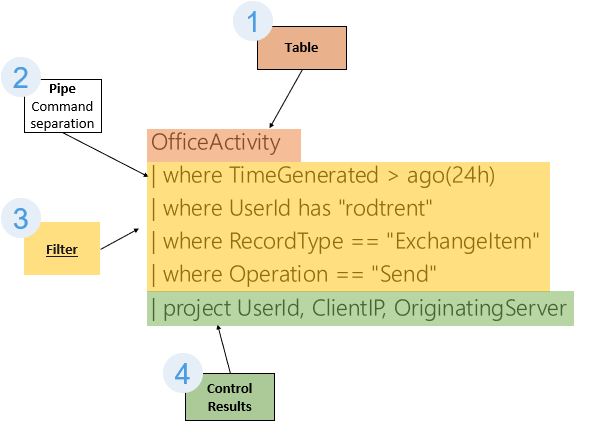
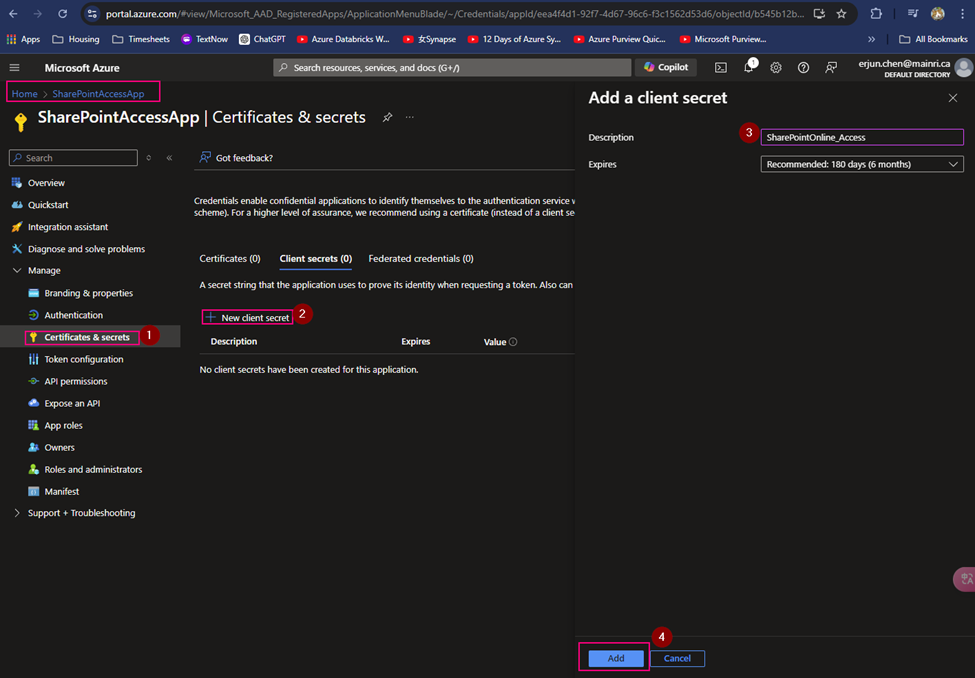
To those whom are familiar SQL query syntax, but new to KQL. The following table shows sample queries in SQL and their KQL equivalents.
| Category | SQL Query | Kusto Query | Learn more |
|---|---|---|---|
| Select data from table | SELECT * FROM dependencies | dependencies | Tabular expression statements |
| — | SELECT name, resultCode FROM dependencies | dependencies | project name, resultCode | project |
| — | SELECT TOP 100 * FROM dependencies | dependencies | take 100 | take |
| Null evaluation | SELECT * FROM dependenciesWHERE resultCode IS NOT NULL | dependencies| where isnotnull(resultCode) | isnotnull() |
| Comparison operators (date) | SELECT * FROM dependenciesWHERE timestamp > getdate()-1 | dependencies| where timestamp > ago(1d) | ago() |
| — | SELECT * FROM dependenciesWHERE timestamp BETWEEN ... AND ... | dependencies| where timestamp between (datetime(2016-10-01) .. datetime(2016-11-01)) | between |
| Comparison operators (string) | SELECT * FROM dependenciesWHERE type = "Azure blob" | dependencies| where type == "Azure blob" | Logical operators |
| — | -- substringSELECT * FROM dependenciesWHERE type like "%blob%" | // substringdependencies| where type has "blob" | has |
| — | -- wildcardSELECT * FROM dependenciesWHERE type like "Azure%" | // wildcarddependencies| where type startswith "Azure"// ordependencies| where type matches regex "^Azure.*" | startswithmatches regex |
| Comparison (boolean) | SELECT * FROM dependenciesWHERE !(success) | dependencies| where success == False | Logical operators |
| Grouping, Aggregation | SELECT name, AVG(duration) FROM dependenciesGROUP BY name | dependencies| summarize avg(duration) by name | summarize avg() |
| Distinct | SELECT DISTINCT name, type FROM dependencies | dependencies| summarize by name, type | summarize distinct |
| — | SELECT name, COUNT(DISTINCT type)FROM dependenciesGROUP BY name | dependencies| summarize by name, type | summarize count() by name// or approximate for large setsdependencies| summarize dcount(type) by name | count() dcount() |
| Column aliases, Extending | SELECT operationName as Name, AVG(duration) as AvgD FROM dependenciesGROUP BY name | dependencies| summarize AvgD = avg(duration) by Name=operationName | Alias statement |
| — | SELECT conference, CONCAT(sessionid, ' ' , session_title) AS session FROM ConferenceSessions | ConferenceSessions| extend session=strcat(sessionid, " ", session_title)| project conference, session | strcat() project |
| Ordering | SELECT name, timestamp FROM dependenciesORDER BY timestamp ASC | dependencies| project name, timestamp| sort by timestamp asc nulls last | sort |
| Top n by measure | SELECT TOP 100 name, COUNT(*) as Count FROM dependenciesGROUP BY nameORDER BY Count DESC | dependencies| summarize Count = count() by name| top 100 by Count desc | top |
| Union | SELECT * FROM dependenciesUNIONSELECT * FROM exceptions | union dependencies, exceptions | union |
| — | SELECT * FROM dependenciesWHERE timestamp > ...UNIONSELECT * FROM exceptionsWHERE timestamp > ... | dependencies| where timestamp > ago(1d)| union(exceptions| where timestamp > ago(1d)) | |
| Join | SELECT * FROM dependenciesLEFT OUTER JOIN exceptionsON dependencies.operation_Id = exceptions.operation_Id | dependencies| join kind = leftouter(exceptions)on $left.operation_Id == $right.operation_Id | join |
| Nested queries Sub-query | SELECT * FROM dependenciesWHERE resultCode ==(SELECT TOP 1 resultCode FROM dependenciesWHERE resultId = 7ORDER BY timestamp DESC) | dependencies| where resultCode == toscalar(dependencies| where resultId == 7| top 1 by timestamp desc| project resultCode) | toscalar |
| Having | SELECT COUNT(\*) FROM dependenciesGROUP BY nameHAVING COUNT(\*) > 3 | dependencies| summarize Count = count() by name| where Count > 3 | summarize where |