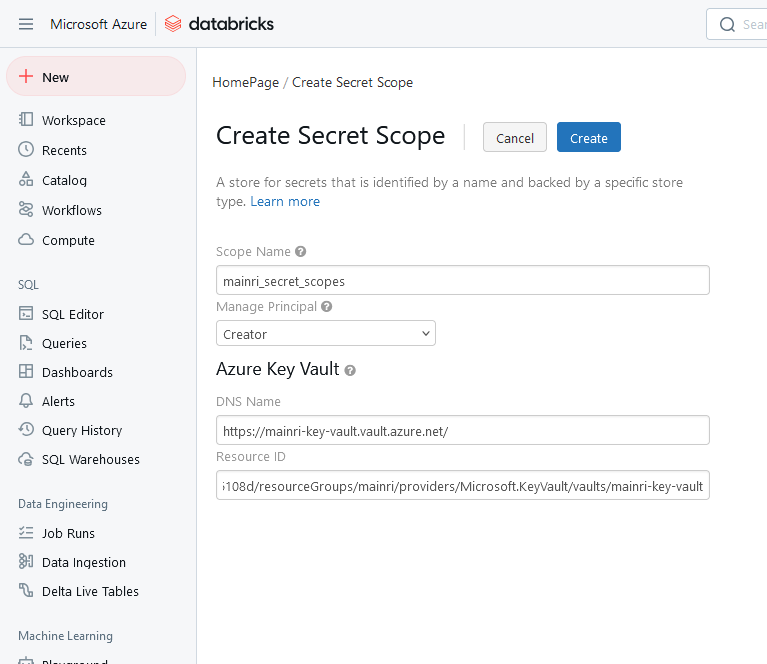
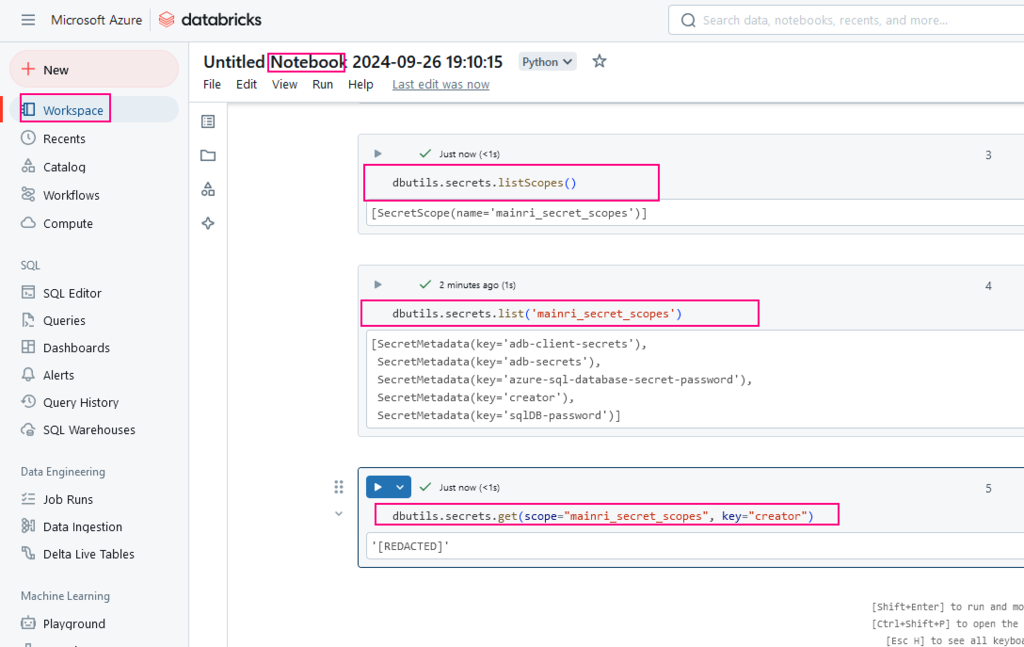
The Databricks File System (DBFS) is a distributed file system integrated with Databricks that allows users to interact with object storage systems like Azure Blob Storage, Amazon S3, and Google Cloud Storage. DBFS enables seamless access to these cloud storage systems within Databricks notebooks and clusters, appearing like a local file system.
Databricks recommends that you store data in mounted object storage rather than in the DBFS root. The DBFS root is not intended for production customer data.
DBFS root is the default file system location provisioned for a Databricks workspace when the workspace is created. It resides in the cloud storage account associated with the Databricks workspace.
Key Features of DBFS
- Unified Storage Access: DBFS provides a unified interface to interact with various cloud storage platforms (Azure Blob, S3, etc.)
- Mounting External Storage: DBFS allows you to mount cloud storage containers or buckets so that they are accessible from your Databricks environment like a directory.
- Persistence: Files written to DBFS in certain directories are persistent and accessible across clusters, ensuring that data is stored and available even when clusters are shut down
- Interoperability: DBFS integrates with Databricks’ Spark engine, meaning you can read and write data directly into Spark DataFrames,
Structure of DBFS
The Databricks File System is structured similarly to a Unix-like file system. It has the following key components:
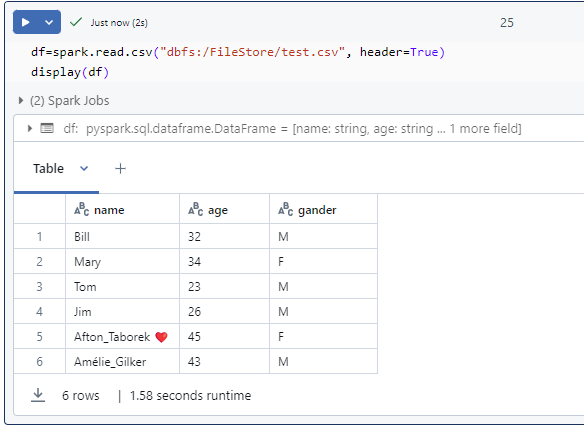
- /FileStore: This is the default directory where you can upload and store small files, such as libraries, scripts, and other assets.
- /databricks-datasets: This directory contains sample datasets provided by Databricks for learning purposes.
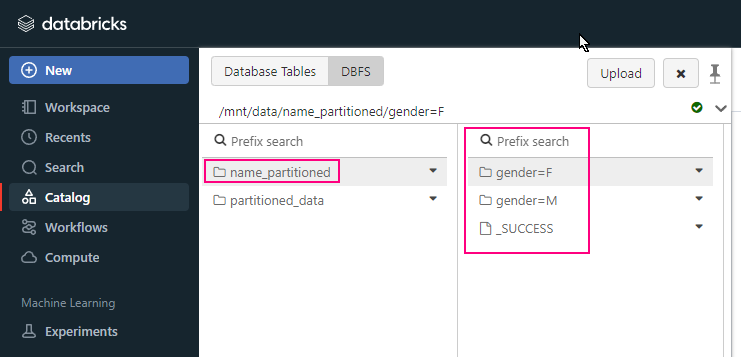
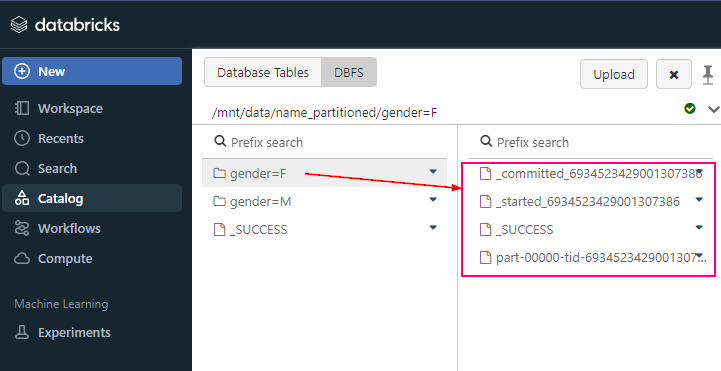
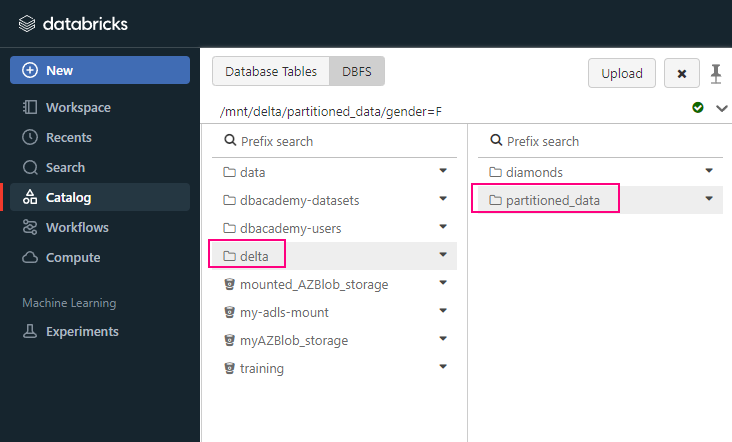
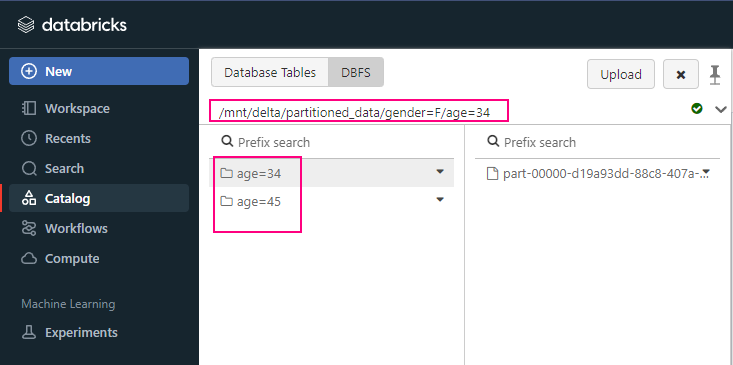
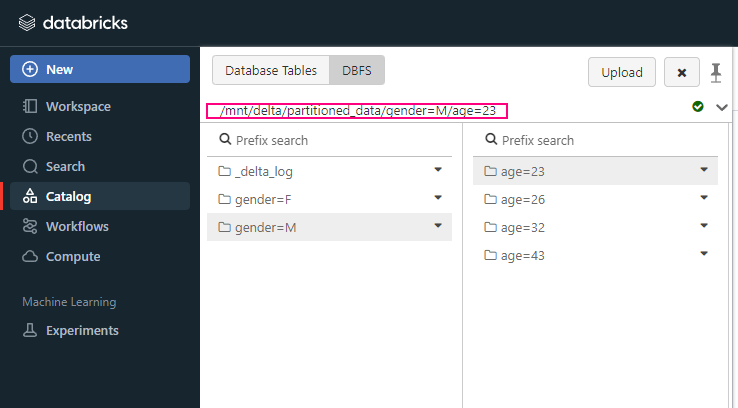
- /mnt: This is the mount point for external cloud storage, where you can mount and interact with cloud storage services like Azure Blob, AWS S3, or GCS (Google Cloud Storage).
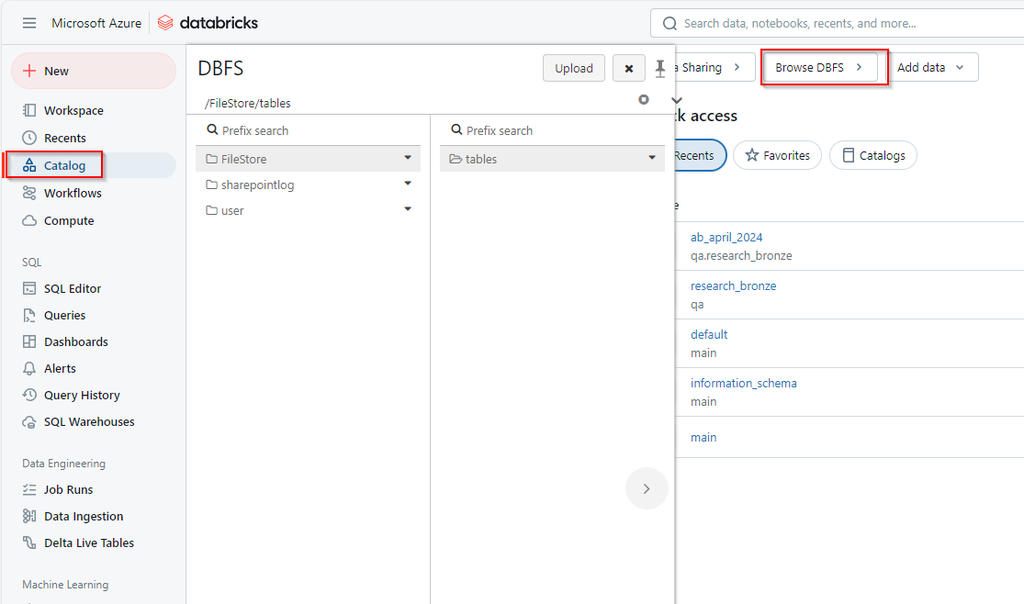
Working with DBFS
List Files in DBFS
dbutils.fs.ls(“/FileStore/”)
Upload Files
dbutils.fs.put(“/FileStore/my_file.txt”, “Hello, DBFS!”, overwrite=True)
Reading Files
df = spark.read.csv(“/FileStore/my_file.csv”, header=True, inferSchema=True)
Writing Files
df.write.csv(“/FileStore/my_output.csv”, mode=”overwrite”)
Mounting External Storage
dbutils.fs.mount(
source = "wasbs://<container>@<storage-account-name>.blob.core.windows.net",
mount_point = "/mnt/myblobstorage",
extra_configs = {"<storage-account-name>.blob.core.windows.net":dbutils.secrets.get(scope = "<scope-name>", key = "<storage-access-key>")})
Unmounting Storage
dbutils.fs.unmount(“/mnt/myblobstorage”)
Conclusion
The Databricks File System (DBFS) is a crucial feature in Databricks that provides seamless, scalable file storage and cloud integration. It abstracts away the complexity of working with distributed storage systems, making it easy to manage and process data. With capabilities like mounting external storage, integration with Spark, and support for various file formats, DBFS is an essential tool for any data engineering or analytics workflow within Databricks.