Today, data engineers have a wide array of tools and platforms at their disposal for data engineering projects. Popular choices include Microsoft Fabric, Azure Synapse Analytics (ASA), Azure Data Factory (ADF), and Azure Databricks (ADB). It’s common to wonder which one is the best fit for your specific needs.
Side by Side comparison
Here’s a concise comparison of Microsoft Fabric, Azure Synapse Analytics, Azure Data Factory (ADF), and Azure Databricks (ADB) based on their key features, use cases, and differences:
Limited (relies on Delta Lake, ADF, or custom code)
Data Warehousing
OneLake (Delta-Parquet based)
Dedicated SQL pools (MPP)
Not applicable
Can integrate with Synapse/Delta Lake
Big Data Processing
Spark-based (Fabric Spark)
Spark pools (serverless/dedicated)
No (orchestration only)
Optimized Spark clusters (Delta Lake)
Real-Time Analytics
Yes (Real-Time Hub)
Yes (Synapse Real-Time Analytics)
No
Yes (Structured Streaming)
Business Intelligence
Power BI (deeply integrated)
Power BI integration
No
Limited (via dashboards or Power BI)
Machine Learning
Basic ML integration
ML in Spark pools
No
Full ML/DL support (MLflow, AutoML)
Pricing Model
Capacity-based (Fabric SKUs)
Pay-as-you-go (serverless) or dedicated
Activity-based
DBU-based (compute + storage)
Open Source Support
Limited (Delta-Parquet)
Limited (Spark, SQL)
No
Full (Spark, Python, R, ML frameworks)
Governance
Centralized (OneLake, Purview)
Workspace-level
Limited
Workspace-level (Unity Catalog)
Key Differences
Fabric vs Synapse: Fabric is a fully managed SaaS (simpler, less configurable), while Synapse offers more control (dedicated SQL pools, Spark clusters).
Data quality is more critical than ever in today’s data-driven world. Organizations are generating and collecting vast amounts of data, and the ability to trust and leverage this information is paramount for success. Poor data quality can have severe negative impacts, ranging from flawed decision-making to regulatory non-compliance and significant financial losses.
Key Dimensions of Data Quality (DAMA-DMBOK or ISO 8000 Standards)
A robust DQX evaluates data across multiple dimensions:
Accuracy: Data correctly represents real-world values.
Completeness: No missing or null values where expected.
Consistency: Data is uniform across systems and over time.
Timeliness: Data is up-to-date and available when needed.
Validity: Data conforms to defined business rules (e.g., format, range).
Uniqueness: No unintended duplicates.
Integrity: Relationships between datasets are maintained.
What is Data Quality Framework (DQX)
A Data Quality Framework (DQX) is an open-source framework from Databricks Labs designed to simplify and automate data quality checks for PySpark workloads on both batch and streaming data.
DAX is a structured approach to assessing, monitoring, and improving the quality of data within an organization. It define, validate, and enforce data quality rules across your data pipelines. It ensures that data is accurate, consistent, complete, reliable, and fit for its intended use. so it can be used confidently for analytics, reporting, compliance, and decision-making.
This article will explore how the DQX framework helps improve data reliability, reduce data errors, and enforce compliance with data quality standards. We will step by step go through all steps, from setup and use DQX framework in databricks notebook with code snippets to implement data quality checks.
DQX usage in the Lakehouse Architecture
In the Lakehouse architecture, new data validation should happen during data entry into the curated layer to ensure bad data is not propagated to the subsequent layers. With DQX, you can implement Dead-Letter pattern to quarantine invalid data and re-ingest it after curation to ensure data quality constraints are met. The data quality can be monitored in real-time between layers, and the quarantine process can be automated.
Benchmarking: Compare against industry standards or past performance.
B. Data Quality Rules & Standards
Define validation rules (e.g., “Email must follow RFC 5322 format”).
Implement checks at the point of entry (e.g., form validation) and during processing.
C. Governance & Roles
Assign data stewards responsible for quality.
Establish accountability (e.g., who fixes issues? Who approves changes?).
D. Monitoring & Improvement
Automated checks: Use tools like Great Expectations, Talend, or custom scripts.
Root Cause Analysis (RCA): Identify why errors occur (e.g., system glitches, human input).
Continuous Improvement: Iterative fixes (e.g., process changes, user training).
E. Tools & Technology
Data Quality Tools: Informatica DQ, IBM InfoSphere, Ataccama, or open-source (Apache Griffin).
Metadata Management: Track data lineage and quality scores.
AI/ML: Anomaly detection (e.g., identifying drift in datasets).
F. Culture & Training
Promote data literacy across teams.
Encourage reporting of data issues without blame.
Using Databricks DQX Framework in a Notebook
Step by Step Implementing DQX
Step 1: Install the DQX Library
install it using the Databricks Labs CLI:
%pip install databricks-labs-dqx
# Restart the kernel after the package is installed in the notebook:
# in a separate cell run:
dbutils.library.restartPython()
Step 2: Initialize the Environment and read input data
Set up the necessary environment for running the Databricks DQX framework, including:
Importing the key components from the Databricks DQX library.
DQProfiler: Used for profiling the input data to understand its structure and generate summary statistics.
DQGenerator: Generates data quality rules based on the profiles.
DQEngine: Executes the defined data quality checks.
WorkspaceClient: Handles communication with the Databricks workspace.
Import Libraries
from databricks.labs.dqx.profiler.profiler import DQProfiler
from databricks.labs.dqx.profiler.generator import DQGenerator
from databricks.labs.dqx.engine import DQEngine
from databricks.sdk import WorkspaceClient
Loading the input data that you want to evaluate.
# Read the input data from a Delta table
input_df = spark.read.table("catalog.schema.table")
Establishing a connection to the Databricks workspace.
# Initialize the WorkspaceClient to interact with the Databricks workspace
ws = WorkspaceClient()
# Initialize a DQProfiler instance with the workspace client
profiler = DQProfiler(ws)
Profiling for data quality.
# Profile the input DataFrame to get summary statistics and data profiles
summary_stats, profiles = profiler.profile(input_df)
The profiler samples 30% of the data (sample ratio = 0.3) and limits the input to 1000 records by default.
Profiling a Table
Tables can be loaded and profiled using profile_table.
from databricks.labs.dqx.profiler.profiler import DQProfiler
from databricks.sdk import WorkspaceClient
# Profile a single table directly
ws = WorkspaceClient()
profiler = DQProfiler(ws)
# Profile a specific table with custom options
summary_stats, profiles = profiler.profile_table(
table="catalog1.schema1.table1",
columns=["col1", "col2", "col3"], # specify columns to profile
options={
"sample_fraction": 0.1, # sample 10% of data
"limit": 500, # limit to 500 records
"remove_outliers": True, # enable outlier detection
"num_sigmas": 2.5 # use 2.5 standard deviations for outliers
}
)
print("Summary Statistics:", summary_stats)
print("Generated Profiles:", profiles)
Profiling Multiple Tables
The profiler can discover and profile multiple tables in Unity Catalog. Tables can be passed explicitly as a list or be included/excluded using regex patterns.
from databricks.labs.dqx.profiler.profiler import DQProfiler
from databricks.sdk import WorkspaceClient
ws = WorkspaceClient()
profiler = DQProfiler(ws)
# Profile several tables by name:
results = profiler.profile_tables(
tables=["main.data.table_001", "main.data.table_002"]
)
# Process results for each table
for summary_stats, profiles in results:
print(f"Table statistics: {summary_stats}")
print(f"Generated profiles: {profiles}")
# Include tables matching specific patterns
results = profiler.profile_tables(
patterns=["$main.*", "$data.*"]
)
# Process results for each table
for summary_stats, profiles in results:
print(f"Table statistics: {summary_stats}")
print(f"Generated profiles: {profiles}")
# Exclude tables matching specific patterns
results = profiler.profile_tables(
patterns=["$sys.*", ".*_tmp"],
exclude_matched=True
)
# Process results for each table
for summary_stats, profiles in results:
print(f"Table statistics: {summary_stats}")
print(f"Generated profiles: {profiles}")
Profiling Options
The profiler supports extensive configuration options to customize the profiling behavior.
from databricks.labs.dqx.profiler.profiler import DQProfiler
from databricks.sdk import WorkspaceClient
# Custom profiling options
custom_options = {
# Sampling options
"sample_fraction": 0.2, # Sample 20% of the data
"sample_seed": 42, # Seed for reproducible sampling
"limit": 2000, # Limit to 2000 records after sampling
# Outlier detection options
"remove_outliers": True, # Enable outlier detection for min/max rules
"outlier_columns": ["price", "age"], # Only detect outliers in specific columns
"num_sigmas": 2.5, # Use 2.5 standard deviations for outlier detection
# Null value handling
"max_null_ratio": 0.05, # Generate is_not_null rule if <5% nulls
# String handling
"trim_strings": True, # Trim whitespace from strings before analysis
"max_empty_ratio": 0.02, # Generate is_not_null_or_empty if <2% empty strings
# Distinct value analysis
"distinct_ratio": 0.01, # Generate is_in rule if <1% distinct values
"max_in_count": 20, # Maximum items in is_in rule list
# Value rounding
"round": True, # Round min/max values for cleaner rules
}
ws = WorkspaceClient()
profiler = DQProfiler(ws)
# Apply custom options to profiling
summary_stats, profiles = profiler.profile(input_df, options=custom_options)
# Apply custom options when profiling tables
tables = [
"dqx.demo.test_table_001",
"dqx.demo.test_table_002",
"dqx.demo.test_table_003", # profiled with default options
]
table_options = {
"dqx.demo.test_table_001": {"limit": 2000},
"dqx.demo.test_table_002": {"limit": 5000},
}
summary_stats, profiles = profiler.profile_tables(tables=tables, options=table_options)
Understanding output
Assuming the sample data is:
customer_id
customer_name
customer_email
is_active
start_date
end_date
1
Alice
alice@mainri.ca
1
2025-01-24
null
2
Bob
bob_new@mainri.ca
1
2025-01-24
null
3
Charlie
invalid_email
1
2025-01-24
null
3
Charlie
invalid_email
0
2025-01-24
2025-01-24
# Initialize the WorkspaceClient to interact with the Databricks workspace
ws = WorkspaceClient()
# Initialize a DQProfiler instance with the workspace client
profiler = DQProfiler(ws)
# Read the input data from a Delta table
input_df = spark.read.table("catalog.schema.table")
# Display a sample of the input data
input_df.display()
# Profile the input DataFrame to get summary statistics and data profiles
summary_stats, profiles = profiler.profile(input_df)
Upon checking the summary and profile of my input data generated, below are the results generated by DQX
print(summary_stats)
Summary of input data on all the columns in input dataframe
In addition to the automatically generated checks, you can define your own custom rules to enforce business-specific data quality requirements. This is particularly useful when your organization has unique validation criteria that aren’t covered by the default checks. By using a configuration-driven approach (e.g., YAML), you can easily maintain and update these rules without modifying your pipeline code.
For example, you might want to enforce that:
Customer IDs must not be null or empty.
Email addresses must match a specific domain format (e.x: @example.com).
# Validate the custom data quality checks
status = DQEngine.validate_checks(checks_custom)
# The above variable for the custom config yaml file can also be pased from workspace file path as given below:
status = DQEngine.validate_checks("path to yaml file in workspace")
# Assert that there are no errors in the validation status
assert not status.has_errors
Step 5: Applying the custom rules and generating results
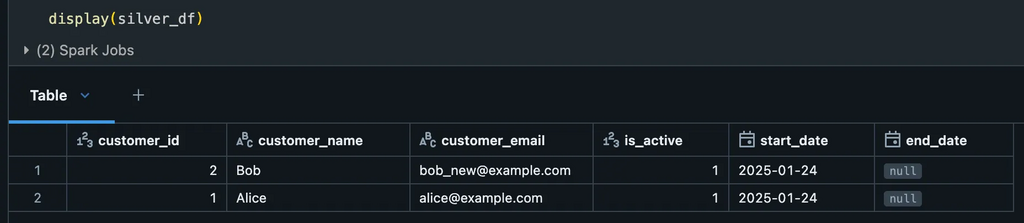
Once your custom data quality rules have been defined and validated, the next step is to apply them to your input data. The DQEngine facilitates this by splitting your dataset into two categories:
Silver Data: Records that meet all quality expectations.
Quarantined Data: Records that fail one or more quality checks.
This approach allows you to separate valid and invalid data for further inspection and remediation. The valid records can proceed to downstream processes, while the quarantined records can be analyzed to determine the cause of failure (e.g., missing values, incorrect formats).
Here’s how you can apply the rules and generate the results:
# Create a DQEngine instance with the WorkspaceClient
dq_engine = DQEngine(WorkspaceClient())
# Apply quality checks and split the DataFrame into silver and quarantine DataFrames
silver_df, quarantine_df = dq_engine.apply_checks_by_metadata_and_split(input_df_1, checks_custom)
Silver data (Valid)Quarantined data – Not matching the rules
Summary
In essence, data quality is no longer just an IT concern; it’s a fundamental business imperative. In today’s complex and competitive landscape, the success of an organization hinges on its ability to leverage high-quality, trusted data for every strategic and operational decision.
A Data Quality Framework (DQX) helps organizations:
In Azure Databricks Unity Catalog, you can create different types of tables depending on your storage and management needs. The main table types are including Managed Tables, External Tables, Delta Tables, Foreign Tables, Streaming Tables, Live Tables (deprecated), Feature Tables, and Hive Tables (legacy). Each table type is explained in detail, and a side-by-side comparison is provided for clarity.
Side-by-Side Comparison Table
Feature
Managed Tables
External Tables
Delta Tables
Foreign Tables
Streaming Tables
Delta Live Tables (DLT)
Feature Tables
Hive Tables (Legacy)
Storage
Databricks-managed
External storage
Managed/External
External database
Databricks-managed
Databricks-managed
Managed/External
Managed/External
Location
Internal Delta Lake
Specified external path
Internal/External Delta Lake
External metastore (Snowflake, BigQuery)
Internal Delta Lake
Internal Delta Lake
Internal/External Delta Lake
Internal/External storage
Ownership
Databricks
User
Databricks/User
External provider
Databricks
Databricks
Databricks/User
Databricks (Legacy Hive Metastore)
Deletion Impact
Deletes data & metadata
Deletes only metadata
Depends (Managed: Deletes, External: Keeps data)
Deletes only metadata reference
Deletes data & metadata
Deletes data & metadata
Deletes metadata (but not feature versions)
Similar to Managed/External
Format
Delta Lake
Parquet, CSV, JSON, Delta
Delta Lake
Snowflake, BigQuery, Redshift, etc.
Delta Lake
Delta Lake
Delta Lake
Parquet, ORC, Avro, CSV
Use Case
Full lifecycle management
Sharing with external tools
Advanced data versioning & ACID compliance
Querying external DBs
Continuous data updates
ETL Pipelines
ML feature storage
Legacy storage (pre-Unity Catalog)
Table type and describes
1. Managed Tables
Managed tables are tables where both the metadata and the data are managed by Unity Catalog. When you create a managed table, the data is stored in the default storage location associated with the catalog or schema.
Data Storage and location:
Unity Catalog manages both the metadata and the underlying data in a Databricks-managed location
The data is stored in a Unity Catalog-managed storage location. Typically in an internal Delta Lake storage, e.g., DBFS or Azure Data Lake Storage
Use Case:
Ideal for Databricks-centric workflows where you want Databricks to handle storage and metadata.
Pros & Cons:
Pros: Easy to manage, no need to worry about storage locations.
Cons: Data is tied to Databricks, making it harder to share externally.
Example:
CREATE TABLE managed_table (
id INT,
name STRING
);
INSERT INTO managed_table VALUES (1, 'Alice');
SELECT * FROM managed_table;
2. External Tables
External tables store metadata in Unity Catalog but keep data in an external storage location (e.g., Azure Blob Storage, ADLS, S3).
Data storage and Location:
The metadata is managed by Unity Catalog, but the actual data remains in external storage (like Azure Data Lake Storage Gen2 or an S3 bucket).
You must specify an explicit storage location, e.g., Azure Blob Storage, ADLS, S3).
Use Case:
Ideal for cross-platform data sharing or when data is managed outside Databricks.
Pros and Cons
Pros: Data is decoupled from Databricks, making it easier to share.
Cons: Requires manual management of external storage and permissions.
Preparing create external table
Before you can create an external table, you must create a storage credential that allows Unity Catalog to read from and write to the path on your cloud tenant, and an external location that references it.
Requirements
In Azure, create a service principal and grant it the Azure Blob Contributor role on your storage container.
In Azure, create a client secret for your service principal. Make a note of the client secret, the directory ID, and the application ID for the client secret.
step 1: Create a storage credential
You can create a storage credential using the Catalog Explorer or the Unity Catalog CLI. Follow these steps to create a storage credential using Catalog Explorer.
In a new browser tab, log in to Databricks.
Click Catalog.
Click Storage Credentials.
Click Create Credential.
Enter example_credential for he name of the storage credential.
Set Client Secret, Directory ID, and Application ID to the values for your service principal.
Optionally enter a comment for the storage credential.
Click Save. Leave this browser open for the next steps.
Create an external location
An external location references a storage credential and also contains a storage path on your cloud tenant. The external location allows reading from and writing to only that path and its child directories. You can create an external location from Catalog Explorer, a SQL command, or the Unity Catalog CLI. Follow these steps to create an external location using Catalog Explorer.
Go to the browser tab where you just created a storage credential.
Click Catalog.
Click External Locations.
Click Create location.
Enter example_location for the name of the external location.
Enter the storage container path for the location allows reading from or writing to.
Set Storage Credential to example_credential to the storage credential you just created.
Optionally enter a comment for the external location.
Click Save.
-- Grant access to create tables in the external location
GRANT USE CATALOG
ON example_catalog
TO `all users`;
GRANT USE SCHEMA
ON example_catalog.example_schema
TO `all users`;
GRANT CREATE EXTERNAL TABLE
ON LOCATION example_location
TO `all users`;
-- Create an example catalog and schema to contain the new table
CREATE CATALOG IF NOT EXISTS example_catalog;
USE CATALOG example_catalog;
CREATE SCHEMA IF NOT EXISTS example_schema;
USE example_schema;
-- Create a new external Unity Catalog table from an existing table
-- Replace <bucket_path> with the storage location where the table will be created
CREATE TABLE IF NOT EXISTS trips_external
LOCATION 'abfss://<bucket_path>'
AS SELECT * from samples.nyctaxi.trips;
-- To use a storage credential directly, add 'WITH (CREDENTIAL <credential_name>)' to the SQL statement.
There are some useful Microsoft document to be refer:
Delta tables use the Delta Lake format, providing ACID transactions, scalable metadata handling, and data versioning.
Data Storage and Location
A special type of managed or external table that uses Delta Lake format.
Can be in managed storage or external storage.
Use Case:
Ideal for reliable, versioned data pipelines.
Pros and Cons
Pros: ACID compliance, time travel, schema enforcement, efficient upserts/deletes.
Cons: Slightly more complex due to Delta Lake features.
Example
CREATE TABLE delta_table (
id INT,
name STRING
)
USING DELTA
LOCATION 'abfss://container@storageaccount.dfs.core.windows.net/path/to/delta';
INSERT INTO delta_table VALUES (1, 'Charlie');
SELECT * FROM delta_table;
-- Time travel example
SELECT * FROM delta_table VERSION AS OF 1;
5. Feature Tables
Feature tables are used in machine learning workflows to store and manage feature data for training and inference.
Data Storage and Location
Used for machine learning (ML) feature storage with Databricks Feature Store.
Can be managed or external.
Use Case:
Ideal for managing and sharing features across ML models and teams.
Pros and Cons:
Pros: Centralized feature management, versioning, and lineage tracking.
Pros: Centralized feature management, versioning, and lineage tracking.
Streaming tables are designed for real-time data ingestion and processing using Structured Streaming.
Data Location:
Can be stored in managed or external storage.
Use Case:
Ideal for real-time data pipelines and streaming analytics.
Pros and Cons
Pros: Supports real-time data processing, integrates with Delta Lake for reliability.
Cons: Requires understanding of streaming concepts and infrastructure.
Example:
CREATE TABLE streaming_table (
id INT,
name STRING
)
USING DELTA;
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("StreamingExample").getOrCreate()
streaming_df = spark.readStream.format("delta").load("/path/to/delta")
streaming_df.writeStream.format("delta").outputMode("append").start("/path/to/streaming_table")
Delta Live Tables (DLT)
Delta Live Tables (DLT) is the modern replacement for Live Tables. It is a framework for building reliable, maintainable, and scalable ETL pipelines using Delta Lake. DLT automatically handles dependencies, orchestration, and error recovery.
Data storage and Location:
Data is stored in Delta Lake format, either in managed or external storage.
Use Case:
Building production-grade ETL pipelines for batch and streaming data.
DLT pipelines are defined using Python or SQL.
Tables are automatically materialized and can be queried like any other Delta table.
Pros and Cons
Declarative pipeline definition.
Automatic dependency management.
Built-in data quality checks and error handling.
Supports both batch and streaming workloads.
Cons: Requires understanding of Delta Lake and ETL concepts.
Hive tables are legacy tables that use the Apache Hive format. They are supported for backward compatibility.
Data storage Location:
Can be stored in managed or external storage.
Use Case:
Legacy systems or migration projects.
Pros and Cons
Pros: Backward compatibility with older systems.
Cons: Lacks modern features like ACID transactions and time travel.
Example
CREATE TABLE hive_table (
id INT,
name STRING
)
STORED AS PARQUET;
INSERT INTO hive_table VALUES (1, 'Dave');
SELECT * FROM hive_table;
Final Thoughts
Use Delta Live Tables for automated ETL pipelines.
Use Feature Tables for machine learning models.
Use Foreign Tables for querying external databases.
Avoid Hive Tables unless working with legacy systems.
Summary
Managed Tables: Fully managed by Databricks, ideal for internal workflows.
External Tables: Metadata managed by Databricks, data stored externally, ideal for cross-platform sharing.
Delta Tables: Advanced features like ACID transactions and time travel, ideal for reliable pipelines.
Foreign Tables: Query external systems without data duplication.
Streaming Tables: Designed for real-time data processing.
Feature Tables: Specialized for machine learning feature management.
Hive Tables: Legacy format, not recommended for new projects.
Each table type has its own creation syntax and usage patterns, and the choice depends on your specific use case, data storage requirements, and workflow complexity.
Please do not hesitate to contact me if you have any questions at William . chen @ mainri.ca
Built on Apache Spark, Delta Lake provides a robust storage layer for data in Delta tables. Its features include ACID transactions, high-performance queries, schema evolution, and data versioning, among others.
Today’s focus is on how Delta Lake simplifies the management of slowly changing dimensions (SCDs).
Quickly review Type 2 of Slowly Changing Dimension
A quick recap of SCD Type 2 follows:
Storing historical dimension data with effective dates.
Keeping a full history of dimension changes (with start/end dates).
Adding new rows for dimension changes (preserving history).
# Existing Dimension datasurrokey depID dep StartDate EndDate IsActivity
1 1001 IT 2019-01-01 9999-12-31 1
2 1002 Sales 2019-01-01 9999-12-31 1
3 1003 HR 2019-01-01 9999-12-31 1
# Dimension changed and new data comes
depId dep
1003 wholesale <--- depID is same, name changed from "Sales" to "wholesale"
1004 Finance <--- new data
# the new Dimension will be:surrokey depID depStartDate EndDate IsActivity
1 1001 IT 2019-01-01 9999-12-31 1 <-- No action required
2 1002 HR 2019-01-01 9999-12-31 1 <-- No action required
3 1003 Sales 2019-01-01 2020-12-31 0 <-- mark as inactive
4 1003 wholesale 2021-01-01 9999-12-31 1 <-- add updated active value
5 1004 Finance 2021-01-01 9999-12-31 1 <-- insert new data
Creating demo data
We’re creating a Delta table, dim_dep, and inserting three rows of existing dimension data.
Existing dimension data
%sql
# Create table dim_dep
%sql
create table dim_dep (
Surrokey BIGINT GENERATED ALWAYS AS IDENTITY
, depID int
, dep string
, StartDate DATE
, End_date DATE
, IsActivity BOOLEAN
)
using delta
location 'dbfs:/mnt/dim/'
# Insert data
insert into dim_dep (depID,dep, StartDate,EndDate,IsActivity) values
(1001,'IT','2019-01-01', '9999-12-31' , 1),
(1002,'Sales','2019-01-01', '9999-12-31' , 1),
(1003,'HR','2019-01-01', '9999-12-31' , 1)
select * from dim_dep
Surrokey depID dep StartDate EndDate IsActivity
1 1001 IT 2019-01-01 9999-12-31 true
2 1002 Sales 2019-01-01 9999-12-31 true
3 1003 HR 2019-01-01 9999-12-31 true
We perform a source dataframe – df_dim_dep_source, left outer join target dataframe – df_dim_dep_target, where source depID = target depID, and also target’s IsActivity = 1 (meant activity)
This join’s intent is not to miss any new data coming through source. And active records in target because only for those data SCD update is required. After joining source and target, the resultant dataframe can be seen below.
Step 4: Filter only the non matched and updated records
In this demo, we only have depid and dep two columns. But in the actual development environment, may have many many columns.
Instead of comparing multiple columns, e.g., src_col1 != tar_col1, src_col2 != tar_col2, ….. src_colN != tar_colN We compute hashes for both column combinations and compare the hashes. In addition of this, in case of column’s data type is different, we convert data type the same one.
The row, dep_id = 1003, dep = HR, was filtered out because both source and target side are the same. No action required.
The row, depid =1002, dep changed from “Sales” to “Wholesale”, need updating.
The row, depid = 1004, Finance is brand new row, need insert into target side – dimension table.
Step 5: Find out records that will be used for inserting
From above discussion, we have known depid=1002, need updating and depid=1004 is a new rocord. We will create a new column ‘merge_key’ which will be used for upsert operation. This column will hold the values of source id.
Add a new column – “merge_key”
df_inserting = df_filtered. withColumn('merge_key', col('depid'))
df_inserting.show()
+-----+---------+------------+---------+-------+-------------+-----------+--------------+---------+
|depid| dep|tar_surrokey|tar_depID|tar_dep|tar_StartDate|tar_EndDate|tar_IsActivity|merge_key|
+-----+---------+------------+---------+-------+-------------+-----------+--------------+---------+
| 1002|Wholesale| 2| 1002| Sales| 2019-01-01| 9999-12-31| true| 1002|
| 1004| Finance| null| null| null| null| null| null| 1004|
+-----+---------+------------+---------+-------+-------------+-----------+--------------+---------+
The above 2 records will be inserted as new records to the target table
The above 2 records will be inserted as new records to the target table.
Step 6: Find out the records that will be used for updating in target table
from pyspark.sql.functions import lit
df_updating = df_filtered.filter(col('tar_depID').isNotNull()).withColumn('merge_key',lit('None')
df_updating.show()
+-----+---------+------------+---------+-------------+-----------+--------------+---------+
|depid| dep|tar_surrokey|tar_depID|tar_StartDate|tar_EndDate|tar_IsActivity|merge_key|
+-----+---------+------------+---------+-------------+-----------+--------------+---------+
| 1003|Wholesale| 3| 1003| 2019-01-01| 9999-12-31| true| None|
+-----+---------+------------+---------+-------------+-----------+--------------+---------+
The above record will be used for updating SCD columns in the target table.
This dataframe filters the records that have tar_depID column not null which means, the record already exists in the table for which SCD update has to be done. The column merge_key will be ‘None’ here which denotes this only requires update in SCD cols.
Step 7: Combine inserting and updating records as stage
we demonstrated how to unlock the power of Slowly Changing Dimension (SCD) Type 2 using Delta Lake, a revolutionary storage layer that transforms data lakes into reliable, high-performance, and scalable repositories. With this approach, organizations can finally unlock the full potential of their data and make informed decisions with confidence
Please do not hesitate to contact me if you have any questions at William . chen @ mainri.ca
PySpark supports a variety of data sources, enabling seamless integration and processing of structured and semi-structured data from multiple formats. such as CSV, JSON, Parquet, and ORC, Database (JDBC), as well as more advanced formats like Avro and Delta Lake, Hive
By default, If you try to write directly to a file (e.g., name1.csv), it conflicts because Spark doesn’t generate a single file but a collection of part files in a directory.
PySpark writes data in parallel, which results in multiple part files rather than a single CSV file by default. However, you can consolidate the data into a single CSV file by performing a coalesce(1) or repartition(1) operation before writing, which reduces the number of partitions to one.
at this time, name1.csv in “dbfs:/FileStore/name1.csv” will treat as a directory, rather than a Filename. PySpark writes the single file with a random name like part-00000-<id>.csv
we need take additional step – “Rename the File to name1.csv“
# List all files in the directory
files = dbutils.fs.ls("dbfs:/FileStore/name1.csv")
# Filter for the part file
for file in files:
if file.name.startswith("part-"):
source_file = file.path # Full path to the part file
destination_file = "dbfs:/FileStore/name1.csv"
# Move and rename the file
dbutils.fs.mv(source_file, destination_file)
break
display(dbutils.fs.ls ( "dbfs:/FileStore/"))
Direct Write with Custom File Name
PySpark doesn’t natively allow specifying a custom file name directly while writing a file because it writes data in parallel using multiple partitions. However, you can achieve a custom file name with a workaround. Here’s how:
Steps:
Use coalesce(1) to combine all data into a single partition.
Save the file to a temporary location.
Rename the part file to the desired name.
# Combine all data into one partition
df.coalesce(1).write.format("csv") \
.option("header", "true") \
.mode("overwrite") \
.save("dbfs:/FileStore/temp_folder")
# Get the name of the part file
files = dbutils.fs.ls("dbfs:/FileStore/temp_folder")
for file in files:
if file.name.startswith("part-"):
part_file = file.path
break
# Move and rename the part file
dbutils.fs.mv(part_file, "dbfs:/FileStore/name1.csv")
# Remove the temporary folder
dbutils.fs.rm("dbfs:/FileStore/temp_folder", True)
sample data save at /tmp/output/people.parquet
df1=spark.read.parquet("/tmp/output/people.parquet")
+---------+----------+--------+-----+------+------+
|firstname|middlename|lastname| dob|gender|salary|
+---------+----------+--------+-----+------+------+
| James | | Smith|36636| M| 3000|
| Michael | Rose| |40288| M| 4000|
| Robert | |Williams|42114| M| 4000|
| Maria | Anne| Jones|39192| F| 4000|
| Jen| Mary| Brown| | F| -1|
+---------+----------+--------+-----+------+------+
read a parquet is the same as reading from csv, nothing special.
write to a parquet
append: appends the data from the DataFrame to the existing file, if the Destination files already exist. In Case the Destination files do not exists, it will create a new parquet file in the specified location.
overwrite: This mode overwrites the destination Parquet file with the data from the DataFrame. If the file does not exist, it creates a new Parquet file.
ignore: If the destination Parquet file already exists, this mode does nothing and does not write the DataFrame to the file. If the file does not exist, it creates a new Parquet file.
pay attention on “.option(“multiline”,”True”)“. since my json file is multiple lines (look at above sample data), if reading without this option, it can still run load. But the dataframe will not work. Once you show, you will get this error
AnalysisException: Since Spark 2.3, the queries from raw JSON/CSV files are disallowed when the referenced columns only include the internal corrupt record column (named _corrupt_record by default).
Reading from Multiline JSON (JSON Array) File
[{
"RecordNumber": 2,
"Zipcode": 704,
"ZipCodeType": "STANDARD",
"City": "PASEO COSTA DEL SUR",
"State": "PR"
},
{
"RecordNumber": 10,
"Zipcode": 709,
"ZipCodeType": "STANDARD",
"City": "BDA SAN LUIS",
"State": "PR"
}]
df_jsonarray_simple = spark.read\
.format("json")\
.option("multiline", "true")\
.load("dbfs:/FileStore/jsonArrary.json")
df_jsonarray_simple.show()
+-------------------+------------+-----+-----------+-------+
| City|RecordNumber|State|ZipCodeType|Zipcode|
+-------------------+------------+-----+-----------+-------+
|PASEO COSTA DEL SUR| 2| PR| STANDARD| 704|
| BDA SAN LUIS| 10| PR| STANDARD| 709|
+-------------------+------------+-----+-----------+-------+
read complex json
df_complexjson=spark.read\
.option("multiline","true")\
.json("dbfs:/FileStore/jsonArrary2.json")
df_complexjson.select("id","type","name","ppu","batters","topping").show(truncate=False, vertical=True)
-RECORD 0--------------------------------------------------------------------------------------------------------------------------------------------
id | 0001
type | donut
name | Cake
ppu | 0.55
batters | {[{1001, Regular}, {1002, Chocolate}, {1003, Blueberry}, {1004, Devil's Food}]}
topping | [{5001, None}, {5002, Glazed}, {5005, Sugar}, {5007, Powdered Sugar}, {5006, Chocolate with Sprinkles}, {5003, Chocolate}, {5004, Maple}]
-RECORD 1--------------------------------------------------------------------------------------------------------------------------------------------
id | 0002
type | donut
name | Raised
ppu | 0.55
batters | {[{1001, Regular}]}
topping | [{5001, None}, {5002, Glazed}, {5005, Sugar}, {5003, Chocolate}, {5004, Maple}]
-RECORD 2--------------------------------------------------------------------------------------------------------------------------------------------
id | 0003
type | donut
name | Old Fashioned
ppu | 0.55
batters | {[{1001, Regular}, {1002, Chocolate}]}
topping | [{5001, None}, {5002, Glazed}, {5003, Chocolate}, {5004, Maple}]
spark.sql("CREATE OR REPLACE TEMPORARY VIEW zipcode USING json OPTIONS" +
" (path 'resources/zipcodes.json')")
spark.sql("select * from zipcode").show()
Write to JSON
Options
path: Specifies the path where the JSON files will be saved.
mode: Specifies the behavior when writing to an existing directory.
compression: Specifies the compression codec to use when writing the JSON files (e.g., “gzip”, “snappy”). df2.write . option(“compression”, “gzip”)
dateFormat: Specifies the format for date and timestamp columns. df.write . option(“dateFormat”, “yyyy-MM-dd”)
timestampFormat: Specifies the format for timestamp columns. df.write . option(“timestampFormat“, “yyyy-MM-dd’T’HH:mm:ss.SSSXXX”)
lineSep: Specifies the character sequence to use as a line separator between JSON objects. \n (Unix/Linux newline); \r\n (Windows newline) df . write . option(“lineSep”, “\r\n”)
encoding: Specifies the character encoding to use when writing the JSON files. UTF-8, UTF-16, ISO-8859-1 (Latin-1), Other Java-supported encodings. df . write . option(“encoding”, “UTF-8”)
Append: Appends the data to the existing data in the target location. If the target location does not exist, it creates a new one.
Overwrite: Overwrites the data in the target location if it already exists. If the target location does not exist, it creates a new one.
Ignore: Ignores the operation and does nothing if the target location already exists. If the target location does not exist, it creates a new one.
Error or ErrorIfExists: Throws an error and fails the operation if the target location already exists. This is the default behavior if no saving mode is specified.
# Write with savemode example
df2.write.mode('Overwrite').json("/tmp/spark_output/zipcodes.json")
In the above example, it reads the entire table into PySpark DataFrame. Sometimes you may not be required to select the entire table, so to select the specific columns, specify the query you wanted to select with dbtable option.
Append: mode("append") to append the rows to the existing SQL Server table.
# we have define variables, here is show again server_name = “mainri-sqldb.database.windows.net” port=1433 username=”my login name” password=”my login password” database_name=”mainri-sqldb” table_name=”dep” jdbc_url = f”jdbc:sqlserver://{server_name}:{port};databaseName={database_name}”
The mode("overwrite") drops the table if already exists by default and re-creates a new one without indexes. Use option(“truncate”,”true”) to retain the index.
PySpark jdbc() method with the option numPartitions you can read the database table in parallel. This option is used with both reading and writing.
The maximum number of partitions that can be used for parallelism in table reading and writing. This also determines the maximum number of concurrent JDBC connections. If the number of partitions to write exceeds this limit, we decrease it to this limit by calling coalesce(numPartitions) before writing.
# Select columns with where clause
df = spark.read \
.format("jdbc") \
.option("driver","com.mysql.cj.jdbc.Driver") \
.option("url", "jdbc:mysql://localhost:3306/emp") \
.option("query","select id,age from employee where gender='M'") \
.option("numPartitions",5) \
.option("user", "root") \
.option("password", "root") \
.load()
Using fetchsize with numPartitions to Read
The fetchsizeis another option which is used to specify how many rows to fetch at a time, by default it is set to 10. The JDBC fetch size determines how many rows to retrieve per round trip which helps the performance of JDBC drivers. Do not set this to very large number as you might see issues.
# Create temporary view
sampleDF.createOrReplaceTempView("sampleView")
# Create a Database CT
spark.sql("CREATE DATABASE IF NOT EXISTS ct")
# Create a Table naming as sampleTable under CT database.
spark.sql("CREATE TABLE ct.sampleTable (id Int, name String, age Int, gender String)")
# Insert into sampleTable using the sampleView.
spark.sql("INSERT INTO TABLE ct.sampleTable SELECT * FROM sampleView")
# Lets view the data in the table
spark.sql("SELECT * FROM ct.sampleTable").show()
Please do not hesitate to contact me if you have any questions at William . chen @ mainri.ca
PySpark DataFrame is a distributed collection of rows, similar to a table in a relational database or a DataFrame in Python’s pandas library. It provides powerful tools for querying, transforming, and analyzing large-scale structured and semi-structured data.
PySpark DataFrame provides a method toPandas() to convert it to Python Pandas DataFrame. toPandas() results in the collection of all records in the PySpark DataFrame to the driver program and should be done only on a small subset of the data.
key different between distinct() and dropDuplicates()
distinct() considers all columns when identifying duplicates, while dropDuplicates() allowing you to specify a subset of columns to determine uniqueness.
distinct() function treats NULL values as equal, so if there are multiple rows with NULL values in all columns, only one of them will be retained after applying distinct().
groupBy ( ), Similar to SQL GROUP BY clause, transformation that is used to group rows that have the same values in specified columns into summary rows
Above example, my DataFrame has 100 records and I wanted to get 6% sample records which are 6 but the sample() function returned 7 records. This proves the sample function doesn’t return the exact fraction specified.
To get consistent same random sampling uses the same slice value for every run. Change slice value to get different results.
print(df.sample(0.1,123).collect())
//Output: 36,37,41,43,56,66,69,75,83
print(df.sample(0.1,123).collect())
//Output: 36,37,41,43,56,66,69,75,83
print(df.sample(0.1,456).collect())
//Output: 19,21,42,48,49,50,75,80
df.show()
+-----+--------------------+
|Seqno| Quote|
+-----+--------------------+
| 1|Be the change tha...|
| 2|Everyone thinks o...|
| 3|The purpose of ou...|
| 4| Be cool.|
+-----+--------------------+
df.show(truncate=False)
df.show(2,truncate=25)
# Display DataFrame rows & columns vertically
df.show(n=3,truncate=25,vertical=True)
-RECORD 0--------------------------
Seqno | 1
Quote | Be the change that you...
-RECORD 1--------------------------
Seqno | 2
Quote | Everyone thinks of cha...
-RECORD 2--------------------------
Seqno | 3
Quote | The purpose of our liv...
only showing top 3 rows
StructType & StructField
StructType
Defines the structure of the DataFrame. StructType represents a schema, which is a collection of StructField objects. A StructType is essentially a list of fields, each with a name and data type, defining the structure of the DataFrame. It allows for the creation of nested structures and complex data types.
StructField
StructField – Defines the metadata of the DataFrame column. It represents a field in the schema, containing metadata such as the name, data type, and nullable status of the field. Each StructField object defines a single column in the DataFrame, specifying its name and the type of data it holds.
PySpark provides a comprehensive library of built-in functions for performing complex transformations, aggregations, and data manipulations on DataFrames. These functions are categorized into different types based on their use cases.
timediff(column1, column2) Calculates the difference between two
Calculates the difference between two
trunc ( )
trunc(column, format) truncate month/year, set to first of day in month/year. e.g. 2024-10-08, truncate month –> 2024-10-01; truncate year –> 2024-01-01
interval Used for advanced time calculations (not directly available but works with PySpark SQL).
Extracting Components from a Datetime
year(column): Extracts the year.
quarter(column): Returns the quarter as an integer from a given date or timestamp.
dayofyear(column): Extracts the day of the year from a given date or timestamp.
dayofmonth(column): Extracts the day of the month.
dayofweek(column): Returns the day of the week (1 = Sunday, 7 = Saturday).
weekofyear(column): Returns the week number of the year.
last_day(column): Return the last day of the month for a given date or timestamp column.The result is a date column where each date corresponds to the last day of the month for the original dates in the specified column.
btrim(str[, trim]) Trim characters at the beginning and end of the string ‘str’ are removed.
trim (): Removes only whitespace from the beginning and end of a string. when you only need to clean up whitespace from strings.
btrim(str[, trim]): Removes all specified leading and trailing characters from a string. when you need to remove specific characters (e.g., punctuation, symbols).
PySpark’s Window Ranking functions, like row_number(), rank(), and dense_rank(), assign sequential numbers to DataFrame rows based on specified criteria within defined partitions. These functions enable sorting and ranking operations, identifying row positions in partitions based on specific orderings.
row_number() assigns unique sequential numbers,
rank() provides the ranking with gaps,
dense_rank() offers ranking without gaps.
row_number ()
row_number() window function gives the sequential row number starting from 1 to the result of each window partition.
The explode() function in PySpark is used to transform an array or map column into multiple rows. Each element of the array or each key-value pair in the map becomes a separate row.
from pyspark.sql.functions import explode explode(col)
col: The name of the column or an expression containing an array or map to be exploded.
Return a new row for each element in the array or each key-value pair in the map.
schema_of_json ( ) function in PySpark is used to infer the schema of a JSON string column or JSON string literal. It is particularly useful when you want to work with complex JSON data and need to define its schema for operations like parsing or transformation. Return a string representation of the schema in the DataType JSON format.
from pyspark.sql.functions import schema_of_json, col
# Sample DataFrame with JSON strings
data = [("1", '{"name": "Alice", "age": 30}'),
("2", '{"name": "Bob", "age": 25}')]
columns = ["id", "json_data"]
df = spark.createDataFrame(data, columns)
# Infer schema from JSON column
schema = df.select(schema_of_json(col("json_data"))).first()[0]
struct<name:string,age:int,skills:array<string>>
PySpark expr() is a SQL function to execute SQL-like expressions and to use an existing DataFrame column value as an expression argument to Pyspark built-in functions.
expr ()
#Using CASE WHEN similar to SQL.
df2=df.withColumn("gender", \
expr("CASE WHEN gender = 'M' THEN 'Male' " +
"WHEN gender = 'F' THEN 'Female' ELSE 'unknown' END") \
)
+-------+-------+
| name| gender|
+-------+-------+
| James| Male|
|Michael| Female|
| Jen|unknown|
+-------+-------+
#Add Month value from another column
df.select(df.date,df.increment,
expr("add_months(date,increment)")
.alias("inc_date")).show()
+----------+---------+----------+
| date|increment| inc_date|
+----------+---------+----------+
|2019-01-23| 1|2019-02-23|
|2019-06-24| 2|2019-08-24|
|2019-09-20| 3|2019-12-20|
+----------+---------+----------+
PySpark SQL functions lit() and typedLit() are used to add a new column to DataFrame by assigning a literal or constant value. Both these functions return Column type as return type. typedLit() provides a way to be explicit about the data type of the constant value being added to a DataFrame,
PySpark SQL functions lit() and typedLit() are used to add a new column to DataFrame by assigning a literal or constant value. typedLit() provides a way to be explicit about the data type of the constant value being added to a DataFrame
Difference between lit() and typedLit() is that the typedLit() function can handle collection types e.g.: Array, Dictionary(map), etc. Below is an example usage of typedLit()
Stack ( )
Stack ( ) function is used to transform columns into rows. It’s particularly useful when you have a wide DataFrame (with many columns) and want to “unpivot” or “melt” it into a longer format.
Syntax
stack(n: Int, exprs: String*): Column
Parameters
n: The number of rows to create per input row. Each set of n expressions in exprs corresponds to a new row.
exprs: A sequence of column-value pairs, typically specified as strings in the format "column_name, column_value".
The StructType and StructField classes in PySpark are used to specify the custom schema to the DataFrame and create complex columns like nested struct, array, and map columns. StructType is a collection of StructField objects that define column name, column data type, boolean to specify if the field can be nullable or not, and metadata.
In Databricks and PySpark, DeltaTables and DataFrames both handle structured data but differ in functionality and use cases. Here’s a detailed comparison:
Definitions
DeltaTable
A DeltaTable is a storage format based on Apache Parquet, with support for ACID transactions, versioning, schema enforcement, and advanced file operations. It is managed by the Delta Lake protocol, offering features like time travel, upserts, and deletion.
DataFrame
A DataFrame is a distributed collection of data organized into named columns. It is an abstraction for structured and semi-structured data in Spark. It is a purely in-memory abstraction and does not directly manage storage or transactions.
Features
Feature
DeltaTable
DataFrame
Persistence
Stores data on disk in a managed format.
Primarily in-memory abstraction (ephemeral).
Schema Enforcement
Enforces schema when writing/updating.
No schema enforcement unless explicitly specified.
ACID Transactions
Supports atomic writes, updates, and deletes.
Not transactional; changes require reprocessing.
Versioning
Maintains historical versions (time travel).
No versioning; a snapshot of data.
Upserts and Deletes
Supports MERGE, UPDATE, and DELETE.
Does not directly support these operations.
Performance
Optimized for storage (Z-order indexing, compaction).
Optimized for in-memory transformations.
Time Travel
Query historical data using snapshots.
No time travel support.
Indexing
Supports indexing (Z-order, data skipping).
No indexing capabilities.
Use Cases
DeltaTable
Ideal for persistent storage with advanced capabilities:
Data lakes or lakehouses.
ACID-compliant operations (e.g., MERGE, DELETE).
Time travel to access historical data.
Optimizing storage with compaction or Z-ordering.
Schema evolution during write operations.
DataFrame
Best for in-memory processing and transformations:
Ad-hoc queries and ETL pipelines.
Working with data from various sources (files, databases, APIs).
Temporary transformations before persisting into Delta or other formats.
Common APIs
DeltaTable
Load Delta table from a path:
from delta.tables import DeltaTable
delta_table = DeltaTable.forPath(spark, "/path/to/delta/table")