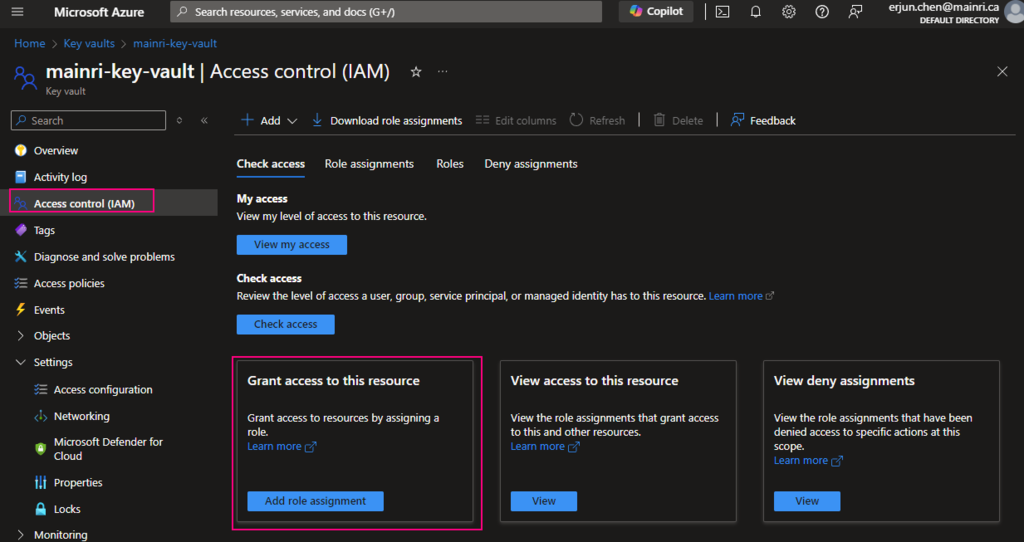
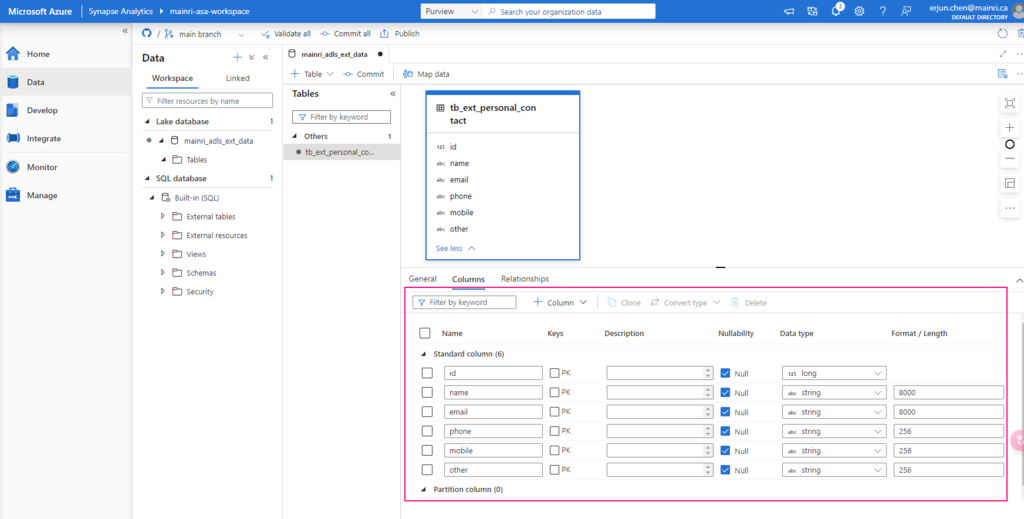
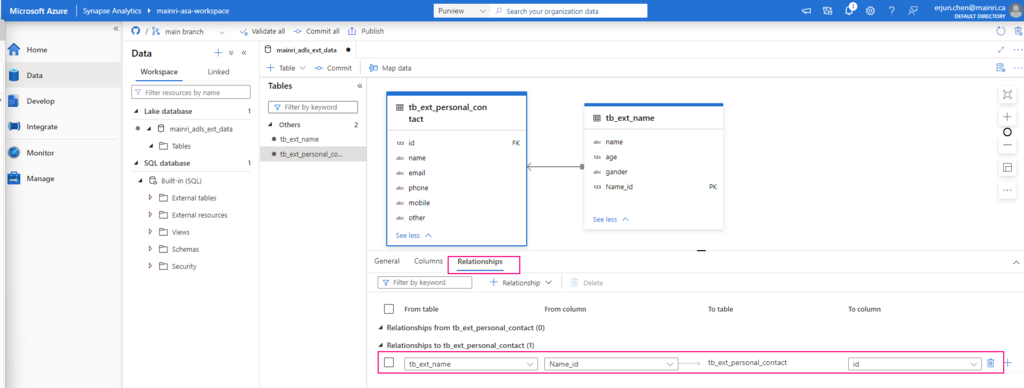
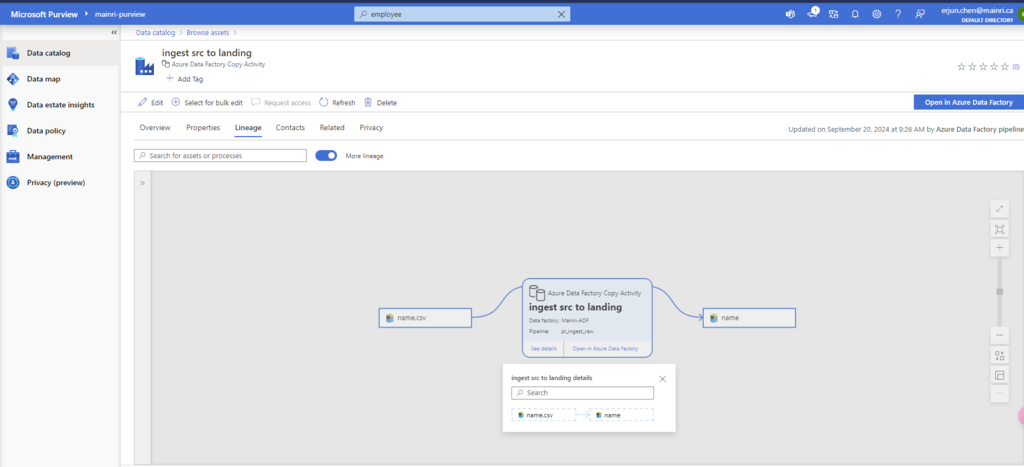
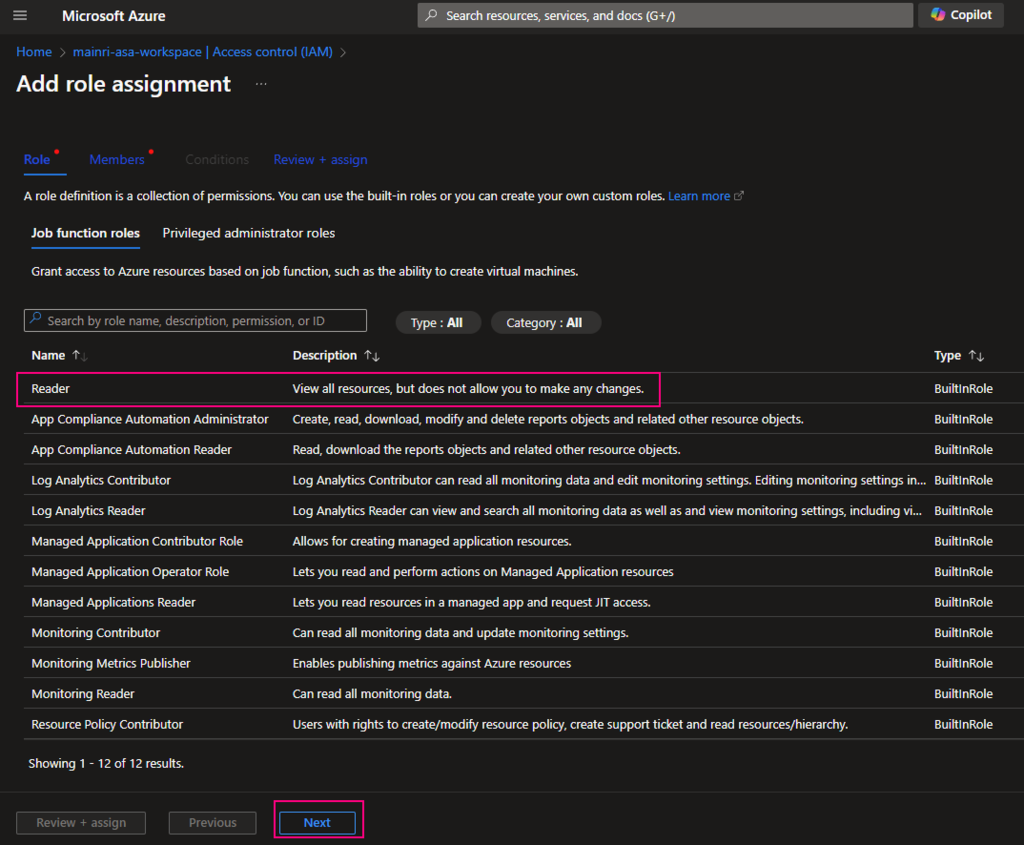
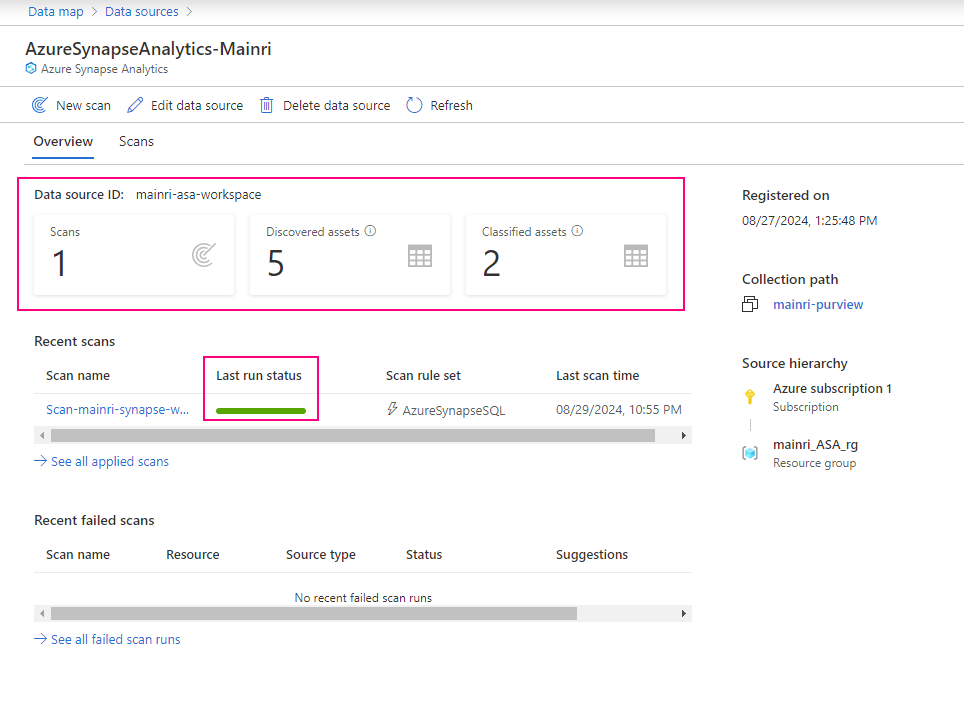
The Get Metadata activity in Azure Data Factory (ADF) is used to retrieve metadata about a file, folder, or database. This activity is particularly useful when you need to dynamically determine properties like file name, size, structure, or existence and use them in subsequent pipeline activities.
We can specify the following metadata types in the Get Metadata activity field list to retrieve the corresponding information:
| Metadata type | Description |
|---|---|
| itemName | Name of the file or folder. |
| itemType | Type of the file or folder. Returned value is File or Folder. |
| size | Size of the file, in bytes. Applicable only to files. |
| created | Created datetime of the file or folder. |
| lastModified | Last modified datetime of the file or folder. |
| childItems | List of subfolders and files in the given folder. Applicable only to folders. Returned value is a list of the name and type of each child item. |
| contentMD5 | MD5 of the file. Applicable only to files. |
| structure | Data structure of the file or relational database table. Returned value is a list of column names and column types. |
| columnCount | Number of columns in the file or relational table. |
| exists | Whether a file, folder, or table exists. If exists is specified in the Get Metadata field list, the activity won’t fail even if the file, folder, or table doesn’t exist. Instead, exists: false is returned in the output. |
- Metadata
structureandcolumnCountare not supported when getting metadata from Binary, JSON, or XML files. - Wildcard filter on folders/files is not supported for Get Metadata activity.
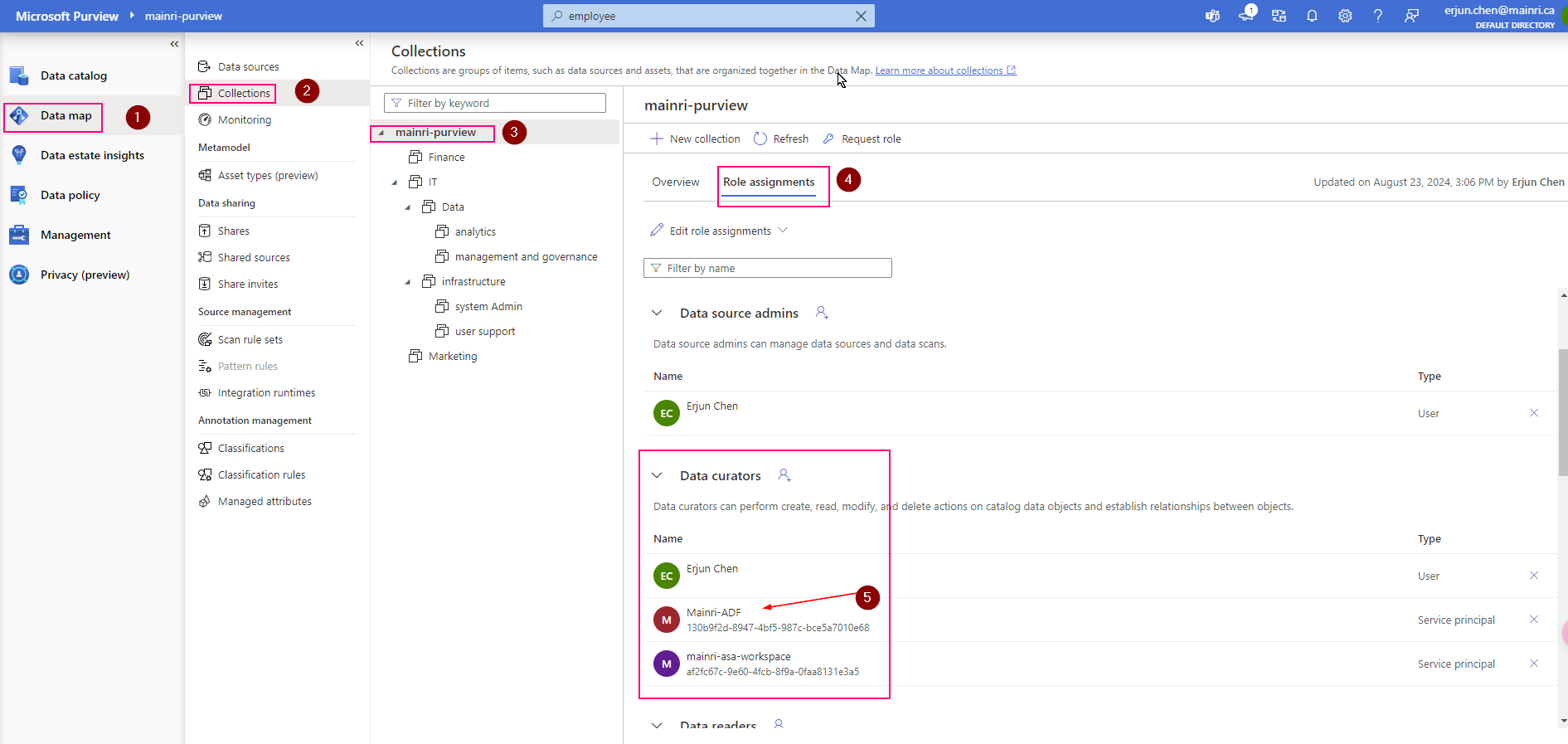
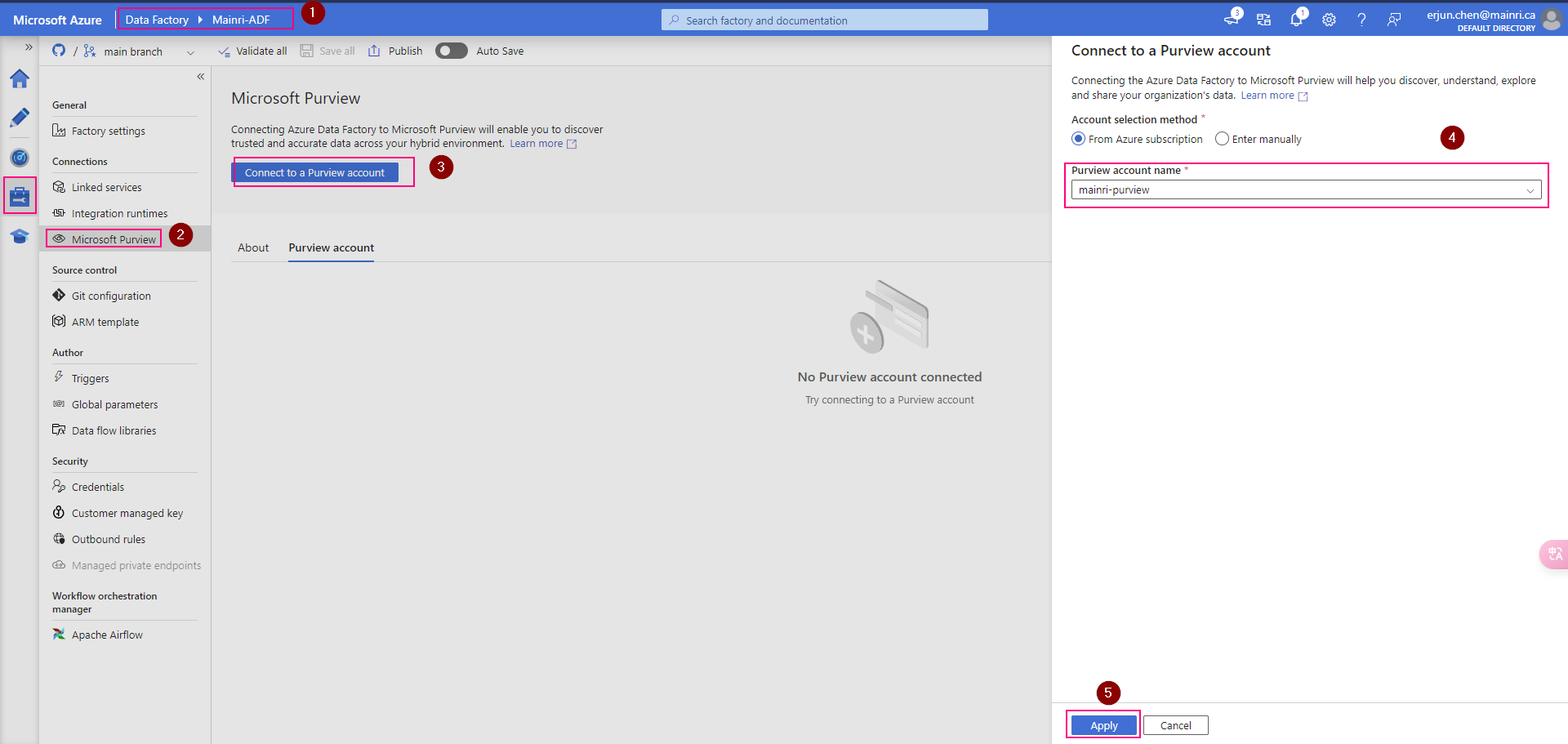
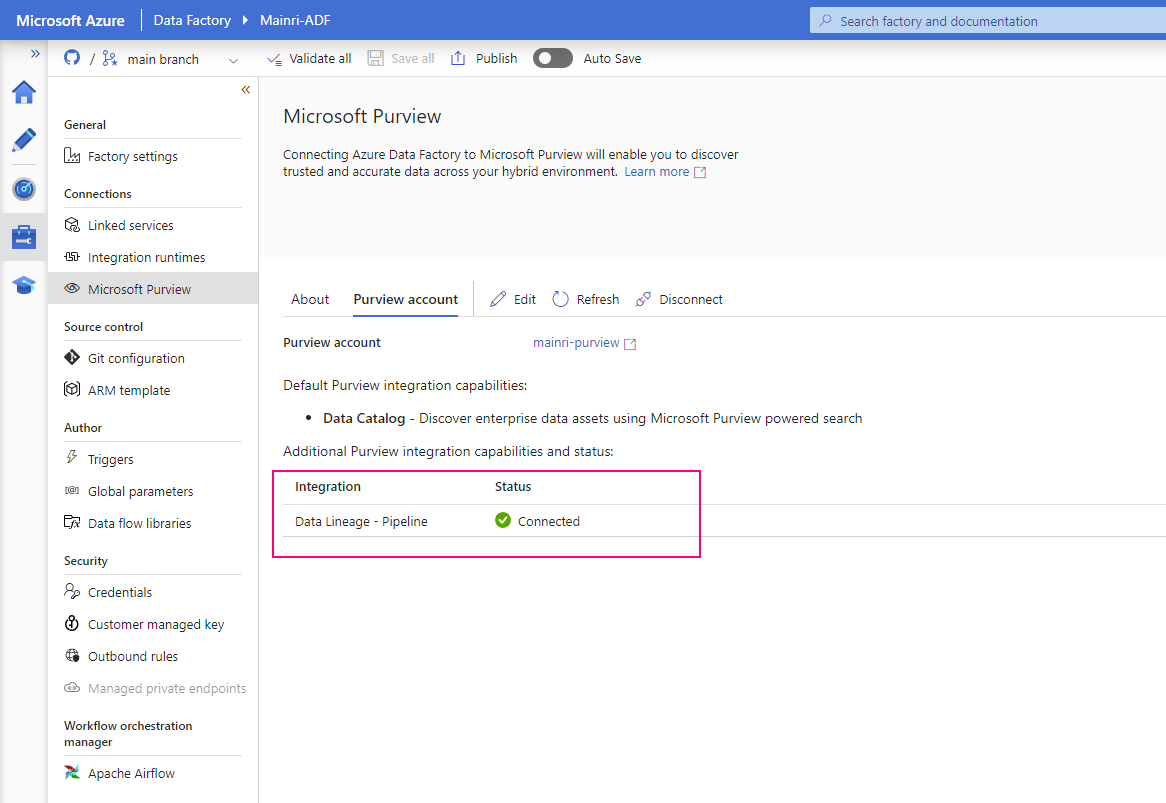
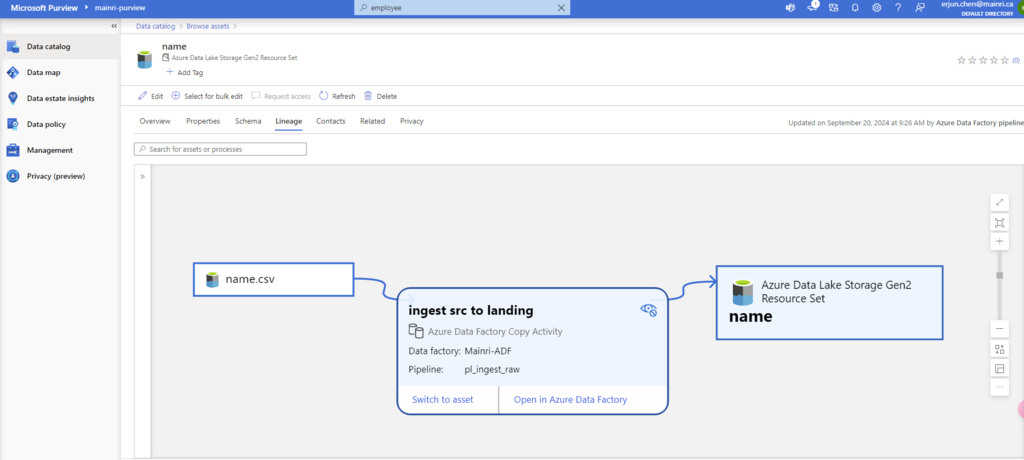
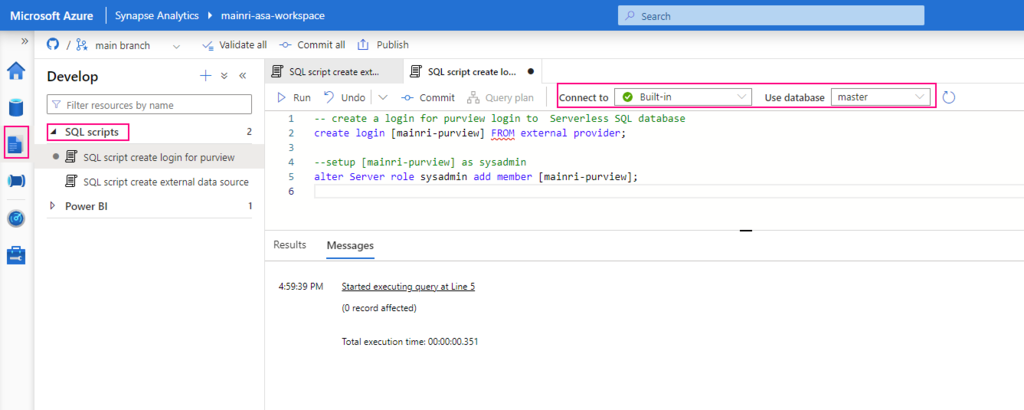
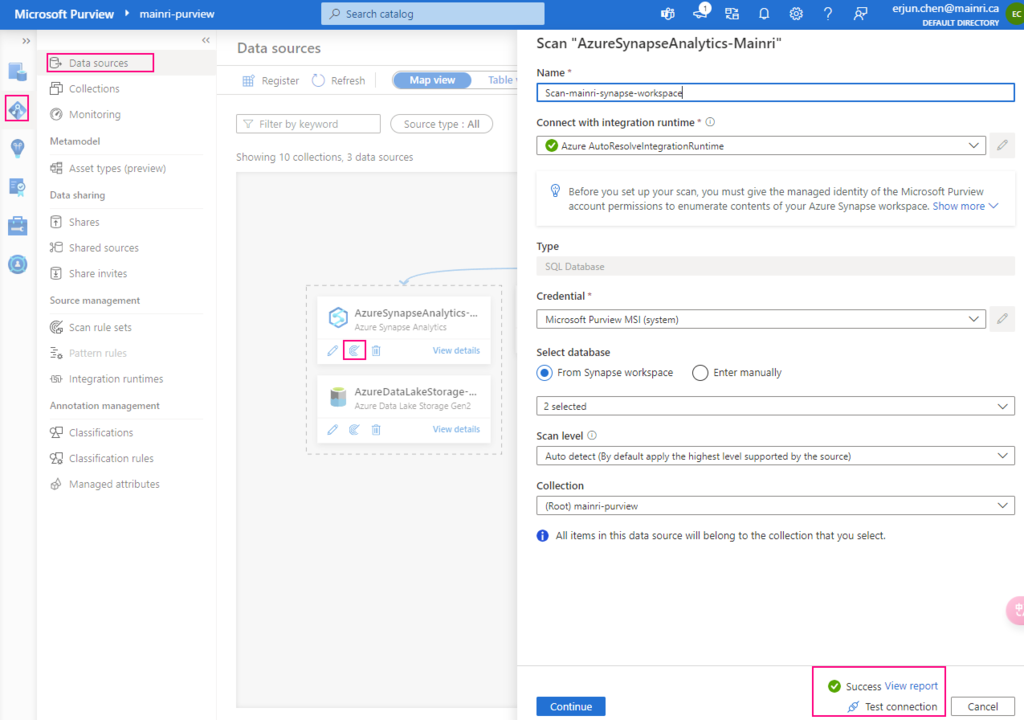
Get Metadata activity on the canvas if it is not already selected, and its Settings tab, to edit its details.

Sample setting and output
Get a folder’s metadata
Setting
select a dataset or create a new
for folder’s metadata, in the Field list of setting, all we can select are:
- Child items
- Exists
- Item name
- Item type
- Last modified


folder’s metadata output
{
"exists": true,
"itemName": "mainri-asa-file-system",
"itemType": "Folder",
"lastModified": "2023-10-12T20:17:34Z",
"childItems": [
{
"name": "out",
"type": "Folder"
},
{
"name": "raw",
"type": "Folder"
}
],
"effectiveIntegrationRuntime": "AutoResolveIntegrationRuntime (East US 2)",
"executionDuration": 1,
"durationInQueue": {
"integrationRuntimeQueue": 0
},
"billingReference": {
"activityType": "PipelineActivity",
"billableDuration": [
{
"meterType": "AzureIR",
"duration": 0.016666666666666666,
"unit": "Hours"
}
]
}
}Get a csv file’s metadata
for a file’s metadata, no matter what kind of file formats, all we can select are:
- Column count
- Content MD5
- Exists
- Item name
- Item type
- Last modified
- Size
- Structure


files’s metadata output
{
"contentMD5": "uRtaObpmyT2DUusCW7jcAQ==",
"exists": true,
"itemName": "name.csv",
"itemType": "File",
"lastModified": "2024-07-18T17:45:04Z",
"size": 109,
"structure": [
{
"name": "name",
"type": "String"
},
{
"name": "age",
"type": "String"
},
{
"name": "gander",
"type": "String"
}
],
"columnCount": 3,
"effectiveIntegrationRuntime": "AutoResolveIntegrationRuntime (East US 2)",
"executionDuration": 3,
"durationInQueue": {
"integrationRuntimeQueue": 0
},
"billingReference": {
"activityType": "PipelineActivity",
"billableDuration": [
{
"meterType": "AzureIR",
"duration": 0.016666666666666666,
"unit": "Hours"
}
]
}
}Get a Parquet file’s metadata
parquet file’s metadata output
{
"contentMD5": null,
"exists": true,
"itemName": "name_parquet.parquet",
"itemType": "File",
"lastModified": "2024-12-25T23:07:13Z",
"size": 753,
"structure": [
{
"name": "name",
"type": "String"
},
{
"name": "age",
"type": "String"
},
{
"name": "gander",
"type": "String"
}
],
"columnCount": 3,
"effectiveIntegrationRuntime": "AutoResolveIntegrationRuntime (East US 2)",
"executionDuration": 1,
"durationInQueue": {
"integrationRuntimeQueue": 0
},
"billingReference": {
"activityType": "PipelineActivity",
"billableDuration": [
{
"meterType": "AzureIR",
"duration": 0.016666666666666666,
"unit": "Hours"
}
]
}
}Get a database table metadata
for a database table’s metadata, all we can select are:
- Column count
- Exists
- Structure


database table’s metadata output
{
"exists": true,
"structure": [
{
"physicalName": "empid",
"type": "Int32",
"logicalType": "Int32",
"name": "empid",
"physicalType": "int",
"precision": 10,
"scale": 255,
"DotNetType": "System.Int32, mscorlib, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089"
},
{
"physicalName": "name",
"type": "String",
"logicalType": "String",
"name": "name",
"physicalType": "varchar",
"precision": 255,
"scale": 255,
"DotNetType": "System.String, mscorlib, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089"
},
{
"physicalName": "Age",
"type": "Int32",
"logicalType": "Int32",
"name": "Age",
"physicalType": "int",
"precision": 10,
"scale": 255,
"DotNetType": "System.Int32, mscorlib, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089"
},
{
"physicalName": "Gender",
"type": "String",
"logicalType": "String",
"name": "Gender",
"physicalType": "varchar",
"precision": 255,
"scale": 255,
"DotNetType": "System.String, mscorlib, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089"
},
{
"physicalName": "depid",
"type": "Int32",
"logicalType": "Int32",
"name": "depid",
"physicalType": "int",
"precision": 10,
"scale": 255,
"DotNetType": "System.Int32, mscorlib, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089"
}
],
"columnCount": 5,
"effectiveIntegrationRuntime": "AutoResolveIntegrationRuntime (Canada Central)",
"executionDuration": 40,
"durationInQueue": {
"integrationRuntimeQueue": 0
},
"billingReference": {
"activityType": "PipelineActivity",
"billableDuration": [
{
"meterType": "AzureIR",
"duration": 0.016666666666666666,
"unit": "Hours"
}
]
}
}Conclusion
The Get Metadata activity in Azure Data Factory (ADF) is a versatile tool for building dynamic, efficient, and robust pipelines. It plays a critical role in handling real-time scenarios by providing essential information about data sources, enabling smarter workflows.
Use Case Scenarios Recap
- File Verification: Check if a file exists or meets specific conditions (e.g., size or modification date) before processing.
- Iterative Processing: Use folder metadata to dynamically loop through files using the ForEach activity.
- Schema Validation: Fetch table or file schema for use in dynamic transformations or validations.
- Dynamic Path Handling: Adjust source/destination paths based on retrieved metadata properties.
Please do not hesitate to contact me if you have any questions at William . chen @ mainri.ca (remove all space from the email account 😊)
Appendix:
MS: Get Metadata activity in Azure Data Factory or Azure Synapse Analytics