In Azure Data Factory (ADF) or Synapse, using Copy Activity with a File System as a source or sink is common when dealing with on-premises file systems, network file shares, or even cloud-based file storage systems. Here’s an overview of how it works, key considerations, and steps to set it up.
Key Components and setup with File System:
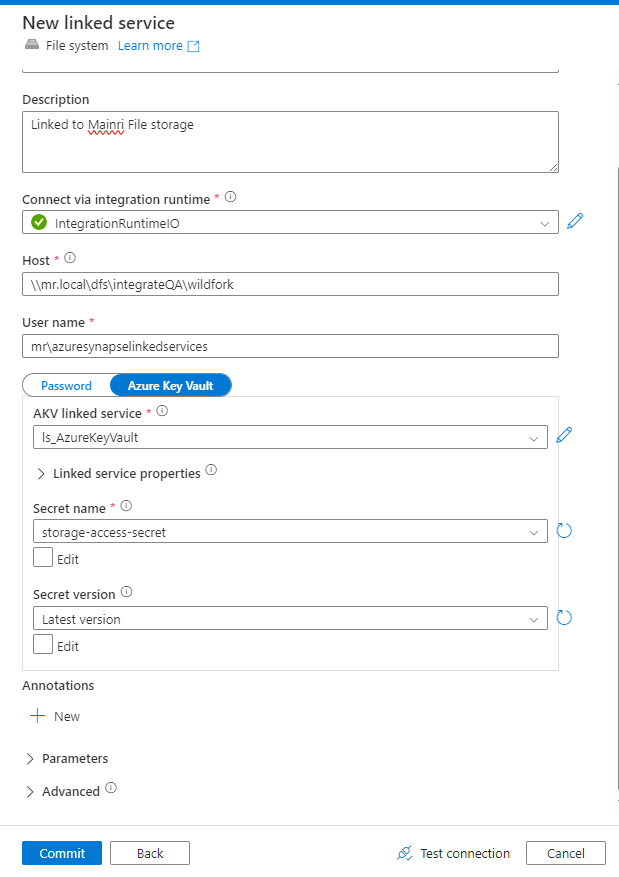
Create a File System Linked Service
Linked Service: For on-premises or network file systems, you typically need a Self-hosted Integration Runtime (SHIR).
Fill in the required fields:
Connection: Specify the file system type (e.g., network share or local path).
Authentication: Provide the appropriate credentials, such as username/password, or key-based authentication.
If the file system is on-premises, configure the Self-hosted Integration Runtime to access it.
Create File System Dataset
Go to Datasets in ADF and create a new dataset. Select File System as the data source.
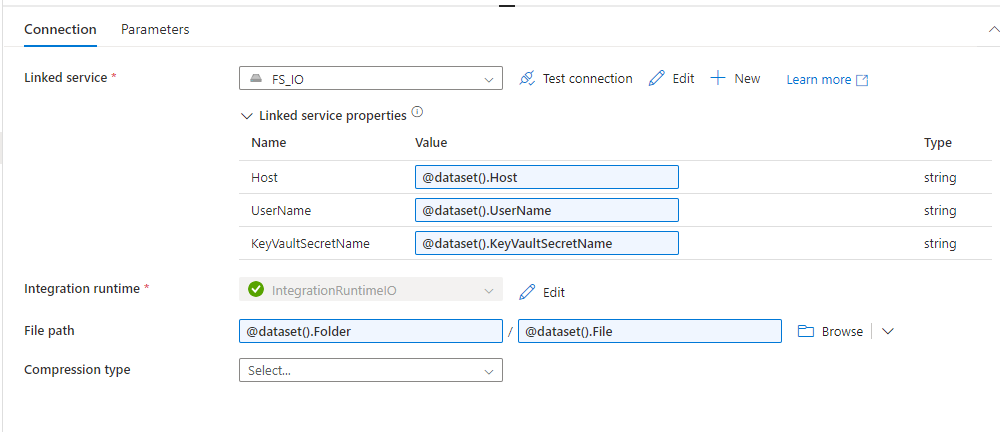
Configure the dataset to point to the correct file or folder:
Specify the File Path.
Define the file format (e.g., CSV, JSON, XML).
Set any schema information if required (for structured data like CSV).
Considerations:
Integration Runtime: For on-premises file systems, the Self-hosted Integration Runtime (SHIR) is essential to securely move data from private networks.
Performance: Data transfer speeds depend on network configurations (for on-prem) and ADF’s parallelism settings.
File Formats: Ensure proper handling of different file formats (e.g., CSV, JSON, Binary etc.) and schema mapping for structured files.
Security: Ensure credentials and network configurations are correctly set up, and consider encryption if dealing with sensitive data.
Common Errors:
Connection issues: If the SHIR is not correctly configured, or if there are issues with firewall or network settings, ADF may not be able to access the file system.
Permission issues: Ensure that the correct permissions are provided to access the file system (file share, SMB, FTP, etc.).
In Azure Data Factory (ADF) or Azure Synapse Analytics, when you create Linked Services, both “Databricks” and “Databricks Delta Lake” are available as options. Here’s the key difference:
Key Differences:
Databricks Linked Service is for connecting to the compute environment (jobs, notebooks) of Databricks.
Databricks Delta Lake Linked Service is for connecting directly to Delta Lake data storage (tables/files).
Here’s a side-by-side comparison between Databricks and Databricks Delta Lake Linked Services in Azure Data Factory (ADF):
Feature
Databricks Linked Service
Databricks Delta Lake Linked Service
Purpose
Connect to an Azure Databricks workspace to run jobs or notebooks.
Connect to Delta Lake tables within Azure Databricks.
Primary Use Case
Run notebooks, Python/Scala/Spark scripts, and perform data processing tasks on Databricks.
Read/write data from/to Delta Lake tables for data ingestion or extraction.
Connection Type
Connects to the compute environment of Databricks (notebooks, clusters, jobs).
Connects to data stored in Delta Lake format (structured data files).
Data Storage
Not focused on specific data formats; used for executing Databricks jobs.
Specifically used for interacting with Delta Lake tables (backed by Parquet files).
ACID Transactions
Does not inherently support ACID transactions (although Databricks jobs can handle them in notebooks).
Delta Lake supports ACID transactions (insert, update, delete) natively.
Common Activities
– Running Databricks notebooks. – Submitting Spark jobs. – Data transformation using PySpark, Scala, etc.
– Reading from or writing to Delta Lake. – Ingesting or querying large datasets with Delta Lake’s ACID support.
Input/Output
Input/output via Databricks notebooks, clusters, or jobs.
Input/output via Delta Lake tables/files (with versioning and schema enforcement).
Data Processing
Focus on data processing (ETL/ELT) using Databricks compute power.
Focus on data management within Delta Lake storage layer, including handling updates and deletes.
When to Use
– When you need to orchestrate and run Databricks jobs for data processing.
– When you need to read or write data specifically stored in Delta Lake. – When managing big data with ACID properties.
Integration in ADF Pipelines
Execute Databricks notebook activities or custom scripts in ADF pipelines.
Access Delta Lake as a data source/destination in ADF pipelines.
Supported Formats
Any format depending on the jobs or scripts running in Databricks.
Primarily deals with Delta Lake format (which is based on Parquet).
In Azure Data Factory (ADF), both the Copy Activity using wildcards (*.*) and the Get Metadata activity for retrieving a file list are designed to work with multiple files for copying or moving. However, they operate differently and are suited to different scenarios.
Copy Activity with Wildcard *.*
Purpose: Automatically copies multiple files from a source to a destination using wildcards.
Use Case: Used when you want to move, copy, or process multiple files in bulk that match a specific pattern (e.g., all .csv files or any file in a folder).
Wildcard Support: The wildcard characters (* for any characters, ? for a single character) help in defining a set of files to be copied. For example:
*.csv will copy all .csv files in the specified folder.
file*.json will copy all files starting with file and having a .json extension.
Bulk Copy: Enables copying multiple files without manually specifying each one.
Common Scenarios:
Copy all files from one folder to another, filtering based on extension or name pattern.
Copy files that were uploaded on a specific date, assuming the date is part of the file name.
Automatic File Handling: ADF will automatically copy all files matching the pattern in a single operation.
Key Benefit: Efficient for bulk file transfers with minimal configuration. You don’t need to explicitly get the file list; it uses wildcards to copy all matching files.
Example Scenario:
You want to copy all .csv files from a folder in Blob Storage to a Data Lake without manually listing them.
2. Get Metadata Activity (File List Retrieval)
Purpose: Retrieves a list of files in a folder, which you can then process individually or use for conditional logic.
Use Case: Used when you need to explicitly obtain the list of files in a folder to apply custom logic, processing each file separately (e.g., for-looping over them).
No Wildcard Support: The Get Metadata activity does not use wildcards directly. Instead, it returns all the files (or specific child items) in a folder. If filtering by name or type is required, additional logic is necessary (e.g., using expressions or filters in subsequent activities).
Custom Processing: After retrieving the file list, you can perform additional steps like looping over each file (with the ForEach activity) and copying or transforming them individually.
Common Scenarios:
Retrieve all files in a folder and process each one in a custom way (e.g., run different processing logic depending on the file name or type).
Check for specific files, log them, or conditionally process based on file properties (e.g., last modified time).
Flexible Logic: Since you get a list of files, you can apply advanced logic, conditions, or transformations for each file individually.
Key Benefit: Provides explicit control over how each file is processed, allowing dynamic processing and conditional handling of individual files.
Example Scenario:
You retrieve a list of files in a folder, loop over them, and process only files that were modified today or have a specific file name pattern.
Side-by-Side Comparison
Feature
Copy Activity (Wildcard *.*)
Get Metadata Activity (File List Retrieval)
Purpose
Copies multiple files matching a wildcard pattern.
Retrieves a list of files from a folder for custom processing.
Wildcard Support
Yes (*.*, *.csv, file?.json, etc.).
No, retrieves all items from the folder (no filtering by pattern).
File Selection
Automatically selects files based on the wildcard pattern.
Retrieves the entire list of files, then requires a filter for specific file selection.
Processing Style
Bulk copying based on file patterns.
Custom logic or per-file processing using the ForEach activity.
Use Case
Simple and fast copying of multiple files matching a pattern.
Used when you need more control over each file (e.g., looping, conditional processing).
File Count Handling
Automatically processes all matching files in one step.
Returns a list of all files in the folder, and each file can be processed individually.
Efficiency
Efficient for bulk file transfer, handles all matching files in one operation.
More complex as it requires looping through files for individual actions.
Post-Processing Logic
No looping required; processes files in bulk.
Requires a ForEach activity to iterate over the file list for individual processing.
Common Scenarios
– Copy all files with a .csv extension. – Move files with a specific prefix or suffix.
– Retrieve all files and apply custom logic for each one. – Check file properties (e.g., last modified date).
Control Over Individual Files
Limited, bulk operation for all files matching the pattern.
Full control over each file, allowing dynamic actions (e.g., conditional processing, transformations).
File Properties Access
No access to specific file properties during the copy operation.
Access to file properties like size, last modified date, etc., through metadata retrieval.
Execution Time
Fast for copying large sets of files matching a pattern.
Slower due to the need to process each file individually in a loop.
Use of Additional Activities
Often works independently without the need for further processing steps.
Typically used with ForEach, If Condition, or other control activities for custom logic.
Scenarios to Use
– Copying all files in a folder that match a certain extension (e.g., *.json). – Moving large numbers of files with minimal configuration.
– When you need to check file properties before processing. – For dynamic file processing (e.g., applying transformations based on file name or type).
When to Use Each:
Copy Activity with Wildcard:
Use when you want to copy multiple files in bulk and don’t need to handle each file separately.
Best for fast, simple file transfers based on file patterns.
Get Metadata Activity with File List:
Use when you need explicit control over each file or want to process files individually (e.g., with conditional logic).
Ideal when you need to loop through files, check properties, or conditionally process files.
Azure Key Vault safeguards encryption keys and secrets like certificates, connection strings, and passwords.
Key vaults define security boundaries for stored secrets. It allows you to securely store service or application credentials like passwords and access keys as secrets. All secrets in your key vault are encrypted with a software key. When you use Key Vault, you no longer need to store security information in your applications. Not having to store security information in applications eliminates the need to make this information part of the code.
What is a secret in Key Vault?
In Key Vault, a secret is a name-value pair of strings. Secret names must be 1-127 characters long, contain only alphanumeric characters and dashes, and must be unique within a vault. A secret value can be any UTF-8 string up to 25 KB in size.
Vault authentication and permissions
Developers usually only need Get and List permissions to a development-environment vault. Some engineers need full permissions to change and add secrets, when necessary.
For apps, often only Get permissions are required. Some apps might require List depending on the way the app is implemented. The app in this module’s exercise requires the List permission because of the technique it uses to read secrets from the vault.
In this article, we will focus on 2 sections, set up secrets in Key Vault and application retrieves secrets that ware saved in Key vault.
Create a Key Vault and store secrets
Creating a vault requires no initial configuration. You can start adding secrets immediately. After you have a vault, you can add and manage secrets from any Azure administrative interface, including the Azure portal, the Azure CLI, and Azure PowerShell. When you set up your application to use the vault, you need to assign the correct permissions to it
Create a Key Vault service
To create Azure Key Vault service, you can follow the steps.
From Azure Portal, search “key Vault”
click “key Vault”
Fill in all properties
Click review + create. That’s all. Quite simple, right?
Create secrets and save in Key Vault
There are two ways to create secret and save in Key vault.
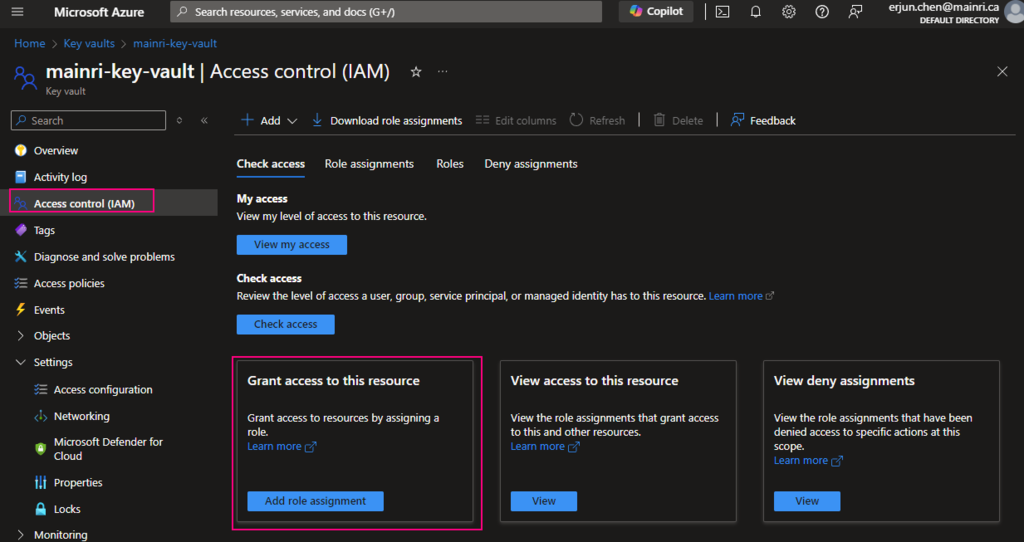
Access control, Identity and Access management (IAM)
Access Policies
Using Access Control (IAM) create a secret
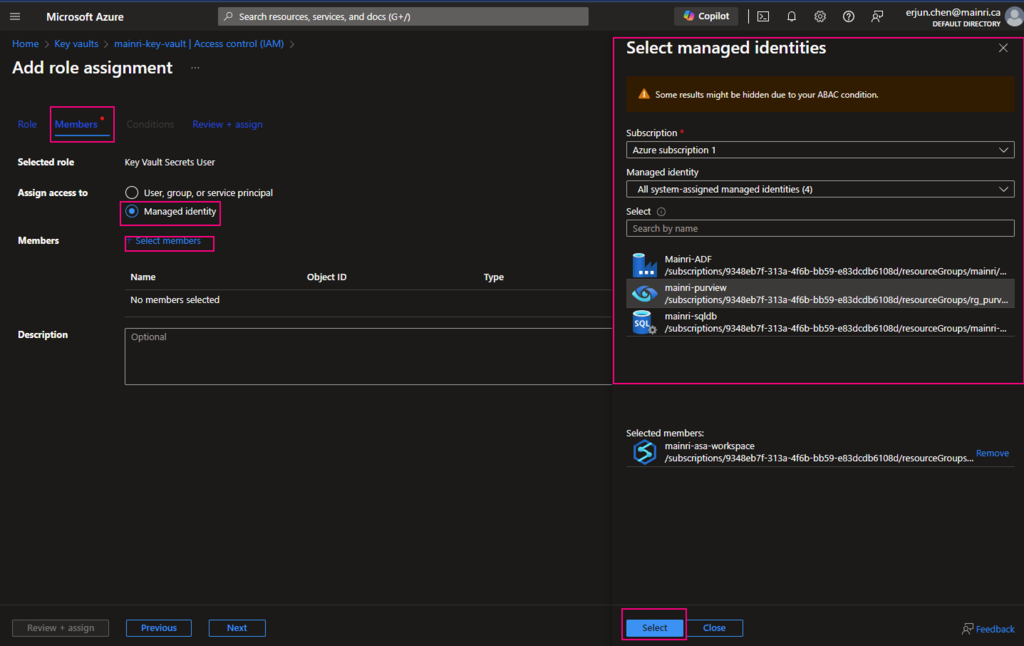
From Key Vault> Access Control (IAM) > Add role Assignment
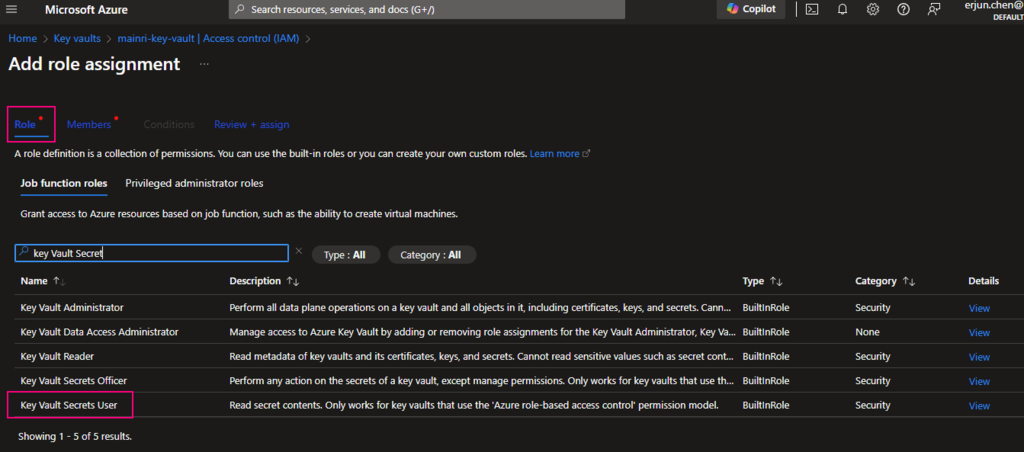
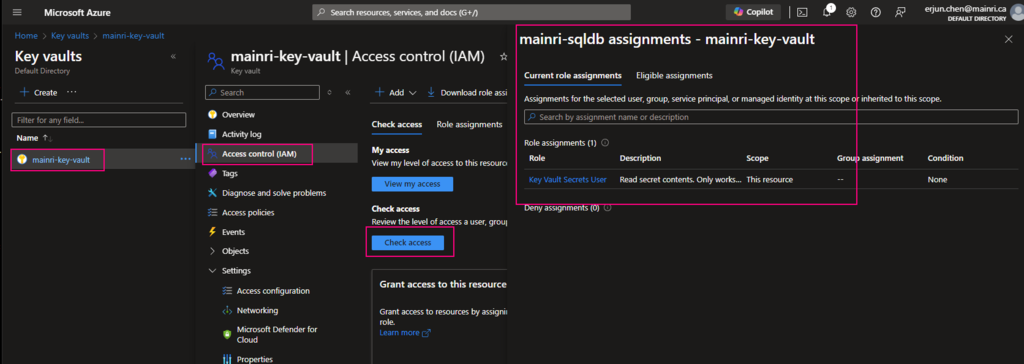
In most cases, if you create and save secrets in key-vault for your users to use, you only need add the “Key vault secrets user” role assignment.
click “next” select a member or group
Pay attention to here, if your organization has multiple instances of the same services, for example, different teams are independently using different ADF instants, make sure you correctly, accurately add the right service instant to access policies.
Once it’s down, check the access.
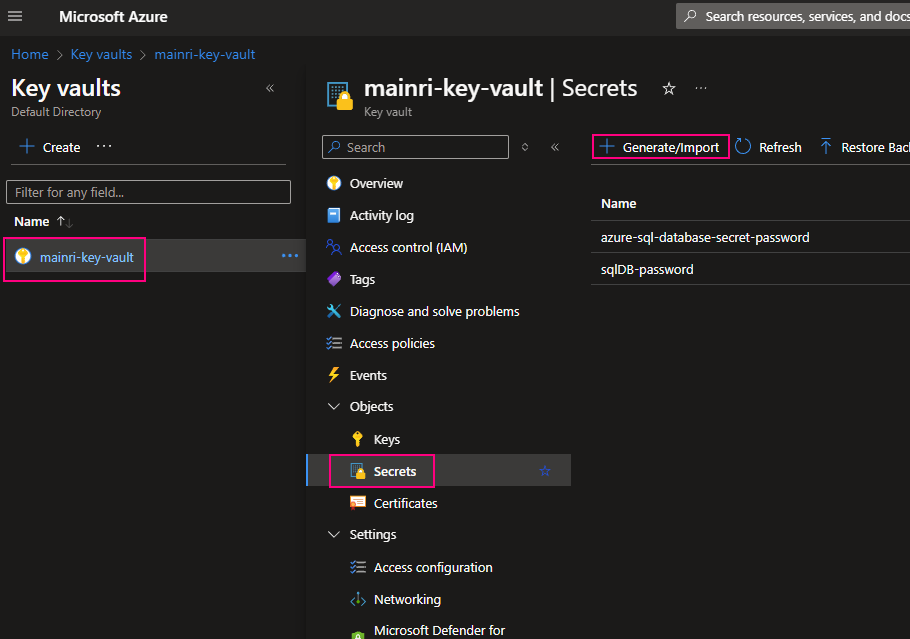
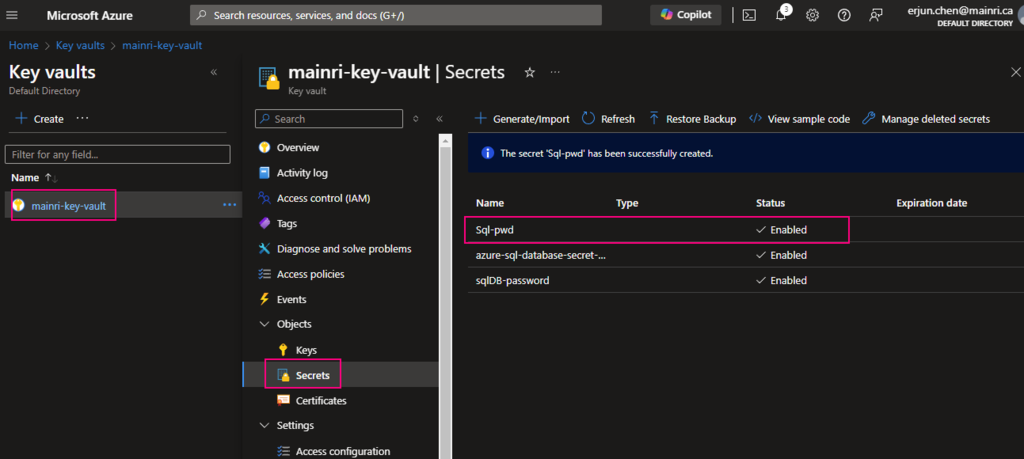
Create a Secret
From “Key Vault” > “Object” > “Secrets” > “+ Generate/Import”
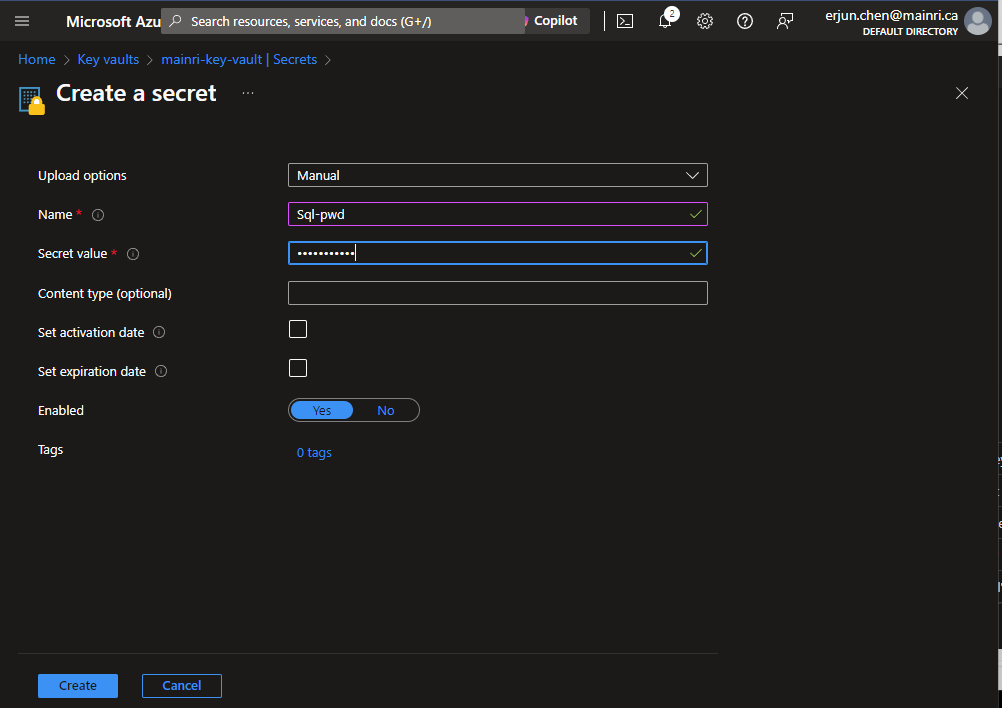
Fill in all properties, :Create”
Secrets key and value created That’s all.
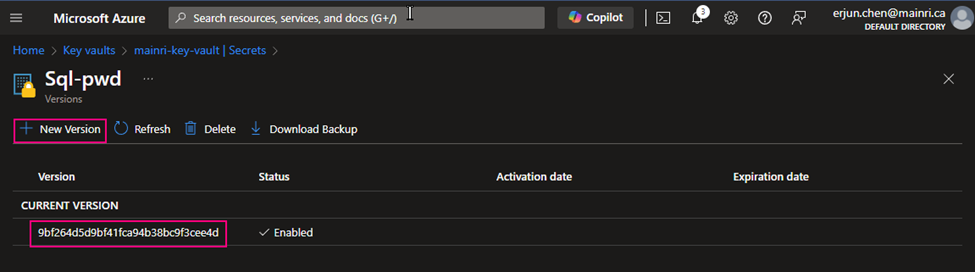
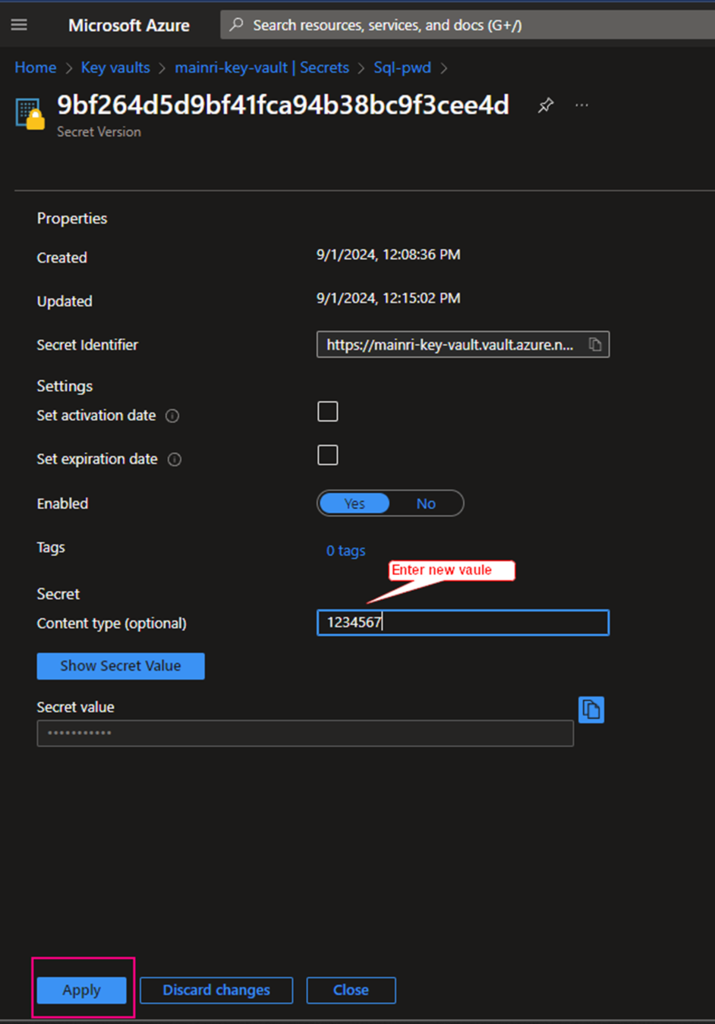
If you want to update the secret, simply click the key, follow the UI guide, you will not miss it.
Click the “version” that you want to update. Update the content > apply it.
That’s all.
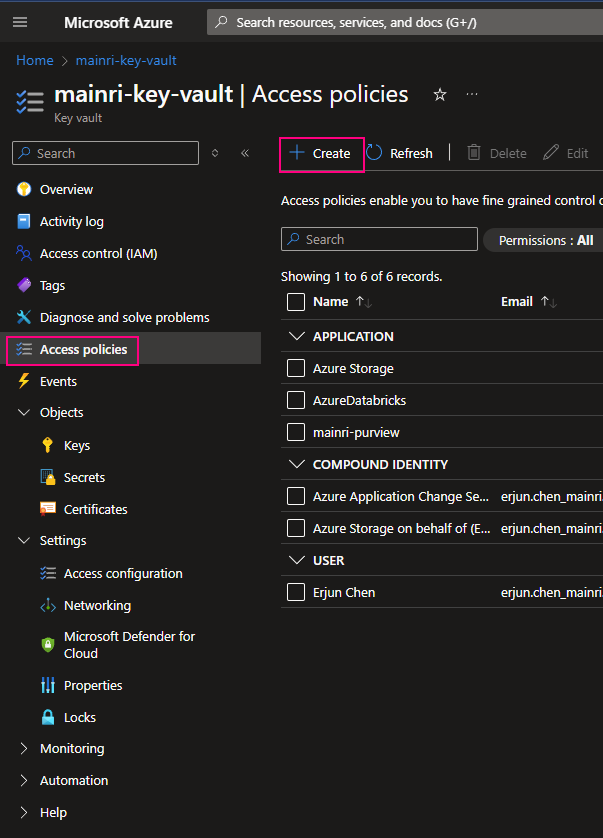
Using Access Policies create a secret
There is another way “Access Policies” to create a secret.
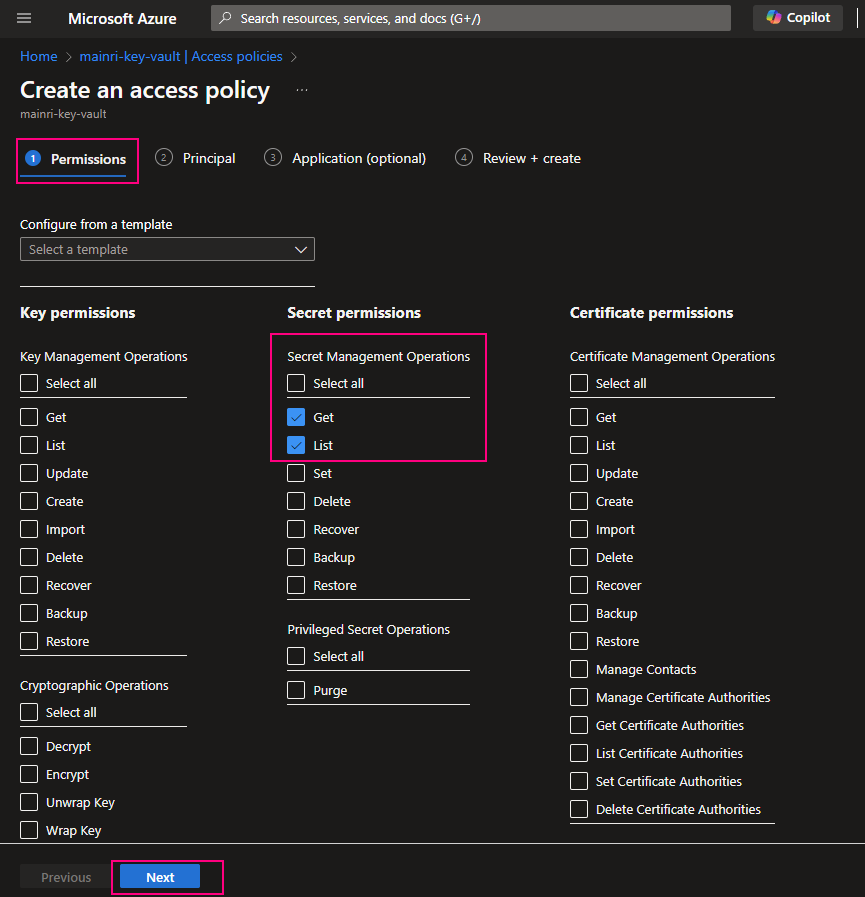
Select the permissions you want under Key permissions, Secret permissions, and Certificate permissions.
If you create a key secret for users to use in their application or other azure services, usually you give “get” and “list” in the “Secret permissions” enough. Otherwise, check Microsoft official documentation.
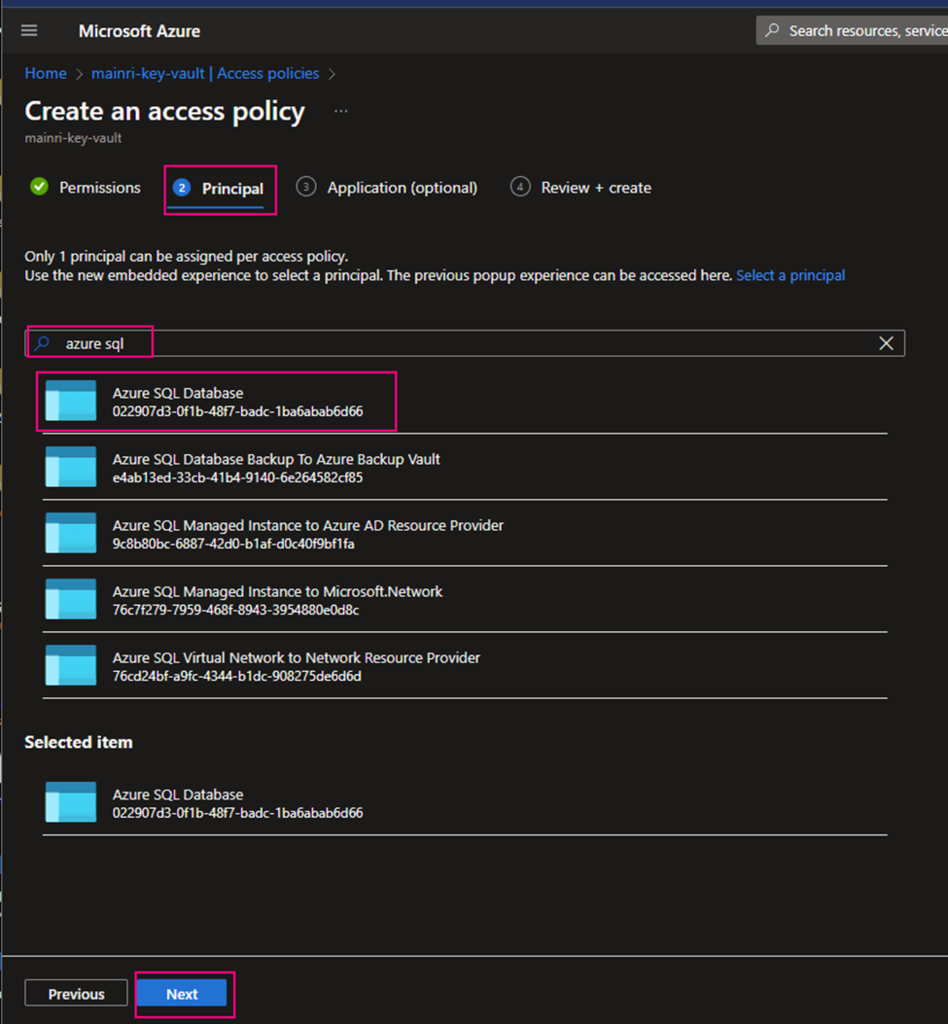
Under the Principal selection pane, enter the name of the user, app or service principal in the search field and select the appropriate result.
Using Azure SQL Database as an example
Caution: when you add principal, make sure you select right service instant. Especially you act as a infrastructure administer, your organization has multiple teams that they are independently using different service instants, e.g. different Synapse Workspace. select correct instant. I have been asked to help trouble shotting this scenario a few time. Azure admin says, he has added policies to key-vault, but the use cannot access there yet. that is a funny mistake made, he has added ADF to kay-vault policies, unfortunately, the ADF is NOT team A used, team B is using it. 🙂
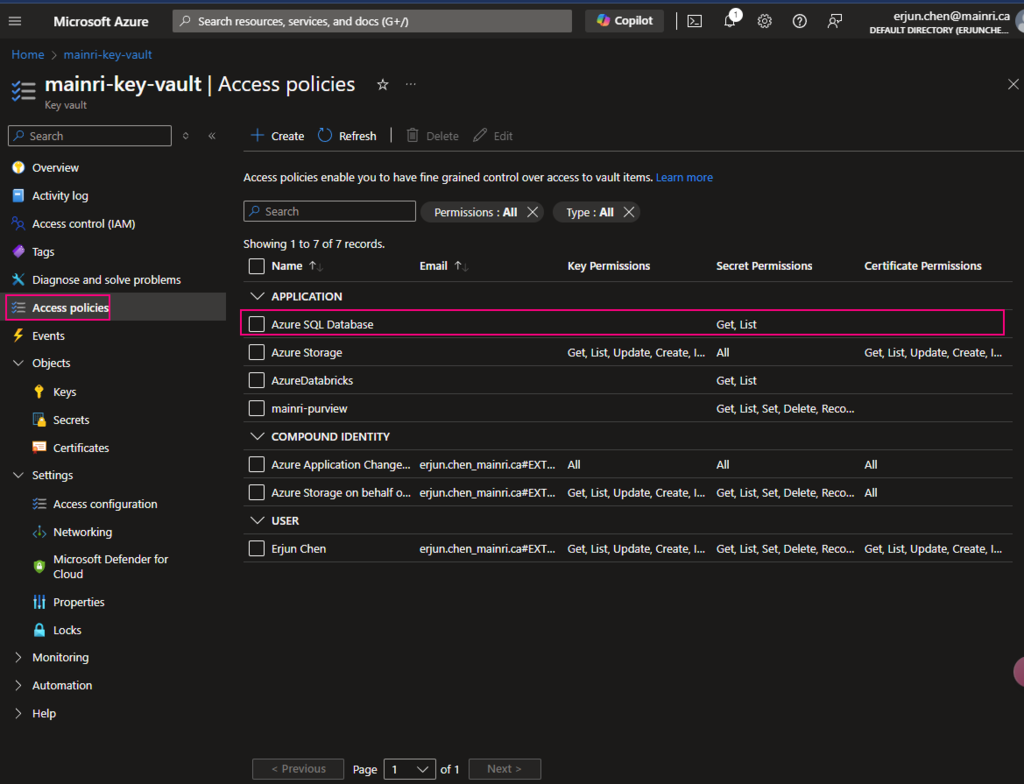
Back on the Access policies page, verify that your access policy is listed.
Create secret key and value
We have discussed it above. Need not verbose.
Done!
Using secrets that were saved in Key Vault
Using secrets usually have 2 major scenarios, directly use, or use REST API call to retrieve the saved secret value.
Let’s use Data Factory as an example to discuss.
Scenario 1, directly use it
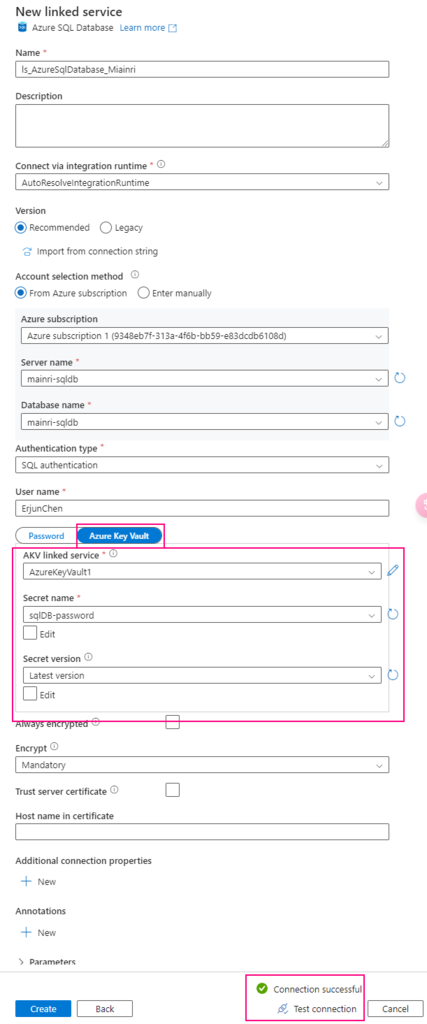
For example, when you create linked service to connect Azure Sql Database
You have to make sure that Key Vault’s access policies has this ADF access policies, get and list
one more example, System workspaces use key-vault.
Once again, make sure your Synapse Workspace has access policies, “Key Vault Secrets User“, “get” and “List”
Scenario 2, REST API call Key Vault to use secret
Many engineers want to call the key Vault to retrieve the secret value for a certain purpose, e.g. Synapse pipeline to get SharePoint Online list or files that resident in SharePoint Library, you need an application secret value to build the query string. Normally, the application’s secret value is saved in Key Vault. In this case, you have to make a http call to Key value.
Get a specified secret from a given key vault. The GET operation is applicable to any secret stored in Azure Key Vault. This operation requires the secrets/get permission.
GET {vaultBaseUrl}/secrets/{secret-name}/{secret-version}?api-version=7.4
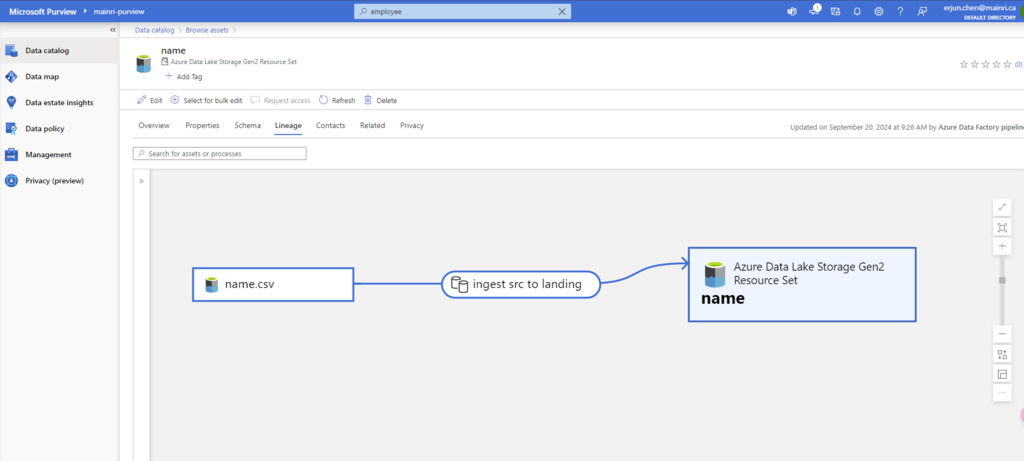
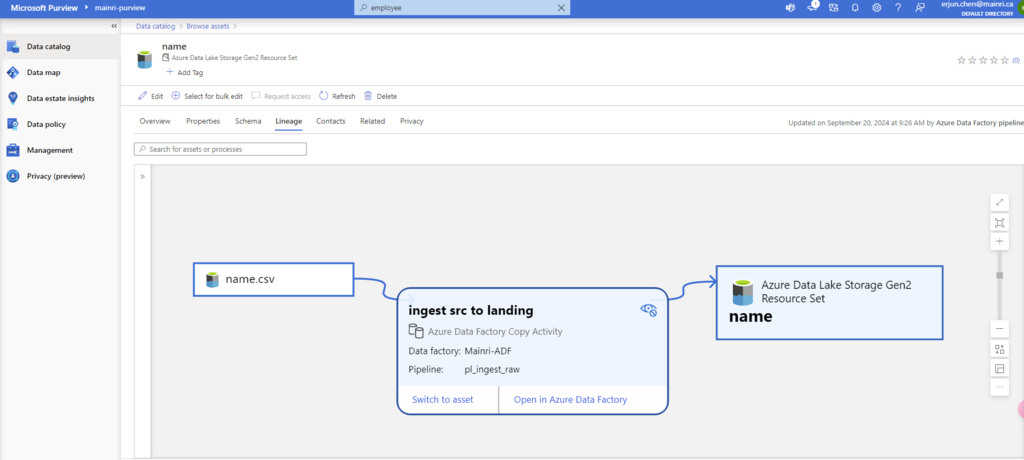
Microsoft Purview provides an overview of data lineage in the Data Catalog. It also details how data systems can integrate with the catalog to capture lineage of data.
Lineage is represented visually to show data moving from source to destination including how the data was transformed. Given the complexity of most enterprise data environments.
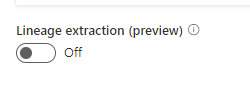
Microsoft Purview supports lineage for views and stored procedures from Azure SQL Database. While lineage for views is supported as part of scanning, you will need to turn on the Lineage extraction toggle to extract stored procedure lineage when you’re setting up a scan.
Lineage collection
Metadata collected in Microsoft Purview from enterprise data systems are stitched across to show an end to end data lineage. Data systems that collect lineage into Microsoft Purview are broadly categorized into following three types:
Data processing systems
Data storage systems
Data analytics and reporting systems
Each system supports a different level of lineage scope.
Data estate might include systems doing data extraction, transformation (ETL/ELT systems), analytics, and visualization systems. Each of the systems captures rich static and operational metadata that describes the state and quality of the data within the systems boundary. The goal of lineage in a data catalog is to extract the movement, transformation, and operational metadata from each data system at the lowest grain possible.
The following example is a typical use case of data moving across multiple systems, where the Data Catalog would connect to each of the systems for lineage.
Data Factory copies data from on-prem/raw zone to a landing zone in the cloud.
Data processing systems like Synapse, Databricks would process and transform data from landing zone to Curated zone using notebooks.
Further processing of data into analytical models for optimal query performance and aggregation.
Data visualization systems will consume the datasets and process through their meta model to create a BI Dashboard, ML experiments and so on.
Lineage for SQL DB views
Starting 6/30/24, SQL DB metadata scan will include lineage extraction for views. Only new scans will include the view lineage extraction. Lineage is extracted at all scan levels (L1/L2/L3). In case of an incremental scan, whatever metadata is scanned as part of incremental scan, the corresponding static lineage for tables/views will be extracted.
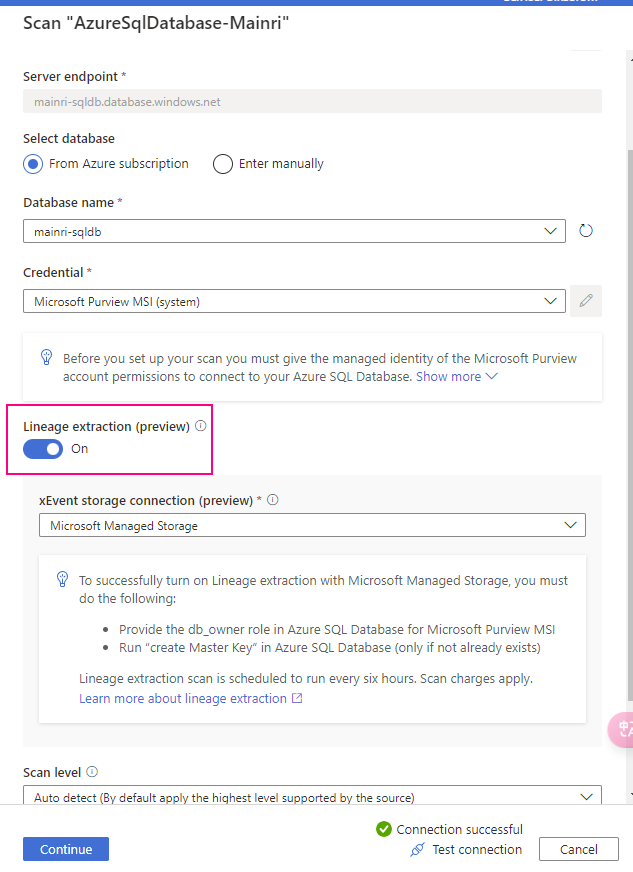
Prerequisites for setting up a scan with Stored Procedure lineage extraction
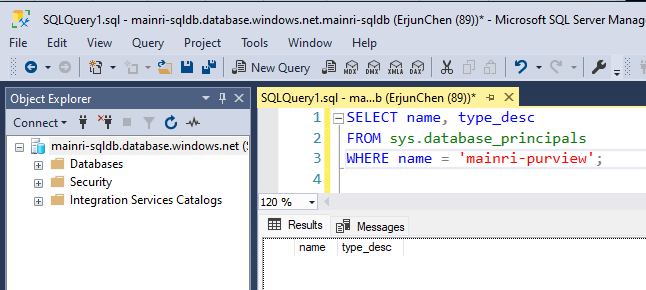
<Purview-Account> can access SQL Database and in db_owner group
To check whether the Account Exists in the Database
SELECT name, type_desc
FROM sys.database_principals
WHERE name = 'YourUserName';
Replace ‘YourUserName’ with the actual username you’re checking for.
If the user exists, it will return the name and type (e.g., SQL_USER or WINDOWS_USER).
If it does not exist, create one.
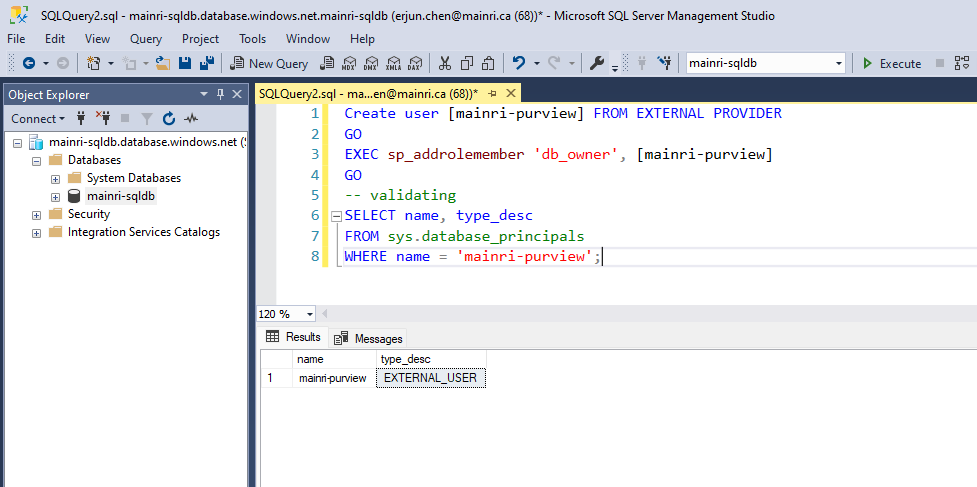
Sign in to Azure SQL Database with your Microsoft Entra account, create a <Purview-account> account and assign db_owner permissions to the Microsoft Purview managed identity.
Create user <purview-account> FROM EXTERNAL PROVIDER
GO
EXEC sp_addrolemember 'db_owner', <purview-account>
GO
replace <purview-account> with the actual purview account name.
Master Key
Check whether master exists or not.
To check if the Database Master Key (DMK) exists or not
SELECT * FROM sys.symmetric_keys
WHERE name = '##MS_DatabaseMasterKey##';Create master key
Go
if the query returns a result, it means the Database Master Key already exists.
If no rows are returned, it means the Database Master Key does not exist, and you may need to create one if required for encryption-related operations.
Create a master key
Create master key
Go
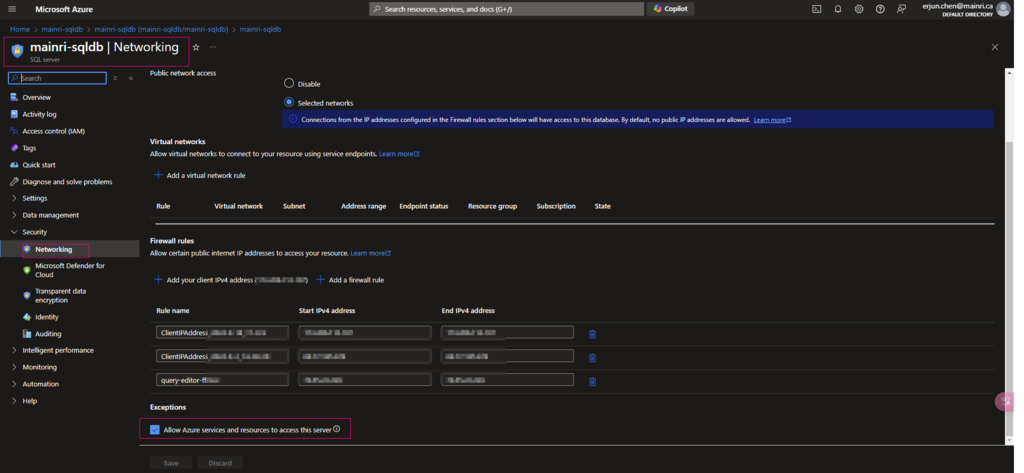
Allow Azure services and resources to access this server
Ensure that Allow Azure services and resources to access this server is enabled under networking/firewall for your Azure SQL resource.
To allow purview extract lineage, we need set to on
Extract Azure Data Factory/Synapse pipeline lineage
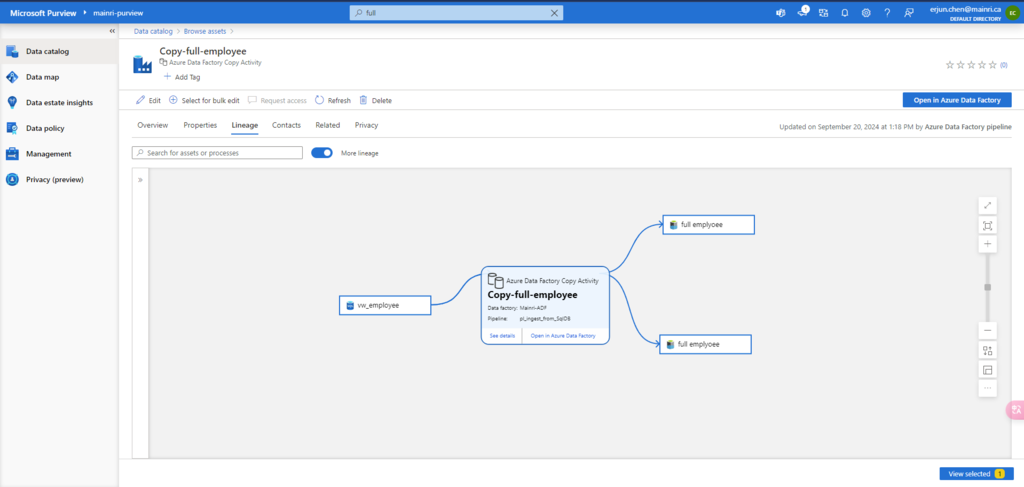
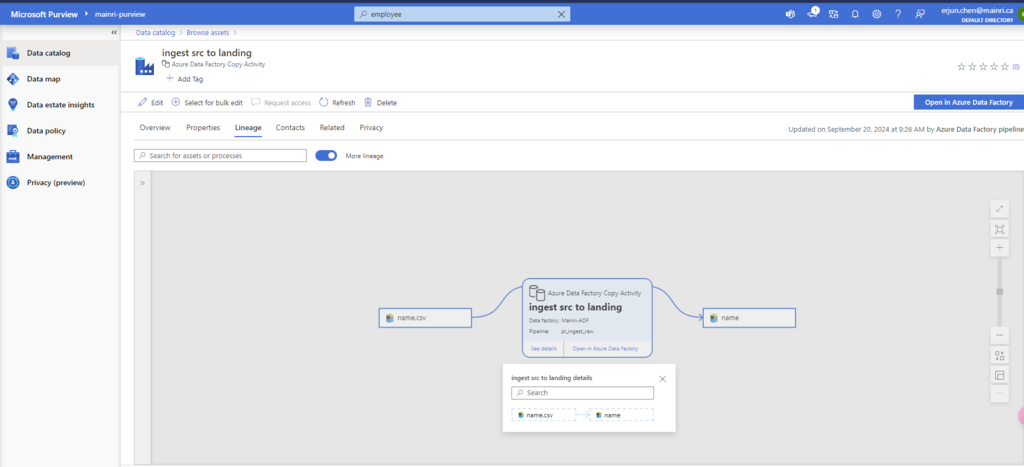
When we connect an Azure Data Factory to Microsoft Purview, whenever a supported Azure Data Factory activity is run, metadata about the activity’s source data, output data, and the activity will be automatically ingested into the Microsoft Purview Data Map.
Microsoft Purview captures runtime lineage from the following Azure Data Factory activities:
Copy Data
Data Flow
Execute SSIS Package
If a data source has already been scanned and exists in the data map, the ingestion process will add the lineage information from Azure Data Factory to that existing source. If the source or output doesn’t exist in the data map and is supported by Azure Data Factory lineage Microsoft Purview will automatically add their metadata from Azure Data Factory into the data map under the root collection.
This can be an excellent way to monitor your data estate as users move and transform information using Azure Data Factory.
Connect to Microsoft Purview account in Data Factory
Set up authentication
Data factory’s managed identity is used to authenticate lineage push operations from data factory to Microsoft Purview. Grant the data factory’s managed identity Data Curator role on Microsoft Purview root collection.
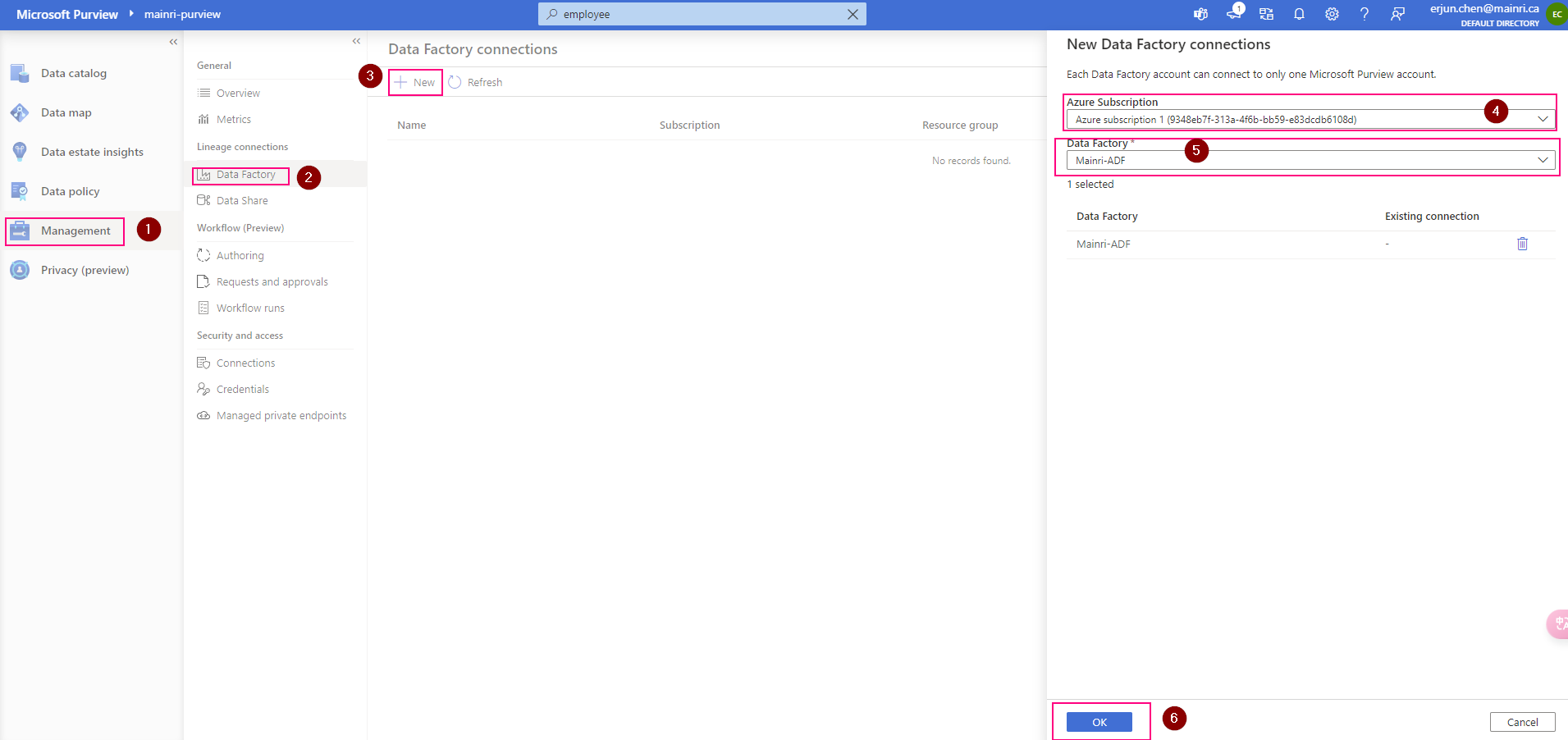
Purview > Management > Lineage connections > Data Factory > new
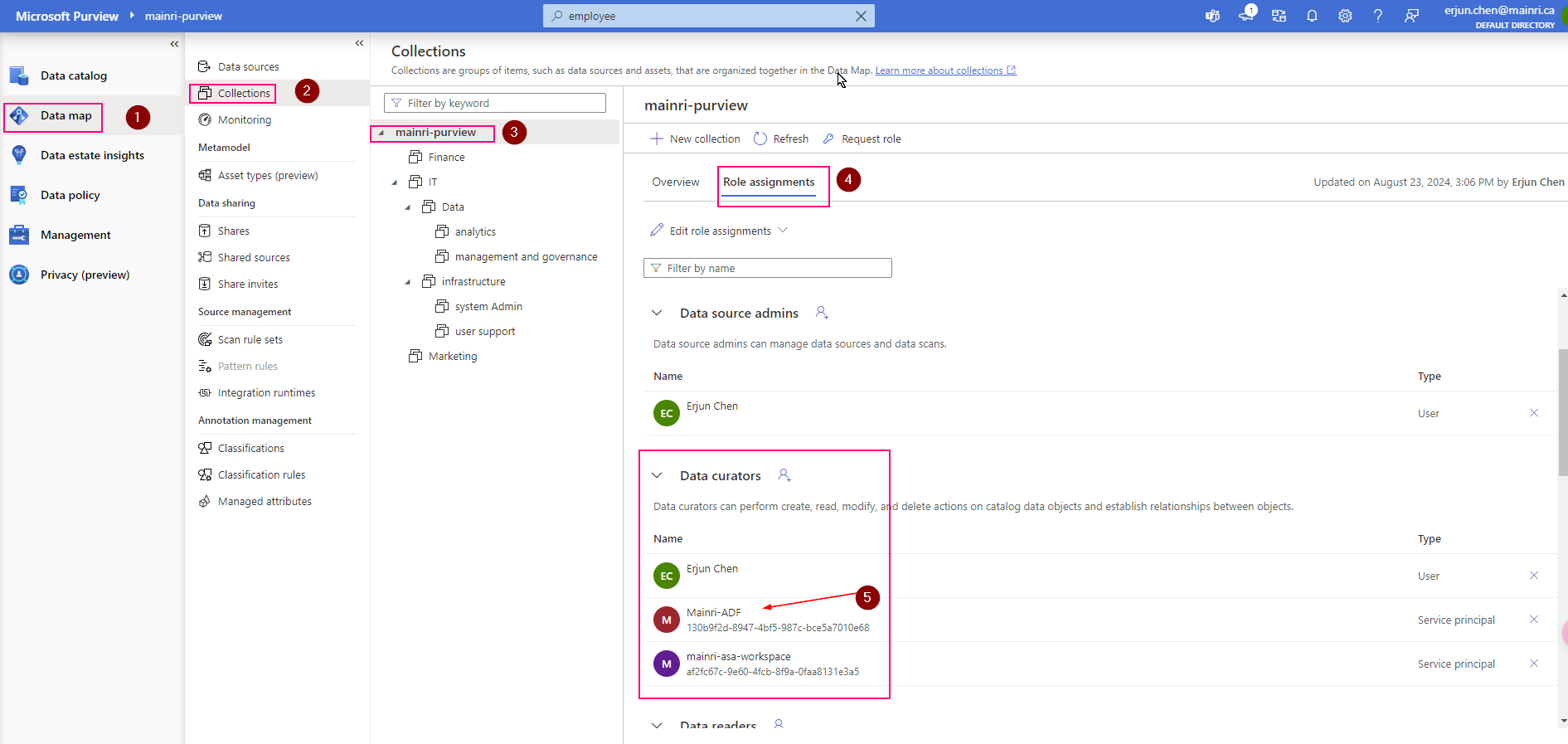
Validation: Purview > Data map > Collection > Root collection > Role assignments >
Check, the ADF is under “data Curators” section. That’s OK
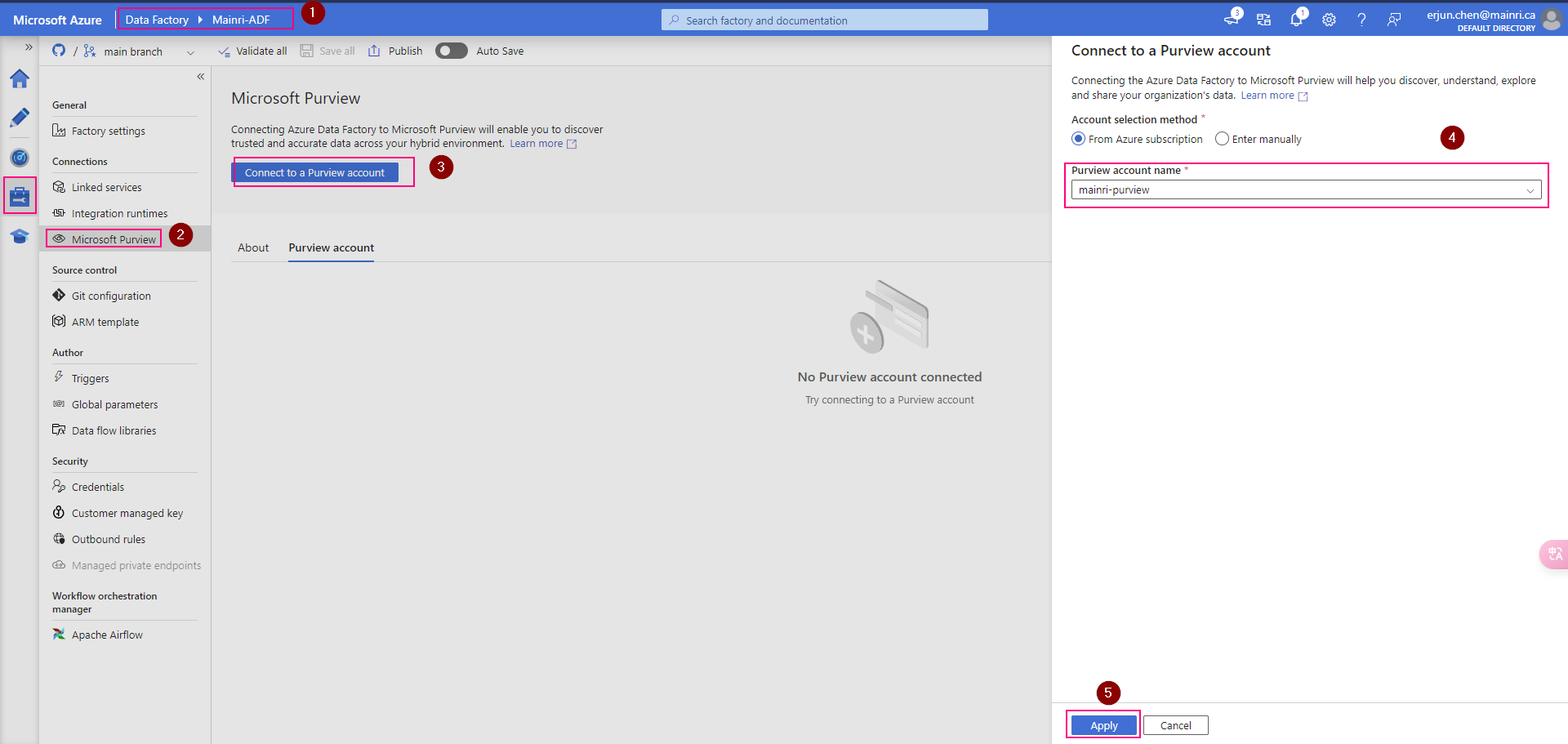
ADF connect to purview
In the ADF studio: Manage -> Microsoft Purview, and select Connect to a Microsoft Purview account
We will see this
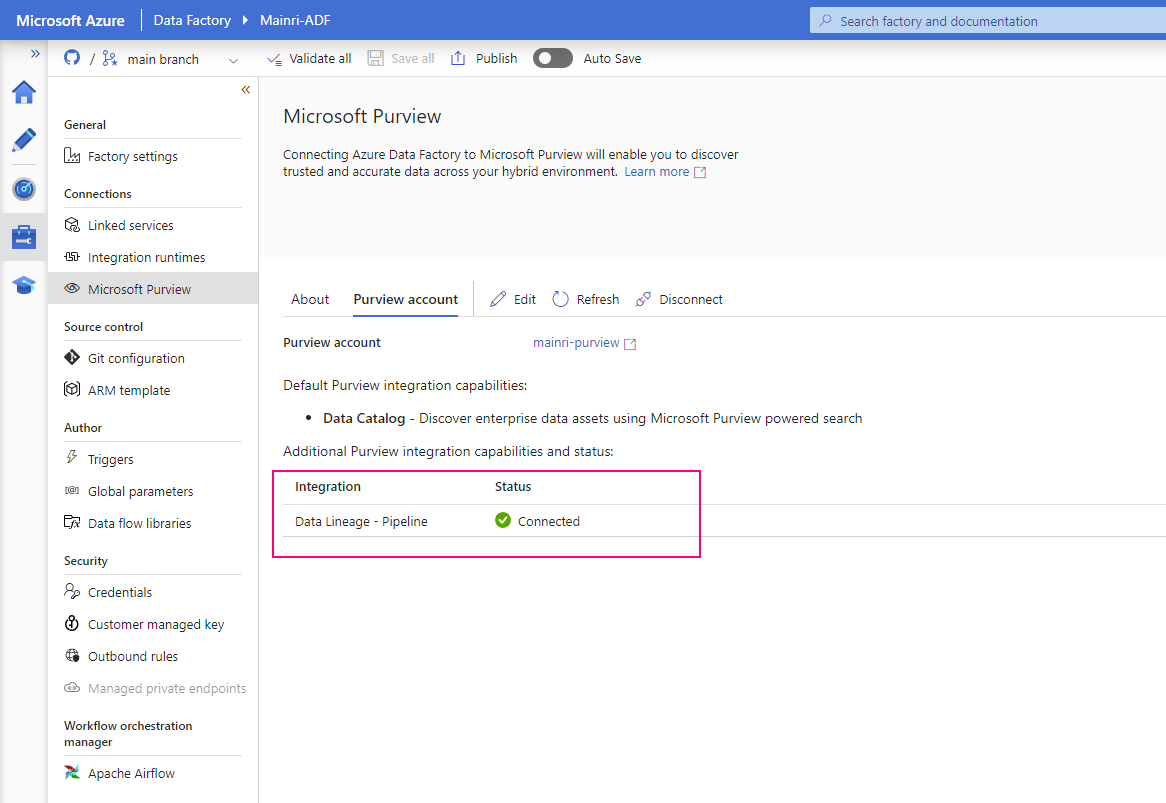
Once pipeline successfully runs, activity will be caught, extracted lineage look this.
Understanding how failures in individual activities affect the pipeline as a whole is crucial for building robust data workflows.
Some people have used SSIS previously, when they switch from SSIS to the Azure Data Factory and Synapse, they might confuse in ADF or ASA ‘s “pipeline logical failure mechanisam” ADF or ASA’s pipeline orchestration allows conditional logic and enables the user to take a different path based upon outcomes of a previous activity. Using different paths allows users to build robust pipelines and incorporates error handling in ETL/ELT logic.
ADF or ASA activity outcomes path
ADF or ASA has 4 paths in total.
A pipeline can have multiple activities that can be executed in sequence or in parallel.
Sequential Execution: Activities are executed one after another.
Parallel Execution: Multiple activities run simultaneously.
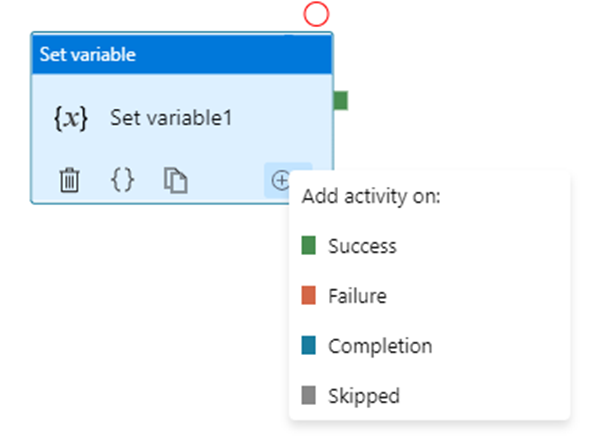
You are able to add multiple branches following an activity, for each pipeline run, at most one path is activated, based on the execution outcome of the activity.
Error Handling Mechanism
When an activity fails within a pipeline, several mechanisms can be employed to handle the failure:
In most cases, pipelines are orchestrated in Parallel, Serial or Mixed model. The key point is understanding what will happen in Parallet or Serial model.
From upon activity point of view, the basic principles that are:
Multiple dependencies with the same source are logical “OR”
Multiple dependencies with different sources are logical “AND”
Different error handling mechanisms lead to different status for the pipeline: while some pipelines fail, others succeed. We determine pipeline success and failures as follows:
Evaluate outcome for all leaves activities. If a leaf activity was skipped, we evaluate its parent activity instead.
Pipeline result is success if and only if all nodes evaluated succeed
Let us discuss in detail.
Multiple dependencies with the same source
This seems like “Serial” or “sequence”
How “Serial” pipeline failure is determined
As we develop more complicated and resilient pipelines, it’s sometimes required to introduce conditional executions to our logic: execute a certain activity only if certain conditions are met. At this point, as long as one or more activities failed while one or other activities success in a pipeline, what is the status of the entire pipeline? Success? Failure? How are pipeline failure determined?
In fact, ADF/ASA has unique insight. Software engineers are used to customary form:
“if … then … else …”; try … catch …”, let’s use the developer’ idiom
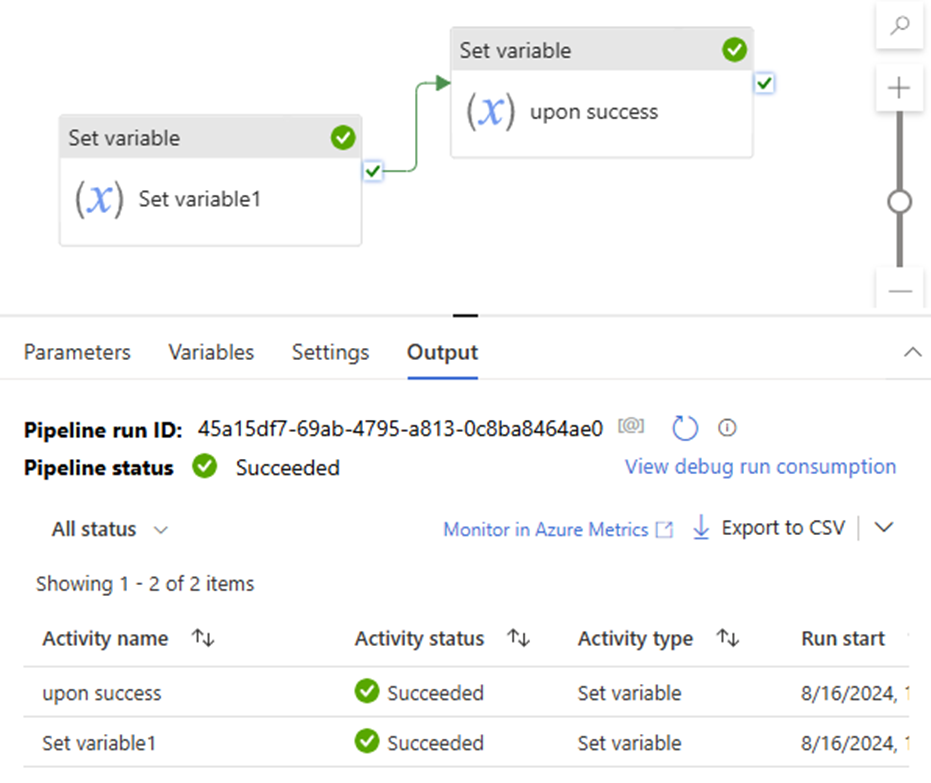
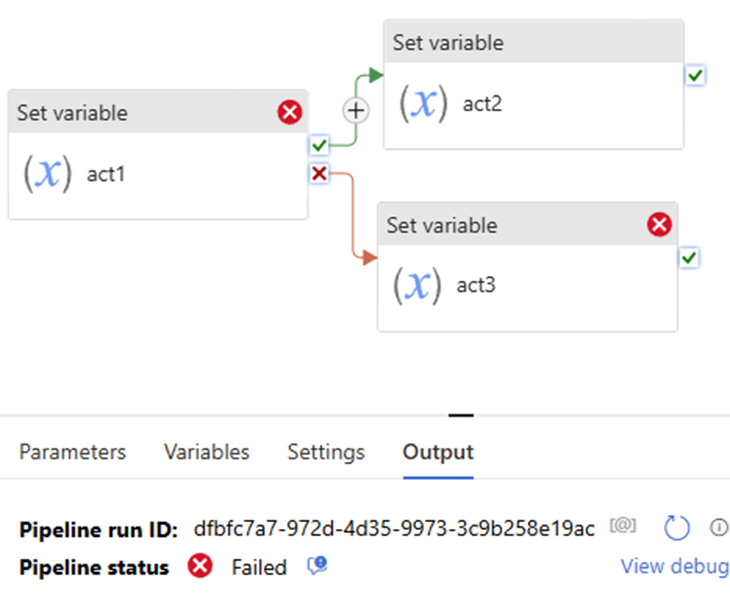
Single upon activity or Serial model, multiple downstream
upon act failed >> downstream act success >> pipeline success
Scenario 2:
If … then … Else …
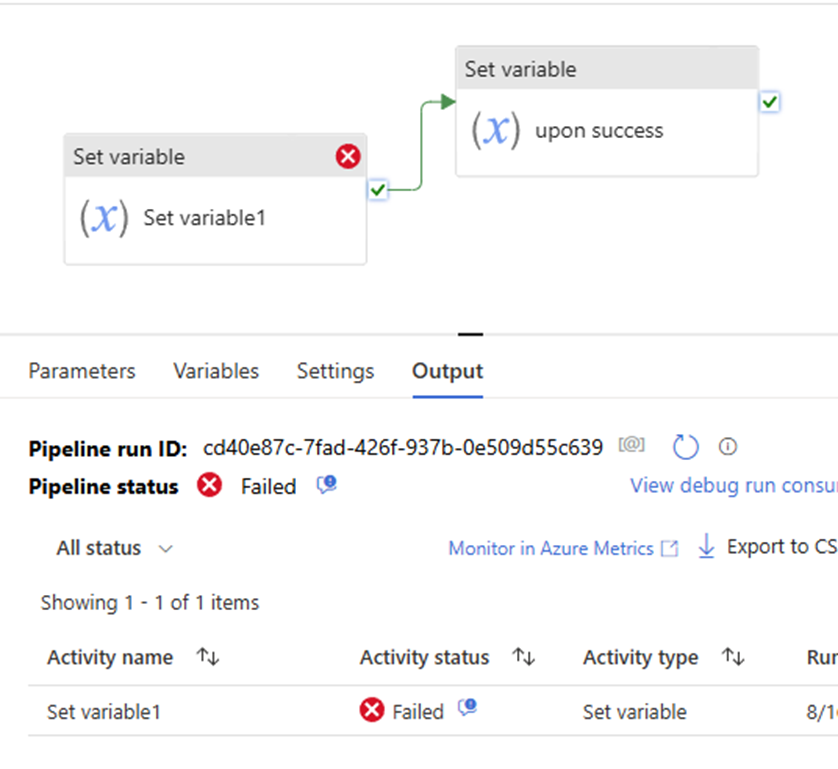
Pipeline defines both the Upon Failure and Upon Success paths. This approach renders pipeline fails, even if Upon Failure path succeeds.
Both success & failure path
upon act failed >> downstream act failed >> pipeline success
Both success & failure path
upon act failed >> downstream failed >> pipeline failed
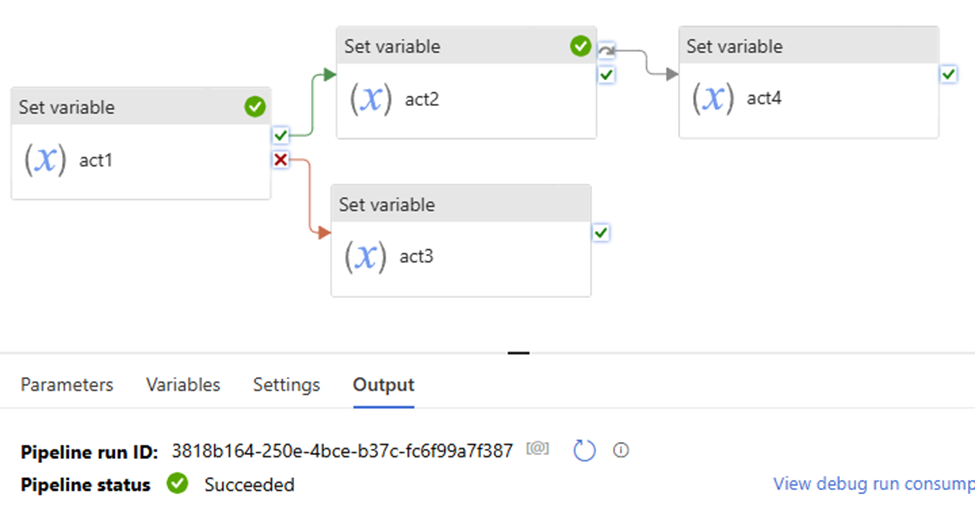
Scenario 3
If …Skip… Else ….
Both success & failure path, and skip path
upon act success >> downstream act success >> skip path is skipped >> pipeline success
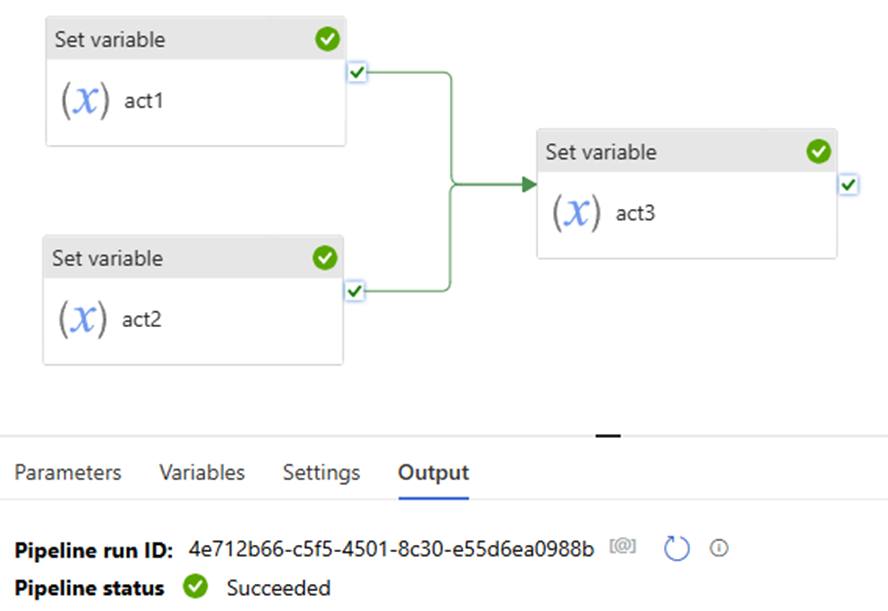
Multiple dependencies with different sources
This seems like “Parallel”, its logical is “And”
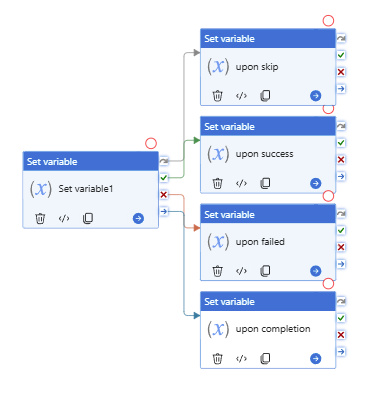
Scenario 4:
Upon act 1 success and upon act 2 success >> downstream act success >> pipeline success.
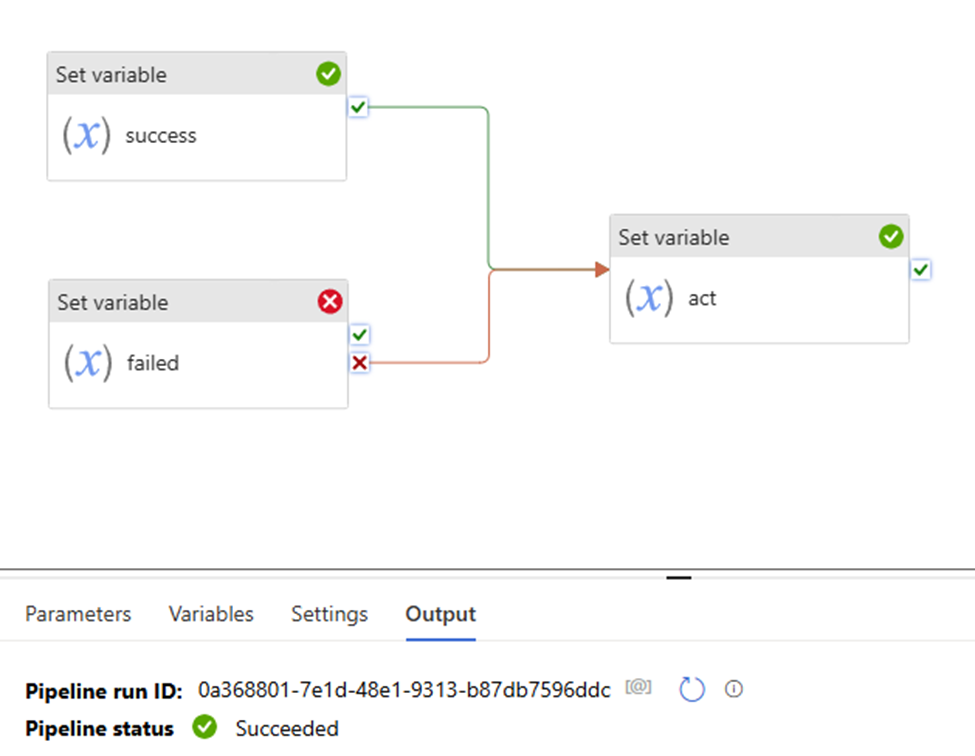
Upon act 1 success and upon act 2 failed >> downstream act success >> pipeline success.
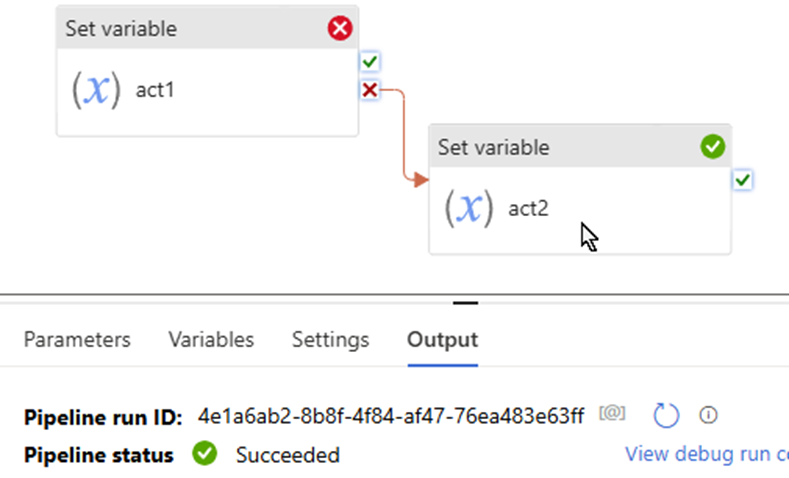
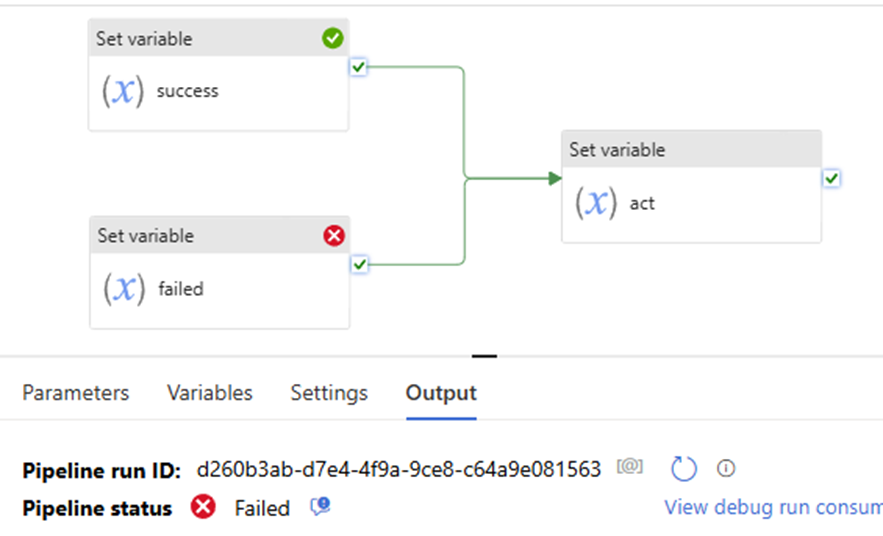
pay attention to the “Set variable failed” uses “fail” path.
That mean:
“set variable success” the action is true
Although “set variable failed” activity failed, but “set variable failed” the action is true.
so both “set variable success” and “set variable failed” the two action true.
pipeline shows to “success”
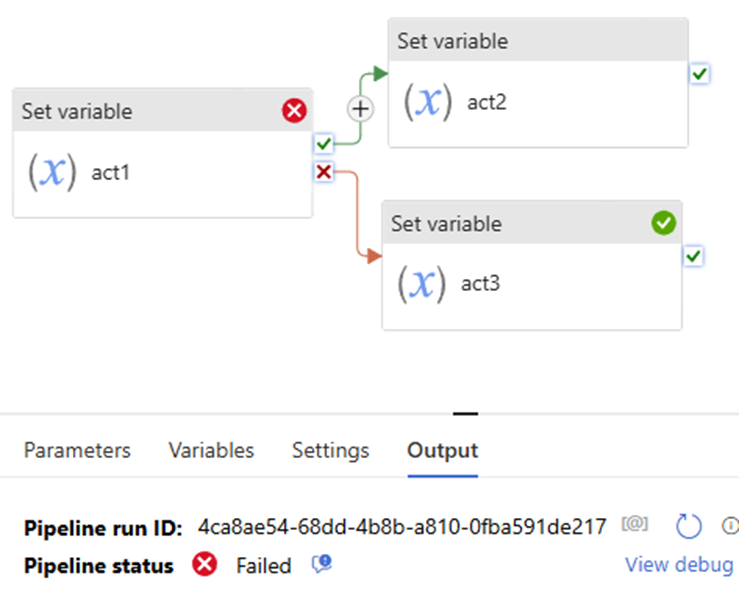
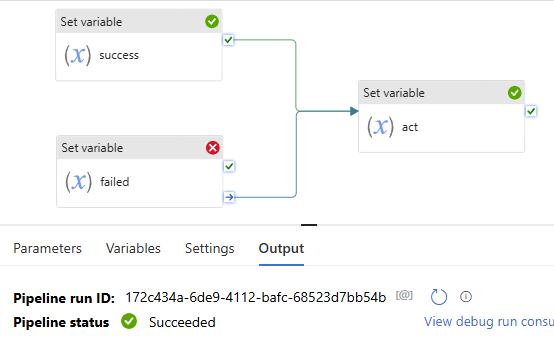
Now, let’s try this:
the “Set variable failed” uses “success” path, to see what pipeline shows, pipeline failed.
Why? since the “Set variable failed” action is not true. even if the “set variable success” action is True. True + False = False. follow activity – “set variable act” is skipped. will not execute, will not run! pipeline failed!
All right, you might immediately realize that once we let the “Set variable failed” path uses “complete”, that means no matter it true or false, the downstream activity “set variable act” will not be skipped. Pipeline will show success.
Error Handling
Sample error handling patterns
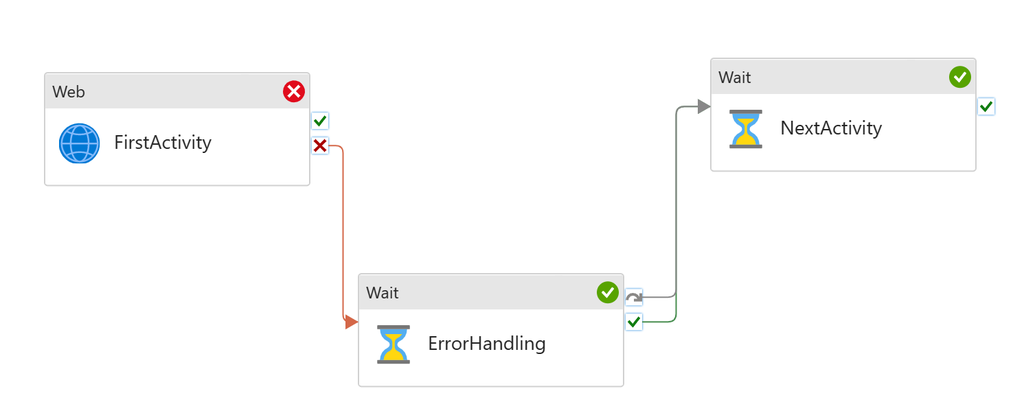
The pattern is equivalent to try catch block in coding. An activity might fail in a pipeline. When it fails, customer needs to run an error handling job to deal with it. However, the single activity failure shouldn’t block next activities in the pipeline. For instance, I attempt to run a copy job, moving files into storage. However it might fail half way through. And in that case, I want to delete the partially copied, unreliable files from the storage account (my error handling step). But I’m OK to proceed with other activities afterwards.
To set up the pattern:
Add first activity
Add error handling to the UponFailure path
Add second activity, but don’t connect to the first activity
Connect both UponFailure and UponSkip paths from the error handling activity to the second activity
Error Handling job runs only when First Activity fails. Next Activity will run regardless if First Activity succeeds or not.
Generic error handling
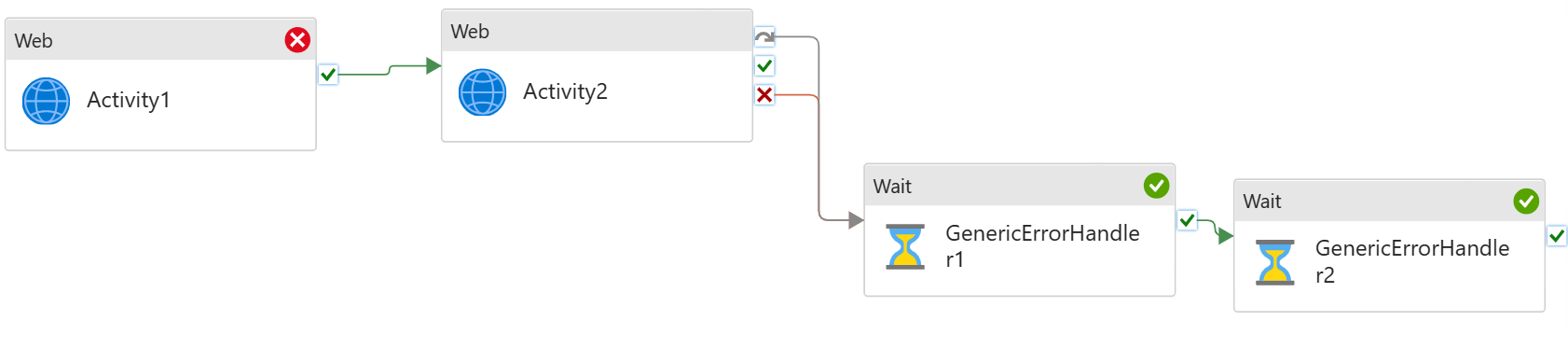
We have multiple activities running sequentially in the pipeline. If any fails, I need to run an error handling job to clear the state, and/or log the error.
For instance, I have sequential copy activities in the pipeline. If any of these fails, I need to run a script job to log the pipeline failure.
To set up the pattern:
Build sequential data processing pipeline
Add generic error handling step to the end of the pipeline
Connect both Upon Failure and Upon Skip paths from the last activity to the error handling activity
The last step, Generic Error Handling, will only run if any of the previous activities fails. It will not run if they all succeed.
You can add multiple activities for error handling.
Summary
Handling activity failures effectively is crucial for building robust pipelines in Azure Data Factory. By employing retry policies, conditional paths, and other error-handling strategies, you can ensure that your data workflows are resilient and capable of recovering from failures, minimizing the impact on your overall data processing operations.
if you have any questions, please do not hesitate to contact me at william. chen @mainri.ca (remove all space from the email account 😊)
A Service Principal in Azure is an identity used by applications, services, or automated tools to access specific Azure resources. It’s tied to an Azure App Registration and is used for managing permissions and authentication.
The Microsoft identity platform performs identity and access management (IAM) only for registered applications. Whether it’s a client application like a ADF or Synapse, Wen Application or mobile app, or it’s a web API that backs a client app, registering establishes a trust relationship between your application and the identity provider, the Microsoft identity platform.
This article is talking on registering an application in the Microsoft Entra admin center. I outline the registration procedure step by step.
Summary steps:
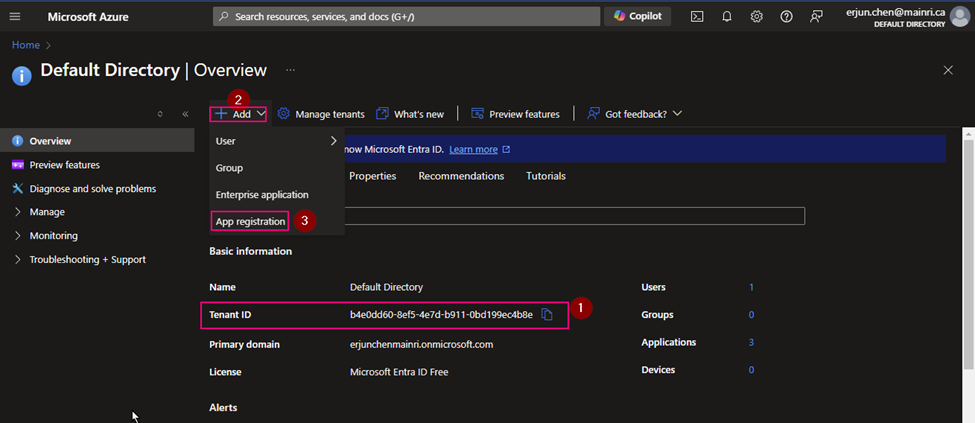
Navigate to Azure Entra ID (Azure Active Directory)
Create an App Registration
Generate Client Secret, note down Important the Application (client) ID and Directory (tenant) ID, Client-Secret-value.
Using the Service Principle – Assign Roles to the Service Principal Navigate to the Azure resource (e.g., Storage Account, Key Vault, SQL Database) you want your Service Principal to access.
Step by Step Demo
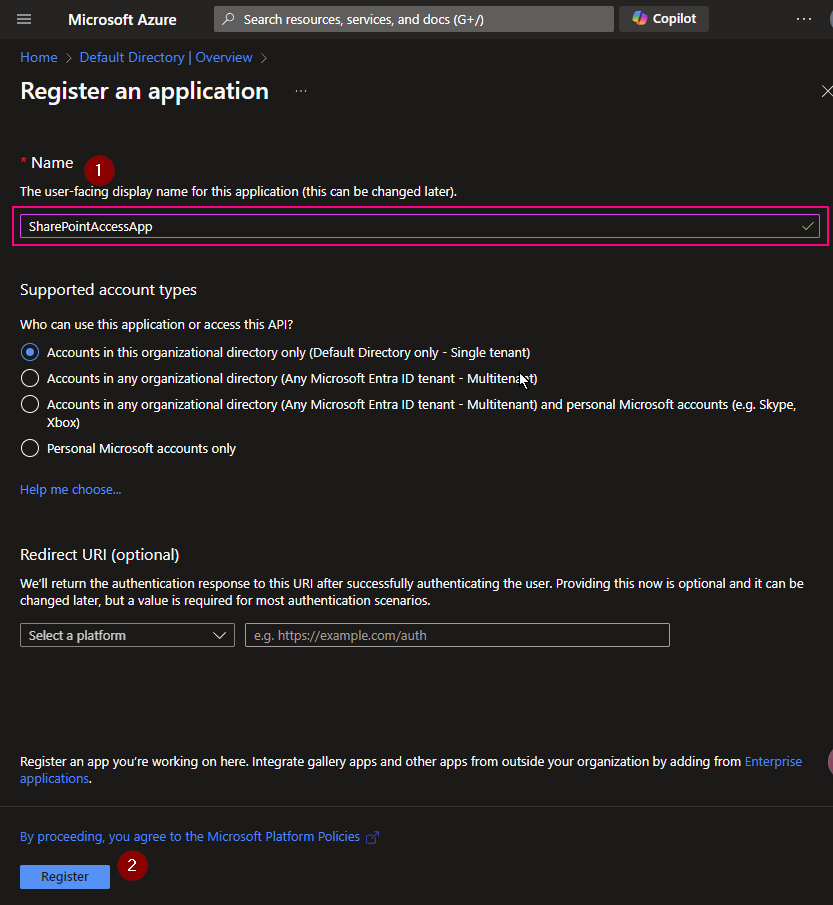
Register a new Application on Azure Entra ID (formerly called Azure Active Directory), get an Application ID and Client Secret value.
Azure Portal >> Azure Entra ID (formerly called Azure Active Directory)
(1) Copy Tenant ID.
We need this Tenant ID later.
(2) App Registration
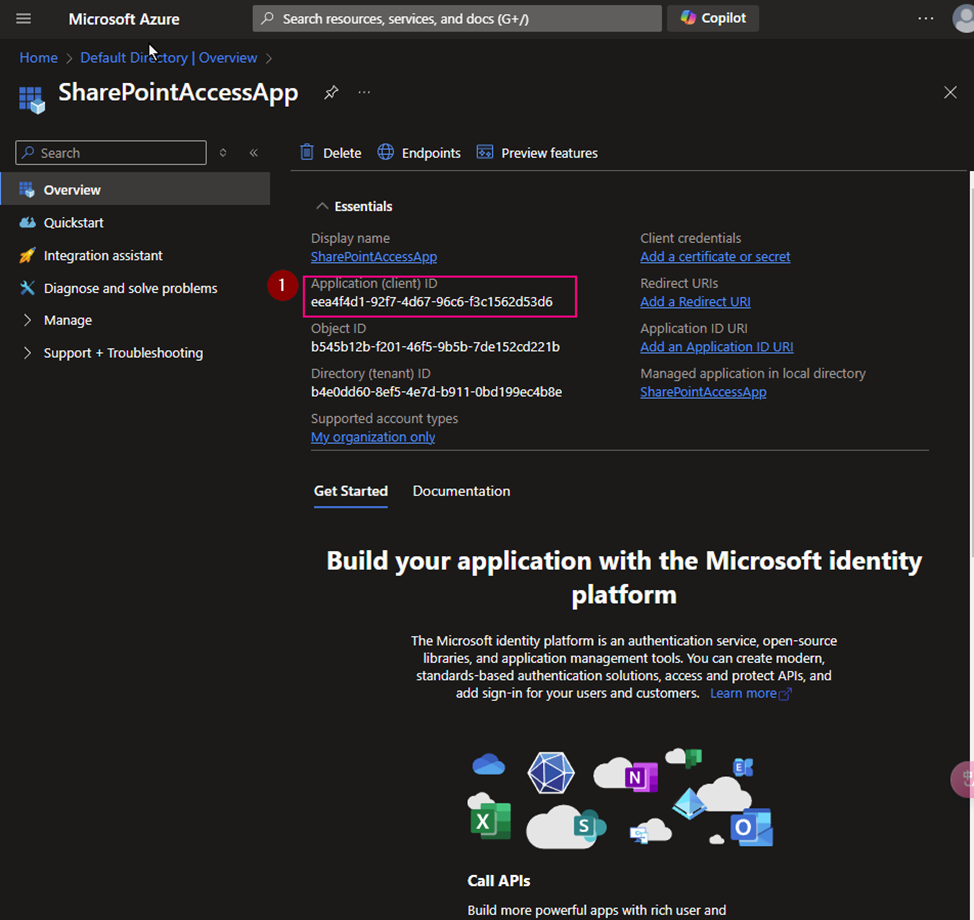
(3) Copy Application ID. We will use it later
(4) Create Client Secret
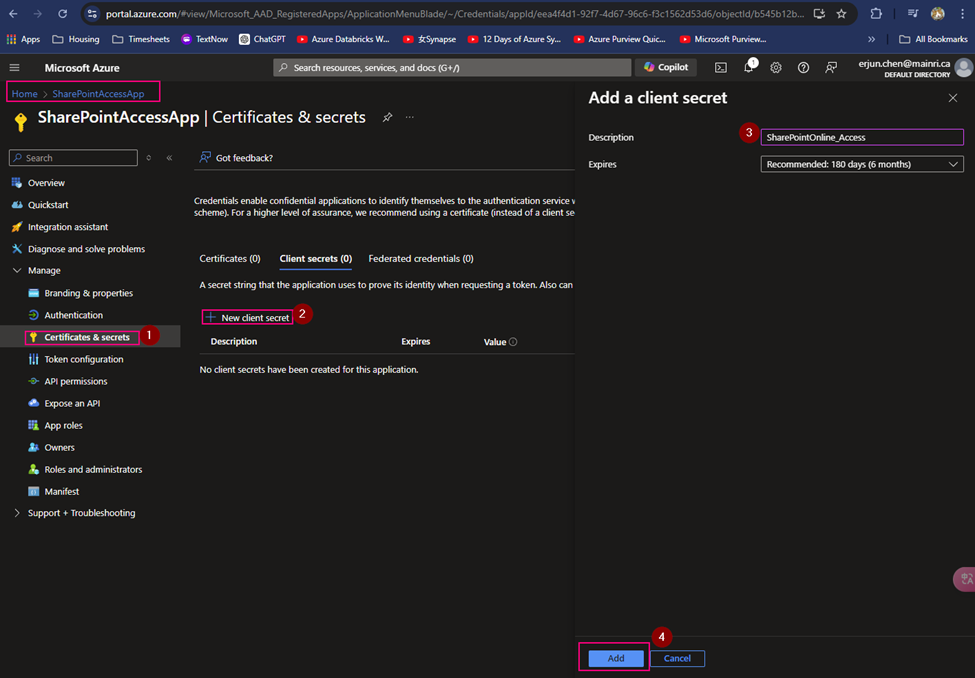
Generate a new client Secret,
(5) copy the Client Secret Value
Copy client-secret-value, we need it later.
Cause: the Client Secret Value you HAVE TO COPY IT RIGHT NOW! IMMEDIATELY copy NOW. And put it to a secure place. Since the Value WILL NOT reappear anymore. IMOPRTANT!
(6) Using the Service Principle – Assign Roles to the Service Principal
Assign Roles to the Service Principal
Now, assign permissions to your Service Principal so it can access specific Azure resources:
Navigate to the Azure resource (e.g., Storage Account, Key Vault, SQL Database) you want your Service Principal to access.
Go to Access Control (IAM).
Click Add and choose Add role assignment.
Choose a role (e.g., Contributor, Reader, or a custom role).
Search for your App Registration by its name and select it.
Save
We have finished all at Azure Entra ID (Former Azure Active Directory)
Please do not hesitate to contact me if you have any questions at william . chen @mainri.ca
In this article I will provide a fully Metadata driven solution about using Azure Data Factory (ADF) or Synapse Analytics (ASA) incrementally copy multiple data sets one time from SharePoint Online (SPO) then sink them to ADSL Gen2.
Previously, I have published articles regarding ADF or ASA working with SPO. if you are interested in specifics matters, please look at related articles from here , or email me at william . chen @ mainri.ca (please remove spaces from email account 🙂 ).
Scenario and Requirements
Metadata driven. All metadata are save on SharePoint list, such as TenantID, ClientID, SPO site name, ADLS account, inspecting offset days for increment loading …. etc.
Initial full load, then monitor data set status, once it update, incrementally load, for example, on daily basis.
Solution
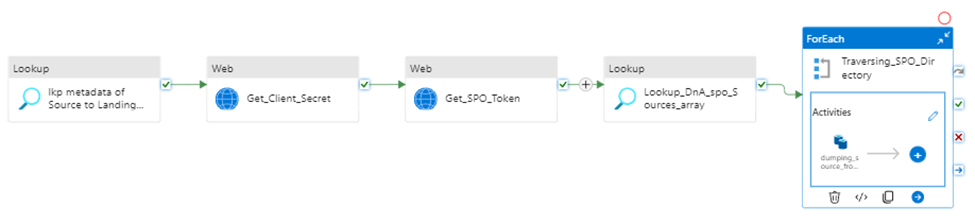
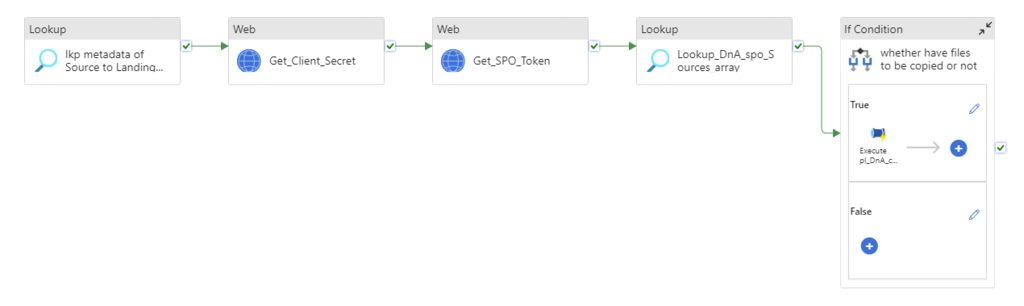
Retrieves metadata >> retrieves “client Secret” >> request access token >> insect and generate interests data list >> iteratively copy interest data sink to destination storage.
Prerequisite
Register SharePoint (SPO) application in Azure Active Directory (AAD).
Grant SPO site permission to registered application in AAD.
Provision Resource Group, ADF (ASA) and ADLS in your Azure Subscription.
I have other articles to talk those in detail. If you need review, please go to
Let us begin , Step by Step in detail, I will mention key points for every steps.
Step1:
Using Lookup activity to retrieve all metadata from SharePoint Online
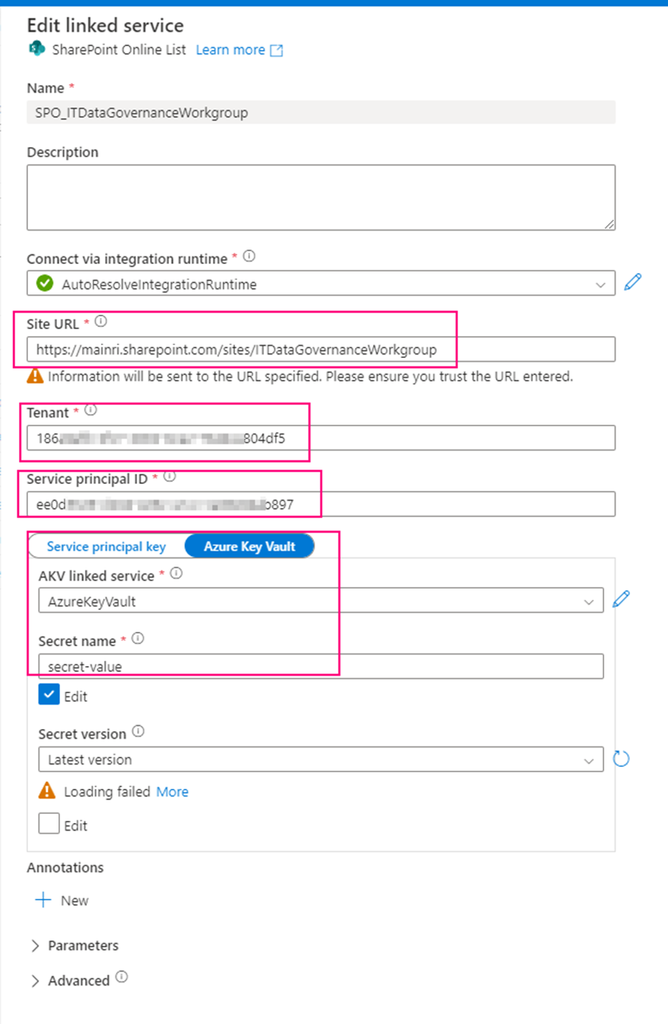
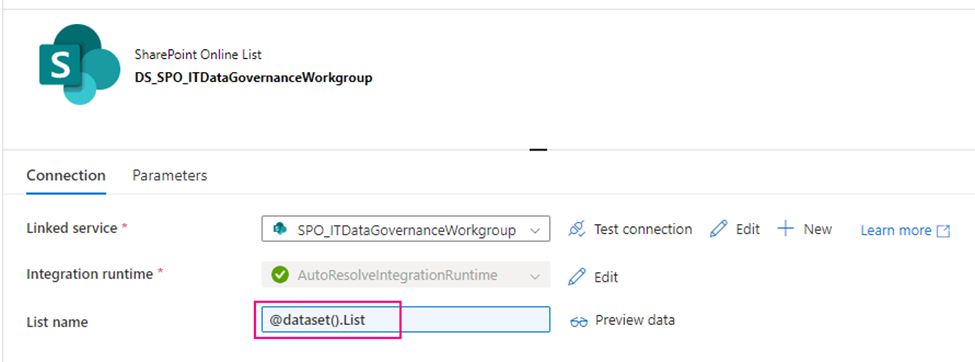
Firstly, create a SharePoint on Line List type Linked Service – SPO_ITDataGovernanceWorkgroup you need provide:
SharePoint site URL, you should replace it by using yours. it looks like htts://[your_domain].sharepoint.sites/[your_site_name]. mine is https://mainri.sharepoint.com/sites/ITDataGovernanceWorkgroup.
Tenant ID. The tenant ID under which your application resides. You can find it from Azure portal Microsoft Entra ID (formerly called Azure AD) overview page.
Service principal ID (Client ID) The application (client) ID of your application registered in Microsoft Entra ID. Make sure to grant SharePoint site permission to this application.
Service principal Key The client secret of your application registered in Microsoft Entra ID. mine is save in Azure Key Vault
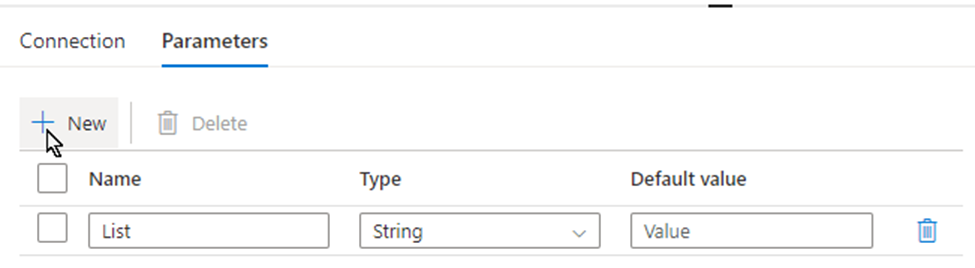
secondly, using above Linked Service create a SharePoint type Dataset – DS_SPO_ITDataGovernanceWorkgroup parametrize the dataset.
I name the parameter “List“, This parameter lets lookup activity knows where your metadata resides. (mine is called SourceToLanding)
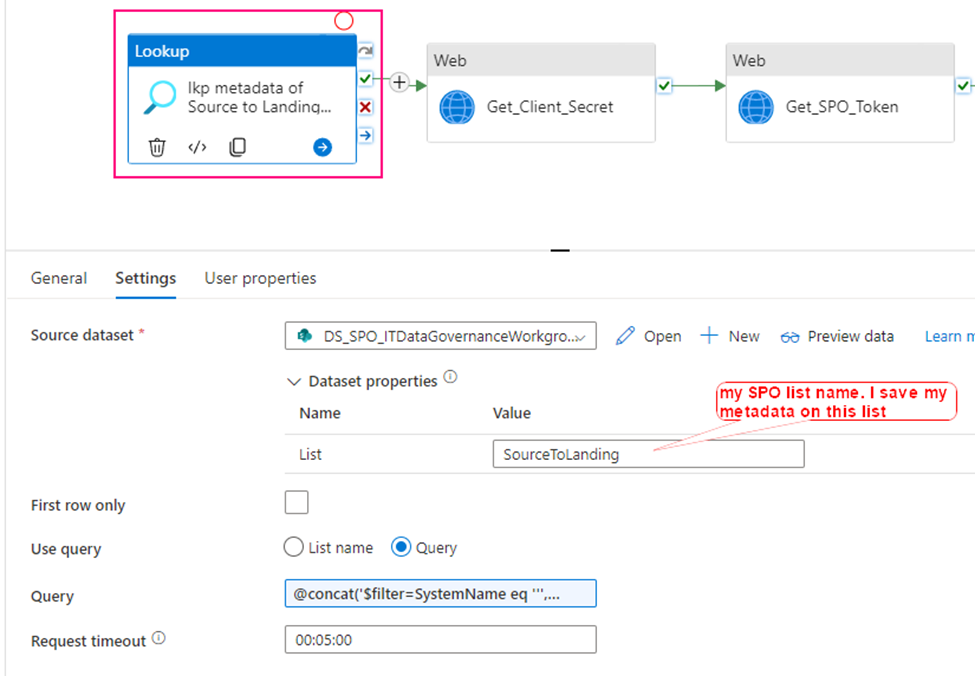
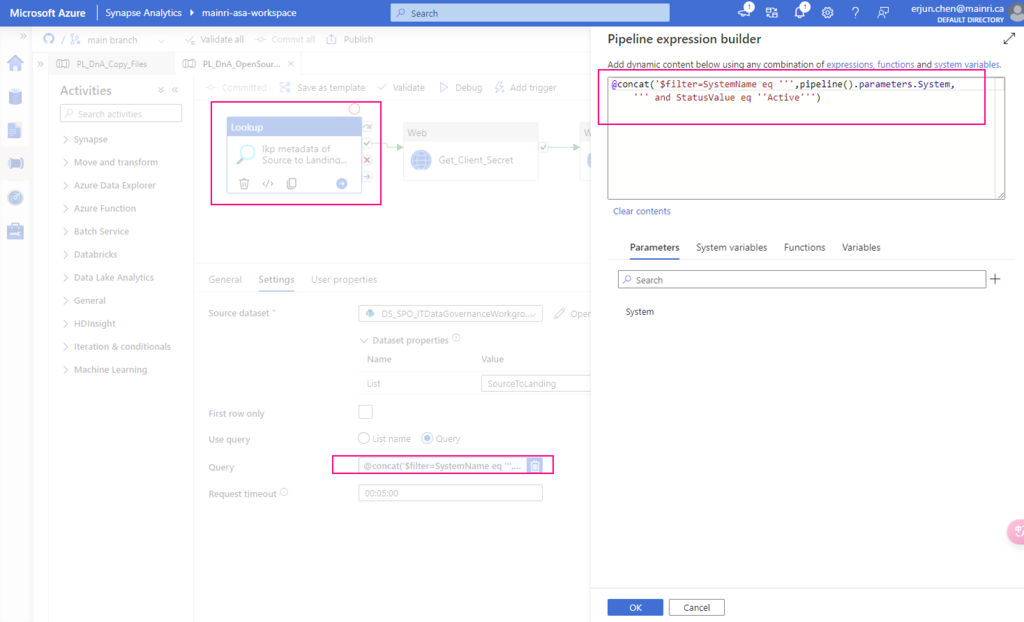
Now, we are ready to configure the Lookup activity
Source dataset: use above created dataset – DS_SPO_ITDataGovernanceWorkgroup
Query: @concat(‘$filter=SystemName eq ”’,pipeline().parameters.System,”’ and StatusValue eq ”Active”’)
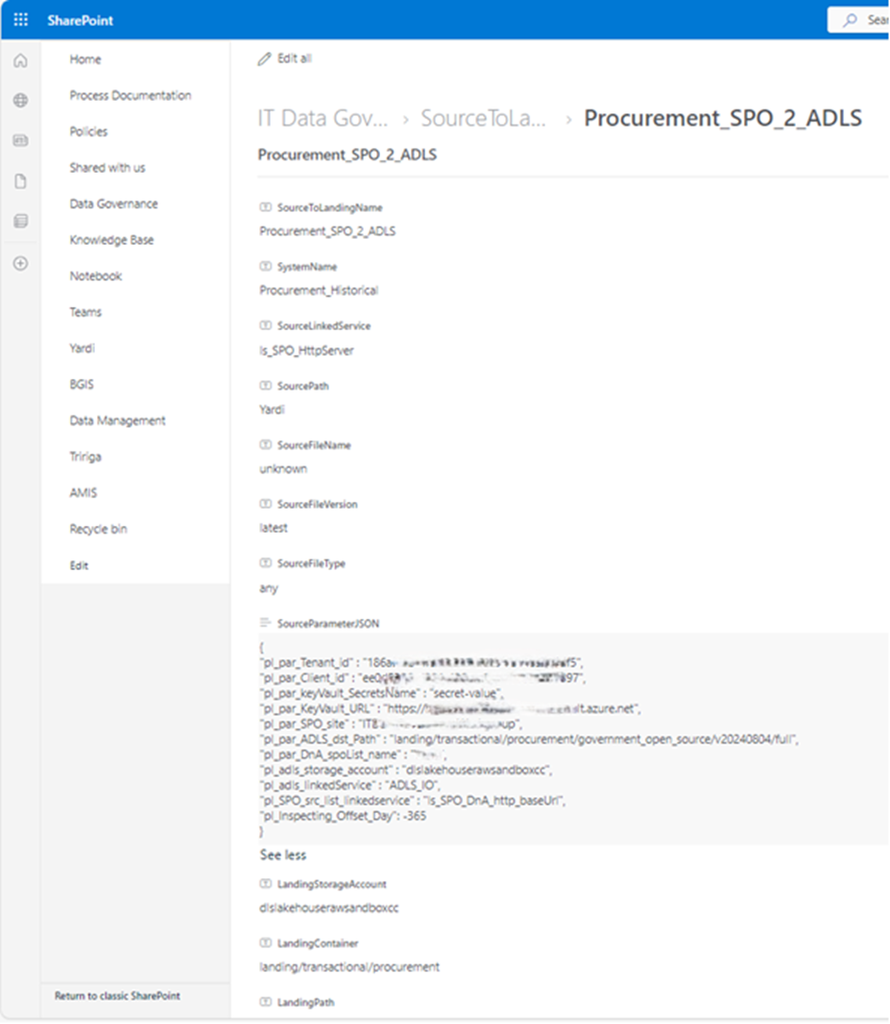
This query filters out my interest SPO list where my metadata saves. My metadata list in SPO looks like this
This lookup activity return metadata retrieved from SPO list. Looks like this.
response is json format. My “SourceParameterJSON” value is string, but it well match json format, could be covert to json.
Step 2:
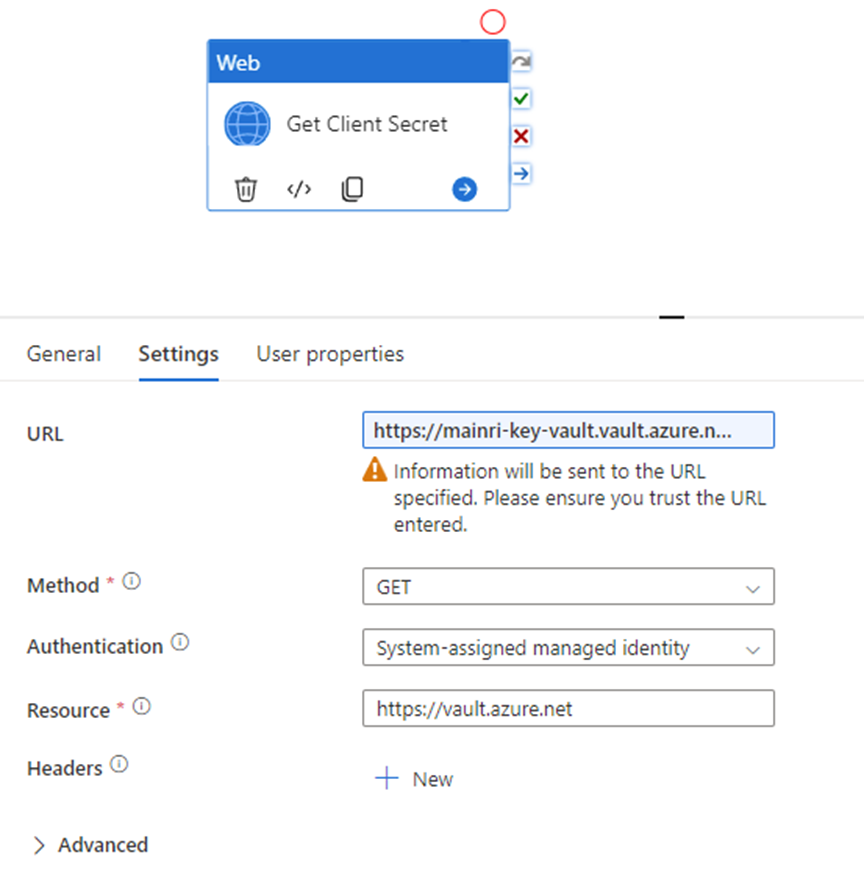
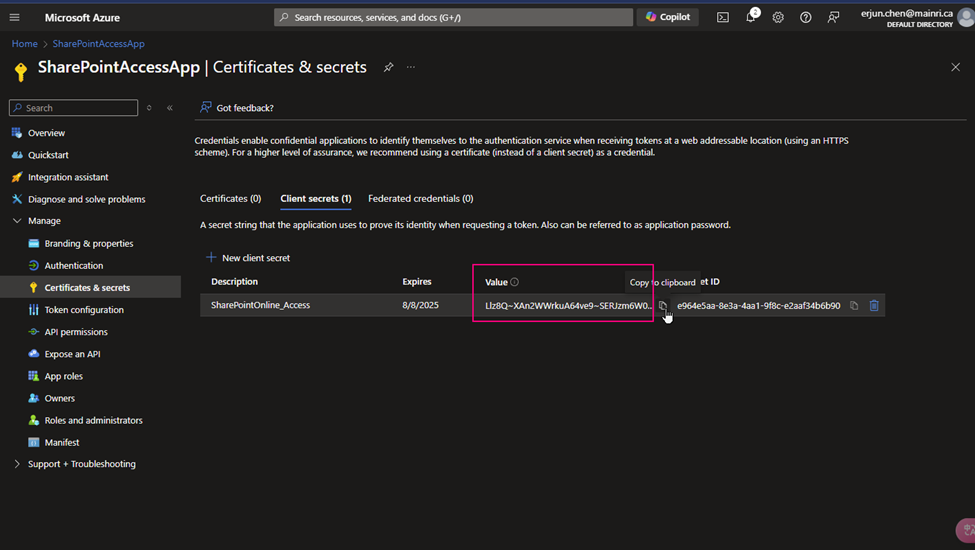
Get Client Secret
To get SPO access token, we need: Tenant ID, Client ID, and Client Secret
Tenant ID: You can get this from Azure Entra ID (former Azure active Directory)
Client ID: When you register your application at Azure Entra ID, azure Entra ID will generate one, called Application ID (Client ID). You can get this from Azure Portal >>Entra ID
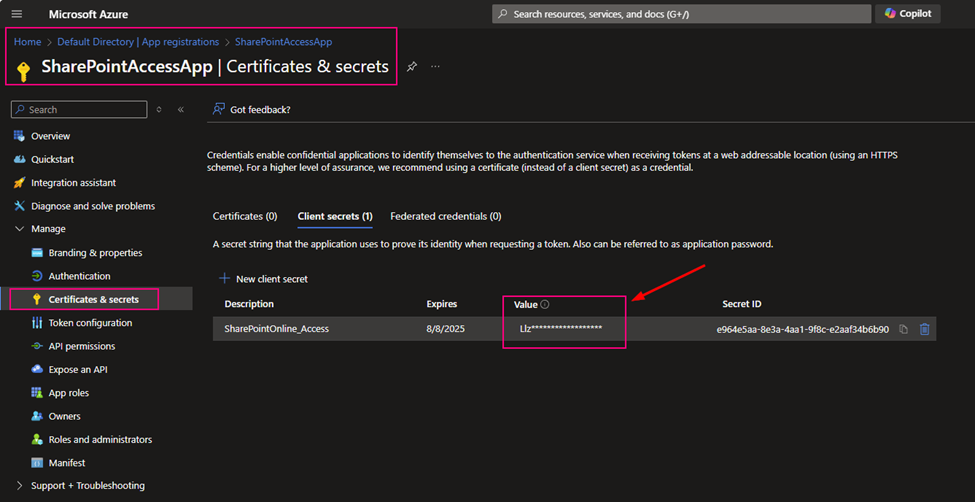
Client Secret: After you registered your application at Azure Entra ID, you build a certificate secret from Azure Entra ID, and you immediately copied and kept that value. The value will not reappear after that process anymore.
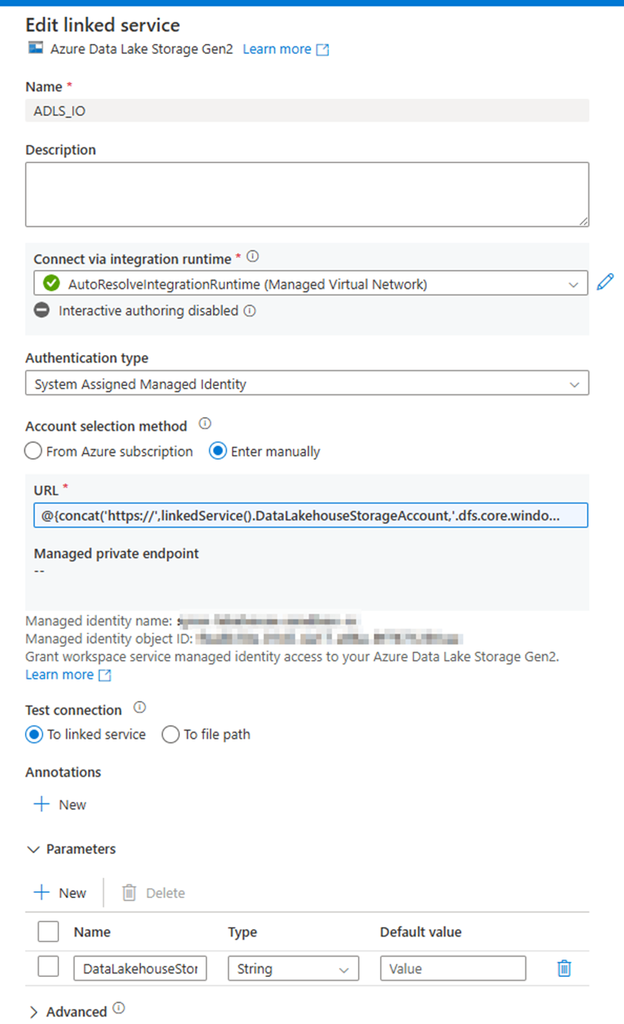
As I mentioned above, my client Secret is saved in azure Key-vault. To get Client Secret, use Web Activity to retrieve Client Secret (if you have the client Secret on hand, you can skip this activity, directly move to next activity Get SPO Token)
Method: GET
Authentication: System Assigned Managed Identity
Resource: https://vault.azure.net
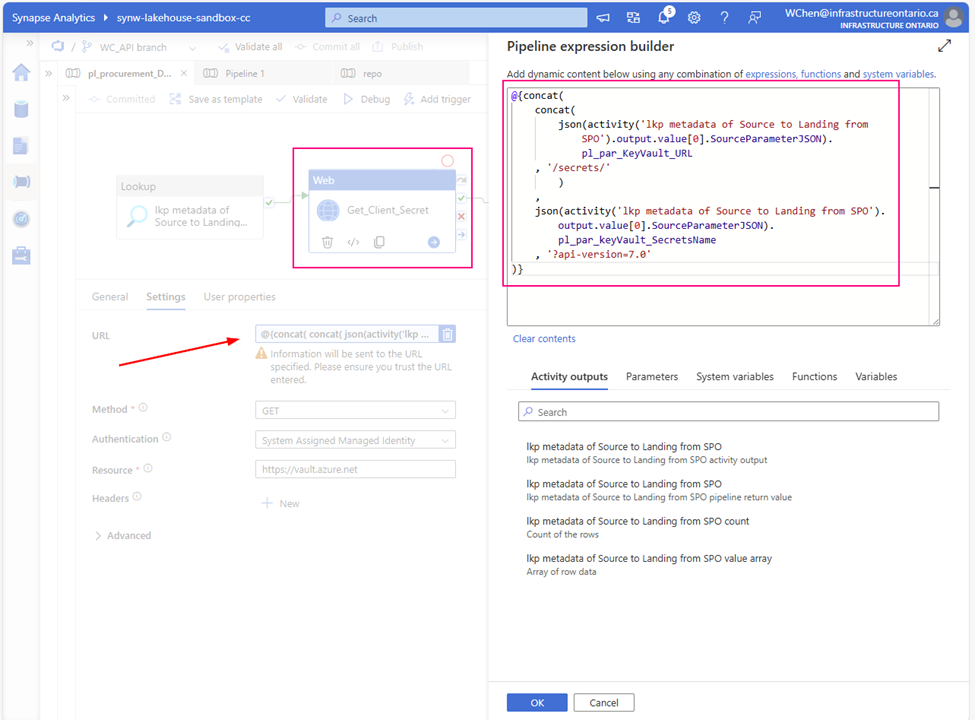
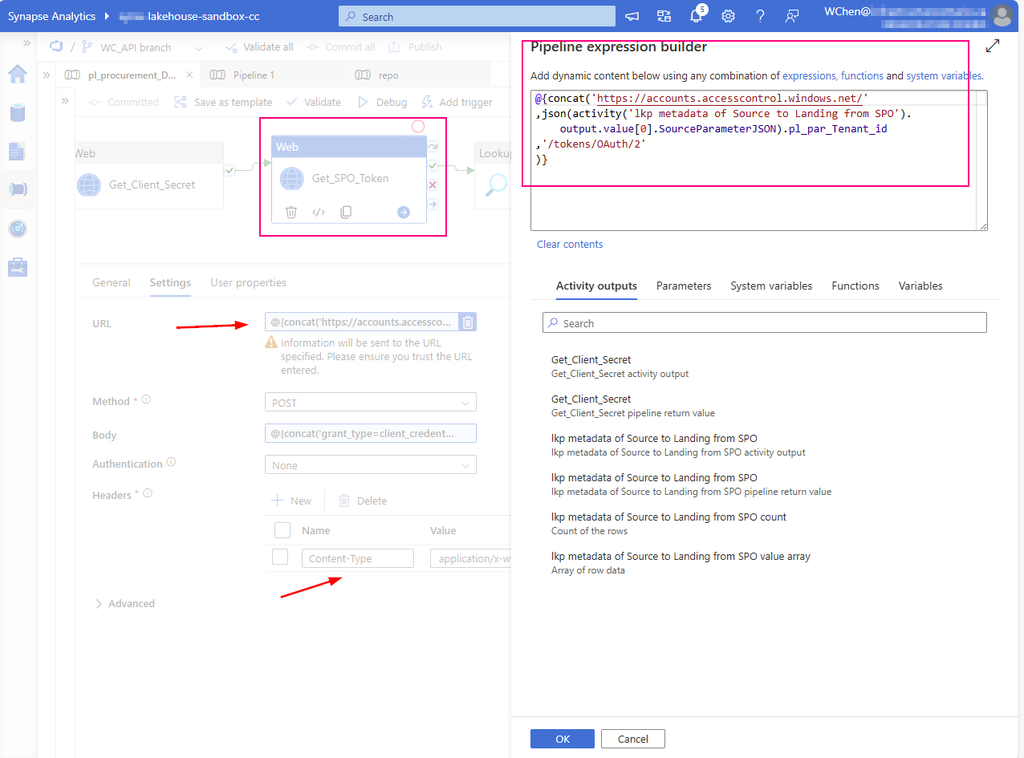
URL:
@{concat( concat( json(activity(‘lkp metadata of Source to Landing from SPO’).output.value[0].SourceParameterJSON).pl_par_KeyVault_URL , ‘/secrets/’ ) , json(activity(‘lkp metadata of Source to Landing from SPO’).output.value[0].SourceParameterJSON).pl_par_keyVault_SecretsName , ‘?api-version=7.0′ )}
Attention: from above URL content, you can see. this SourceParameterJSON section matches well with json format. BUT it is NOT json, it is a string, so I convert the string to json. ?api-version=7.0 is another key point. You must add to your URL
Create a Web Activity to get the access token from SharePoint Online:
URL: https://accounts.accesscontrol.windows.net/[Tenant-ID]/tokens/OAuth/2. Replace the tenant ID.
mine looks : @{concat(‘https://accounts.accesscontrol.windows.net/’ ,json(activity(‘lkp metadata of Source to Landing from SPO’).output.value[0].SourceParameterJSON).pl_par_Tenant_id ,’/tokens/OAuth/2′ )}
Replace the client ID (application ID), client secret (application key), tenant ID, and tenant name (of the SharePoint tenant).
mine looks: @{concat(‘grant_type=client_credentials&client_id=’ , json(activity(‘lkp metadata of Source to Landing from SPO’).output.value[0].SourceParameterJSON).pl_par_Client_id , ‘@’ , json(activity(‘lkp metadata of Source to Landing from SPO’).output.value[0].SourceParameterJSON).pl_par_Tenant_id ,’&client_secret=’ , activity(‘Get_Client_Secret’).output.value , ‘&resource=00000003-0000-0ff1-ce00-000000000000/infrastructureontario.sharepoint.com@’ , json(activity(‘lkp metadata of Source to Landing from SPO’).output.value[0].SourceParameterJSON).pl_par_Tenant_id )}
Attention: As mentioned at Step 2 , pay attention to json convert for section “SourceParameterJSON”
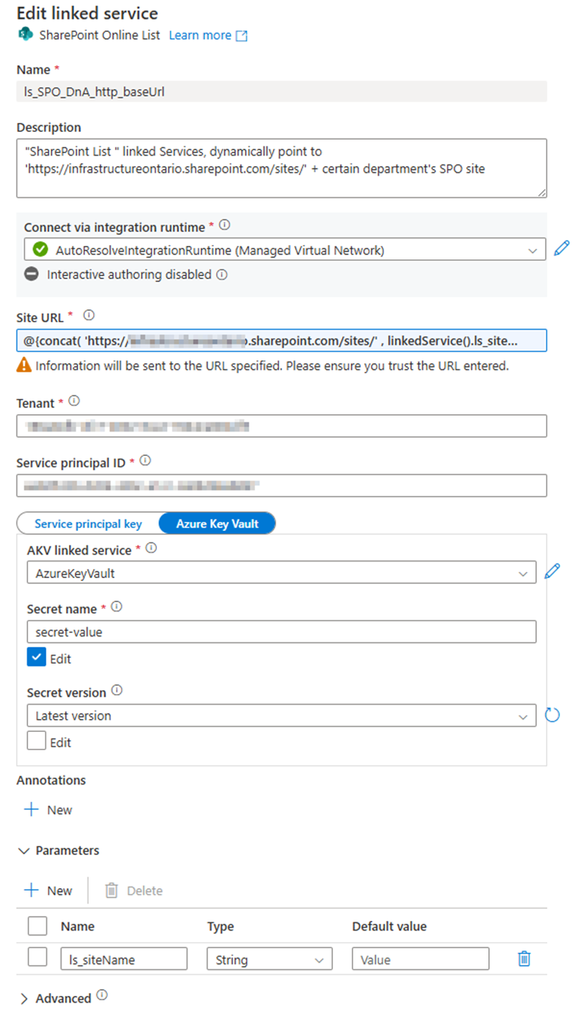
Called: “ls_SPO_DnA_http_baseUrl”, Parameteriz the Linked Service
Provide:
SharePoint site URL Pattern: https://<your domain>.sharepoint.com/sites/<SPO site Name> Replace <your domain> and <SPO site Name> Mine looks: https://mainri.sharepoint.com/sites/dataengineering
Tenant ID
Service principal (or says clientID, applicationID)
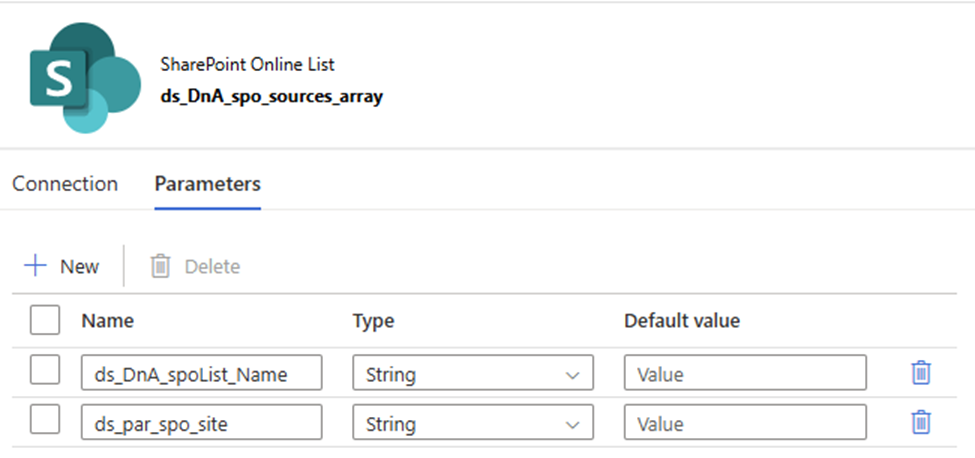
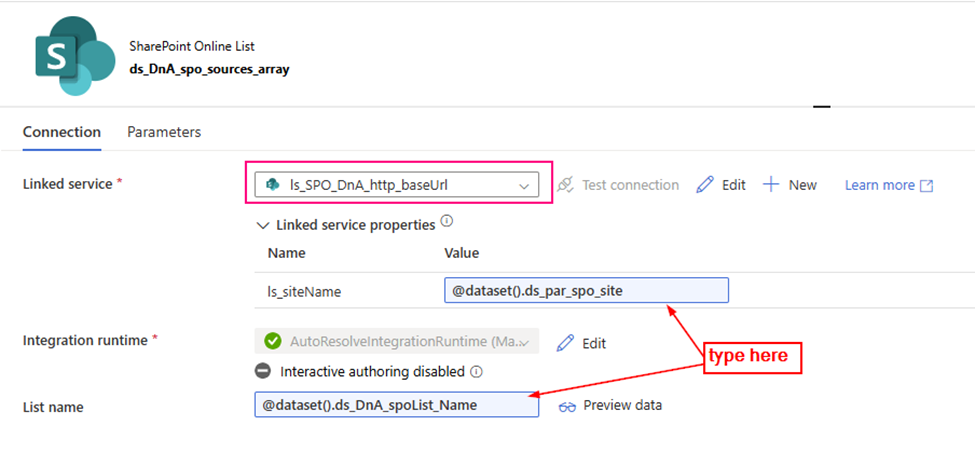
2. Create a SharePoint List type Dataset, Called “ds_DnA_spo_sources_array” and parameteriz the dataset.
Linked service: ls_SPO_DnA_http_baseUrl (you just created)
Parameter:
ds_DnA_spoList_Name
ds_par_spo_site
The dataset looks
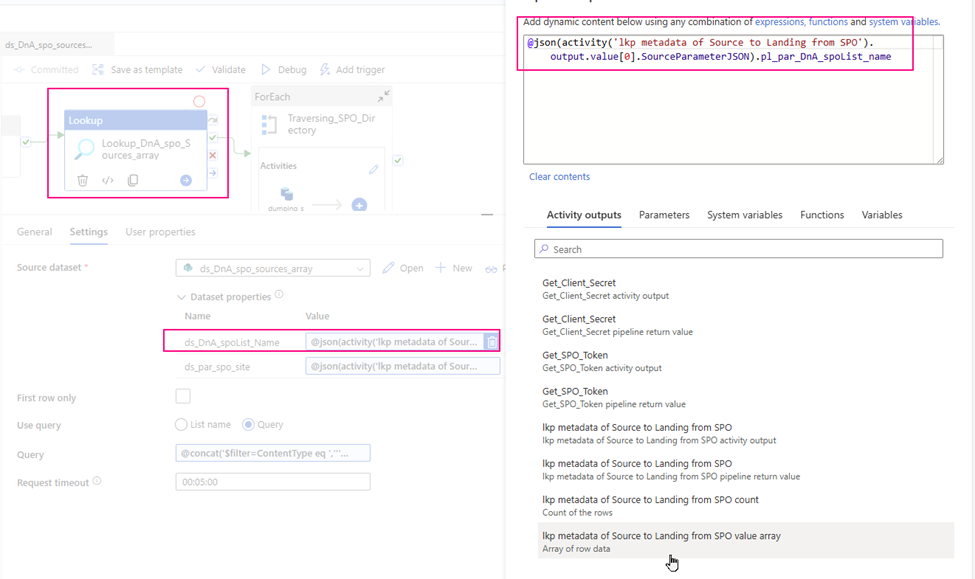
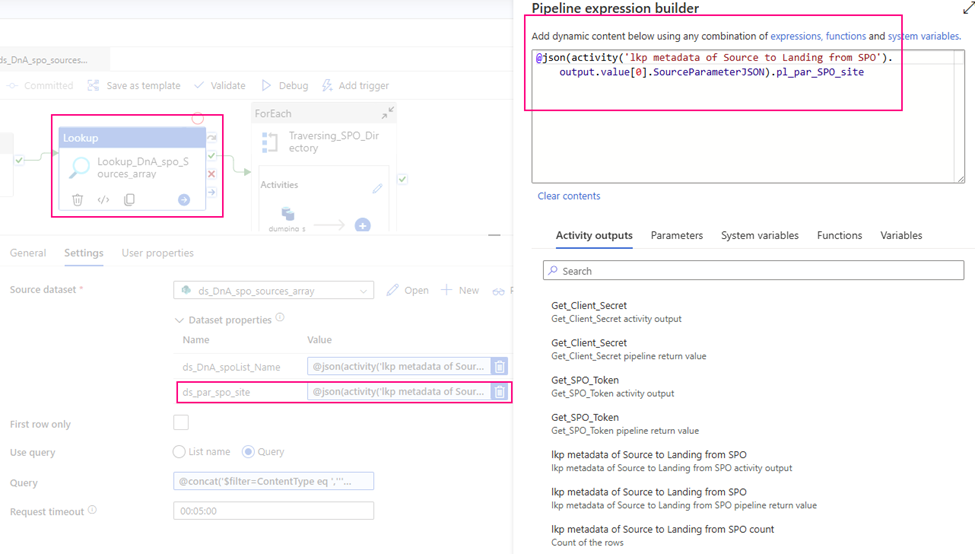
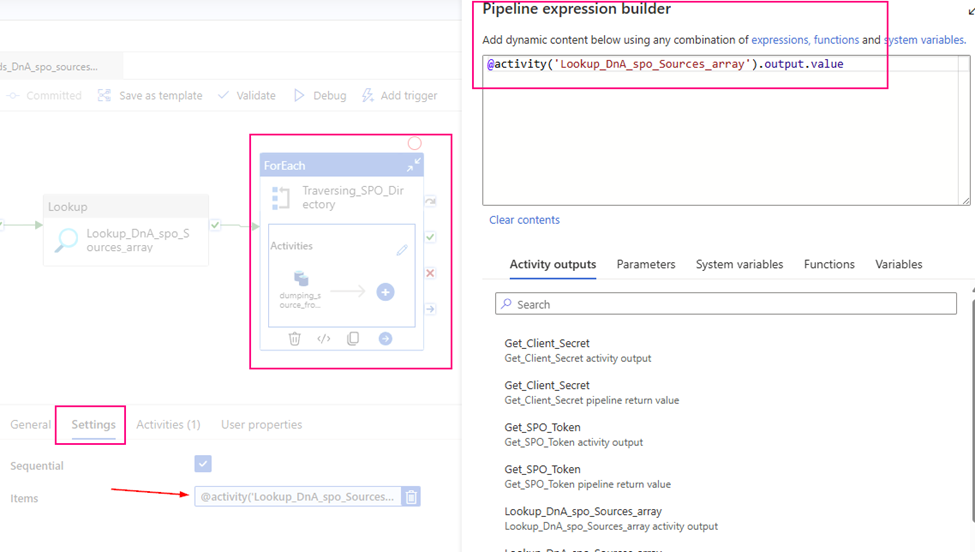
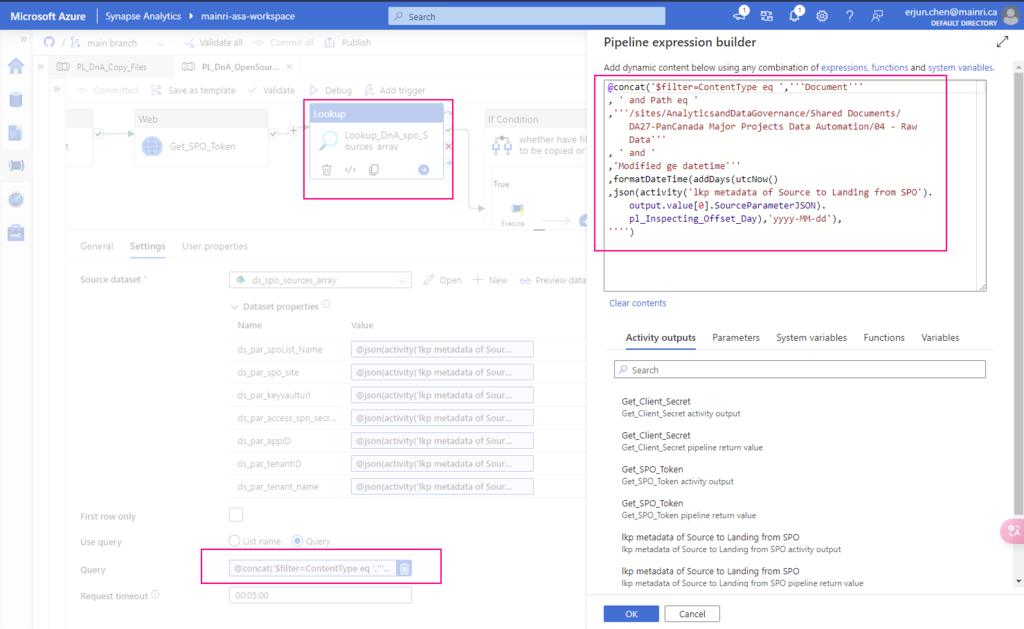
3. configure the Lookup Activity
Use up steam activities return results to configure lookup activity.
source dataset: ds_DnA_spo_sources_array
Dynamic content: ds_DnA_spoList_Name: @json(activity(‘lkp metadata of Source to Landing from SPO’).output.value[0].SourceParameterJSON).pl_par_DnA_spoList_name
ds_par_spo_site: @json(activity(‘lkp metadata of Source to Landing from SPO’).output.value[0].SourceParameterJSON).pl_par_SPO_site
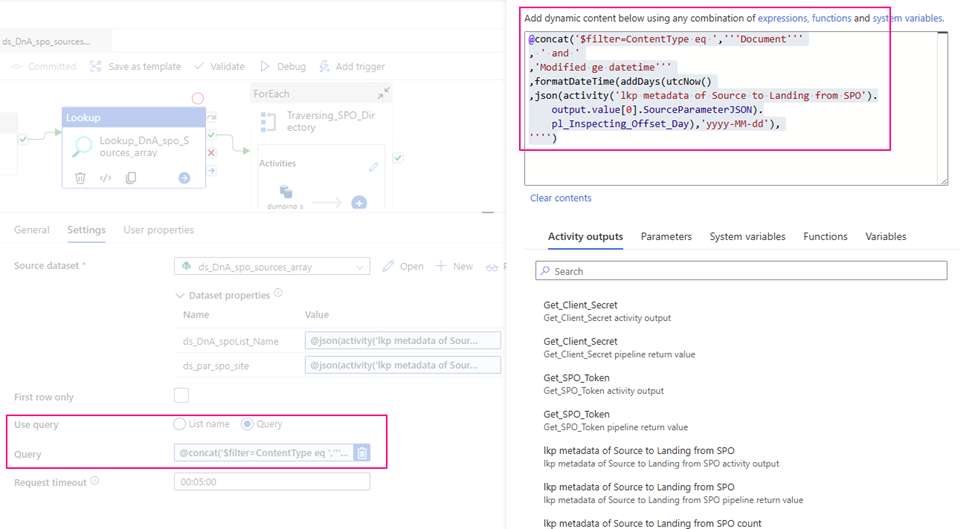
Query: I incrementally ingest data, so I use query to filter out interest items only.
@concat(‘$filter=ContentType eq ‘,”’Document”’ , ‘ and ‘ ,’Modified ge datetime”’ ,formatDateTime(addDays(utcNow() ,json(activity(‘lkp metadata of Source to Landing from SPO’).output.value[0].SourceParameterJSON).pl_Inspecting_Offset_Day),’yyyy-MM-dd’), ””)
The value of ‘GetFileByServerRelativeUrl’ is our key point of work. It points to the specific URL location of the dataset. In fact, all upstream work efforts are aimed at generating specific content for this link item!
Cheers, we are almost there!
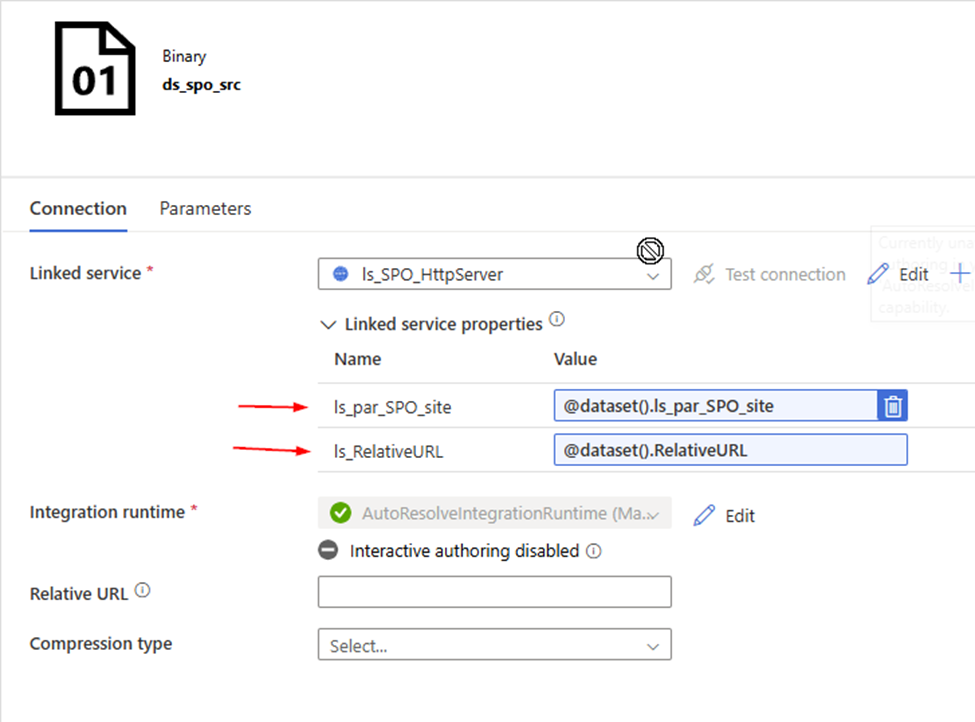
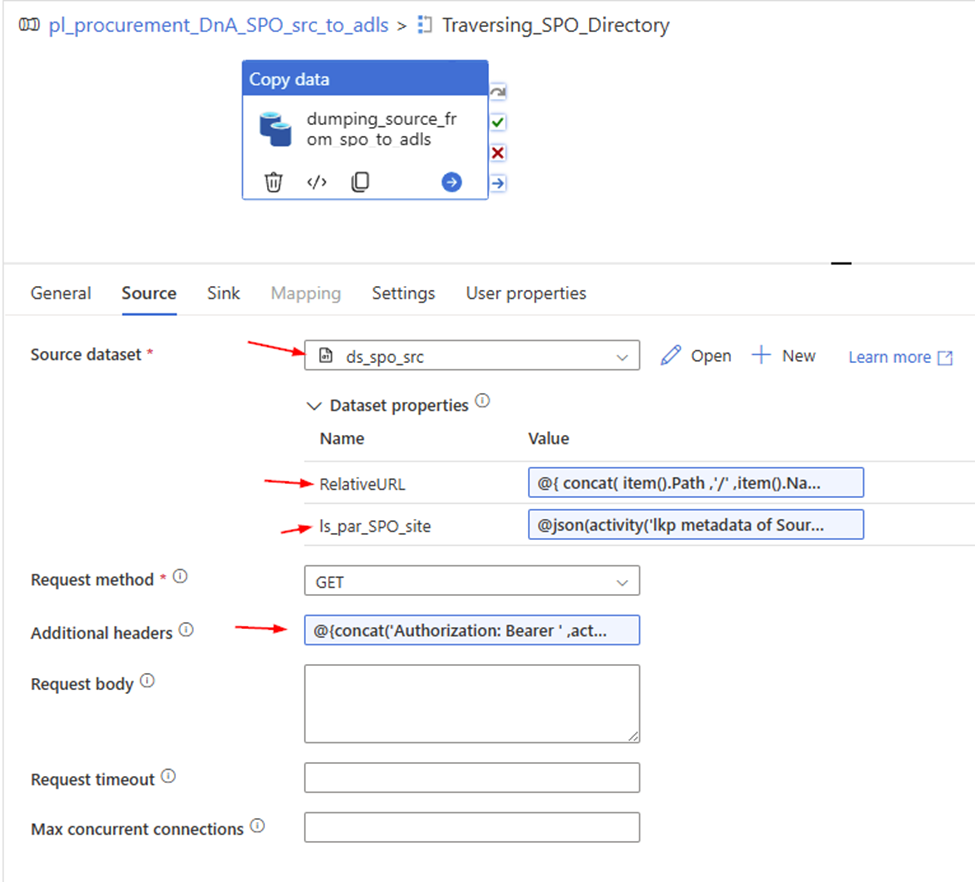
2. Create a Http Binary source dataset , called “ds_spo_src”, Parameterize it
Parameter: RelativeURL ls_par_SPO_site
Linked Service: ls_SPO_HttpServer , we just created.
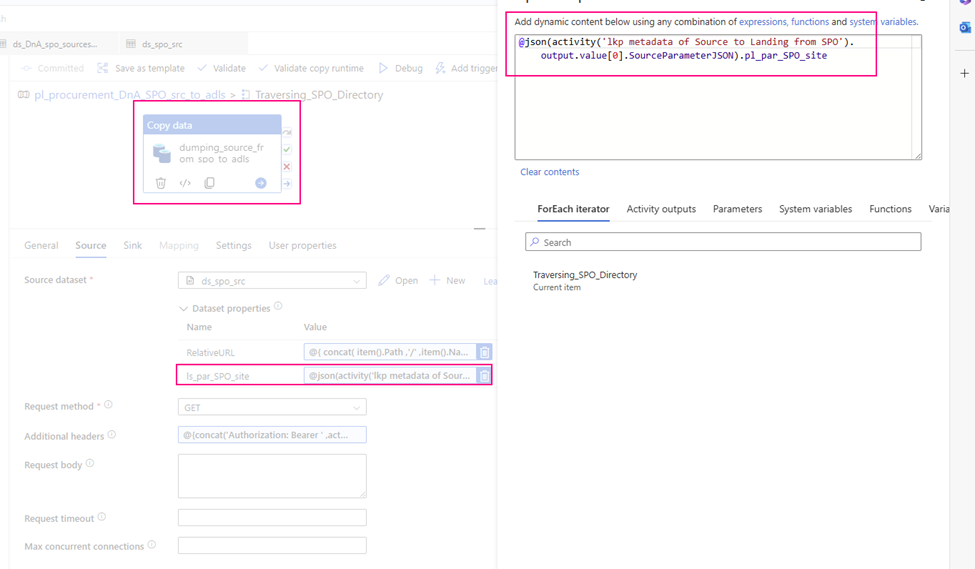
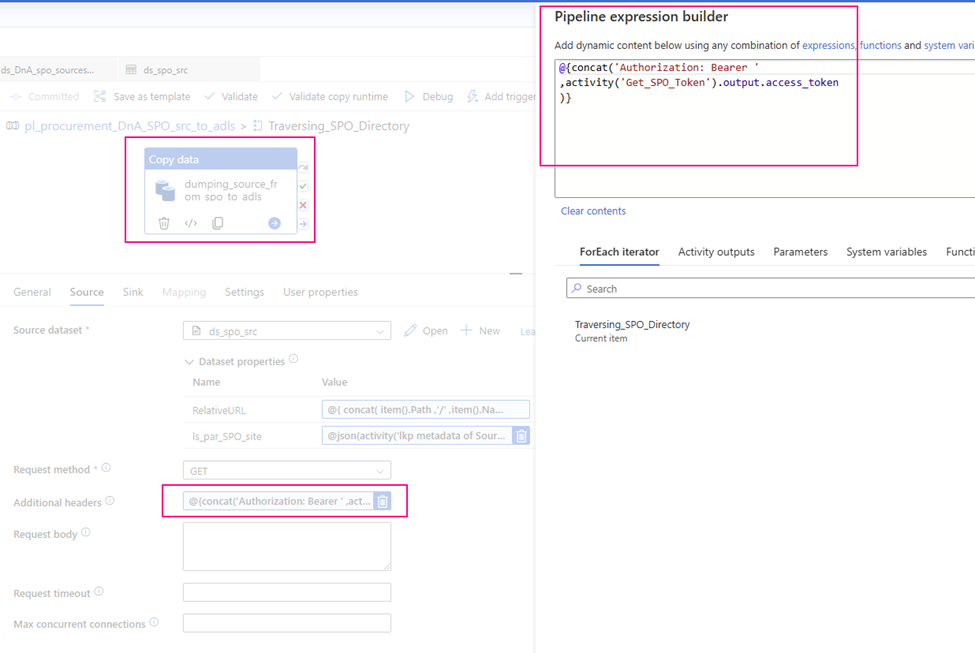
3. Configure copy activity’s “Source”
Request method: GET
Source dataset: ds_spo_src
RelativeURL:
@{ concat( item().Path ,’/’ ,item().Name ) }
ls_par_SPO_site:
@json(activity(‘lkp metadata of Source to Landing from SPO’).output.value[0].SourceParameterJSON).pl_par_SPO_site
This article is focused on ADF or ASA lookup activity filter modified date, type, is Current version or not etc. query for SharePoint Online List.
Scenario:
Many organizations like to save data on SharePoint Online site, especially metadata. To incrementally extract the latest or certain date ranges modified data from SharePoint Online (SPO) we need to filter the modified date and inspect whether it is the latest version or not.
For example, there are items (documents, folders, ……) reside on SharePoint Online, items property looks like:
We want to know whether they are modified after a certain date, the latest version?, is it a document or folder etc. we need to check when we retrieve it from SharePoint Online we will get json response.
Let’s begin.
Solution:
In this article, we focus on the Lookup Activity only, especially on lookup query content. Not only I will ignore lookup’s other configurations, but also skip other activities steps from the pipeline. Such as how to access SPO, how to extract data SPO how to sink to destination ….
If you are interested in those and want to know more in detail, please review my previous articles:
2) Check items on SPO modified “DATE” and type is “document”
Copy Activity: Lookup_DnA_spo_Sources_array
This lookup activity filter items that save in SharePoint Library:
ContentTyep = Document;
FIle Saving Path = /sites/AnalyticsandDataGovernance/Shared Documents/DA27-PanCanada Major Projects Data Automation/04 – Raw Data that means, I look up the files save at this path only.
file’s Modified >= pre-set offset day
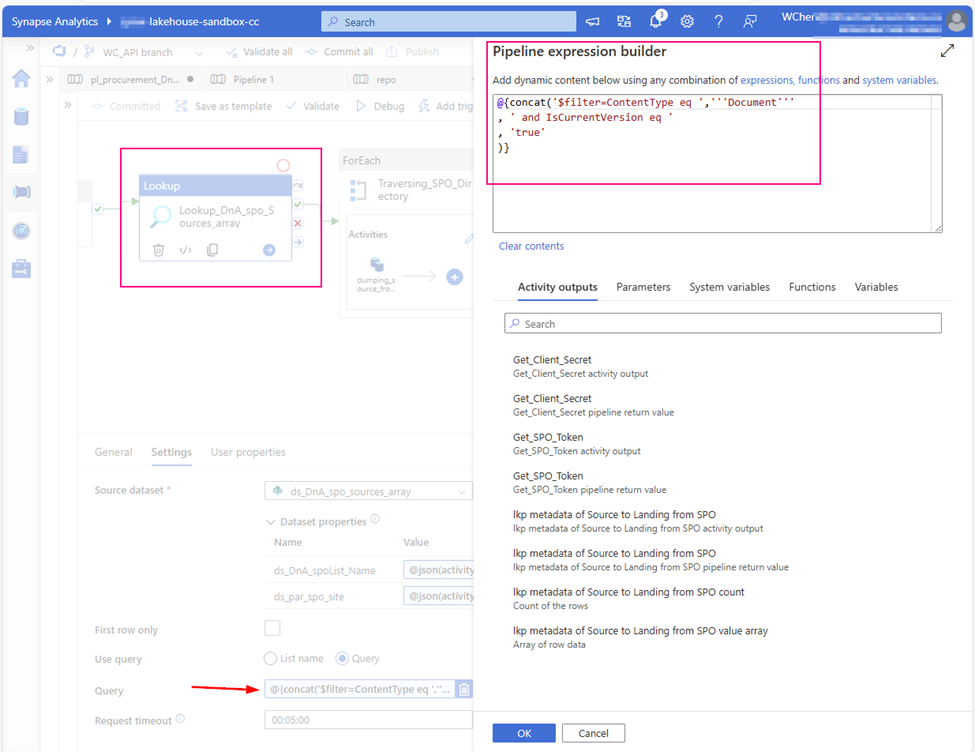
@concat('$filter=ContentType eq ','''Document''', ' and Path eq ','''/sites/AnalyticsandDataGovernance/Shared Documents/DA27-PanCanada Major Projects Data Automation/04 - Raw Data''', ' and ','Modified ge datetime''',formatDateTime(addDays(utcNow(),json(activity('lkp metadata of Source to Landing from SPO').output.value[0].SourceParameterJSON).pl_Inspecting_Offset_Day),'yyyy-MM-dd'),'''')
Here, I use “offset” conception, it is a poperty I save on SPO list. Of course, you can provide this offset value in many ways, such as pipeline parameter, save in SQL table, save in a file ….etc. wherever you like.
For example, you incrementally ingest data on daily basis,
the offset = -1 weekly basis, offset = -7 Ten days, customized period, offset = -10 ……… etc.
one more example. if you want to check items saved in SPO “isCurrentVersion” or not and type is “document”