This can be a string representing the data type (e.g., "int", "double", "string", etc.) or a PySpark DataType object (like IntegerType(), StringType(), FloatType(), etc.).
Common Data Types:
IntegerType(), "int": For integer values.
DoubleType(), "double": For double (floating-point) values.
FloatType(), "float": For floating-point numbers.
StringType(), "string": For text or string values.
DateType(), "date": For date values.
TimestampType(), "timestamp": For timestamps.
BooleanType(), "boolean": For boolean values (true/false).
from pyspark.sql.functions import col
# Cast a string column to integer
df1 = df.withColumn("age_int", col("age").cast("int"))
df1.printSchema()
==output==
root
|-- id: long (nullable = true)
|-- age: long (nullable = true)
|-- age_int: integer (nullable = true)
# Cast 'id' from long to string and 'age' from long to double
df_casted = df.withColumn("id", col("id").cast("int")) \
.withColumn("age", col("age").cast("double"))
df_casted.show()
df_casted.printSchema()
==output==
+---+----+
| id| age|
+---+----+
| 1|25.0|
| 2|12.0|
| 3|40.0|
+---+----+
root
|-- id: string (nullable = true)
|-- age: double (nullable = true)
filter (), where (),
filter () or where () function is used to filter rows from a DataFrame based on a condition or set of conditions. It works similarly to SQL’s WHERE clause,
df.filter(condition) df.where(condition)
Condition (for ‘filter’)
& (AND)
| (OR)
~ (NOT)
== (EQUAL)
all “filter” can change to “where”, vice versa.
sample dataframe
+------+---+-------+
| Name|Age|Salary|
+------+---+-------+
| Alice| 30| 50000|
| Bob| 25| 30000|
|Alicia| 40| 80000|
| Ann| 32| 35000|
+------+---+-------+
# Filter rows where age is greater than 30 AND salary is greater than 50000
df.filter((df["age"] > 30) & (df["salary"] > 50000))
df.where((df["age"] > 30) & (df["salary"] > 50000))
+------+---+------+
| Name|Age|Salary|
+------+---+------+
|Alicia| 40| 80000|
+------+---+------+
# Filter rows where age is less than 25 OR salary is less than 40000
df.filter((df["age"] < 25) | (df["salary"] < 40000))
df.where((df["age"] < 25) | (df["salary"] < 40000))
+----+---+------+
|Name|Age|Salary|
+----+---+------+
| Bob| 25| 30000|
| Ann| 32| 35000|
+----+---+------+
like ()
like() function is used to perform pattern matching on string columns, similar to the SQL LIKE operator
df.filter(df[“column_name”].like(“pattern”))
Pattern
%: Represents any sequence of characters.
_: Represents a single character.
pattern is case sensitive.
sample dataframe
+------+---+
| Name|Age|
+------+---+
| Alice| 30|
| Bob| 25|
|Alicia| 28|
| Ann| 32|
+------+---+
# Filtering names that start with 'Al'
df.filter(df["Name"].like("Al%")).show()
+------+---+
| Name|Age|
+------+---+
| Alice| 30|
|Alicia| 28|
+------+---+
# Filtering names that end with 'n'
df.filter(df["Name"].like("%n")).show()
+----+---+
|Name|Age|
+----+---+
| Ann| 32|
+----+---+
# Filtering names that contain 'li'
df.filter(df["Name"].like("%li%")).show()
+------+---+
| Name|Age|
+------+---+
| Alice| 30|
|Alicia| 28|
+------+---+
# Filtering names where the second letter is 'l'
df.filter(df["Name"].like("A_l%")).show()
+----+---+
|Name|Age|
+----+---+
+----+---+
nothing found in this pattern
In PySpark, there isn’t an explicit “if-else" statement construct like in regular Python. Instead, PySpark provides several ways to implement conditional logic using functions such as when (), otherwise (), withColumn(),expr (), UDF etc.
using when (), expr() look at following sections. now focus on UDF to implement “if — then — else –” logic”.
from pyspark.sql.functions import udf
from pyspark.sql.types import StringType
# Define a Python function for age classification
def classify_age(age):
if age >= 18:
return 'Adult'
else:
return 'Minor'
# Register the function as a UDF
classify_age_udf = udf(classify_age, StringType())
# Create the DataFrame
data = [(1, 25), (2, 12), (3, 40)]
df = spark.createDataFrame(data, ["id", "age"])
+---+---+
| id|age|
+---+---+
| 1| 25|
| 2| 12|
| 3| 40|
+---+---+
# Apply the UDF to create a new column with the if-else logic
df = df.withColumn("age_group", classify_age_udf(df["age"]))
df.show()
+---+---+---------+
| id|age|age_group|
+---+---+---------+
| 1| 25| Adult|
| 2| 12| Minor|
| 3| 40| Adult|
+---+---+---------+
In this example:
The function classify_age behaves like a Python if-else statement.
The UDF (classify_age_udf) applies this logic to the DataFrame.
when (), otherwise ()
when function in PySpark is used for conditional expressions, similar to SQL’s CASE WHEN clause.
Syntax
from pyspark.sql.functions import when when(condition, value).otherwise(default_value)
Parameters
condition: A condition that returns a boolean (True/False). If this condition is true, the function will return the specified value.
value: The value to return when the condition is true.
otherwise(default_value): An optional method that specifies the default value to return when the condition is false.
The expr () function allows you to use SQL expressions as a part of the DataFrame transformation logic.
Syntax
expr () from pyspark.sql.functions import expr expr(sql_expression)
Parameters:
sql_expression: A string containing a SQL-like expression to be applied to the DataFrame. It can contain any valid SQL operations, such as arithmetic operations, column references, conditional logic, or function calls.
The selectExpr() method allows you to directly select columns or apply SQL expressions on multiple columns simultaneously, similar to SQL’s SELECT statement.
Syntax
from pyspark.sql.functions import selectExpr
df.selectExpr(*sql_expressions)
Parameters:
sql_expression: A list of SQL-like expressions (as strings) that define how to transform or select columns. Each expression can involve selecting a column, renaming it, applying arithmetic, or adding conditions using SQL syntax.
from pyspark.sql.functions import selectExpr
# Select specific columns and rename them using selectExpr()
df = df.selectExpr("id", "value * 2 as double_value", "value as original_value")
df.show()
==output==
+---+------------+--------------+
| id|double_value|original_value|
+---+------------+--------------+
| 1| 20| 10|
| 2| 40| 20|
| 3| 60| 30|
+---+------------+--------------+
# Use CASE WHEN to categorize values
df = df.selectExpr("id", "value", "CASE WHEN value >= 20 THEN 'High' ELSE 'Low' END as category")
df.show()
+---+-----+--------+
| id|value|category|
+---+-----+--------+
| 1| 10| Low|
| 2| 20| High|
| 3| 30| High|
+---+-----+--------+
# Apply multiple transformations and expressions
df = df.selectExpr("id", "value", "value * 2 as double_value", "CASE WHEN value >= 20 THEN 'High' ELSE 'Low' END as category")
df.show()
+---+-----+------------+--------+
| id|value|double_value|category|
+---+-----+------------+--------+
| 1| 10| 20| Low|
| 2| 20| 40| High|
| 3| 30| 60| High|
+---+-----+------------+--------+
comparison: expr () and selectExpr ()
Key Differences expr () is used when you want to apply SQL-like expressions in the middle of a transformation, typically within withColumn() or filter(). selectExpr() is used when you want to apply multiple expressions in a single statement to transform and select columns, much like a SQL SELECT statement.
Feature
expr()
selectExpr()
Purpose
Used for applying single SQL expressions
Used for applying multiple SQL expressions
Typical Usage
Inside select(), withColumn(), filter()
As a standalone method for multiple expressions
Operates On
Individual column expressions
Multiple expressions at once
Flexibility
Allows complex operations on a single column
Simpler for multiple transformations
Example
df.select(expr("age + 5").alias("new_age"))
df.selectExpr("age + 5 as new_age", "age * 2")
Use Case
Fine-grained control of expressions in various transformations
Quickly apply and select multiple expressions as new columns
Conclusion expr (): Ideal for transforming or adding individual columns using SQL expressions. selectExpr (): Useful for selecting, renaming, and transforming multiple columns at once using SQL-like syntax.
na.fill ()
na.fill(): Used to replace null values in DataFrames.
#Fill null values in a specific column with a default value (e.g., 0)
df = df.na.fill({"value": 0})
df.show()
==output==
+---+-----+
| id|value|
+---+-----+
| 1| 10|
| 2| 20|
| 3| 30|
| 4| 0|
+---+-----+
coalescs ()
coalesce function is used to return the first non-null value among the columns you provide
Syntax
from pyspark.sql.functions import coalesce coalesce(col1, col2, …, colN)
from pyspark.sql.functions import coalesce
# Return the first non-null value from multiple columns
df = df.withColumn("first_non_null", coalesce(col("column1"), col("column2"), col("column3")))
isin ()
isin function is used to check if a value belongs to a list or set of values.
Syntax from pyspark.sql.functions import col col(“column_name”).isin(value1, value2, …, valueN)
from pyspark.sql.functions import col
# Check if the value is between 20 and 30
df = df.withColumn("value_between_20_and_30", col("value").between(20, 30)).show()
df.show()
==output==
+---+-----+-----------------------+
| id|value|value_between_20_and_30|
+---+-----+-----------------------+
| 1| 15| false|
| 2| 20| true|
| 3| 30| true|
| 4| 36| false|
note: it included boundary value - "20" and "30"
isNull (), isNotNull ()
PySpark provides isNull and isNotNull functions to check for null values in DataFrame columns.
It’s a “transformation”. withColumn() add or replace a column_name in a DataFrame. In other words, if “column_name” exists, replace/change the existing column, otherwise, add “column_name” as new column.
"column_name": The name of the new or existing column.
expression: Any transformation, calculation, or function applied to create or modify the column.
Basic Column Creation (with literal values)
from pyspark.sql.functions import lit # Add a column with a constant value df_new = df.withColumn(“New_Column”, lit(100)) ===output=== ID Name Grade New_Column 1 Alice null 100 2 Bob B 100 3 Charlie C 100
# Add a new column, no value df_new = df.withColumn(“New_Column”, lit(None)) ===output=== ID Name Grade New_Column 1 Alice null null 2 Bob B null 3 Charlie C null
Arithmetic Operation
from pyspark.sql.functions import col # Create a new column based on arithmetic operations df_arithmetic = df.withColumn(“New_ID”, col(“ID”) * 2 + 5) df_arithmetic.show() ===output=== ID Name Grade New_ID 1 Alice null 7 2 Bob B 9 3 Charlie C 11
Using SQL Function
you can use functions like concat(), substring(), when(), length(), etc.
from pyspark.sql.functions import concat, lit # Concatenate two columns with a separator df_concat = df.withColumn(“Full_Description”, concat(col(“Name”), lit(” has ID “), col(“ID”)))
Conditional Logic
Using when() and otherwise() is equivalent to SQL’s CASE WHEN expression.
from pyspark.sql.functions import when
# Add a new column with conditional logic
df_conditional = df.withColumn("Is_Adult", when(col("ID") > 18, "Yes").otherwise("No"))
df_conditional.show()
String Function
You can apply string functions like upper(), lower(), or substring()
from pyspark.sql.functions import upper # Convert a column to uppercase df_uppercase = df.withColumn(“Uppercase_Name”, upper(col(“Name”))) df_uppercase.show()
Type Casting
You can cast a column to a different data type.
Cast the ID column to a string
# Cast the ID column to a string df_cast = df.withColumn(“ID_as_string”, col(“ID”).cast(“string”)) df_cast.show()
Handling Null Values
create columns that handle null values using coalesce() or fill()
Coalesce:
This function returns the first non-null value among its arguments.
from pyspark.sql.functions import coalesce # Return non-null value between two columns df_coalesce = df.withColumn(“NonNullValue”, coalesce(col(“Name”), lit(“Unknown”))) df_coalesce.show()
Fill Missing Values:
# Replace nulls in a column with a default value df_fill = df.na.fill({“Name”: “Unknown”}) df_fill.show()
Creating Columns with Complex Expressions
create columns based on more complex expressions or multiple transformations at once.
# Create a column with multiple transformations df_complex = df.withColumn( “Complex_Column”, concat(upper(col(“Name”)), lit(“_”), col(“ID”).cast(“string”)) ) df_complex.show(truncate=False)
example
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, lit, concat, when, upper, coalesce
# Initialize Spark session
spark = SparkSession.builder.appName("withColumnExample").getOrCreate()
# Create a sample DataFrame
data = [(1, "Alice", None), (2, "Bob", "B"), (3, "Charlie", "C")]
df = spark.createDataFrame(data, ["ID", "Name", "Grade"])
# Perform various transformations using withColumn()
df_transformed = df.withColumn("ID_Multiplied", col("ID") * 10) \
.withColumn("Full_Description", concat(upper(col("Name")), lit(" - ID: "), col("ID"))) \
.withColumn("Pass_Status", when(col("Grade") == "C", "Pass").otherwise("Fail")) \
.withColumn("Non_Null_Grade", coalesce(col("Grade"), lit("N/A"))) \
.withColumn("ID_as_String", col("ID").cast("string"))
# Show the result
df_transformed.show(truncate=False)
==output==
ID Name Grade ID_Multiplied Full_Description Pass_Status Non_Null_Grade ID_as_String
1 Alice null 10 ALICE - ID: 1 Fail N/A 1
2 Bob B 20 BOB - ID: 2 Fail B 2
3 Charlie C 30 CHARLIE - ID: 3 Pass C 3
select ()
select () is used to project (select) a set of columns or expressions from a DataFrame. This function allows you to choose and work with specific columns, create new columns, or apply transformations to the data.
Syntax
DataFrame.select(*cols)
Commonly Used PySpark Functions with select()
col(column_name): Refers to a column.
alias(new_name): Assigns a new name to a column.
lit(value): Adds a literal value.
round(column, decimals): Rounds off the values in a column.
Renaming Columns:
df.select(df["column1"].alias("new_column1"), df["column2"]).show()
Using Expressions:
from pyspark.sql import functions as F
df.select(F.col("column1"), F.lit("constant_value"), (F.col("column2") + 10).alias("modified_column2")).show()
Performing Calculations
df.select((df["column1"] * 2).alias("double_column1"), F.round(df["column2"], 2).alias("rounded_column2")).show()
Handling Complex Data Types (Struct, Array, Map):
df.select("struct_column.field_name").show()
Selecting with Wildcards:
While PySpark doesn’t support SQL-like wildcards directly, you can achieve similar functionality using selectExpr (discussed below) or other methods like looping over df.columns.
df.select([c for c in df.columns if “some_pattern” in c]).show()
Using selectExpr ()
df.selectExpr(“column1”, “column2 + 10 as new_column2”).show()
df = spark.read \
.format("parquet") \
.option("mergeSchema", "true") \ # Merges schemas of all files (useful when reading from multiple files with different schemas)
.option("pathGlobFilter", "*.parquet") \ # Read only specific files based on file name patterns
.option("recursiveFileLookup", "true") \ # Recursively read files from directories and subdirectories
.load("/path/to/parquet/file/or/directory")
Options
mergeSchema: When reading Parquet files with different schemas, merge them into a single schema.
true (default: false)
pathGlobFilter: Allows specifying a file pattern to filter which files to read (e.g., “*.parquet”).
recursiveFileLookup: Reads files recursively from subdirectories.
true (default: false)
modifiedBefore/modifiedAfter: Filter files by modification time. For example: .option(“modifiedBefore”, “2023-10-01T12:00:00”) .option(“modifiedAfter”, “2023-01-01T12:00:00”)
maxFilesPerTrigger: Limits the number of files processed in a single trigger, useful for streaming jobs.
schema: Provides the schema of the Parquet file (useful when reading files without inferring schema).
Programmatically pass a list of file paths. These options help streamline your data ingestion process when dealing with multiple Parquet files in Databricks.
Write to parquet
Syntax
# Writing a Parquet file
df.write \
.format("parquet") \
.mode("overwrite") \ # Options: "overwrite", "append", "ignore", "error"
.option("compression", "snappy") \ # Compression options: none, snappy, gzip, lzo, brotli, etc.
.option("maxRecordsPerFile", 100000) \ # Max number of records per file
.option("path", "/path/to/output/directory") \
.partitionBy("year", "month") \ # Partition the output by specific columns
.save()
Options
compression: .option(“compression”, “snappy”)
Specifies the compression codec to use when writing files. Options: none, snappy (default), gzip, lzo, brotli, lz4, zstd, etc.
multiline: option (“multiline”, “true”) If your JSON files contain multiple lines for a single record, you need to enable multiline.
Mode: option (“mode”, “FAILFAST”) Determines the behavior when the input file contains corrupt records. Available options: PERMISSIVE (default): Tries to parse all records and puts corrupt records in a new column _corrupt_record. DROPMALFORMED: Drops the corrupted records. FAILFAST: Fails when corrupt records are encountered.
mode: mode(“overwrite”) Specifies how to handle existing data. Available options: · overwrite: Overwrites existing data. · append: Appends to existing data. · ignore: Ignores write operation if the file already exists. · error (default): Throws an error if the file exists
compression: option(“compression”, “gzip”) Specifies compression for the output file. Available options include gzip, bzip2, none (default).
dateFormat: option(“dateFormat”, “yyyy-MM-dd”) Sets the format for date fields during writing.
timestampFormat: option(“timestampFormat”, “yyyy-MM-dd’T’HH:mm:ss”) Sets the format for timestamp fields during writing.
ignoreNullFields: option(“ignoreNullFields”, “true”) Ignores null fields when writing JSON.
lineSep: option(“lineSep”, “\r\n”) Custom line separator (default is \n).
#Reading the Complex JSON df = spark.read.option(“multiline”, “true”).json(“/path/to/complex.json”)
Step 1: Flattening Nested Objects
Flattening the Nested JSON, use PySpark’s select and explode functions to flatten the structure.
from pyspark.sql.functions import col
df_flattened = df.select(
col("name"),
col("age"),
col("address.street").alias("street"),
col("address.city").alias("city"),
col("contact.phone").alias("phone"),
col("contact.email").alias("email")
)
df_flattened.show(truncate=False)
This will flatten the address and contact fields.
Step 2: Flattening Arrays with explode
For fields that contain arrays (like orders), you can use explode to flatten the array into individual rows.
from pyspark.sql.functions import explode
df_flattened_orders = df.select(
col("name"),
col("age"),
col("address.street").alias("street"),
col("address.city").alias("city"),
col("contact.phone").alias("phone"),
col("contact.email").alias("email"),
explode(col("orders")).alias("order")
)
# Now flatten the fields inside the "order" structure
df_final = df_flattened_orders.select(
col("name"),
col("age"),
col("street"),
col("city"),
col("phone"),
col("email"),
col("order.id").alias("order_id"),
col("order.item").alias("order_item"),
col("order.price").alias("order_price")
)
df_final.show(truncate=False)
Output
name
age
street
city
phone
email
order_id
order_item
order_price
John
30
123 Main St
New York
123-456-7890
john@example.com
1
Laptop
999.99
John
30
123 Main St
New York
123-456-7890
john@example.com
2
Mouse
49.99
Key Functions Used:
col(): Accesses columns of the DataFrame.
alias(): Renames a column.
explode(): Converts an array into multiple rows, one for each element in the array.
Generalize for Deeper Nested Structures
For deeply nested JSON structures, you can apply this process recursively by continuing to use select, alias, and explode to flatten additional layers.
In PySpark, we can read from and write to CSV files using DataFrameReader and DataFrameWriter with the csv method. Here’s a guide on how to work with CSV files in PySpark:
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
# Define the schema
schema = StructType([
StructField("column1", IntegerType(), True), # Column1 is Integer, nullable
StructField("column2", StringType(), True), # Column2 is String, nullable
StructField("column3", StringType(), False) # Column3 is String, non-nullable
])
#or simple format
schema="col1 INTEGER, col2 STRING, col3 STRING, col4 INTEGER"
Example
Read CSV file with header, infer schema, and specify null value
# Read a CSV file with header, infer schema, and specify null value
df = spark.read.format("csv") \
.option("header", "true") \ # Use the first row as the header
.option("inferSchema", "true")\ # Automatically infer the schema
.option("sep", ",") \ # Specify the delimiter
.load("path/to/input_file.csv")\ # Load the file
.option("nullValue", "NULL" # Define a string representation of null
# Read multiple CSV files with header, infer schema, and specify null value
df = spark.read.format("csv") \
.option("inferSchema", "true")\
.option("sep", ",") \
.load("path/file1.csv", "path/file2.csv", "path/file3.csv")\
.option("nullValue", "NULL")
# Read folder all CSV files with header, infer schema, and specify null value
df = spark.read.format("csv") \
.option("inferSchema", "true")\
.option("sep", ",") \
.load("/path_folder/)\
.option("nullValue", "NULL")
When you want to read multiple files into a single Dataframe, if schemas are different, load files into Separate DataFrames, then take additional process to merge them together.
# Write the result DataFrame to a new CSV file
result_df.write.format("csv") \
.option("header", "true") \
.mode("overwrite") \
.save("path/to/output_directory")
# Write DataFrame to a CSV file with header, partitioning, and compression
df.write.format("csv") \
.option("header", "true") \ # Write the header
.option("compression", "gzip") \ # Use gzip compression
.partitionBy("year", "month") \ # Partition the output by specified columns
.mode("overwrite") \ # Overwrite existing data
.save("path/to/output_directory") # Specify output directory
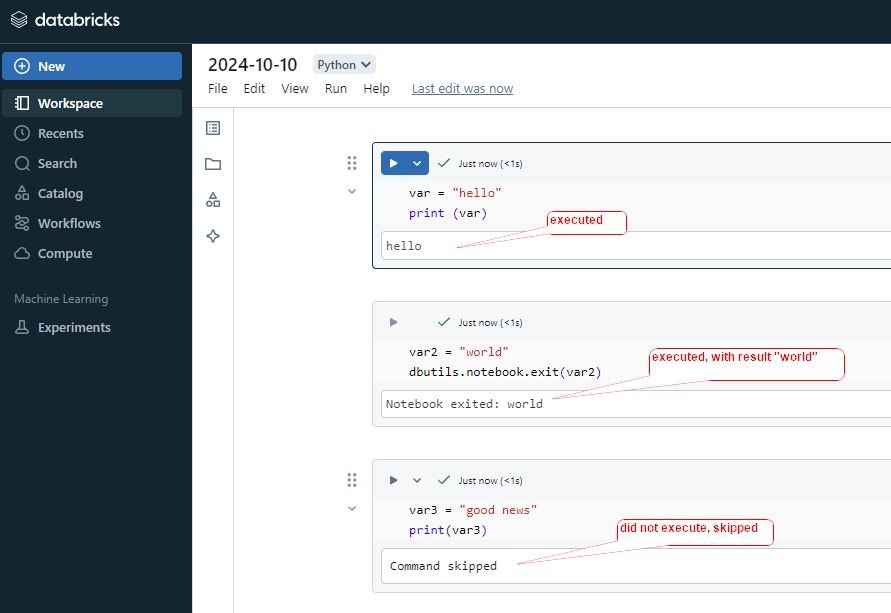
In Databricks, dbutils.notebook provides a set of utilities that allow you to interact with notebooks programmatically. This includes running other notebooks, exiting a notebook with a result, and managing notebook workflows.
Parent Notebook pass parameters to child notebook
run()
dbutils.notebook.run()
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value
The dbutils.notebook.run() function allows you to run another notebook from your current notebook. It also allows you to pass parameters to the called child notebook and capture the result of the execution.
notebook_path: The path to the notebook you want to run. This can be a relative or absolute path.
timeout_seconds: How long to wait before timing out. If the notebook does not complete within this time, an error will occur.
In other words, if the notebook completes before the timeout, it proceeds as normal, returning the result. However, if the notebook exceeds the specified timeout duration, the notebook run is terminated, and an error is raised.
arguments: A dictionary of parameters to pass to the called notebook. The called notebook can access these parameters via dbutils.widgets.get().
Parent notebooks
# Define parameters to pass to the child notebook
params = {
"param1": "value1",
"param2": "value2"
}
# Run the child notebook and capture its result
result =
dbutils.notebook.run("/Users/your-email@domain.com/child_notebook",
60, params)
# Print the result returned from the child notebook
print(f"Child notebook result:
{result}")
Parent notebook calls/runs his child notebook in python only, cannot use SQL
In the child notebook, you can retrieve the passed parameters using dbutils.widgets.get():
— Use the widget values in a query SELECT * FROM my_table WHERE column1 = ‘${getArgument(‘param1′)}’ AND column2 = ‘${getArgument(‘param2′)}’;
Child notebook returns values to parent notebook
When parent notebook run/call a child notebook using dbutils.notebook.run(), the child notebook can return a single value (usually a string) using dbutils.notebook.exit() return value to parent notebook. The parent notebook can capture this return value for further processing.
Key Points:
The value returned by dbutils.notebook.exit() must be a string.
The parent notebook captures this return value when calling dbutils.notebook.run().
exit()
dbutils.notebook.help() get help.
dbutils.notebook.exit(value: String): void
dbutils.notebook.exit() Exit a notebook with a result.
The dbutils.notebook.exit() function is used to terminate the execution of a notebook and return a value to the calling notebook.
After this executed, all below cells commend will skipped, will not execute.
Parent notebook uses child notebook returned value
Parent Notebook
#parent notebook
# Call the child notebook and pass any necessary parameters
result = dbutils.notebook.run("/Notebooks/child_notebook", 60, {"param1": "some_value"})
#use the child notebook returned value
print(f"I use the Returned result: {result}")
# Use the result for further logic
if result == "Success":
print("The child notebook completed successfully!")
else:
print("The child notebook encountered an issue.")
child Notebook
#child Notebook
# Simulate some processing (e.g., a query result or a status)
result_value = "Success"
# Return the result to the parent notebook
dbutils.notebook.exit(result_value)
Handling Complex Return Values
Since dbutils.notebook.exit()only returns a string, if you need to return a more complex object (like a dictionary or a list), you need to serialize it to a string format (like JSON) and then deserialize it in the parent notebook.
Child Notebook:
import json
# Simulate a complex return value (a dictionary)
result = {"status": "Success", "rows_processed": 1234}
# Convert the dictionary to a JSON string and exit
dbutils.notebook.exit(json.dumps(result))
Parent Notebook:
import json
# Run the child notebook
result_str = dbutils.notebook.run("/Notebooks/child_notebook", 60, {"param1": "some_value"})
# Convert the returned JSON string back into a dictionary
result = json.loads(result_str)
# Use the values from the result
print(f"Status: {result['status']}")
print(f"Rows Processed: {result['rows_processed']}")
Summary:
You can call child notebooks from a parent notebook using Python (dbutils.notebook.run()), but not with SQL directly.
You can pass parameters using widgets in the child notebook.
Python recommend to use dbutils.get(“parameterName”), still can use getArgument(“parameterName”)
SQL use getArgument(“parameterName”) in child notebook only.
Results can be returned to the parent notebook using dbutils.notebook.exit().
Please do not hesitate to contact me if you have any questions at William . chen @ mainri.ca
Schema Evolution in Databricks refers to the ability to automatically adapt and manage changes in the structure (schema) of a Delta Lake table over time. It allows users to modify the schema of an existing table (e.g., adding or updating columns) without the need for a complete rewrite of the data.
Key Features of Schema Evolution
Automatic Adaptation: Delta Lake can automatically evolve the schema of a table when new columns are added to the incoming data, or when data types change, if certain configurations are enabled.
Backward and Forward Compatibility: Delta Lake ensures that new data can be written to a table without breaking the existing schema. It also ensures that existing queries remain compatible, even if the schema changes.
Configuration for Schema Evolution
mergeSchema This option allows you to append new data with a schema that differs from the existing table schema. It merges the new schema into the table. Usage: Typically used when you are appending data.
overwriteSchema This option is used when you want to completely replace the schema of the table with the schema of the new data. Usage: Typically used when you are overwriting data
mergSchema
When new data has additional columns that aren’t present in the target Delta table, Delta Lake can automatically merge the new schema into the existing table schema.
# Append new data to the Delta table with automatic schema merging
df_new_data.write.format("delta").mode("append").option("mergeSchema", "true").save("/path/to/delta-table")
overwriteSchema
If you want to replace the entire schema (including removing existing columns), you can use the overwriteSchema option.
# Overwrite the existing Delta table schema with new data
df_new_data.write.format("delta").mode("overwrite").option("overwriteSchema", "true").save("/path/to/delta-table")
Configure spark.databricks.delta.schema.autoMerge
You can configure this setting at the following levels:
Session Level (applies to a specific session or job)
Cluster Level (applies to all jobs on the cluster)
Session-Level Configuration (Spark session level)
Once this is enabled, all write and merge operations in the session will automatically allow schema evolution.
# Enable auto schema merging for the session
spark.conf.set("spark.databricks.delta.schema.autoMerge.enabled", "true")
Cluster-Level Configuration
This enables automatic schema merging for all operations on the cluster without needing to set it in each job.
Go to your Databricks Workspace.
Navigate to Clusters and select your cluster.
Go to the Configuration tab.
Under Spark Config, add the following configuration: spark.databricks.delta.schema.autoMerge.enabled true
Please do not hesitate to contact me if you have any questions at William . chen @ mainri.ca
In Databricks, partitioning is a strategy used to organize and store large datasets into smaller, more manageable chunks based on specific column values. Partitioning can improve query performance and resource management when working with large datasets in Spark, especially in distributed environments like Databricks.
Key Concepts of Partitioning in Databricks
Partitioning in Tables:
When saving a DataFrame as a table or Parquet file in Databricks, you can specify partitioning columns to divide the data into separate directories. Each partition contains a subset of the data based on the values of the partitioning column(s).
Partitioning in DataFrames
Spark partitions data in-memory across nodes in the cluster to parallelize processing. Partitioning helps distribute the workload evenly across the cluster.
Types of Partitioning
Static Partitioning (Manual Partitioning)
When saving or writing data to a file or table, you can manually specify one or more columns to partition the data by. This helps when querying large tables, as Spark can scan only the relevant partitions instead of the entire dataset.
Dynamic Partitioning (Automatic Partitioning)
Spark automatically partitions a DataFrame based on the size of the data and available resources. The number of partitions is determined by Spark’s internal algorithm based on the data’s size and complexity.
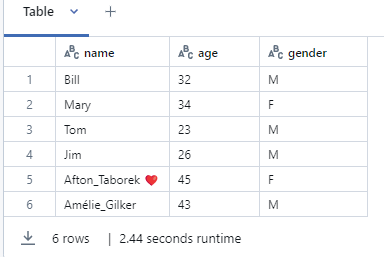
Let’s say, there is dataframe
Partitioning in Databricks File System (DBFS)
When writing data to files in Databricks (e.g., Parquet, Delta), you can specify partitioning columns to optimize reads and queries. For example, when you partition by a column, Databricks will store the data in different folders based on that column’s values.
# Example of saving a DataFrame with partitioning
df.write.partitionBy("year", "month").parquet("/mnt/data/name_partitioned")
In this example, the data will be saved in a directory structure like:
In Delta Lake (which is a storage layer on top of Databricks), partitioning is also a best practice to optimize data management and queries. When you define a Delta table, you can specify partitions to enable efficient query pruning, which results in faster reads and reduced I/O.
# Writing a Delta table with partitioning
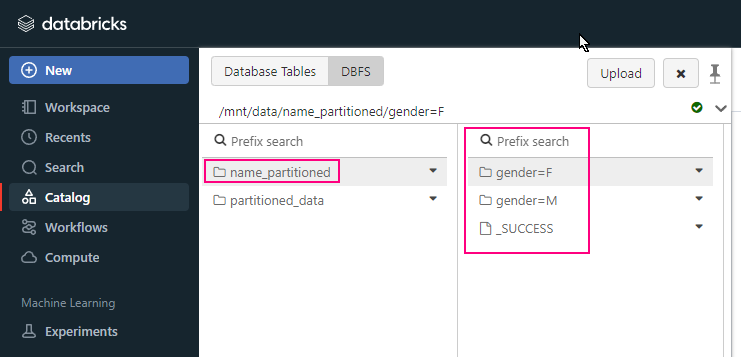
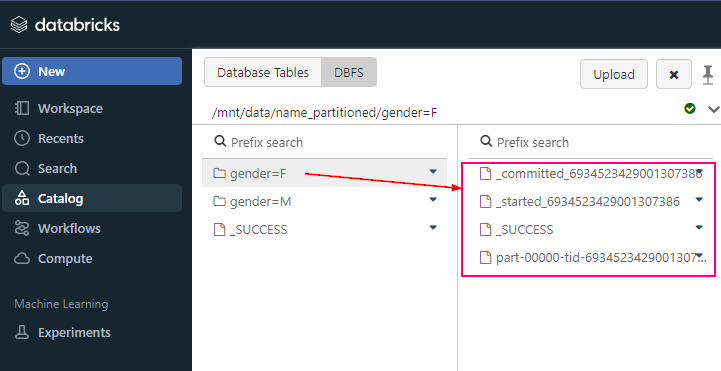
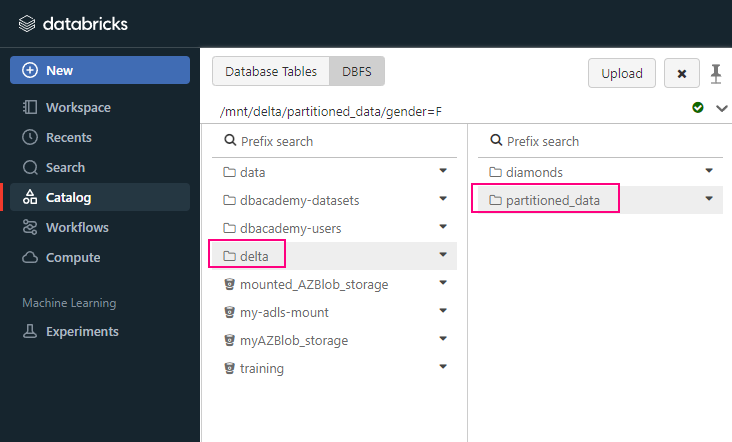
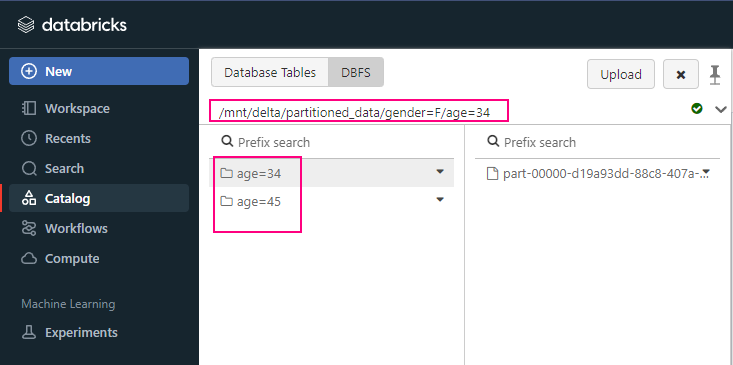
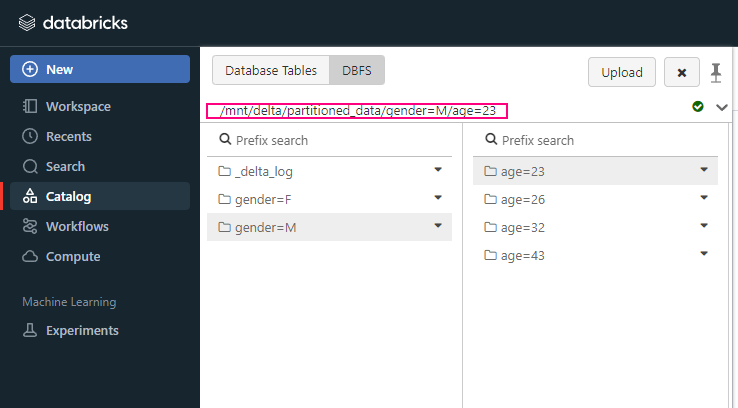
df.write.format("delta").partitionBy("gender", "age").save("/mnt/delta/partitioned_data")
In this example, the data will be saved in a directory structure like:
When working with in-memory Spark DataFrames in Databricks, you can manually control the number of partitions to optimize performance.
Repartition
This increases or decreases the number of partitions. This operation reshuffles the data, redistributing it into a new number of partitions.
df = df.repartition(10) # repartition into 10 partitions
Coalesce
This reduces the number of partitions without triggering a shuffle operation (which is often more efficient than repartition). This is a more efficient way to reduce the number of partitions without triggering a shuffle.
df = df.coalesce(5) # reduce partitions to 5
When to Use Partitioning
Partitioning works best when you frequently query the data using the columns you’re partitioning by. For example, partitioning by date (e.g., year, month, day) is a common use case when working with time-series data.
Don’t over-partition: Too many partitions can lead to small file sizes, which increases the overhead of managing the partitions.
Summary
Partitioning divides data into smaller, more manageable chunks.
It improves query performance by allowing Spark to read only relevant data.
You can control partitioning when saving DataFrames or Delta tables to optimize storage and query performance.
Use repartition() or coalesce() to manage in-memory partitions for better parallelization.
Use coalesce() to reduce partitions without shuffling.
Use repartition() when you need to rebalance data.