from pyspark.sql.functions import array_contains
# Using array_contains to check if the array contains 'apple'
df.select("id", array_contains("fruits", "apple").alias("has_apple")).show()
==output==
+---+----------+
| id|has_apple |
+---+----------+
| 1| true|
| 2| true|
| 3| false|
+---+----------+
getItem()
Access individual elements of an array by their index using the getItem() method
# Select the second element (index start from 0) of the 'numbers' array
df1 = df.withColumn("item_1_value", df.numbers.getItem(1))
display(df1)
==output==
id numbers item_1_value
1 [1,2,3] 2
2 [4,5,6] 5
3 [7,8,9] 8
size ()
Returns the size of the array.
from pyspark.sql.functions import size
# Get the size of the 'numbers' array
df.select(size(df.numbers)).show()
==output==
+-------------+
|size(numbers)|
+-------------+
| 3|
| 3|
| 3|
+-------------+
sort_array()
Sorts the array elements.
sort_array(col: ‘ColumnOrName’, asc: bool = True)
If `asc` is True (default) then ascending and if False then descending. if asc=True, can be omitted.
concat() is used to concatenate arrays (or strings) into a single array (or string). When dealing with ArrayType, concat() is typically used to combine two or more arrays into one.
from pyspark.sql.functions import concat concat(*cols)
If any of the input columns are null, the entire result can become null. This is why you’re seeing null instead of just the non-null array.
To handle this, you can use coalesce() to substitute null with an empty array before performing the concat(). coalesce() returns the first non-null argument. Here’s how you can modify your code:
from pyspark.sql.functions import concat, coalesce, lit
# Define an empty array for the same type
empty_array = array()
# Concatenate with null handling using coalesce
df_concat = df.withColumn(
"concatenated_array",
concat(coalesce(col("array1"), empty_array), coalesce(col("array2"), empty_array))
)
df_concat.show(truncate=False)
==output==
+---+------+------+------------------+
|id |array1|array2|concatenated_array|
+---+------+------+------------------+
|1 |[a, b]|[x, y]|[a, b, x, y] |
|2 |[c] |[z] |[c, z] |
|3 |[d, e]|null |[d, e] |
+---+------+------+------------------+
array_zip ()
Combines arrays into a single array of structs.
☰ MapType column, and functions
MapType is used to represent map key-value pair similar to python Dictionary (Dic)
from pyspark.sql.types import MapType, StringType, IntegerType # Define a MapType my_map = MapType(StringType(), IntegerType(), valueContainsNull=True)
Parameters:
keyType: Data type of the keys in the map. You can use PySpark data types like StringType(), IntegerType(), DoubleType(), etc.
valueType: Data type of the values in the map. It can be any valid PySpark data type
valueContainsNull: Boolean flag (optional). It indicates whether null values are allowed in the map. Default is True.
sample dataset # Sample dataset (Product ID and prices in various currencies) data = [ (1, {“USD”: 100, “EUR”: 85, “GBP”: 75}), (2, {“USD”: 150, “EUR”: 130, “GBP”: 110}), (3, {“USD”: 200, “EUR”: 170, “GBP”: 150}), ]
To get the price for a specific currency (e.g., USD) for each product:
from pyspark.sql.functions import col, map_keys, map_values
# Access the value for a specific key in the map
df.select(
col("product_id"),
col("prices").getItem("USD").alias("price_in_usd")
).show(truncate=False)
==output==
+----------+------------+
|product_id|price_in_usd|
+----------+------------+
|1 |100 |
|2 |150 |
|3 |200 |
+----------+------------+
filtering
filter the rows based on conditions involving the map values
from pyspark.sql.functions import col, map_keys, map_values
# Filter rows where price in USD is greater than 150
df.filter(col("prices").getItem("USD") > 150).show(truncate=False)
==output==
+----------+------------------------------------+
|product_id|prices |
+----------+------------------------------------+
|3 |{EUR -> 170, GBP -> 150, USD -> 200}|
+----------+------------------------------------+
map_concat ()
Combines two or more map columns by merging their key-value pairs.
from pyspark.sql.functions import map_concat, create_map, lit
# Define the additional currency as a new map using create_map()
additional_currency = create_map(lit("CAD"), lit(120))
# Add a new currency (e.g., CAD) with a fixed price to all rows
df.withColumn(
"updated_prices",
map_concat(col("prices"), additional_currency)
).show(truncate=False)
==output==
+----------+------------------------------------+
|product_id|prices |
+----------+------------------------------------+
|3 |{EUR -> 170, GBP -> 150, USD -> 200}|
+----------+------------------------------------+
existingName: The current name of the column you want to rename. newName: The new name for the column.
drop ()
In PySpark, you can drop columns from a DataFrame using the drop() method. Here’s a breakdown of the syntax, options, parameters, and examples for dropping columns in PySpark.
Syntax
DataFrame.drop(*cols)
*cols: One or more column names (as strings) that you want to drop from the DataFrame. You can pass these as individual arguments or a list of column names.
# Drop single column 'age'
df_dropped = df.drop("age")
# Drop multiple columns 'id' and 'age'
df_dropped_multiple = df.drop("id", "age")
# Dropping Columns Using a List of Column Names
# Define columns to drop
columns_to_drop = ["id", "age"]
# Drop columns using list
df_dropped_list = df.drop(*columns_to_drop)
df_dropped_list.show()
Show()
By default, display 20 row, truncate 20 characters
If a Delta table is saved in Blob Storage or Azure Data Lake Storage (ADLS), you access it using the file path rather than a cataloged name (like in Unity Catalog). Here’s how to read from and write to Delta tables stored in Blob Storage or ADLS in Spark SQL and PySpark.
Reading Delta Tables from Blob Storage or ADLS
To read Delta tables from Blob Storage or ADLS, you specify the path to the Delta table and use the delta. format.
When writing to Delta tables, use the delta format and specify the path where you want to store the table.
Spark SQL cannot directly write to a Delta table in Blob or ADLS (use PySpark for this). However, you can run SQL queries and insert into a Delta table using INSERT INTO:
# SparkSQL
INSERT INTO delta.`/mnt/path/to/delta/table`SELECT * FROM my_temp_table
caution: " ` " - backticks
# PySpark
df.write.format("delta").mode("overwrite").save("path/to/delta/table")
Options and Parameters for Delta Read/Write
Options for Reading Delta Tables:
You can configure the read operation with options like:
mergeSchema: Allows schema evolution if the structure of the Delta table changes.
spark.sql.files.ignoreCorruptFiles: Ignores corrupt files during reading.
timeTravel: Enables querying older versions of the Delta table.
Delta supports time travel, allowing you to query previous versions of the data. This is very useful for audits or retrieving data at a specific point in time.
# Read from a specific version
df = spark.read.format("delta").option("versionAsOf", 2).load("path/to/delta/table")
df.show()
# Read data at a specific timestamp
df = spark.read.format("delta").option("timestampAsOf", "2024-10-01").load("path/to/delta/table")
df.show()
Conclusion:
Delta is a powerful format that works well with ADLS or Blob Storage when used with PySpark.
Ensure that you’re using the Delta Lake library to access Delta features, like ACID transactions, schema enforcement, and time travel.
For reading, use .format("delta").load("path").
For writing, use .write.format("delta").save("path").
To read from and write to Unity Catalog in PySpark, you typically work with tables registered in the catalog rather than directly with file paths. Unity Catalog tables can be accessed using the format catalog_name.schema_name.table_name.
Reading from Unity Catalog
To read a table from Unity Catalog, specify the table’s full path:
# Reading a table
df = spark.read.table("catalog.schema.table")
df.show()
# Using Spark SQL
df = spark.sql("SELECT * FROM catalog.schema.table")
Writing to Unity Catalog
To write data to Unity Catalog, you specify the table name in the saveAsTable method:
# Writing a DataFrame to a new table
df.write.format("delta") \
.mode("overwrite") \
.saveAsTable("catalog.schema.new_table")
Options for Writing to Unity Catalog:
format: Set to "delta" for Delta Lake tables, as Unity Catalog uses Delta format.
mode: Options include overwrite, append, ignore, and error.
Example: Read, Transform, and Write Back to Unity Catalog
# Read data from a Unity Catalog table
df = spark.read.table("catalog_name.schema_name.source_table")
# Perform transformations
transformed_df = df.filter(df["column_name"] > 10)
# Write transformed data back to a different table
transformed_df.write.format("delta") \
.mode("overwrite") \
.saveAsTable("catalog_name.schema_name.target_table")
Lacks built-in schema enforcement; additional steps needed for ACID or schema evolution.
Detailed Comparison and Notes:
Unity Catalog
Delta: Unity Catalog fully supports Delta format, allowing for schema evolution, ACID transactions, and built-in security and governance.
JSON and CSV: To use JSON or CSV in Unity Catalog, convert them into Delta tables or load them as temporary views before making them part of Unity’s governed catalog. This is because Unity Catalog enforces structured data formats with schema definitions.
Blob Storage & ADLS (Azure Data Lake Storage)
Delta: Blob Storage and ADLS support Delta tables if the Delta Lake library is enabled. Delta on Blob or ADLS retains most Delta features but may lack some governance capabilities found in Unity Catalog.
JSON & CSV: Both Blob and ADLS provide support for JSON and CSV formats, allowing flexibility with semi-structured data. However, they do not inherently support schema enforcement, ACID compliance, or governance features without Delta Lake.
Delta Table Benefits:
Schema Evolution and Enforcement: Delta enables schema evolution, essential in big data environments.
Time Travel: Delta provides versioning, allowing access to past versions of data.
ACID Transactions: Delta ensures consistency and reliability in large-scale data processing.
from_json() is a function used to parse a JSON string into a structured DataFrame format (such as StructType, ArrayType, etc.). It is commonly used to deserialize JSON strings stored in a DataFrame column into complex types that PySpark can work with more easily.
Syntax
from_json(column, schema, options={})
Parameters
column: The column containing the JSON string. Can be a string that refers to the column name or a column object.
schema
Specifies the schema of the expected JSON structure. Can be a StructType (or other types like ArrayType depending on the JSON structure).
options
allowUnquotedFieldNames: Allows field names without quotes. (default: false)
allowNumericLeadingZeros: Allows leading zeros in numbers. (default: false)
allowBackslashEscapingAnyCharacter: Allows escaping any character with a backslash. (default: false)
mode: Controls how to handle malformed records PERMISSIVE: The default mode that sets null values for corrupted fields. DROPMALFORMED: Discards rows with malformed JSON strings. FAILFAST: Fails the query if any malformed records are found.
Sample DF
+----------------------------+
|json_string |
+----------------------------+
|{"name": "John", "age": 30} |
|{"name": "Alice", "age": 25}|
+----------------------------+
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, StructType
from pyspark.sql.functions import from_json, col
# Define the schema for the nested JSON
schema = StructType([
StructField("name", StructType([
StructField("first", StringType(), True),
StructField("last", StringType(), True)
]), True),
StructField("age", IntegerType(), True)
])
# Parse the JSON string into structured columns
df_parsed = df.withColumn("parsed_json", from_json(col("json_string"), schema))
# Display the parsed JSON
df_parsed.select("parsed_json.*").show(truncate=False)
+--------+---+
| name |age|
+--------+---+
|{John, Doe}|30|
|{Alice, Smith}|25|
+--------+---+
to_json()
to_json() is a function that converts a structured column (such as one of type StructType, ArrayType, etc.) into a JSON string.
Syntax
to_json(column, options={})
Parameters
column: The column you want to convert into a JSON string. The column should be of a complex data type, such as StructType, ArrayType, or MapType. Can be a column name (as a string) or a Column object.
options
pretty: If set to true, it pretty-prints the JSON output.
dateFormat: Specifies the format for DateType and TimestampType columns (default: yyyy-MM-dd).
timestampFormat: Specifies the format for TimestampType columns (default: yyyy-MM-dd'T'HH:mm:ss.SSSXXX).
ignoreNullFields: When set to true, null fields are omitted from the resulting JSON string (default: true).
compression: Controls the compression codec used to compress the JSON output, e.g., gzip, bzip2.
Usage: transform() is a higher-order function available in PySpark that applies a custom function element-wise to each element in an array column. It’s a DataFrame-specific function that is mainly used for manipulating array elements in a column.
Performance: Since transform() operates natively within Spark’s execution engine, it is highly optimized. It avoids the performance overhead that comes with using UDFs.
udf ()
Usage: udf() allows you to define and apply a user-defined function to a column or multiple columns. It can be used for more general-purpose operations, applying Python functions to rows or columns that don’t necessarily need to be array types.
Performance: UDFs in PySpark are not optimized as they run Python code within the JVM context, which introduces significant overhead due to serialization and deserialization (data is transferred between Python and JVM).
Side by side comparison
Function Type
Higher-order function
User-defined function (UDF)
Purpose
Apply a function element-wise to array columns
Apply custom Python logic to any column or columns
Performance
Highly optimized, uses Spark’s Catalyst engine
Slower, incurs overhead due to Python-JVM communication
Supported Data Types
Arrays (array of elements in a column)
Any data type (strings, integers, arrays, etc.)
Return Type
Returns native Spark types
Can return complex types but requires explicit return type definition
Ease of Use
Simple to use for array-specific transformations
Flexible but requires registering the function and specifying return types
Serialization Overhead
No overhead (operates entirely within Spark engine)
Significant overhead as data moves between Python and JVM
When to Use
– When you have an array column and need to modify each element – For array transformations with high performance
– When complex logic is required that cannot be expressed using native PySpark functions – When you need full flexibility for applying custom logic to various data types
Flexibility
Limited to arrays and simple element-wise operations
Very flexible, can handle any data type and complex custom logic
Parallelism
Uses Spark’s internal optimizations for parallelism
Python UDFs don’t leverage full Spark optimizations and may run slower
Built-in Functions
Can use SQL expressions or anonymous functions
Requires explicit Python code, even for simple operations
Example
python df.withColumn("squared_numbers", F.expr("transform(numbers, x -> x * x)"))
May require extra effort to handle errors within the UDF logic
Use Case Limitations
– Only for array column manipulation
– Can be used on any column type but slower compared to native functions
Key Takeaway
transform() is faster and preferred for operations on array columns when the logic is simple and can be expressed within Spark’s native functions.
udf() provides the flexibility to handle more complex and custom transformations but comes at a performance cost, so it should be used when necessary and avoided if native Spark functions can achieve the task.
StructType() in PySpark is part of the pyspark.sql.types module and it is used to define the structure of a DataFrame schema. StructField () is a fundamental part of PySpark’s StructType, used to define individual fields (columns) within a schema. A StructField specifies the name, data type, and other attributes of a column in a DataFrame schema.
fields (optional): A list of StructField objects that define the schema. Each StructField object specifies the name, type, and whether the field can be null.
Key Components
name: The name of the column.
dataType: The data type of the column (e.g., StringType(), IntegerType(), DoubleType(), etc.).
nullable: Boolean flag indicating whether the field can contain null values (True for nullable).
Common Data Types Used in StructField
StringType(): Used for string data.
IntegerType(): For integers.
DoubleType(): For floating-point numbers.
LongType(): For long integers.
ArrayType(): For arrays (lists) of values.
MapType(): For key-value pairs (dictionaries).
TimestampType(): For timestamp fields.
BooleanType(): For boolean values (True/False).
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
# Initialize Spark session
spark = SparkSession.builder.appName("Example").getOrCreate()
# Define schema using StructTypeschema = StructType([
StructField("name", StringType(), True),
StructField("age", IntegerType(), True)
])
# Create DataFrame using the schema
data = [("John", 30), ("Alice", 25)]
df = spark.createDataFrame(data, schema)
df.show()
+-----+---+
| name|age|
+-----+---+
| John| 30|
|Alice| 25|
+-----+---+
Nested Schema
StructType can define a nested schema. For example, a column in the DataFrame might itself contain multiple fields.
The contains() function in PySpark is used to check if a string column contains a specific substring. It’s typically used in a filter() or select() operation to search within the contents of a column and return rows where the condition is true.
Syntax
Column.contains(substring: str)
Key Points
contains() is case-sensitive by default. For case-insensitive matching, use it with lower() or upper().
It works on string columns only. For non-string columns, you would need to cast the column to a string first.
The collect () function simply gathers all rows from the DataFrame or RDD and returns them as a list of Row objects. It does not accept any parameters.
Syntax
DataFrame.collect() not any parameter at all
Key Points
Use on Small Data: Since collect() brings all the data to the driver, it should be used only on small datasets. If you try to collect a very large dataset, it can cause memory issues or crash the driver..
For large datasets, consider using alternatives like take(n), toPandas(), show(n)
sample DF
+-------+---+
| Name|Age|
+-------+---+
| Alice| 25|
| Bob| 30|
|Charlie| 35|
+-------+---+
# Collect all rows from the DataFrame
collected_data = df.collect()
# Access all rows
print(collected_data)
[Row(Name='Alice', Age=25), Row(Name='Bob', Age=30), Row(Name='Charlie', Age=35)]
# Access a row
print(collected_data[0])
Row(Name='Alice', Age=25)
# Access a cell
print(collected_data[0][0])
Alice
# Display the collected data
for row in collected_data:
print(row)
==output==
Row(Name='Alice', Age=25)
Row(Name='Bob', Age=30)
Row(Name='Charlie', Age=35)
# Filter and collect
filtered_data = df.filter(df["Age"] > 30).collect()
# Process collected data
for row in filtered_data:
print(f"{row['Name']} is older than 30.")
==output==
Charlie is older than 30.
# Access specific columns from collected data
for row in collected_data:
print(f"Name: {row['Name']}, Age: {row.Age}")
==output==
Name: Alice, Age: 25
Name: Bob, Age: 30
Name: Charlie, Age: 35
transform ()
The transform () function in PySpark is a higher-order function introduced to apply custom transformations to columns in a DataFrame. It allows you to perform a transformation function on an existing column, returning the transformed data as a new column. It is particularly useful when working with complex data types like arrays or for applying custom logic to column values.
Syntax
df1 = df.transform(my_function)
Parameters
my_function: a python function
Key point
The transform() method takes a function as an argument. It automatically passes the DataFrame (in this case, df) to the function. So, you only need to pass the function name “my_function"
sample DF
+-------+---+
| Name|Age|
+-------+---+
| Alice| 25|
| Bob| 30|
|Charlie| 35|
+-------+---+
from pyspark.sql.functions import upper
#Declare my function
def addTheAge(mydf):
return mydf.withColumn('age',mydf.age + 2)
def upcaseTheName(mydf):
reture mydf.withColumn("Name", upper(mydf.Name))
#transforming: age add 2 years
df1=df.transform(addTheAge)
df1.show()
+-------+---+
| Name|Age|
+-------+---+
| Alice| 27|
| Bob| 32|
|Charlie| 37|
+-------+---+
The transform () method takes a function as an argument. It automatically passes the DataFrame (in this case, df) to the function. So, you only need to pass the function name "my_function".
#transforming to upcase
df1=df.transform(upcaseTheName)
df1.show()
+-------+---+
| Name|Age|
+-------+---+
| ALICE| 25|
| BOB| 30|
|CHARLIE| 35|
+-------+---+
#transforming to upcase and age add 2 years
df1=df.transform(addTheAge).transform(upcaseTheName)
df1.show()
+-------+---+
| Name|Age|
+-------+---+
| ALICE| 27|
| BOB| 32|
|CHARLIE| 37|
+-------+---+
udf()
The udf (User Defined Function) allows you to create custom transformations for DataFrame columns using Python functions. You can use UDFs when PySpark’s built-in functions don’t cover your use case or when you need more complex logic.
Syntax
from pyspark.sql.functions import udf from pyspark.sql.types import DataType # Define a UDF function , # Register the function as a UDF my_udf = udf(py_function, returnType)
Parameters
py_function: A Python function you define to transform the data.
returnType: PySpark data type (e.g., StringType(), IntegerType(), DoubleType(), etc.) that indicates what type of data your UDF returns.
StringType(): For returning strings.
IntegerType(): For integers.
FloatType(): For floating-point numbers.
BooleanType(): For booleans.
ArrayType(DataType): For arrays.
StructType(): For structured data.
Key point
You need to specify the return type for the UDF, as PySpark needs to understand how to handle the results of the UDF.
sample DF
+-------+---+
| Name|Age|
+-------+---+
| Alice| 25|
| Bob| 30|
|Charlie| 35|
+-------+---+
from pyspark.sql import SparkSession
from pyspark.sql.functions import udf
from pyspark.sql.types import StringType
# Define a Python function
def to_upper(name):
return name.upper()
# Register the function as a UDF, specifying the return type as StringType
uppercase_udf = udf(to_upper, StringType())
# Apply the UDF using withColumn
df_upper = df.withColumn("Upper_Name", uppercase_udf(df["Name"]))
df_upper.show()
+-------+---+----------+
| Name|Age|Upper_Name|
+-------+---+----------+
| Alice| 25| ALICE|
| Bob| 30| BOB|
|Charlie| 35| CHARLIE|
+-------+---+----------+
# UDF Returning Boolean
from pyspark.sql.functions import udf
from pyspark.sql.types import BooleanType
# Define a Python function
def is_adult(age):
return age > 30
# Register the UDF
is_adult_udf = udf(is_adult, BooleanType())
# Apply the UDF
df_adult = df.withColumn("Is_Adult", is_adult_udf(df["Age"]))
# Show the result
df_adult.show()
+-------+---+--------+
| Name|Age|Is_Adult|
+-------+---+--------+
| Alice| 25| false|
| Bob| 30| false|
|Charlie| 35| true|
+-------+---+--------+
# UDF with Multiple Columns (Multiple Arguments)
from pyspark.sql.functions import udf
from pyspark.sql.types import StringType
# Define a Python function that concatenates two columns
def concat_name_age(name, age):
return f"{name} is {age} years old"
# Register the UDF
concat_udf = udf(concat_name_age, StringType())
# Apply the UDF to multiple columns
df_concat = df.withColumn("Description", concat_udf(df["Name"], df["Age"]))
# Show the result
df_concat.show()
+-------+---+--------------------+
| Name|Age| Description|
+-------+---+--------------------+
| Alice| 25|Alice is 25 years...|
| Bob| 30| Bob is 30 years old|
|Charlie| 35|Charlie is 35 yea...|
+-------+---+--------------------+
spark.udf.register(),Register for SQL query
in PySpark, you can use spark.udf.register() to register a User Defined Function (UDF) so that it can be used not only in DataFrame operations but also in SQL queries. This allows you to apply your custom Python functions directly within SQL statements executed against your Spark session.
registered_pyFun_for_sql: The name of the UDF, which will be used in SQL queries.
original_pyFun: The original Python function that contains the custom logic.
returnType: The return type of the UDF, which must be specified (e.g., StringType(), IntegerType()).
smaple df
+-------+---+
| Name|Age|
+-------+---+
| Alice| 25|
| Bob| 30|
|Charlie| 35|
+-------+---+
from pyspark.sql import SparkSession
from pyspark.sql.types import StringType
# Register the DataFrame as a SQL temporary view
df.createOrReplaceTempView("people")
# Define a Python function
def original_myPythonFun(name):
return name.upper()
# Register the function as a UDF for SQL with the return type StringType
spark.udf.register("registered_pythonFun_for_sql"\
, original_myPythonFun\
, StringType()\
)
# Use the UDF - "registered_pythonFun_for_sql" in a SQL query
result = spark.sql(\
"SELECT Name, registered_pythonFun_for_sql(Name) AS Upper_Name \
FROM people"\
)
result.show()
+-------+----------+
| Name|Upper_Name|
+-------+----------+
| Alice| ALICE|
| Bob| BOB|
|Charlie| CHARLIE|
+-------+----------+
we can directly use SQL style with magic %sql
%sql
SELECT Name
, registered_pythonFun_for_sql(Name) AS Upper_Name
FROM people
+-------+----------+
| Name|Upper_Name|
+-------+----------+
| Alice| ALICE|
| Bob| BOB|
|Charlie| CHARLIE|
+-------+----------+
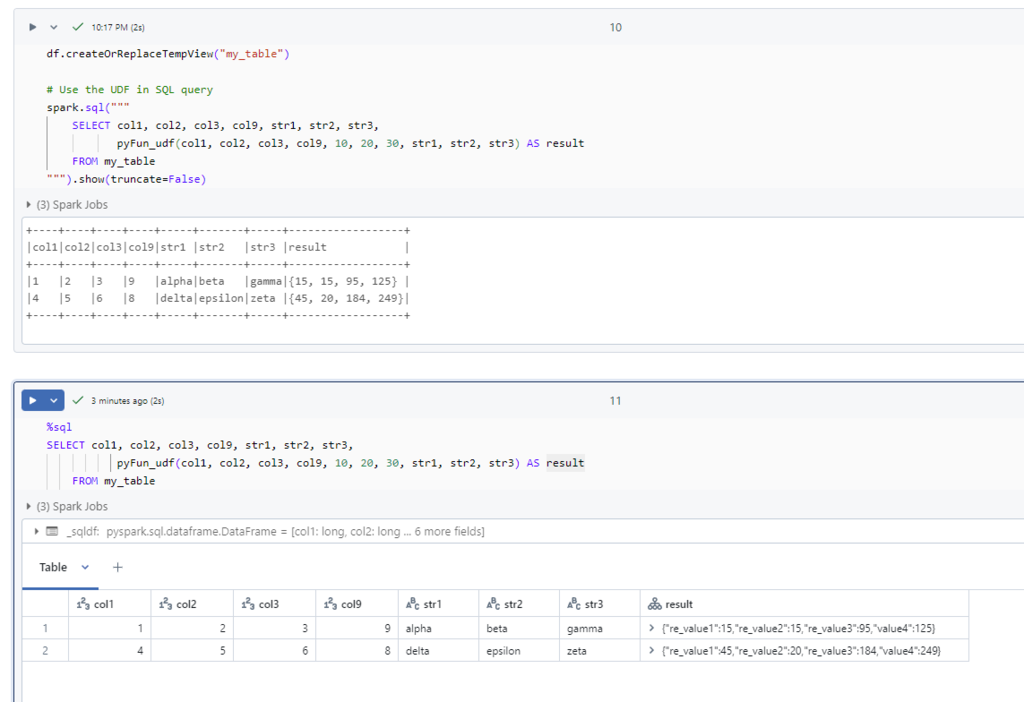
A complex python function declares, udf register, and apply example
Define the Python function to handle multiple columns and scalars
# Define the Python function to handle multiple columns and scalars
def pyFun(col1, col2, col3, col9, int1, int2, int3, str1, str2, str3):
# Example business logic
re_value1 = col1 * int1 + len(str1)
re_value2 = col2 + col9 + len(str2)
re_value3 = col3 * int3 + len(str3)
value4 = re_value1 + re_value2 + re_value3
# Return multiple values as a tuple
return re_value1, re_value2, re_value3, value4
Define the return schema for the UDF
# Define the return schema for the UDF
return_schema = StructType([
StructField("re_value1", IntegerType(), True),
StructField("re_value2", IntegerType(), True),
StructField("re_value3", IntegerType(), True),
StructField("value4", IntegerType(), True)
])
Register the UDF
# register the UDF
# for SQL use this
# spark.udf.register("pyFun_udf", pyFun, returnType=return_schema)
pyFun_udf = udf(pyFun, returnType=return_schema)
Apply the UDF to the DataFrame, using ‘lit()’ for constant values
# Apply the UDF to the DataFrame, using 'lit()' for constant values
df_with_udf = df.select(
col("col1"),
col("col2"),
col("col3"),
col("col9"),
col("str1"),
col("str2"),
col("str3"),
pyFun_udf(
col("col1"),
col("col2"),
col("col3"),
col("col9"),
lit(10), # Use lit() for the constant integer values
lit(20),
lit(30),
col("str1"),
col("str2"),
col("str3")
).alias("result")
)
# Show the result
df_with_udf.show(truncate=False)
==output==
+----+----+----+----+-----+-------+-----+------------------+
|col1|col2|col3|col9|str1 |str2 |str3 |result |
+----+----+----+----+-----+-------+-----+------------------+
|1 |2 |3 |9 |alpha|beta |gamma|{15, 15, 95, 125} |
|4 |5 |6 |8 |delta|epsilon|zeta |{45, 20, 184, 249}|
+----+----+----+----+-----+-------+-----+------------------+