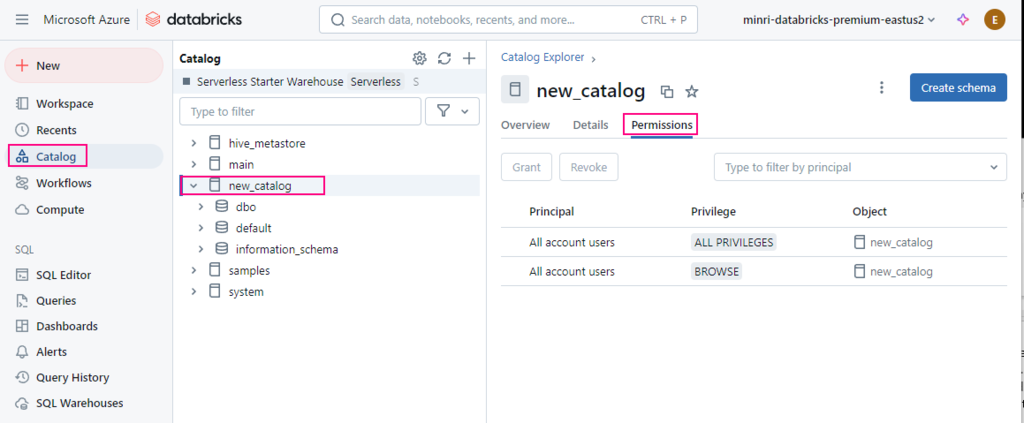
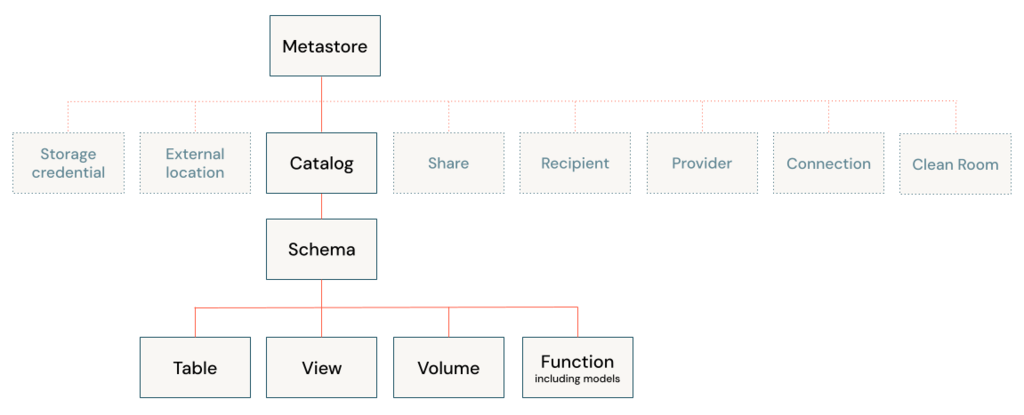
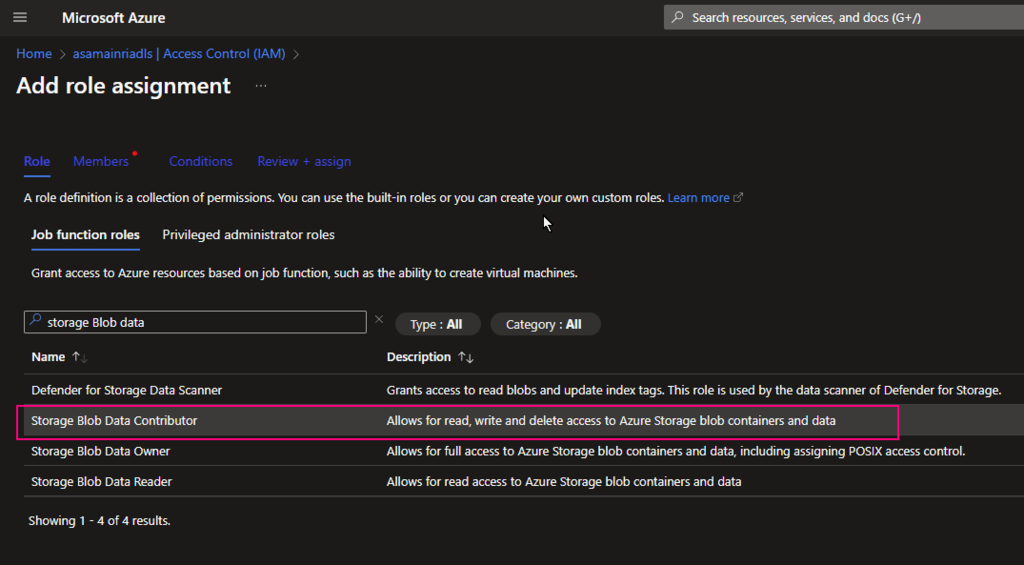
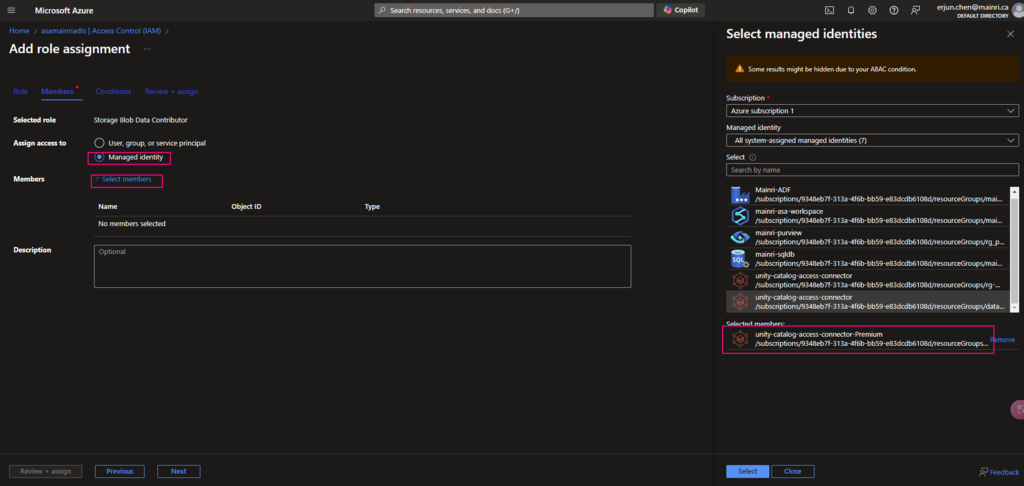
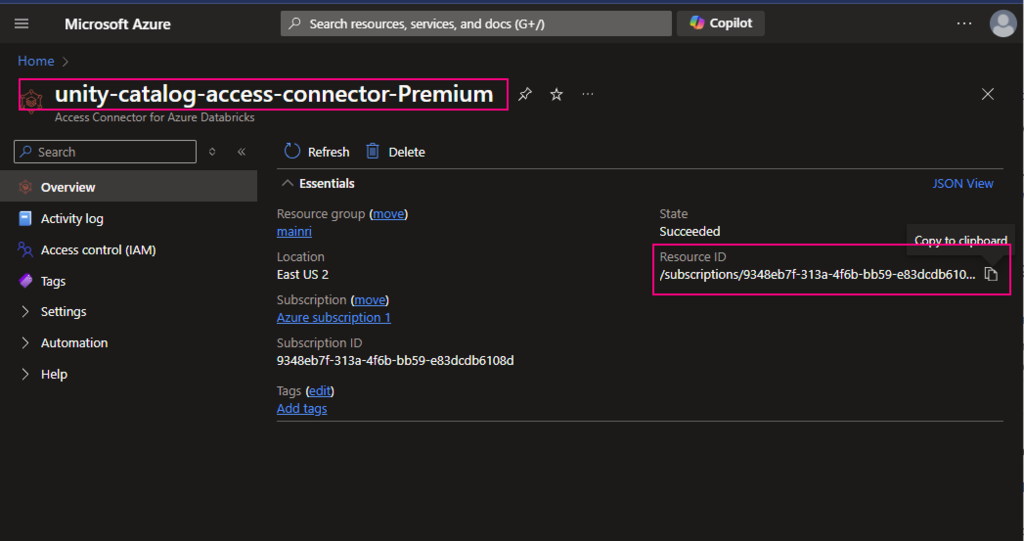
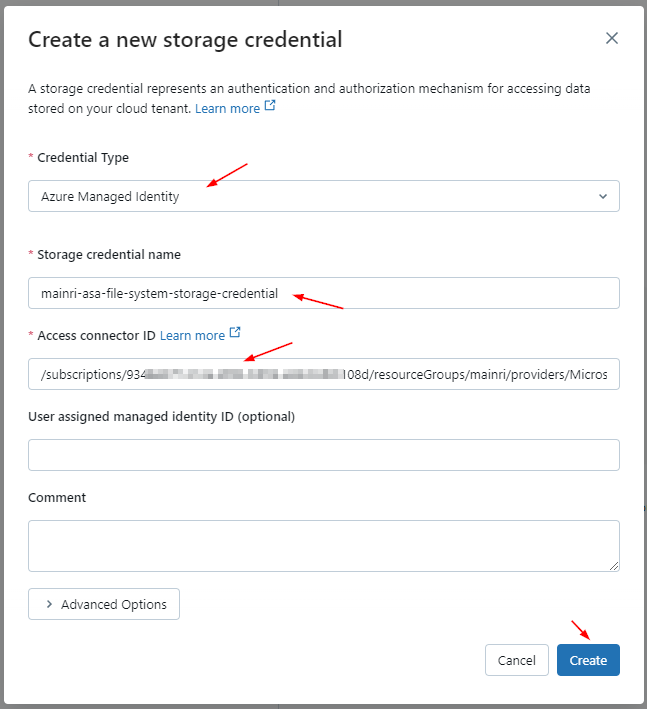
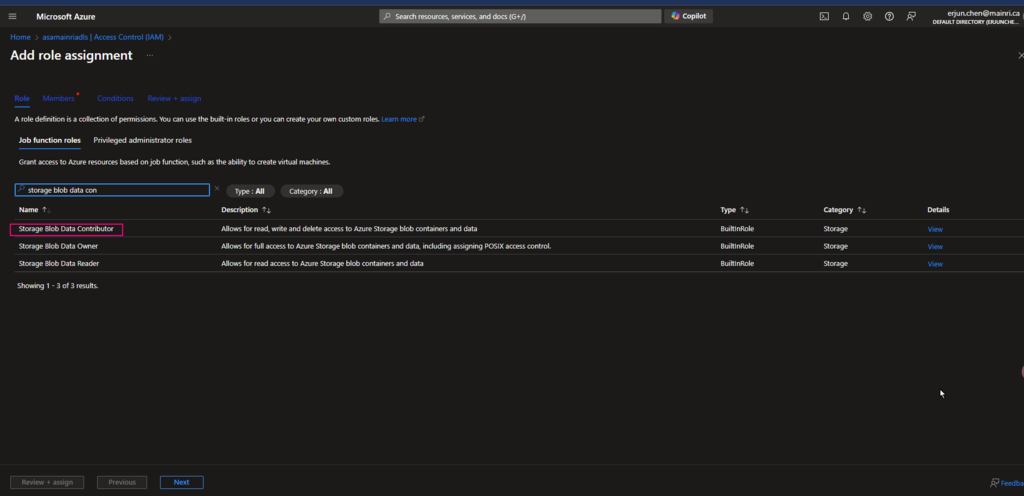
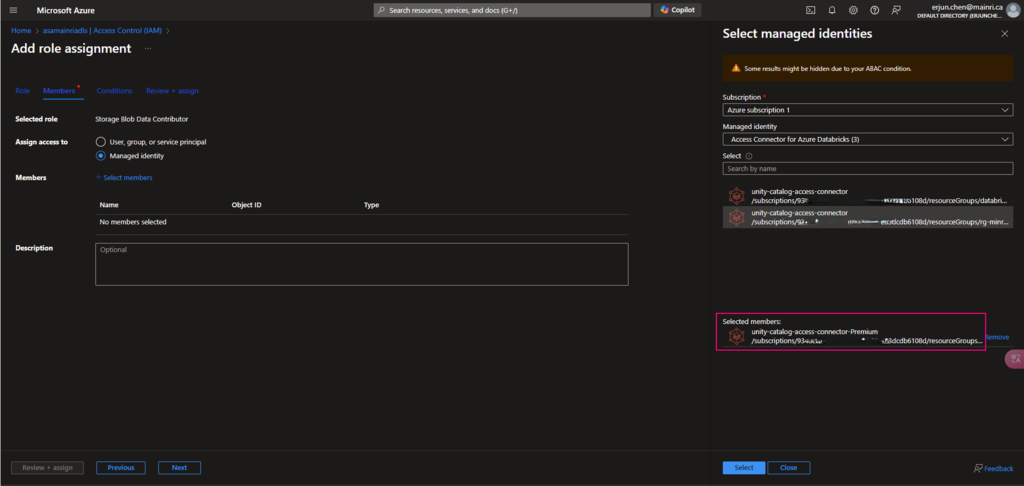
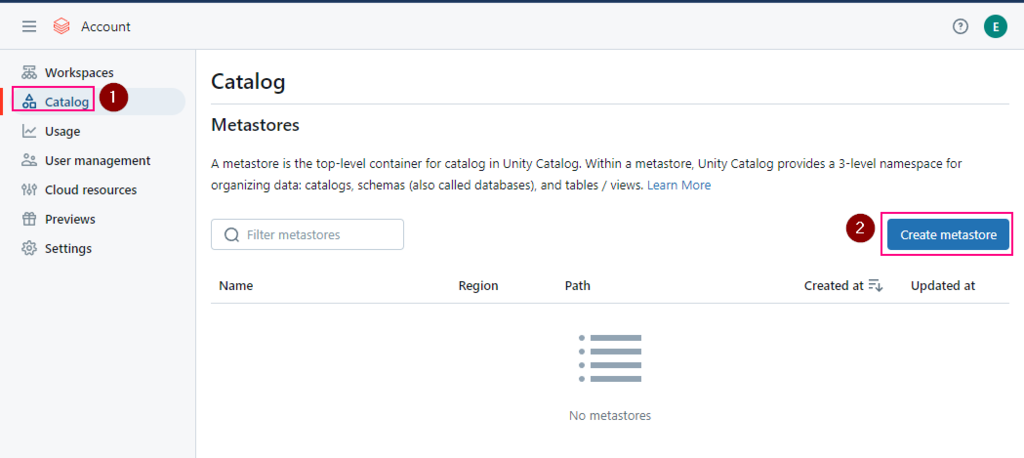
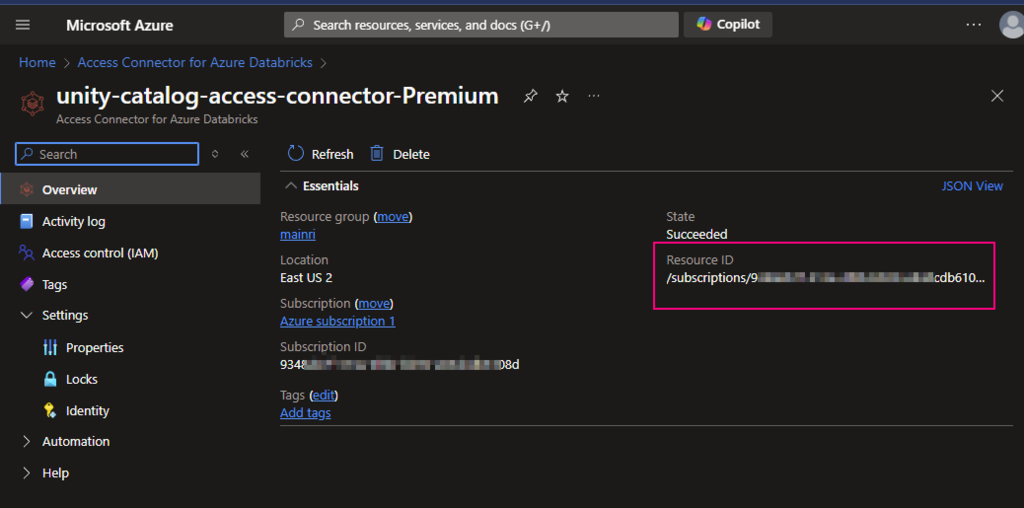
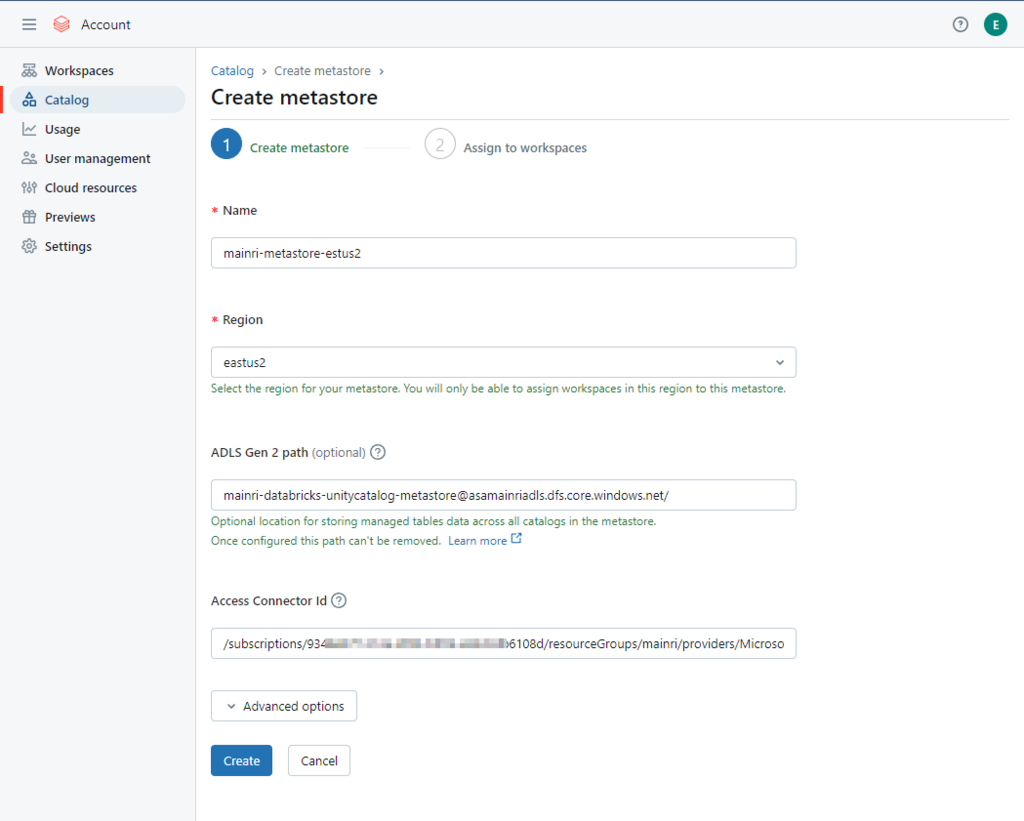
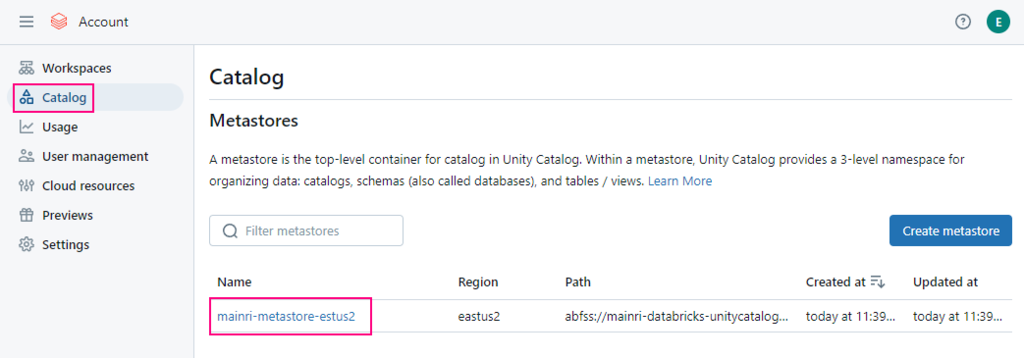
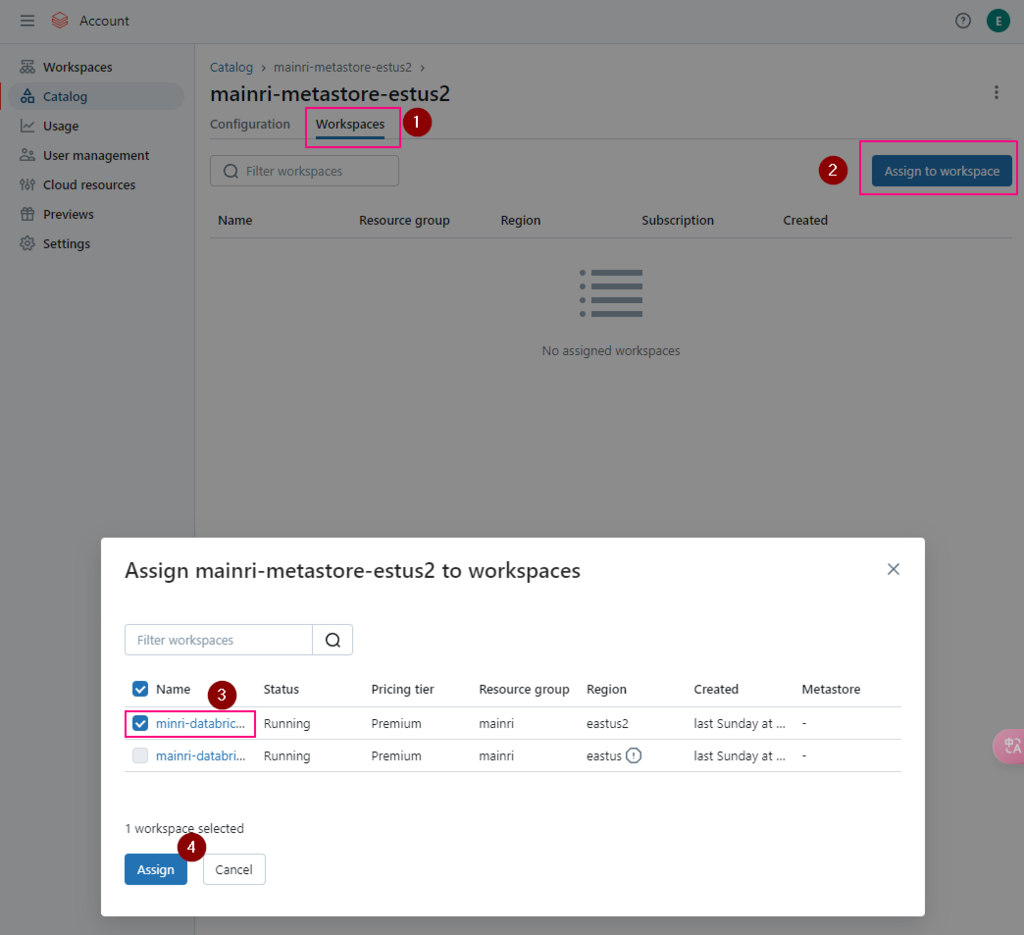
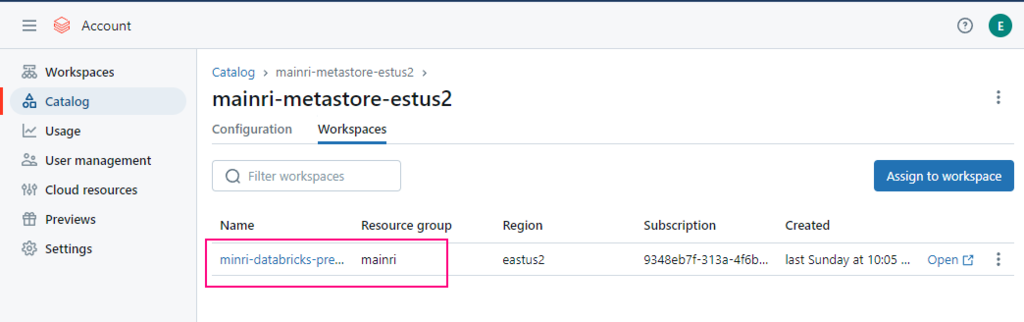
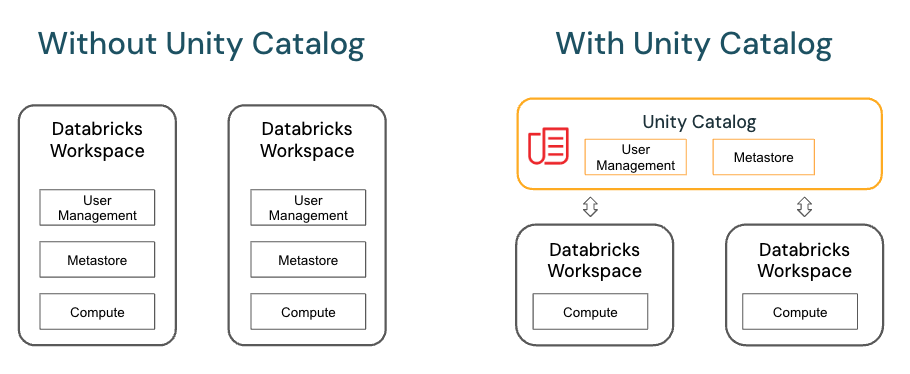
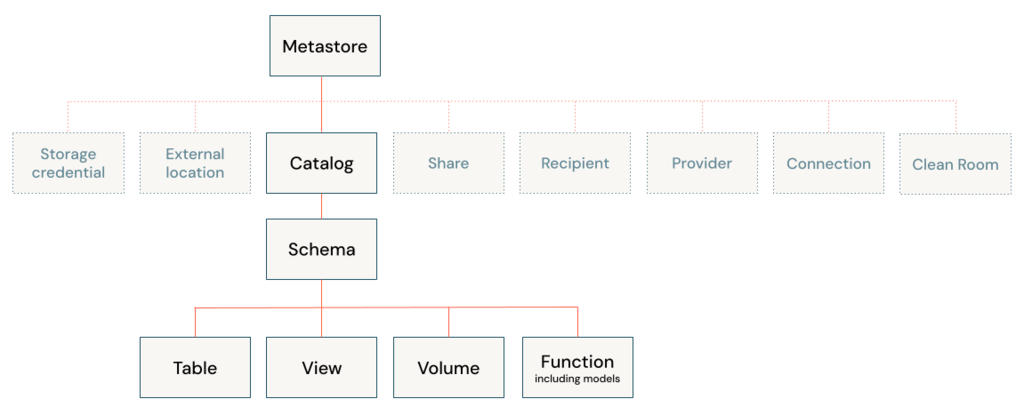
To read from and write to Unity Catalog in PySpark, you typically work with tables registered in the catalog rather than directly with file paths. Unity Catalog tables can be accessed using the format catalog_name.schema_name.table_name.
Reading from Unity Catalog
To read a table from Unity Catalog, specify the table’s full path:
# Reading a table
df = spark.read.table("catalog.schema.table")
df.show()
# Using Spark SQL
df = spark.sql("SELECT * FROM catalog.schema.table")
Writing to Unity Catalog
To write data to Unity Catalog, you specify the table name in the saveAsTable method:
# Writing a DataFrame to a new table
df.write.format("delta") \
.mode("overwrite") \
.saveAsTable("catalog.schema.new_table")
Options for Writing to Unity Catalog:
format: Set to"delta"for Delta Lake tables, as Unity Catalog uses Delta format.mode: Options includeoverwrite,append,ignore, anderror.
Example: Read, Transform, and Write Back to Unity Catalog
# Read data from a Unity Catalog table
df = spark.read.table("catalog_name.schema_name.source_table")
# Perform transformations
transformed_df = df.filter(df["column_name"] > 10)
# Write transformed data back to a different table
transformed_df.write.format("delta") \
.mode("overwrite") \
.saveAsTable("catalog_name.schema_name.target_table")
Comparison of Delta, JSON, and CSV Reads/Writes
| Format | Storage Location | Read Syntax | Write Syntax | Notes |
|---|---|---|---|---|
| Delta | Unity Catalog | df = spark.read.table("catalog.schema.table") | df.write.format("delta").mode("overwrite").saveAsTable("catalog.schema.table") | Unity Catalog natively supports Delta with schema enforcement and versioning. |
| Blob/ADLS | df = spark.read.format("delta").load("path/to/delta/folder") | df.write.format("delta").mode("overwrite").save("path/to/delta/folder") | Requires Delta Lake library; supports ACID transactions and time-travel capabilities. | |
| JSON | Unity Catalog | Not directly supported in Unity Catalog; typically needs to be read as a Delta table or temporary table. | Not directly supported; must be converted to Delta format before writing to Unity Catalog. | Convert JSON to Delta format to enable integration with Unity Catalog. |
| Blob/ADLS | df = spark.read.json("path/to/json/files") | df.write.mode("overwrite").json("path/to/json/folder") | Simple structure, no schema enforcement by default; ideal for semi-structured data. | |
| CSV | Unity Catalog | Not directly supported; CSV files should be imported as Delta tables or temporary views. | Not directly supported; convert to Delta format for compatibility with Unity Catalog. | Similar to JSON, requires conversion for use in Unity Catalog. |
| Blob/ADLS | df = spark.read.option("header", True).csv("path/to/csv/files") | df.write.option("header", True).mode("overwrite").csv("path/to/csv/folder") | Lacks built-in schema enforcement; additional steps needed for ACID or schema evolution. |
Detailed Comparison and Notes:
- Unity Catalog
- Delta: Unity Catalog fully supports Delta format, allowing for schema evolution, ACID transactions, and built-in security and governance.
- JSON and CSV: To use JSON or CSV in Unity Catalog, convert them into Delta tables or load them as temporary views before making them part of Unity’s governed catalog. This is because Unity Catalog enforces structured data formats with schema definitions.
- Blob Storage & ADLS (Azure Data Lake Storage)
- Delta: Blob Storage and ADLS support Delta tables if the Delta Lake library is enabled. Delta on Blob or ADLS retains most Delta features but may lack some governance capabilities found in Unity Catalog.
- JSON & CSV: Both Blob and ADLS provide support for JSON and CSV formats, allowing flexibility with semi-structured data. However, they do not inherently support schema enforcement, ACID compliance, or governance features without Delta Lake.
- Delta Table Benefits:
- Schema Evolution and Enforcement: Delta enables schema evolution, essential in big data environments.
- Time Travel: Delta provides versioning, allowing access to past versions of data.
- ACID Transactions: Delta ensures consistency and reliability in large-scale data processing.