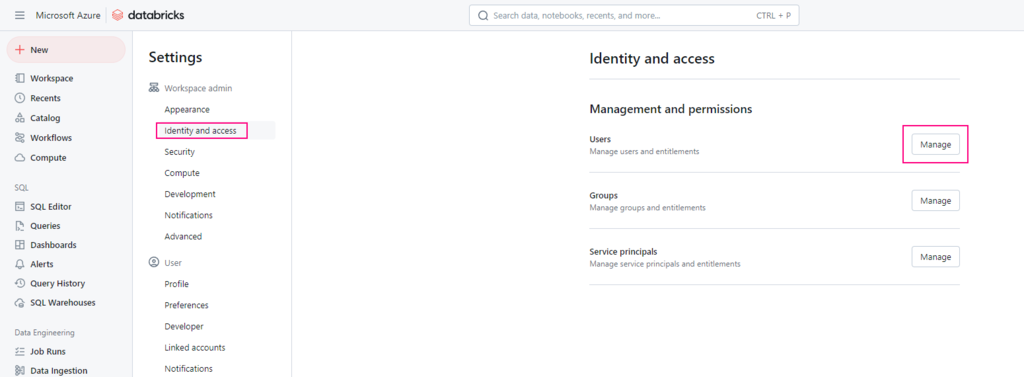
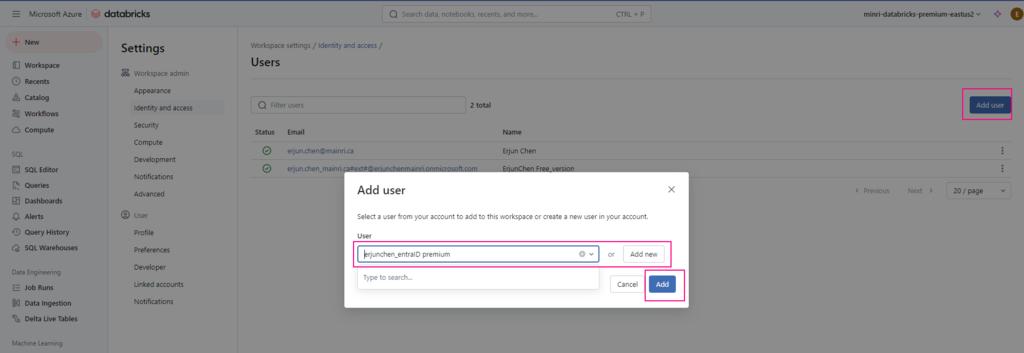
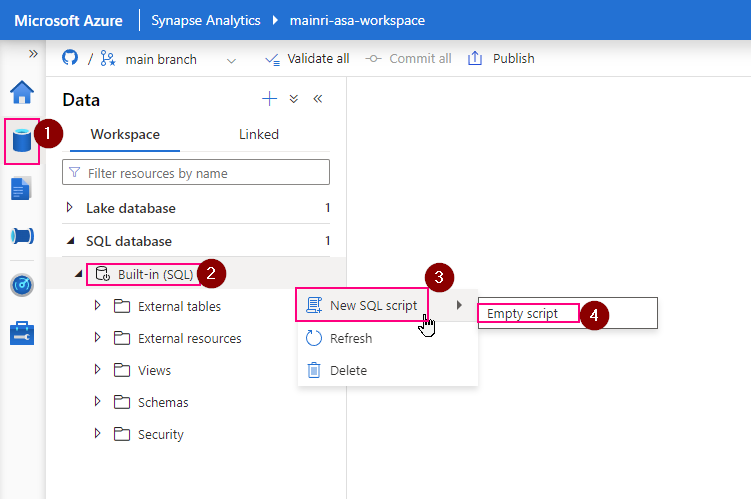
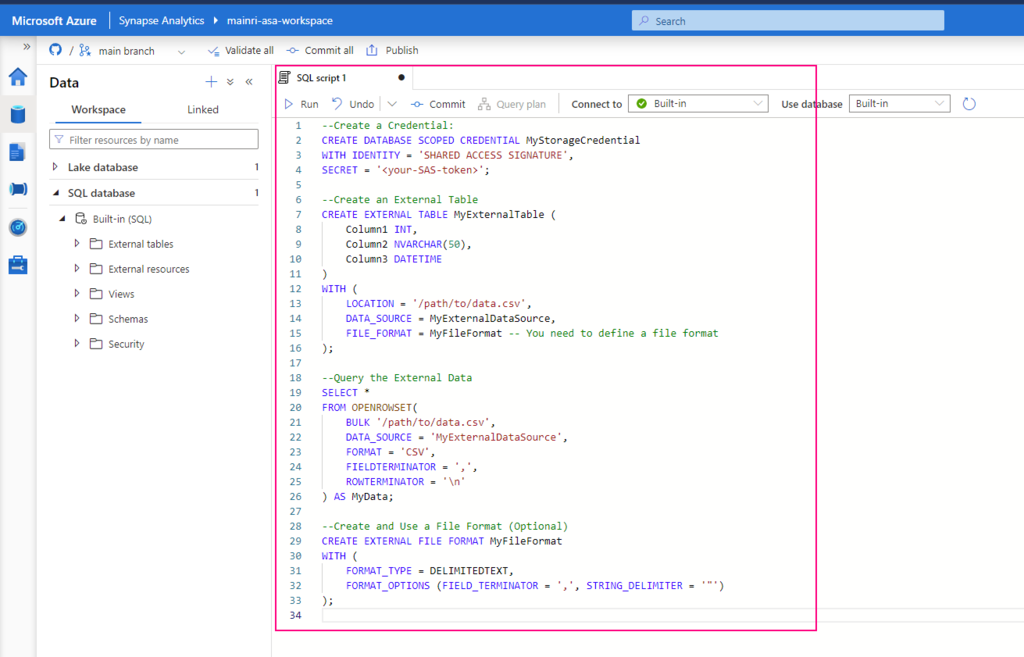
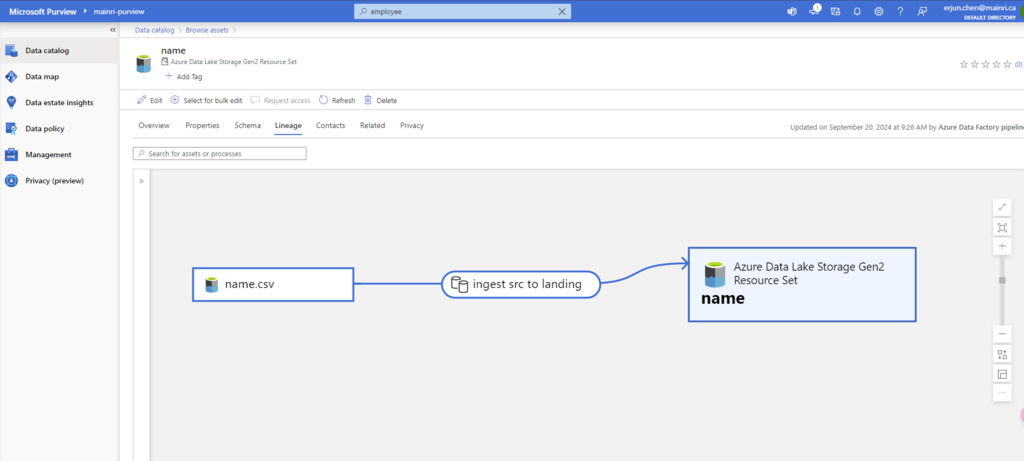
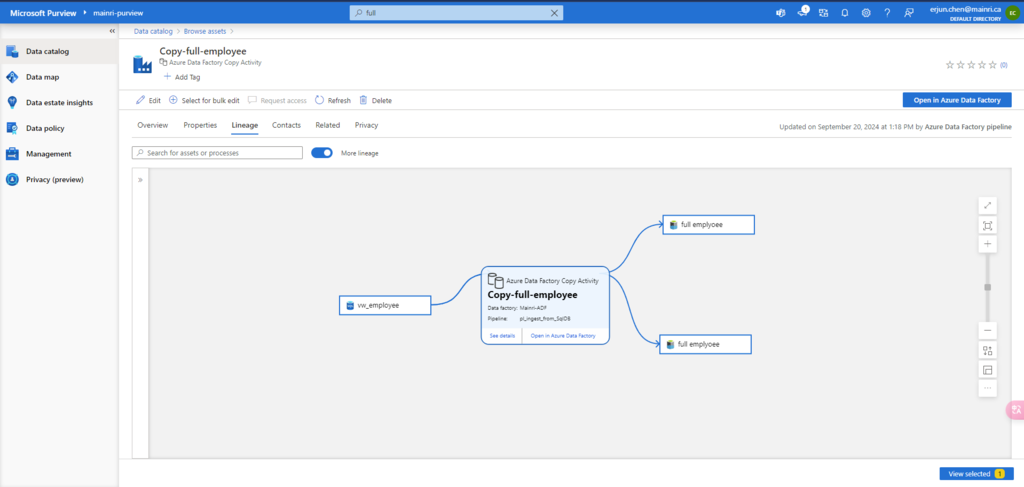
To allow another user to use your Azure Databricks workspace, follow these steps:
1. Log in to Databricks
Log in to the Azure Databricks workspace as a workspace admin.
2. Setting
Click your username in the top bar of the Azure Databricks workspace and select Settings.
3. Navigate to the Identity and access tab.
Next to Users, click Manage.
4. Click Add User.
Select an existing user
Select an existing user to assign to the workspace or click Add new to create a new user. You can add any user who belongs to the Microsoft Entra ID (formerly Azure Active Directory) tenant of your Azure Databricks workspace.
Azure Databricks is a managed platform for running Apache Spark jobs. In this post, I’ll go through some key Databricks terms to give you an overview of the different points you’ll use when running Databricks jobs (sorted by alphabet):
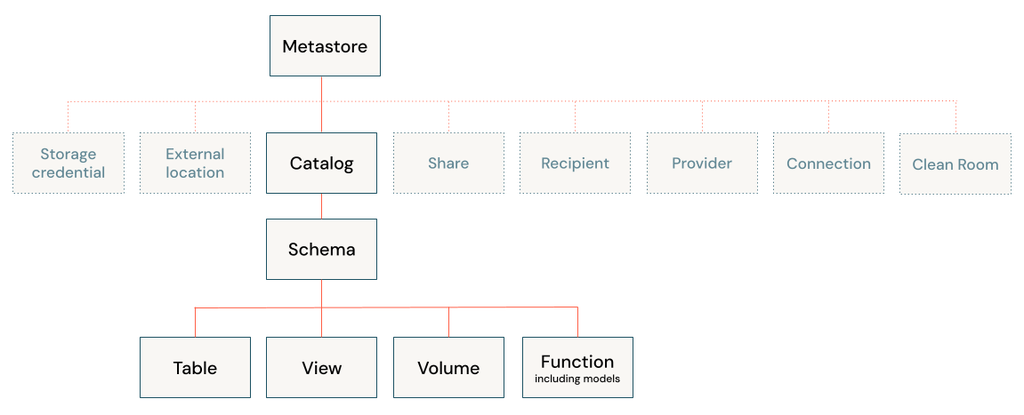
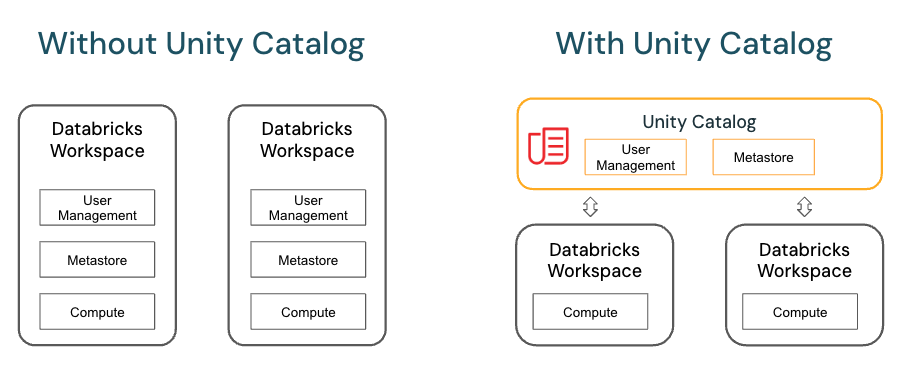
Catalog (Unity Catalog)
the Unity Catalog is a feature that provides centralized governance for data, allowing you to manage access to data across different Databricks workspaces and cloud environments. It helps define permissions, organize tables, and manage metadata, supporting multi-cloud and multi-workspace environments. Key benefits include:
Support for multi-cloud data governance.
Centralized access control and auditing.
Data lineage tracking.
Delta table
A Delta table is a data management solution provided by Delta Lake, an open-source storage layer that brings ACID transactions to big data workloads. A Delta table stores data as a directory of files on cloud object storage and registers table metadata to the metastore within a catalog and schema. By default, all tables created in Databricks are Delta tables.
External tables
External tables are tables whose data lifecycle, file layout, and storage location are not managed by Unity Catalog. Multiple data formats are supported for external tables.
CREATE EXTERNAL TABLE my_external_table (
id INT,
name STRING,
age INT
)
LOCATION 'wasbs://[container]@[account].blob.core.windows.net/data/';
External Data Source
A connection to a data store that isn’t natively in Databricks but can be queried through a connection.
External Data Sources are typically external databases or data services (e.g., Azure SQL Database, Azure Synapse Analytics, Amazon RDS, or other relational or NoSQL databases). These sources are accessed via connectors (JDBC, ODBC, etc.) within Databricks.
The Hive Metastore is the metadata repository for the data in Databricks, storing information about tables and databases. It’s used by the Spark SQL engine to manage metadata for the tables and to store information like schemas, table locations, and partitions. In Azure Databricks:
Schemas: Column names, types, and table structure.
Table locations: The path to where the actual data resides (in HDFS, Azure Data Lake, S3, etc.).
Partitions: If the table is partitioned, the metadata helps optimize query performance.
By default, each Databricks workspace has its own managed Hive metastore.
You can also connect to an external Hive metastore that is shared across multiple Databricks workspaces or use Azure-managed services like Azure SQL Database for Hive metadata storage.
Managed tables
Managed tables are the preferred way to create tables in Unity Catalog. Unity Catalog fully manages their lifecycle, file layout, and storage. Unity Catalog also optimizes their performance automatically. Managed tables always use the Delta table format.
Managed tables reside in a managed storage location that you reserve for Unity Catalog. Because of this storage requirement, you must use CLONE or CREATE TABLE AS SELECT (CTAS) if you want to copy existing Hive tables to Unity Catalog as managed tables.
Mounting Data
Mounting external storage into Databricks as if it’s part of the Databricks File System (DBFS)
In Databricks, Workflows are a way to orchestrate data pipelines, machine learning tasks, and other computational processes. Workflows allow you to automate the execution of notebooks, Python scripts, JAR files, or any other job task within Databricks and run them on a schedule, trigger, or as part of a complex pipeline.
Key Components of Workflows in Databricks:
Jobs: Workflows in Databricks are typically managed through jobs. A job is a scheduled or triggered run of a notebook, script, or other tasks in Databricks. Jobs can consist of a single task or multiple tasks linked together.
Task: Each task in a job represents an individual unit of work. You can have multiple tasks in a job, which can be executed sequentially or in parallel.
Triggers: Workflows can be triggered manually, based on a schedule (e.g., hourly, daily), or triggered by an external event (such as a webhook).
Cluster: When running a job in a workflow, you need to specify a Databricks cluster (either an existing cluster or one that is started just for the job). Workflows can also specify job clusters, which are clusters that are spun up and terminated automatically for the specific job.
Types of Workflows
Single-task Jobs: These jobs consist of just one task, like running a Databricks notebook or a Python/Scala/SQL script. You can schedule these jobs to run at specific intervals or trigger them manually.
Multi-task Workflows: These workflows are more complex and allow for creating pipelines of interdependent tasks that can be run in sequence or in parallel. Each task can have dependencies on the completion of previous tasks, allowing you to build complex pipelines that branch based on results.Example: A data pipeline might consist of three tasks:
Task 1: Ingest data from a data lake into a Delta table.
Task 2: Perform transformations on the ingested data.
Task 3: Run a machine learning model on the transformed data.
Parameterized Workflows: You can pass parameters to a job when scheduling it, allowing for more dynamic behavior. This is useful when you want to run the same task with different inputs (e.g., processing data for different dates).
Creating Workflows in Databricks
Workflows can be created through the Jobs UI in Databricks or programmatically using the Databricks REST API.
Example of Creating a Simple Workflow:
Navigate to the Jobs Tab:
In Databricks, go to the Jobs tab in the workspace.
Create a New Job:
Click Create Job.
Specify the name of the job.
Define a Task:
Choose a task type (Notebook, JAR, Python script, etc.).
Select the cluster to run the job on (or specify a job cluster).
Add parameters or libraries if required.
Schedule or Trigger the Job:
Set a schedule (e.g., run every day at 9 AM) or choose manual triggering.
You can also configure alerts or notifications (e.g., send an email if the job fails).
Multi-task Workflow Example:
Add Multiple Tasks:
After creating a job, you can add more tasks by clicking Add Task.
For each task, you can specify dependencies (e.g., Task 2 should run only after Task 1 succeeds).
Manage Dependencies:
You can configure tasks to run in sequence or in parallel.
Define whether a task should run on success, failure, or based on a custom condition.
Key Features of Databricks Workflows:
Orchestration: Allows for complex job orchestration, including dependencies between tasks, retries, and conditional logic.
Job Scheduling: You can schedule jobs to run at regular intervals (e.g., daily, weekly) using cron expressions or Databricks’ simple scheduler.
Parameterized Runs: Pass parameters to notebooks, scripts, or other tasks in the workflow, allowing dynamic control of jobs.
Cluster Management: Workflows automatically handle cluster management, starting clusters when needed and shutting them down after the job completes.
Notifications: Workflows allow setting up notifications on job completion, failure, or other conditions. These notifications can be sent via email, Slack, or other integrations.
Retries: If a job or task fails, you can configure it to automatically retry a specified number of times before being marked as failed.
Versioning: Workflows can be versioned, so you can track changes and run jobs based on different versions of a notebook or script.
Common Use Cases for Databricks Workflows:
ETL Pipelines: Automating the extraction, transformation, and loading (ETL) of data from source systems to a data lake or data warehouse.
Machine Learning Pipelines: Orchestrating the steps involved in data preprocessing, model training, evaluation, and deployment.
Batch Processing: Scheduling large-scale data processing tasks to run on a regular basis.
Data Ingestion: Automating the ingestion of raw data into Delta Lake or other storage solutions.
Alerts and Monitoring: Running scheduled jobs that trigger alerts based on conditions in the data (e.g., anomaly detection).
You are working on a project that requires migrating legacy stuffs from old environment to a new one, and requirement says upgrade business logic to latest. Unfortunately, not enough and clearly documents for you to refer. You did not even know an object where it is since there are so many databases resident in the same server, so many tables, so many views, stored procedure, user defined functions… etc. It is hard to find out the legacy business logics.
sp_MSforeachdb
The sp_MSforeachdb procedure is an undocumented procedure that allows you to run the same command against all databases. There are several ways to get creative with using this command and we will cover these in the examples below. This can be used to select data, update data and even create database objects. You can use the sp_MSforeachdb stored procedure to search for objects by their name across all databases:
EXEC sp_MSforeachdb
'USE [?];
SELECT ''?'' AS DatabaseName, name AS ObjectName, type_desc AS ObjectType, Type_desc as object_Desc
, Create_date
, Modify_date
FROM sys.objects
WHERE name = ''YourObjectName'';';
Replace ‘YourObjectName’ with the actual name of the object you’re searching for (table, view, stored procedure, etc.).
The type_desc column will tell you the type of the object (e.g., USER_TABLE, VIEW, SQL_STORED_PROCEDURE, etc.).
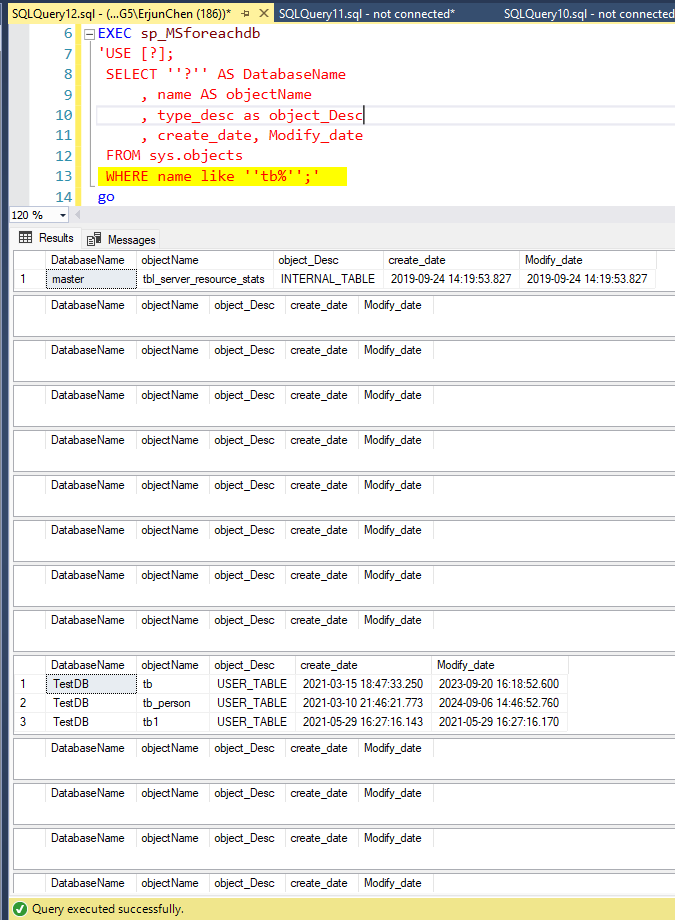
For example, find out the “tb” prefix objects
EXEC sp_MSforeachdb 'USE [?]; SELECT ''?'' AS DatabaseName , name AS objectName , type_desc as object_Desc , create_date, Modify_date FROM sys.objects WHERE name like ''tb%'';' go
Alternative – Loop Through Databases Using a Cursor
If sp_MSforeachdb is not available, you can use a cursor to loop through each database and search for the object:
DECLARE @DBName NVARCHAR(255);
DECLARE @SQL NVARCHAR(MAX);
DECLARE DB_Cursor CURSOR FOR
SELECT name
FROM sys.databases
WHERE state = 0; -- Only look in online databases
OPEN DB_Cursor;
FETCH NEXT FROM DB_Cursor INTO @DBName;
WHILE @@FETCH_STATUS = 0
BEGIN
SET @SQL =
'USE [' + @DBName + '];
IF EXISTS (SELECT 1 FROM sys.objects WHERE name = ''YourObjectName'')
BEGIN
SELECT ''' + @DBName + ''' AS DatabaseName, name AS ObjectName, type_desc AS ObjectType
FROM sys.objects
WHERE name = ''YourObjectName'';
END';
EXEC sp_executesql @SQL;
FETCH NEXT FROM DB_Cursor INTO @DBName;
END;
CLOSE DB_Cursor;
DEALLOCATE DB_Cursor;
You can modify the query to search for specific object types, such as tables or stored procedures:
Find the table
You can use the sp_MSforeachdb system stored procedure to search for the table across all databases.
EXEC sp_MSforeachdb
'USE [?];
SELECT ''?'' AS DatabaseName, name AS TableName
FROM sys.tables
WHERE name = ''YourTableName'';';
If sp_MSforeachdb is not enabled or available, you can use a cursor to loop through all databases and search for the table:
DECLARE @DBName NVARCHAR(255);
DECLARE @SQL NVARCHAR(MAX);
DECLARE DB_Cursor CURSOR FOR
SELECT name
FROM sys.databases
WHERE state = 0; -- Only look in online databases
OPEN DB_Cursor;
FETCH NEXT FROM DB_Cursor INTO @DBName;
WHILE @@FETCH_STATUS = 0
BEGIN
SET @SQL =
'USE [' + @DBName + '];
IF EXISTS (SELECT 1 FROM sys.tables WHERE name = ''YourTableName'')
BEGIN
SELECT ''' + @DBName + ''' AS DatabaseName, name AS TableName
FROM sys.tables
WHERE name = ''YourTableName'';
END';
EXEC sp_executesql @SQL;
FETCH NEXT FROM DB_Cursor INTO @DBName;
END;
CLOSE DB_Cursor;
DEALLOCATE DB_Cursor;
Find the View
You can use the sp_MSforeachdb system stored procedure to search for the view across all databases.
EXEC sp_MSforeachdb 'USE [?]; SELECT ''?'' AS DatabaseName, name AS TableName FROM sys.views WHERE name = ''YourTableName'';';
Find the Stored Procedure
EXEC sp_MSforeachdb
'USE [?];
SELECT ''?'' AS DatabaseName, name AS ProcedureName
FROM sys.procedures
WHERE name = ''YourProcedureName'';';
Please do not hesitate to contact me if you have any questions at William . chen @ mainri.ca
SQL Server Change Data Capture (CDC) is a feature that captures changes to data in SQL Server tables. It captures the changes in the source data and updates only the data in the destination that has changed. Any inserts, updates or deletes made to any of the tables made in a specified time window are captured for further use, such as in ETL processes. Here’s a step-by-step guide to enable and use CDC.
Preconditions
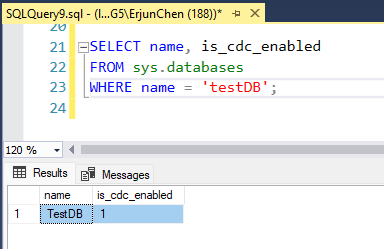
1. SQL Server Agent is running
Since CDC relies on SQL Server Agent, verify that the agent is up and running.
To check if SQL Server Agent is running, you can follow these steps:
Open SQL Server Management Studio (SSMS).
In the Object Explorer, expand the SQL Server Agent node. If you see a green icon next to SQL Server Agent, it means the Agent is running. If the icon is red or gray, it means the SQL Server Agent is stopped or disabled.
To start the Agent, right-click on SQL Server Agent and select Start.
Or start it from SSMS or by using the following command:
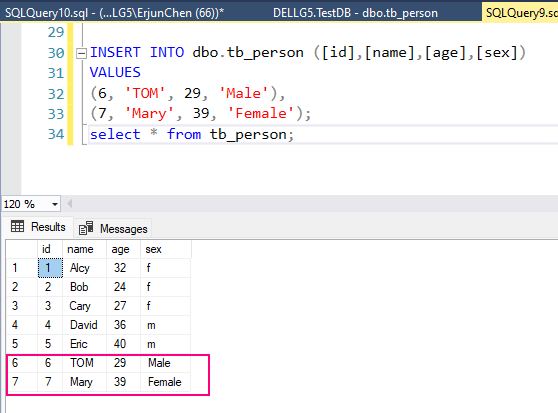
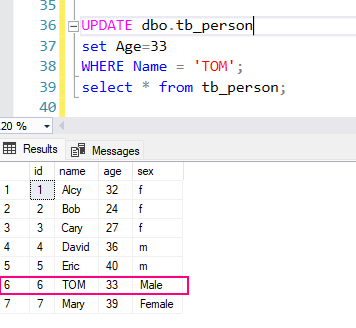
UPDATE dbo.tb_person
set Age=33
WHERE Name = 'TOM';
select * from tb_person;
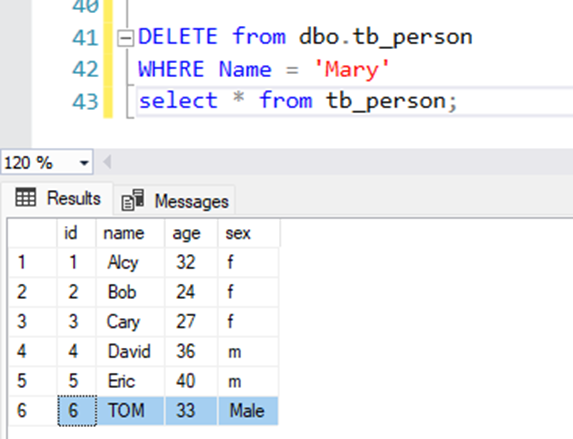
3, Delete a row:
DELETE from dbo.tb_person
WHERE Name = 'Mary'
select * from tb_person;
Step 5: Query the CDC Change Table
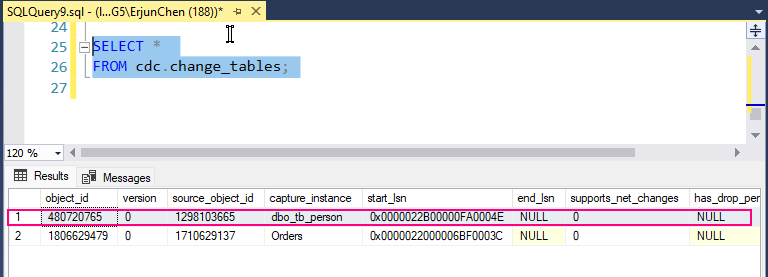
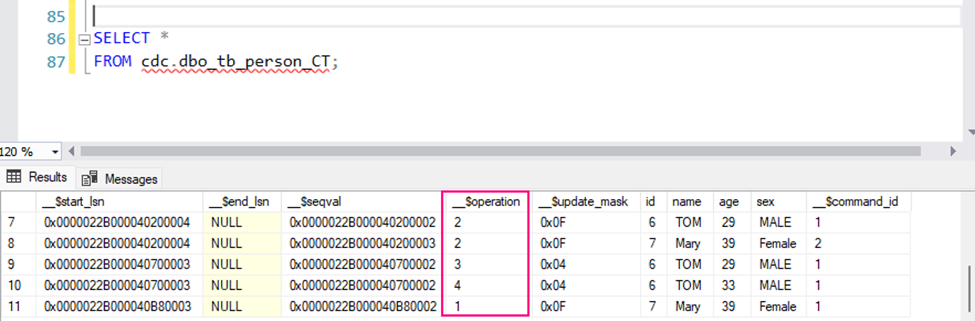
Once CDC is enabled, SQL Server will start capturing insert, update, and delete operations on the tracked tables.
The CDC system creates specific change tables. The name of the change table is derived from the source table and schema. For example, for tb_Person in the dbo schema, the change table might be named something like cdc.dbo_tb_person_CT.
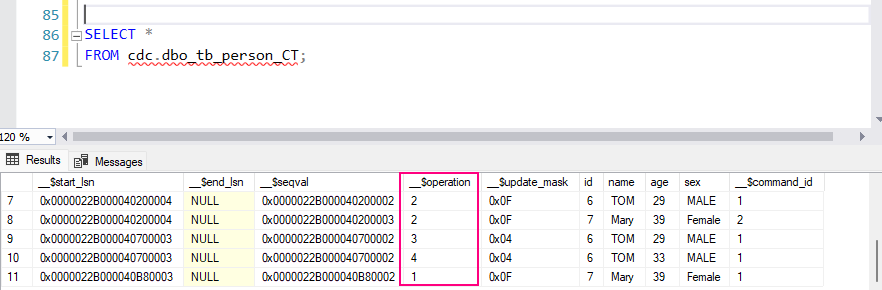
Querying the change table: To retrieve changes captured by CDC, you can query the change table directly:
SELECT *
FROM cdc.dbo_tb_person_CT;
This table contains:
__$operation: The type of operation:
1: DELETE
2: INSERT
3: UPDATE (before image)
4: UPDATE (after image)
__$start_lsn: The log sequence number (LSN) of the transaction.
Columns of the original table (e.g., OrderID, CustomerName, Product, etc.) showing the state of the data before and after the change.
Step 5: Manage CDC
As your tables grow, CDC will collect more data in its change tables. To manage this, SQL Server includes functions to clean up old change data.
1. Set up CDC clean-up jobs, Adjust the retention period (default is 3 days)
SQL Server automatically creates a cleanup job to remove old CDC data based on retention periods. You can modify the retention period by adjusting the @retention parameter.
EXEC sys.sp_cdc_change_job
@job_type = N'cleanup',
@retention = 4320; -- Retention period in minutes (default 3 days)
2. Disable CDC on a table:
If you no longer want to track changes on a table, disable CDC:
If you want to disable CDC for the entire database, run:
USE YourDatabaseName; GO EXEC sys.sp_cdc_disable_db; GO
Step 6: Monitor CDC
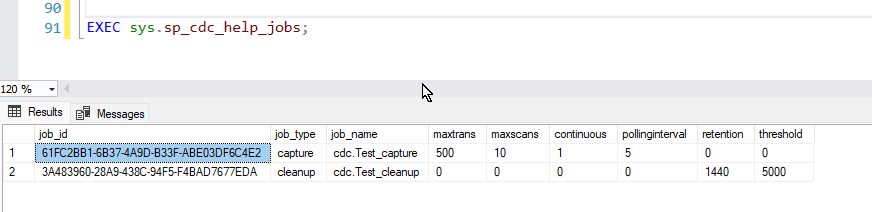
You can monitor CDC activity and performance using the following methods
1. Check the current status of CDC jobs:
EXEC sys.sp_cdc_help_jobs;
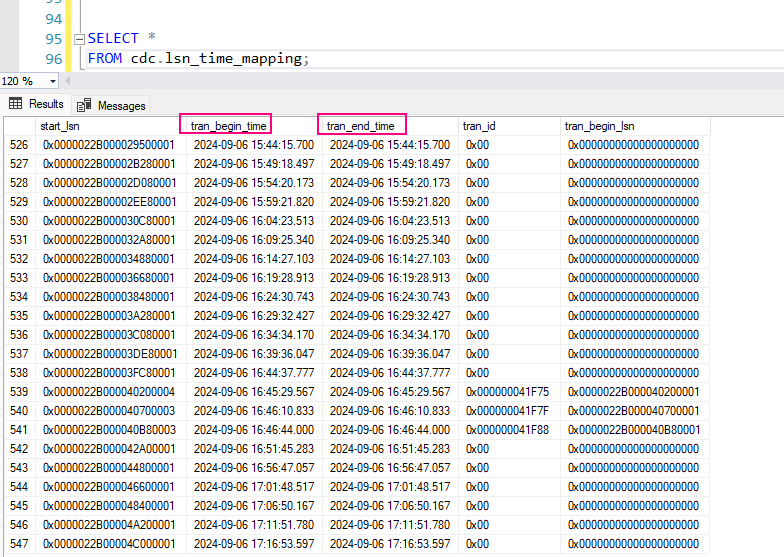
2. Monitor captured transactions:
You can query the cdc.lsn_time_mapping table to monitor captured LSNs and their associated times:
SELECT *
FROM cdc.lsn_time_mapping;
Step 7: Using CDC Data in ETL Processes
Once CDC is capturing data, you can integrate it into ETL processes or use it for auditing or tracking changes over time. Use change tables
cdc. [YourSchema]_[YourTableName]_CT
to identify rows that have been modified, deleted, or inserted, and process the changes accordingly. e.g.
SELECT *
FROM cdc.dbo_tb_person_CT;
System function cdc.fn_cdc_get_all_changes_<Capture_Instance>
cdc.fn_cdc_get_all_changes_<capture_instance>
The function fn_cdc_get_all_changes_<capture_instance> is a system function that allows you to retrieve all the changes (inserts, updates, and deletes) made to a CDC-enabled table over a specified range of log sequence numbers (LSNs).
For your table tb_person, if CDC has been enabled, the function to use would be:
@from_lsn: The starting log sequence number (LSN). This represents the point in time (or transaction) from which you want to begin retrieving changes.
@to_lsn: The ending LSN. This represents the point up to which you want to retrieve changes.
N'all': This parameter indicates that you want to retrieve all changes (including inserts, updates, and deletes).
Retrieve LSN Values
You need to get the LSN values for the time range you want to query. You can use the following system function to get the from_lsn and to_lsn values:
Get the minimum LSN for the CDC-enabled table: sys.fn_cdc_get_min_lsn(‘dbo_tb_person’) e.g. SELECT sys.fn_cdc_get_min_lsn(‘dbo_tb_person’);
Get the maximum LSN (which represents the latest changes captured): sys.fn_cdc_get_max_lsn(); SELECT sys.fn_cdc_get_max_lsn();
Use the LSN Values in the Query
Now, you can use these LSNs to query the changes. Here’s an example:
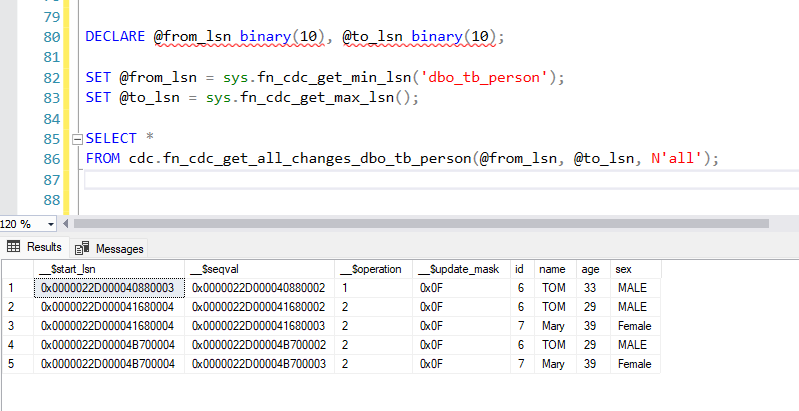
DECLARE @from_lsn binary(10), @to_lsn binary(10);
SET @from_lsn = sys.fn_cdc_get_min_lsn('dbo_tb_person');
SET @to_lsn = sys.fn_cdc_get_max_lsn();
SELECT *
FROM cdc.fn_cdc_get_all_changes_dbo_tb_person(@from_lsn, @to_lsn, N'all');
The result set will include:
__$operation: The type of change (1 = delete, 2 = insert, 3 = update before, 4 = update after).
__$start_lsn: The LSN value at which the change occurred.
__$seqval: Sequence value for sorting the changes within a transaction.
__$update_mask: Binary value indicating which columns were updated.
All the columns from the original tb_person table.
Querying Only Inserts, Updates, or Deletes
If you want to query only a specific type of change, such as inserts or updates, you can modify the function’s third parameter:
Inserts only:
SELECT *
FROM cdc.fn_cdc_get_all_changes_dbo_tb_person(@from_lsn, @to_lsn, N'insert');
Updates only:
SELECT *
FROM cdc.fn_cdc_get_all_changes_dbo_tb_person(@from_lsn, @to_lsn, N'update');
Deletes only:
SELECT *
FROM cdc.fn_cdc_get_all_changes_dbo_tb_person(@from_lsn, @to_lsn, N'delete');
Map datetime to log sequence number (lsn)
sys.fn_cdc_map_time_to_lsn
The sys.fn_cdc_map_time_to_lsn function in SQL Server is used to map a datetime value to a corresponding log sequence number (LSN) in Change Data Capture (CDC). Since CDC captures changes using LSNs, this function is helpful to find the LSN that corresponds to a specific point in time, making it easier to query CDC data based on a time range.
lsn_time_mapping: Specifies how you want to map the datetime_value to an LSN. It can take one of the following values:
smallest greater than or equal: Returns the smallest LSN that is greater than or equal to the specified datetime_value.
largest less than or equal: Returns the largest LSN that is less than or equal to the specified datetime_value.
datetime_value: The datetime value you want to map to an LSN.
Using sys.fn_cdc_map_time_to_lsn() in a CDC Query
Mapping a Date/Time to an LSN
-- Mapping a Date/Time to an LSN
DECLARE @from_lsn binary(10);
SET @from_lsn = sys.fn_cdc_map_time_to_lsn('smallest greater than or equal', '2024-09-06 12:00:00');
This will map the datetime'2024-09-06 12:00:00' to the corresponding LSN.
Finding the Largest LSN Before a Given Time
-- Finding the Largest LSN Before a Given Time
DECLARE @to_lsn binary(10);
SET @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', '2024-09-06 12:00:00');
This will return the largest LSN that corresponds to or is less than the datetime'2024-09-06 12:00:00'.
from_lsn: The starting LSN in the range of changes to be retrieved.
to_lsn: The ending LSN in the range of changes to be retrieved.
row_filter_option: Defines which changes to return:
'all': Returns both the before and after images of the changes for update operations.
'all update old': Returns the before image of the changes for update operations.
'all update new': Returns the after image of the changes for update operations.
Let’s say you want to find all the changes made to the tb_person table between '2024-09-05 08:00:00' and '2024-09-06 18:00:00'. You can map these times to LSNs and then query the CDC changes.
-- Querying Changes Between Two Time Points
DECLARE @from_lsn binary(10), @to_lsn binary(10);
-- Map the datetime range to LSNs
SET @from_lsn = sys.fn_cdc_map_time_to_lsn('smallest greater than or equal', '2024-09-05 08:00:00');
SET @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', '2024-09-06 18:00:00');
-- Query the CDC changes for the table tb_person within the LSN range
SELECT *
FROM cdc.fn_cdc_get_all_changes_dbo_tb_person(@from_lsn, @to_lsn, N'all');
Output:
This query will return the following data for changes between the specified LSN range:
__$operation: Indicates whether the row was inserted, updated, or deleted.
__$start_lsn: The LSN at which the change occurred.
Other columns: Any other columns that exist in the tb_person table.
Using sys.fn_cdc_map_lsn_to_time () convert an LSN value to a readable datetime
In SQL Server, Change Data Capture (CDC) tracks changes using Log Sequence Numbers (LSNs), but these LSNs are in a binary format and are not directly human-readable. However, you can map LSNs to timestamps (datetime values) using the system function sys.fn_cdc_map_lsn_to_time
Syntax
sys.fn_cdc_map_lsn_to_time (lsn_value)
Example: Mapping LSN to Datetime
Get the LSN range for the cdc.fn_cdc_get_all_changes function:
DECLARE @from_lsn binary(10), @to_lsn binary(10);
-- Get minimum and maximum LSN for the table
SET @from_lsn = sys.fn_cdc_get_min_lsn('dbo_tb_person');
SET @to_lsn = sys.fn_cdc_get_max_lsn();
Query the CDC changes and retrieve the LSN values:
-- Query CDC changes for the tb_person table SELECT $start_lsn, $operation, PersonID, FirstName, LastName FROM cdc.fn_cdc_get_all_changes_dbo_tb_person(@from_lsn, @to_lsn, 'all');
Convert the LSN to a datetime using sys.fn_cdc_map_lsn_to_time
-- Convert the LSN to datetime
SELECT $start_lsn, sys.fn_cdc_map_lsn_to_time($start_lsn) AS ChangeTime,
__$operation,
PersonID,
FirstName,
LastName
FROM cdc.fn_cdc_get_all_changes_dbo_tb_person(@from_lsn, @to_lsn, 'all');
Output
$start_lsn ChangeTime __$operation PersonID FirstName LastName 0x000000240000005A 2024-09-06 10:15:34.123 2 1 John Doe 0x000000240000005B 2024-09-06 10:18:45.321 4 1 John Smith 0x000000240000005C 2024-09-06 10:25:00.789 1 2 Jane Doe
Explanation
sys.fn_cdc_map_lsn_to_time(__$start_lsn) converts the LSN from the CDC changes to a human-readable datetime.
This is useful for analyzing the time at which changes were recorded.
Notes:
CDC vs Temporal Tables: CDC captures only DML changes (inserts, updates, deletes), while temporal tables capture a full history of changes.
Performance: Capturing changes can add some overhead to your system, so it’s important to monitor CDC’s impact on performance.
Summary
Step 1: Enable CDC at the database level.
Step 2: Enable CDC on the SalesOrder table.
Step 3: Verify CDC is enabled.
Step 4: Perform data changes (insert, update, delete).
Step 5: Query the CDC change table to see captured changes.
Step 6: Manage CDC retention and disable it when no longer needed.
Step 7: Using CDC Data in ETL Processes
This step-by-step example shows how CDC captures data changes, making it easier to track, audit, or integrate those changes into ETL pipelines.
Please do not hesitate to contact me if you have any questions at William . chen @ mainri.ca
Azure Key Vault safeguards encryption keys and secrets like certificates, connection strings, and passwords.
Key vaults define security boundaries for stored secrets. It allows you to securely store service or application credentials like passwords and access keys as secrets. All secrets in your key vault are encrypted with a software key. When you use Key Vault, you no longer need to store security information in your applications. Not having to store security information in applications eliminates the need to make this information part of the code.
What is a secret in Key Vault?
In Key Vault, a secret is a name-value pair of strings. Secret names must be 1-127 characters long, contain only alphanumeric characters and dashes, and must be unique within a vault. A secret value can be any UTF-8 string up to 25 KB in size.
Vault authentication and permissions
Developers usually only need Get and List permissions to a development-environment vault. Some engineers need full permissions to change and add secrets, when necessary.
For apps, often only Get permissions are required. Some apps might require List depending on the way the app is implemented. The app in this module’s exercise requires the List permission because of the technique it uses to read secrets from the vault.
In this article, we will focus on 2 sections, set up secrets in Key Vault and application retrieves secrets that ware saved in Key vault.
Create a Key Vault and store secrets
Creating a vault requires no initial configuration. You can start adding secrets immediately. After you have a vault, you can add and manage secrets from any Azure administrative interface, including the Azure portal, the Azure CLI, and Azure PowerShell. When you set up your application to use the vault, you need to assign the correct permissions to it
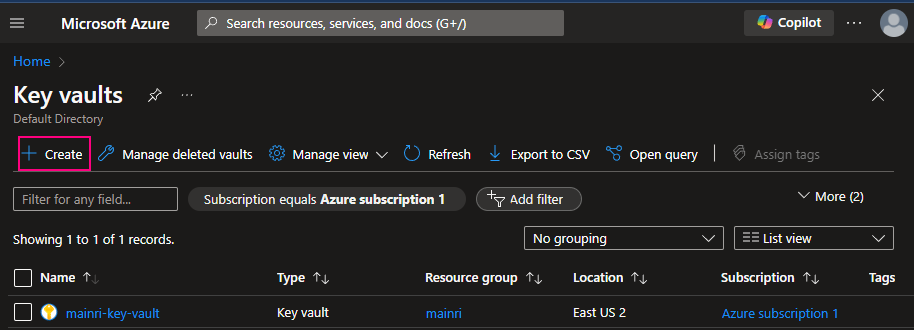
Create a Key Vault service
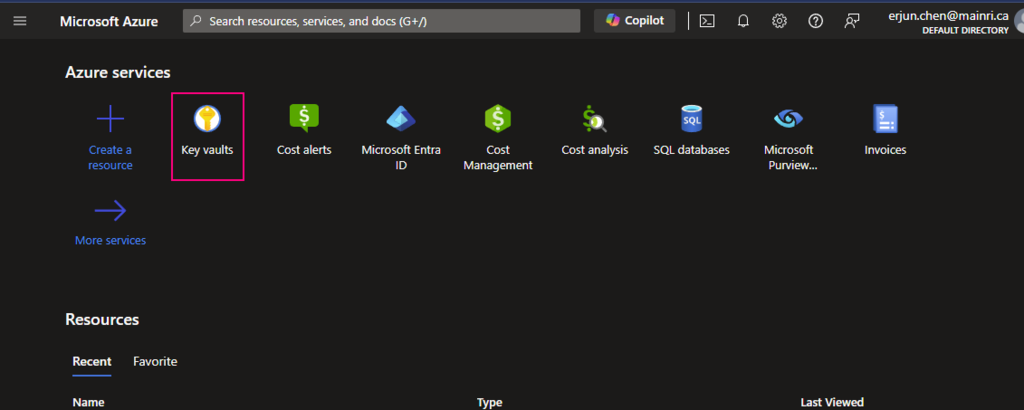
To create Azure Key Vault service, you can follow the steps.
From Azure Portal, search “key Vault”
click “key Vault”
Fill in all properties
Click review + create. That’s all. Quite simple, right?
Create secrets and save in Key Vault
There are two ways to create secret and save in Key vault.
Access control, Identity and Access management (IAM)
Access Policies
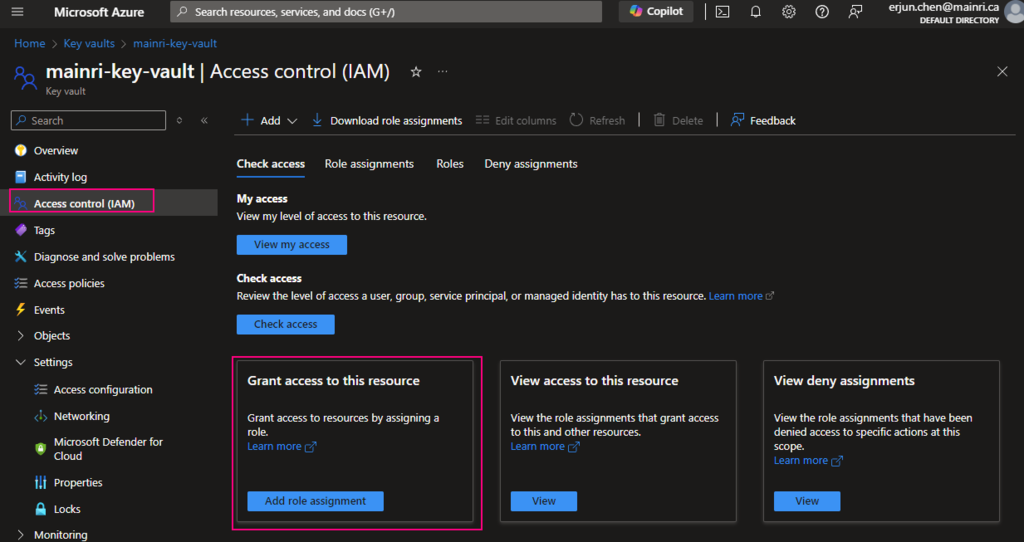
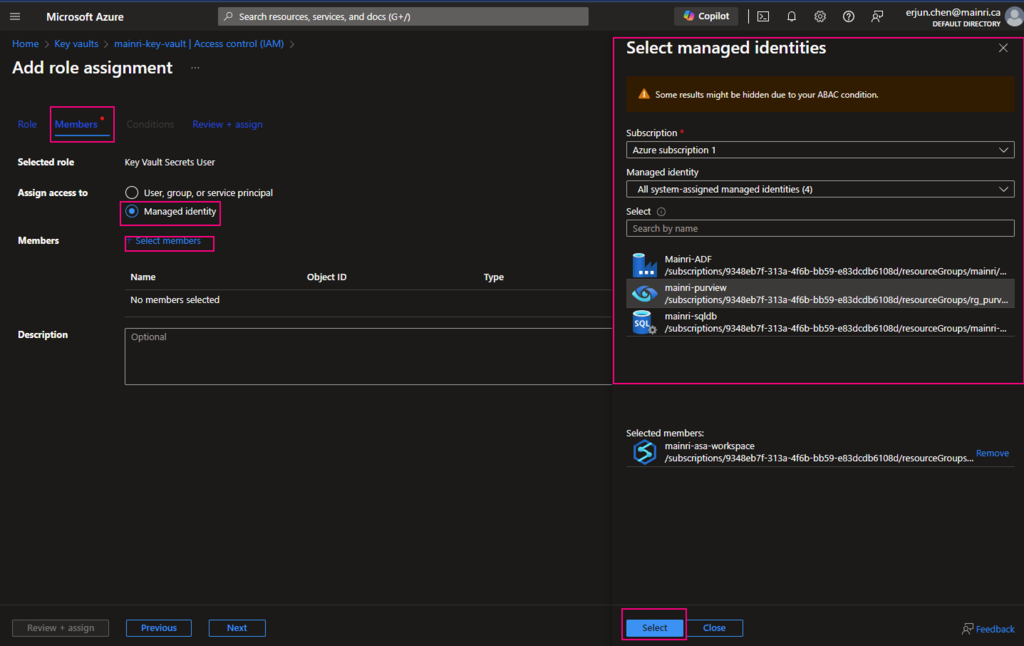
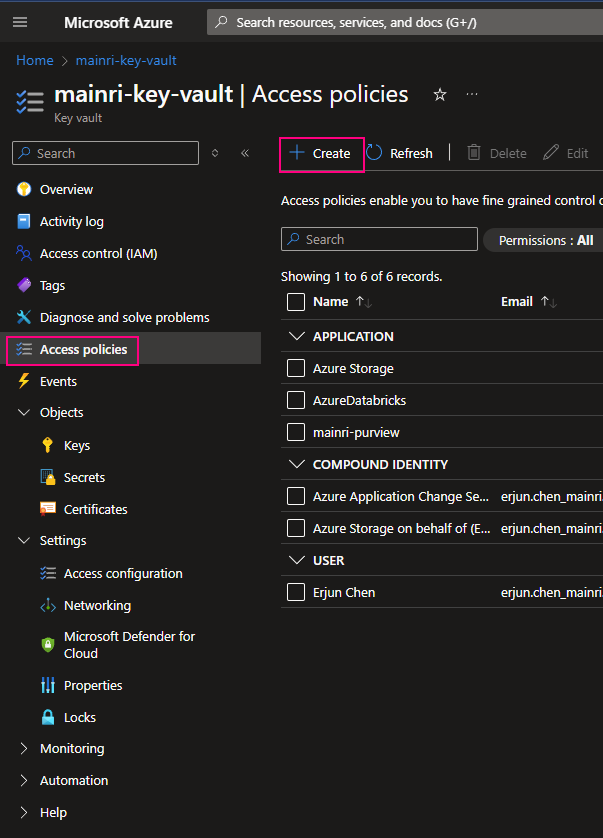
Using Access Control (IAM) create a secret
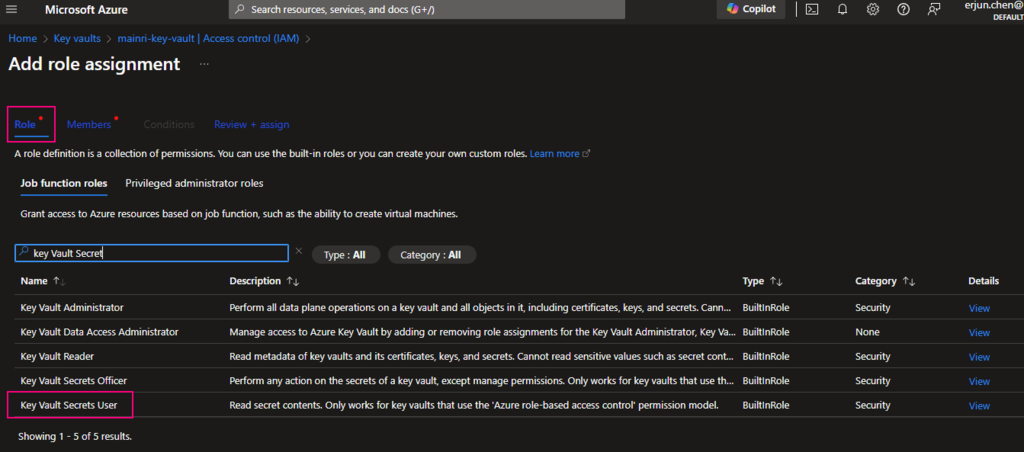
From Key Vault> Access Control (IAM) > Add role Assignment
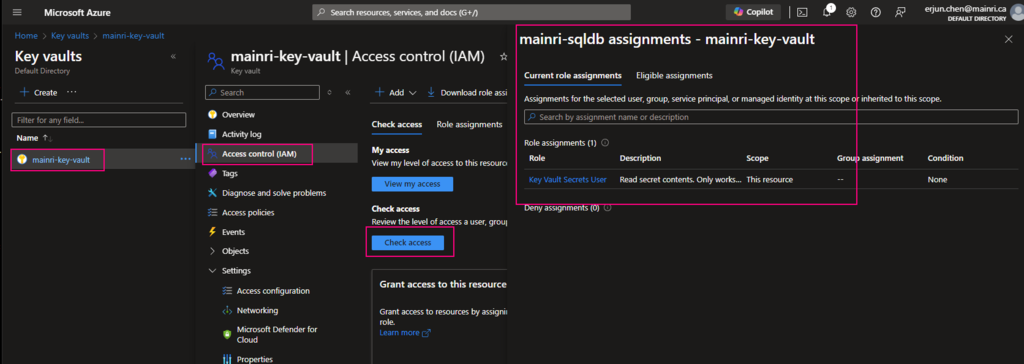
In most cases, if you create and save secrets in key-vault for your users to use, you only need add the “Key vault secrets user” role assignment.
click “next” select a member or group
Pay attention to here, if your organization has multiple instances of the same services, for example, different teams are independently using different ADF instants, make sure you correctly, accurately add the right service instant to access policies.
Once it’s down, check the access.
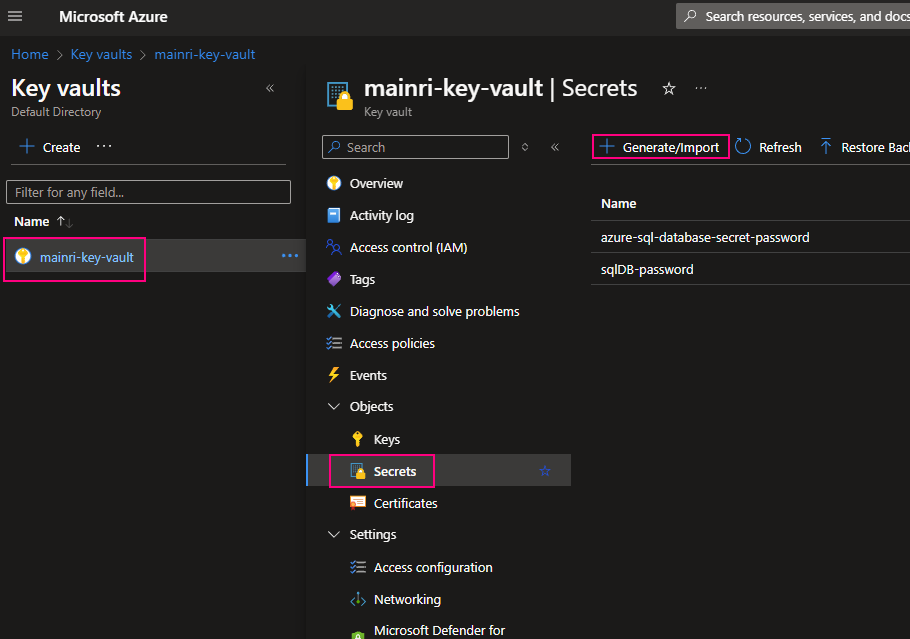
Create a Secret
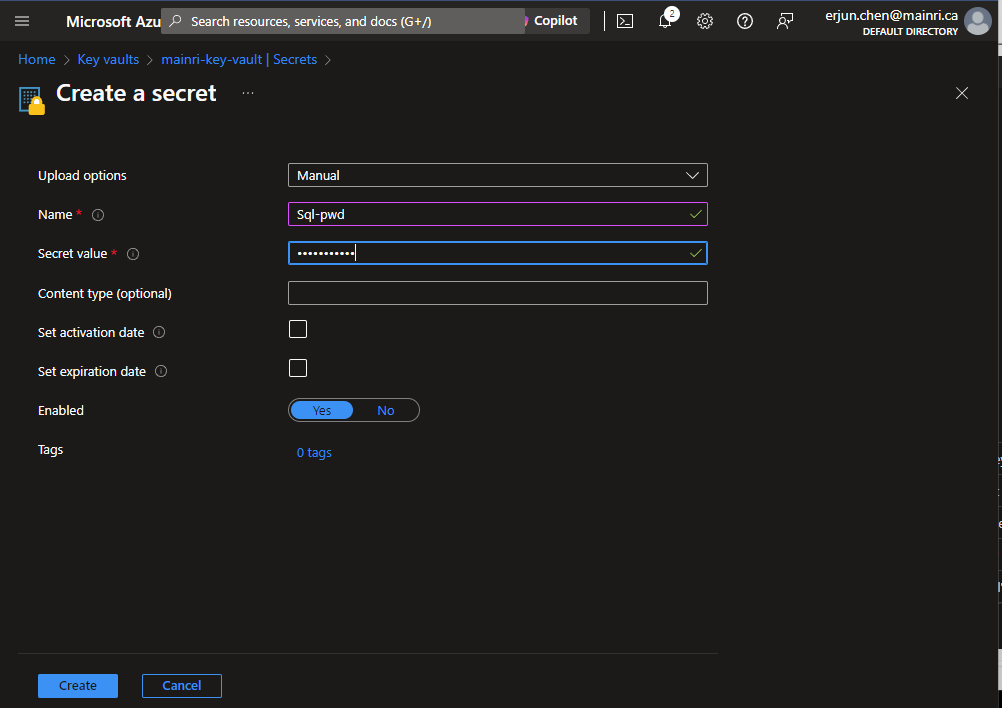
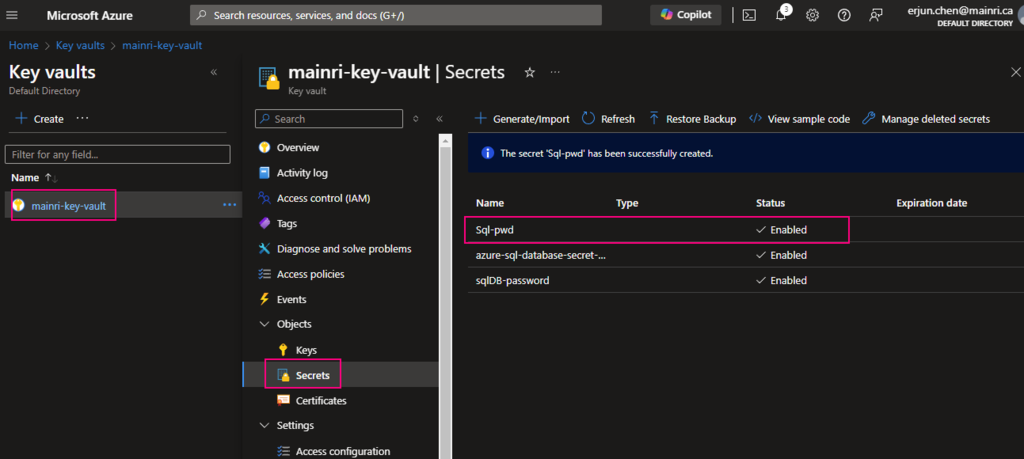
From “Key Vault” > “Object” > “Secrets” > “+ Generate/Import”
Fill in all properties, :Create”
Secrets key and value created That’s all.
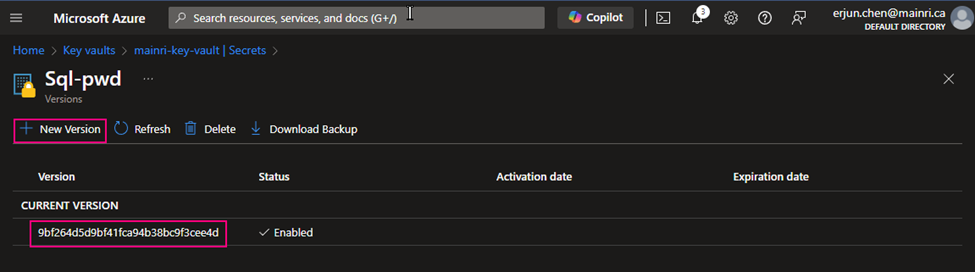
If you want to update the secret, simply click the key, follow the UI guide, you will not miss it.
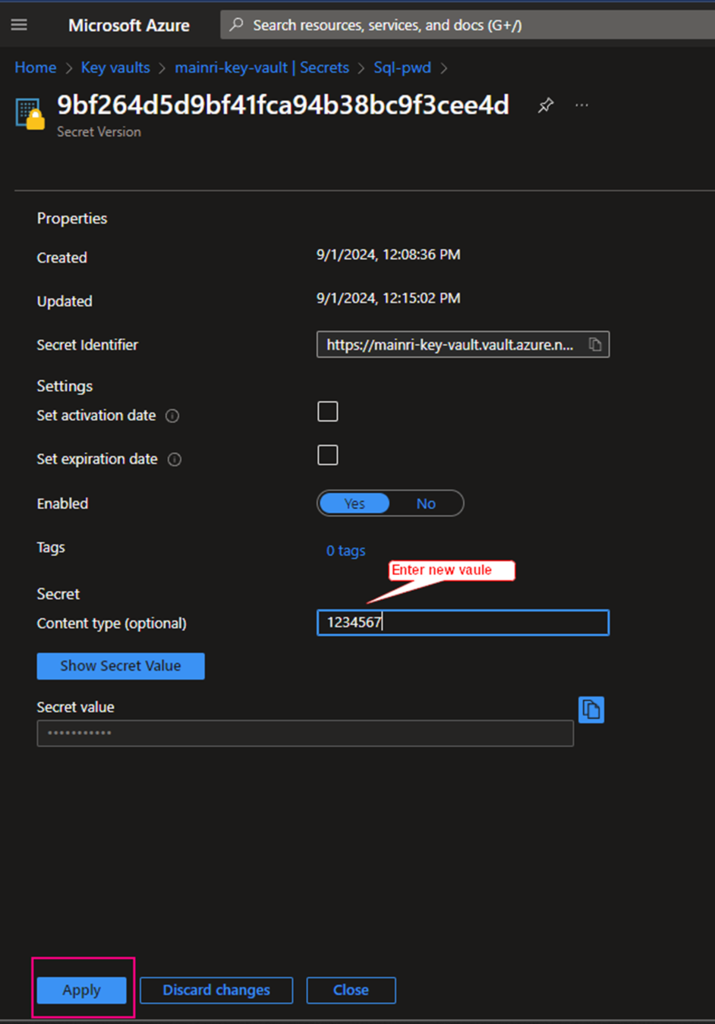
Click the “version” that you want to update. Update the content > apply it.
That’s all.
Using Access Policies create a secret
There is another way “Access Policies” to create a secret.
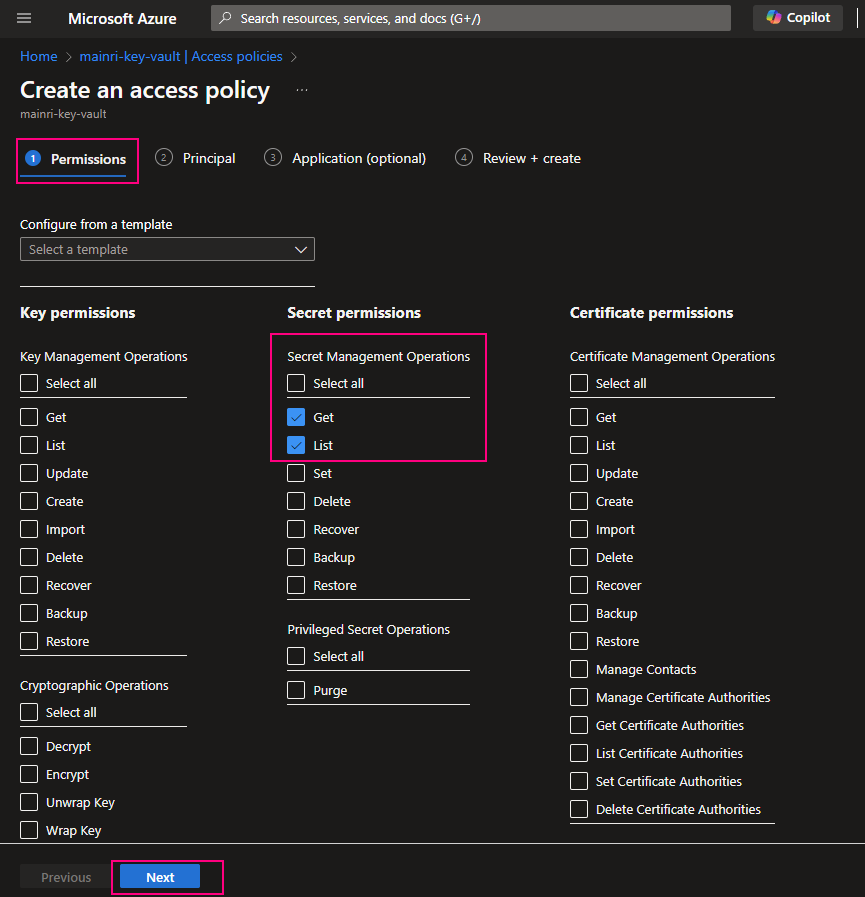
Select the permissions you want under Key permissions, Secret permissions, and Certificate permissions.
If you create a key secret for users to use in their application or other azure services, usually you give “get” and “list” in the “Secret permissions” enough. Otherwise, check Microsoft official documentation.
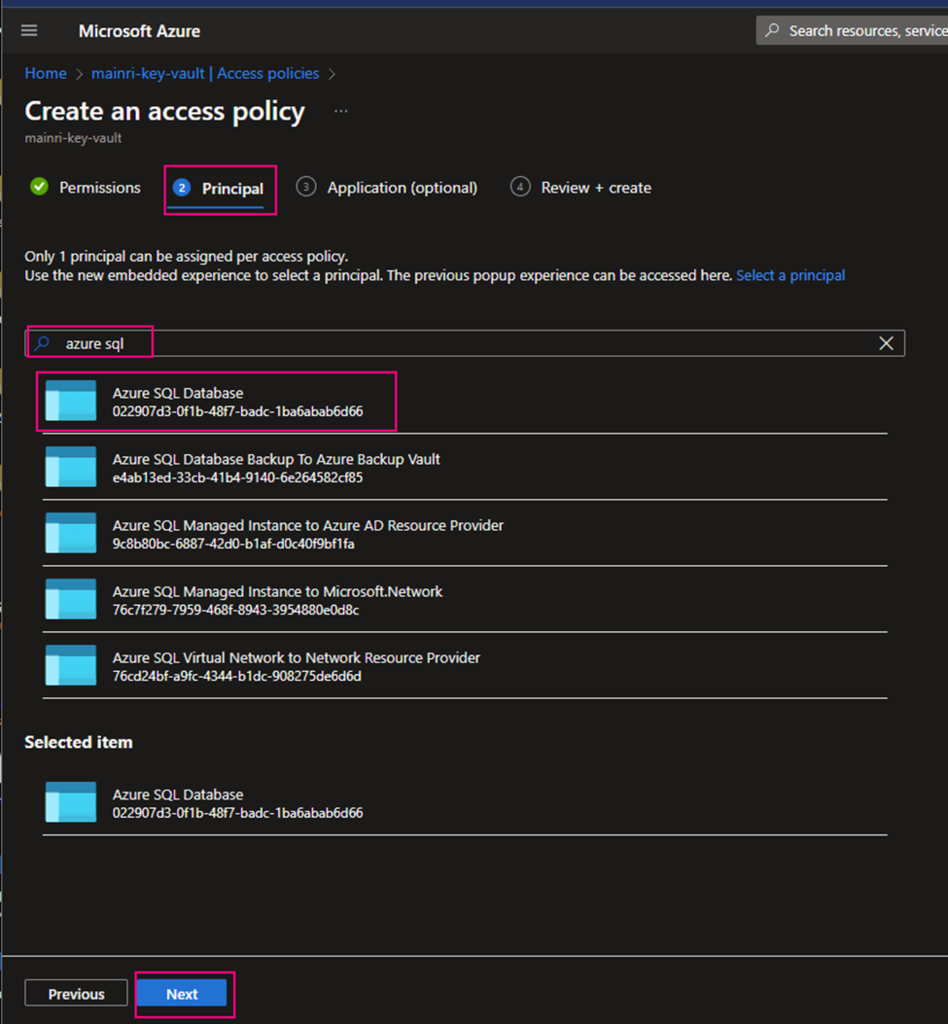
Under the Principal selection pane, enter the name of the user, app or service principal in the search field and select the appropriate result.
Using Azure SQL Database as an example
Caution: when you add principal, make sure you select right service instant. Especially you act as a infrastructure administer, your organization has multiple teams that they are independently using different service instants, e.g. different Synapse Workspace. select correct instant. I have been asked to help trouble shotting this scenario a few time. Azure admin says, he has added policies to key-vault, but the use cannot access there yet. that is a funny mistake made, he has added ADF to kay-vault policies, unfortunately, the ADF is NOT team A used, team B is using it. 🙂
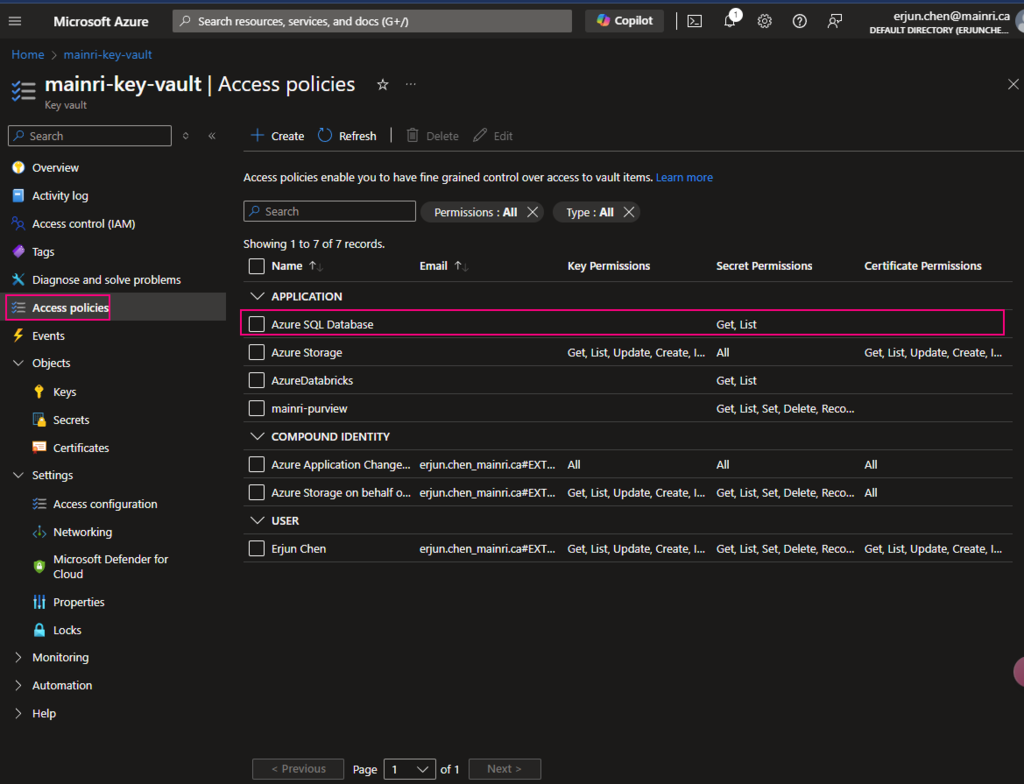
Back on the Access policies page, verify that your access policy is listed.
Create secret key and value
We have discussed it above. Need not verbose.
Done!
Using secrets that were saved in Key Vault
Using secrets usually have 2 major scenarios, directly use, or use REST API call to retrieve the saved secret value.
Let’s use Data Factory as an example to discuss.
Scenario 1, directly use it
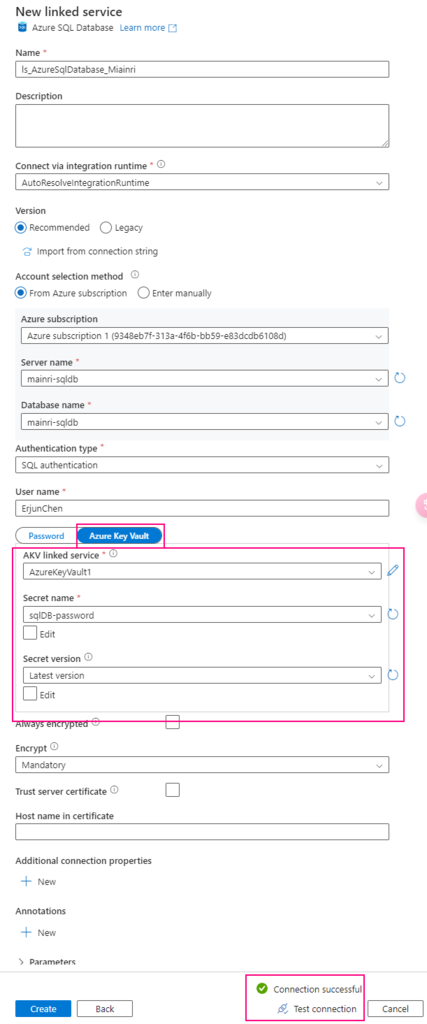
For example, when you create linked service to connect Azure Sql Database
You have to make sure that Key Vault’s access policies has this ADF access policies, get and list
one more example, System workspaces use key-vault.
Once again, make sure your Synapse Workspace has access policies, “Key Vault Secrets User“, “get” and “List”
Scenario 2, REST API call Key Vault to use secret
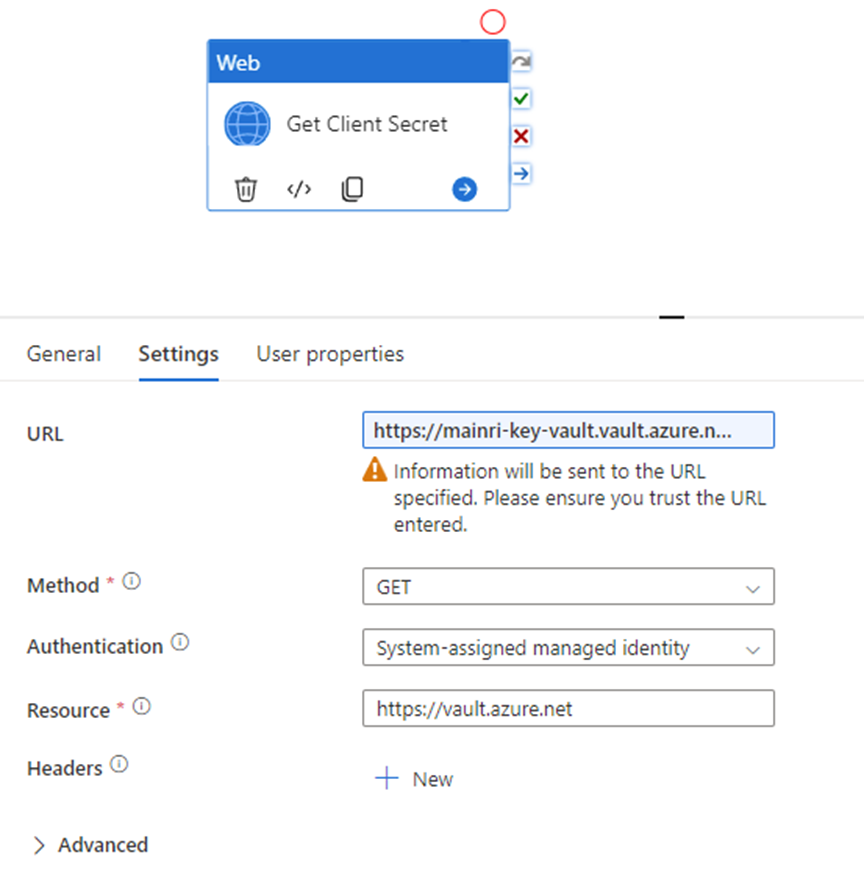
Many engineers want to call the key Vault to retrieve the secret value for a certain purpose, e.g. Synapse pipeline to get SharePoint Online list or files that resident in SharePoint Library, you need an application secret value to build the query string. Normally, the application’s secret value is saved in Key Vault. In this case, you have to make a http call to Key value.
Get a specified secret from a given key vault. The GET operation is applicable to any secret stored in Azure Key Vault. This operation requires the secrets/get permission.
GET {vaultBaseUrl}/secrets/{secret-name}/{secret-version}?api-version=7.4
An external data source in Synapse serverless SQL is typically used to reference data stored outside of the SQL pool, such as in Azure Data Lake Storage (ADLS) or Blob Storage. This allows you to query data directly from these external sources using T-SQL.
There are different ways to create external data source. Using Synapse Studio UI, coding etc. the easiest way is to leverage Synapse Studio UI. But we had better know how to use code to create it since in some cases we have to use this way.
Here’s how to create an external data source in Synapse serverless SQL
Using Synapse Studio UI to create External Data Source
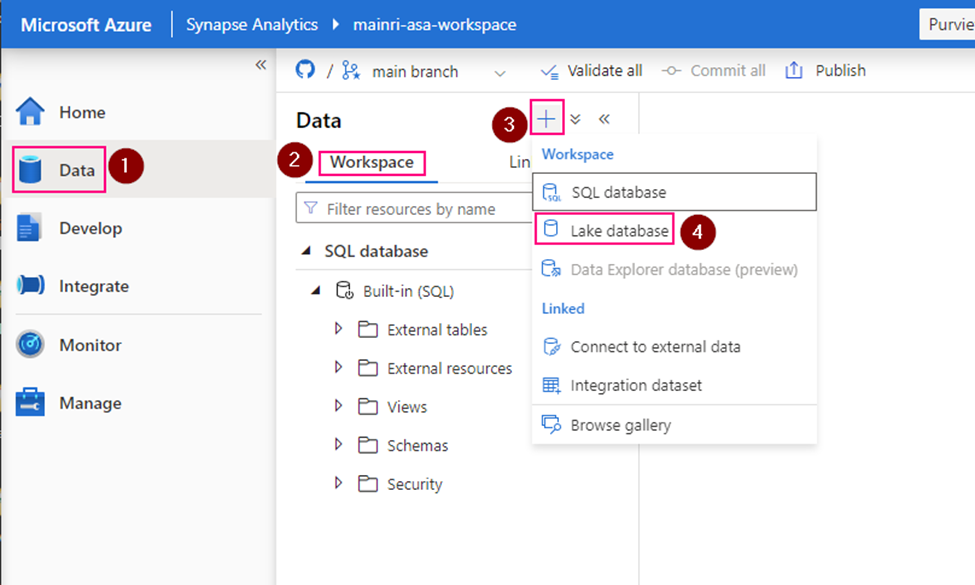
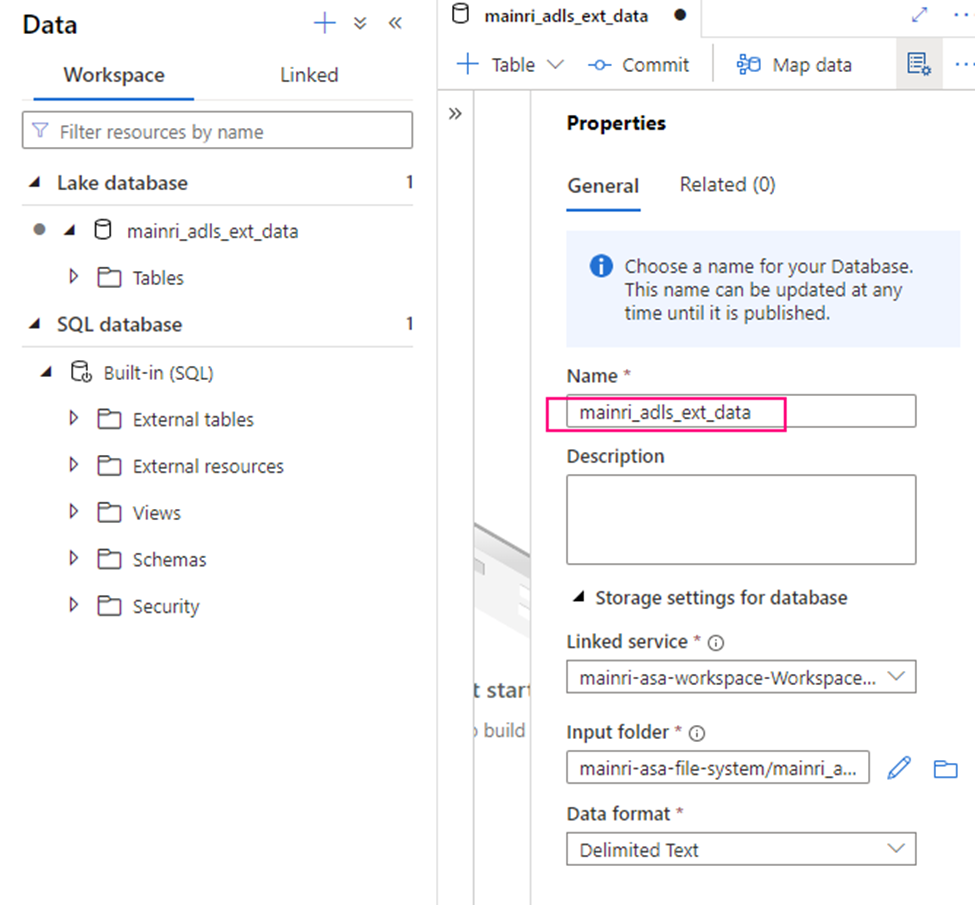
Create Lake Database
Open Synapse Studio
On the left side, select Data portal > workspace
Fill in the properties:
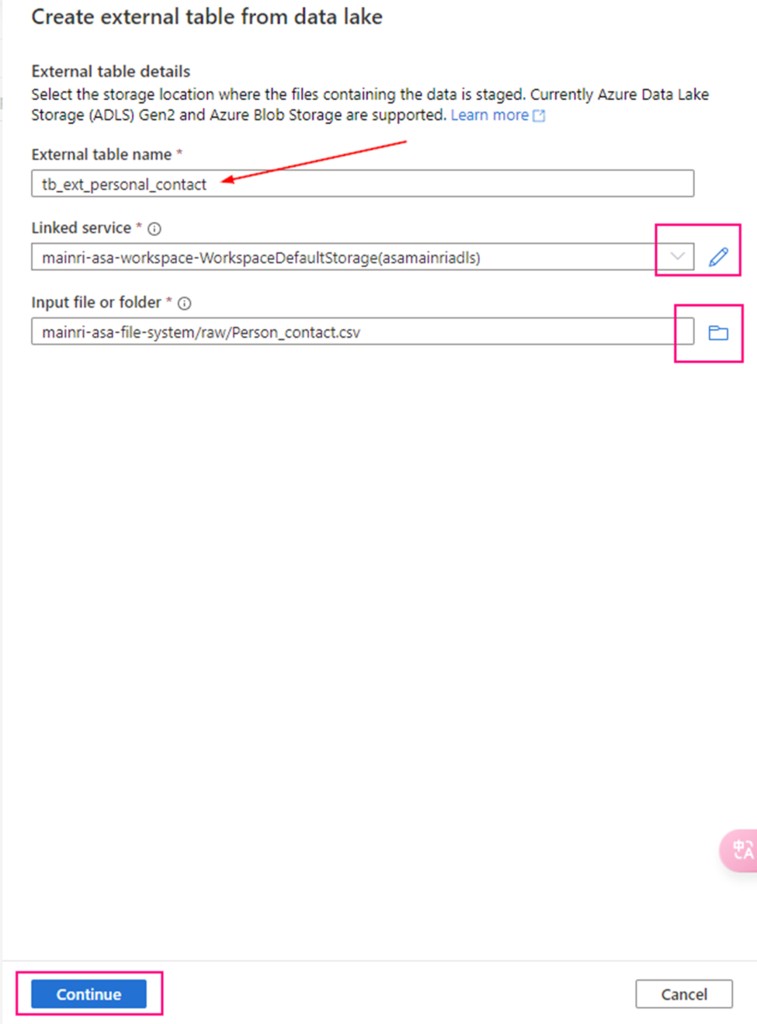
Create external table from data lake
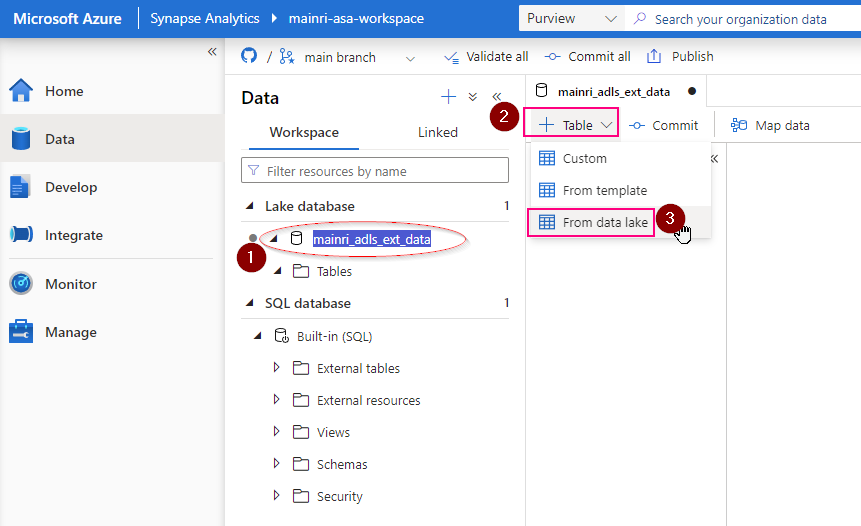
Double clicks the Lake Database you just created.
in the Lake Database tag, click “+ Table”
fill in the detail information:
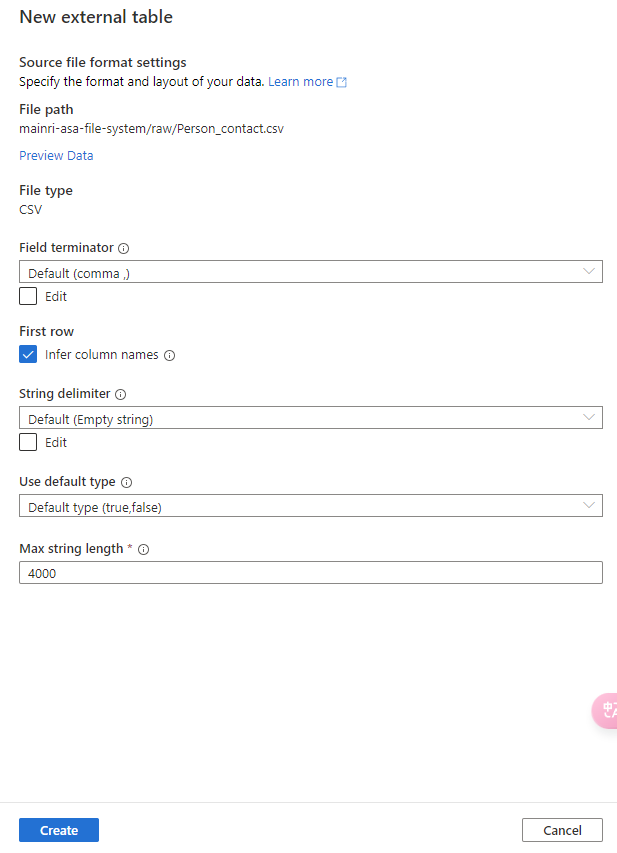
Continue to configure the table properyies
Adjust Table properties
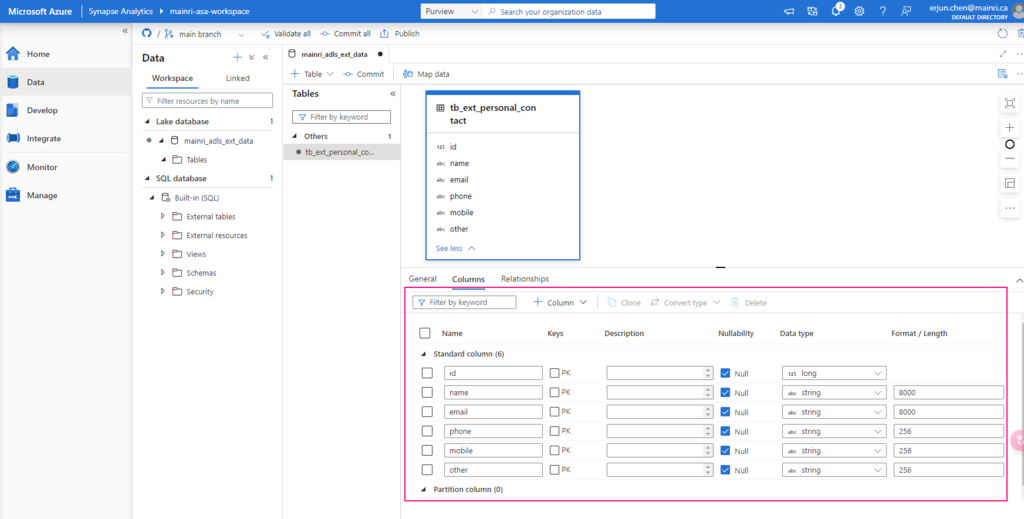
Adjust column other properties, or add even more columns, such as data type, description, Nullability, Primary Key, set up partition create relationship …… etc.
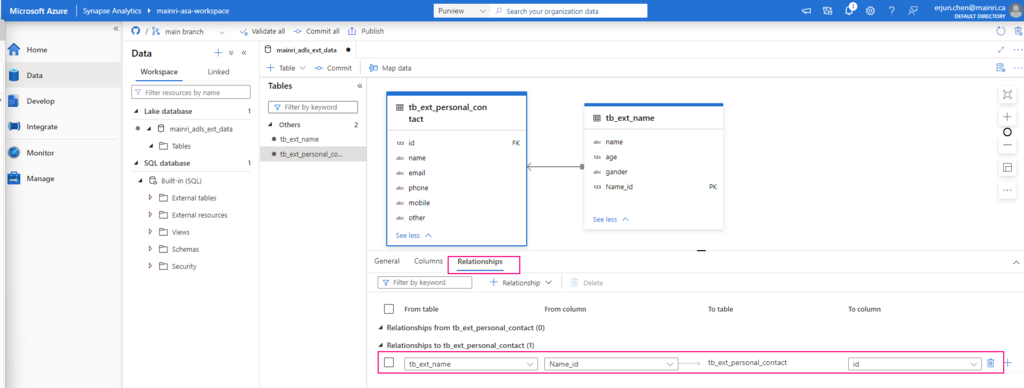
Repeat the above steps to create even more tables to meet your business logic need, or create relationship if need.
Script to create an External Data Source
Step 1:
1. Connect to Serverless SQL Pool:
Open Synapse Studio, go to the “Data” hub, and connect to your serverless SQL pool.
2. Create the External Data Source:
Use the following T-SQL script to create an external data source that points to your Azure Data Lake Storage (ADLS) or Blob Storage:
CREATE EXTERNAL DATA SOURCE MyExternalDataSource WITH ( LOCATION = ‘https://<your-storage-account-name>.dfs.core.windows.net/<your-filesystem-name>‘, CREDENTIAL = <your-credential-name> );
Replace <your-storage-account-name>, <your-filesystem-name>, and <your-credential-name> with the appropriate values:
LOCATION: The URL of your Azure Data Lake Storage (ADLS) or Blob Storage.
CREDENTIAL: The name of the database credential used to access the storage. (You may need to create this credential if it doesn’t already exist.)
Step 2:
If you don’t have a credential yet, create one as follows:
Replace <your-SAS-token> with your Azure Storage Shared Access Signature (SAS) token.
2. Create an External Table or Query the External Data
After setting up the external data source, you can create external tables or directly query data:
Create an External Table:
You can create an external table that maps to the data in your external storage:
CREATE EXTERNAL TABLE MyExternalTable ( Column1 INT, Column2 NVARCHAR(50), Column3 DATETIME ) WITH ( LOCATION = ‘/path/to/data.csv’, DATA_SOURCE = MyExternalDataSource, FILE_FORMAT = MyFileFormat — You need to define a file format );
Query the External Data
You can also directly query the data without creating an external table:
SELECT * FROM OPENROWSET( BULK ‘/path/to/data.csv’, DATA_SOURCE = ‘MyExternalDataSource’, FORMAT = ‘CSV’, FIELDTERMINATOR = ‘,’, ROWTERMINATOR = ‘\n’ ) AS MyData;
Create and Use a File Format (Optional)
If you are querying structured files (like CSV, Parquet), you might need to define a file format:
CREATE EXTERNAL FILE FORMAT MyFileFormat WITH ( FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS (FIELD_TERMINATOR = ‘,’, STRING_DELIMITER = ‘”‘) );
Summary
By following these steps, you should be able to connect to and query your external data sources using the serverless SQL pool in Synapse. Let me know if you need further assistance!
Create an external data source in Synapse serverless SQL to point to your external storage.
Create a database scoped credential if necessary to access your storage.
Create an external table or directly query data using OPENROWSET.
Define a file format if working with structured data like CSV or Parquet.
Please do not hesitate to contact me if you have any questions at William . chen @ mainri.ca
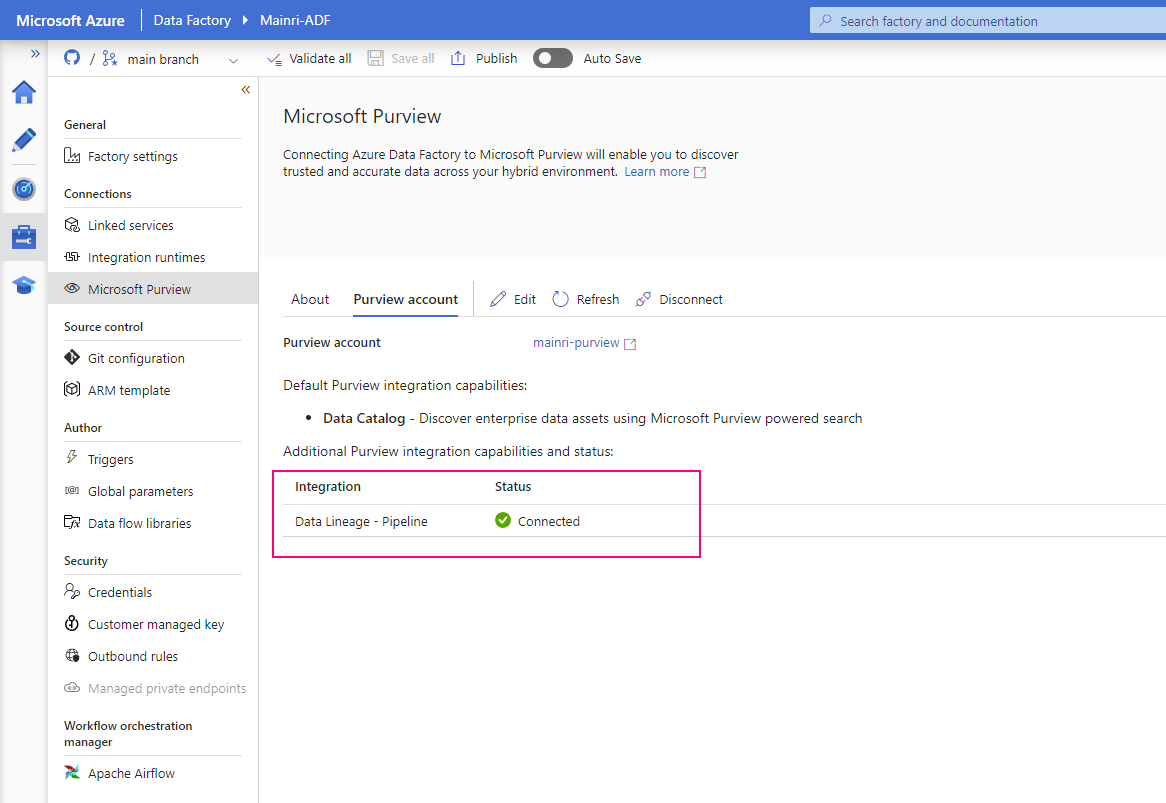
Microsoft Purview provides an overview of data lineage in the Data Catalog. It also details how data systems can integrate with the catalog to capture lineage of data.
Lineage is represented visually to show data moving from source to destination including how the data was transformed. Given the complexity of most enterprise data environments.
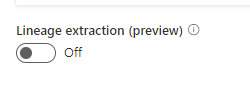
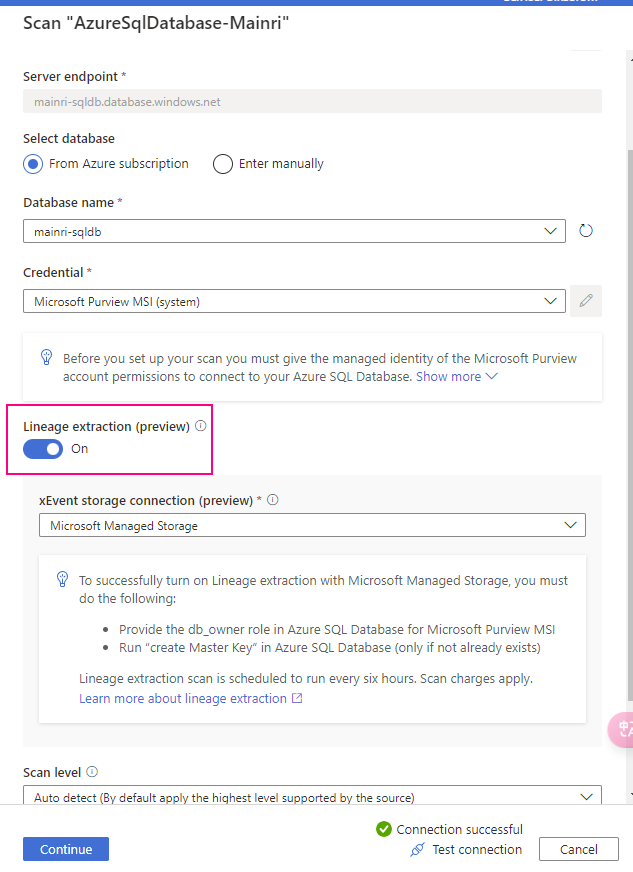
Microsoft Purview supports lineage for views and stored procedures from Azure SQL Database. While lineage for views is supported as part of scanning, you will need to turn on the Lineage extraction toggle to extract stored procedure lineage when you’re setting up a scan.
Lineage collection
Metadata collected in Microsoft Purview from enterprise data systems are stitched across to show an end to end data lineage. Data systems that collect lineage into Microsoft Purview are broadly categorized into following three types:
Data processing systems
Data storage systems
Data analytics and reporting systems
Each system supports a different level of lineage scope.
Data estate might include systems doing data extraction, transformation (ETL/ELT systems), analytics, and visualization systems. Each of the systems captures rich static and operational metadata that describes the state and quality of the data within the systems boundary. The goal of lineage in a data catalog is to extract the movement, transformation, and operational metadata from each data system at the lowest grain possible.
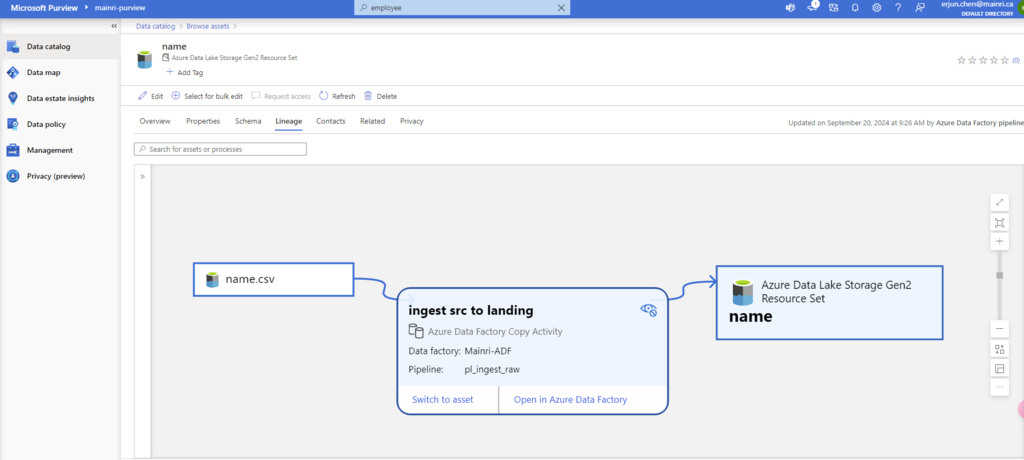
The following example is a typical use case of data moving across multiple systems, where the Data Catalog would connect to each of the systems for lineage.
Data Factory copies data from on-prem/raw zone to a landing zone in the cloud.
Data processing systems like Synapse, Databricks would process and transform data from landing zone to Curated zone using notebooks.
Further processing of data into analytical models for optimal query performance and aggregation.
Data visualization systems will consume the datasets and process through their meta model to create a BI Dashboard, ML experiments and so on.
Lineage for SQL DB views
Starting 6/30/24, SQL DB metadata scan will include lineage extraction for views. Only new scans will include the view lineage extraction. Lineage is extracted at all scan levels (L1/L2/L3). In case of an incremental scan, whatever metadata is scanned as part of incremental scan, the corresponding static lineage for tables/views will be extracted.
Prerequisites for setting up a scan with Stored Procedure lineage extraction
<Purview-Account> can access SQL Database and in db_owner group
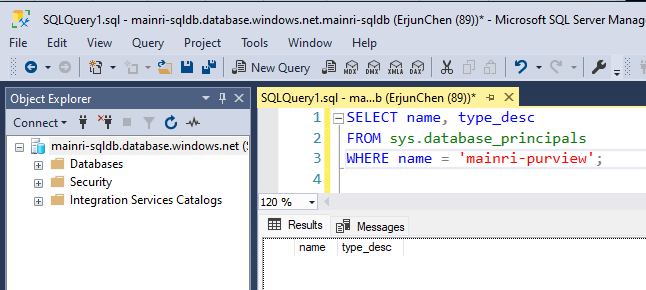
To check whether the Account Exists in the Database
SELECT name, type_desc
FROM sys.database_principals
WHERE name = 'YourUserName';
Replace ‘YourUserName’ with the actual username you’re checking for.
If the user exists, it will return the name and type (e.g., SQL_USER or WINDOWS_USER).
If it does not exist, create one.
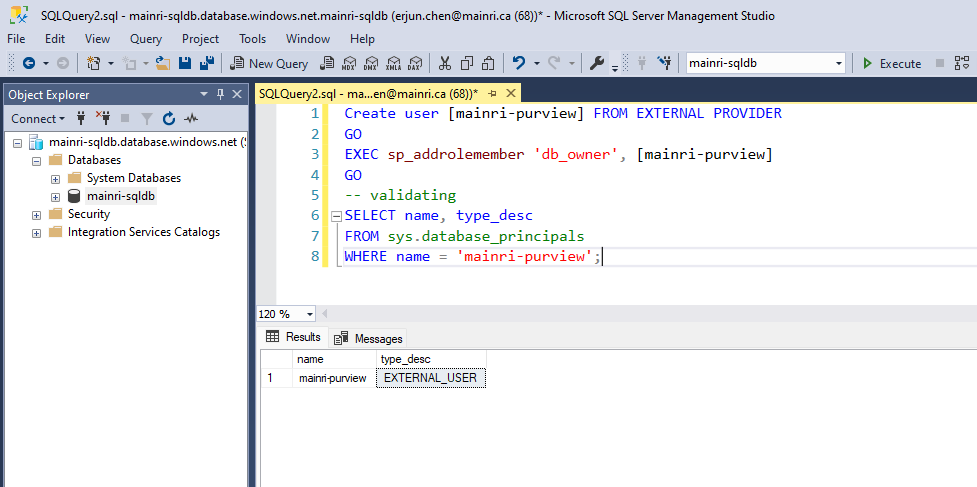
Sign in to Azure SQL Database with your Microsoft Entra account, create a <Purview-account> account and assign db_owner permissions to the Microsoft Purview managed identity.
Create user <purview-account> FROM EXTERNAL PROVIDER
GO
EXEC sp_addrolemember 'db_owner', <purview-account>
GO
replace <purview-account> with the actual purview account name.
Master Key
Check whether master exists or not.
To check if the Database Master Key (DMK) exists or not
SELECT * FROM sys.symmetric_keys
WHERE name = '##MS_DatabaseMasterKey##';Create master key
Go
if the query returns a result, it means the Database Master Key already exists.
If no rows are returned, it means the Database Master Key does not exist, and you may need to create one if required for encryption-related operations.
Create a master key
Create master key
Go
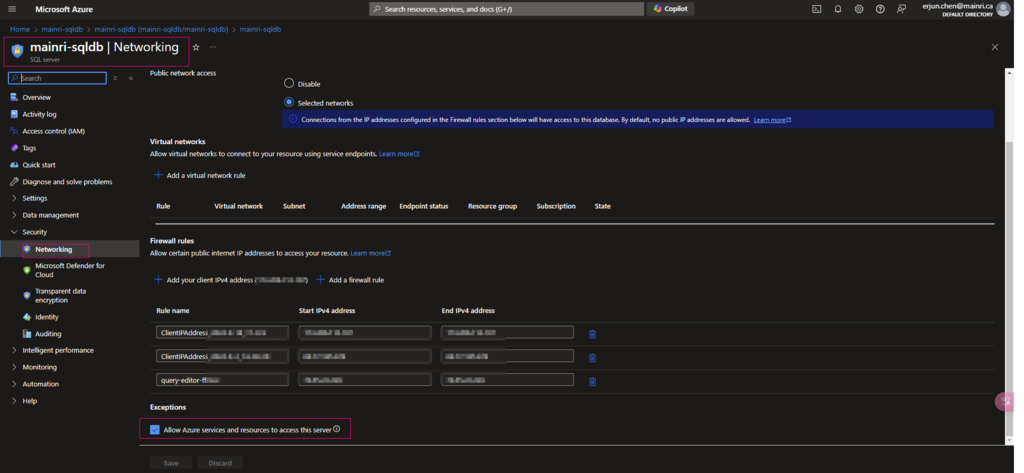
Allow Azure services and resources to access this server
Ensure that Allow Azure services and resources to access this server is enabled under networking/firewall for your Azure SQL resource.
To allow purview extract lineage, we need set to on
Extract Azure Data Factory/Synapse pipeline lineage
When we connect an Azure Data Factory to Microsoft Purview, whenever a supported Azure Data Factory activity is run, metadata about the activity’s source data, output data, and the activity will be automatically ingested into the Microsoft Purview Data Map.
Microsoft Purview captures runtime lineage from the following Azure Data Factory activities:
Copy Data
Data Flow
Execute SSIS Package
If a data source has already been scanned and exists in the data map, the ingestion process will add the lineage information from Azure Data Factory to that existing source. If the source or output doesn’t exist in the data map and is supported by Azure Data Factory lineage Microsoft Purview will automatically add their metadata from Azure Data Factory into the data map under the root collection.
This can be an excellent way to monitor your data estate as users move and transform information using Azure Data Factory.
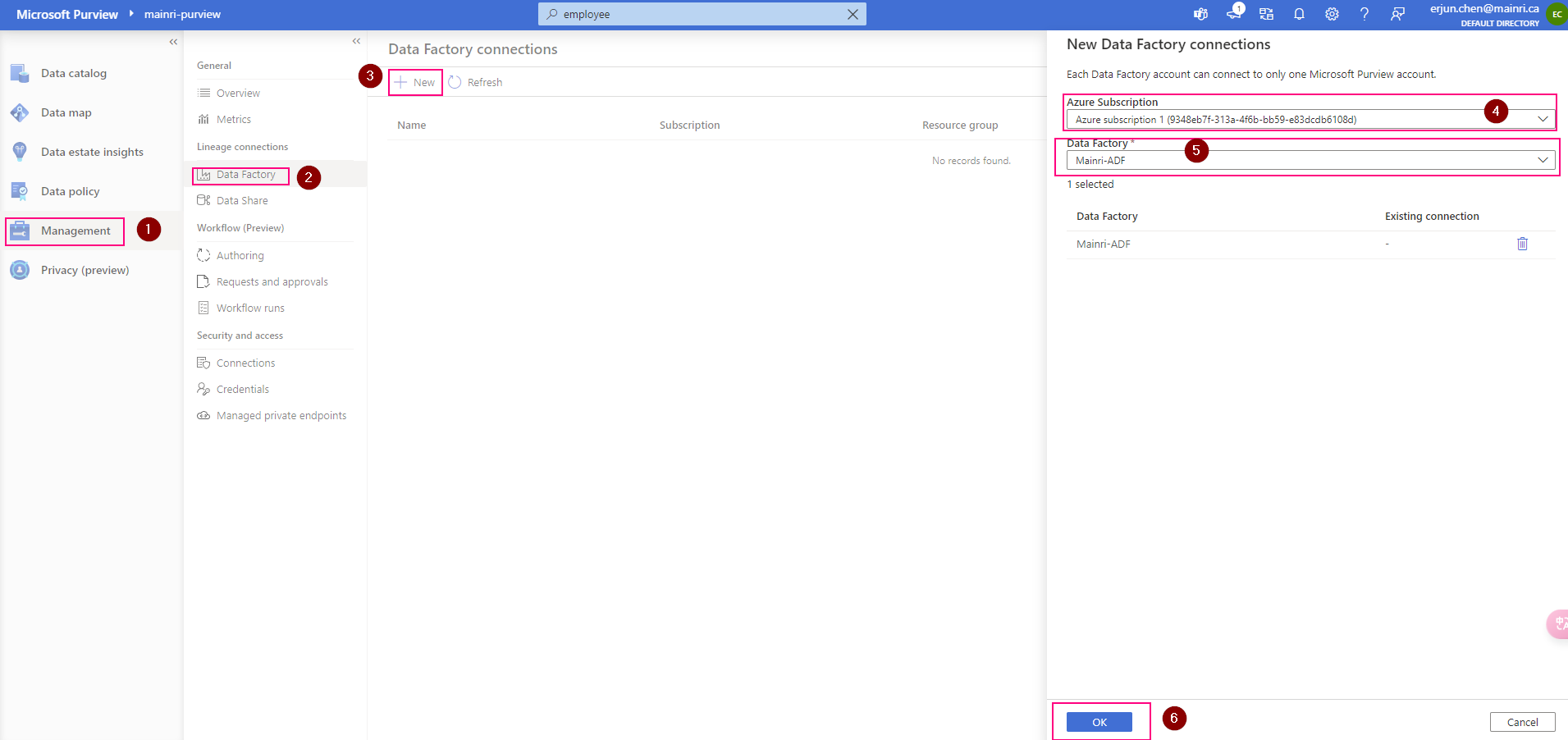
Connect to Microsoft Purview account in Data Factory
Set up authentication
Data factory’s managed identity is used to authenticate lineage push operations from data factory to Microsoft Purview. Grant the data factory’s managed identity Data Curator role on Microsoft Purview root collection.
Purview > Management > Lineage connections > Data Factory > new
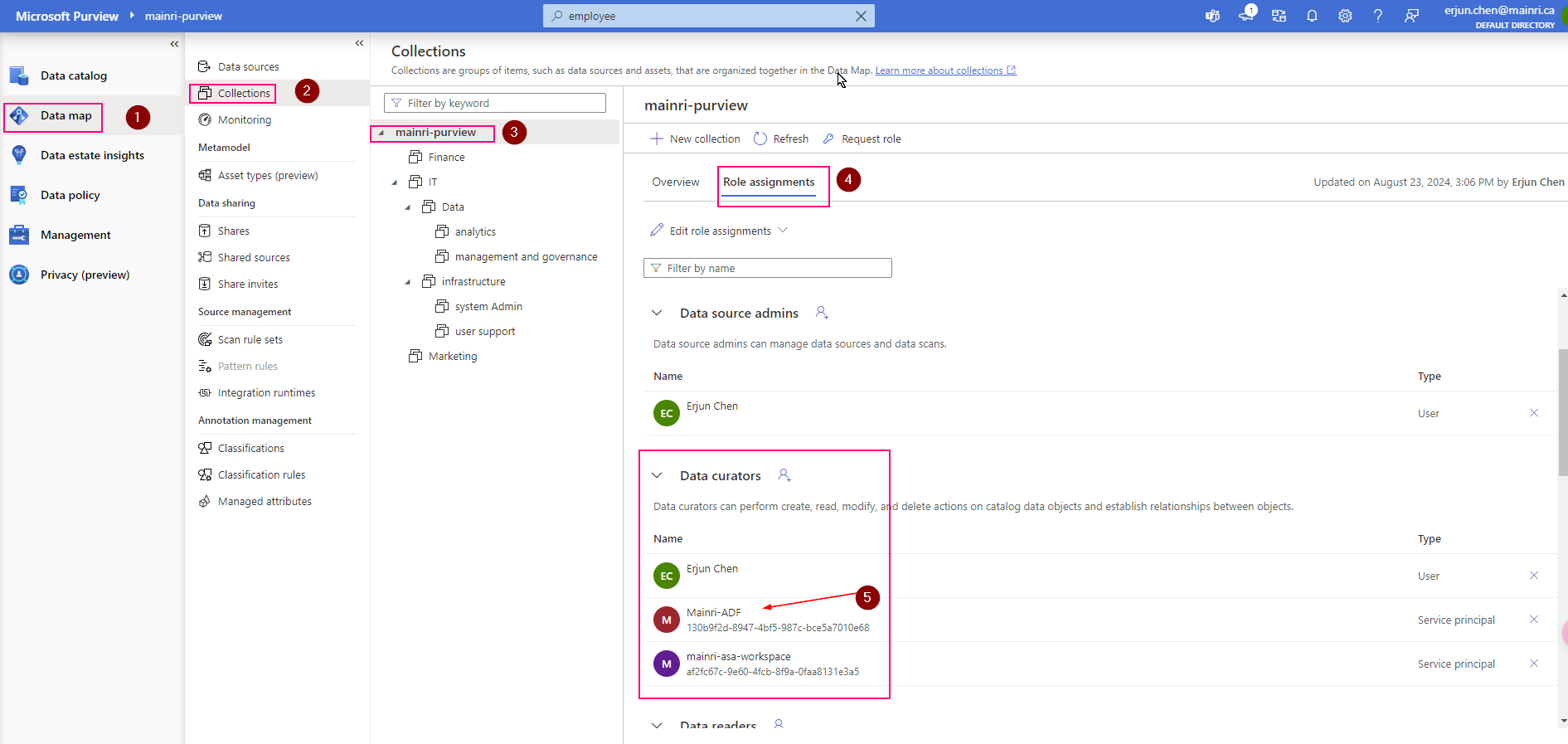
Validation: Purview > Data map > Collection > Root collection > Role assignments >
Check, the ADF is under “data Curators” section. That’s OK
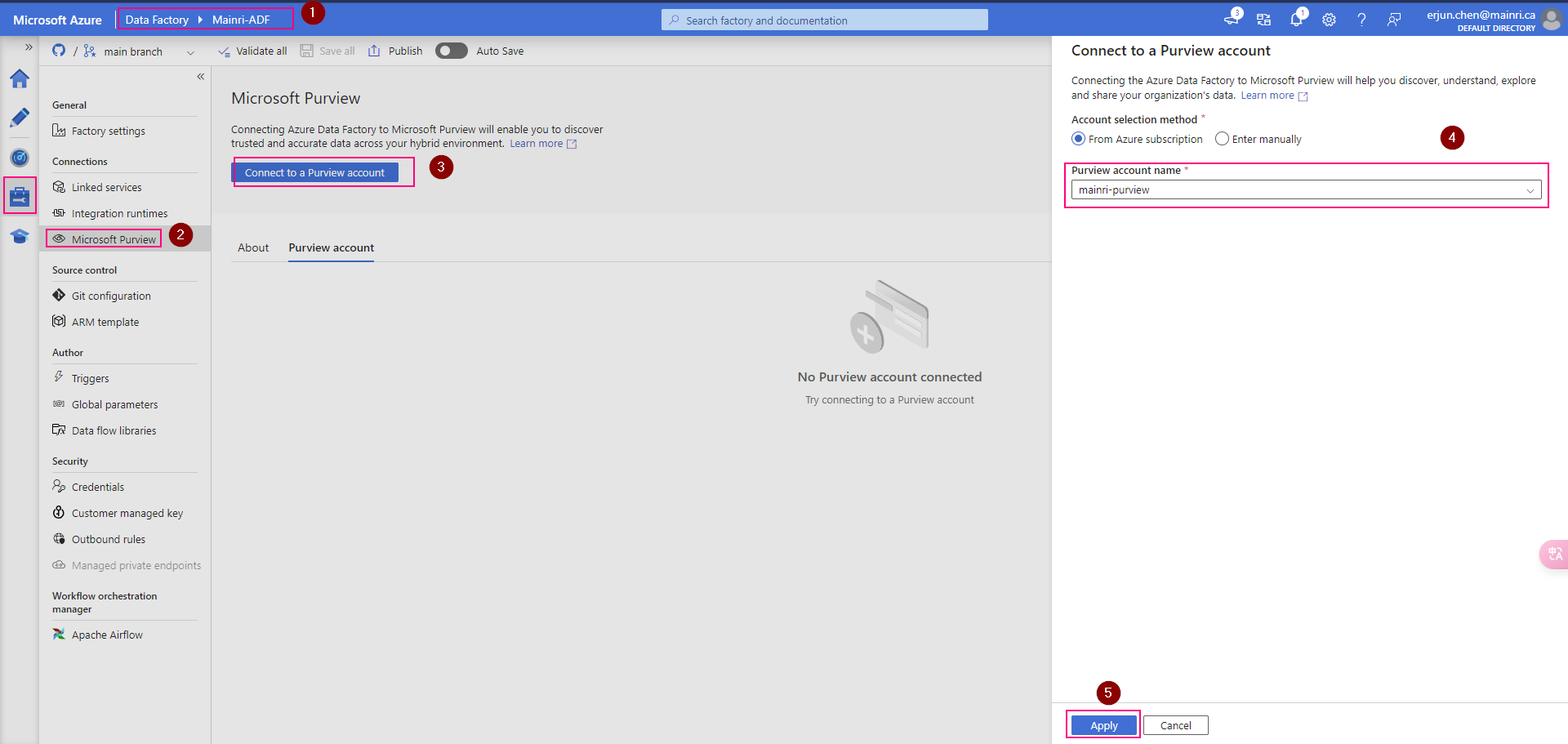
ADF connect to purview
In the ADF studio: Manage -> Microsoft Purview, and select Connect to a Microsoft Purview account
We will see this
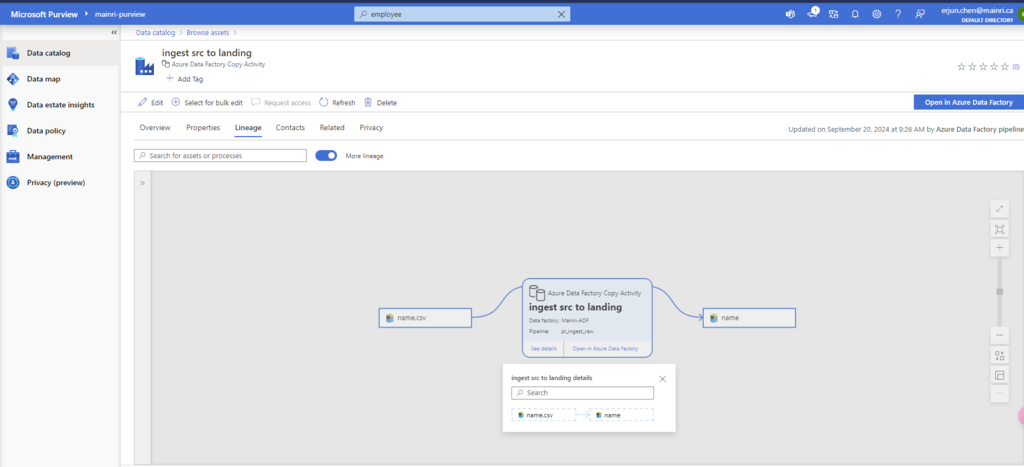
Once pipeline successfully runs, activity will be caught, extracted lineage look this.
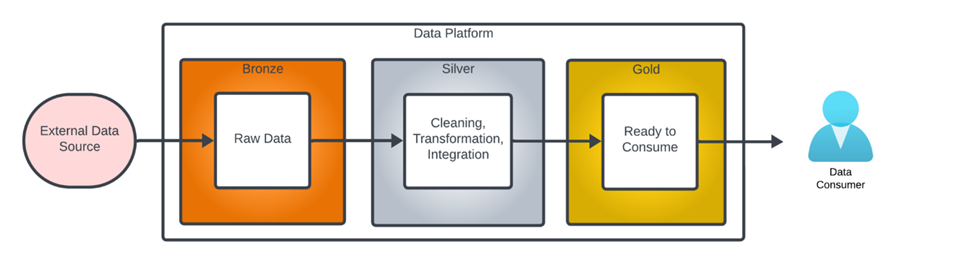
The term “Medallion Data Architecture” was first called by databricks. It is a data design pattern used to logically organize data in a lakehouse. It describes data at different stages of processing as being “bronze,” “silver” or “gold” level data. with the goal of incrementally and progressively improving the structure and quality of data as it flows through each layer of the architecture.
Bronze ⇒ Silver ⇒ Gold layer tables
Bronze data refers to data in its unprocessed state, exactly as loaded from the data source.
Silver data refers to data at various stages of intermediate processing.
Gold level data is fully cleaned and prepared ready for use by a data consumer.
Bronze zone/layer
Data in bronze is raw, unprocessed data. It acts as a landing zone including structured, semi-structured, and unstructured data. Data in this layer is ingested as-is, it is a copy of the data exactly as it was loaded from the data source. meaning it’s often messy, unclean, and can include duplicates.
If a fault occurs, it allows you to quickly determine if the the problem is related to source data or processing within the data platform.
Gold zone
Sometimes it is also called Curated zone/layer.
Data in this layer is fully cleaned, secured and maybe pre-aggregated data. All data is ready for access. contains highly curated, aggregated. data usually tailored for specific use cases, such as reporting, business intelligence, or machine learning.and often ready-for-consumption data.
Silver Layer (Cleaned Data)
There is layer between the Bronze and Gold layer, it is called Silver Layer. The silver layer is where data is cleaned, transformed, and often enriched. It’s meant to be a more refined version of the bronze layer, ready for further analysis or use in applications. Data in this layer is typically free of duplicates, missing values are handled, and unnecessary data is filtered out. The transformations applied here make the data more structured and reliable.
Why use Medallion Architecture
Many software engineers are familiar the “multiple tiers architecture” in software development. Medallion Architecture has the same meaning “multiple architectures”.
Scalability: The layered approach allows for scaling each part of the data pipeline independently.
Flexibility: It provides flexibility in data processing and the ability to handle different data types and sources.
Data Quality: By progressing data through these layers, the architecture naturally enforces data quality and consistency.
Ease of Use: It simplifies data management by organizing the data into distinct stages, making it easier to understand and manage.
Conclusion
Overall, the Medallion Architecture is a powerful pattern for managing data lifecycle, from raw ingestion to refined, consumable datasets. It often use in data engineering project. such as Data Lakes, Big Data Processing, ETL/ELT Pipelines etc.
Please do not hesitate to contact me if you have any questions at William . chen @mainri.ca
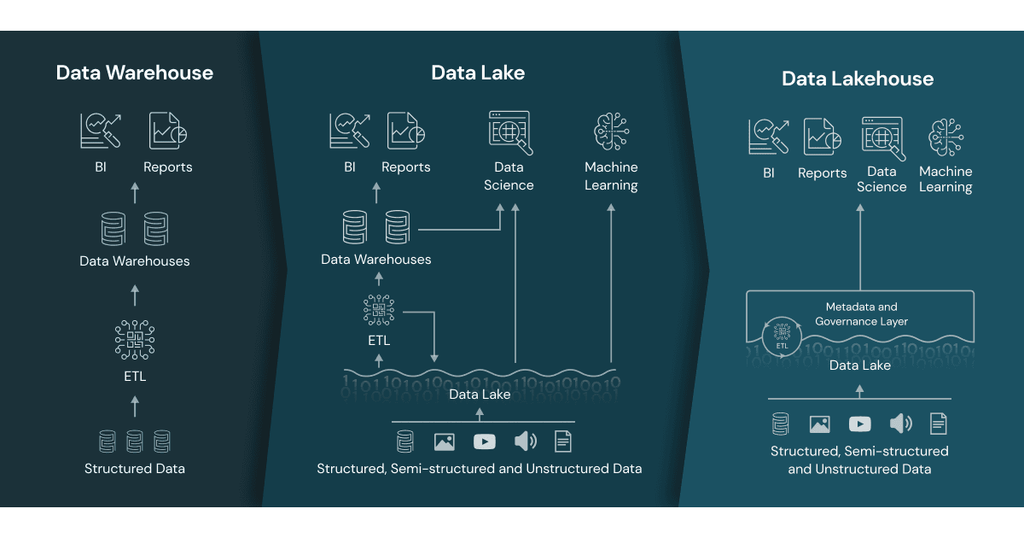
As a data engineer, we often hear terms like Data Lake, Delta Lake, Data Lakehouse, and data warehouse, which might be confusing at times. Today, we’ll explain these terms and talk about the differences of each of the technologies and concepts, along with scenarios of usage for each.
Delta Lake
Delta lake is an open-source technology, we don’t have a Delta Lake; you use Delta Lake to store your data in Delta tables. Delta lake improves data storage by supporting ACID transactions, high-performance query optimizations, schema evolution, data versioning and many other features.
Delta Lake takes your existing Parquet data lake and makes it more reliable and performant by:
Storing all the metadata in a separate transaction log
Tracking all the changes to your data in this transaction log
Organizing your data for maximum query performance
Data Lakehouse
Data lakehouse is a new, open data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of data warehouses, enabling business intelligence (BI) and machine learning (ML) on all data.
Data Lake
A data lake is a centralized repository that allows organizations to store vast amounts of structured, semi-structured, and unstructured data. Unlike traditional data warehouses, a data lake retains data in its raw form until it is needed, which provides flexibility in how the data can be used.
Data Warehouse
A data warehouse is a centralized repository that stores structured data (database tables, Excel sheets) and semi-structured data (XML files, webpages) Its data is usually cleaned and standardized for the purposes of reporting and analysis.
Data lakes vs. data lakehouse vs. data warehouses
follow table simply compared what difference .
Data lake
Data lakehouse
Data warehouse
Types of data
All types: Structured data, semi-structured data, unstructured (raw) data
All types: Structured data, semi-structured data, unstructured (raw) data
Structured data only
Cost
$
$
$$$
Format
Open format
Open format
Closed, proprietary format
Scalability
Scales to hold any amount of data at low cost, regardless of type
Scales to hold any amount of data at low cost, regardless of type
Scaling up becomes exponentially more expensive due to vendor costs
Intended users
Limited: Data scientists
Unified: Data analysts, data scientists, machine learning engineers
Limited: Data analysts
Reliability
Low quality, data swamp
High quality, reliable data
High quality, reliable data
Ease of use
Difficult: Exploring large amounts of raw data can be difficult without tools to organize and catalog the data
Simple: Provides simplicity and structure of a data warehouse with the broader use cases of a data lake
Simple: Structure of a data warehouse enables users to quickly and easily access data for reporting and analytics
Performance
Poor
High
High
summary
Data lakes are a good technology that give you flexible and low-cost data storage. Data lakes can be a great choice for you if:
You have data in multiple formats coming from multiple sources
You want to use this data in many different downstream tasks, e.g. analytics, data science, machine learning, etc.
You want flexibility to run many different kinds of queries on your data and do not want to define the questions you want to ask your data in advance
You don’t want to be locked into a vendor-specific proprietary table format
Data lakes can also get messy because they do not provide reliability guarantees. Data lakes are also not always optimized to give you the fastest query performance.
Delta Lake is almost always more reliable, faster and more developer-friendly than a regular data lake. Delta lake can be a great choice for you because:
You have data in multiple formats coming from multiple sources
You want to use this data in many different downstream tasks, e.g. analytics, data science, machine learning, etc.
You want flexibility to run many different kinds of queries on your data and do not want to define the questions you want to ask your data in advance
You don’t want to be locked into a vendor-specific proprietary table format
Please do not hesitate to contact me if you have any questions at William . chen @mainri.ca
A Service Principal in Azure is an identity used by applications, services, or automated tools to access specific Azure resources. It’s tied to an Azure App Registration and is used for managing permissions and authentication.
The Microsoft identity platform performs identity and access management (IAM) only for registered applications. Whether it’s a client application like a ADF or Synapse, Wen Application or mobile app, or it’s a web API that backs a client app, registering establishes a trust relationship between your application and the identity provider, the Microsoft identity platform.
This article is talking on registering an application in the Microsoft Entra admin center. I outline the registration procedure step by step.
Summary steps:
Navigate to Azure Entra ID (Azure Active Directory)
Create an App Registration
Generate Client Secret, note down Important the Application (client) ID and Directory (tenant) ID, Client-Secret-value.
Using the Service Principle – Assign Roles to the Service Principal Navigate to the Azure resource (e.g., Storage Account, Key Vault, SQL Database) you want your Service Principal to access.
Step by Step Demo
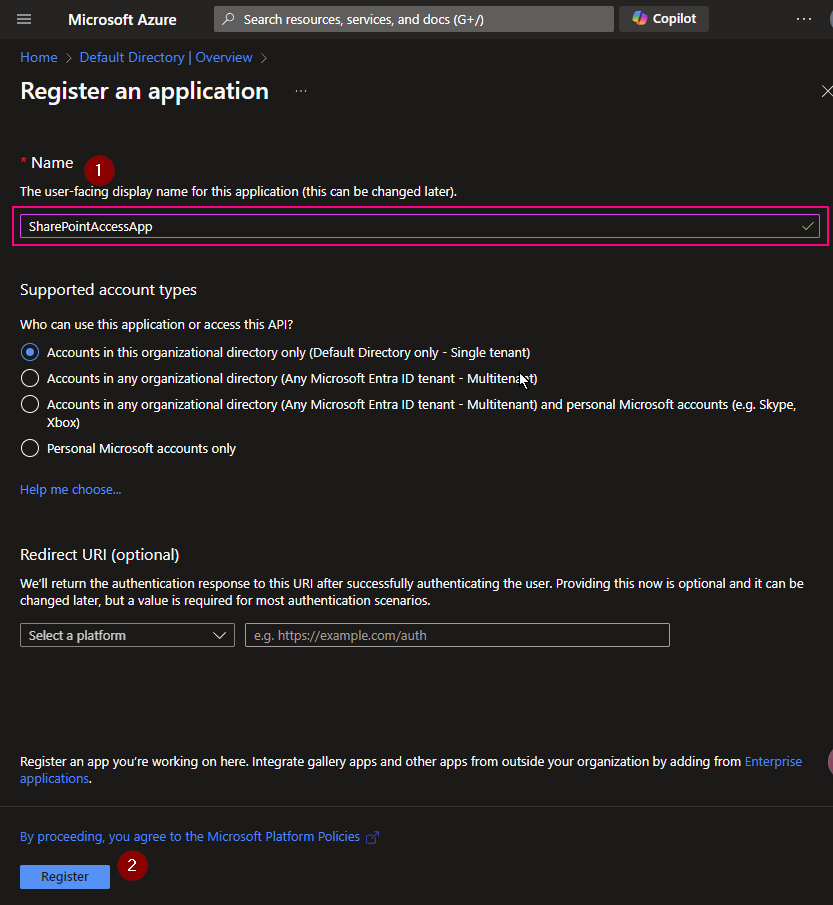
Register a new Application on Azure Entra ID (formerly called Azure Active Directory), get an Application ID and Client Secret value.
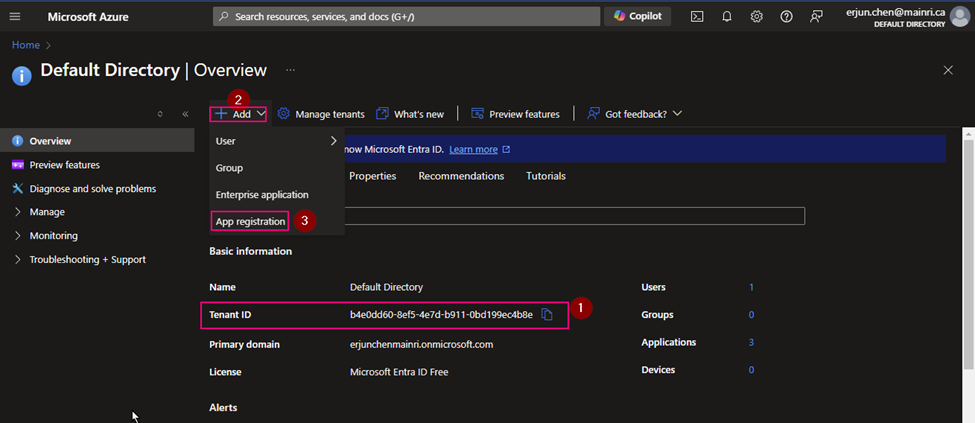
Azure Portal >> Azure Entra ID (formerly called Azure Active Directory)
(1) Copy Tenant ID.
We need this Tenant ID later.
(2) App Registration
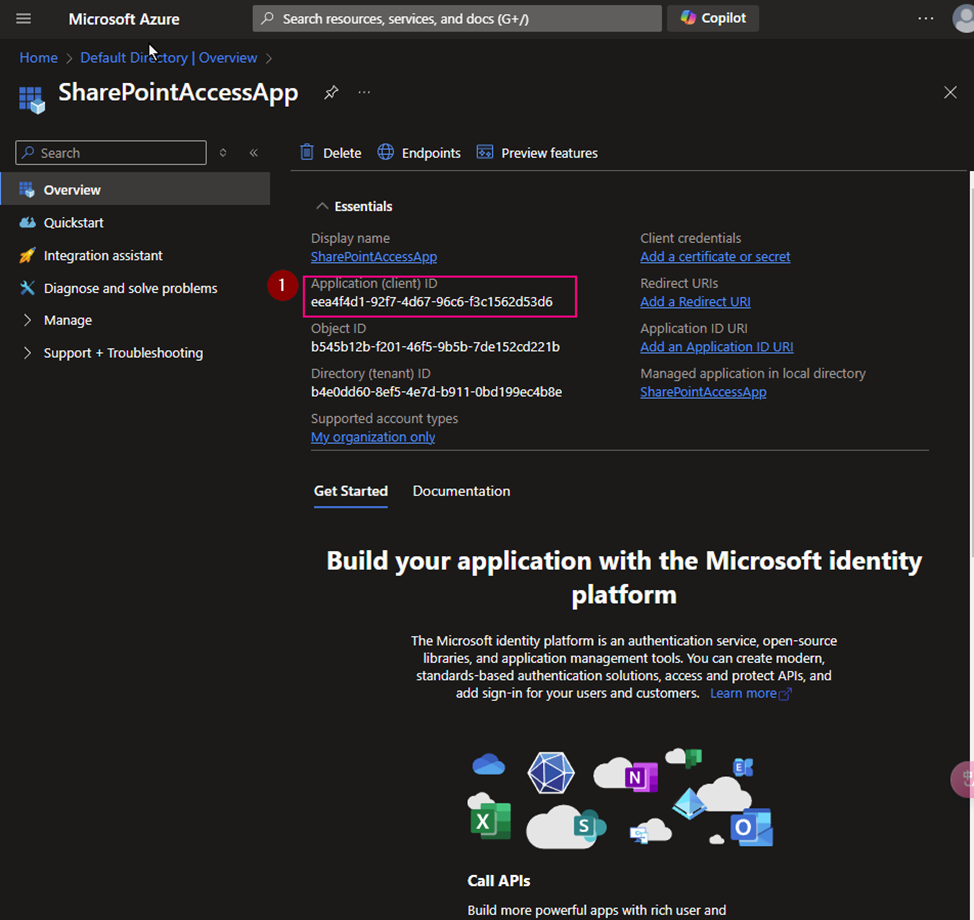
(3) Copy Application ID. We will use it later
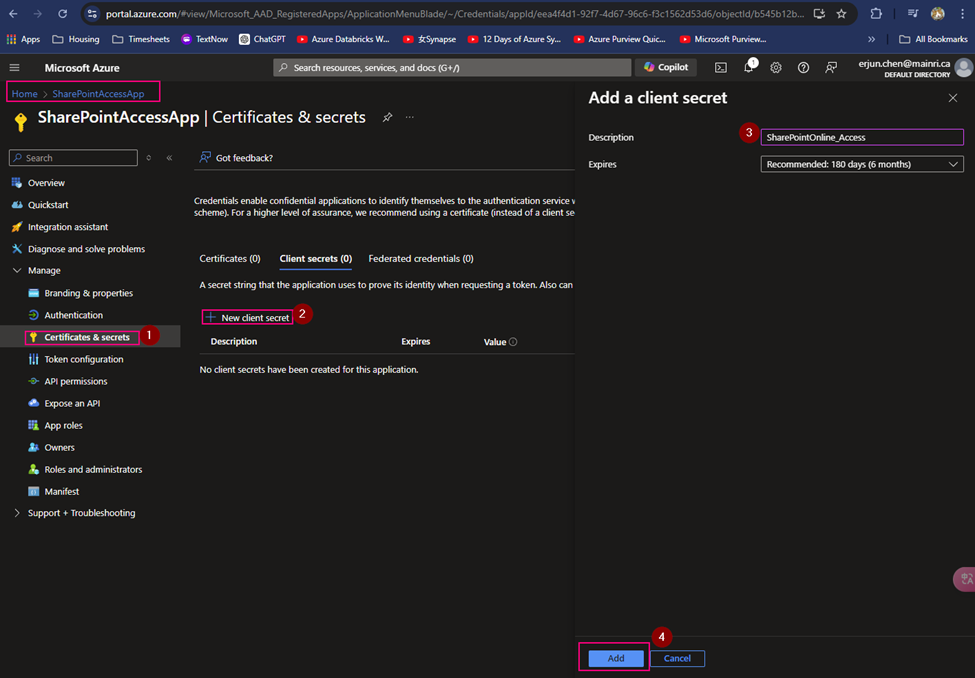
(4) Create Client Secret
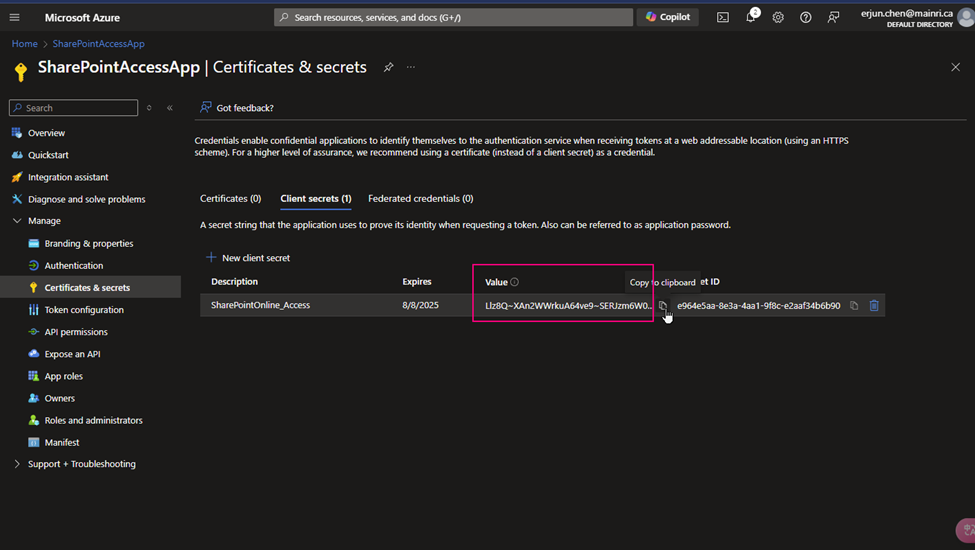
Generate a new client Secret,
(5) copy the Client Secret Value
Copy client-secret-value, we need it later.
Cause: the Client Secret Value you HAVE TO COPY IT RIGHT NOW! IMMEDIATELY copy NOW. And put it to a secure place. Since the Value WILL NOT reappear anymore. IMOPRTANT!
(6) Using the Service Principle – Assign Roles to the Service Principal
Assign Roles to the Service Principal
Now, assign permissions to your Service Principal so it can access specific Azure resources:
Navigate to the Azure resource (e.g., Storage Account, Key Vault, SQL Database) you want your Service Principal to access.
Go to Access Control (IAM).
Click Add and choose Add role assignment.
Choose a role (e.g., Contributor, Reader, or a custom role).
Search for your App Registration by its name and select it.
Save
We have finished all at Azure Entra ID (Former Azure Active Directory)
Please do not hesitate to contact me if you have any questions at william . chen @mainri.ca