The Job Interview is the single most critical step in the job hunting process. It is the definitive arena where all of your abilities must integrate. The interview itself is not a skill you possess; it is the moment you deploy your Integrated Skill Set, blending:
- Hard Skills (Technical Mastery): Demonstrating not just knowledge of advanced topics, but the depth of your expertise and how you previously applied it to solve complex, real-world problems.
- Soft Skills (Communication & Presence): Clearly articulating strategy, managing complexity under pressure, and exhibiting the leadership presence expected of senior-level and expert-level candidates.
- Contextual Skills (Business Acumen): Framing your solutions within the company’s business goals and culture, showing that you understand the strategic impact of your work.
This Integrated Skill represents your first real opportunity to sell your strategic value to the employer.
| Azure Data Factory | Azure Databricks | Azure Synapse Analytics | SQL / KQL |
| Power BI | Microsoft Fabric | Azure Purview | Azure Sentinel |
Azure Data Factory
Data Factory
Can you talk on …
what is
Databricks
Azure Databricks / Delta / Unity Catalog / Lakehouse
What is Databricks Delta (Delta Lakehouse) and how does it enhance the capabilities of Azure Databricks?
Databricks Delta, now known as Delta Lake, is an open-source storage layer that brings ACID transactions to Apache Spark and big data workloads. It enhances Azure Databricks by providing features like:
- ACID transactions for data reliability and consistency.
- Scalable metadata handling for large tables.
- Time travel for data versioning and historical data analysis.
- Schema enforcement and evolution.
- Improved performance with data skipping and Z-ordering
Are there any alternative solution that is similar to Delta lakehouse?
there are several alternative technologies that provide Delta Lake–style Lakehouse capabilities (ACID + schema enforcement + time travel + scalable storage + SQL engine). such as,
- Apache Iceberg
- Apache Hudi
- Snowflake (Iceberg Tables / Unistore)
- BigQuery + BigLake
- AWS Redshift + Lake Formation + Apache Iceberg
- Microsoft Fabric (OneLake + Delta/DQ/DLTS)
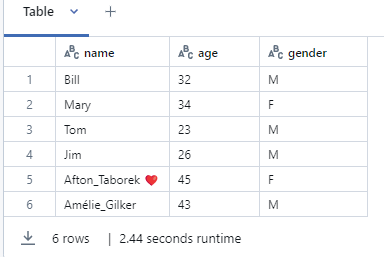
What is Delta Lake Table?
Delta lake tables are tables that store data in the delta format. Delta Lake is an extension to existing data lakes,
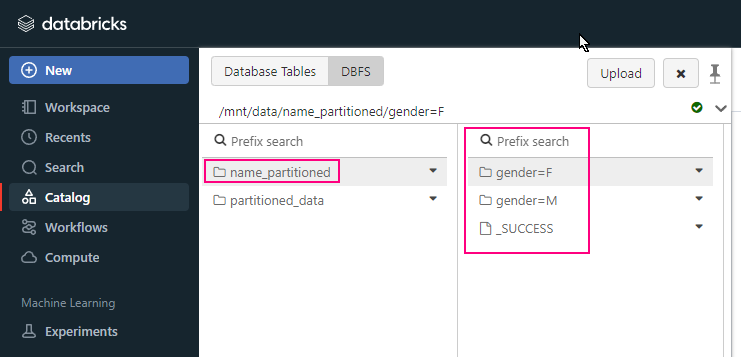
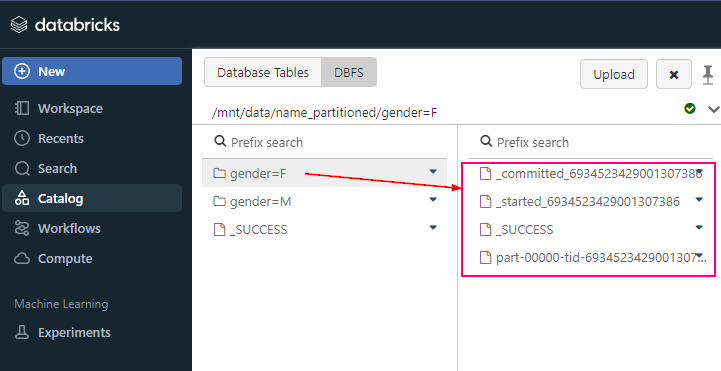
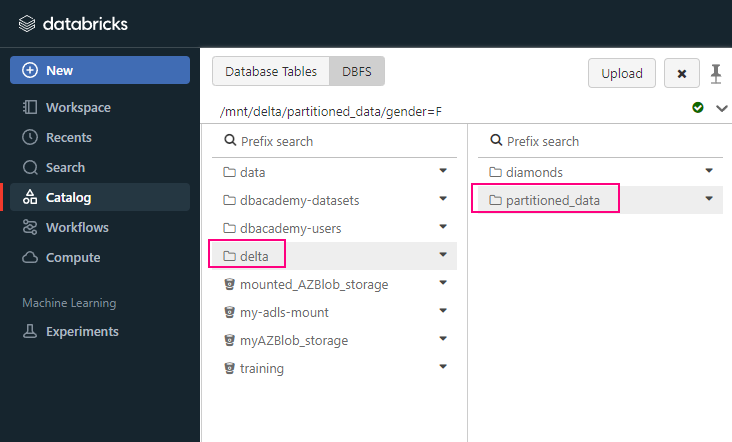
Explain how you can use Databricks to implement a Medallion Architecture (Bronze, Silver, Gold).
- Bronze Layer (Raw Data): Ingest raw data from various sources into the Bronze layer. This data is stored as-is, without any transformation.
- Silver Layer (Cleaned Data, as known Enriched layer): Clean and enrich the data from the Bronze layer. Apply transformations, data cleansing, and filtering to create more refined datasets.
- Gold Layer (Aggregated Data, as known Curated layer): Aggregate and further transform the data from the Silver layer to create high-level business tables or machine learning features. This layer is used for analytics and reporting.
What Is Z-Order (Databricks / Delta Lake)?
Z-Ordering in Databricks (specifically for Delta Lake tables) is an optimization technique designed to co-locate related information into the same set of data files on disk.
OPTIMIZE mytable
ZORDER BY (col1, col2);What Is Liquid Clustering (Databricks)?
Liquid Clustering is Databricks’ next-generation data layout optimization for Delta Lake.
It replaces (and is far superior to) Z-Order.
ALTER TABLE sales
SET TBLPROPERTIES (
'delta.liquidClustered' = 'true',
'delta.liquidClustered.columns' = 'customer_id, event_date'
);What is a Dataframe, RDD, Dataset in Azure Databricks?
Dataframe refers to a specified form of tables employed to store the data within Databricks during runtime. In this data structure, the data will be arranged into two-dimensional rows and columns to achieve better accessibility.
RDD, Resilient Distributed Dataset, is a fault-tolerant, immutable collection of elements partitioned across the nodes of a cluster. RDDs are the basic building blocks that power all of Spark’s computations.
Dataset is an extension of the DataFrame API that provides compile-time type safety and object-oriented programming benefits.
What is catching and its types?
A cache is a temporary storage that holds frequently accessed data, aiming to reduce latency and enhance speed. Caching involves the process of storing data in cache memory.
How would you secure and manage secrets in Azure Databricks when connecting to external data sources?
- Use Azure Key Vault to store and manage secrets securely.
- Integrate Azure Key Vault with Azure Databricks using Databricks-backed or Azure-backed scopes.
- Access secrets in notebooks and jobs using the dbutils.secrets API.
dbutils.secrets.get(scope=”<scope-name>”, key=”<key-name>”) - Ensure that secret access policies are strictly controlled and audited.
Scenario: You need to implement a data governance strategy in Azure Databricks. What steps would you take?
- Data Classification: Classify data based on sensitivity and compliance requirements.
- Access Controls: Implement role-based access control (RBAC) using Azure Active Directory.
- Data Lineage: Use tools like Databricks Lineage to track data transformations and movement.
- Audit Logs: Enable and monitor audit logs to track access and changes to data.
- Compliance Policies: Implement Azure Policies and Azure Purview for data governance and compliance monitoring.
Scenario: You need to optimize a Spark job that has a large number of shuffle operations causing performance issues. What techniques would you use?
- Repartitioning: Repartition the data to balance the workload across nodes and reduce skew.
- Broadcast Joins: Use broadcast joins for small datasets to avoid shuffle operations.
- Caching: Cache intermediate results to reduce the need for recomputation.
- Shuffle Partitions: Increase the number of shuffle partitions to distribute the workload more evenly.
- Skew Handling: Identify and handle skewed data by adding salt keys or custom partitioning strategies.
Scenario: You need to migrate an on-premises Hadoop workload to Azure Databricks. Describe your migration strategy.
- Assessment: Evaluate the existing Hadoop workloads and identify components to be migrated.
- Data Transfer: Use Azure Data Factory or Azure Databricks to transfer data from on-premises HDFS to ADLS.
- Code Migration: Convert Hadoop jobs (e.g., MapReduce, Hive) to Spark jobs and test them in Databricks.
- Optimization: Optimize the Spark jobs for performance and cost-efficiency.
- Validation: Validate the migrated workloads to ensure they produce the same results as on-premises.
- Deployment: Deploy the migrated workloads to production and monitor their performance.
Azure Synapse Analytics
Synapse
what is …
what is
SQL / KQL
SQL
Can you talk about database locker?
Database locking is the mechanism a database uses to control concurrent access to data so that transactions stay consistent, isolated, and safe.
Locking prevents:
- Dirty reads
- Lost updates
- Write conflicts
- Race conditions
Types of Locks:
1. Shared Lock (S)
- Used when reading data
- Multiple readers allowed
- No writers allowed
2. Exclusive Lock (X)
- Used when updating or inserting
- No one else can read or write the locked item
3. Update Lock (U) (SQL Server specific)
- Prevents deadlocks when upgrading from Shared → Exclusive
- Only one Update lock allowed
4. Intention Locks (IS, IX, SIX)
Used at table or page level to signal a lower-level lock is coming.
5. Row / Page / Table Locks
Based on granularity:
- Row-level: Most common, best concurrency
- Page-level: Several rows together
- Table-level: When scanning or modifying large portions
DB engines automatically escalate:
Row → Page → Table
when there are too many small locks.
Can you talk on Deadlock?
A deadlock happens when:
- Transaction A holds Lock 1 and wants Lock 2
- Transaction B holds Lock 2 and wants Lock 1
Both wait on each other → neither can move → database detects → kills one transaction (“deadlock victim”).
Deadlocks usually involve one writer + one writer, but can also involve readers depending on isolation level.
How to Troubleshoot Deadlocks?
A: In SQL Server: Enable Deadlock Graph Capture
run:
ALTER DATABASE [YourDB] SET DEADLOCK_PRIORITY NORMAL;
use:
DBCC TRACEON (1222, -1);
DBCC TRACEON (1204, -1);
B: Interpret the Deadlock Graph
You will see:
- Processes (T1, T2…)
- Resources (keys, pages, objects)
- Types of locks (X, S, U, IX, etc.)
- Which statement caused the deadlock
Look for:
- Two queries touching the same index/rows in different order
- A scanning query locking too many rows
- Missed indexes
- Query patterns that cause U → X lock upgrades
C. Identify
- The exact tables/images involved
- The order of locking
- The hotspot row or range
- Rows with heavy update/contention
This will tell you what to fix.
How to Prevent Deadlocks (Practical + Senior-Level)
- Always update rows in the same order
- Keep transactions short
- Use appropriate indexes
- Use the correct isolation level
- Avoid long reads before writes
Can you discuss on database normalization and denormalization
Normalization is the process of structuring a relational database to minimize data redundancy (duplicate data) and improve data integrity.
| Normal Form | Rule Summary | Problem Solved |
| 1NF (First) | Eliminate repeating groups; ensure all column values are atomic (indivisible). | Multi-valued columns, non-unique rows. |
| 2NF (Second) | Be in 1NF, AND all non-key attributes must depend on the entire primary key. | Partial Dependency (non-key attribute depends on part of a composite key). |
| 3NF (Third) | Be in 2NF, AND eliminate transitive dependency (non-key attribute depends on another non-key attribute). | Redundancy due to indirect dependencies. |
| BCNF (Boyce-Codd) | A stricter version of 3NF; every determinant (column that determines another column) must be a candidate key. | Edge cases involving multiple candidate keys. |
Denormalization is the process of intentionally introducing redundancy into a previously normalized database to improve read performance and simplify complex queries.
- Adding Redundant Columns: Copying a value from one table to another (e.g., copying the
CustomerNameinto theOrderstable to avoid joining to theCustomertable every time an order is viewed). - Creating Aggregate/Summary Tables: Storing pre-calculated totals, averages, or counts to avoid running expensive aggregate functions at query time (e.g., a table that stores the daily sales total).
- Merging Tables: Combining two tables that are frequently joined into a single, wider table.