save and run the scan progress or back to change it.
You can see this by clicking “view detail”
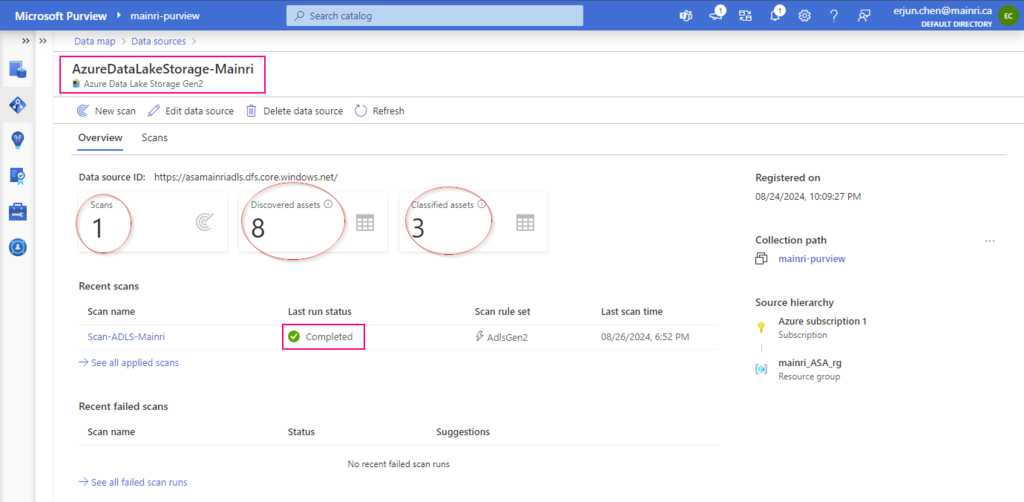
You will see this once the scan progress completed.
In this article I will provide a fully Metadata driven solution about using Azure Data Factory (ADF) or Synapse Analytics (ASA) incrementally copy multiple data sets one time from SharePoint Online (SPO) then sink them to ADSL Gen2.
Previously, I have published articles regarding ADF or ASA working with SPO. if you are interested in specifics matters, please look at related articles from here , or email me at william . chen @ mainri.ca (please remove spaces from email account 🙂 ).
Scenario and Requirements
Metadata driven. All metadata are save on SharePoint list, such as TenantID, ClientID, SPO site name, ADLS account, inspecting offset days for increment loading …. etc.
Initial full load, then monitor data set status, once it update, incrementally load, for example, on daily basis.
Solution
Retrieves metadata >> retrieves “client Secret” >> request access token >> insect and generate interests data list >> iteratively copy interest data sink to destination storage.
Prerequisite
Register SharePoint (SPO) application in Azure Active Directory (AAD).
Grant SPO site permission to registered application in AAD.
Provision Resource Group, ADF (ASA) and ADLS in your Azure Subscription.
I have other articles to talk those in detail. If you need review, please go to
Let us begin , Step by Step in detail, I will mention key points for every steps.
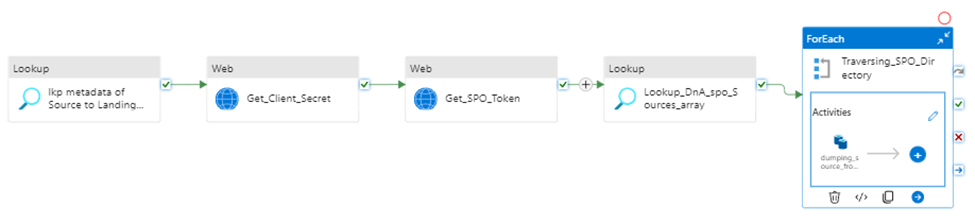
Step1:
Using Lookup activity to retrieve all metadata from SharePoint Online
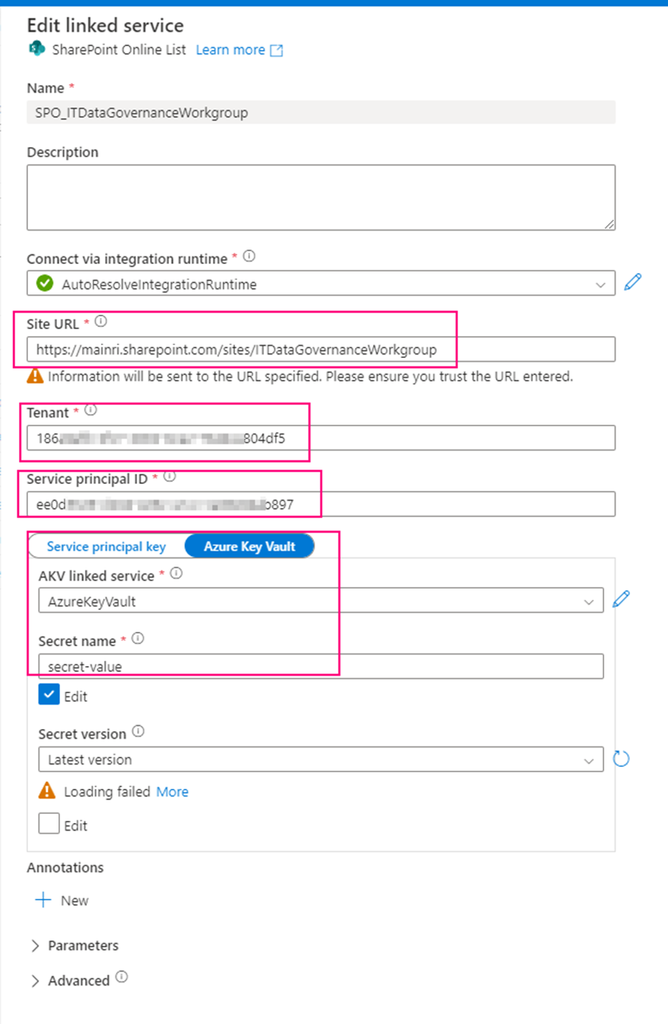
Firstly, create a SharePoint on Line List type Linked Service – SPO_ITDataGovernanceWorkgroup you need provide:
SharePoint site URL, you should replace it by using yours. it looks like htts://[your_domain].sharepoint.sites/[your_site_name]. mine is https://mainri.sharepoint.com/sites/ITDataGovernanceWorkgroup.
Tenant ID. The tenant ID under which your application resides. You can find it from Azure portal Microsoft Entra ID (formerly called Azure AD) overview page.
Service principal ID (Client ID) The application (client) ID of your application registered in Microsoft Entra ID. Make sure to grant SharePoint site permission to this application.
Service principal Key The client secret of your application registered in Microsoft Entra ID. mine is save in Azure Key Vault
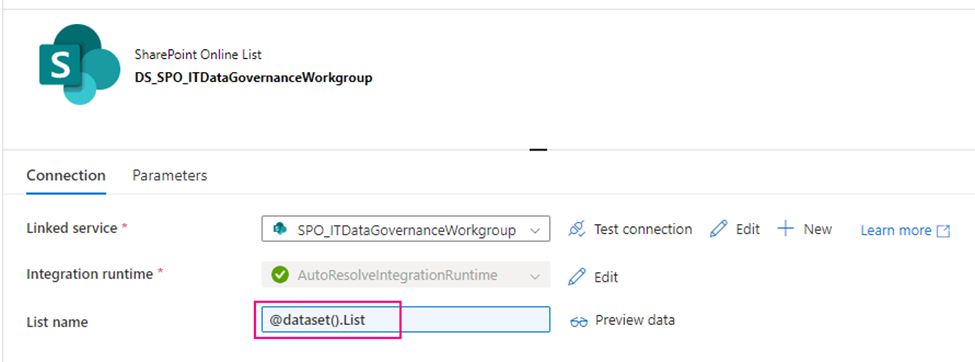
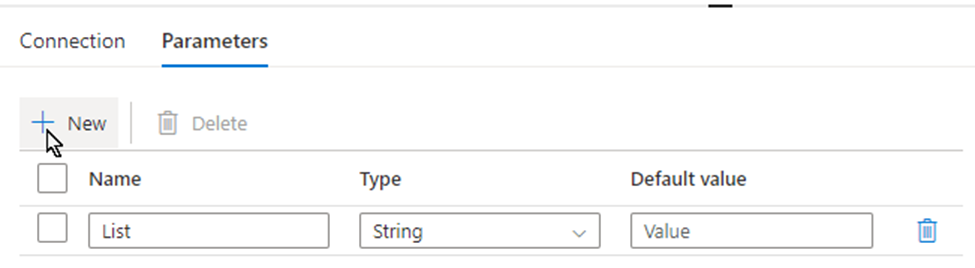
secondly, using above Linked Service create a SharePoint type Dataset – DS_SPO_ITDataGovernanceWorkgroup parametrize the dataset.
I name the parameter “List“, This parameter lets lookup activity knows where your metadata resides. (mine is called SourceToLanding)
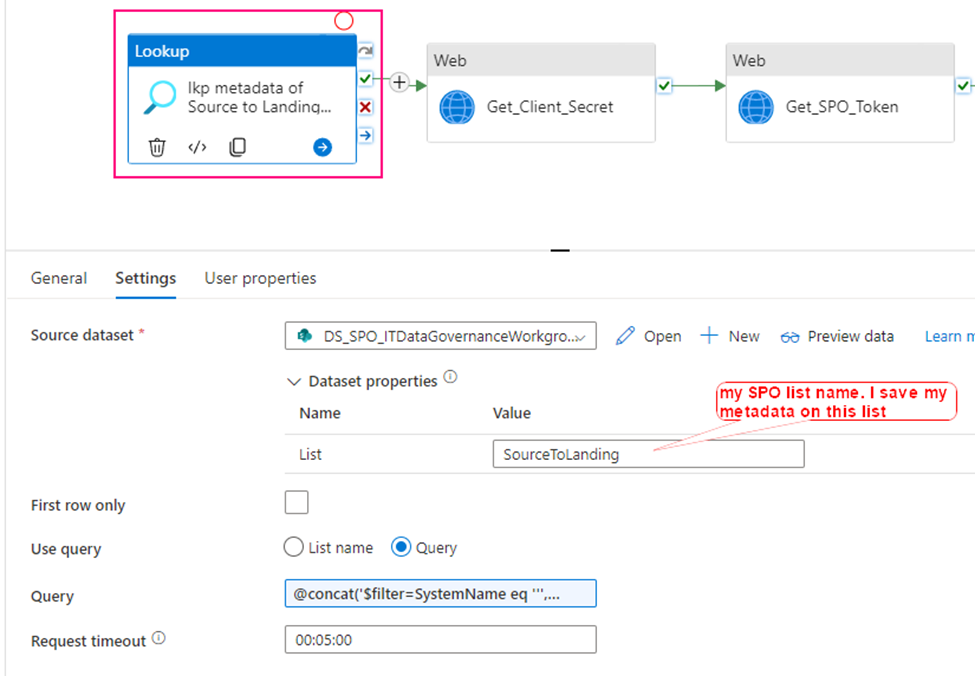
Now, we are ready to configure the Lookup activity
Source dataset: use above created dataset – DS_SPO_ITDataGovernanceWorkgroup
Query: @concat(‘$filter=SystemName eq ”’,pipeline().parameters.System,”’ and StatusValue eq ”Active”’)
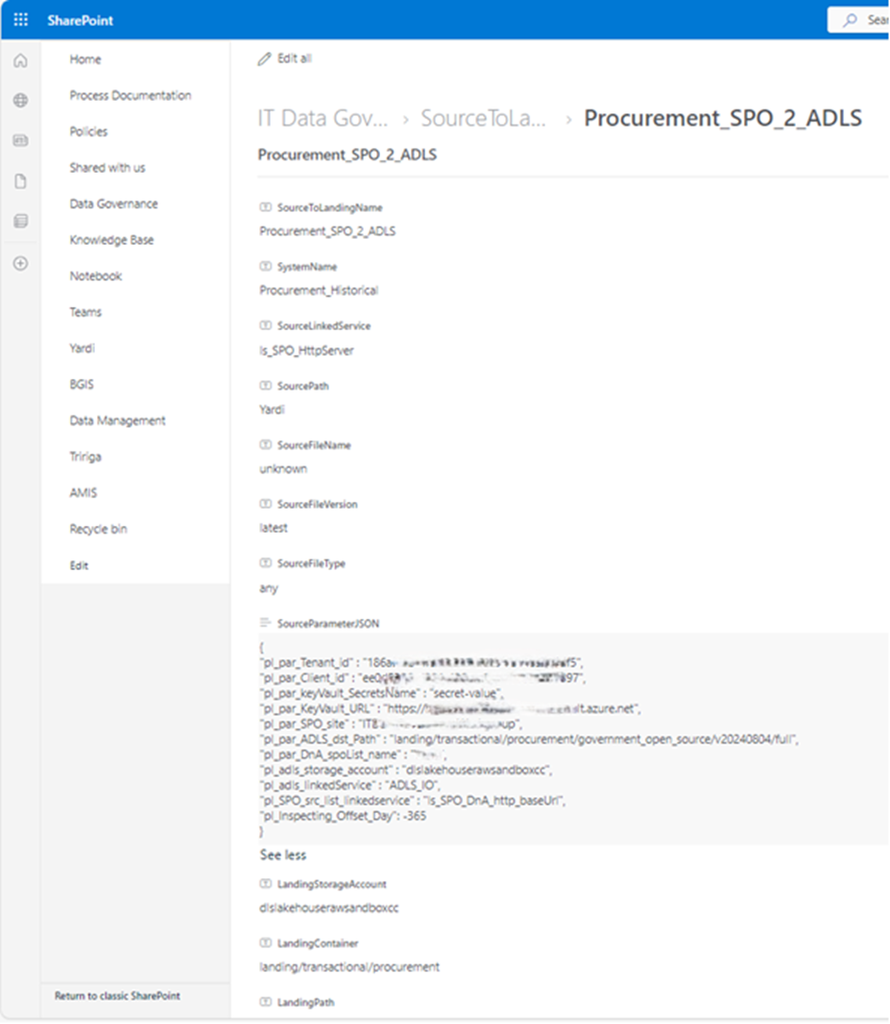
This query filters out my interest SPO list where my metadata saves. My metadata list in SPO looks like this
This lookup activity return metadata retrieved from SPO list. Looks like this.
response is json format. My “SourceParameterJSON” value is string, but it well match json format, could be covert to json.
Step 2:
Get Client Secret
To get SPO access token, we need: Tenant ID, Client ID, and Client Secret
Tenant ID: You can get this from Azure Entra ID (former Azure active Directory)
Client ID: When you register your application at Azure Entra ID, azure Entra ID will generate one, called Application ID (Client ID). You can get this from Azure Portal >>Entra ID
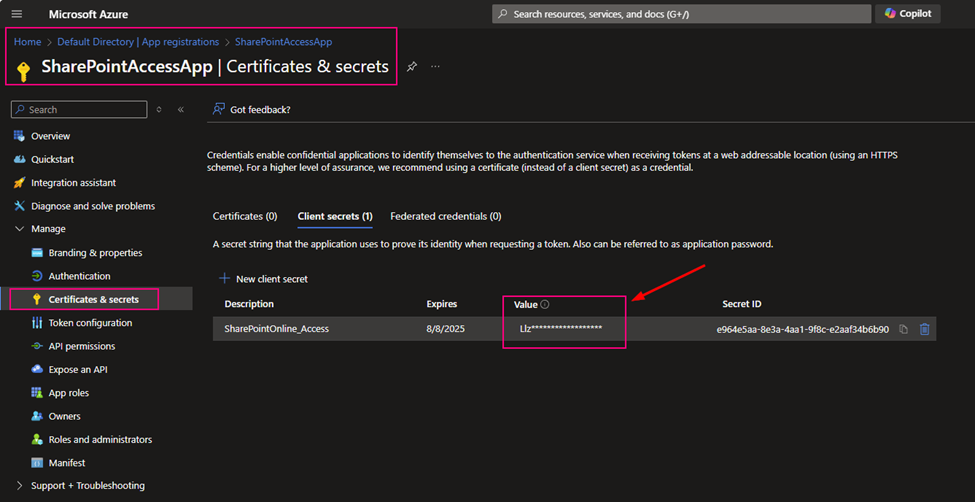
Client Secret: After you registered your application at Azure Entra ID, you build a certificate secret from Azure Entra ID, and you immediately copied and kept that value. The value will not reappear after that process anymore.
As I mentioned above, my client Secret is saved in azure Key-vault. To get Client Secret, use Web Activity to retrieve Client Secret (if you have the client Secret on hand, you can skip this activity, directly move to next activity Get SPO Token)
Method: GET
Authentication: System Assigned Managed Identity
Resource: https://vault.azure.net
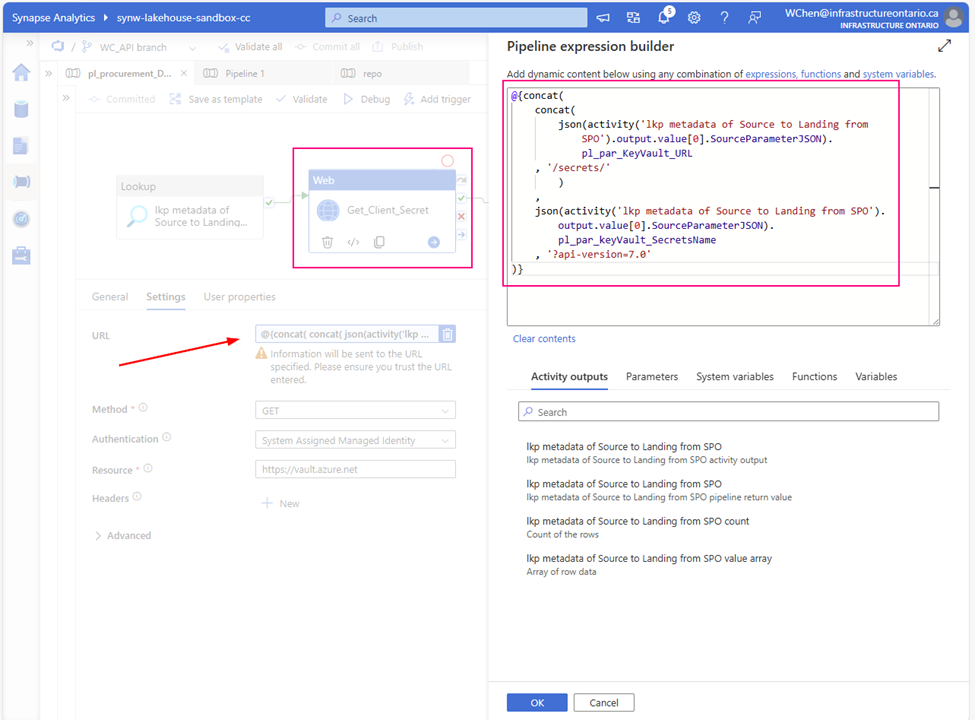
URL:
@{concat( concat( json(activity(‘lkp metadata of Source to Landing from SPO’).output.value[0].SourceParameterJSON).pl_par_KeyVault_URL , ‘/secrets/’ ) , json(activity(‘lkp metadata of Source to Landing from SPO’).output.value[0].SourceParameterJSON).pl_par_keyVault_SecretsName , ‘?api-version=7.0′ )}
Attention: from above URL content, you can see. this SourceParameterJSON section matches well with json format. BUT it is NOT json, it is a string, so I convert the string to json. ?api-version=7.0 is another key point. You must add to your URL
Create a Web Activity to get the access token from SharePoint Online:
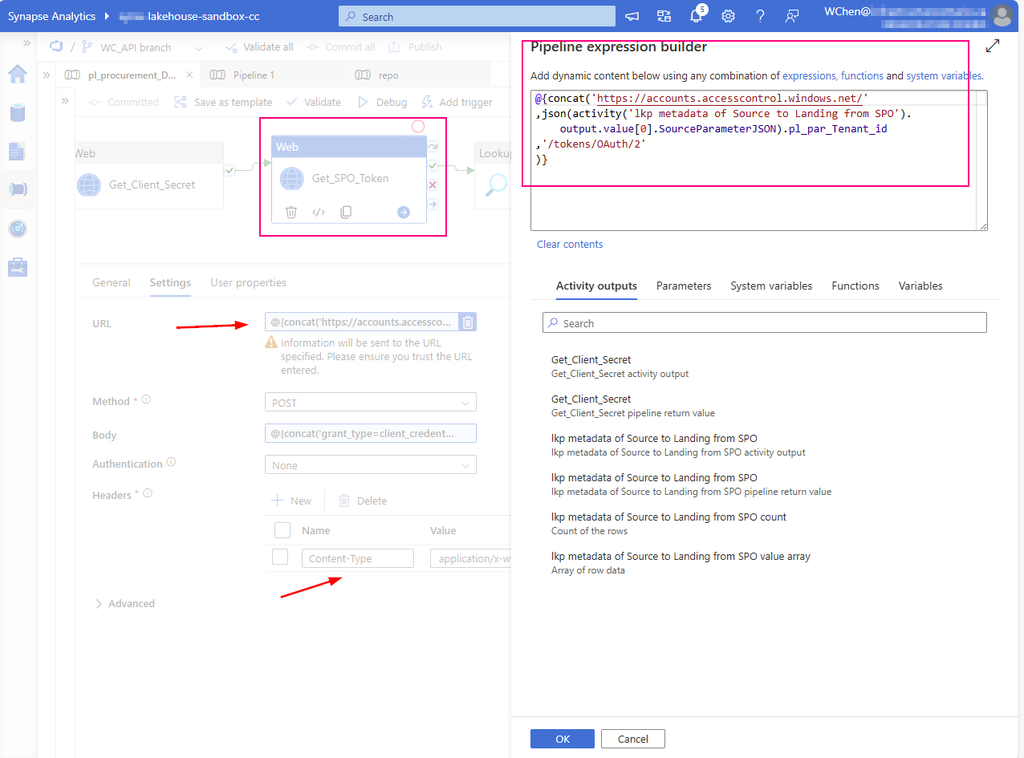
URL: https://accounts.accesscontrol.windows.net/[Tenant-ID]/tokens/OAuth/2. Replace the tenant ID.
mine looks : @{concat(‘https://accounts.accesscontrol.windows.net/’ ,json(activity(‘lkp metadata of Source to Landing from SPO’).output.value[0].SourceParameterJSON).pl_par_Tenant_id ,’/tokens/OAuth/2′ )}
Replace the client ID (application ID), client secret (application key), tenant ID, and tenant name (of the SharePoint tenant).
mine looks: @{concat(‘grant_type=client_credentials&client_id=’ , json(activity(‘lkp metadata of Source to Landing from SPO’).output.value[0].SourceParameterJSON).pl_par_Client_id , ‘@’ , json(activity(‘lkp metadata of Source to Landing from SPO’).output.value[0].SourceParameterJSON).pl_par_Tenant_id ,’&client_secret=’ , activity(‘Get_Client_Secret’).output.value , ‘&resource=00000003-0000-0ff1-ce00-000000000000/infrastructureontario.sharepoint.com@’ , json(activity(‘lkp metadata of Source to Landing from SPO’).output.value[0].SourceParameterJSON).pl_par_Tenant_id )}
Attention: As mentioned at Step 2 , pay attention to json convert for section “SourceParameterJSON”
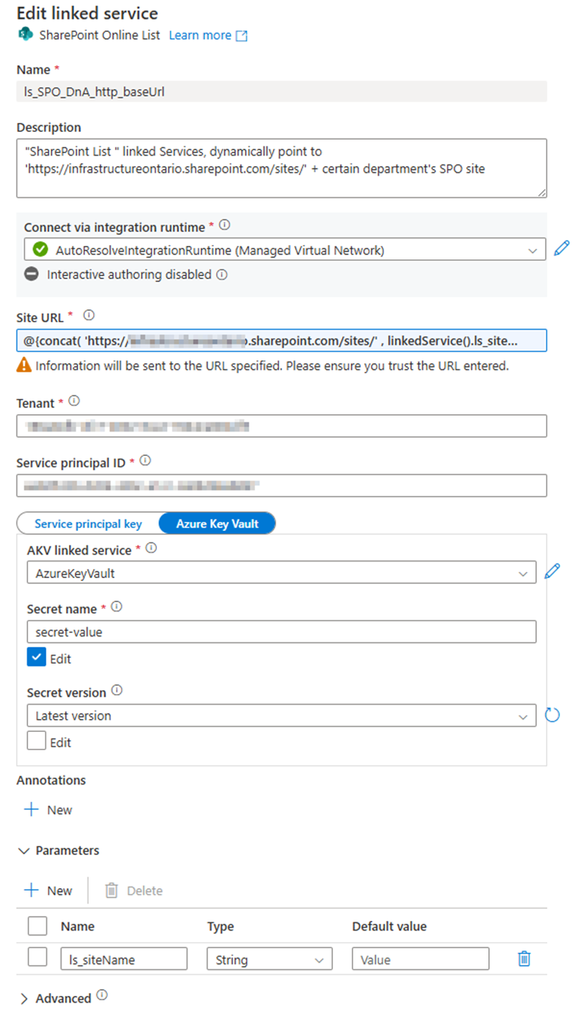
Called: “ls_SPO_DnA_http_baseUrl”, Parameteriz the Linked Service
Provide:
SharePoint site URL Pattern: https://<your domain>.sharepoint.com/sites/<SPO site Name> Replace <your domain> and <SPO site Name> Mine looks: https://mainri.sharepoint.com/sites/dataengineering
Tenant ID
Service principal (or says clientID, applicationID)
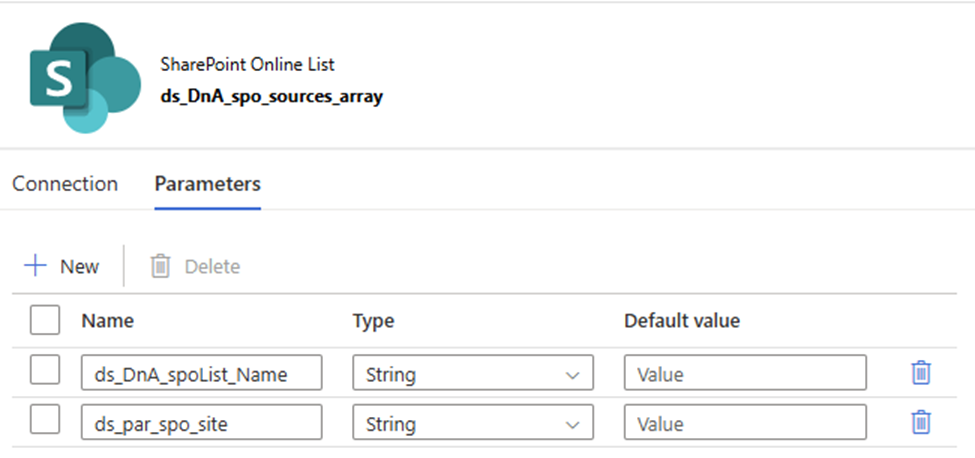
2. Create a SharePoint List type Dataset, Called “ds_DnA_spo_sources_array” and parameteriz the dataset.
Linked service: ls_SPO_DnA_http_baseUrl (you just created)
Parameter:
ds_DnA_spoList_Name
ds_par_spo_site
The dataset looks
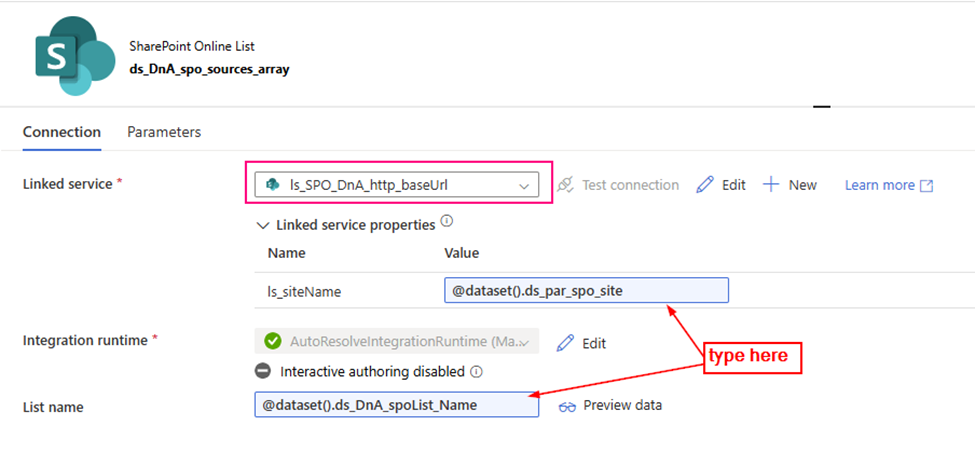
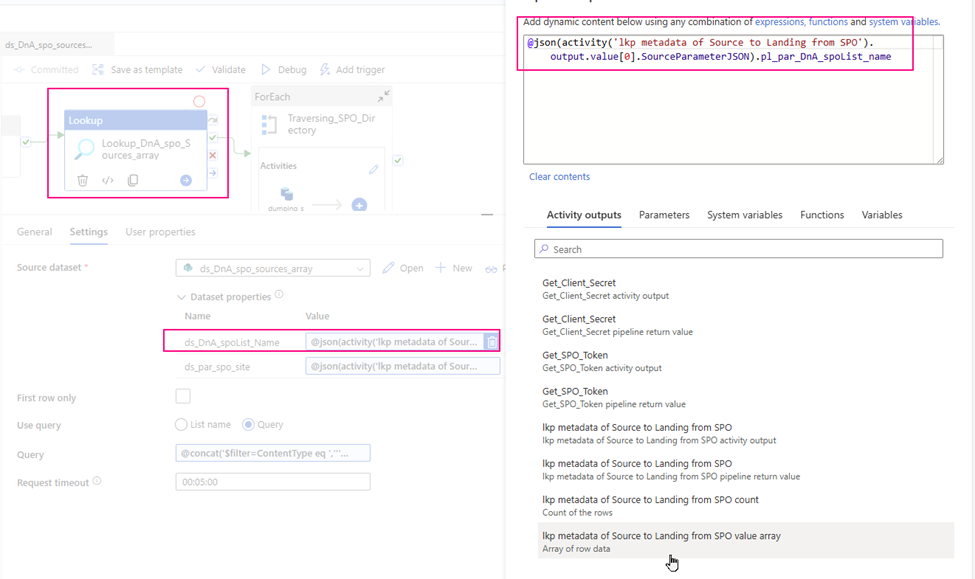
3. configure the Lookup Activity
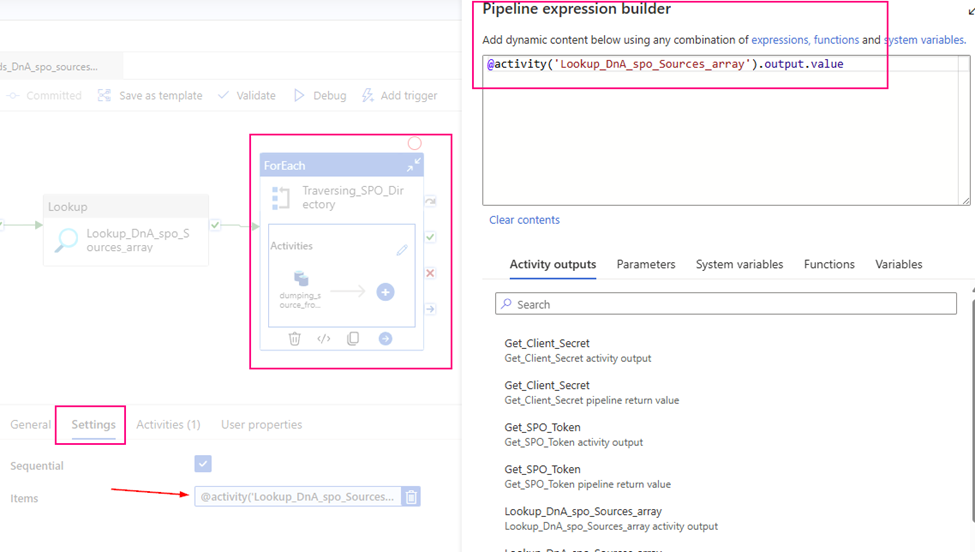
Use up steam activities return results to configure lookup activity.
source dataset: ds_DnA_spo_sources_array
Dynamic content: ds_DnA_spoList_Name: @json(activity(‘lkp metadata of Source to Landing from SPO’).output.value[0].SourceParameterJSON).pl_par_DnA_spoList_name
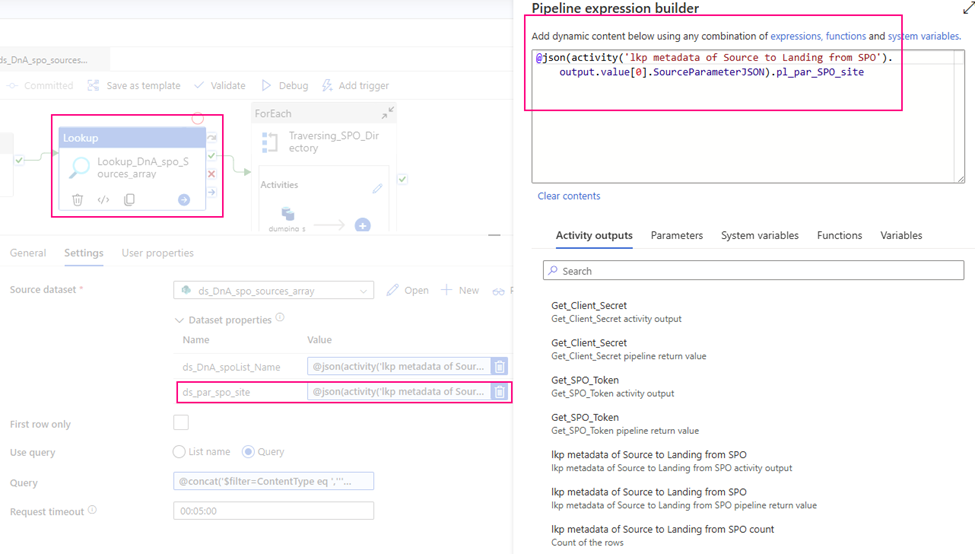
ds_par_spo_site: @json(activity(‘lkp metadata of Source to Landing from SPO’).output.value[0].SourceParameterJSON).pl_par_SPO_site
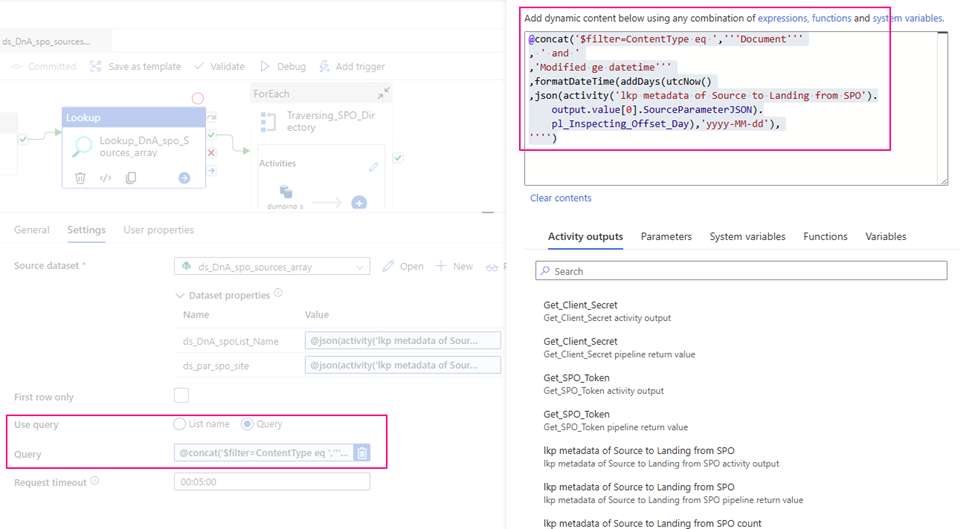
Query: I incrementally ingest data, so I use query to filter out interest items only.
@concat(‘$filter=ContentType eq ‘,”’Document”’ , ‘ and ‘ ,’Modified ge datetime”’ ,formatDateTime(addDays(utcNow() ,json(activity(‘lkp metadata of Source to Landing from SPO’).output.value[0].SourceParameterJSON).pl_Inspecting_Offset_Day),’yyyy-MM-dd’), ””)
The value of ‘GetFileByServerRelativeUrl’ is our key point of work. It points to the specific URL location of the dataset. In fact, all upstream work efforts are aimed at generating specific content for this link item!
Cheers, we are almost there!
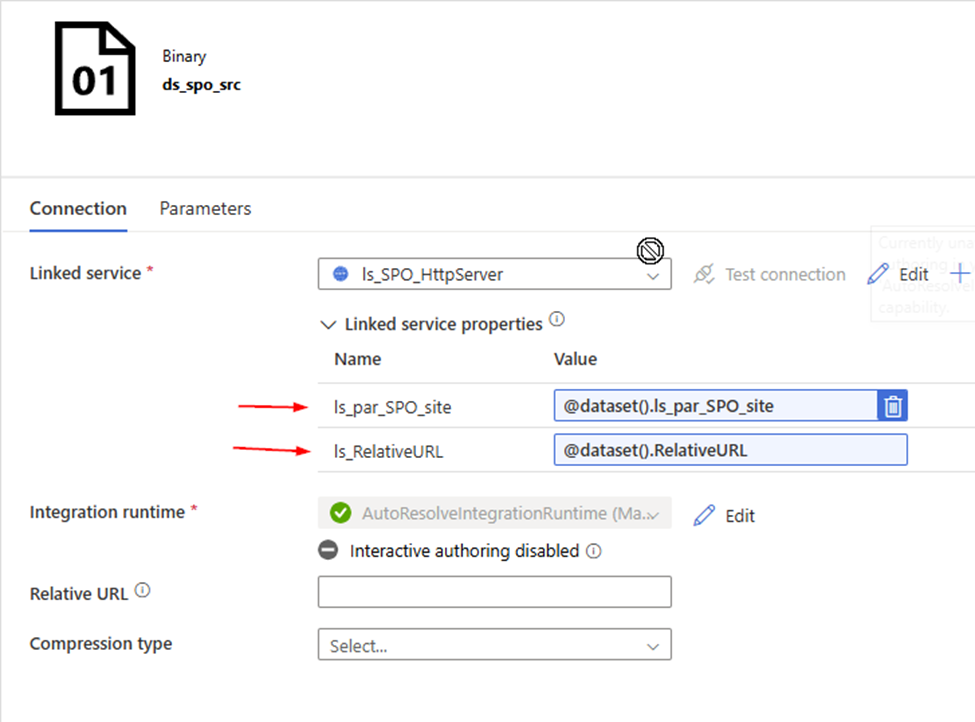
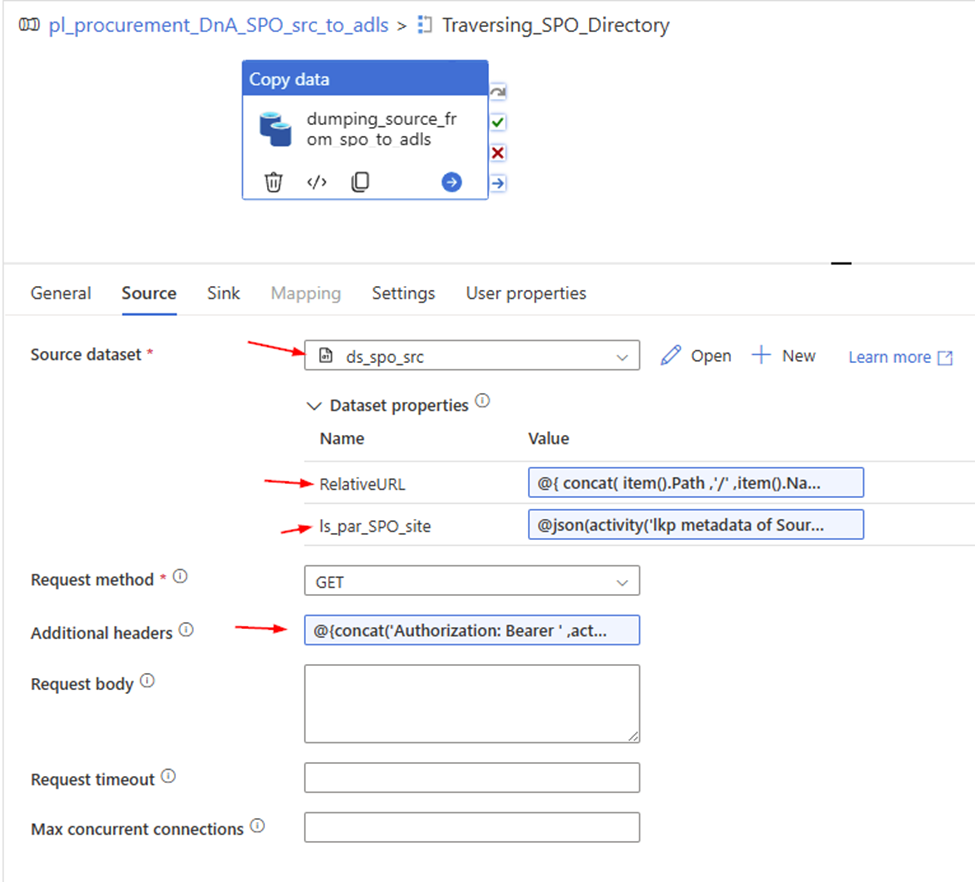
2. Create a Http Binary source dataset , called “ds_spo_src”, Parameterize it
Parameter: RelativeURL ls_par_SPO_site
Linked Service: ls_SPO_HttpServer , we just created.
3. Configure copy activity’s “Source”
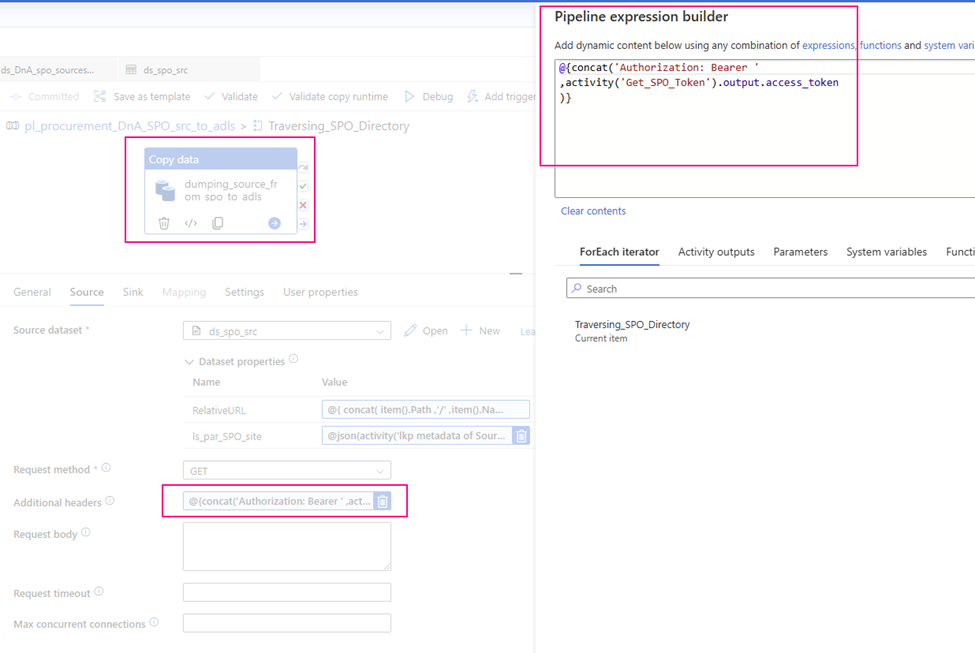
Request method: GET
Source dataset: ds_spo_src
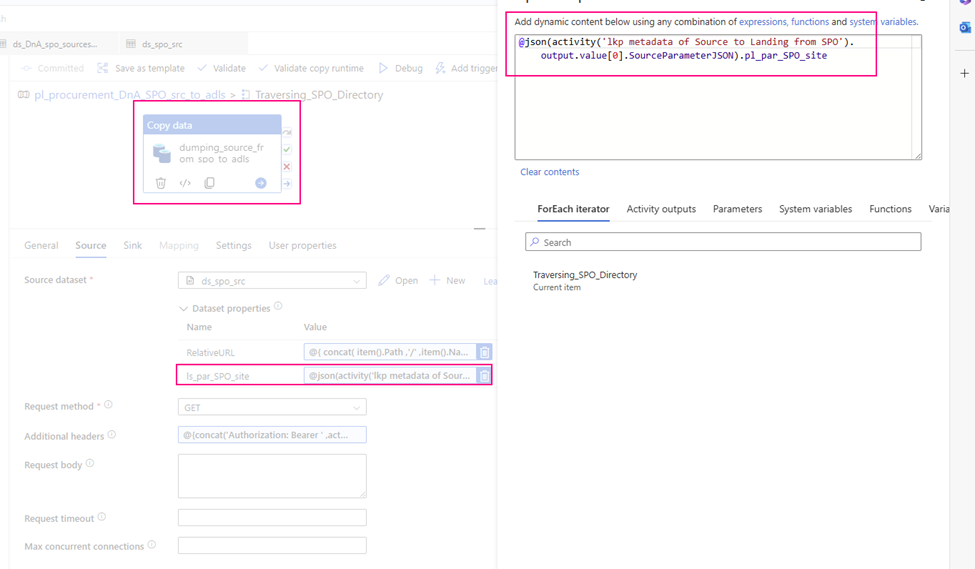
RelativeURL:
@{ concat( item().Path ,’/’ ,item().Name ) }
ls_par_SPO_site:
@json(activity(‘lkp metadata of Source to Landing from SPO’).output.value[0].SourceParameterJSON).pl_par_SPO_site