Azure Databricks is a managed platform for running Apache Spark jobs. In this post, I’ll go through some key Databricks terms to give you an overview of the different points you’ll use when running Databricks jobs (sorted by alphabet):
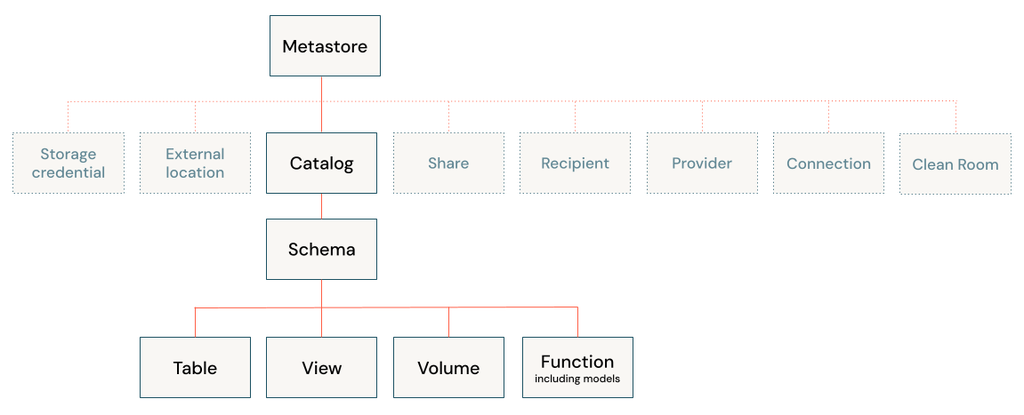
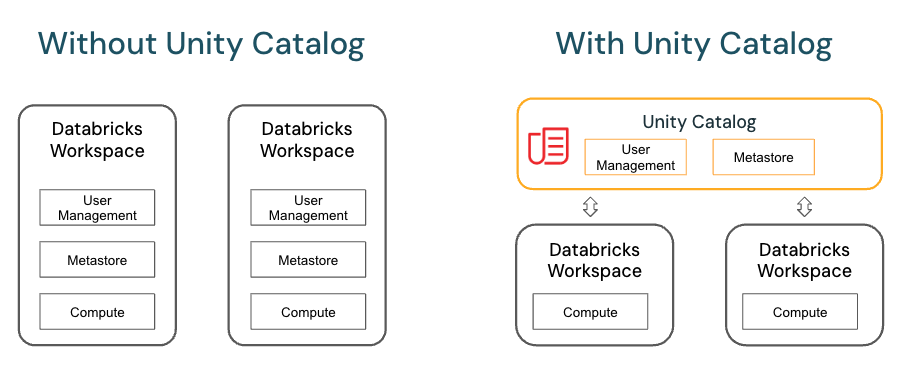
Catalog (Unity Catalog)
the Unity Catalog is a feature that provides centralized governance for data, allowing you to manage access to data across different Databricks workspaces and cloud environments. It helps define permissions, organize tables, and manage metadata, supporting multi-cloud and multi-workspace environments. Key benefits include:
Support for multi-cloud data governance.
Centralized access control and auditing.
Data lineage tracking.
Delta table
A Delta table is a data management solution provided by Delta Lake, an open-source storage layer that brings ACID transactions to big data workloads. A Delta table stores data as a directory of files on cloud object storage and registers table metadata to the metastore within a catalog and schema. By default, all tables created in Databricks are Delta tables.
External tables
External tables are tables whose data lifecycle, file layout, and storage location are not managed by Unity Catalog. Multiple data formats are supported for external tables.
CREATE EXTERNAL TABLE my_external_table (
id INT,
name STRING,
age INT
)
LOCATION 'wasbs://[container]@[account].blob.core.windows.net/data/';
External Data Source
A connection to a data store that isn’t natively in Databricks but can be queried through a connection.
External Data Sources are typically external databases or data services (e.g., Azure SQL Database, Azure Synapse Analytics, Amazon RDS, or other relational or NoSQL databases). These sources are accessed via connectors (JDBC, ODBC, etc.) within Databricks.
The Hive Metastore is the metadata repository for the data in Databricks, storing information about tables and databases. It’s used by the Spark SQL engine to manage metadata for the tables and to store information like schemas, table locations, and partitions. In Azure Databricks:
Schemas: Column names, types, and table structure.
Table locations: The path to where the actual data resides (in HDFS, Azure Data Lake, S3, etc.).
Partitions: If the table is partitioned, the metadata helps optimize query performance.
By default, each Databricks workspace has its own managed Hive metastore.
You can also connect to an external Hive metastore that is shared across multiple Databricks workspaces or use Azure-managed services like Azure SQL Database for Hive metadata storage.
Managed tables
Managed tables are the preferred way to create tables in Unity Catalog. Unity Catalog fully manages their lifecycle, file layout, and storage. Unity Catalog also optimizes their performance automatically. Managed tables always use the Delta table format.
Managed tables reside in a managed storage location that you reserve for Unity Catalog. Because of this storage requirement, you must use CLONE or CREATE TABLE AS SELECT (CTAS) if you want to copy existing Hive tables to Unity Catalog as managed tables.
Mounting Data
Mounting external storage into Databricks as if it’s part of the Databricks File System (DBFS)
In Databricks, Workflows are a way to orchestrate data pipelines, machine learning tasks, and other computational processes. Workflows allow you to automate the execution of notebooks, Python scripts, JAR files, or any other job task within Databricks and run them on a schedule, trigger, or as part of a complex pipeline.
Key Components of Workflows in Databricks:
Jobs: Workflows in Databricks are typically managed through jobs. A job is a scheduled or triggered run of a notebook, script, or other tasks in Databricks. Jobs can consist of a single task or multiple tasks linked together.
Task: Each task in a job represents an individual unit of work. You can have multiple tasks in a job, which can be executed sequentially or in parallel.
Triggers: Workflows can be triggered manually, based on a schedule (e.g., hourly, daily), or triggered by an external event (such as a webhook).
Cluster: When running a job in a workflow, you need to specify a Databricks cluster (either an existing cluster or one that is started just for the job). Workflows can also specify job clusters, which are clusters that are spun up and terminated automatically for the specific job.
Types of Workflows
Single-task Jobs: These jobs consist of just one task, like running a Databricks notebook or a Python/Scala/SQL script. You can schedule these jobs to run at specific intervals or trigger them manually.
Multi-task Workflows: These workflows are more complex and allow for creating pipelines of interdependent tasks that can be run in sequence or in parallel. Each task can have dependencies on the completion of previous tasks, allowing you to build complex pipelines that branch based on results.Example: A data pipeline might consist of three tasks:
Task 1: Ingest data from a data lake into a Delta table.
Task 2: Perform transformations on the ingested data.
Task 3: Run a machine learning model on the transformed data.
Parameterized Workflows: You can pass parameters to a job when scheduling it, allowing for more dynamic behavior. This is useful when you want to run the same task with different inputs (e.g., processing data for different dates).
Creating Workflows in Databricks
Workflows can be created through the Jobs UI in Databricks or programmatically using the Databricks REST API.
Example of Creating a Simple Workflow:
Navigate to the Jobs Tab:
In Databricks, go to the Jobs tab in the workspace.
Create a New Job:
Click Create Job.
Specify the name of the job.
Define a Task:
Choose a task type (Notebook, JAR, Python script, etc.).
Select the cluster to run the job on (or specify a job cluster).
Add parameters or libraries if required.
Schedule or Trigger the Job:
Set a schedule (e.g., run every day at 9 AM) or choose manual triggering.
You can also configure alerts or notifications (e.g., send an email if the job fails).
Multi-task Workflow Example:
Add Multiple Tasks:
After creating a job, you can add more tasks by clicking Add Task.
For each task, you can specify dependencies (e.g., Task 2 should run only after Task 1 succeeds).
Manage Dependencies:
You can configure tasks to run in sequence or in parallel.
Define whether a task should run on success, failure, or based on a custom condition.
Key Features of Databricks Workflows:
Orchestration: Allows for complex job orchestration, including dependencies between tasks, retries, and conditional logic.
Job Scheduling: You can schedule jobs to run at regular intervals (e.g., daily, weekly) using cron expressions or Databricks’ simple scheduler.
Parameterized Runs: Pass parameters to notebooks, scripts, or other tasks in the workflow, allowing dynamic control of jobs.
Cluster Management: Workflows automatically handle cluster management, starting clusters when needed and shutting them down after the job completes.
Notifications: Workflows allow setting up notifications on job completion, failure, or other conditions. These notifications can be sent via email, Slack, or other integrations.
Retries: If a job or task fails, you can configure it to automatically retry a specified number of times before being marked as failed.
Versioning: Workflows can be versioned, so you can track changes and run jobs based on different versions of a notebook or script.
Common Use Cases for Databricks Workflows:
ETL Pipelines: Automating the extraction, transformation, and loading (ETL) of data from source systems to a data lake or data warehouse.
Machine Learning Pipelines: Orchestrating the steps involved in data preprocessing, model training, evaluation, and deployment.
Batch Processing: Scheduling large-scale data processing tasks to run on a regular basis.
Data Ingestion: Automating the ingestion of raw data into Delta Lake or other storage solutions.
Alerts and Monitoring: Running scheduled jobs that trigger alerts based on conditions in the data (e.g., anomaly detection).
In Azure Data Factory (ADF), both the Copy Activity using wildcards (*.*) and the Get Metadata activity for retrieving a file list are designed to work with multiple files for copying or moving. However, they operate differently and are suited to different scenarios.
Copy Activity with Wildcard *.*
Purpose: Automatically copies multiple files from a source to a destination using wildcards.
Use Case: Used when you want to move, copy, or process multiple files in bulk that match a specific pattern (e.g., all .csv files or any file in a folder).
Wildcard Support: The wildcard characters (* for any characters, ? for a single character) help in defining a set of files to be copied. For example:
*.csv will copy all .csv files in the specified folder.
file*.json will copy all files starting with file and having a .json extension.
Bulk Copy: Enables copying multiple files without manually specifying each one.
Common Scenarios:
Copy all files from one folder to another, filtering based on extension or name pattern.
Copy files that were uploaded on a specific date, assuming the date is part of the file name.
Automatic File Handling: ADF will automatically copy all files matching the pattern in a single operation.
Key Benefit: Efficient for bulk file transfers with minimal configuration. You don’t need to explicitly get the file list; it uses wildcards to copy all matching files.
Example Scenario:
You want to copy all .csv files from a folder in Blob Storage to a Data Lake without manually listing them.
2. Get Metadata Activity (File List Retrieval)
Purpose: Retrieves a list of files in a folder, which you can then process individually or use for conditional logic.
Use Case: Used when you need to explicitly obtain the list of files in a folder to apply custom logic, processing each file separately (e.g., for-looping over them).
No Wildcard Support: The Get Metadata activity does not use wildcards directly. Instead, it returns all the files (or specific child items) in a folder. If filtering by name or type is required, additional logic is necessary (e.g., using expressions or filters in subsequent activities).
Custom Processing: After retrieving the file list, you can perform additional steps like looping over each file (with the ForEach activity) and copying or transforming them individually.
Common Scenarios:
Retrieve all files in a folder and process each one in a custom way (e.g., run different processing logic depending on the file name or type).
Check for specific files, log them, or conditionally process based on file properties (e.g., last modified time).
Flexible Logic: Since you get a list of files, you can apply advanced logic, conditions, or transformations for each file individually.
Key Benefit: Provides explicit control over how each file is processed, allowing dynamic processing and conditional handling of individual files.
Example Scenario:
You retrieve a list of files in a folder, loop over them, and process only files that were modified today or have a specific file name pattern.
Side-by-Side Comparison
Feature
Copy Activity (Wildcard *.*)
Get Metadata Activity (File List Retrieval)
Purpose
Copies multiple files matching a wildcard pattern.
Retrieves a list of files from a folder for custom processing.
Wildcard Support
Yes (*.*, *.csv, file?.json, etc.).
No, retrieves all items from the folder (no filtering by pattern).
File Selection
Automatically selects files based on the wildcard pattern.
Retrieves the entire list of files, then requires a filter for specific file selection.
Processing Style
Bulk copying based on file patterns.
Custom logic or per-file processing using the ForEach activity.
Use Case
Simple and fast copying of multiple files matching a pattern.
Used when you need more control over each file (e.g., looping, conditional processing).
File Count Handling
Automatically processes all matching files in one step.
Returns a list of all files in the folder, and each file can be processed individually.
Efficiency
Efficient for bulk file transfer, handles all matching files in one operation.
More complex as it requires looping through files for individual actions.
Post-Processing Logic
No looping required; processes files in bulk.
Requires a ForEach activity to iterate over the file list for individual processing.
Common Scenarios
– Copy all files with a .csv extension. – Move files with a specific prefix or suffix.
– Retrieve all files and apply custom logic for each one. – Check file properties (e.g., last modified date).
Control Over Individual Files
Limited, bulk operation for all files matching the pattern.
Full control over each file, allowing dynamic actions (e.g., conditional processing, transformations).
File Properties Access
No access to specific file properties during the copy operation.
Access to file properties like size, last modified date, etc., through metadata retrieval.
Execution Time
Fast for copying large sets of files matching a pattern.
Slower due to the need to process each file individually in a loop.
Use of Additional Activities
Often works independently without the need for further processing steps.
Typically used with ForEach, If Condition, or other control activities for custom logic.
Scenarios to Use
– Copying all files in a folder that match a certain extension (e.g., *.json). – Moving large numbers of files with minimal configuration.
– When you need to check file properties before processing. – For dynamic file processing (e.g., applying transformations based on file name or type).
When to Use Each:
Copy Activity with Wildcard:
Use when you want to copy multiple files in bulk and don’t need to handle each file separately.
Best for fast, simple file transfers based on file patterns.
Get Metadata Activity with File List:
Use when you need explicit control over each file or want to process files individually (e.g., with conditional logic).
Ideal when you need to loop through files, check properties, or conditionally process files.
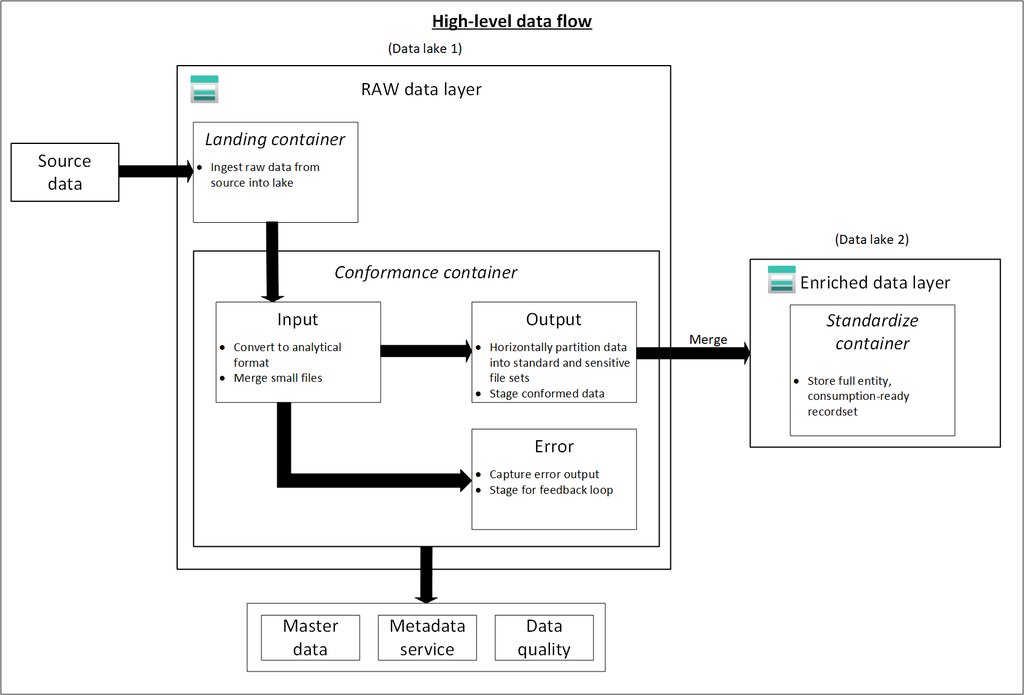
The Azure Data Lake is a massively scalable and secure data storage for high-performance analytics workloads. We can create three storage accounts within a single resource group.
Consider whether an organization needs one or many storage accounts and consider what file systems I require to build our logical data lake. (by the way, Multiple storage accounts or file systems can’t incur a monetary cost until data is accessed or stored.)
Each storage account within our data landing zone stores data in one of three stages:
Raw data
Enriched and curated data
Development data lakes
You might want to consolidate raw, enriched, and curated layers into one storage account. Keep another storage account named “development” for data consumers to bring other useful data products.
A data application can consume enriched and curated data from a storage account which has been ingested an automated data agnostic ingestion service.
we are going to Leveraged the medallion architecture to implement it. if you need more information about medallion architecture please review my previously articles – Medallion Architecture
It’s important to plan data structure before landing data into a data lake.
Data Lake Planning
When you plan a data lake, always consider appropriate consideration to structure, governance, and security. Multiple factors influence each data lake’s structure and organization:
The type of data stored
How its data is transformed
Who accesses its data
What its typical access patterns are
If your data lake contains a few data assets and automated processes like extract, transform, load (ETL) offloading, your planning is likely to be fairly easy. If your data lake contains hundreds of data assets and involves automated and manual interaction, expect to spend a longer time planning, as you’ll need a lot more collaboration from data owners.
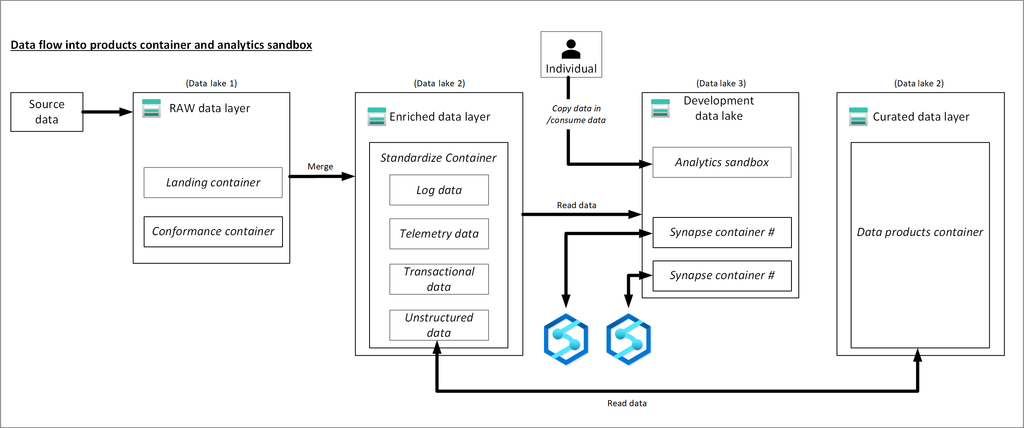
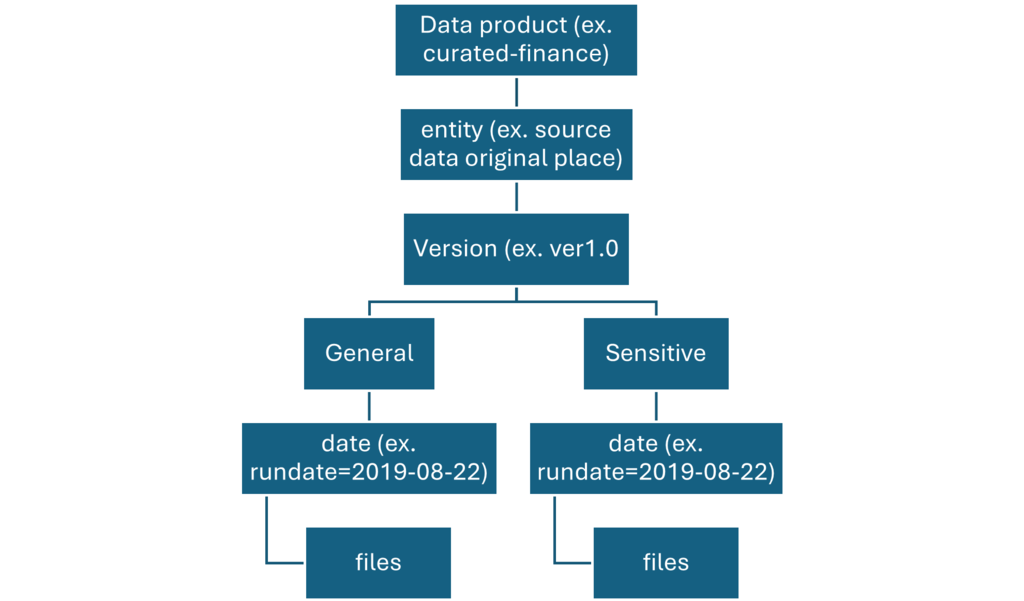
Three data lakes are illustrated in each data landing zone. The data lake sits across three data lake accounts, multiple containers, and folders, but it represents one logical data lake for our data landing zone.
Lake number
Layers
Container number
Container name
1
Raw
1
Landing
1
Raw
2
Conformance
2
Enriched
1
Standardized
2
Curated
2
Data products
3
Development
1
Analytics sandbox
3
Development
#
Synapse primary storage number
Data Lake and container number with Layer
Depending on requirements, you might want to consolidate raw, enriched, and curated layers into one storage account. Keep another storage account named “development” for data consumers to bring other useful data products.
Enable Azure Storage with the hierarchical name space feature, which allows you to efficiently manage files.
Each data product should have two folders in the data products container that our data product team owns.
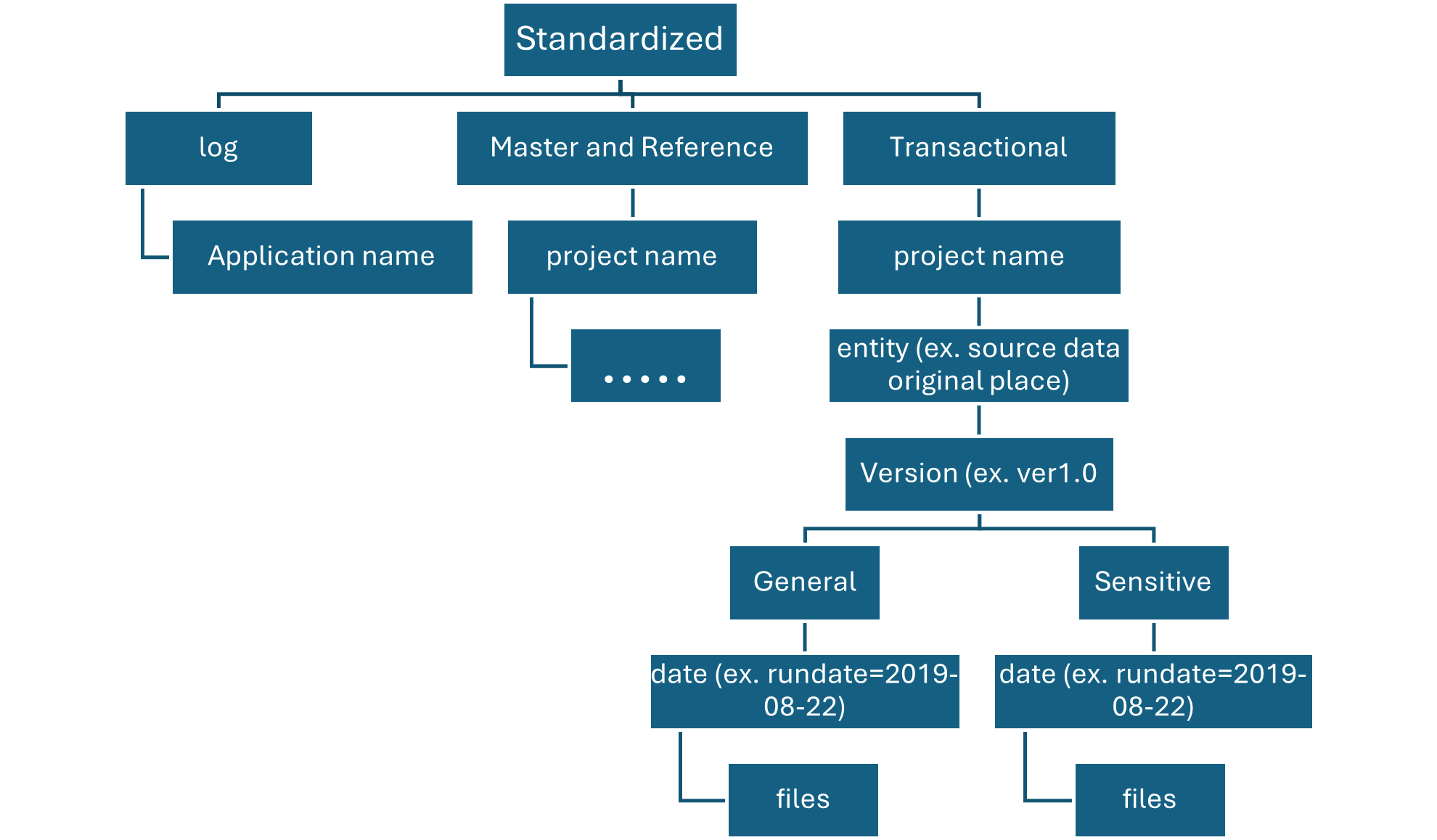
On enriched layer, standardized container, there are two folders per source system, divided by classification. With this structure, team can separately store data that has different security and data classifications and assign them different security access.
Our standardized container needs a general folder for confidential or below data and a sensitive folder for personal data. Control access to these folders by using access control lists (ACLs). We can create a dataset with all personal data removed, and store it in our general folder. We can have another dataset that includes all personal data in our sensitive personal data folder.
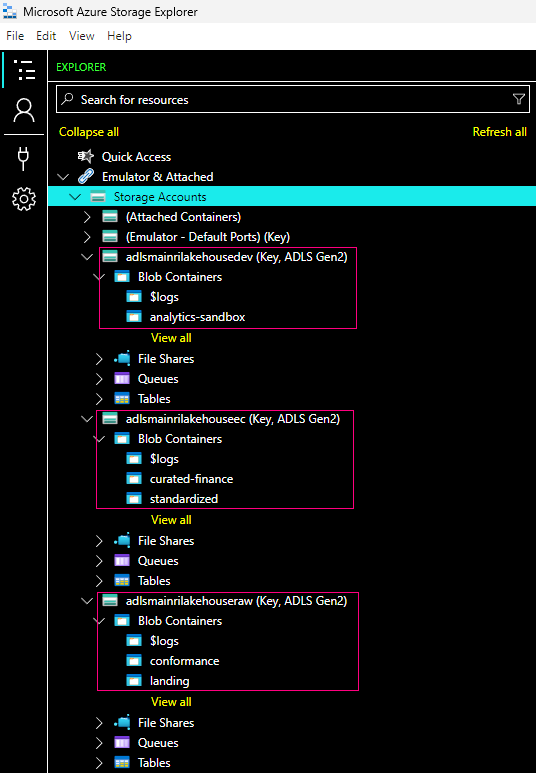
I created 3 accounts (Azure storage naming allows low case and number only. no dash, no underscore etc. allows)
adlsmainrilakehousedev — Development
adlsmainrilakehouseec — Enrich and Curated
adlsmainrilakehouseraw — Raw data
Raw layer (data lake one)
This data layer is considered the bronze layer or landing raw source data. Think of the raw layer as a reservoir that stores data in its natural and original state. It’s unfiltered and unpurified.
You might store the data in its original format, such as JSON or CSV. Or it might be cost effective to store the file contents as a column in a compressed file format, like Avro, Parquet, or Databricks Delta Lake.
You can organize this layer by using one folder per source system. Give each ingestion process write access to only its associated folder.
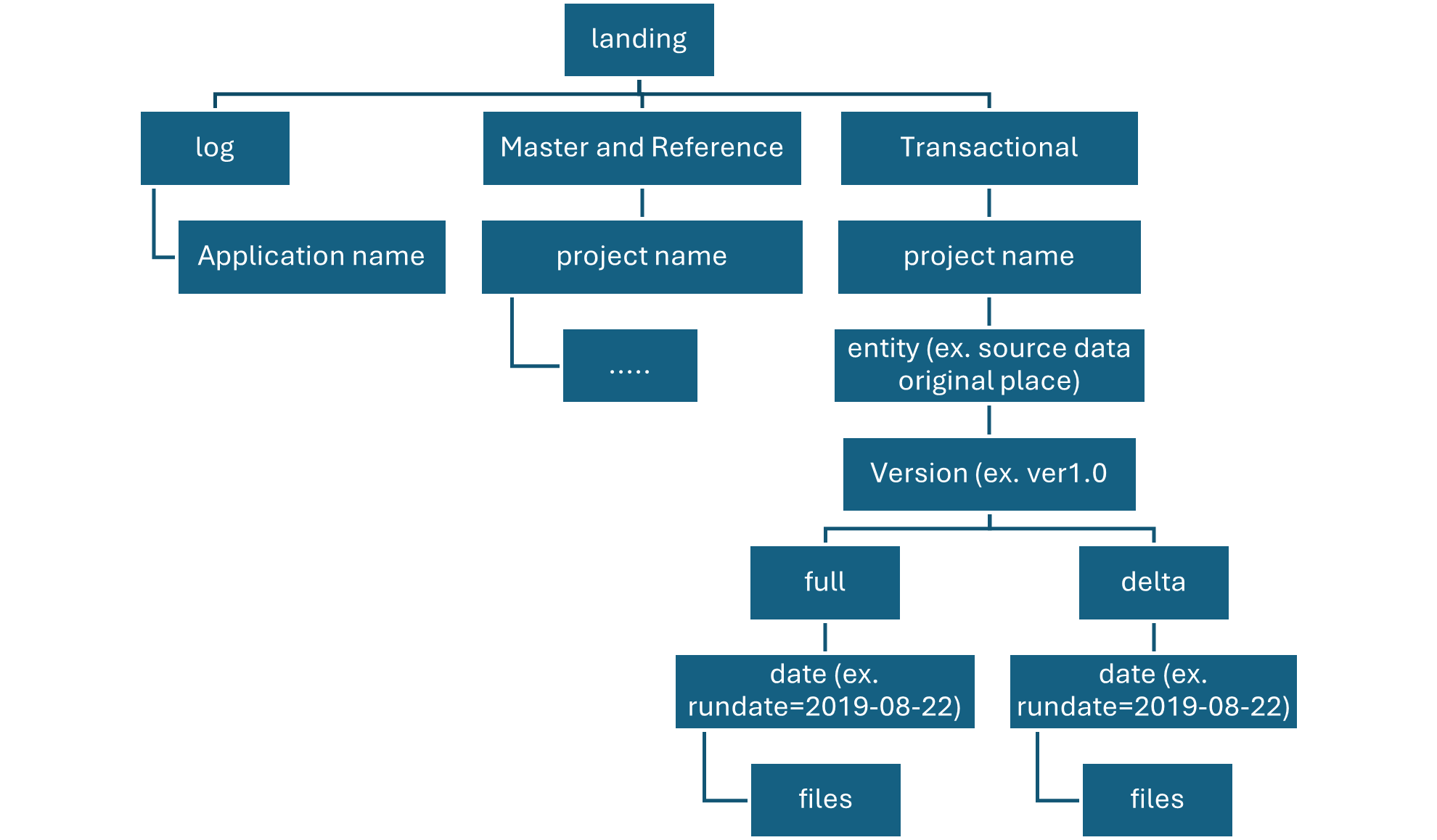
Raw Layer Landing container
The landing container is reserved for raw data that’s from a recognized source system.
Our data agnostic ingestion engine or a source-aligned data application loads the data, which is unaltered and in its original supported format.
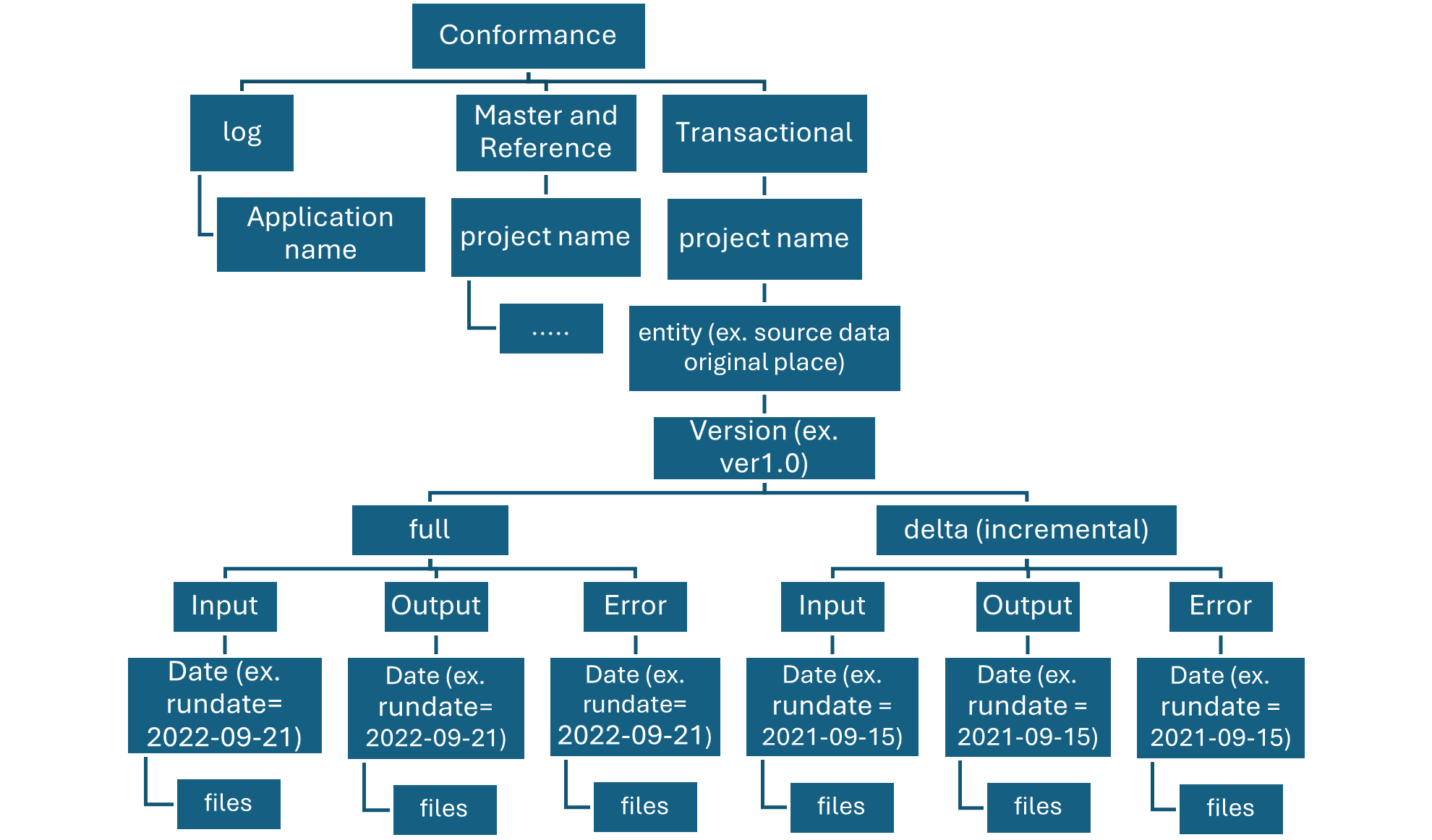
Raw layer conformance container
The conformance container in raw layer contains data quality conformed data.
As data is copied to a landing container, data processing and computing is triggered to copy the data from the landing container to the conformance container. In this first stage, data gets converted into the delta lake format and lands in an input folder. When data quality runs, records that pass are copied into the output folder. Records that fail land in an error folder.
Enriched layer (data lake two)
Think of the enriched layer as a filtration layer. It removes impurities and can also involve enrichment. This data layer is also considered the silver layer.
The following diagram shows the flow of data lakes and containers from source data to a standardized container.
Standardized container
Standardization container holds systems of record and masters. Data within this layer has had no transformations applied other than data quality, delta lake conversion, and data type alignment.
Folders in Standardized container are segmented first by subject area, then by entity. Data is available in merged, partitioned tables that are optimized for analytics consumption.
Curated layer (data lake two)
The curated layer is our consumption layer and known as Golden layer. It’s optimized for analytics rather than data ingestion or processing. The curated layer might store data in denormalized data marts or star schemas.
Data from our standardized container is transformed into high-value data products that are served to our data consumers. This data has structure. It can be served to the consumers as-is, such as data science notebooks, or through another read data store, such as Azure SQL Database.
This layer isn’t a replacement for a data warehouse. Its performance typically isn’t adequate for responsive dashboards or end user and consumer interactive analytics. This layer is best suited for internal analysts and data scientists who run large-scale, improvised queries or analysis, or for advanced analysts who don’t have time-sensitive reporting needs.
Data products container
Data assets in this zone are typically highly governed and well documented. Assign permissions by department or by function, and organize permissions by consumer group or data mart.
When landing data in another read data store, like Azure SQL Database, ensure that we have a copy of that data located in the curated data layer. Our data product users are guided to main read data store or Azure SQL Database instance, but they can also explore data with extra tools if we make the data available in our data lake.
Development layer (data lake three)
Our data consumers can/may bring other useful data products along with the data ingested into our standardized container in the silver layer.
Analytics Sandbox
The analytics sandbox area is a working area for an individual or a small group of collaborators. The sandbox area’s folders have a special set of policies that prevent attempts to use this area as part of a production solution. These policies limit the total available storage and how long data can be stored.
In this scenario, our data platform can/may allocate an analytics sandbox area for these consumers. In the sandbox, they, consumers, can generate valuable insights by using the curated data and data products that they bring.
For example, if a data science team wants to determine the best product placement strategy for a new region, they can bring other data products, like customer demographics and usage data, from similar products in that region. The team can use the high-value sales insights from this data to analyze the product market fit and offering strategy.
These data products are usually of unknown quality and accuracy. They’re still categorized as data products, but are temporary and only relevant to the user group that’s using the data.
When these data products mature, our enterprise can promote these data products to the curated data layer. To keep data product teams responsible for new data products, provide the teams with a dedicated folder on our curated data zone. They can store new results in the folder and share them with other teams across organization.
Conclusion
Data lakes are an indispensable tool in a modern data strategy. They allow teams to store data in a variety of formats, including structured, semi-structured, and unstructured data – all vendor-neutral forms, which eliminates the danger of vendor lock-in and gives users more control over the data. They also make data easier to access and retrieve, opening the door to a wider choice of analytical tools and applications.
Please do not hesitate to contact me if you have any questions at William . chen @mainri.ca
Merges the rows of two tables to form a new table by matching values of the specified column(s) from each table. Supports a full range of join types: fullouter, inner, innerunique, leftanti, leftantisemi, leftouter, leftsemi, rightanti, rightantisemi, rightouter, rightsemi
LeftTable | join [JoinParameters] ( RightTable ) on Attributes
Binds a name to expressions that can refer to its bound value. Values can be lambda expressions to create query-defined functions as part of the query. Use let to create expressions over tables whose results look like a new table.
let Name = ScalarExpression | TabularExpression | FunctionDefinitionExpression
You are working on a project that requires migrating legacy stuffs from old environment to a new one, and requirement says upgrade business logic to latest. Unfortunately, not enough and clearly documents for you to refer. You did not even know an object where it is since there are so many databases resident in the same server, so many tables, so many views, stored procedure, user defined functions… etc. It is hard to find out the legacy business logics.
sp_MSforeachdb
The sp_MSforeachdb procedure is an undocumented procedure that allows you to run the same command against all databases. There are several ways to get creative with using this command and we will cover these in the examples below. This can be used to select data, update data and even create database objects. You can use the sp_MSforeachdb stored procedure to search for objects by their name across all databases:
EXEC sp_MSforeachdb
'USE [?];
SELECT ''?'' AS DatabaseName, name AS ObjectName, type_desc AS ObjectType, Type_desc as object_Desc
, Create_date
, Modify_date
FROM sys.objects
WHERE name = ''YourObjectName'';';
Replace ‘YourObjectName’ with the actual name of the object you’re searching for (table, view, stored procedure, etc.).
The type_desc column will tell you the type of the object (e.g., USER_TABLE, VIEW, SQL_STORED_PROCEDURE, etc.).
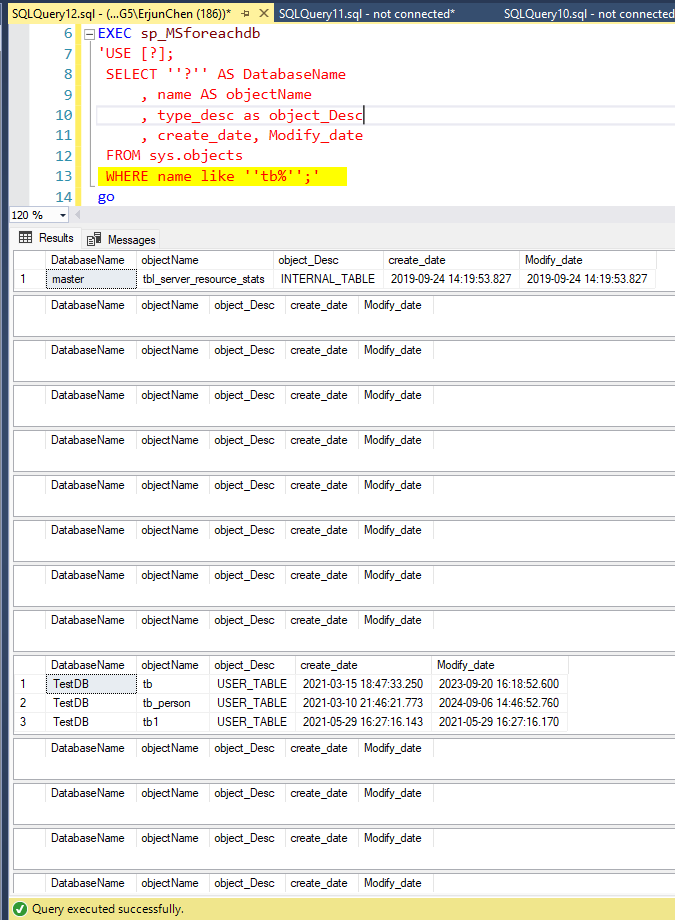
For example, find out the “tb” prefix objects
EXEC sp_MSforeachdb 'USE [?]; SELECT ''?'' AS DatabaseName , name AS objectName , type_desc as object_Desc , create_date, Modify_date FROM sys.objects WHERE name like ''tb%'';' go
Alternative – Loop Through Databases Using a Cursor
If sp_MSforeachdb is not available, you can use a cursor to loop through each database and search for the object:
DECLARE @DBName NVARCHAR(255);
DECLARE @SQL NVARCHAR(MAX);
DECLARE DB_Cursor CURSOR FOR
SELECT name
FROM sys.databases
WHERE state = 0; -- Only look in online databases
OPEN DB_Cursor;
FETCH NEXT FROM DB_Cursor INTO @DBName;
WHILE @@FETCH_STATUS = 0
BEGIN
SET @SQL =
'USE [' + @DBName + '];
IF EXISTS (SELECT 1 FROM sys.objects WHERE name = ''YourObjectName'')
BEGIN
SELECT ''' + @DBName + ''' AS DatabaseName, name AS ObjectName, type_desc AS ObjectType
FROM sys.objects
WHERE name = ''YourObjectName'';
END';
EXEC sp_executesql @SQL;
FETCH NEXT FROM DB_Cursor INTO @DBName;
END;
CLOSE DB_Cursor;
DEALLOCATE DB_Cursor;
You can modify the query to search for specific object types, such as tables or stored procedures:
Find the table
You can use the sp_MSforeachdb system stored procedure to search for the table across all databases.
EXEC sp_MSforeachdb
'USE [?];
SELECT ''?'' AS DatabaseName, name AS TableName
FROM sys.tables
WHERE name = ''YourTableName'';';
If sp_MSforeachdb is not enabled or available, you can use a cursor to loop through all databases and search for the table:
DECLARE @DBName NVARCHAR(255);
DECLARE @SQL NVARCHAR(MAX);
DECLARE DB_Cursor CURSOR FOR
SELECT name
FROM sys.databases
WHERE state = 0; -- Only look in online databases
OPEN DB_Cursor;
FETCH NEXT FROM DB_Cursor INTO @DBName;
WHILE @@FETCH_STATUS = 0
BEGIN
SET @SQL =
'USE [' + @DBName + '];
IF EXISTS (SELECT 1 FROM sys.tables WHERE name = ''YourTableName'')
BEGIN
SELECT ''' + @DBName + ''' AS DatabaseName, name AS TableName
FROM sys.tables
WHERE name = ''YourTableName'';
END';
EXEC sp_executesql @SQL;
FETCH NEXT FROM DB_Cursor INTO @DBName;
END;
CLOSE DB_Cursor;
DEALLOCATE DB_Cursor;
Find the View
You can use the sp_MSforeachdb system stored procedure to search for the view across all databases.
EXEC sp_MSforeachdb 'USE [?]; SELECT ''?'' AS DatabaseName, name AS TableName FROM sys.views WHERE name = ''YourTableName'';';
Find the Stored Procedure
EXEC sp_MSforeachdb
'USE [?];
SELECT ''?'' AS DatabaseName, name AS ProcedureName
FROM sys.procedures
WHERE name = ''YourProcedureName'';';
Please do not hesitate to contact me if you have any questions at William . chen @ mainri.ca
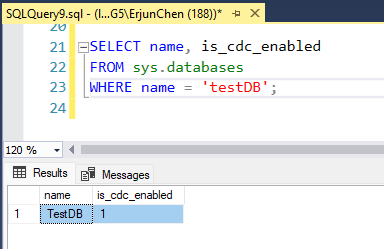
SQL Server Change Data Capture (CDC) is a feature that captures changes to data in SQL Server tables. It captures the changes in the source data and updates only the data in the destination that has changed. Any inserts, updates or deletes made to any of the tables made in a specified time window are captured for further use, such as in ETL processes. Here’s a step-by-step guide to enable and use CDC.
Preconditions
1. SQL Server Agent is running
Since CDC relies on SQL Server Agent, verify that the agent is up and running.
To check if SQL Server Agent is running, you can follow these steps:
Open SQL Server Management Studio (SSMS).
In the Object Explorer, expand the SQL Server Agent node. If you see a green icon next to SQL Server Agent, it means the Agent is running. If the icon is red or gray, it means the SQL Server Agent is stopped or disabled.
To start the Agent, right-click on SQL Server Agent and select Start.
Or start it from SSMS or by using the following command:
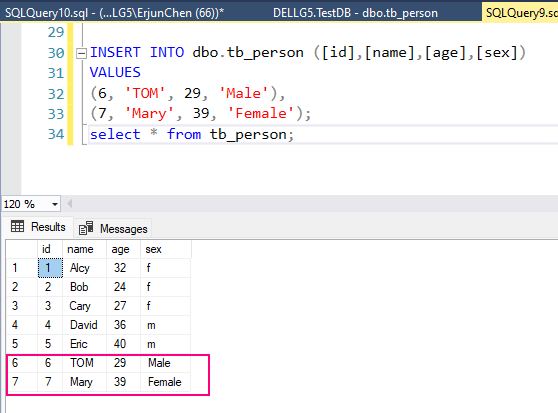
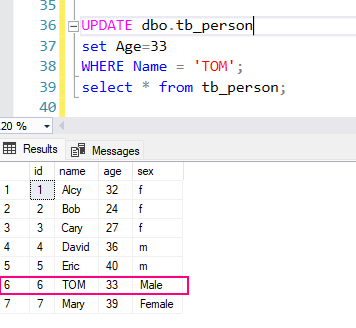
UPDATE dbo.tb_person
set Age=33
WHERE Name = 'TOM';
select * from tb_person;
3, Delete a row:
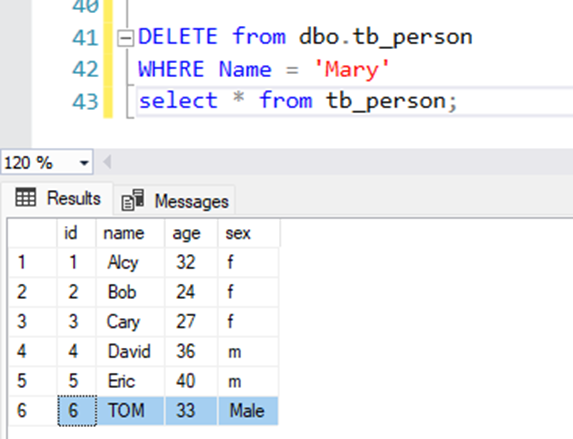
DELETE from dbo.tb_person
WHERE Name = 'Mary'
select * from tb_person;
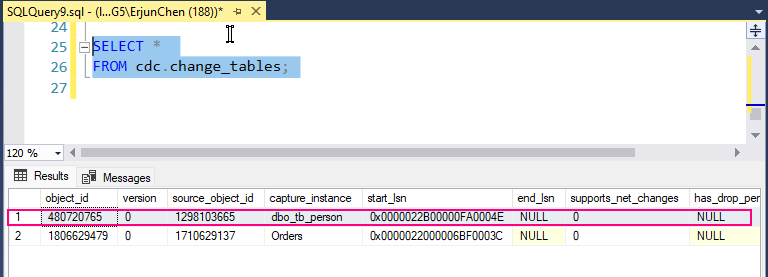
Step 5: Query the CDC Change Table
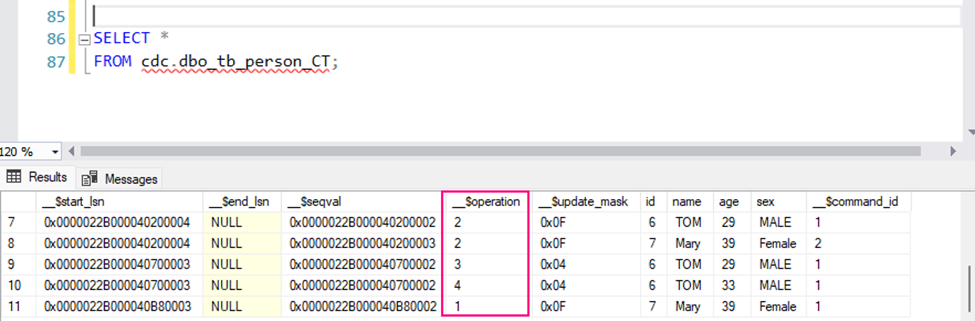
Once CDC is enabled, SQL Server will start capturing insert, update, and delete operations on the tracked tables.
The CDC system creates specific change tables. The name of the change table is derived from the source table and schema. For example, for tb_Person in the dbo schema, the change table might be named something like cdc.dbo_tb_person_CT.
Querying the change table: To retrieve changes captured by CDC, you can query the change table directly:
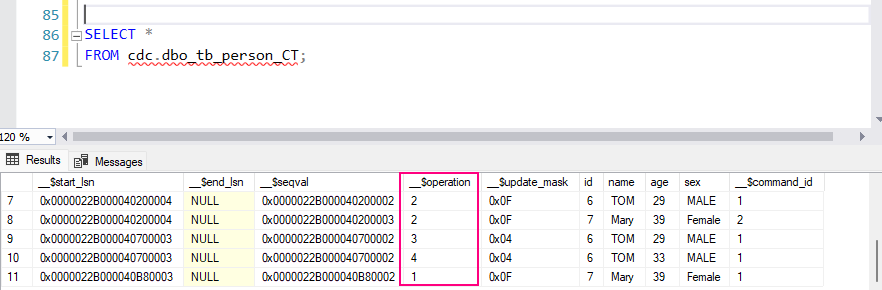
SELECT *
FROM cdc.dbo_tb_person_CT;
This table contains:
__$operation: The type of operation:
1: DELETE
2: INSERT
3: UPDATE (before image)
4: UPDATE (after image)
__$start_lsn: The log sequence number (LSN) of the transaction.
Columns of the original table (e.g., OrderID, CustomerName, Product, etc.) showing the state of the data before and after the change.
Step 5: Manage CDC
As your tables grow, CDC will collect more data in its change tables. To manage this, SQL Server includes functions to clean up old change data.
1. Set up CDC clean-up jobs, Adjust the retention period (default is 3 days)
SQL Server automatically creates a cleanup job to remove old CDC data based on retention periods. You can modify the retention period by adjusting the @retention parameter.
EXEC sys.sp_cdc_change_job
@job_type = N'cleanup',
@retention = 4320; -- Retention period in minutes (default 3 days)
2. Disable CDC on a table:
If you no longer want to track changes on a table, disable CDC:
If you want to disable CDC for the entire database, run:
USE YourDatabaseName; GO EXEC sys.sp_cdc_disable_db; GO
Step 6: Monitor CDC
You can monitor CDC activity and performance using the following methods
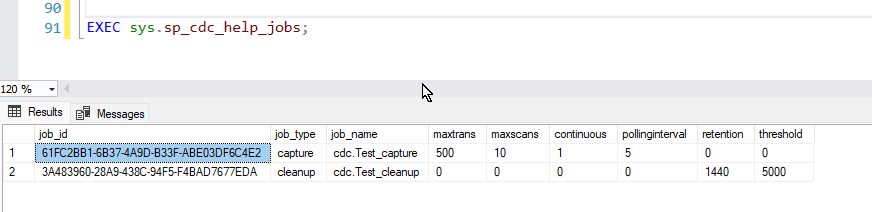
1. Check the current status of CDC jobs:
EXEC sys.sp_cdc_help_jobs;
2. Monitor captured transactions:
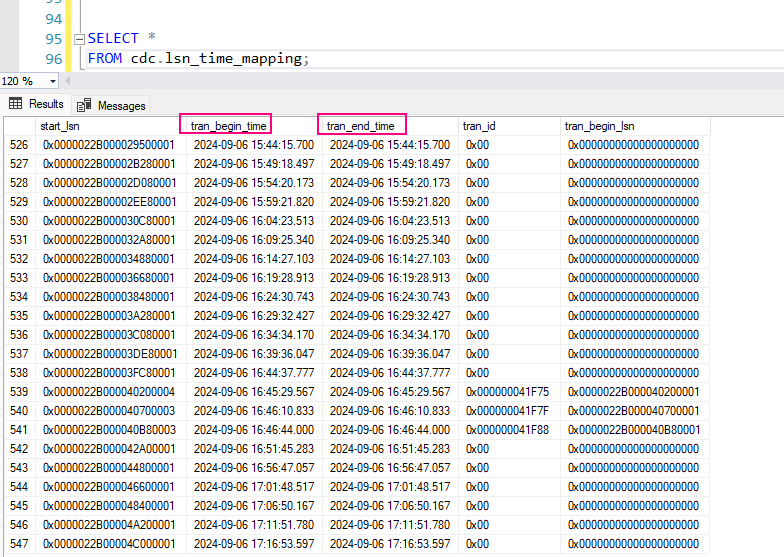
You can query the cdc.lsn_time_mapping table to monitor captured LSNs and their associated times:
SELECT *
FROM cdc.lsn_time_mapping;
Step 7: Using CDC Data in ETL Processes
Once CDC is capturing data, you can integrate it into ETL processes or use it for auditing or tracking changes over time. Use change tables
cdc. [YourSchema]_[YourTableName]_CT
to identify rows that have been modified, deleted, or inserted, and process the changes accordingly. e.g.
SELECT *
FROM cdc.dbo_tb_person_CT;
System function cdc.fn_cdc_get_all_changes_<Capture_Instance>
cdc.fn_cdc_get_all_changes_<capture_instance>
The function fn_cdc_get_all_changes_<capture_instance> is a system function that allows you to retrieve all the changes (inserts, updates, and deletes) made to a CDC-enabled table over a specified range of log sequence numbers (LSNs).
For your table tb_person, if CDC has been enabled, the function to use would be:
@from_lsn: The starting log sequence number (LSN). This represents the point in time (or transaction) from which you want to begin retrieving changes.
@to_lsn: The ending LSN. This represents the point up to which you want to retrieve changes.
N'all': This parameter indicates that you want to retrieve all changes (including inserts, updates, and deletes).
Retrieve LSN Values
You need to get the LSN values for the time range you want to query. You can use the following system function to get the from_lsn and to_lsn values:
Get the minimum LSN for the CDC-enabled table: sys.fn_cdc_get_min_lsn(‘dbo_tb_person’) e.g. SELECT sys.fn_cdc_get_min_lsn(‘dbo_tb_person’);
Get the maximum LSN (which represents the latest changes captured): sys.fn_cdc_get_max_lsn(); SELECT sys.fn_cdc_get_max_lsn();
Use the LSN Values in the Query
Now, you can use these LSNs to query the changes. Here’s an example:
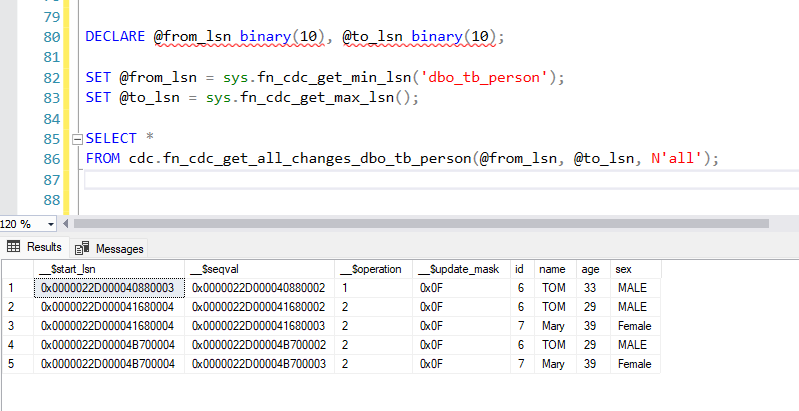
DECLARE @from_lsn binary(10), @to_lsn binary(10);
SET @from_lsn = sys.fn_cdc_get_min_lsn('dbo_tb_person');
SET @to_lsn = sys.fn_cdc_get_max_lsn();
SELECT *
FROM cdc.fn_cdc_get_all_changes_dbo_tb_person(@from_lsn, @to_lsn, N'all');
The result set will include:
__$operation: The type of change (1 = delete, 2 = insert, 3 = update before, 4 = update after).
__$start_lsn: The LSN value at which the change occurred.
__$seqval: Sequence value for sorting the changes within a transaction.
__$update_mask: Binary value indicating which columns were updated.
All the columns from the original tb_person table.
Querying Only Inserts, Updates, or Deletes
If you want to query only a specific type of change, such as inserts or updates, you can modify the function’s third parameter:
Inserts only:
SELECT *
FROM cdc.fn_cdc_get_all_changes_dbo_tb_person(@from_lsn, @to_lsn, N'insert');
Updates only:
SELECT *
FROM cdc.fn_cdc_get_all_changes_dbo_tb_person(@from_lsn, @to_lsn, N'update');
Deletes only:
SELECT *
FROM cdc.fn_cdc_get_all_changes_dbo_tb_person(@from_lsn, @to_lsn, N'delete');
Map datetime to log sequence number (lsn)
sys.fn_cdc_map_time_to_lsn
The sys.fn_cdc_map_time_to_lsn function in SQL Server is used to map a datetime value to a corresponding log sequence number (LSN) in Change Data Capture (CDC). Since CDC captures changes using LSNs, this function is helpful to find the LSN that corresponds to a specific point in time, making it easier to query CDC data based on a time range.
lsn_time_mapping: Specifies how you want to map the datetime_value to an LSN. It can take one of the following values:
smallest greater than or equal: Returns the smallest LSN that is greater than or equal to the specified datetime_value.
largest less than or equal: Returns the largest LSN that is less than or equal to the specified datetime_value.
datetime_value: The datetime value you want to map to an LSN.
Using sys.fn_cdc_map_time_to_lsn() in a CDC Query
Mapping a Date/Time to an LSN
-- Mapping a Date/Time to an LSN
DECLARE @from_lsn binary(10);
SET @from_lsn = sys.fn_cdc_map_time_to_lsn('smallest greater than or equal', '2024-09-06 12:00:00');
This will map the datetime'2024-09-06 12:00:00' to the corresponding LSN.
Finding the Largest LSN Before a Given Time
-- Finding the Largest LSN Before a Given Time
DECLARE @to_lsn binary(10);
SET @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', '2024-09-06 12:00:00');
This will return the largest LSN that corresponds to or is less than the datetime'2024-09-06 12:00:00'.
from_lsn: The starting LSN in the range of changes to be retrieved.
to_lsn: The ending LSN in the range of changes to be retrieved.
row_filter_option: Defines which changes to return:
'all': Returns both the before and after images of the changes for update operations.
'all update old': Returns the before image of the changes for update operations.
'all update new': Returns the after image of the changes for update operations.
Let’s say you want to find all the changes made to the tb_person table between '2024-09-05 08:00:00' and '2024-09-06 18:00:00'. You can map these times to LSNs and then query the CDC changes.
-- Querying Changes Between Two Time Points
DECLARE @from_lsn binary(10), @to_lsn binary(10);
-- Map the datetime range to LSNs
SET @from_lsn = sys.fn_cdc_map_time_to_lsn('smallest greater than or equal', '2024-09-05 08:00:00');
SET @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', '2024-09-06 18:00:00');
-- Query the CDC changes for the table tb_person within the LSN range
SELECT *
FROM cdc.fn_cdc_get_all_changes_dbo_tb_person(@from_lsn, @to_lsn, N'all');
Output:
This query will return the following data for changes between the specified LSN range:
__$operation: Indicates whether the row was inserted, updated, or deleted.
__$start_lsn: The LSN at which the change occurred.
Other columns: Any other columns that exist in the tb_person table.
Using sys.fn_cdc_map_lsn_to_time () convert an LSN value to a readable datetime
In SQL Server, Change Data Capture (CDC) tracks changes using Log Sequence Numbers (LSNs), but these LSNs are in a binary format and are not directly human-readable. However, you can map LSNs to timestamps (datetime values) using the system function sys.fn_cdc_map_lsn_to_time
Syntax
sys.fn_cdc_map_lsn_to_time (lsn_value)
Example: Mapping LSN to Datetime
Get the LSN range for the cdc.fn_cdc_get_all_changes function:
DECLARE @from_lsn binary(10), @to_lsn binary(10);
-- Get minimum and maximum LSN for the table
SET @from_lsn = sys.fn_cdc_get_min_lsn('dbo_tb_person');
SET @to_lsn = sys.fn_cdc_get_max_lsn();
Query the CDC changes and retrieve the LSN values:
-- Query CDC changes for the tb_person table SELECT $start_lsn, $operation, PersonID, FirstName, LastName FROM cdc.fn_cdc_get_all_changes_dbo_tb_person(@from_lsn, @to_lsn, 'all');
Convert the LSN to a datetime using sys.fn_cdc_map_lsn_to_time
-- Convert the LSN to datetime
SELECT $start_lsn, sys.fn_cdc_map_lsn_to_time($start_lsn) AS ChangeTime,
__$operation,
PersonID,
FirstName,
LastName
FROM cdc.fn_cdc_get_all_changes_dbo_tb_person(@from_lsn, @to_lsn, 'all');
Output
$start_lsn ChangeTime __$operation PersonID FirstName LastName 0x000000240000005A 2024-09-06 10:15:34.123 2 1 John Doe 0x000000240000005B 2024-09-06 10:18:45.321 4 1 John Smith 0x000000240000005C 2024-09-06 10:25:00.789 1 2 Jane Doe
Explanation
sys.fn_cdc_map_lsn_to_time(__$start_lsn) converts the LSN from the CDC changes to a human-readable datetime.
This is useful for analyzing the time at which changes were recorded.
Notes:
CDC vs Temporal Tables: CDC captures only DML changes (inserts, updates, deletes), while temporal tables capture a full history of changes.
Performance: Capturing changes can add some overhead to your system, so it’s important to monitor CDC’s impact on performance.
Summary
Step 1: Enable CDC at the database level.
Step 2: Enable CDC on the SalesOrder table.
Step 3: Verify CDC is enabled.
Step 4: Perform data changes (insert, update, delete).
Step 5: Query the CDC change table to see captured changes.
Step 6: Manage CDC retention and disable it when no longer needed.
Step 7: Using CDC Data in ETL Processes
This step-by-step example shows how CDC captures data changes, making it easier to track, audit, or integrate those changes into ETL pipelines.
Please do not hesitate to contact me if you have any questions at William . chen @ mainri.ca
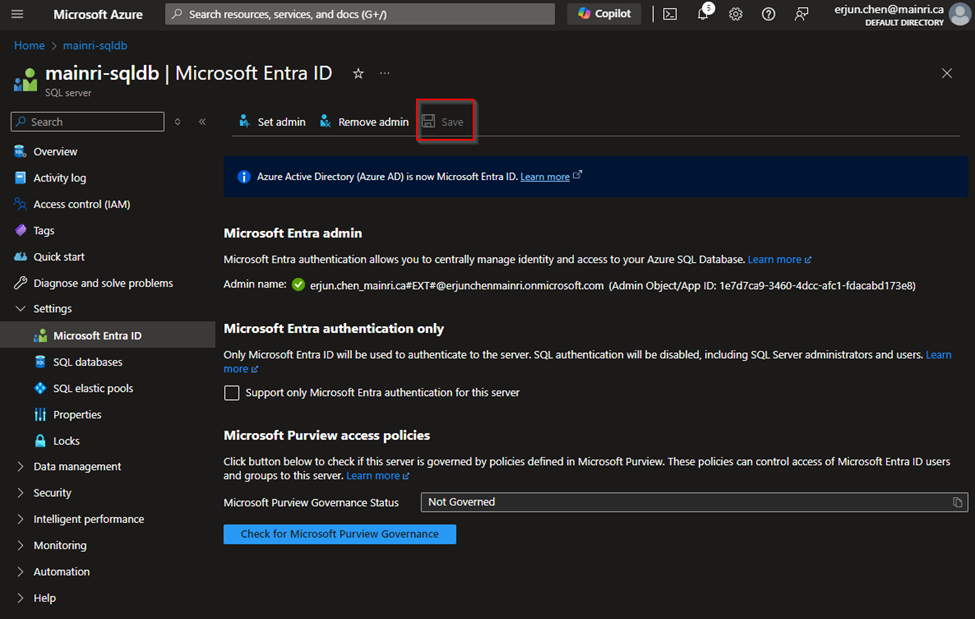
Azure SQL Database can be integrated with Azure Entra ID to provide identity and access management. With this integration, users can sign in to Azure SQL Database using their Azure Entra ID credentials, enabling a centralized and secure way to manage database access.
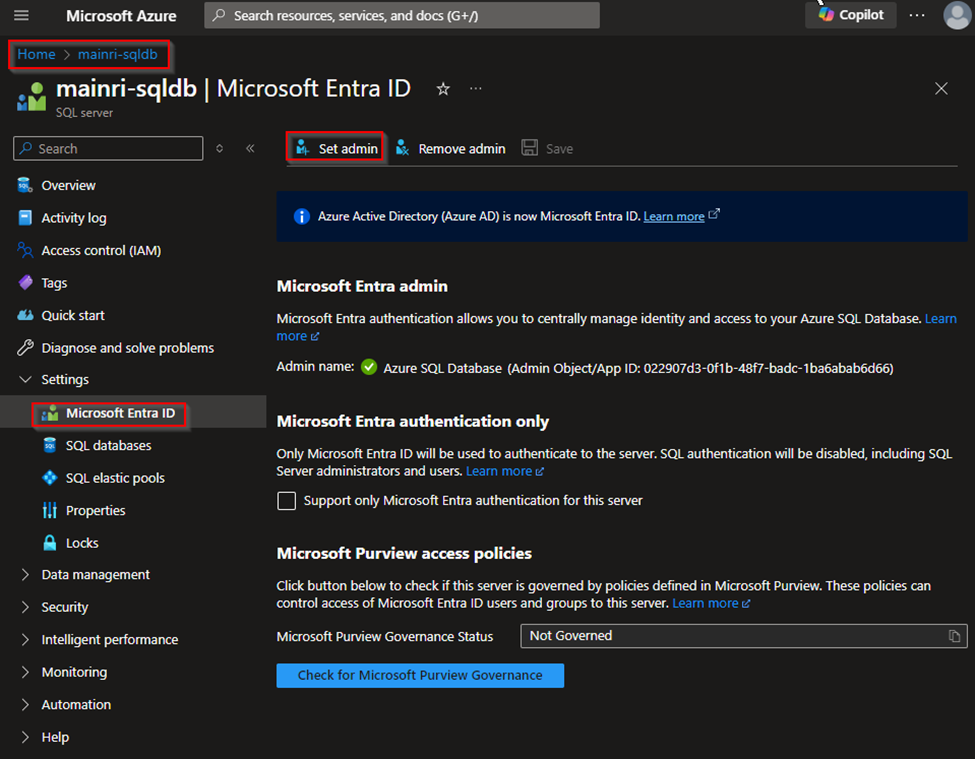
Register the SQL Server in Azure Entra ID
Enable Azure Entra ID Admin
Register your SQL Server (or SQL Database) as an application in Azure Entra ID.
Azure Portal > find out the SQL Server that you want to register with Azure Entra ID >
Settings > Microsoft Entra ID (Active Directory Admin)
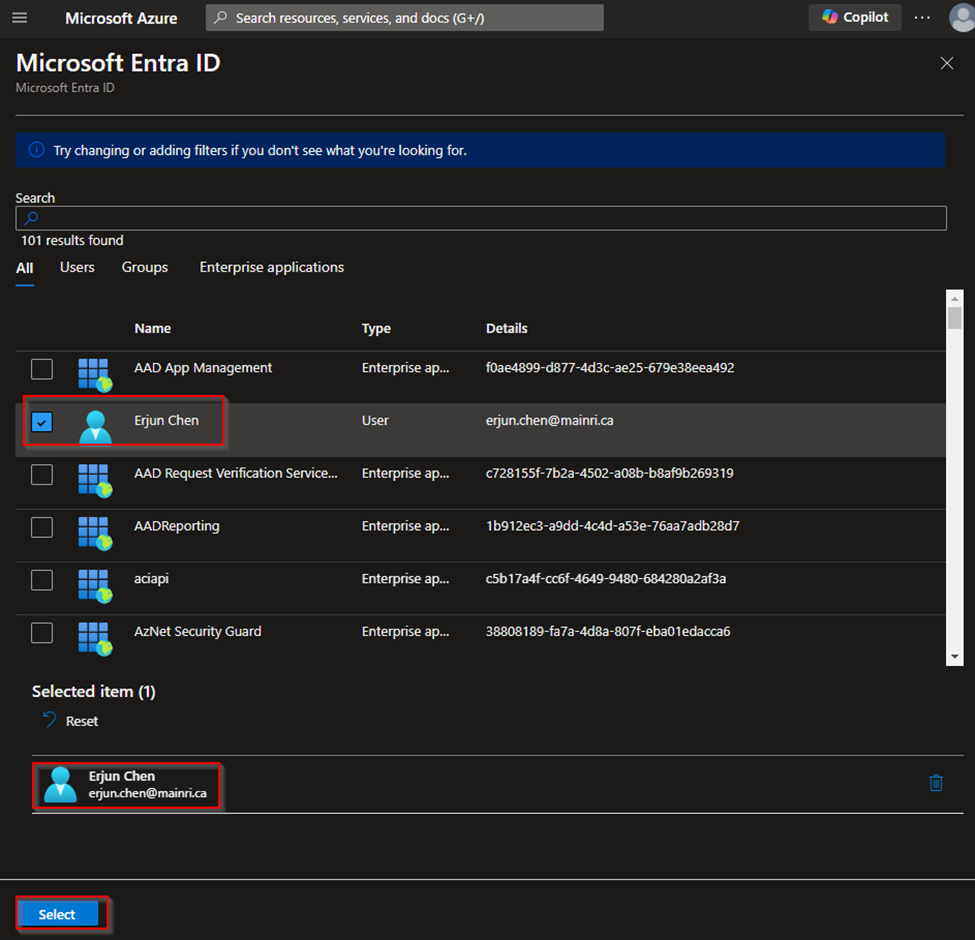
Assign Users/Groups
You can assign Azure Entra ID users or groups to specific roles within the SQL Database, such as db_owner, db_datareader, or db_datawriter.
Then, Click Save to apply the changes.
Configure Azure Entra ID Authentication in Azure SQL Database
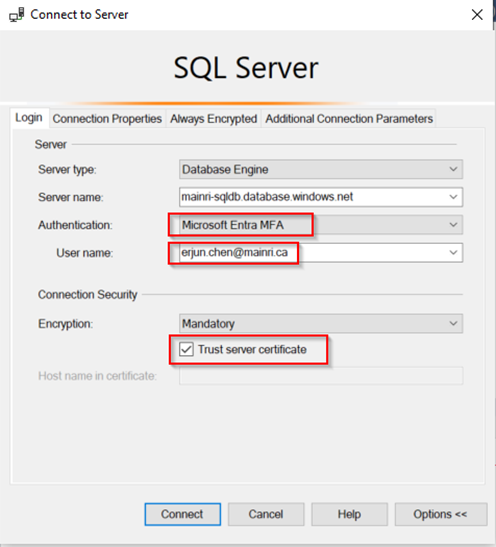
Connect to SQL Database using Azure Entra ID
You can connect to your Azure SQL Database using Azure Entra ID by selecting the “Azure Active Directory – Universal with MFA support” authentication method in tools like SQL Server Management Studio (SSMS).
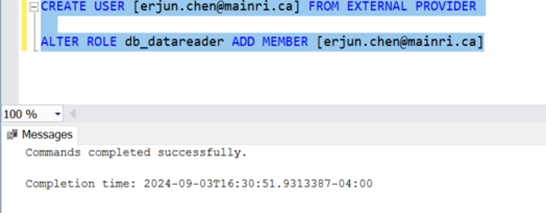
Assign Roles to Azure Entra ID Users
Use a SQL query to assign roles to Azure Entra ID users or groups. For example:
CREATE USER [your_username@yourdomain.com] FROM EXTERNAL PROVIDER; ALTER ROLE db_datareader ADD MEMBER [your_username@yourdomain.com];
This command creates an Azure Entra ID user in your SQL Database and adds them to the db_datareader role.
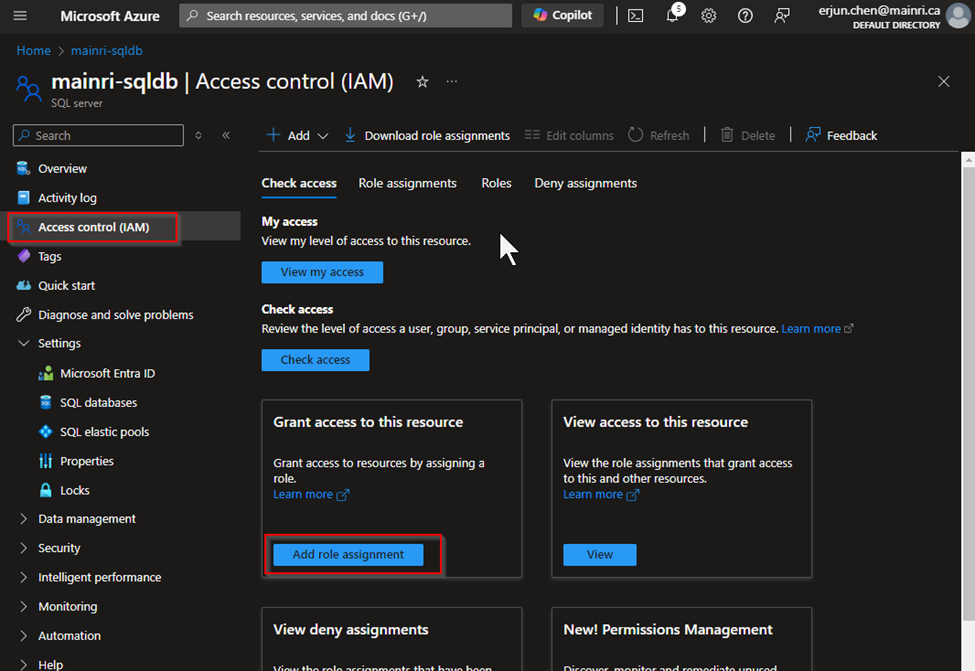
Set Up Role-Based Access Control (RBAC)
You can manage permissions through Azure Entra ID roles and assign these roles to your SQL Database resources.
Assign Roles via Azure Portal
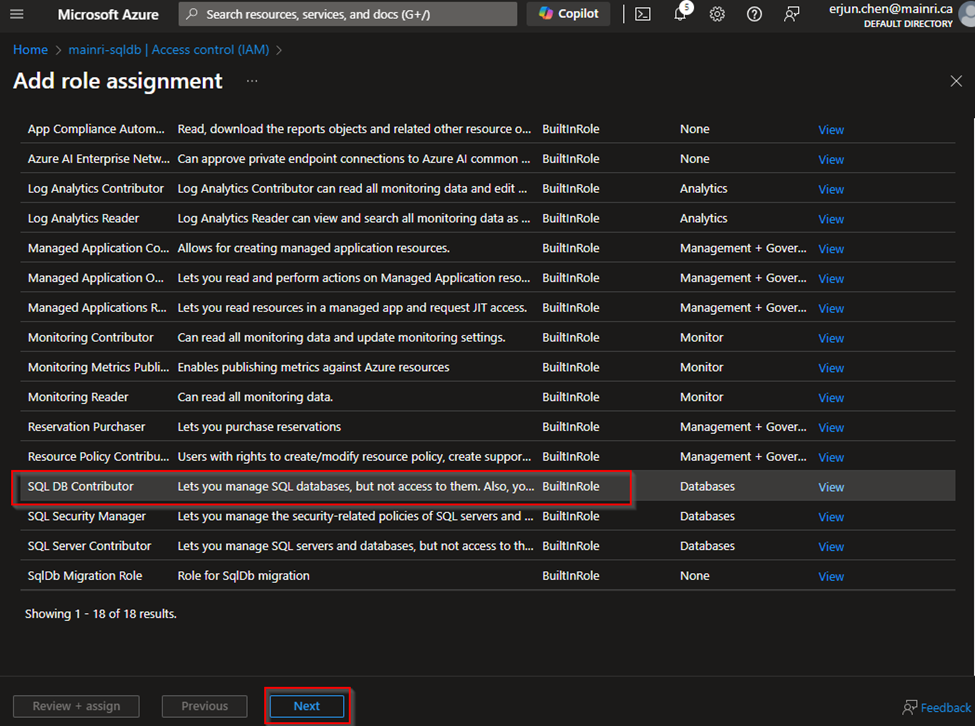
Azure portal > your SQL Database > Access control (IAM) > Add role assignment.
Choose the appropriate role, such as “SQL DB Contributor“.
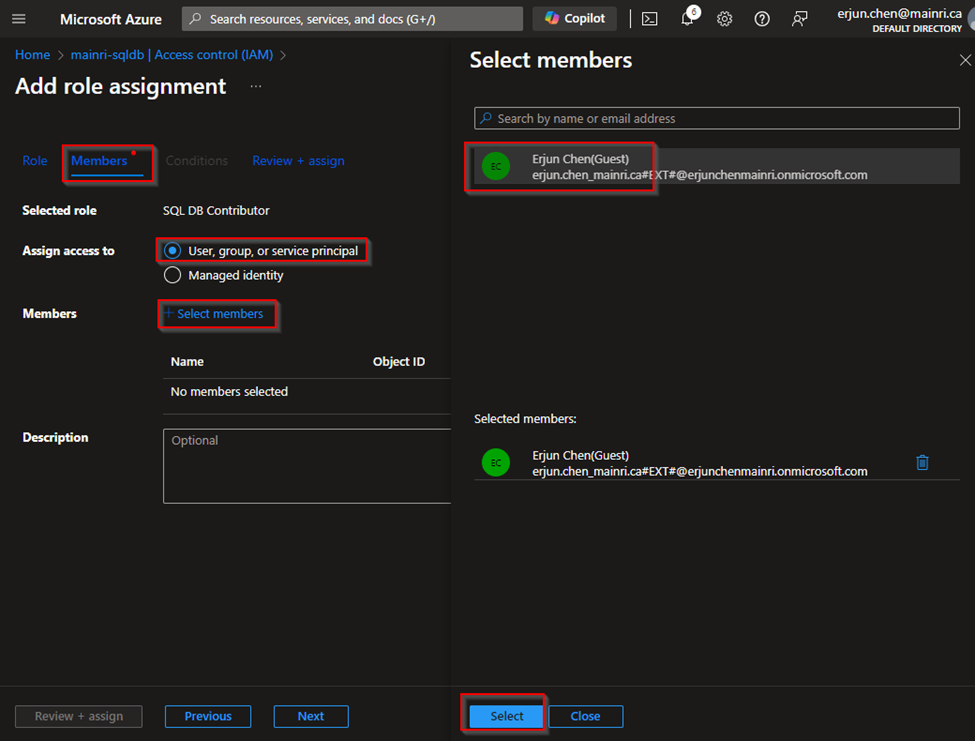
and assign it to the desired Azure Entra ID user or group
Considerations
No Password Management: Since authentication is managed via Azure Entra ID, there’s no need to manage passwords directly within the database.
Integration with Conditional Access: This allows you to enforce compliance requirements, such as requiring MFA or ensuring connections only come from specific locations.
Please do not hesitate to contact me if you have any questions at William . chen @ mainri.ca
Azure Key Vault safeguards encryption keys and secrets like certificates, connection strings, and passwords.
Key vaults define security boundaries for stored secrets. It allows you to securely store service or application credentials like passwords and access keys as secrets. All secrets in your key vault are encrypted with a software key. When you use Key Vault, you no longer need to store security information in your applications. Not having to store security information in applications eliminates the need to make this information part of the code.
What is a secret in Key Vault?
In Key Vault, a secret is a name-value pair of strings. Secret names must be 1-127 characters long, contain only alphanumeric characters and dashes, and must be unique within a vault. A secret value can be any UTF-8 string up to 25 KB in size.
Vault authentication and permissions
Developers usually only need Get and List permissions to a development-environment vault. Some engineers need full permissions to change and add secrets, when necessary.
For apps, often only Get permissions are required. Some apps might require List depending on the way the app is implemented. The app in this module’s exercise requires the List permission because of the technique it uses to read secrets from the vault.
In this article, we will focus on 2 sections, set up secrets in Key Vault and application retrieves secrets that ware saved in Key vault.
Create a Key Vault and store secrets
Creating a vault requires no initial configuration. You can start adding secrets immediately. After you have a vault, you can add and manage secrets from any Azure administrative interface, including the Azure portal, the Azure CLI, and Azure PowerShell. When you set up your application to use the vault, you need to assign the correct permissions to it
Create a Key Vault service
To create Azure Key Vault service, you can follow the steps.
From Azure Portal, search “key Vault”
click “key Vault”
Fill in all properties
Click review + create. That’s all. Quite simple, right?
Create secrets and save in Key Vault
There are two ways to create secret and save in Key vault.
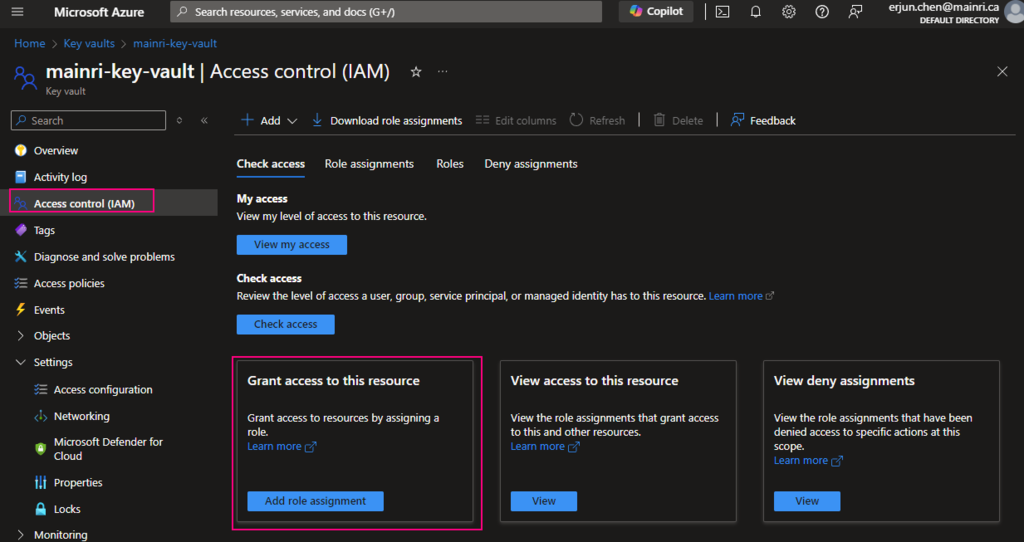
Access control, Identity and Access management (IAM)
Access Policies
Using Access Control (IAM) create a secret
From Key Vault> Access Control (IAM) > Add role Assignment
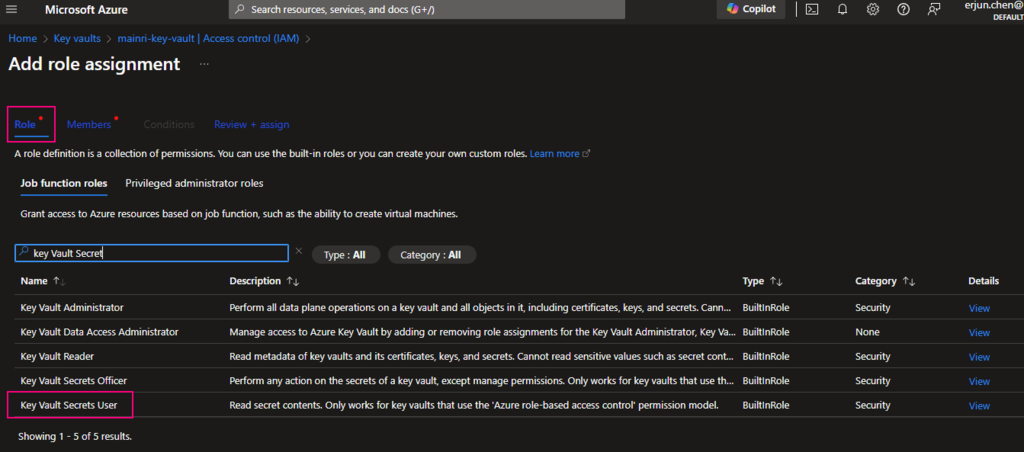
In most cases, if you create and save secrets in key-vault for your users to use, you only need add the “Key vault secrets user” role assignment.
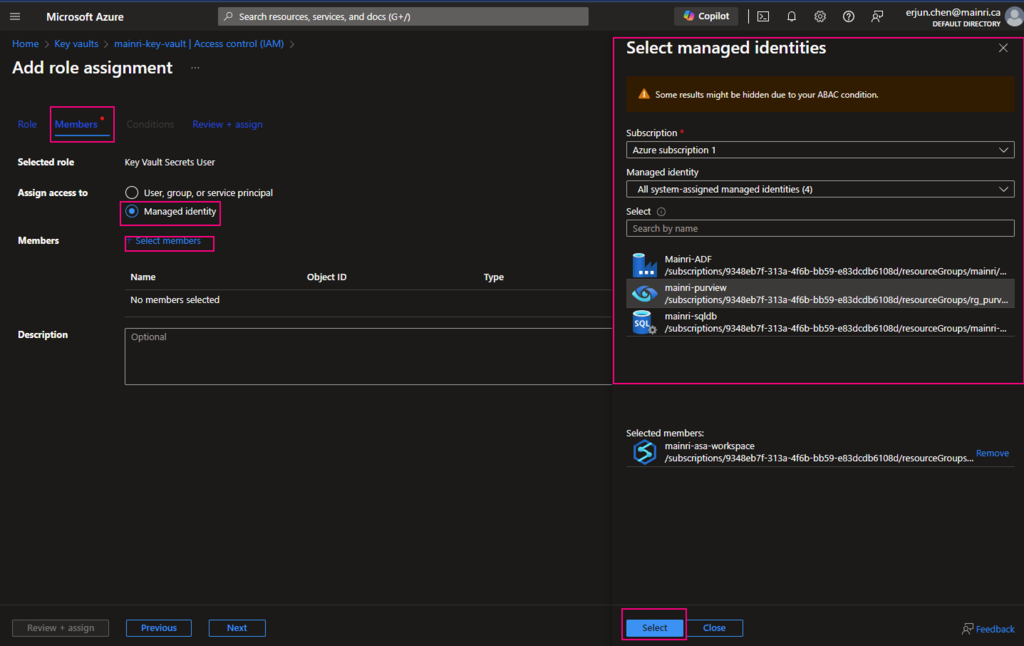
click “next” select a member or group
Pay attention to here, if your organization has multiple instances of the same services, for example, different teams are independently using different ADF instants, make sure you correctly, accurately add the right service instant to access policies.
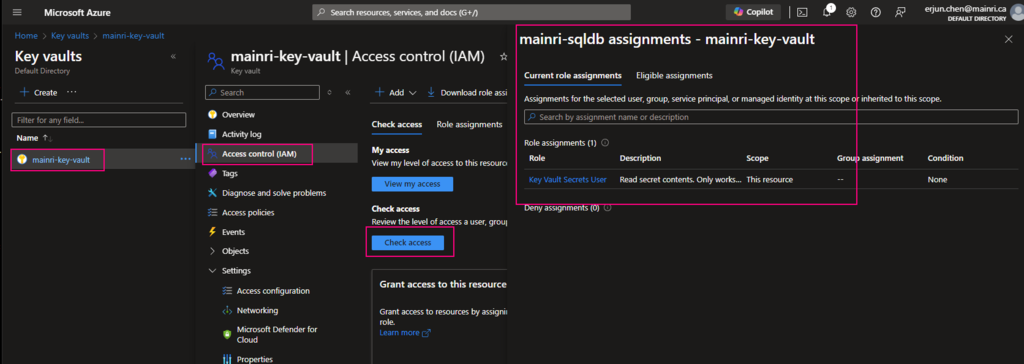
Once it’s down, check the access.
Create a Secret
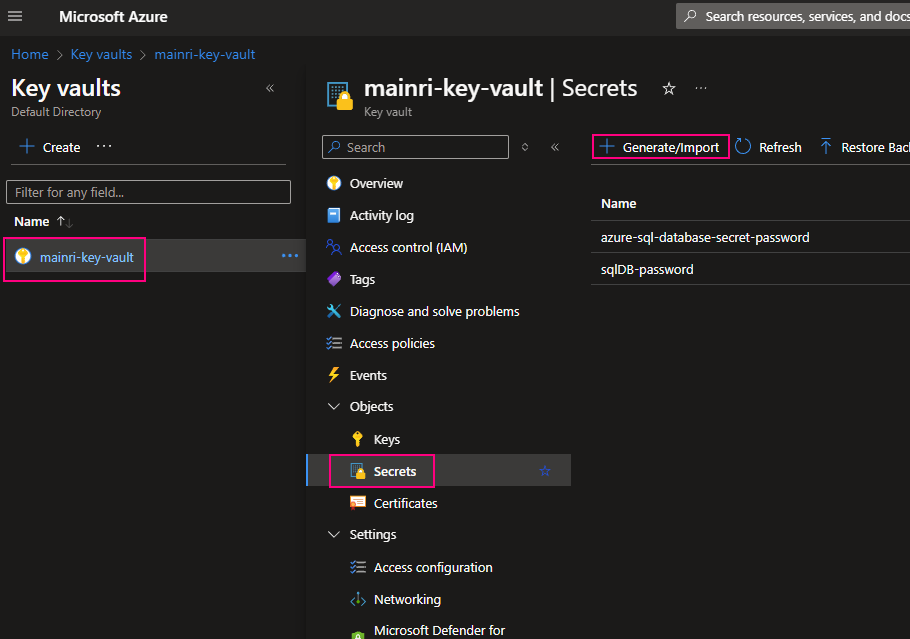
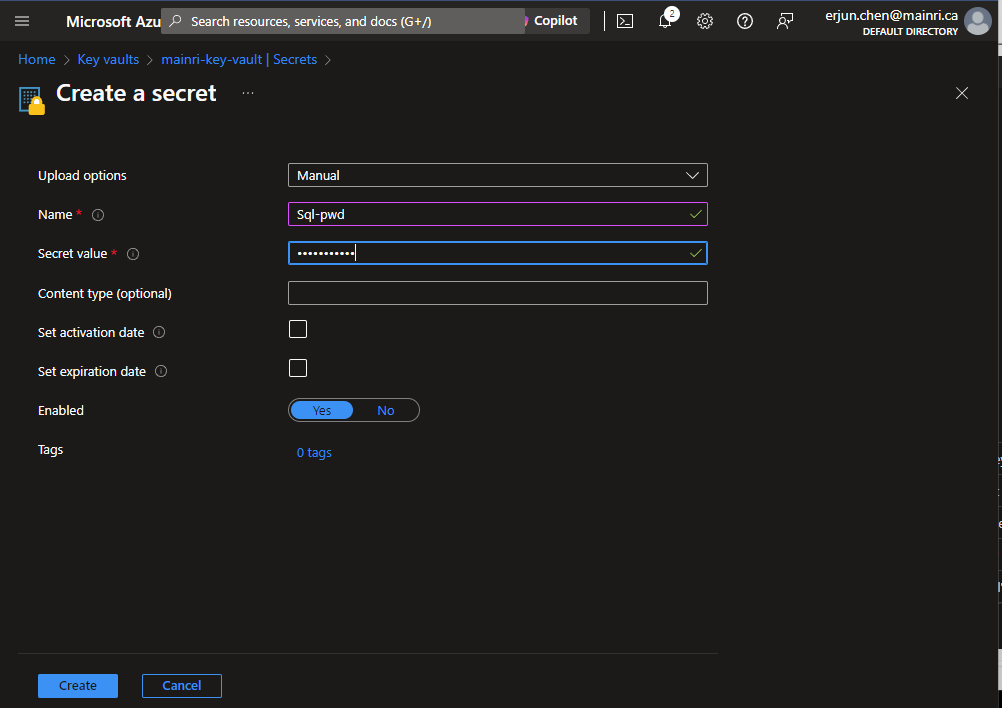
From “Key Vault” > “Object” > “Secrets” > “+ Generate/Import”
Fill in all properties, :Create”
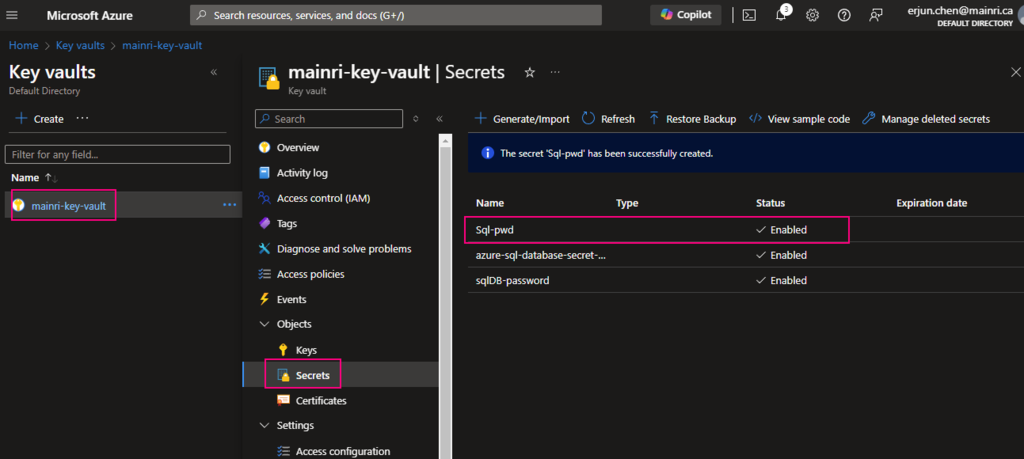
Secrets key and value created That’s all.
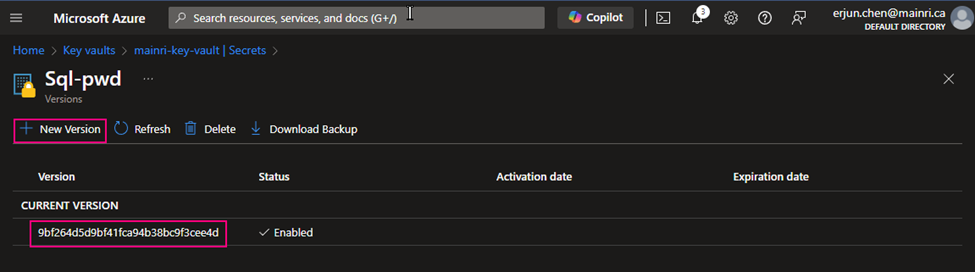
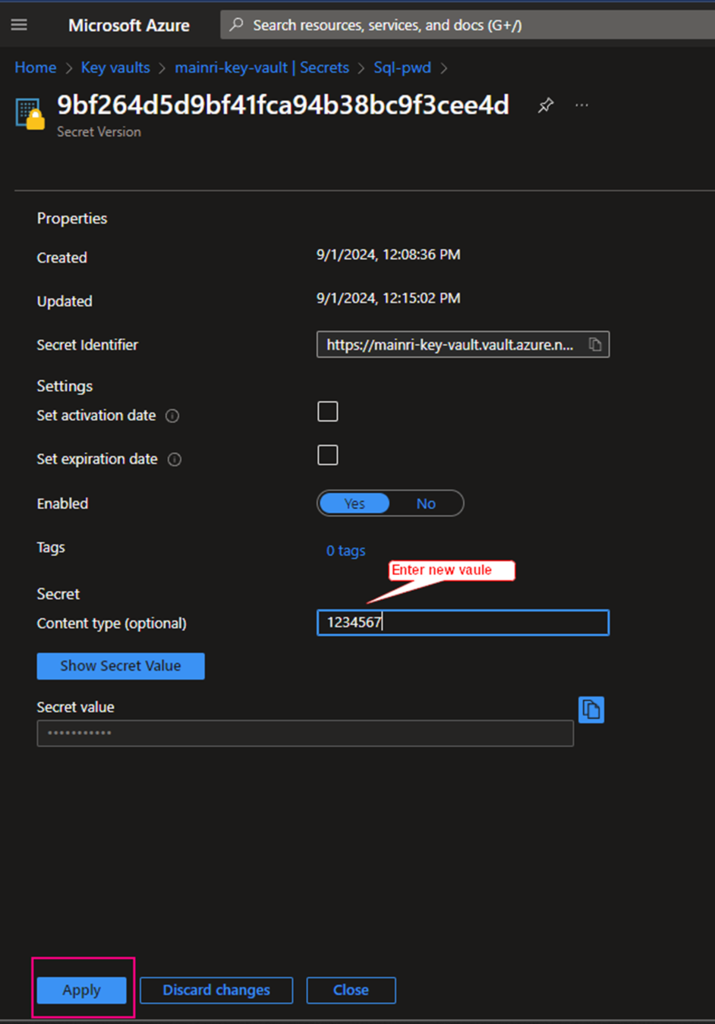
If you want to update the secret, simply click the key, follow the UI guide, you will not miss it.
Click the “version” that you want to update. Update the content > apply it.
That’s all.
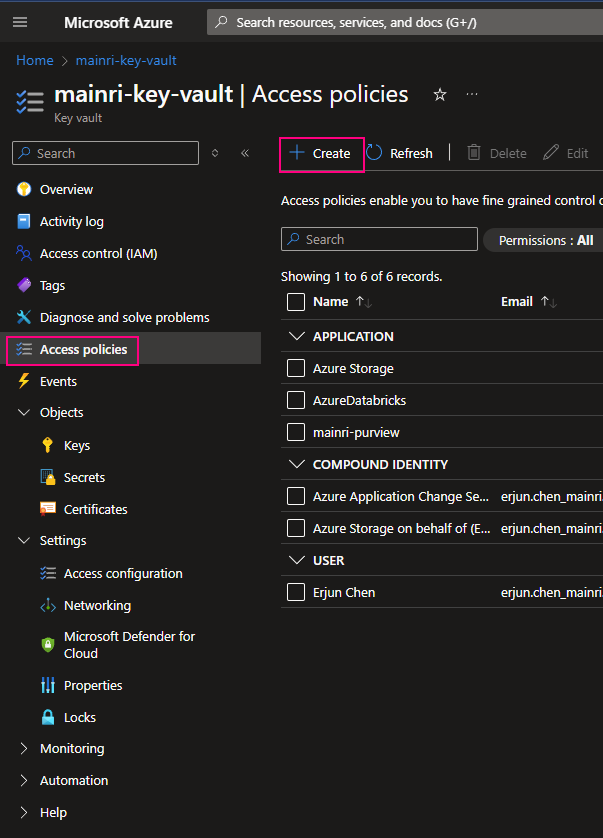
Using Access Policies create a secret
There is another way “Access Policies” to create a secret.
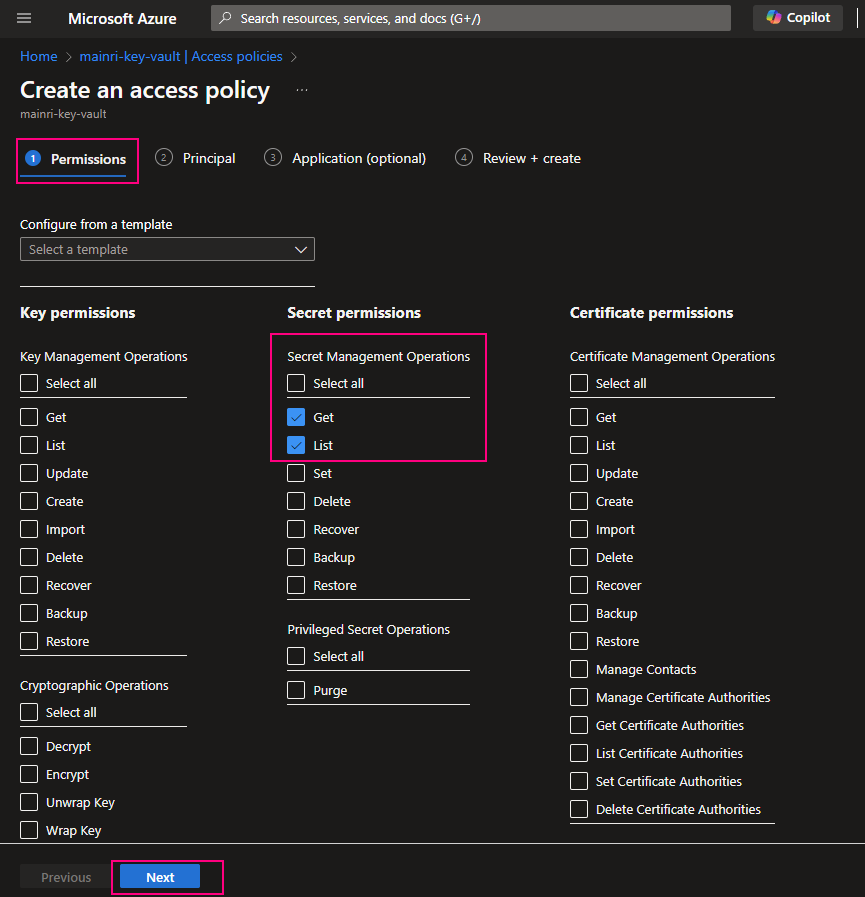
Select the permissions you want under Key permissions, Secret permissions, and Certificate permissions.
If you create a key secret for users to use in their application or other azure services, usually you give “get” and “list” in the “Secret permissions” enough. Otherwise, check Microsoft official documentation.
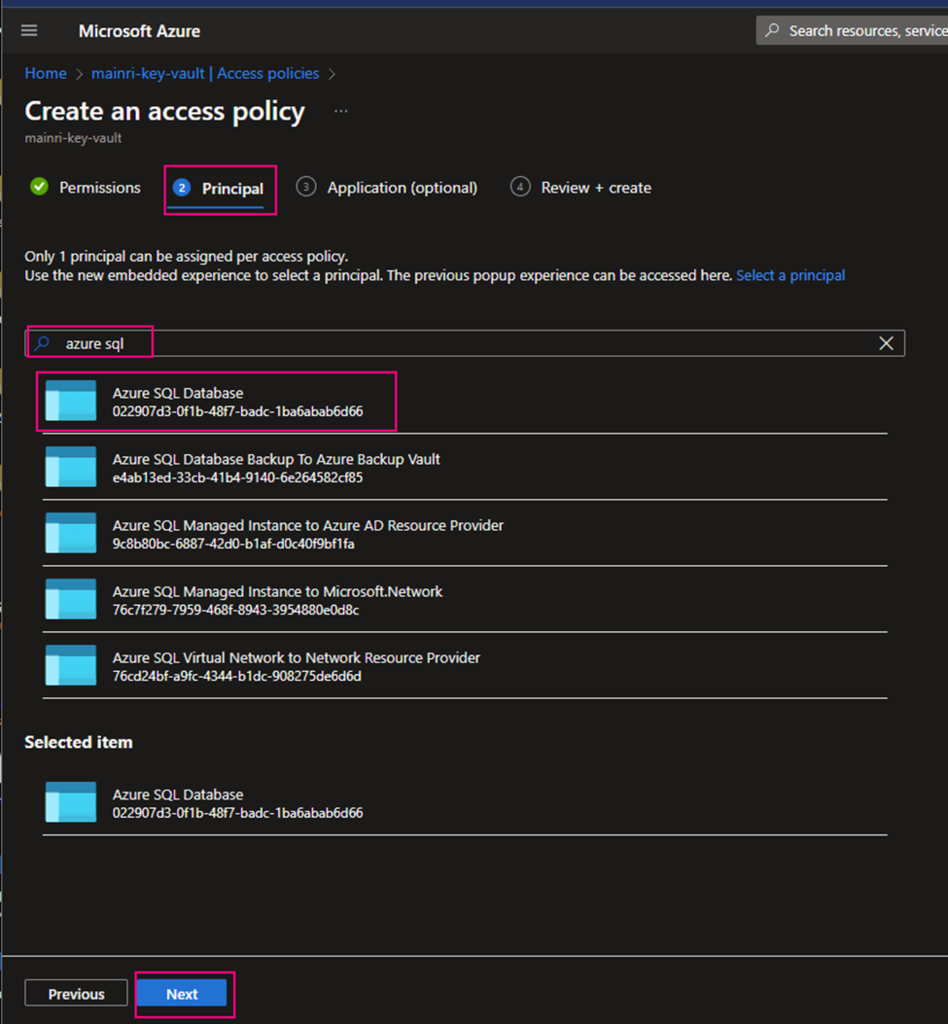
Under the Principal selection pane, enter the name of the user, app or service principal in the search field and select the appropriate result.
Using Azure SQL Database as an example
Caution: when you add principal, make sure you select right service instant. Especially you act as a infrastructure administer, your organization has multiple teams that they are independently using different service instants, e.g. different Synapse Workspace. select correct instant. I have been asked to help trouble shotting this scenario a few time. Azure admin says, he has added policies to key-vault, but the use cannot access there yet. that is a funny mistake made, he has added ADF to kay-vault policies, unfortunately, the ADF is NOT team A used, team B is using it. 🙂
Back on the Access policies page, verify that your access policy is listed.
Create secret key and value
We have discussed it above. Need not verbose.
Done!
Using secrets that were saved in Key Vault
Using secrets usually have 2 major scenarios, directly use, or use REST API call to retrieve the saved secret value.
Let’s use Data Factory as an example to discuss.
Scenario 1, directly use it
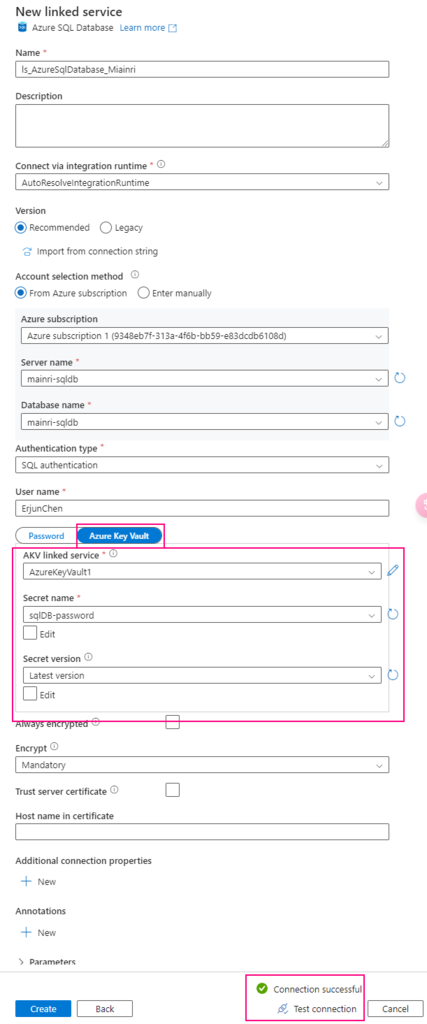
For example, when you create linked service to connect Azure Sql Database
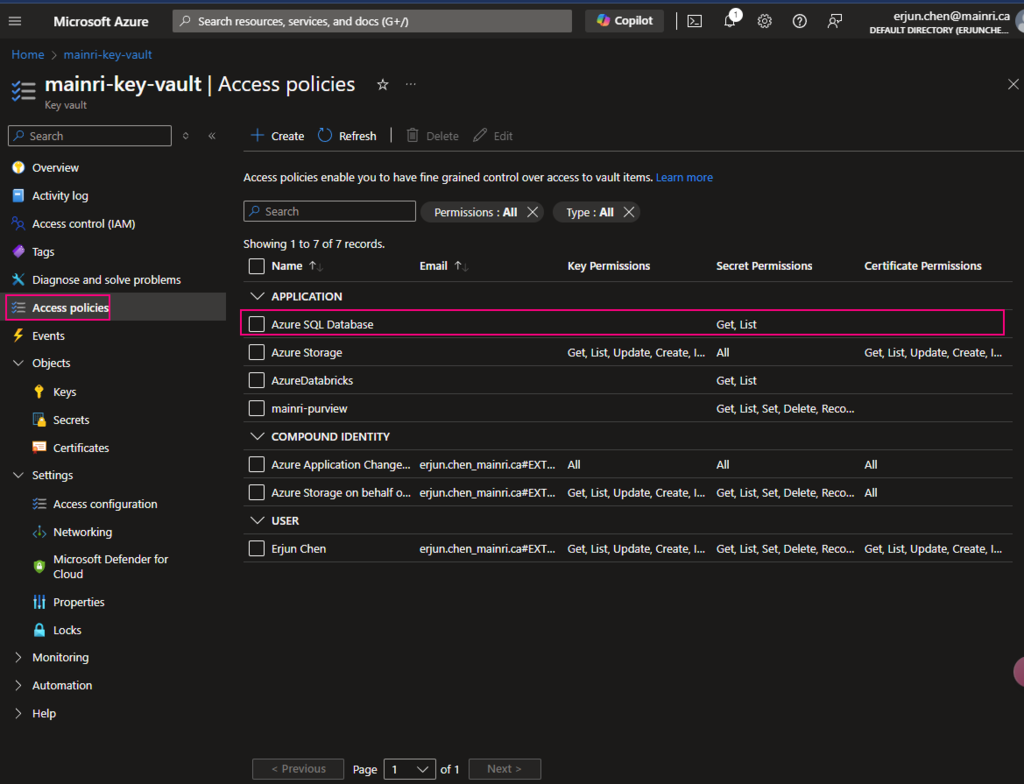
You have to make sure that Key Vault’s access policies has this ADF access policies, get and list
one more example, System workspaces use key-vault.
Once again, make sure your Synapse Workspace has access policies, “Key Vault Secrets User“, “get” and “List”
Scenario 2, REST API call Key Vault to use secret
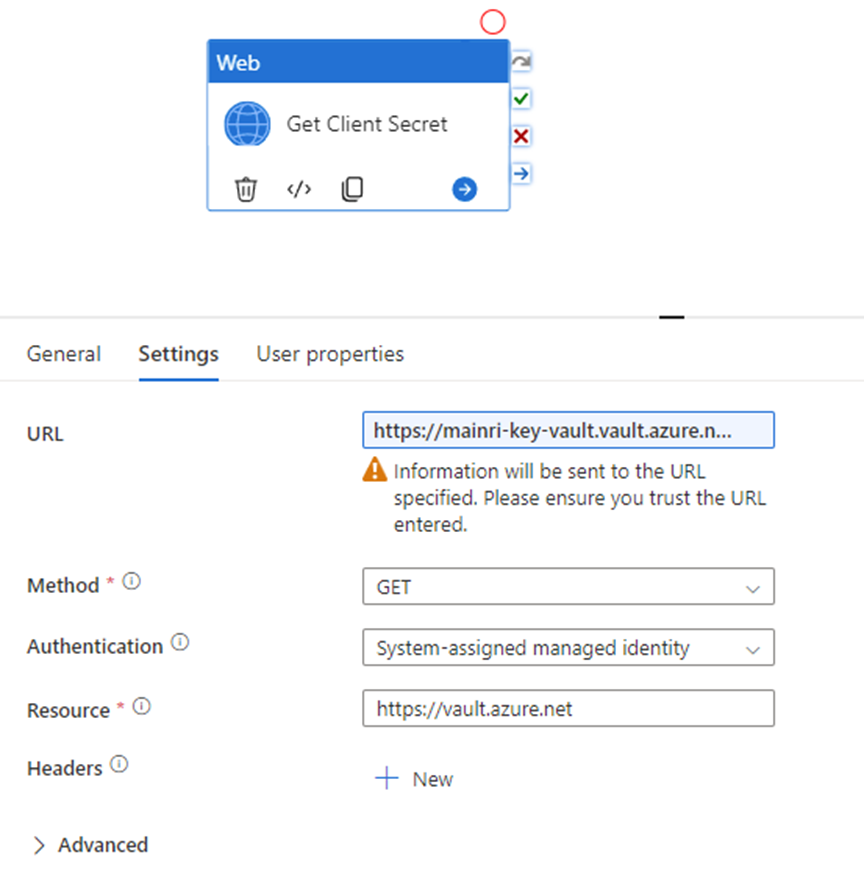
Many engineers want to call the key Vault to retrieve the secret value for a certain purpose, e.g. Synapse pipeline to get SharePoint Online list or files that resident in SharePoint Library, you need an application secret value to build the query string. Normally, the application’s secret value is saved in Key Vault. In this case, you have to make a http call to Key value.
Get a specified secret from a given key vault. The GET operation is applicable to any secret stored in Azure Key Vault. This operation requires the secrets/get permission.
GET {vaultBaseUrl}/secrets/{secret-name}/{secret-version}?api-version=7.4
An external data source in Synapse serverless SQL is typically used to reference data stored outside of the SQL pool, such as in Azure Data Lake Storage (ADLS) or Blob Storage. This allows you to query data directly from these external sources using T-SQL.
There are different ways to create external data source. Using Synapse Studio UI, coding etc. the easiest way is to leverage Synapse Studio UI. But we had better know how to use code to create it since in some cases we have to use this way.
Here’s how to create an external data source in Synapse serverless SQL
Using Synapse Studio UI to create External Data Source
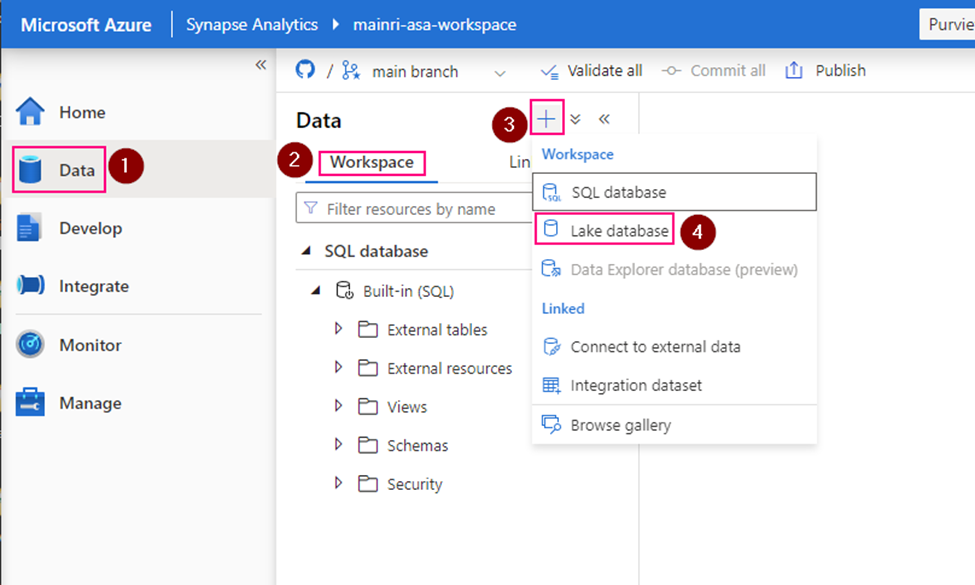
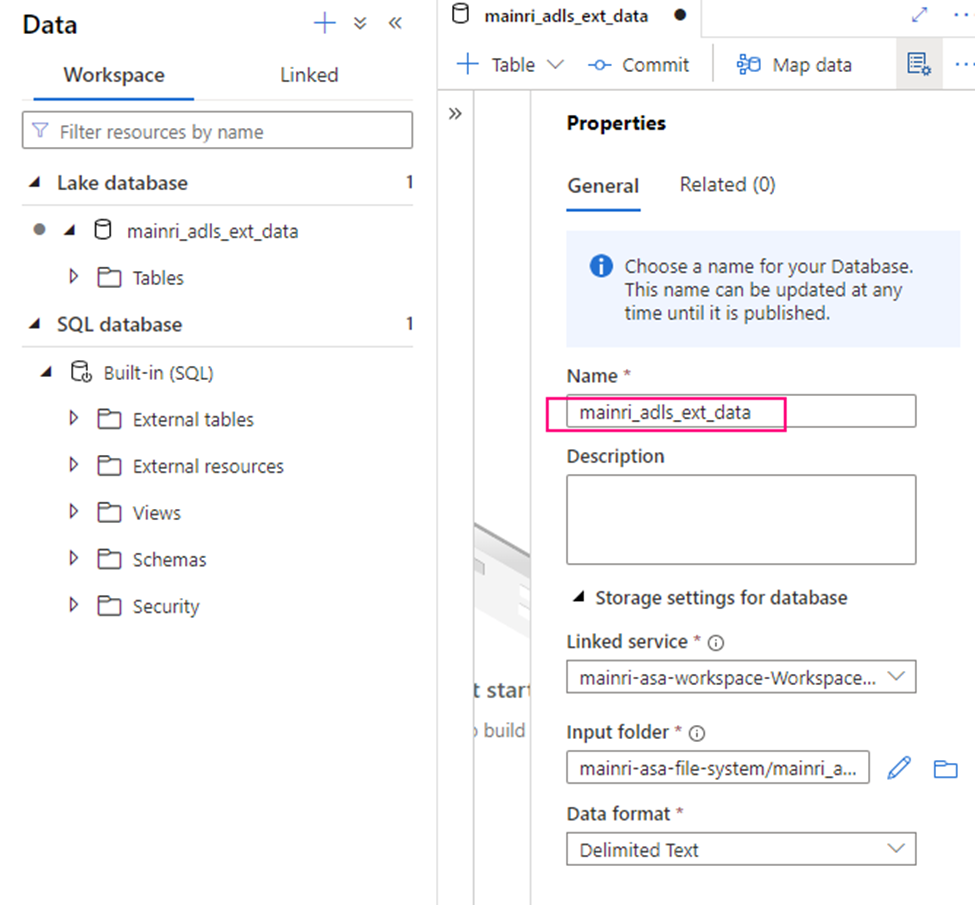
Create Lake Database
Open Synapse Studio
On the left side, select Data portal > workspace
Fill in the properties:
Create external table from data lake
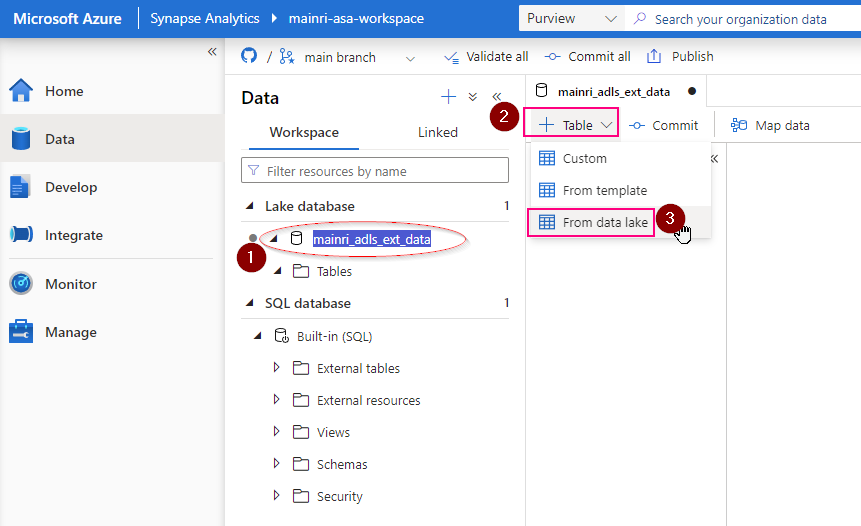
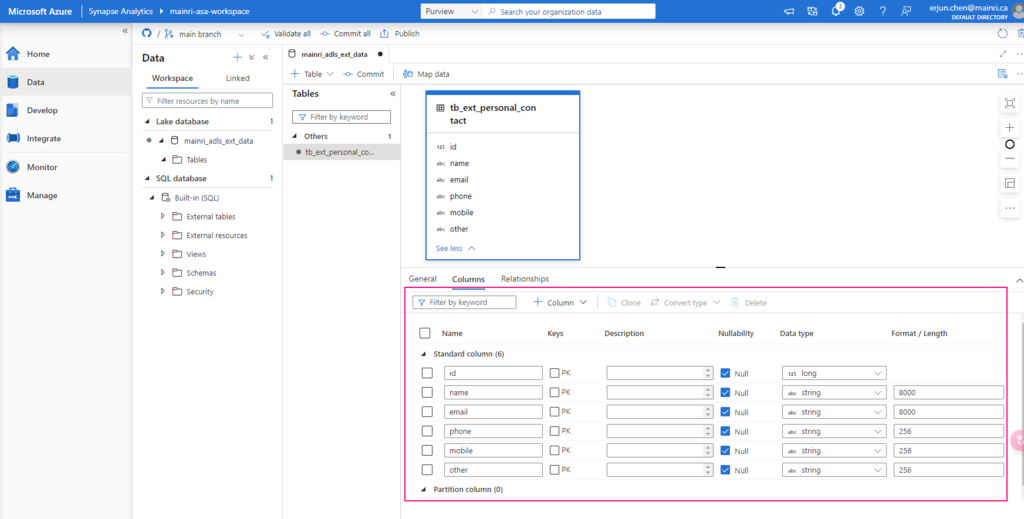
Double clicks the Lake Database you just created.
in the Lake Database tag, click “+ Table”
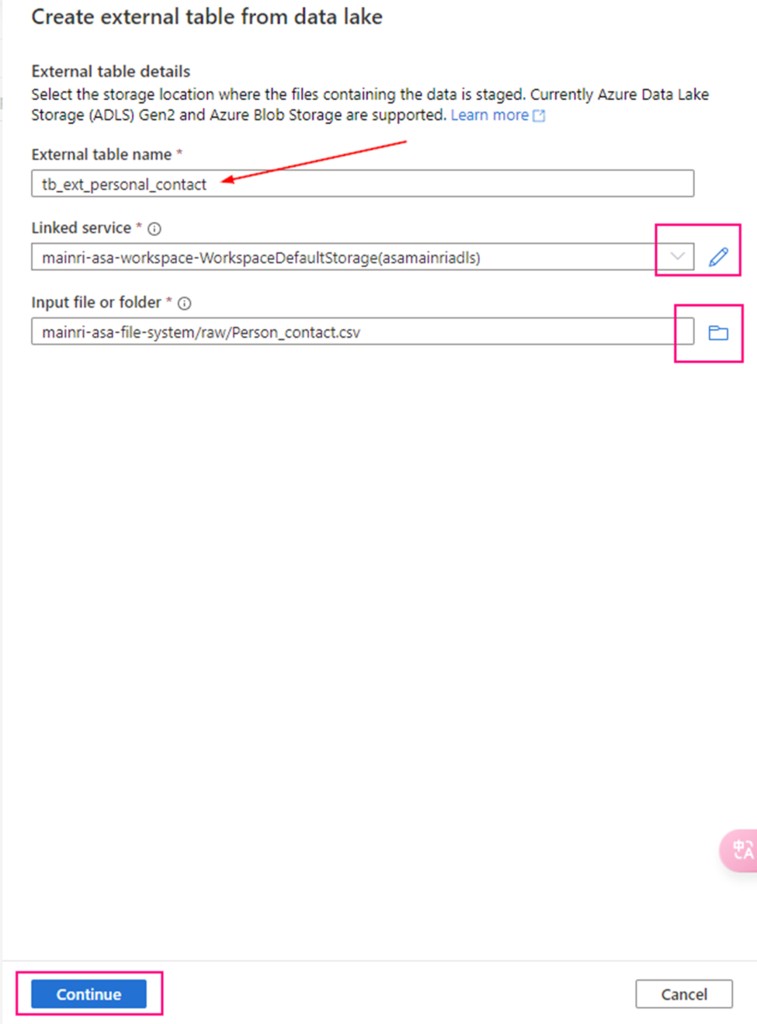
fill in the detail information:
Continue to configure the table properyies
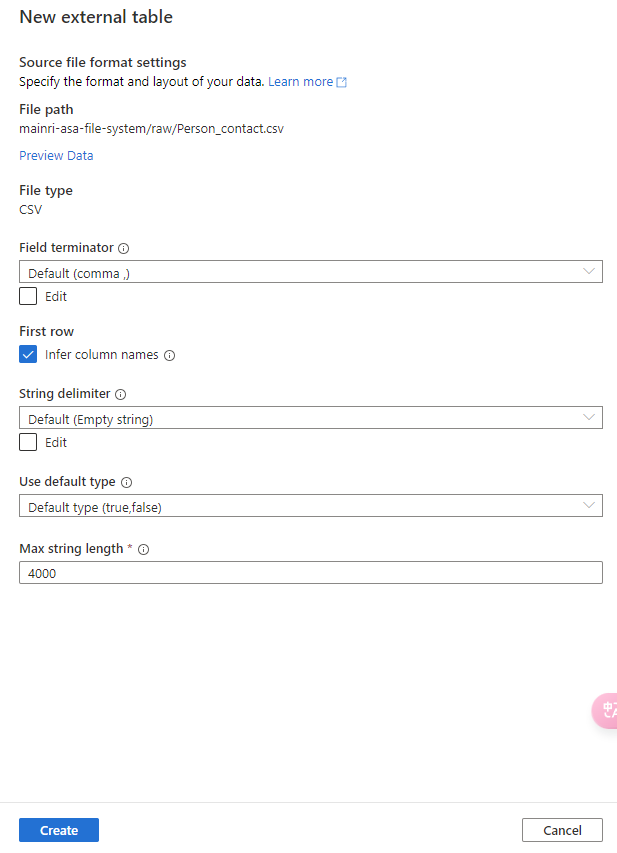
Adjust Table properties
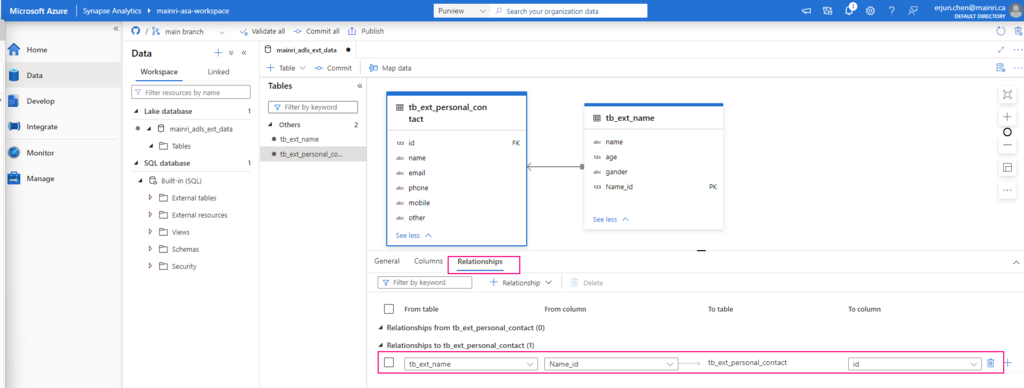
Adjust column other properties, or add even more columns, such as data type, description, Nullability, Primary Key, set up partition create relationship …… etc.
Repeat the above steps to create even more tables to meet your business logic need, or create relationship if need.
Script to create an External Data Source
Step 1:
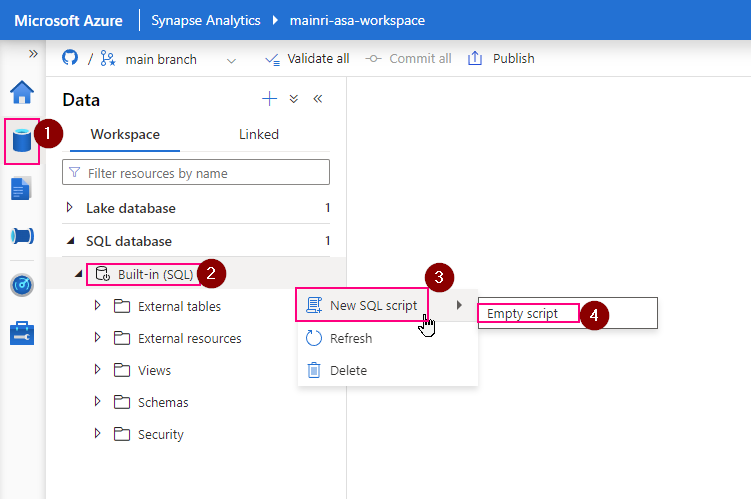
1. Connect to Serverless SQL Pool:
Open Synapse Studio, go to the “Data” hub, and connect to your serverless SQL pool.
2. Create the External Data Source:
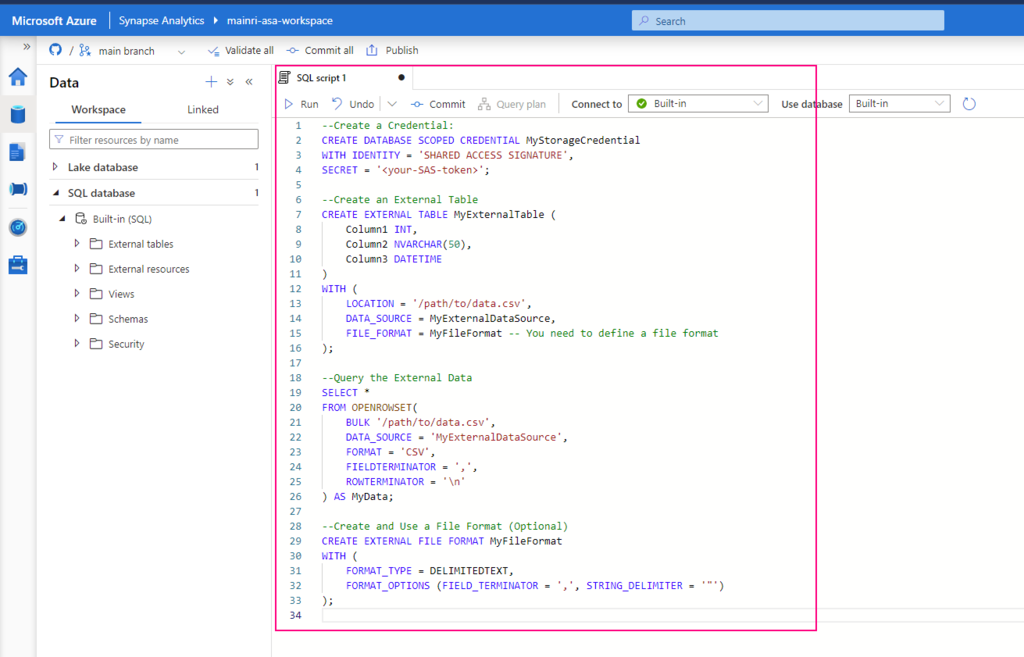
Use the following T-SQL script to create an external data source that points to your Azure Data Lake Storage (ADLS) or Blob Storage:
CREATE EXTERNAL DATA SOURCE MyExternalDataSource WITH ( LOCATION = ‘https://<your-storage-account-name>.dfs.core.windows.net/<your-filesystem-name>‘, CREDENTIAL = <your-credential-name> );
Replace <your-storage-account-name>, <your-filesystem-name>, and <your-credential-name> with the appropriate values:
LOCATION: The URL of your Azure Data Lake Storage (ADLS) or Blob Storage.
CREDENTIAL: The name of the database credential used to access the storage. (You may need to create this credential if it doesn’t already exist.)
Step 2:
If you don’t have a credential yet, create one as follows:
Replace <your-SAS-token> with your Azure Storage Shared Access Signature (SAS) token.
2. Create an External Table or Query the External Data
After setting up the external data source, you can create external tables or directly query data:
Create an External Table:
You can create an external table that maps to the data in your external storage:
CREATE EXTERNAL TABLE MyExternalTable ( Column1 INT, Column2 NVARCHAR(50), Column3 DATETIME ) WITH ( LOCATION = ‘/path/to/data.csv’, DATA_SOURCE = MyExternalDataSource, FILE_FORMAT = MyFileFormat — You need to define a file format );
Query the External Data
You can also directly query the data without creating an external table:
SELECT * FROM OPENROWSET( BULK ‘/path/to/data.csv’, DATA_SOURCE = ‘MyExternalDataSource’, FORMAT = ‘CSV’, FIELDTERMINATOR = ‘,’, ROWTERMINATOR = ‘\n’ ) AS MyData;
Create and Use a File Format (Optional)
If you are querying structured files (like CSV, Parquet), you might need to define a file format:
CREATE EXTERNAL FILE FORMAT MyFileFormat WITH ( FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS (FIELD_TERMINATOR = ‘,’, STRING_DELIMITER = ‘”‘) );
Summary
By following these steps, you should be able to connect to and query your external data sources using the serverless SQL pool in Synapse. Let me know if you need further assistance!
Create an external data source in Synapse serverless SQL to point to your external storage.
Create a database scoped credential if necessary to access your storage.
Create an external table or directly query data using OPENROWSET.
Define a file format if working with structured data like CSV or Parquet.
Please do not hesitate to contact me if you have any questions at William . chen @ mainri.ca