Unity Catalog introduces several new securable objects to grant privileges to data in cloud object storage.
A storage credential is a securable object representing an Azure managed identity or Microsoft Entra ID service principal.
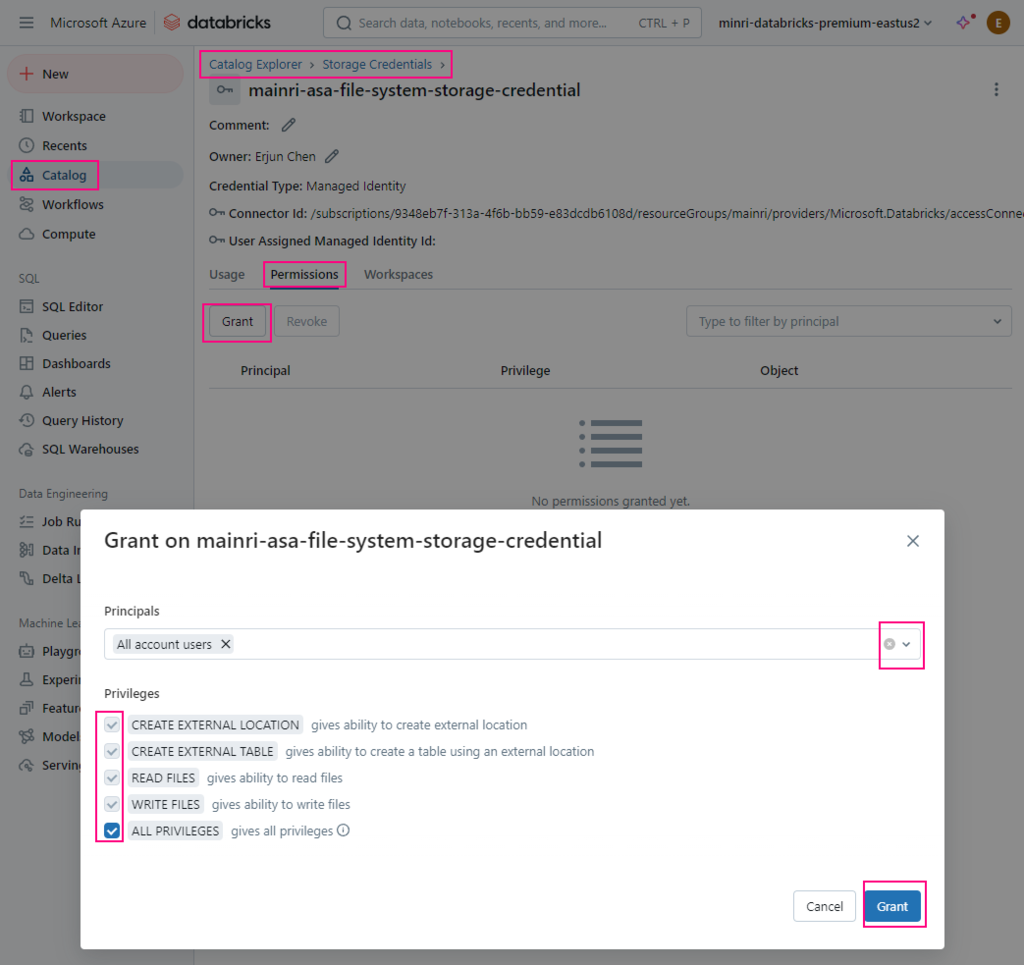
Once a storage credential is created access to it can be granted to principals, users and groups.
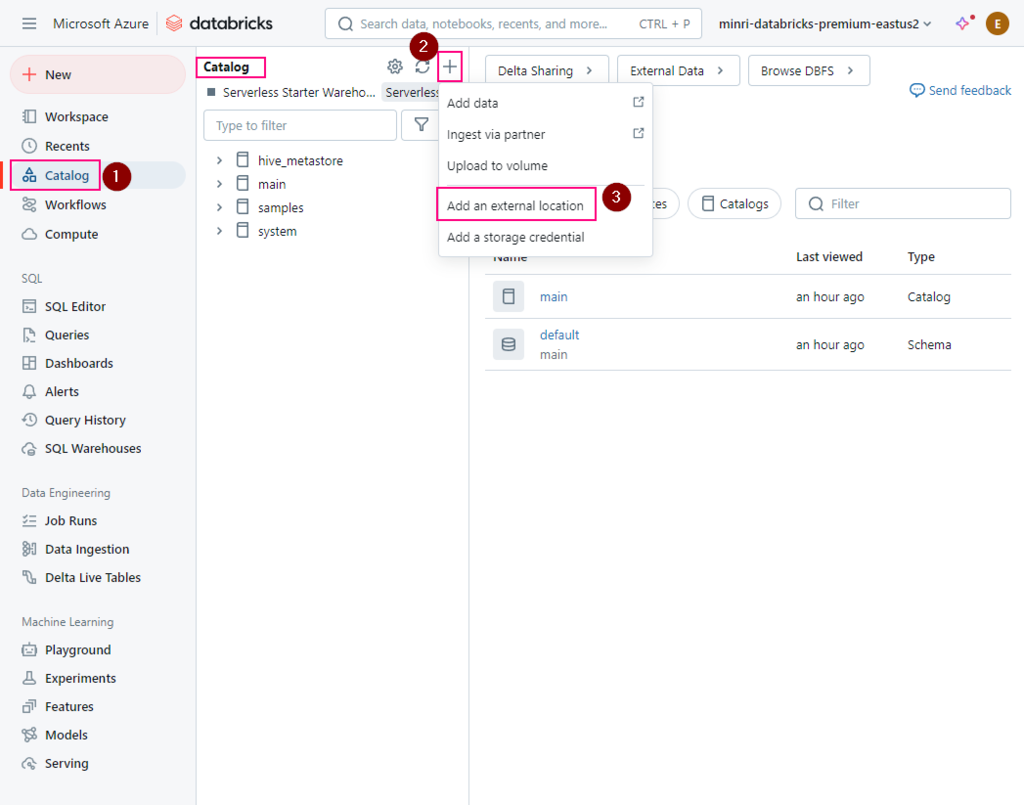
An external location is a securable object that combines a storage path with a storage credential that authorizes access to that path.
Storage credential
A storage credential is an authentication and authorization mechanism for accessing data stored on your cloud tenant.
Once a storage credential is created access to it can be granted to principals (users and groups).
Storage credentials are primarily used to create external locations, which scope access to a specific storage path. Storage credential names are unqualified and must be unique within the metastore.
External Location
An object that combines a cloud storage path with a storage credential that authorizes access to the cloud storage path.
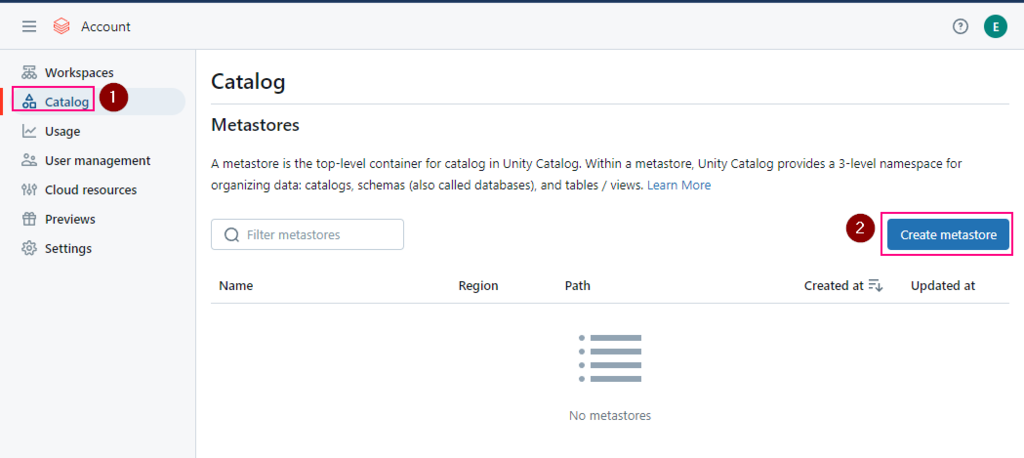
Step by step Demo
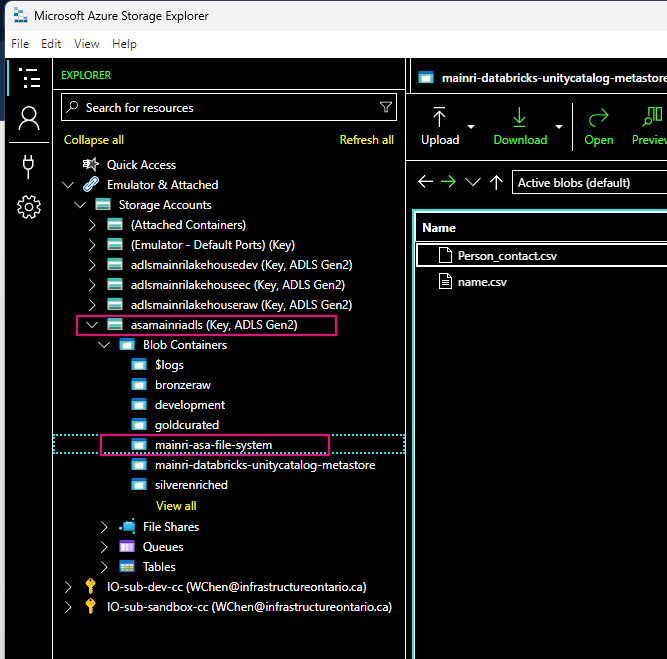
Let’s say I have a container on ADLS, called “mainri-asa-file-system”
1. Allow “access connector” for azure databricks to access
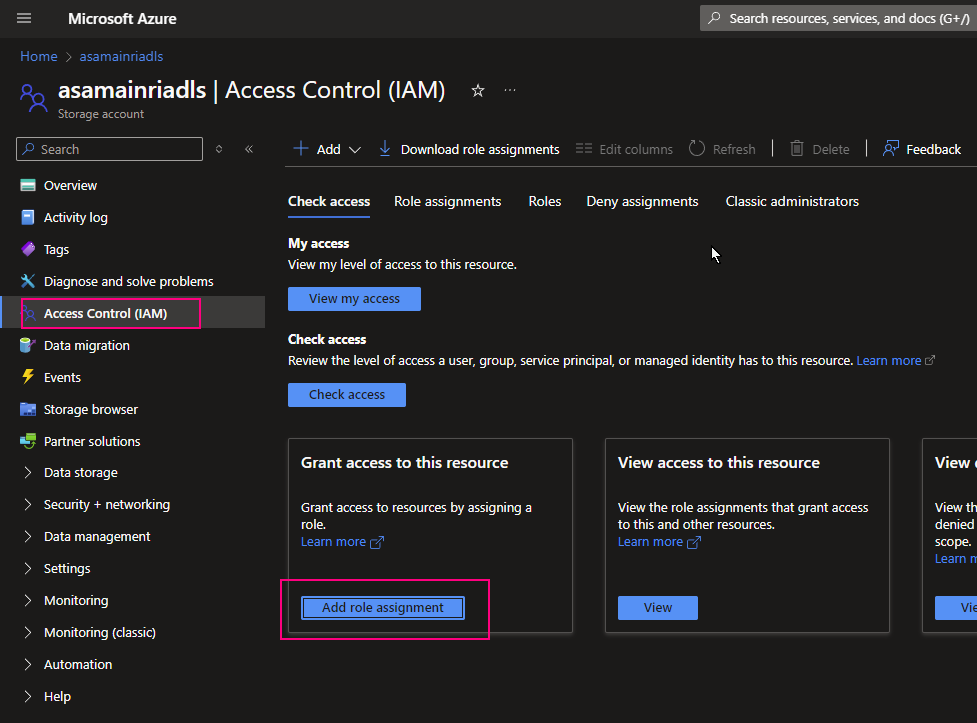
Azure Portal > storage Account > Access Control (IAM) > add role assignment
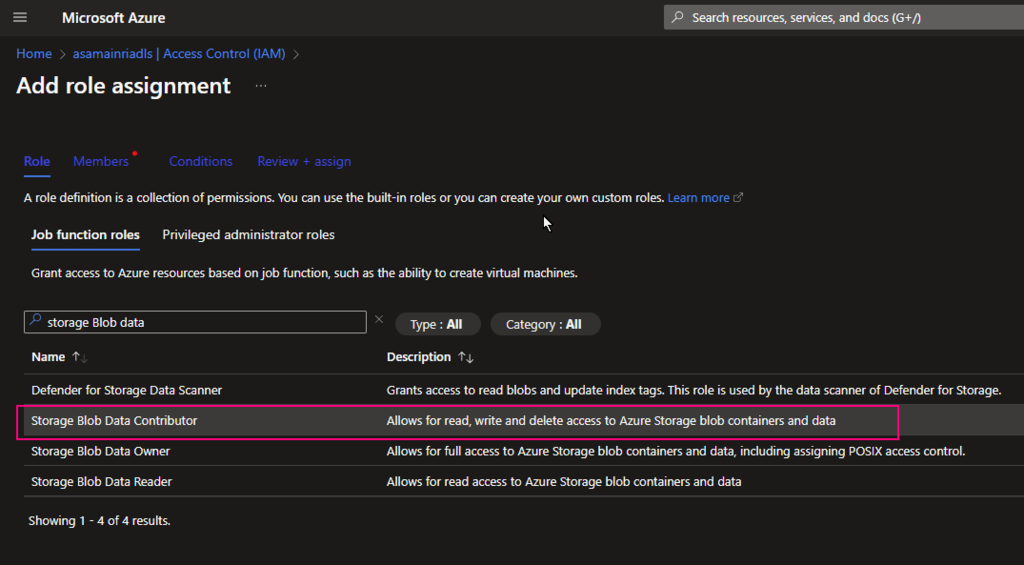
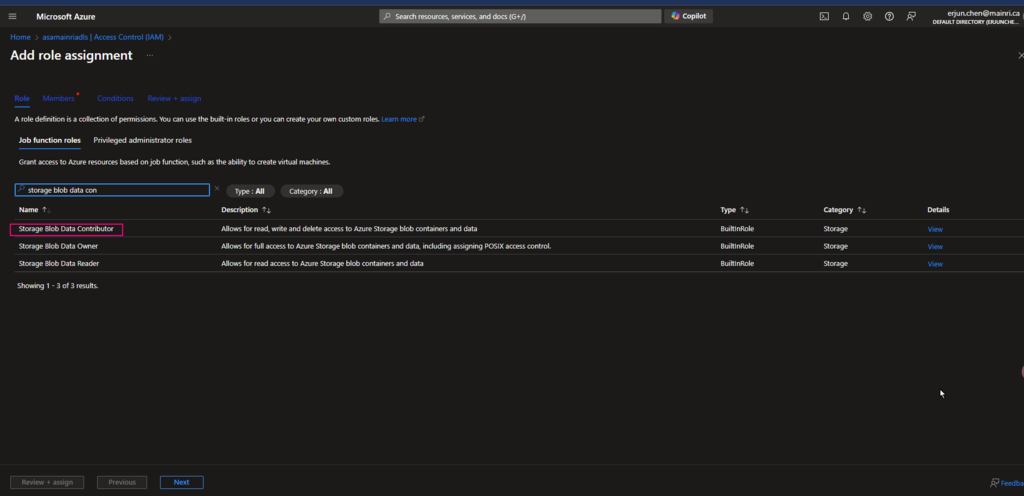
Add “storage Blob Data Contributor” role
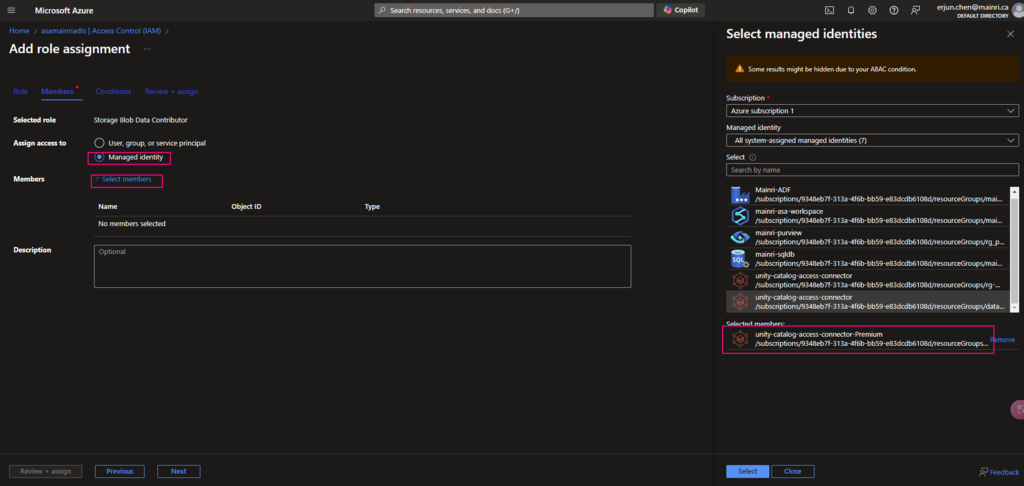
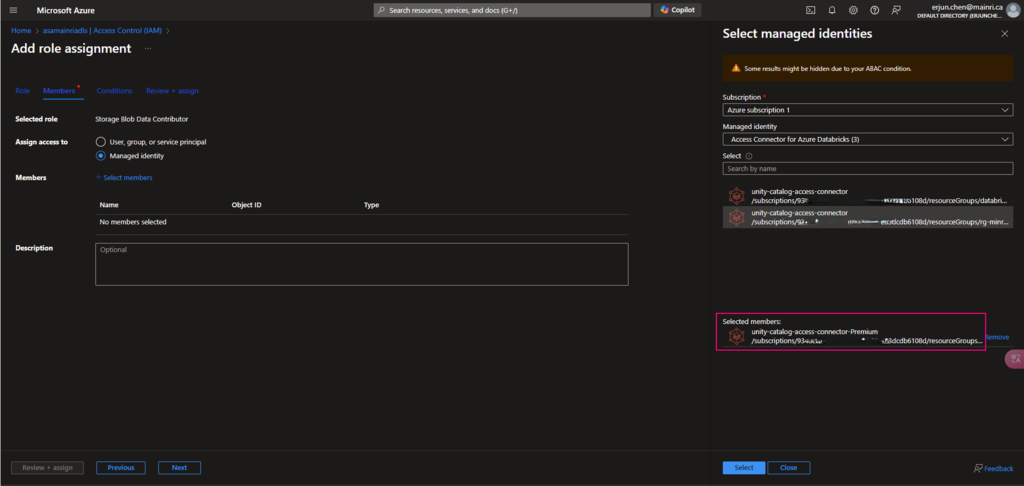
Assign to the access connector for azure databricks
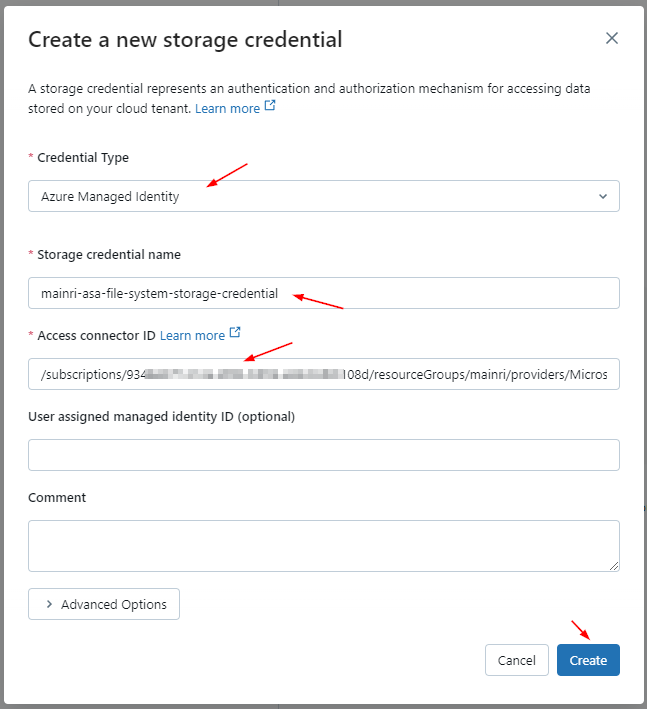
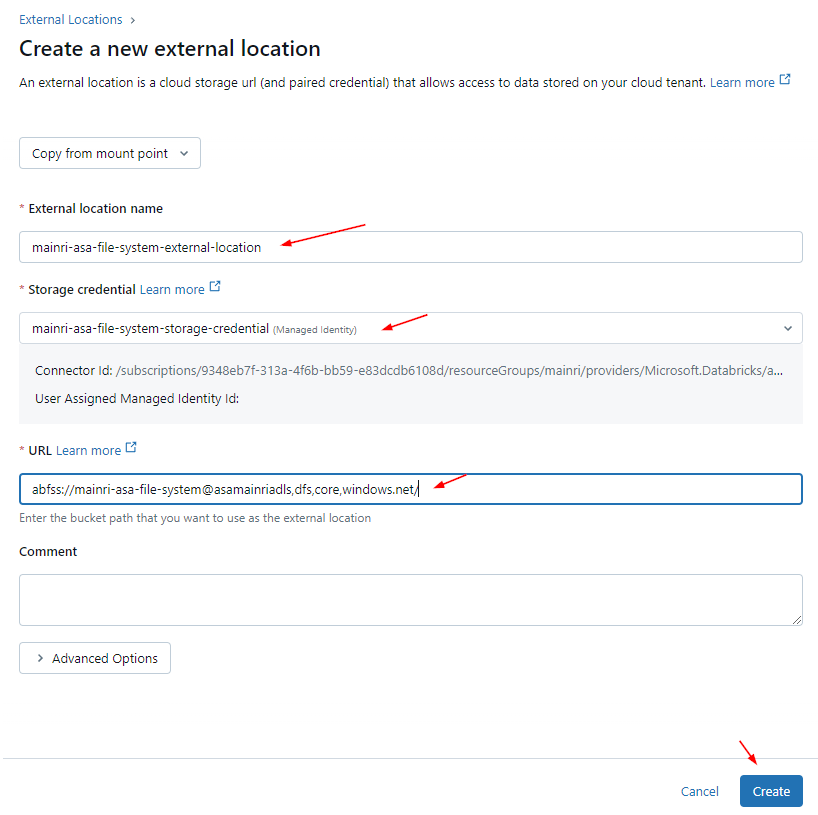
2. Create Storage credential
Azure Databricas > Catalog > add a storage credential
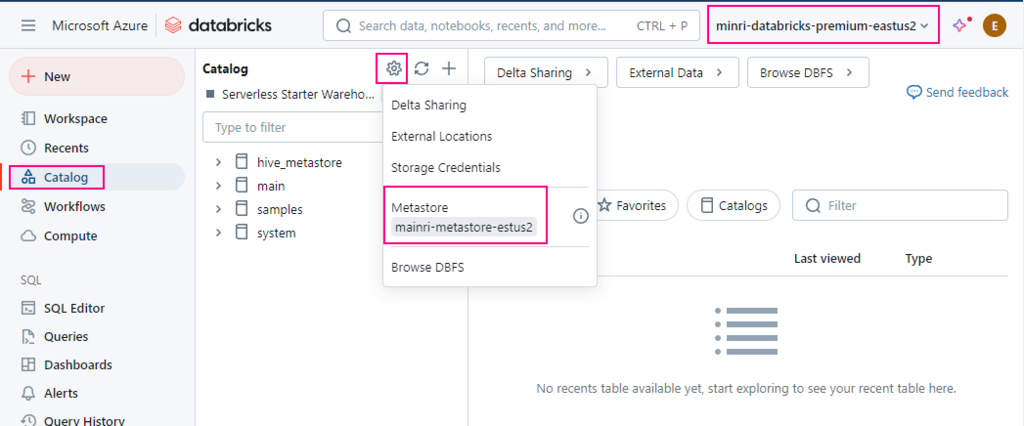
A metastore is the top-level container for data in Unity Catalog. Unity Catalog metastore register metadata about securable objects (such as tables, volumes, external locations, and shares) and the permissions that govern access to them.
Each metastore exposes a three-level namespace (catalog.schema.table) by which data can be organized. You must have one metastore for each region in which your organization operates.
Microsoft said that Databricks began to enable new workspaces for Unity Catalog automatically on November 9, 2023, with a rollout proceeding gradually across accounts. Otherwise, we must follow the instructions in this article to create a metastore in your workspace region.
Preconditions
Before we begin
1. Microsoft Entra ID Global Administrator
The first Azure Databricks account admin must be a Microsoft Entra ID Global Administrator
The first Azure Databricks account admin must be a Microsoft Entra ID Global Administrator at the time that they first log in to the Azure Databricks account console.
Upon first login, that user becomes an Azure Databricks account admin and no longer needs the Microsoft Entra ID Global Administrator role to access the Azure.
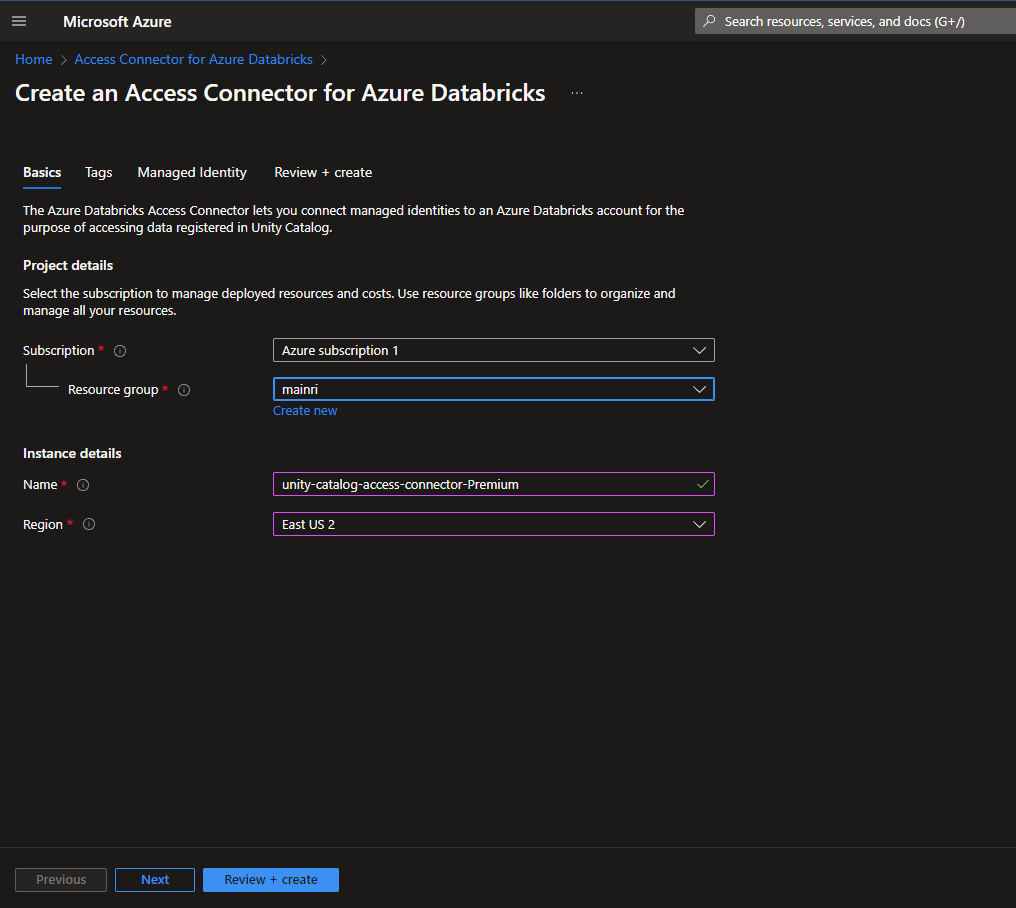
2. Premium Tire
Databricks workspaces Pricing tire must be Premium Tire.
3. The same region
Databricks region is in the same as ADLS’s region. Each region allows one metastore only.
Manual create metastore and enable unity catalog process
Create an ADLS G2 (if you did not have) Create storage account and container to store manage table and volume data at the metastore level, the container will be the root storage for the unity catalog metastore
Create an Access Connector for Azure Databricks
Grant “Storage Blob Data Contributor” role to access Connector for Azure Databricks on ADLS G2 storage Account
Enable Unity Catalog by creating Metastore and assigning to workspace
Step by step Demo
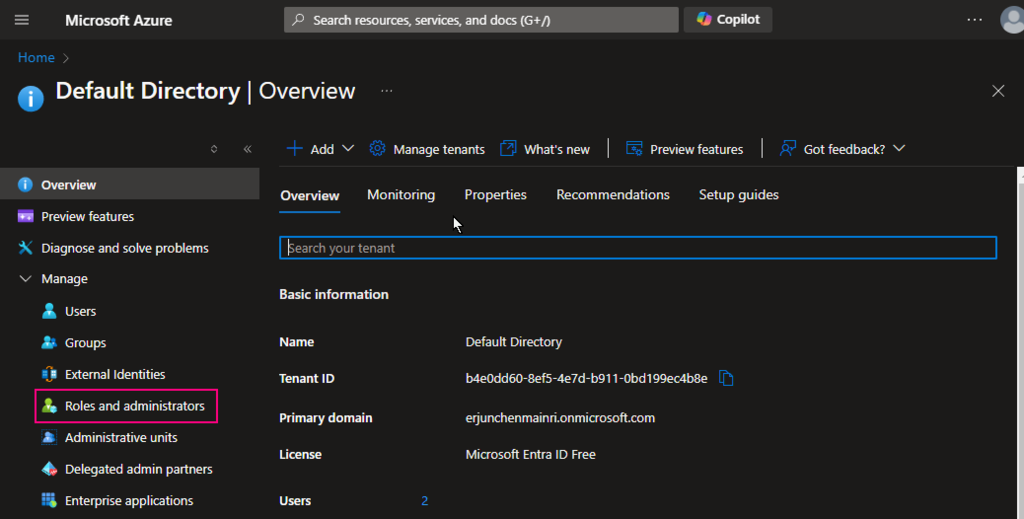
1. Check Entra ID role.
To check whether I am a Microsoft Entra ID Global Administrator role.
Azure Portal > Entra ID > Role and administrators
I am a Global Administrator
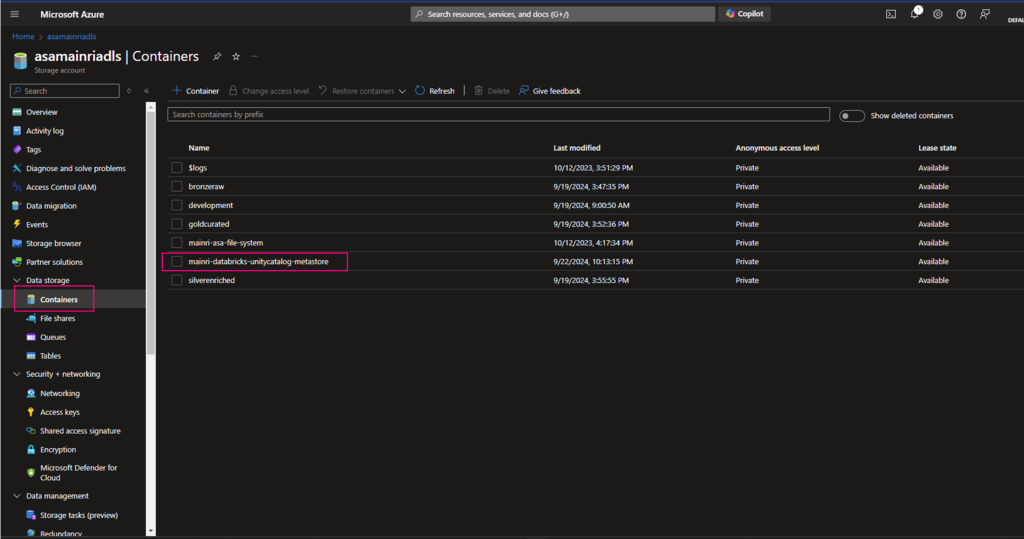
2. Create a container for saving metastore
Create a container at ROOT of ADLS Gen2
Since we have created an ADLS Gen2, directly move to create a container at root of ADLS.
3. Create an Access Connector for Databricks
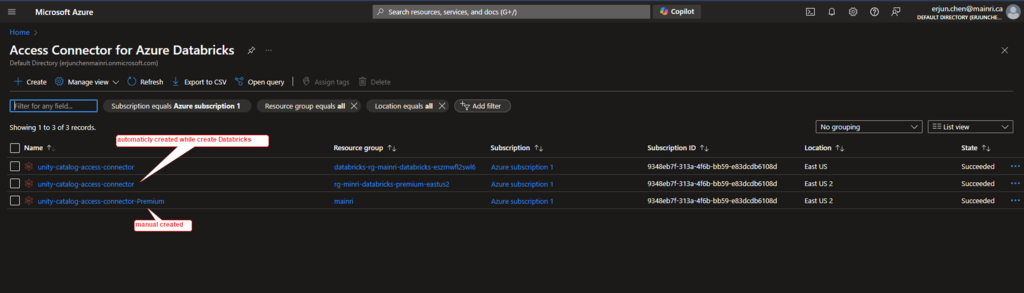
If it did not automatically create while you create Azure databricks service, manual create one.
Azure portal > Access Connector for Databricks
once all required fields filled, we can see a new access connector created.
4. Grant Storage Blob Data Contributor to access Connector
Add “storage Blob data contributor” role assign to “access connector for Azure Databricks” I just created.
Azure Portal > ADLS Storage account > Access Control (IAM) > add role
Continue to add role assignment
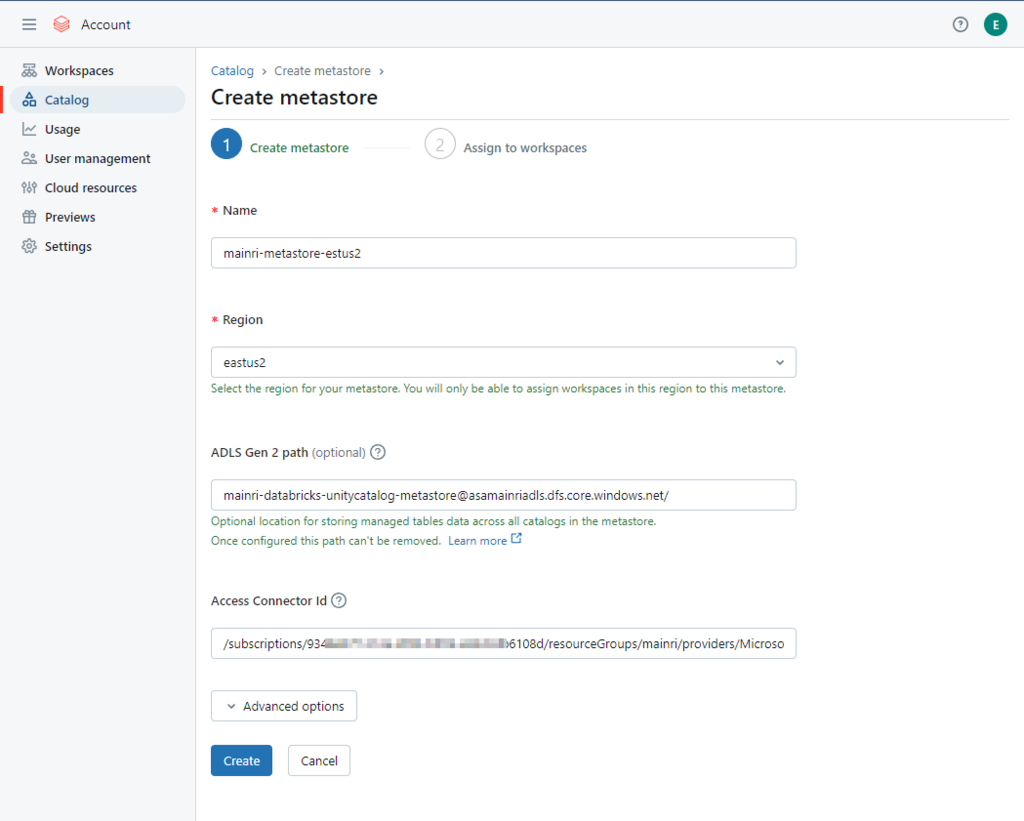
5. Create a metastore
If you are an account admin, you can login accounts console, otherwise, ask your account admin to help.
before you begin to create a metastore, make sure
You must be an Azure Databricks account admin. The first Azure Databricks account admin must be a Microsoft Entra ID Global Administrator at the time that they first log in to the Azure Databricks account console. Upon first login, that user becomes an Azure Databricks account admin and no longer needs the Microsoft Entra ID Global Administrator role to access the Azure Databricks account. The first account admin can assign users in the Microsoft Entra ID tenant as additional account admins (who can themselves assign more account admins). Additional account admins do not require specific roles in Microsoft Entra ID.
The workspaces that you attach to the metastore must be on the Azure Databricks Premium plan.
If you want to set up metastore-level root storage, you must have permission to create the following in your Azure tenant
Select the same region for your metastore. You will only be able to assign workspaces in this region to this metastore.
Container name and path The pattern is: <contain_name>@<storage_account_name>.dfs.core.windows.net/<path> For this demo I used this mainri-databricks-unitycatalog-metastore-eastus2@asamainriadls.dfs.core.windows.net/
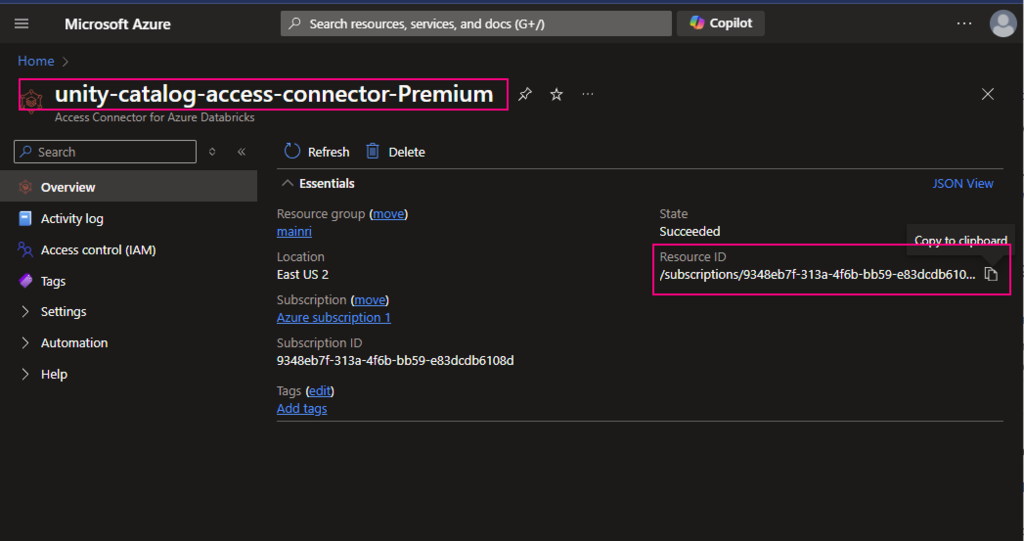
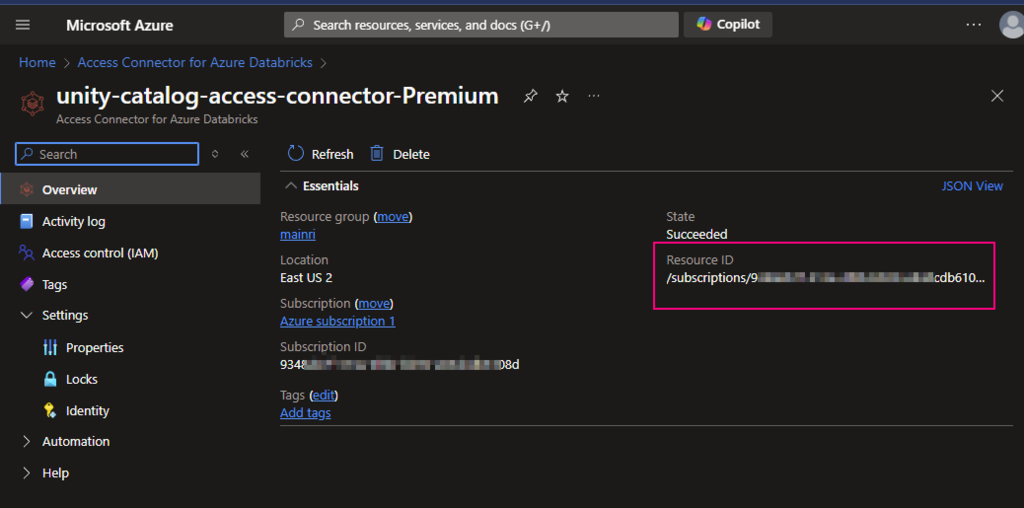
Access connector ID The pattern is: /subscriptions/{sub-id}/resourceGroups/{rg-name}/providers/Microsoft.databricks/accessconnects/<connector-name>
Find out the Access connector ID
Azure portal > Access Connector for Azure Databricks
For this demo I used this /subscriptions/9348XXXXXXXXXXX6108d/resourceGroups/mainri/providers/Microsoft.Databricks/accessConnectors/unity-catalog-access-connector-Premiu
Looks like this
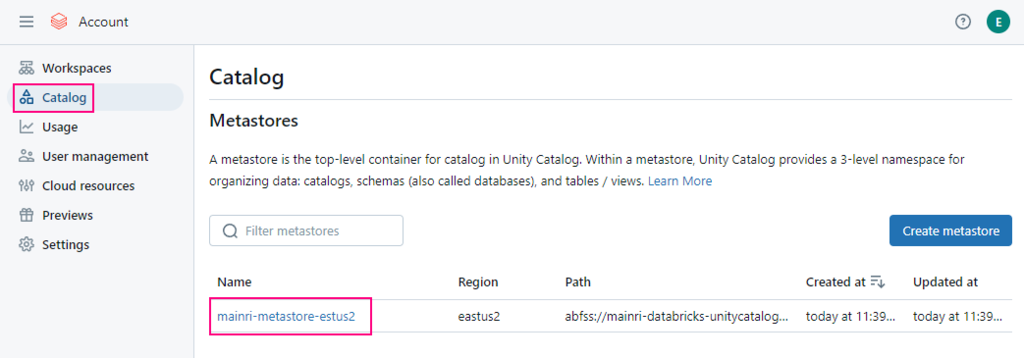
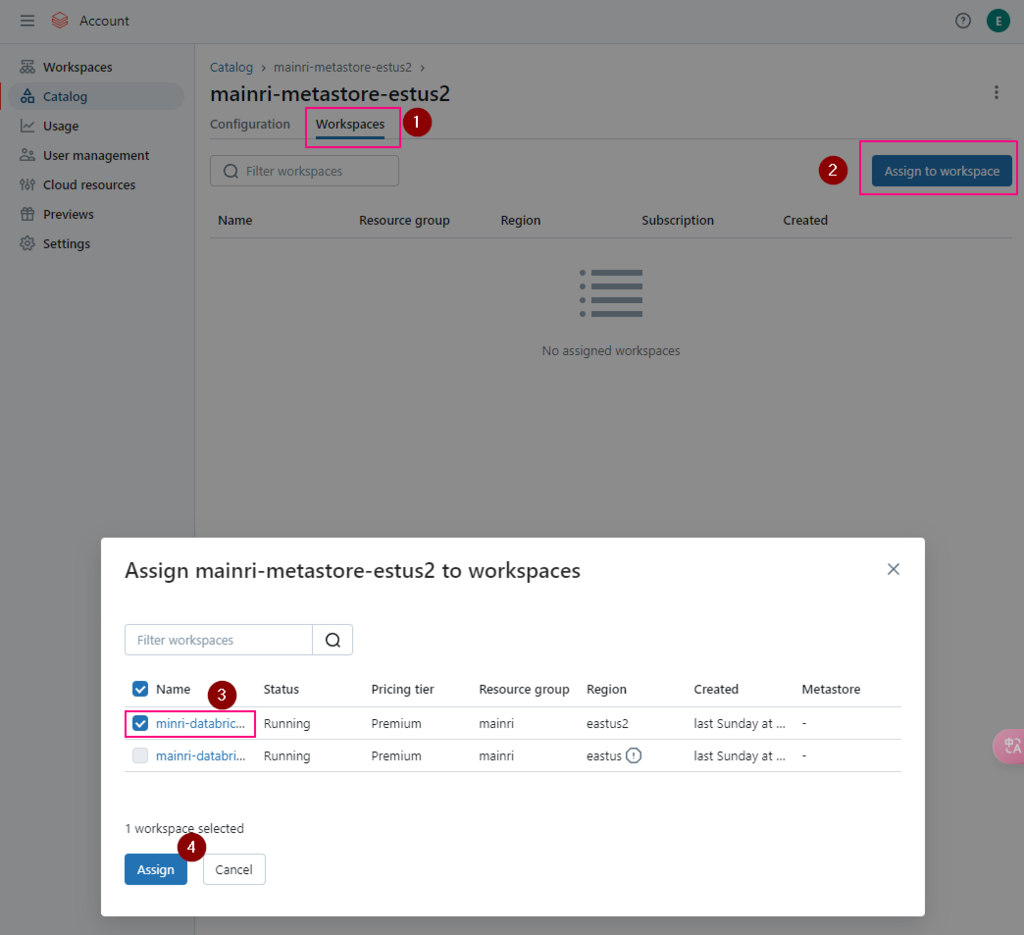
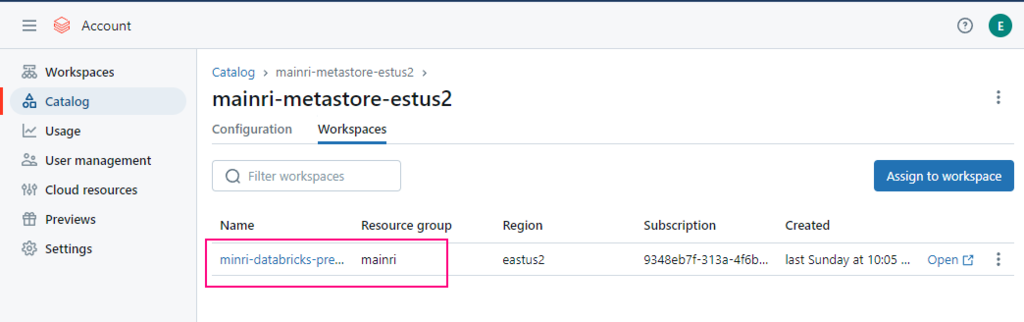
Enable Unity catalog
Assign to workspace
To enable an Azure Databricks workspace for Unity Catalog, you assign the workspace to a Unity Catalog metastore using the account console:
The Azure Data Lake is a massively scalable and secure data storage for high-performance analytics workloads. We can create three storage accounts within a single resource group.
Consider whether an organization needs one or many storage accounts and consider what file systems I require to build our logical data lake. (by the way, Multiple storage accounts or file systems can’t incur a monetary cost until data is accessed or stored.)
Each storage account within our data landing zone stores data in one of three stages:
Raw data
Enriched and curated data
Development data lakes
You might want to consolidate raw, enriched, and curated layers into one storage account. Keep another storage account named “development” for data consumers to bring other useful data products.
A data application can consume enriched and curated data from a storage account which has been ingested an automated data agnostic ingestion service.
we are going to Leveraged the medallion architecture to implement it. if you need more information about medallion architecture please review my previously articles – Medallion Architecture
It’s important to plan data structure before landing data into a data lake.
Data Lake Planning
When you plan a data lake, always consider appropriate consideration to structure, governance, and security. Multiple factors influence each data lake’s structure and organization:
The type of data stored
How its data is transformed
Who accesses its data
What its typical access patterns are
If your data lake contains a few data assets and automated processes like extract, transform, load (ETL) offloading, your planning is likely to be fairly easy. If your data lake contains hundreds of data assets and involves automated and manual interaction, expect to spend a longer time planning, as you’ll need a lot more collaboration from data owners.
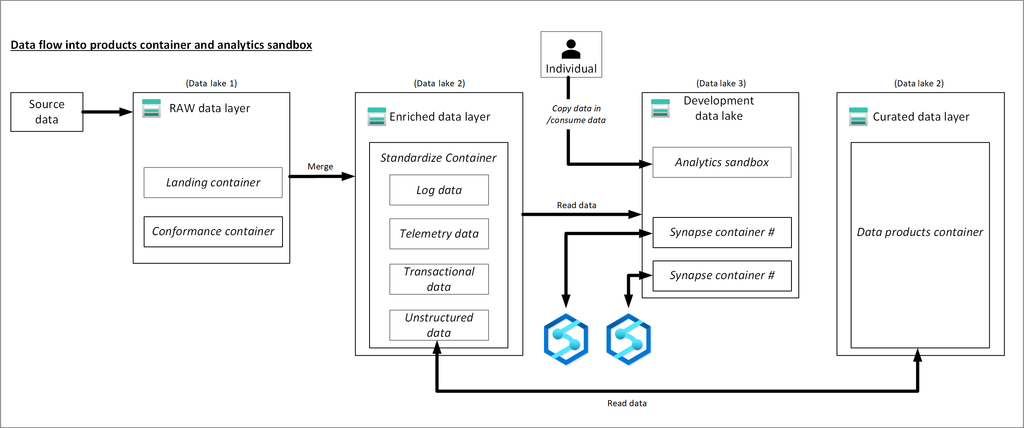
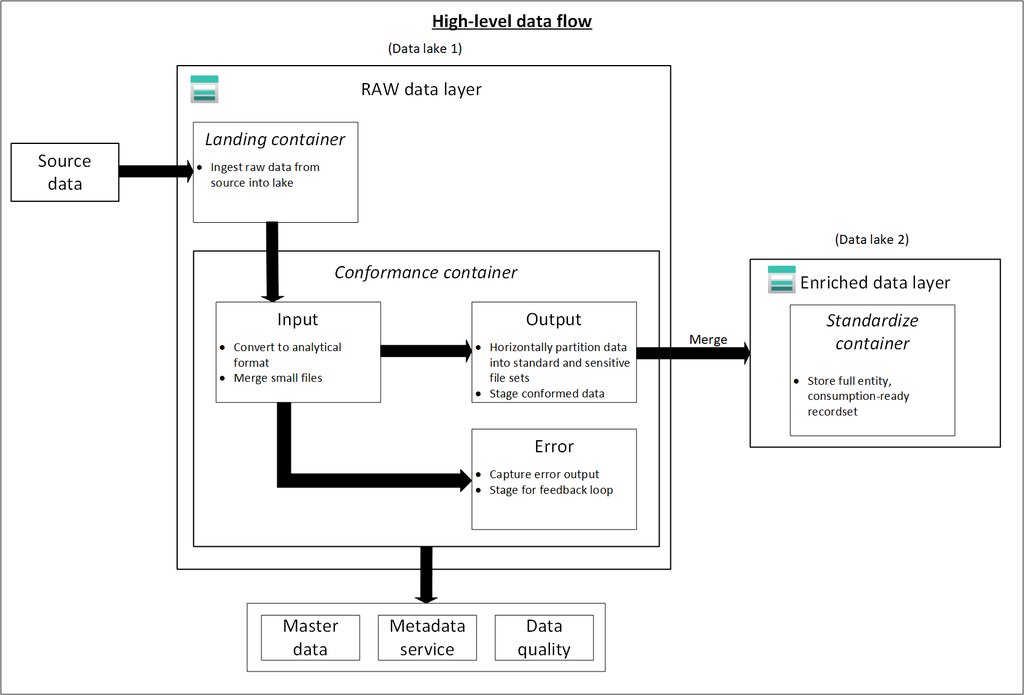
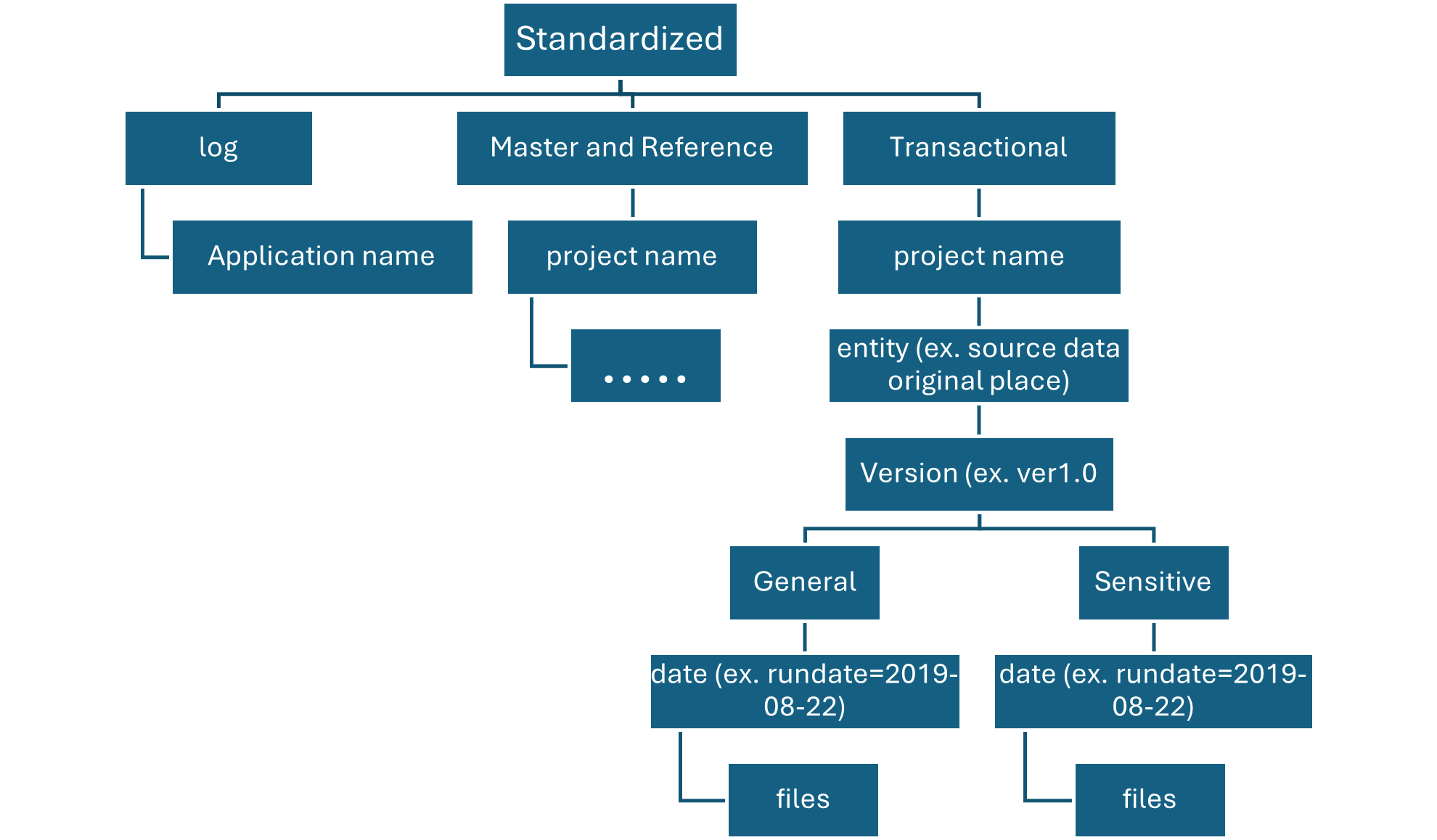
Three data lakes are illustrated in each data landing zone. The data lake sits across three data lake accounts, multiple containers, and folders, but it represents one logical data lake for our data landing zone.
Lake number
Layers
Container number
Container name
1
Raw
1
Landing
1
Raw
2
Conformance
2
Enriched
1
Standardized
2
Curated
2
Data products
3
Development
1
Analytics sandbox
3
Development
#
Synapse primary storage number
Data Lake and container number with Layer
Depending on requirements, you might want to consolidate raw, enriched, and curated layers into one storage account. Keep another storage account named “development” for data consumers to bring other useful data products.
Enable Azure Storage with the hierarchical name space feature, which allows you to efficiently manage files.
Each data product should have two folders in the data products container that our data product team owns.
On enriched layer, standardized container, there are two folders per source system, divided by classification. With this structure, team can separately store data that has different security and data classifications and assign them different security access.
Our standardized container needs a general folder for confidential or below data and a sensitive folder for personal data. Control access to these folders by using access control lists (ACLs). We can create a dataset with all personal data removed, and store it in our general folder. We can have another dataset that includes all personal data in our sensitive personal data folder.
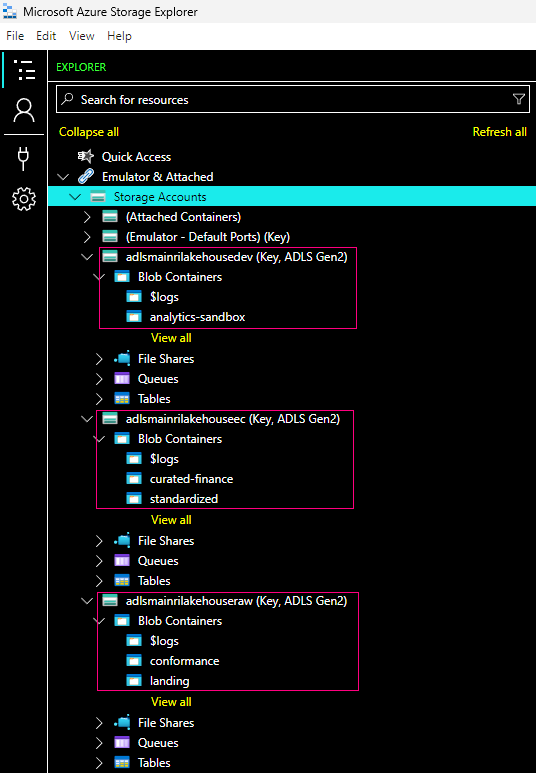
I created 3 accounts (Azure storage naming allows low case and number only. no dash, no underscore etc. allows)
adlsmainrilakehousedev — Development
adlsmainrilakehouseec — Enrich and Curated
adlsmainrilakehouseraw — Raw data
Raw layer (data lake one)
This data layer is considered the bronze layer or landing raw source data. Think of the raw layer as a reservoir that stores data in its natural and original state. It’s unfiltered and unpurified.
You might store the data in its original format, such as JSON or CSV. Or it might be cost effective to store the file contents as a column in a compressed file format, like Avro, Parquet, or Databricks Delta Lake.
You can organize this layer by using one folder per source system. Give each ingestion process write access to only its associated folder.
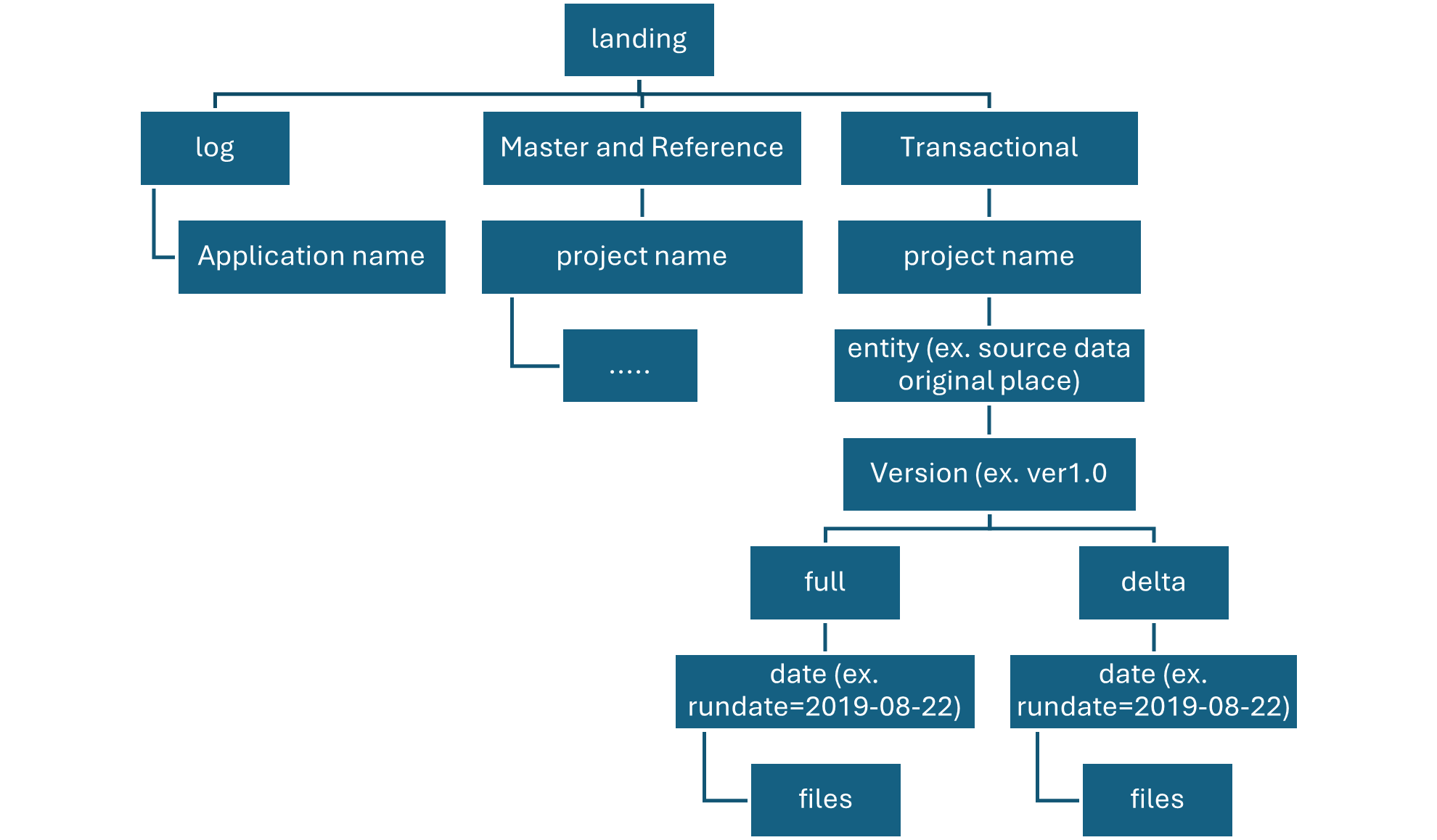
Raw Layer Landing container
The landing container is reserved for raw data that’s from a recognized source system.
Our data agnostic ingestion engine or a source-aligned data application loads the data, which is unaltered and in its original supported format.
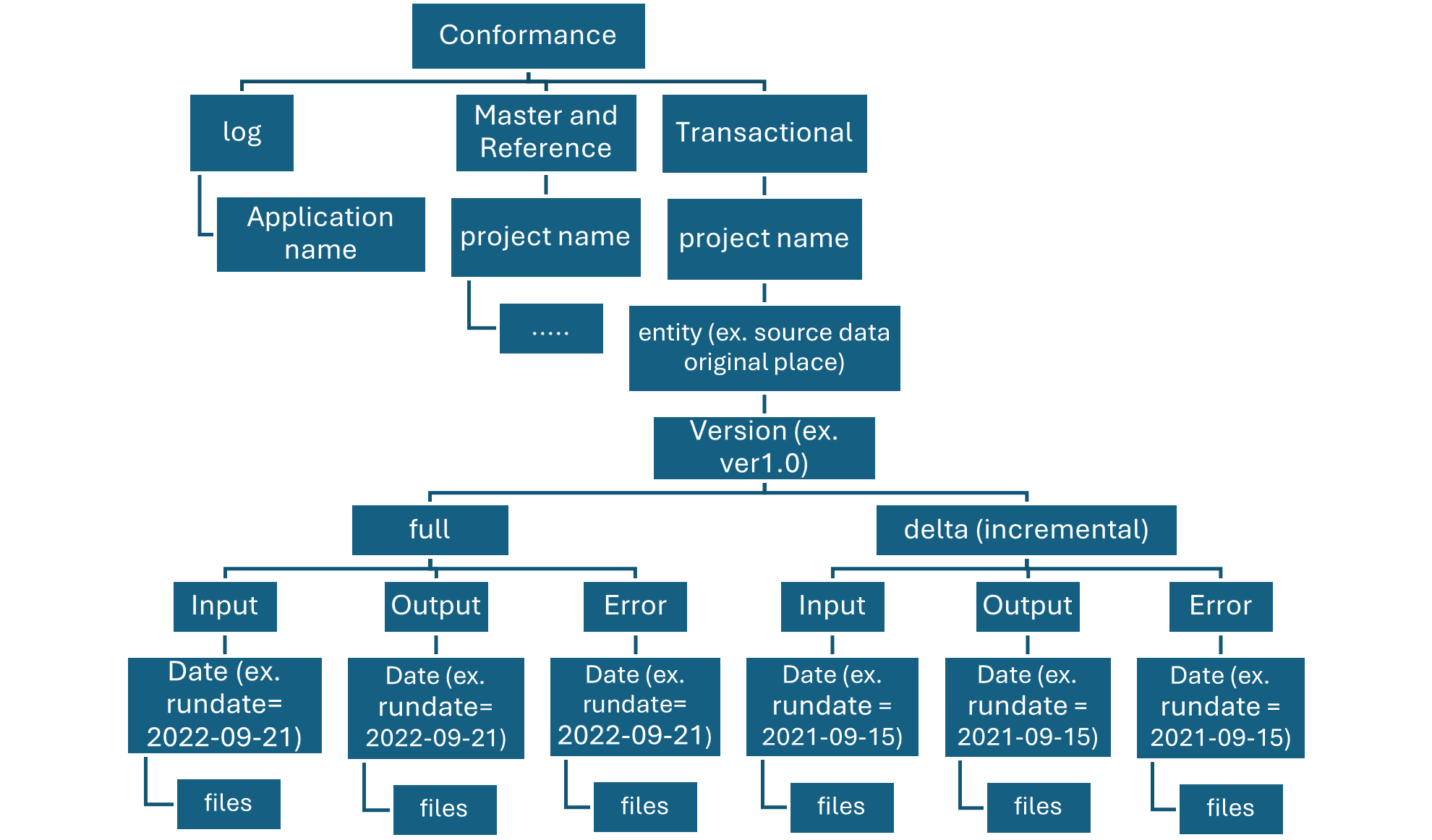
Raw layer conformance container
The conformance container in raw layer contains data quality conformed data.
As data is copied to a landing container, data processing and computing is triggered to copy the data from the landing container to the conformance container. In this first stage, data gets converted into the delta lake format and lands in an input folder. When data quality runs, records that pass are copied into the output folder. Records that fail land in an error folder.
Enriched layer (data lake two)
Think of the enriched layer as a filtration layer. It removes impurities and can also involve enrichment. This data layer is also considered the silver layer.
The following diagram shows the flow of data lakes and containers from source data to a standardized container.
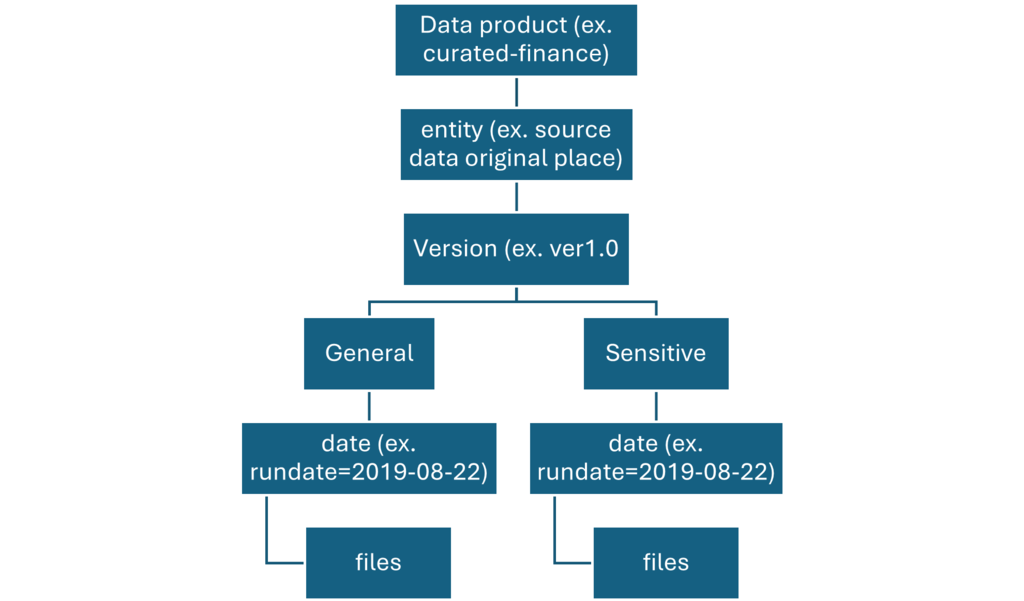
Standardized container
Standardization container holds systems of record and masters. Data within this layer has had no transformations applied other than data quality, delta lake conversion, and data type alignment.
Folders in Standardized container are segmented first by subject area, then by entity. Data is available in merged, partitioned tables that are optimized for analytics consumption.
Curated layer (data lake two)
The curated layer is our consumption layer and known as Golden layer. It’s optimized for analytics rather than data ingestion or processing. The curated layer might store data in denormalized data marts or star schemas.
Data from our standardized container is transformed into high-value data products that are served to our data consumers. This data has structure. It can be served to the consumers as-is, such as data science notebooks, or through another read data store, such as Azure SQL Database.
This layer isn’t a replacement for a data warehouse. Its performance typically isn’t adequate for responsive dashboards or end user and consumer interactive analytics. This layer is best suited for internal analysts and data scientists who run large-scale, improvised queries or analysis, or for advanced analysts who don’t have time-sensitive reporting needs.
Data products container
Data assets in this zone are typically highly governed and well documented. Assign permissions by department or by function, and organize permissions by consumer group or data mart.
When landing data in another read data store, like Azure SQL Database, ensure that we have a copy of that data located in the curated data layer. Our data product users are guided to main read data store or Azure SQL Database instance, but they can also explore data with extra tools if we make the data available in our data lake.
Development layer (data lake three)
Our data consumers can/may bring other useful data products along with the data ingested into our standardized container in the silver layer.
Analytics Sandbox
The analytics sandbox area is a working area for an individual or a small group of collaborators. The sandbox area’s folders have a special set of policies that prevent attempts to use this area as part of a production solution. These policies limit the total available storage and how long data can be stored.
In this scenario, our data platform can/may allocate an analytics sandbox area for these consumers. In the sandbox, they, consumers, can generate valuable insights by using the curated data and data products that they bring.
For example, if a data science team wants to determine the best product placement strategy for a new region, they can bring other data products, like customer demographics and usage data, from similar products in that region. The team can use the high-value sales insights from this data to analyze the product market fit and offering strategy.
These data products are usually of unknown quality and accuracy. They’re still categorized as data products, but are temporary and only relevant to the user group that’s using the data.
When these data products mature, our enterprise can promote these data products to the curated data layer. To keep data product teams responsible for new data products, provide the teams with a dedicated folder on our curated data zone. They can store new results in the folder and share them with other teams across organization.
Conclusion
Data lakes are an indispensable tool in a modern data strategy. They allow teams to store data in a variety of formats, including structured, semi-structured, and unstructured data – all vendor-neutral forms, which eliminates the danger of vendor lock-in and gives users more control over the data. They also make data easier to access and retrieve, opening the door to a wider choice of analytical tools and applications.
Please do not hesitate to contact me if you have any questions at William . chen @mainri.ca
SQL Server Change Data Capture (CDC) is a feature that captures changes to data in SQL Server tables. It captures the changes in the source data and updates only the data in the destination that has changed. Any inserts, updates or deletes made to any of the tables made in a specified time window are captured for further use, such as in ETL processes. Here’s a step-by-step guide to enable and use CDC.
Preconditions
1. SQL Server Agent is running
Since CDC relies on SQL Server Agent, verify that the agent is up and running.
To check if SQL Server Agent is running, you can follow these steps:
Open SQL Server Management Studio (SSMS).
In the Object Explorer, expand the SQL Server Agent node. If you see a green icon next to SQL Server Agent, it means the Agent is running. If the icon is red or gray, it means the SQL Server Agent is stopped or disabled.
To start the Agent, right-click on SQL Server Agent and select Start.
Or start it from SSMS or by using the following command:
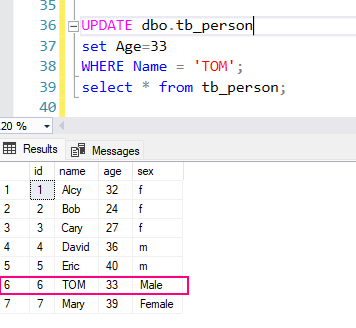
UPDATE dbo.tb_person
set Age=33
WHERE Name = 'TOM';
select * from tb_person;
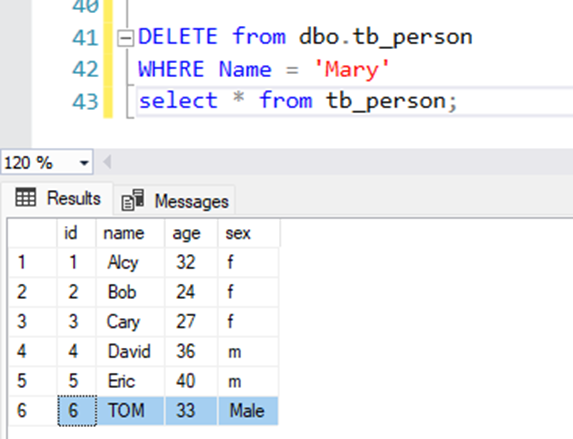
3, Delete a row:
DELETE from dbo.tb_person
WHERE Name = 'Mary'
select * from tb_person;
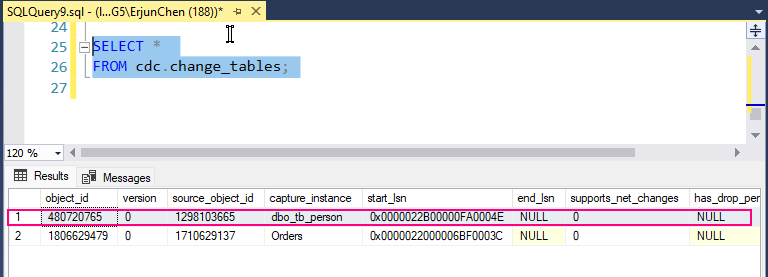
Step 5: Query the CDC Change Table
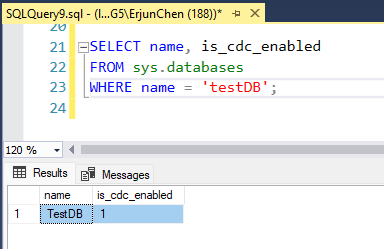
Once CDC is enabled, SQL Server will start capturing insert, update, and delete operations on the tracked tables.
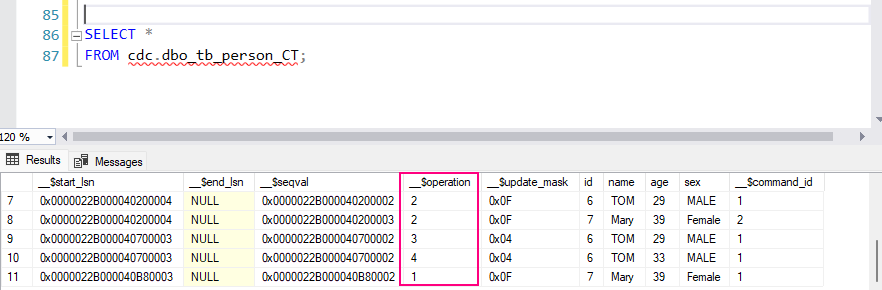
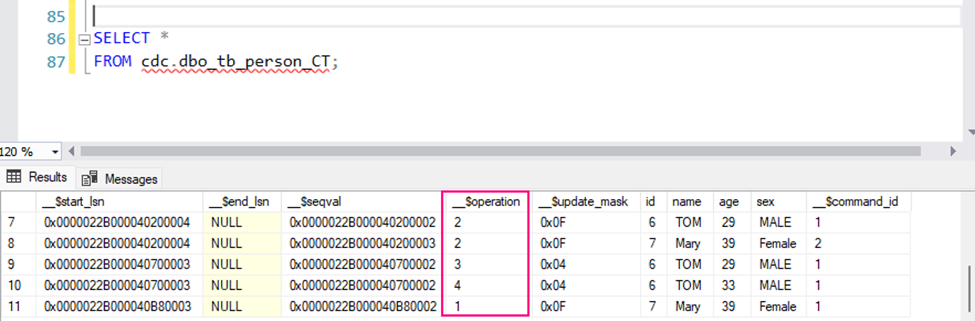
The CDC system creates specific change tables. The name of the change table is derived from the source table and schema. For example, for tb_Person in the dbo schema, the change table might be named something like cdc.dbo_tb_person_CT.
Querying the change table: To retrieve changes captured by CDC, you can query the change table directly:
SELECT *
FROM cdc.dbo_tb_person_CT;
This table contains:
__$operation: The type of operation:
1: DELETE
2: INSERT
3: UPDATE (before image)
4: UPDATE (after image)
__$start_lsn: The log sequence number (LSN) of the transaction.
Columns of the original table (e.g., OrderID, CustomerName, Product, etc.) showing the state of the data before and after the change.
Step 5: Manage CDC
As your tables grow, CDC will collect more data in its change tables. To manage this, SQL Server includes functions to clean up old change data.
1. Set up CDC clean-up jobs, Adjust the retention period (default is 3 days)
SQL Server automatically creates a cleanup job to remove old CDC data based on retention periods. You can modify the retention period by adjusting the @retention parameter.
EXEC sys.sp_cdc_change_job
@job_type = N'cleanup',
@retention = 4320; -- Retention period in minutes (default 3 days)
2. Disable CDC on a table:
If you no longer want to track changes on a table, disable CDC:
If you want to disable CDC for the entire database, run:
USE YourDatabaseName; GO EXEC sys.sp_cdc_disable_db; GO
Step 6: Monitor CDC
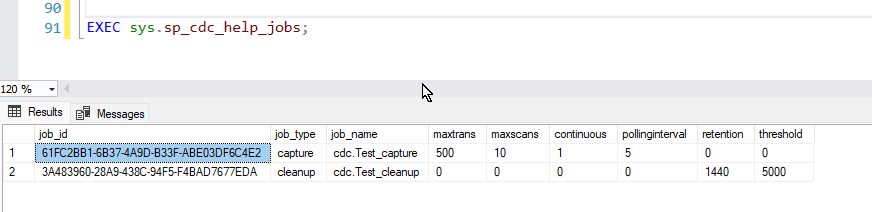
You can monitor CDC activity and performance using the following methods
1. Check the current status of CDC jobs:
EXEC sys.sp_cdc_help_jobs;
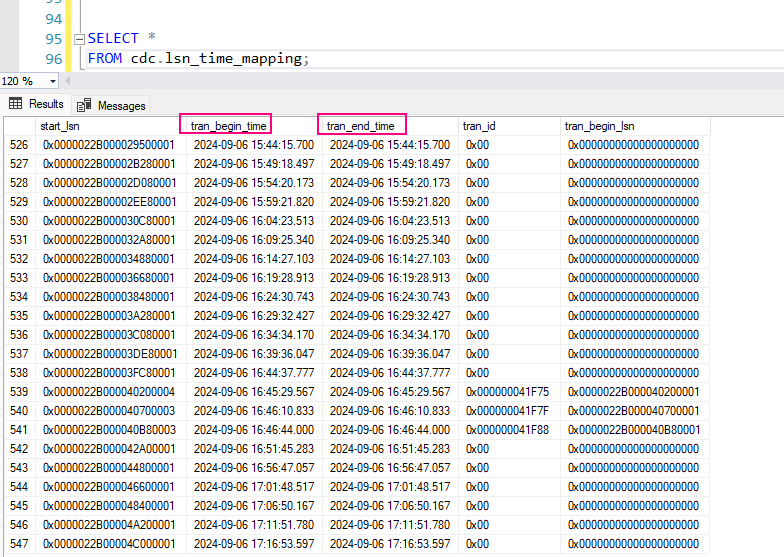
2. Monitor captured transactions:
You can query the cdc.lsn_time_mapping table to monitor captured LSNs and their associated times:
SELECT *
FROM cdc.lsn_time_mapping;
Step 7: Using CDC Data in ETL Processes
Once CDC is capturing data, you can integrate it into ETL processes or use it for auditing or tracking changes over time. Use change tables
cdc. [YourSchema]_[YourTableName]_CT
to identify rows that have been modified, deleted, or inserted, and process the changes accordingly. e.g.
SELECT *
FROM cdc.dbo_tb_person_CT;
System function cdc.fn_cdc_get_all_changes_<Capture_Instance>
cdc.fn_cdc_get_all_changes_<capture_instance>
The function fn_cdc_get_all_changes_<capture_instance> is a system function that allows you to retrieve all the changes (inserts, updates, and deletes) made to a CDC-enabled table over a specified range of log sequence numbers (LSNs).
For your table tb_person, if CDC has been enabled, the function to use would be:
@from_lsn: The starting log sequence number (LSN). This represents the point in time (or transaction) from which you want to begin retrieving changes.
@to_lsn: The ending LSN. This represents the point up to which you want to retrieve changes.
N'all': This parameter indicates that you want to retrieve all changes (including inserts, updates, and deletes).
Retrieve LSN Values
You need to get the LSN values for the time range you want to query. You can use the following system function to get the from_lsn and to_lsn values:
Get the minimum LSN for the CDC-enabled table: sys.fn_cdc_get_min_lsn(‘dbo_tb_person’) e.g. SELECT sys.fn_cdc_get_min_lsn(‘dbo_tb_person’);
Get the maximum LSN (which represents the latest changes captured): sys.fn_cdc_get_max_lsn(); SELECT sys.fn_cdc_get_max_lsn();
Use the LSN Values in the Query
Now, you can use these LSNs to query the changes. Here’s an example:
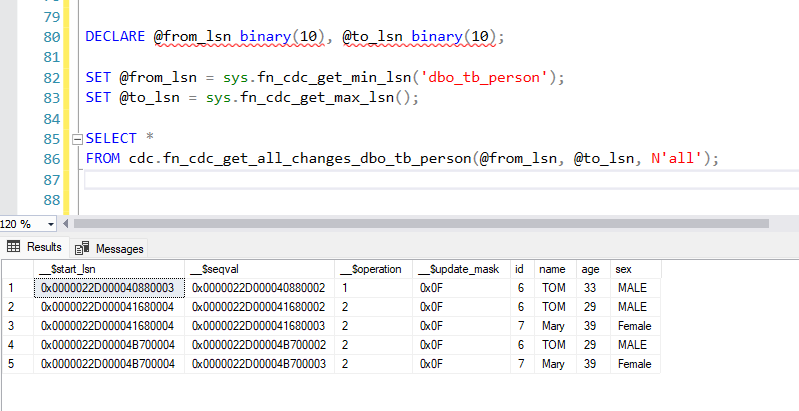
DECLARE @from_lsn binary(10), @to_lsn binary(10);
SET @from_lsn = sys.fn_cdc_get_min_lsn('dbo_tb_person');
SET @to_lsn = sys.fn_cdc_get_max_lsn();
SELECT *
FROM cdc.fn_cdc_get_all_changes_dbo_tb_person(@from_lsn, @to_lsn, N'all');
The result set will include:
__$operation: The type of change (1 = delete, 2 = insert, 3 = update before, 4 = update after).
__$start_lsn: The LSN value at which the change occurred.
__$seqval: Sequence value for sorting the changes within a transaction.
__$update_mask: Binary value indicating which columns were updated.
All the columns from the original tb_person table.
Querying Only Inserts, Updates, or Deletes
If you want to query only a specific type of change, such as inserts or updates, you can modify the function’s third parameter:
Inserts only:
SELECT *
FROM cdc.fn_cdc_get_all_changes_dbo_tb_person(@from_lsn, @to_lsn, N'insert');
Updates only:
SELECT *
FROM cdc.fn_cdc_get_all_changes_dbo_tb_person(@from_lsn, @to_lsn, N'update');
Deletes only:
SELECT *
FROM cdc.fn_cdc_get_all_changes_dbo_tb_person(@from_lsn, @to_lsn, N'delete');
Map datetime to log sequence number (lsn)
sys.fn_cdc_map_time_to_lsn
The sys.fn_cdc_map_time_to_lsn function in SQL Server is used to map a datetime value to a corresponding log sequence number (LSN) in Change Data Capture (CDC). Since CDC captures changes using LSNs, this function is helpful to find the LSN that corresponds to a specific point in time, making it easier to query CDC data based on a time range.
lsn_time_mapping: Specifies how you want to map the datetime_value to an LSN. It can take one of the following values:
smallest greater than or equal: Returns the smallest LSN that is greater than or equal to the specified datetime_value.
largest less than or equal: Returns the largest LSN that is less than or equal to the specified datetime_value.
datetime_value: The datetime value you want to map to an LSN.
Using sys.fn_cdc_map_time_to_lsn() in a CDC Query
Mapping a Date/Time to an LSN
-- Mapping a Date/Time to an LSN
DECLARE @from_lsn binary(10);
SET @from_lsn = sys.fn_cdc_map_time_to_lsn('smallest greater than or equal', '2024-09-06 12:00:00');
This will map the datetime'2024-09-06 12:00:00' to the corresponding LSN.
Finding the Largest LSN Before a Given Time
-- Finding the Largest LSN Before a Given Time
DECLARE @to_lsn binary(10);
SET @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', '2024-09-06 12:00:00');
This will return the largest LSN that corresponds to or is less than the datetime'2024-09-06 12:00:00'.
from_lsn: The starting LSN in the range of changes to be retrieved.
to_lsn: The ending LSN in the range of changes to be retrieved.
row_filter_option: Defines which changes to return:
'all': Returns both the before and after images of the changes for update operations.
'all update old': Returns the before image of the changes for update operations.
'all update new': Returns the after image of the changes for update operations.
Let’s say you want to find all the changes made to the tb_person table between '2024-09-05 08:00:00' and '2024-09-06 18:00:00'. You can map these times to LSNs and then query the CDC changes.
-- Querying Changes Between Two Time Points
DECLARE @from_lsn binary(10), @to_lsn binary(10);
-- Map the datetime range to LSNs
SET @from_lsn = sys.fn_cdc_map_time_to_lsn('smallest greater than or equal', '2024-09-05 08:00:00');
SET @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', '2024-09-06 18:00:00');
-- Query the CDC changes for the table tb_person within the LSN range
SELECT *
FROM cdc.fn_cdc_get_all_changes_dbo_tb_person(@from_lsn, @to_lsn, N'all');
Output:
This query will return the following data for changes between the specified LSN range:
__$operation: Indicates whether the row was inserted, updated, or deleted.
__$start_lsn: The LSN at which the change occurred.
Other columns: Any other columns that exist in the tb_person table.
Using sys.fn_cdc_map_lsn_to_time () convert an LSN value to a readable datetime
In SQL Server, Change Data Capture (CDC) tracks changes using Log Sequence Numbers (LSNs), but these LSNs are in a binary format and are not directly human-readable. However, you can map LSNs to timestamps (datetime values) using the system function sys.fn_cdc_map_lsn_to_time
Syntax
sys.fn_cdc_map_lsn_to_time (lsn_value)
Example: Mapping LSN to Datetime
Get the LSN range for the cdc.fn_cdc_get_all_changes function:
DECLARE @from_lsn binary(10), @to_lsn binary(10);
-- Get minimum and maximum LSN for the table
SET @from_lsn = sys.fn_cdc_get_min_lsn('dbo_tb_person');
SET @to_lsn = sys.fn_cdc_get_max_lsn();
Query the CDC changes and retrieve the LSN values:
-- Query CDC changes for the tb_person table SELECT $start_lsn, $operation, PersonID, FirstName, LastName FROM cdc.fn_cdc_get_all_changes_dbo_tb_person(@from_lsn, @to_lsn, 'all');
Convert the LSN to a datetime using sys.fn_cdc_map_lsn_to_time
-- Convert the LSN to datetime
SELECT $start_lsn, sys.fn_cdc_map_lsn_to_time($start_lsn) AS ChangeTime,
__$operation,
PersonID,
FirstName,
LastName
FROM cdc.fn_cdc_get_all_changes_dbo_tb_person(@from_lsn, @to_lsn, 'all');
Output
$start_lsn ChangeTime __$operation PersonID FirstName LastName 0x000000240000005A 2024-09-06 10:15:34.123 2 1 John Doe 0x000000240000005B 2024-09-06 10:18:45.321 4 1 John Smith 0x000000240000005C 2024-09-06 10:25:00.789 1 2 Jane Doe
Explanation
sys.fn_cdc_map_lsn_to_time(__$start_lsn) converts the LSN from the CDC changes to a human-readable datetime.
This is useful for analyzing the time at which changes were recorded.
Notes:
CDC vs Temporal Tables: CDC captures only DML changes (inserts, updates, deletes), while temporal tables capture a full history of changes.
Performance: Capturing changes can add some overhead to your system, so it’s important to monitor CDC’s impact on performance.
Summary
Step 1: Enable CDC at the database level.
Step 2: Enable CDC on the SalesOrder table.
Step 3: Verify CDC is enabled.
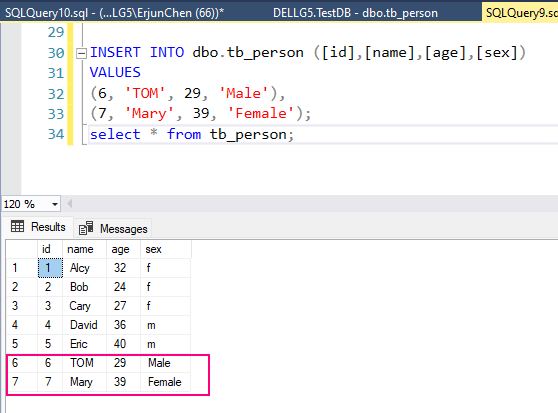
Step 4: Perform data changes (insert, update, delete).
Step 5: Query the CDC change table to see captured changes.
Step 6: Manage CDC retention and disable it when no longer needed.
Step 7: Using CDC Data in ETL Processes
This step-by-step example shows how CDC captures data changes, making it easier to track, audit, or integrate those changes into ETL pipelines.
Please do not hesitate to contact me if you have any questions at William . chen @ mainri.ca
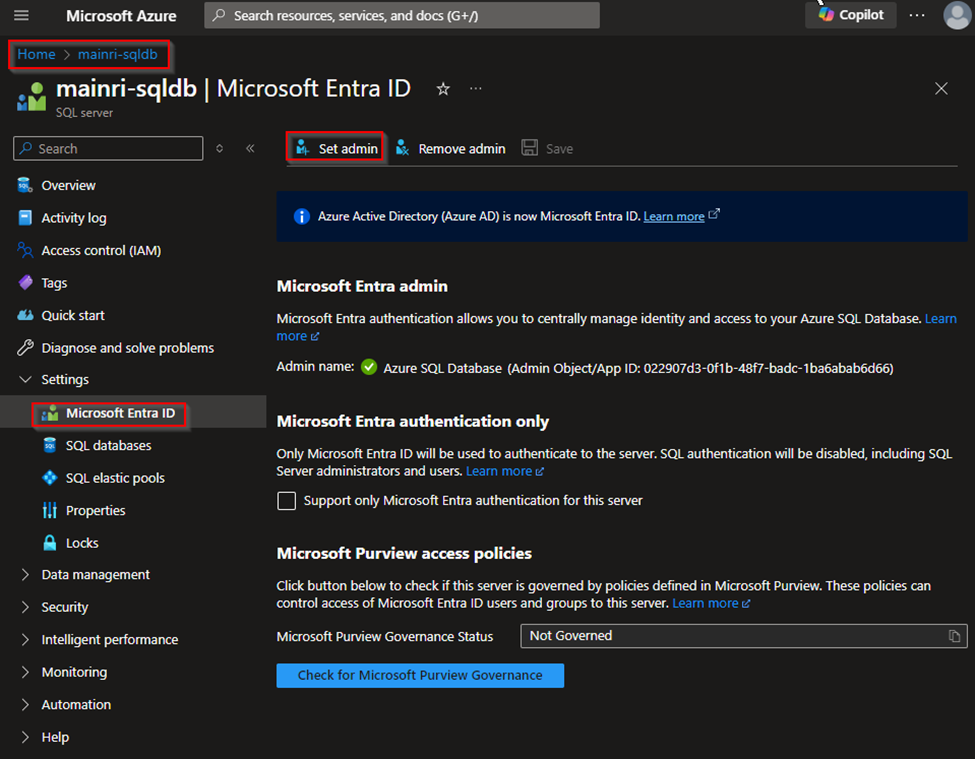
Azure SQL Database can be integrated with Azure Entra ID to provide identity and access management. With this integration, users can sign in to Azure SQL Database using their Azure Entra ID credentials, enabling a centralized and secure way to manage database access.
Register the SQL Server in Azure Entra ID
Enable Azure Entra ID Admin
Register your SQL Server (or SQL Database) as an application in Azure Entra ID.
Azure Portal > find out the SQL Server that you want to register with Azure Entra ID >
Settings > Microsoft Entra ID (Active Directory Admin)
Assign Users/Groups
You can assign Azure Entra ID users or groups to specific roles within the SQL Database, such as db_owner, db_datareader, or db_datawriter.
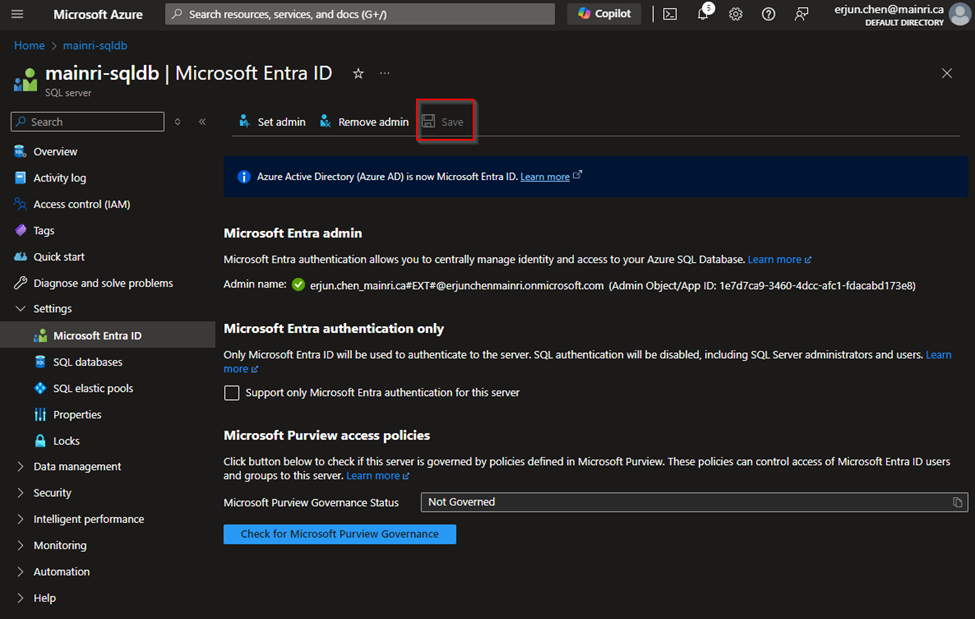
Then, Click Save to apply the changes.
Configure Azure Entra ID Authentication in Azure SQL Database
Connect to SQL Database using Azure Entra ID
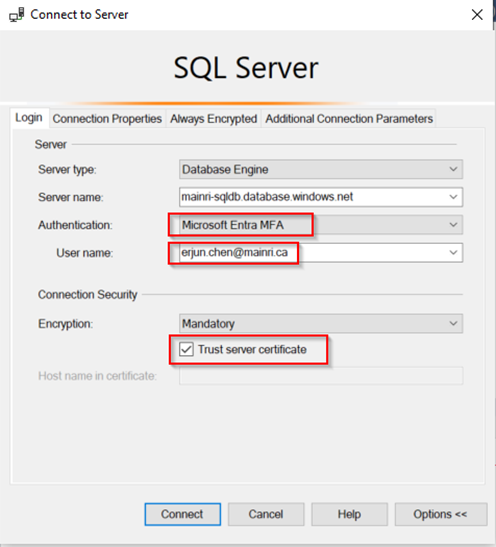
You can connect to your Azure SQL Database using Azure Entra ID by selecting the “Azure Active Directory – Universal with MFA support” authentication method in tools like SQL Server Management Studio (SSMS).
Assign Roles to Azure Entra ID Users
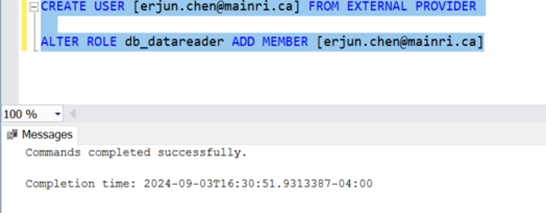
Use a SQL query to assign roles to Azure Entra ID users or groups. For example:
CREATE USER [your_username@yourdomain.com] FROM EXTERNAL PROVIDER; ALTER ROLE db_datareader ADD MEMBER [your_username@yourdomain.com];
This command creates an Azure Entra ID user in your SQL Database and adds them to the db_datareader role.
Set Up Role-Based Access Control (RBAC)
You can manage permissions through Azure Entra ID roles and assign these roles to your SQL Database resources.
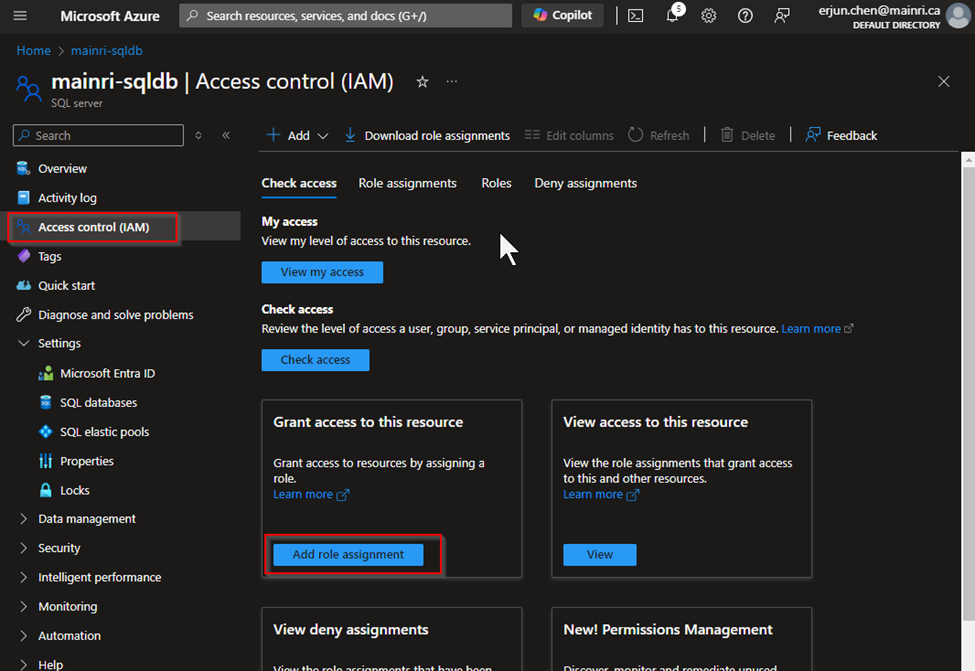
Assign Roles via Azure Portal
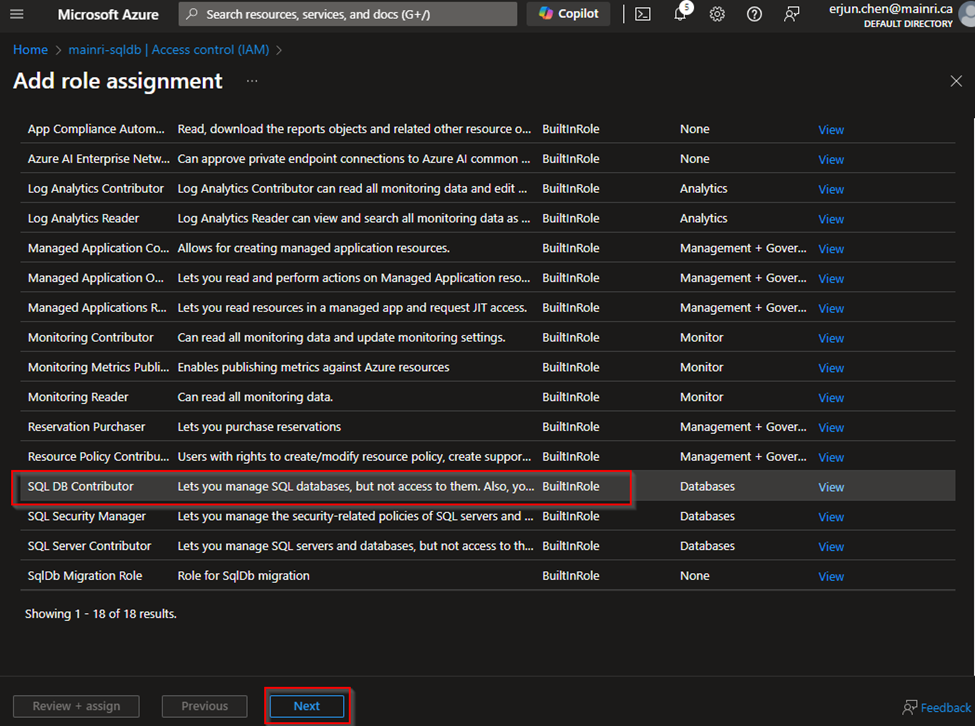
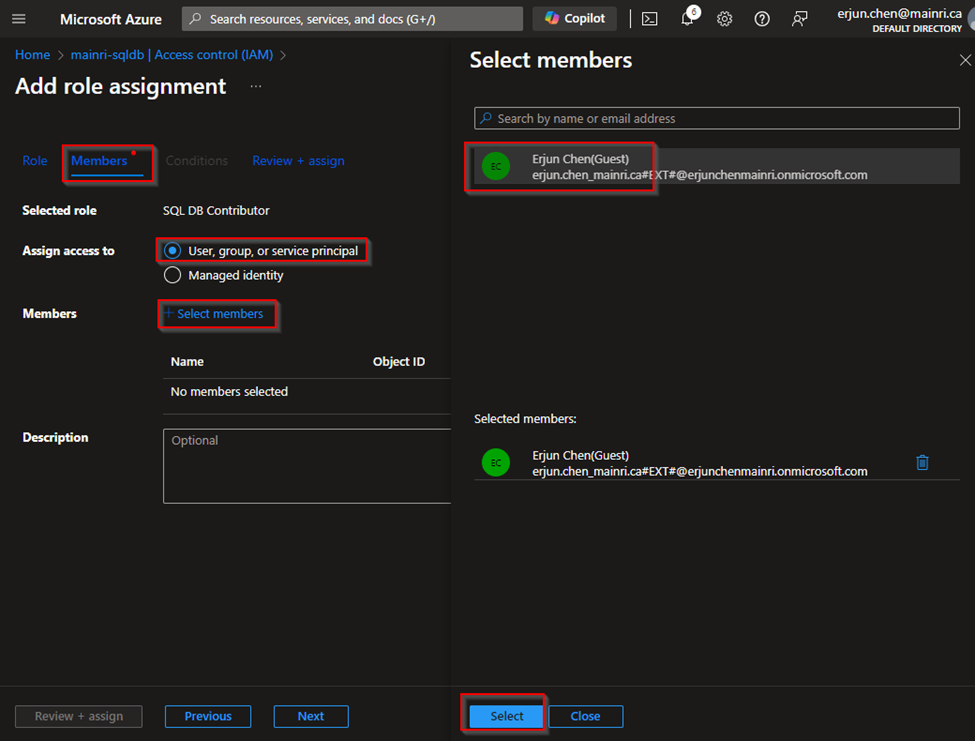
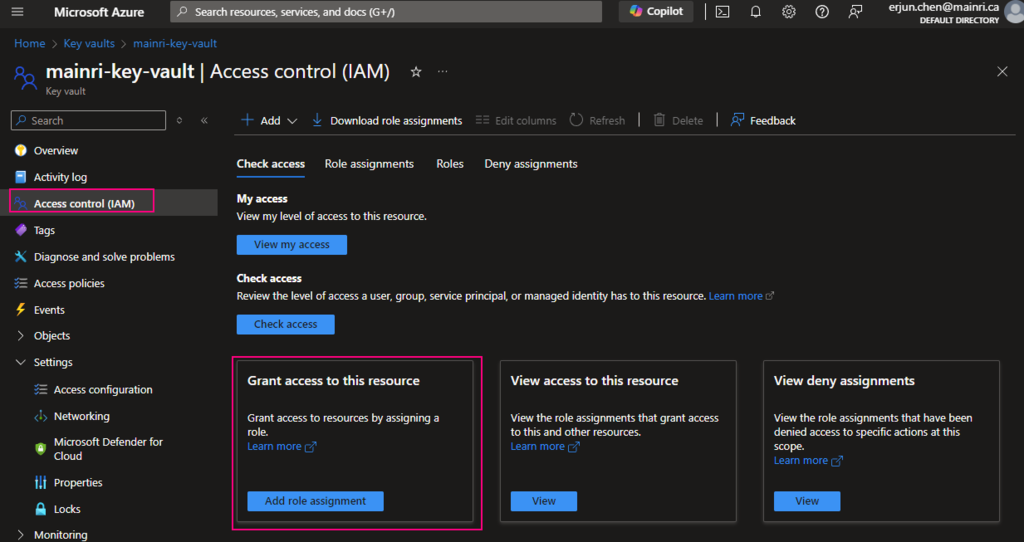
Azure portal > your SQL Database > Access control (IAM) > Add role assignment.
Choose the appropriate role, such as “SQL DB Contributor“.
and assign it to the desired Azure Entra ID user or group
Considerations
No Password Management: Since authentication is managed via Azure Entra ID, there’s no need to manage passwords directly within the database.
Integration with Conditional Access: This allows you to enforce compliance requirements, such as requiring MFA or ensuring connections only come from specific locations.
Please do not hesitate to contact me if you have any questions at William . chen @ mainri.ca
Azure Key Vault safeguards encryption keys and secrets like certificates, connection strings, and passwords.
Key vaults define security boundaries for stored secrets. It allows you to securely store service or application credentials like passwords and access keys as secrets. All secrets in your key vault are encrypted with a software key. When you use Key Vault, you no longer need to store security information in your applications. Not having to store security information in applications eliminates the need to make this information part of the code.
What is a secret in Key Vault?
In Key Vault, a secret is a name-value pair of strings. Secret names must be 1-127 characters long, contain only alphanumeric characters and dashes, and must be unique within a vault. A secret value can be any UTF-8 string up to 25 KB in size.
Vault authentication and permissions
Developers usually only need Get and List permissions to a development-environment vault. Some engineers need full permissions to change and add secrets, when necessary.
For apps, often only Get permissions are required. Some apps might require List depending on the way the app is implemented. The app in this module’s exercise requires the List permission because of the technique it uses to read secrets from the vault.
In this article, we will focus on 2 sections, set up secrets in Key Vault and application retrieves secrets that ware saved in Key vault.
Create a Key Vault and store secrets
Creating a vault requires no initial configuration. You can start adding secrets immediately. After you have a vault, you can add and manage secrets from any Azure administrative interface, including the Azure portal, the Azure CLI, and Azure PowerShell. When you set up your application to use the vault, you need to assign the correct permissions to it
Create a Key Vault service
To create Azure Key Vault service, you can follow the steps.
From Azure Portal, search “key Vault”
click “key Vault”
Fill in all properties
Click review + create. That’s all. Quite simple, right?
Create secrets and save in Key Vault
There are two ways to create secret and save in Key vault.
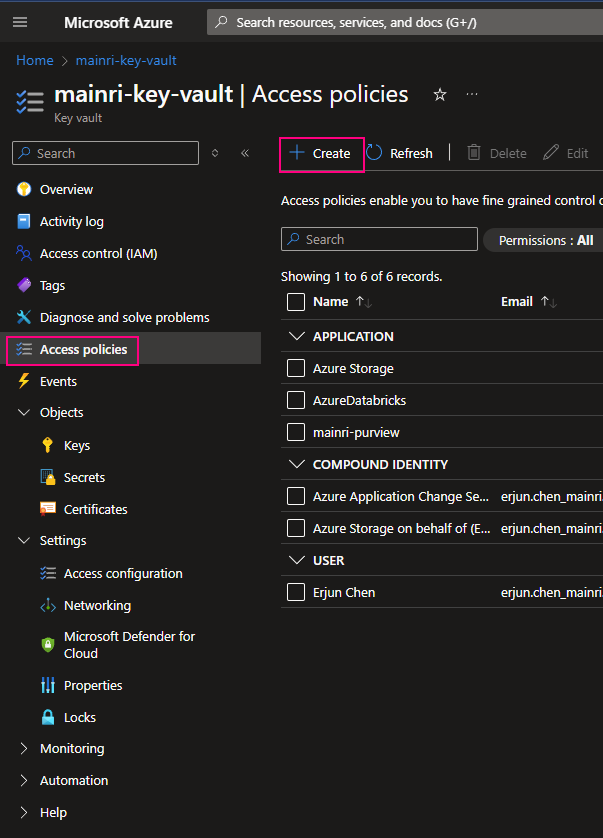
Access control, Identity and Access management (IAM)
Access Policies
Using Access Control (IAM) create a secret
From Key Vault> Access Control (IAM) > Add role Assignment
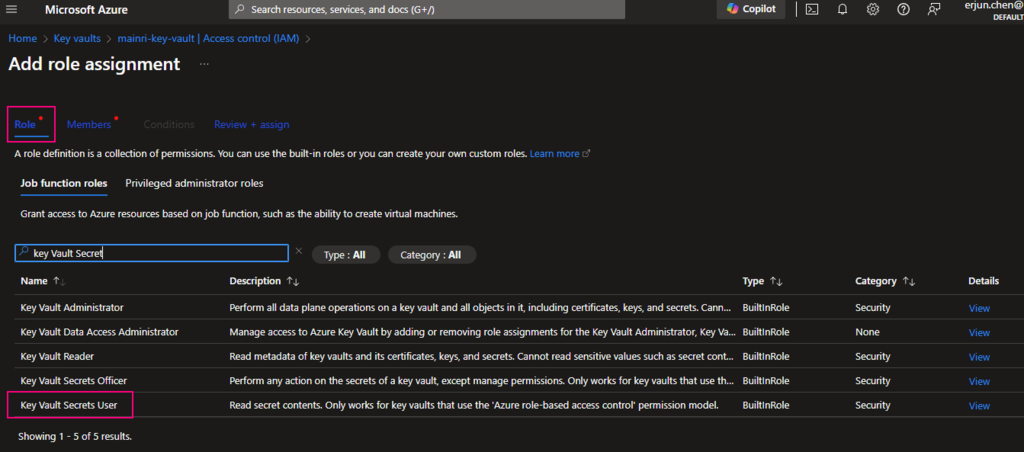
In most cases, if you create and save secrets in key-vault for your users to use, you only need add the “Key vault secrets user” role assignment.
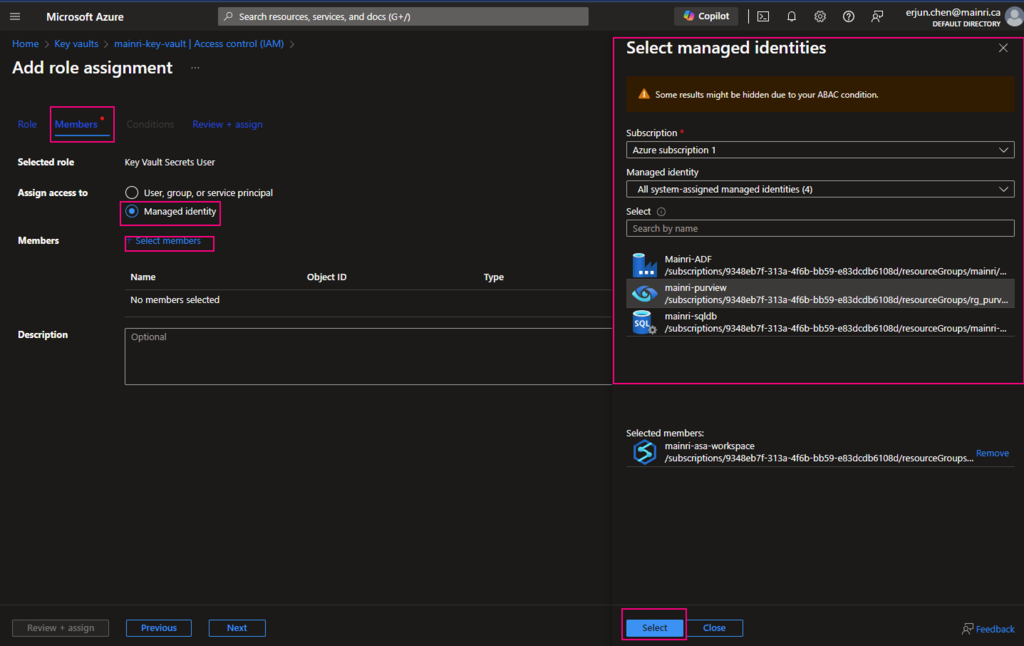
click “next” select a member or group
Pay attention to here, if your organization has multiple instances of the same services, for example, different teams are independently using different ADF instants, make sure you correctly, accurately add the right service instant to access policies.
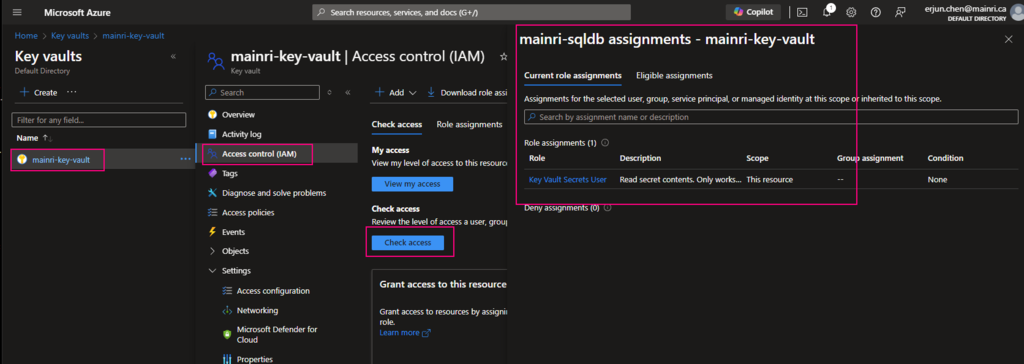
Once it’s down, check the access.
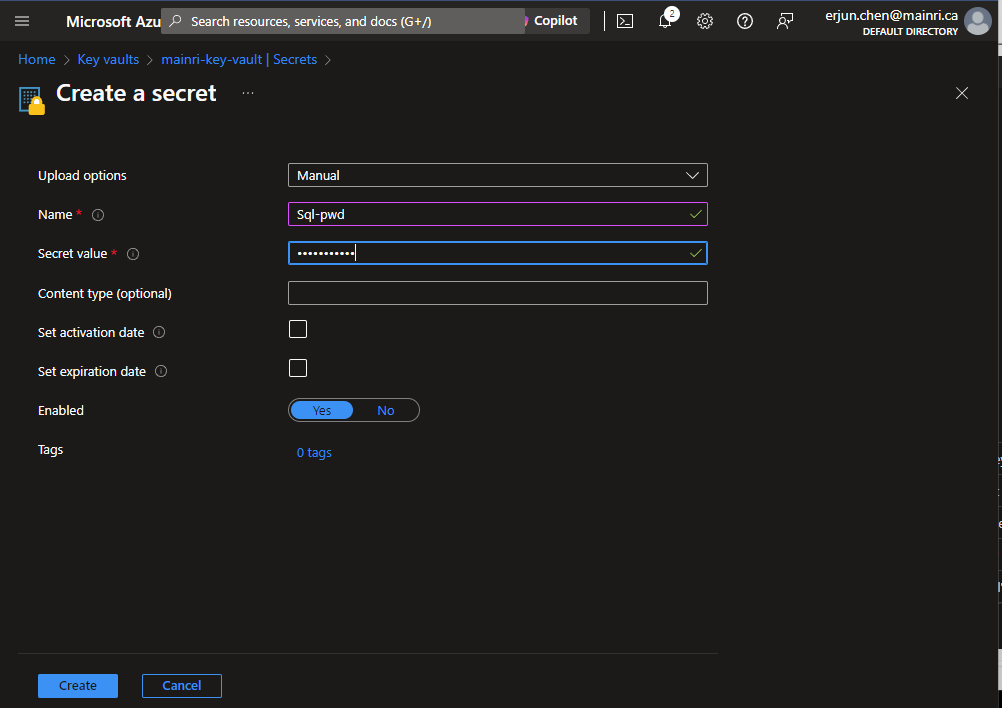
Create a Secret
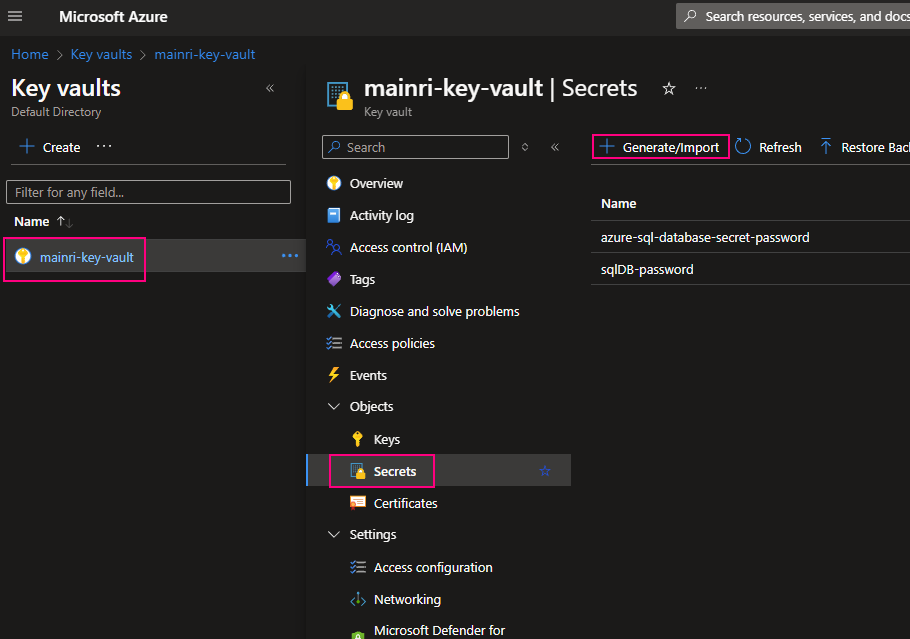
From “Key Vault” > “Object” > “Secrets” > “+ Generate/Import”
Fill in all properties, :Create”
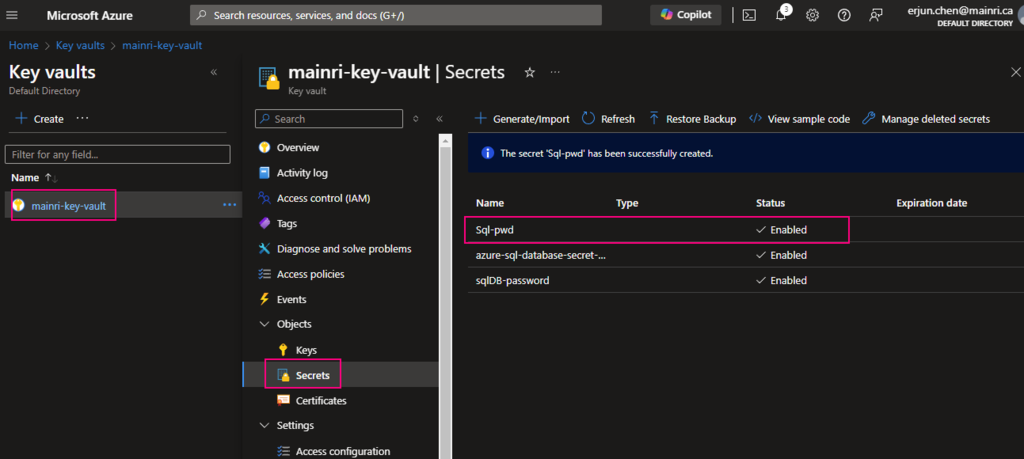
Secrets key and value created That’s all.
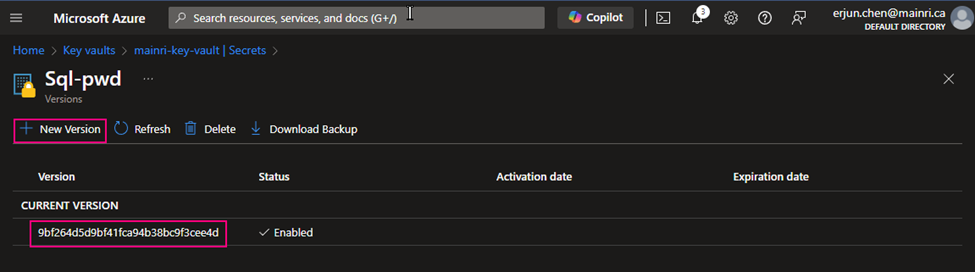
If you want to update the secret, simply click the key, follow the UI guide, you will not miss it.
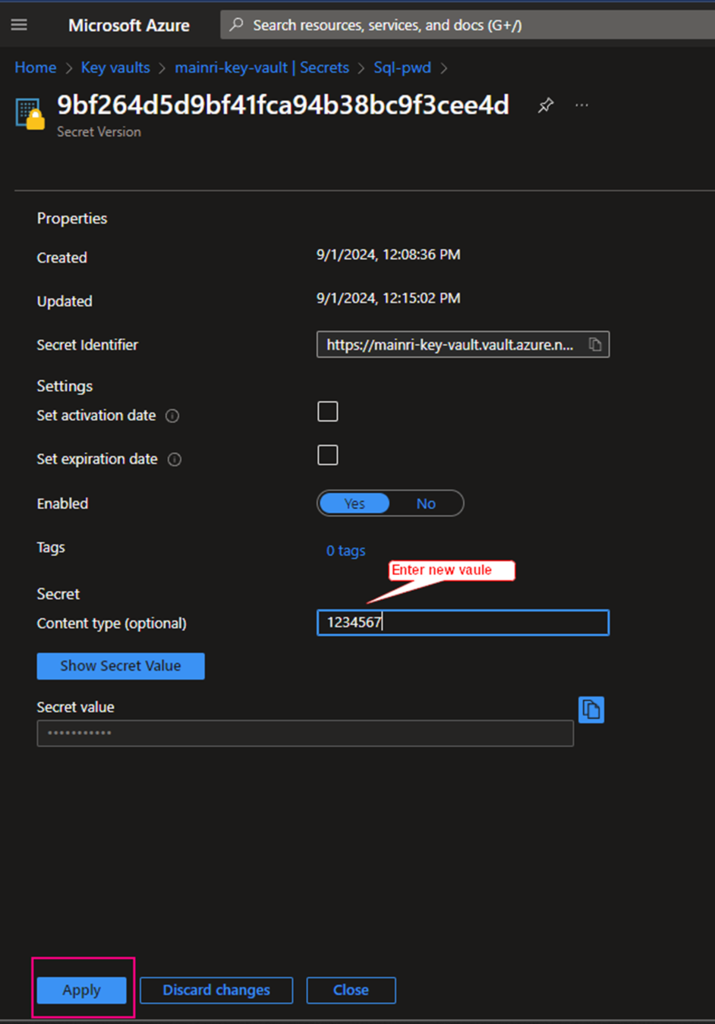
Click the “version” that you want to update. Update the content > apply it.
That’s all.
Using Access Policies create a secret
There is another way “Access Policies” to create a secret.
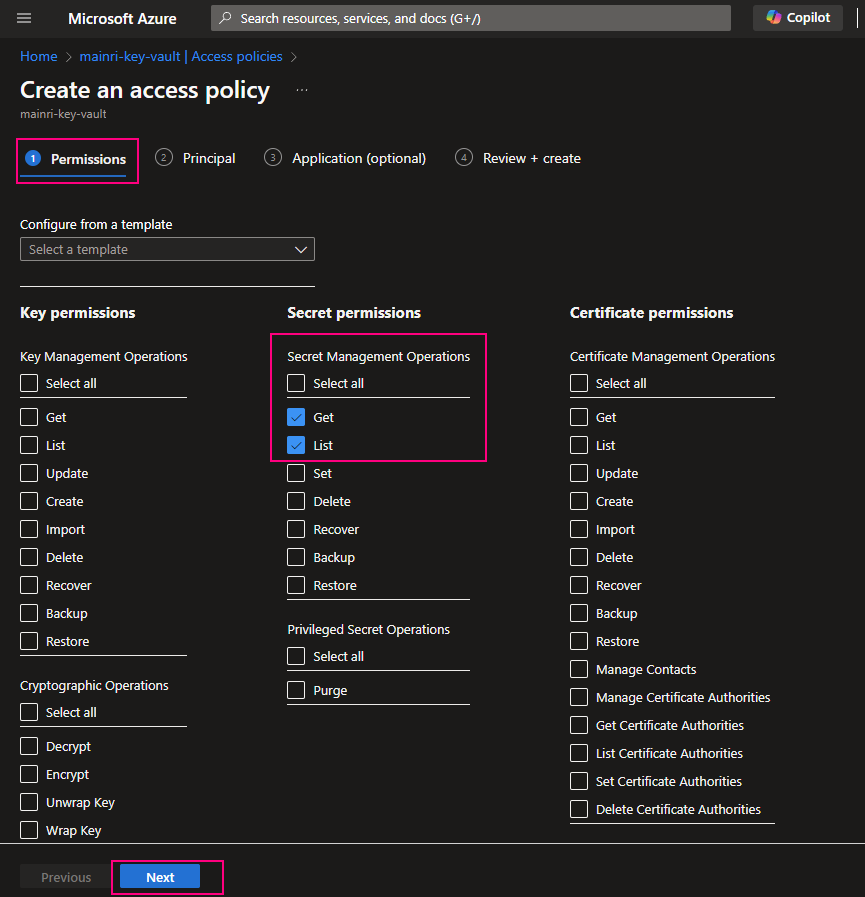
Select the permissions you want under Key permissions, Secret permissions, and Certificate permissions.
If you create a key secret for users to use in their application or other azure services, usually you give “get” and “list” in the “Secret permissions” enough. Otherwise, check Microsoft official documentation.
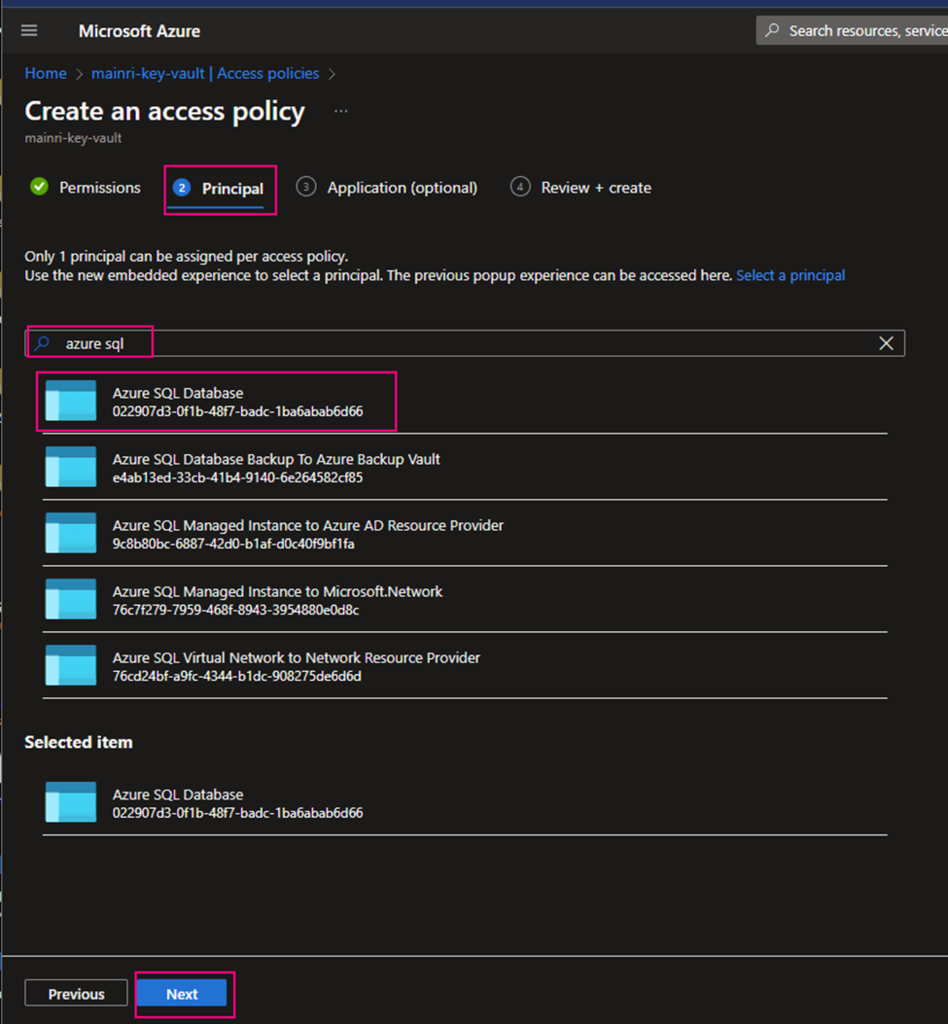
Under the Principal selection pane, enter the name of the user, app or service principal in the search field and select the appropriate result.
Using Azure SQL Database as an example
Caution: when you add principal, make sure you select right service instant. Especially you act as a infrastructure administer, your organization has multiple teams that they are independently using different service instants, e.g. different Synapse Workspace. select correct instant. I have been asked to help trouble shotting this scenario a few time. Azure admin says, he has added policies to key-vault, but the use cannot access there yet. that is a funny mistake made, he has added ADF to kay-vault policies, unfortunately, the ADF is NOT team A used, team B is using it. 🙂
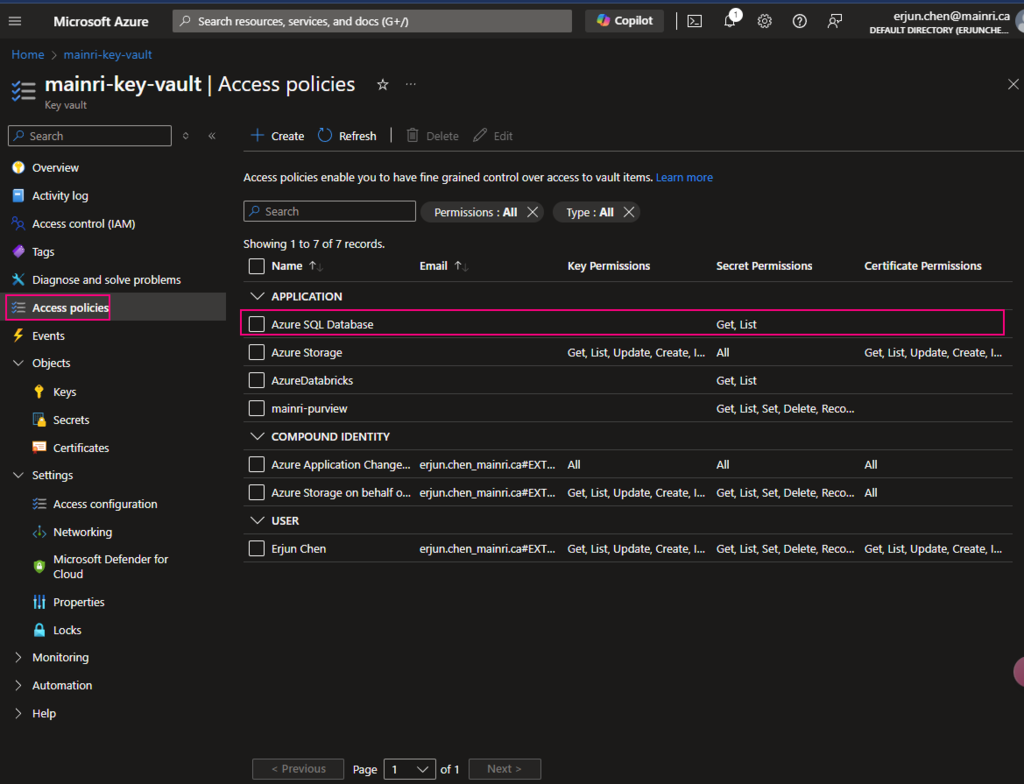
Back on the Access policies page, verify that your access policy is listed.
Create secret key and value
We have discussed it above. Need not verbose.
Done!
Using secrets that were saved in Key Vault
Using secrets usually have 2 major scenarios, directly use, or use REST API call to retrieve the saved secret value.
Let’s use Data Factory as an example to discuss.
Scenario 1, directly use it
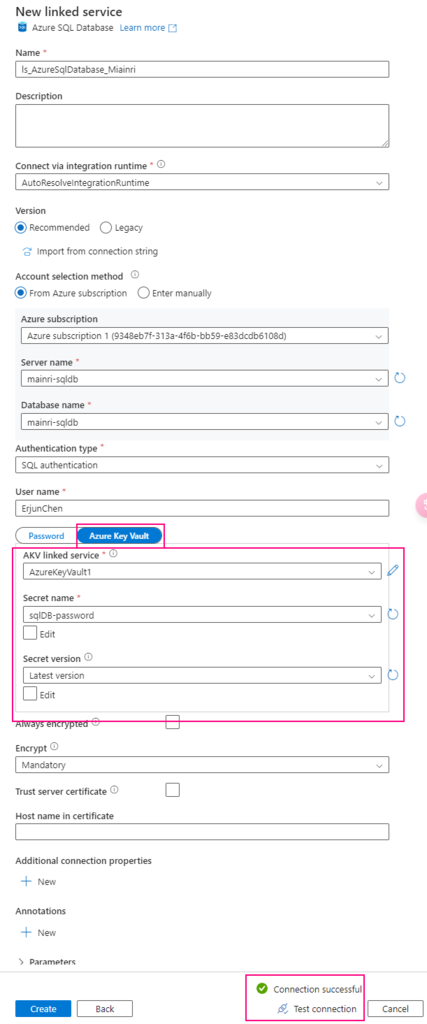
For example, when you create linked service to connect Azure Sql Database
You have to make sure that Key Vault’s access policies has this ADF access policies, get and list
one more example, System workspaces use key-vault.
Once again, make sure your Synapse Workspace has access policies, “Key Vault Secrets User“, “get” and “List”
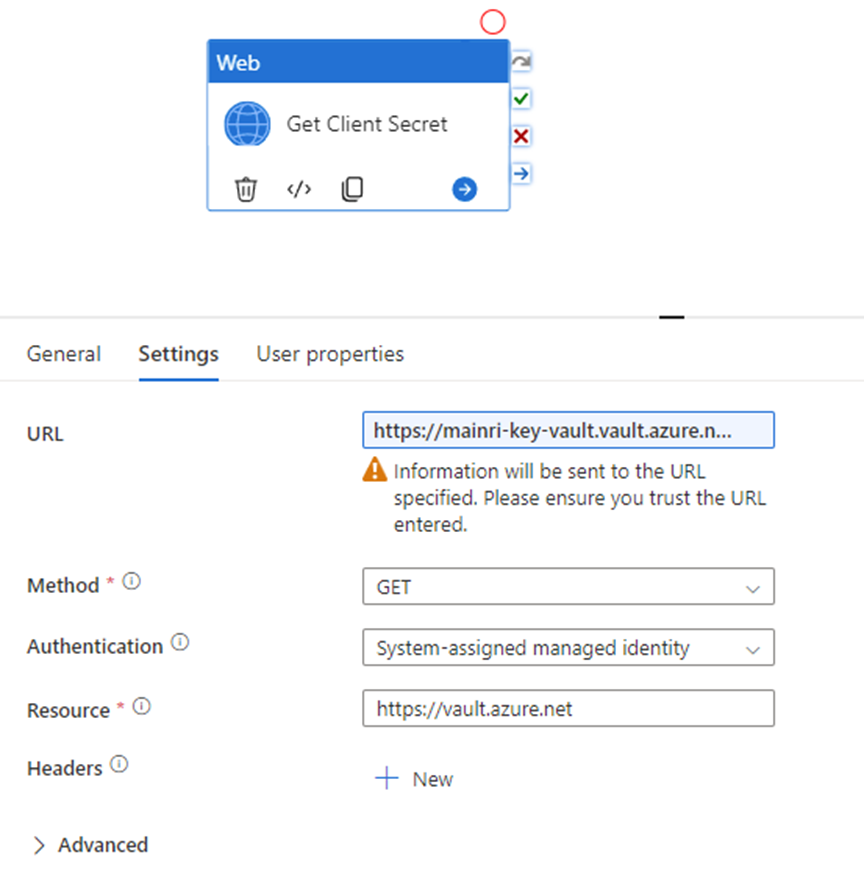
Scenario 2, REST API call Key Vault to use secret
Many engineers want to call the key Vault to retrieve the secret value for a certain purpose, e.g. Synapse pipeline to get SharePoint Online list or files that resident in SharePoint Library, you need an application secret value to build the query string. Normally, the application’s secret value is saved in Key Vault. In this case, you have to make a http call to Key value.
Get a specified secret from a given key vault. The GET operation is applicable to any secret stored in Azure Key Vault. This operation requires the secrets/get permission.
GET {vaultBaseUrl}/secrets/{secret-name}/{secret-version}?api-version=7.4
Before we scan data sources in Azure Purview, we have to register data resources that to be scanned.
First, we will learn the concept of managed identity and how Azure purview uses it.
Second, we will learn the steps involved in registering ADLS Gen2.
Azure Purview Managed Identity
We will use Azure Purview Managed Identity that is an Azure resource feature found in Azure Active Directory (Azure AD). The managed identities for Azure resources feature is free and there’s no additional cost.
We can use the identity to authenticate to any service that supports Azure AD authentication, including Key Vault, without any credentials in your code. We will use Azure Purview Managed Identity.
Let’s register source data first.
We have to follow these steps to register and scan ADLS Gen 2 account:
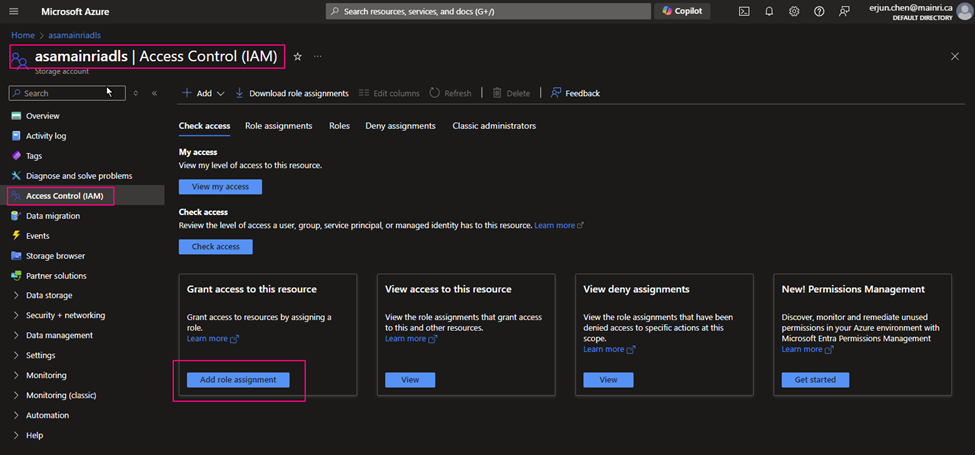
Grant the Azure Purview Managed Identity access to ADLS Gen2 so purview can have access to it. Preview managed identity should have storage blob reader permission on ADLS Gen2
Scan ADLS Gen2 with the Purview Managed Identity registered in step 1
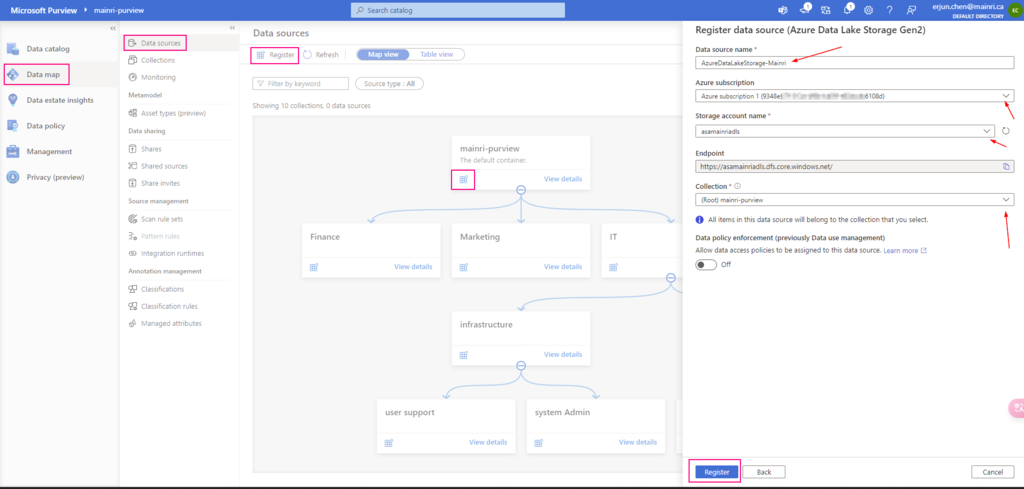
Register an Azure Data Lake Storage Gen2 account
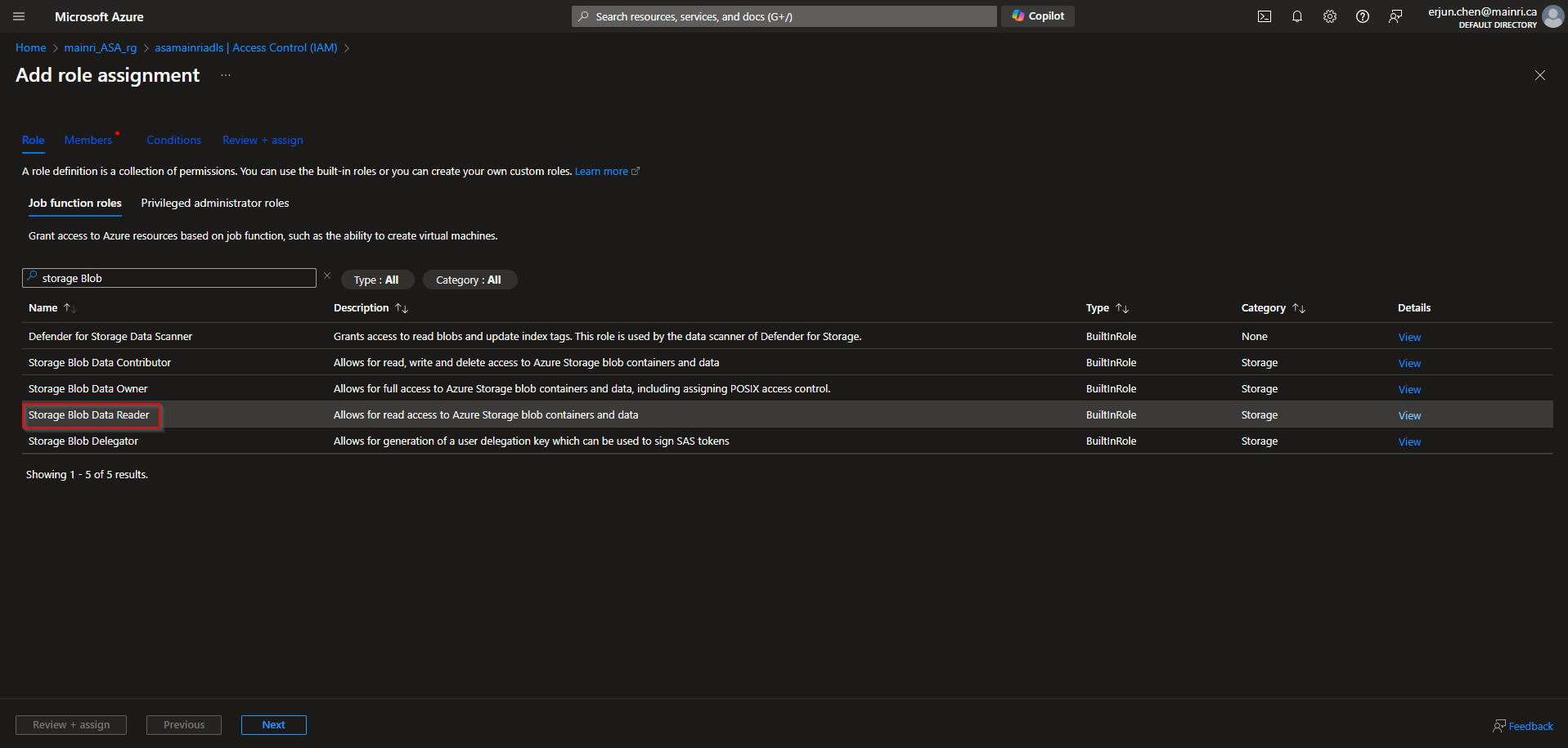
Azure Portal > ADLS > Access Control > Add role assignment
> storage BLOB Data
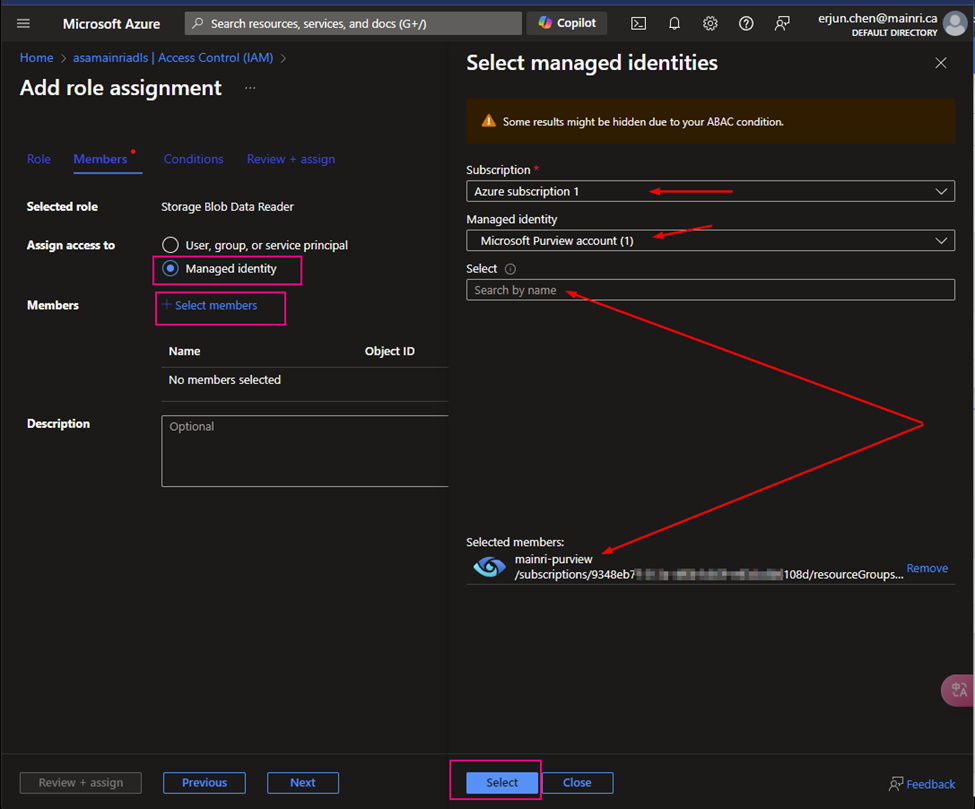
>Select managed Identities
>next > next > review + assign
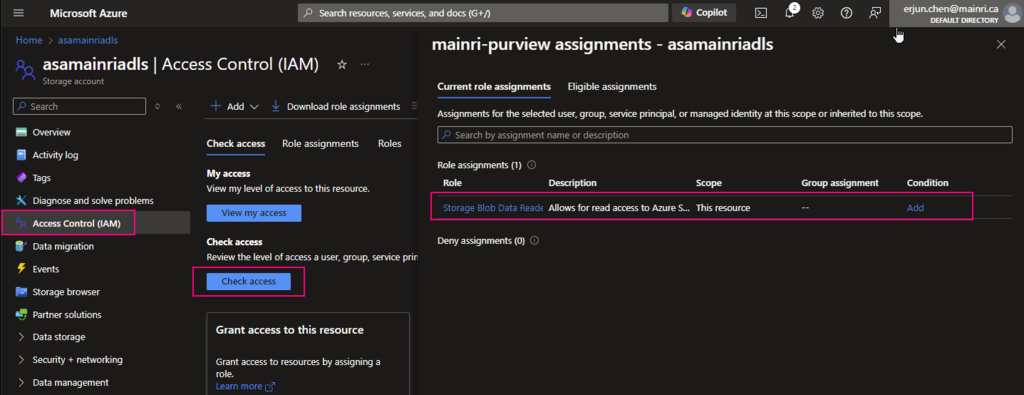
Now, you can “check access”, Now, you can “check access”. It’s added/
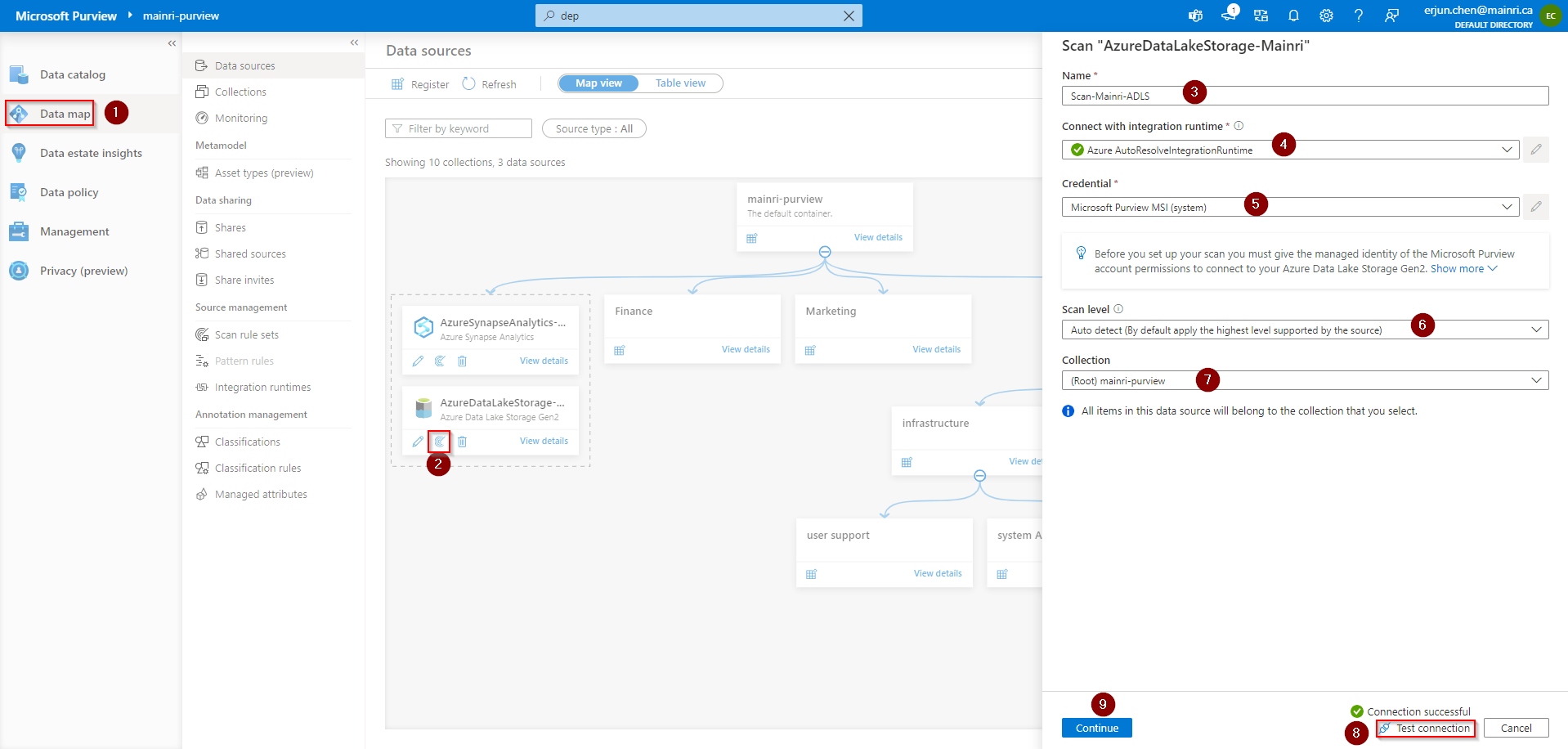
now, it’s time for scanning. from Azure Purview Studio
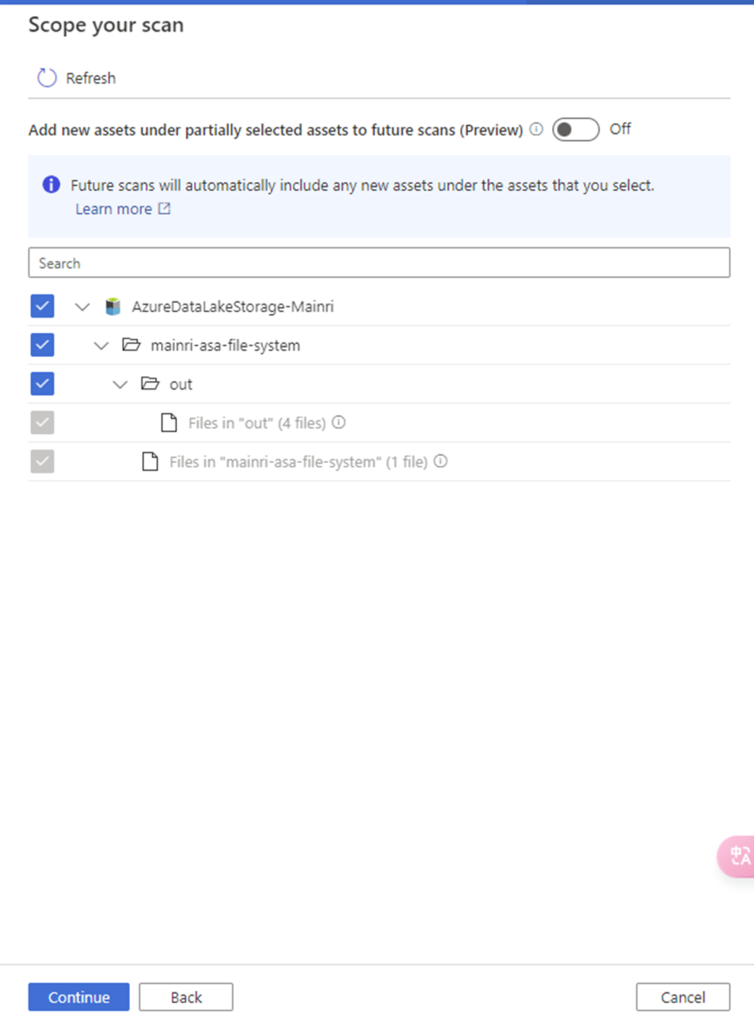
Scope your scan
You will see “scope your scan”. Now we can see all my data and directory structure on ADLS appear.
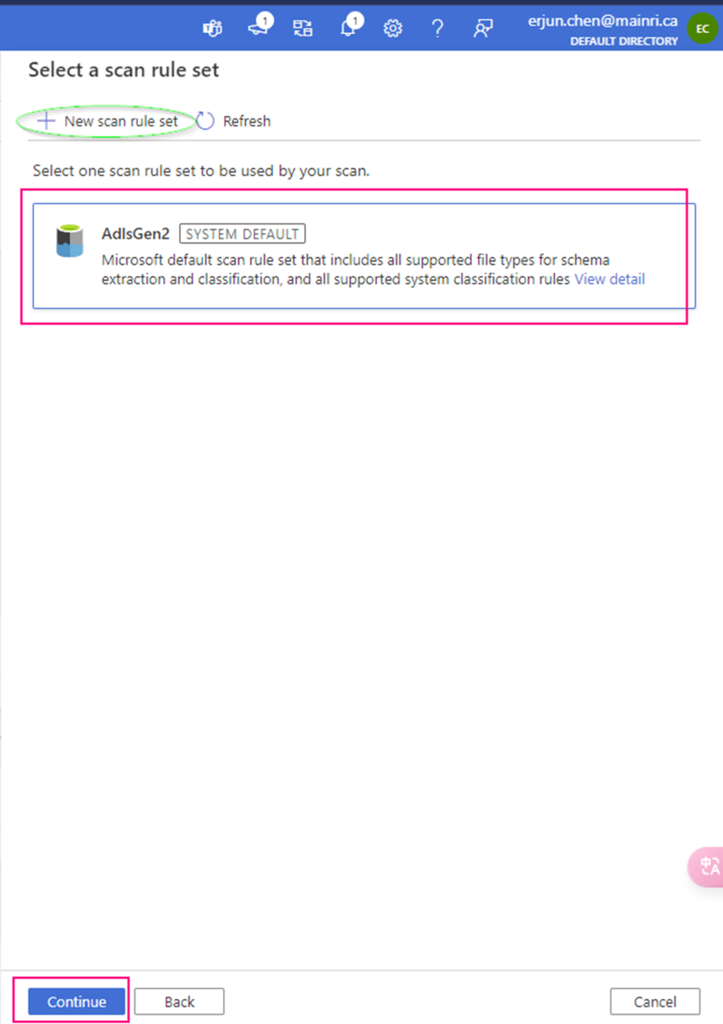
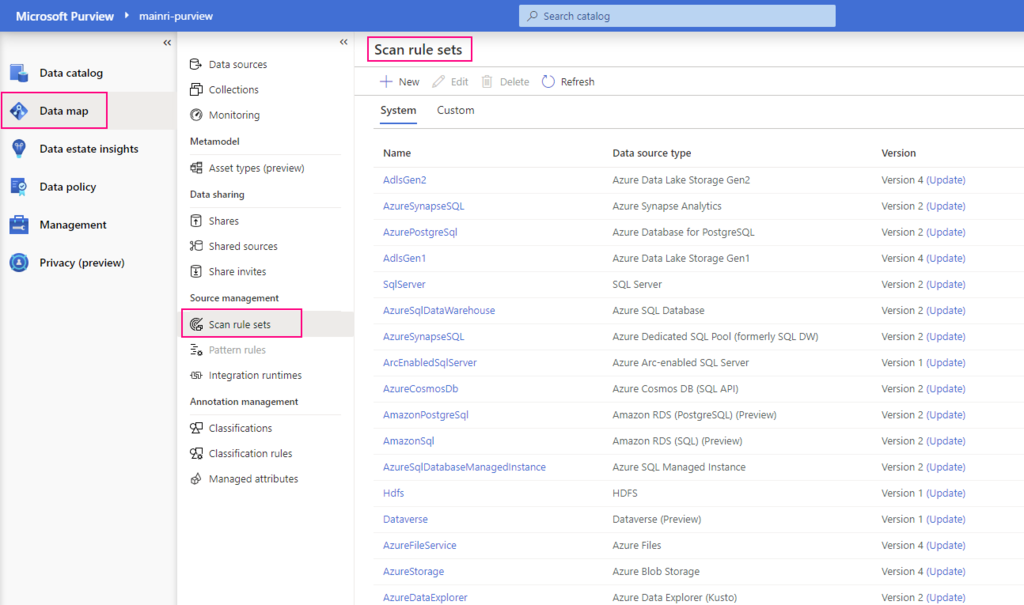
Select scan rule set
We have talked the rile sets in last article. You are able to add even more new scan rule set at this step if you like, or use default Azure System default scan rule set.
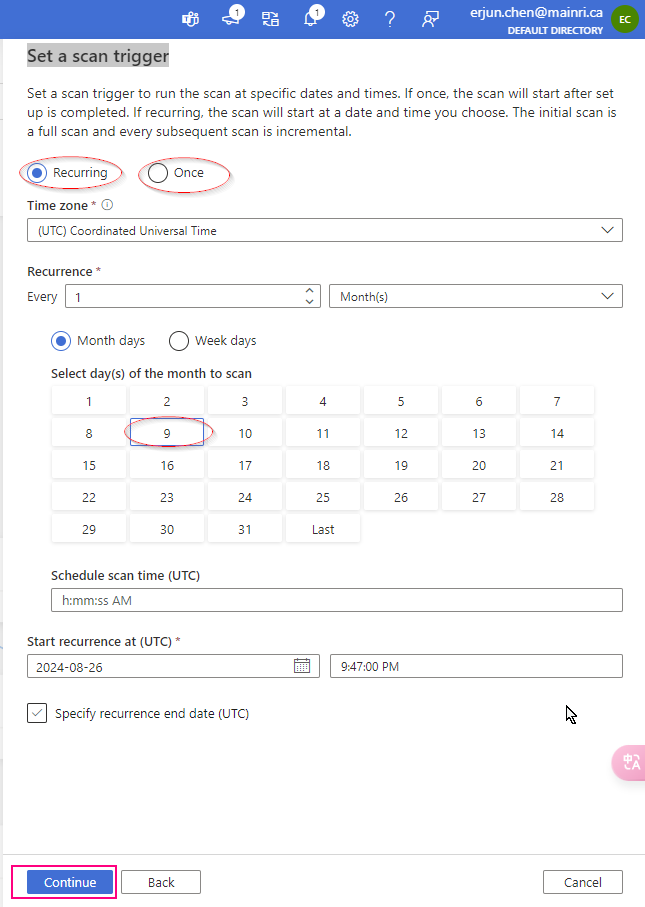
Set a scan trigger
Click the continue, you can setup trigger to scan, either once or recurring.
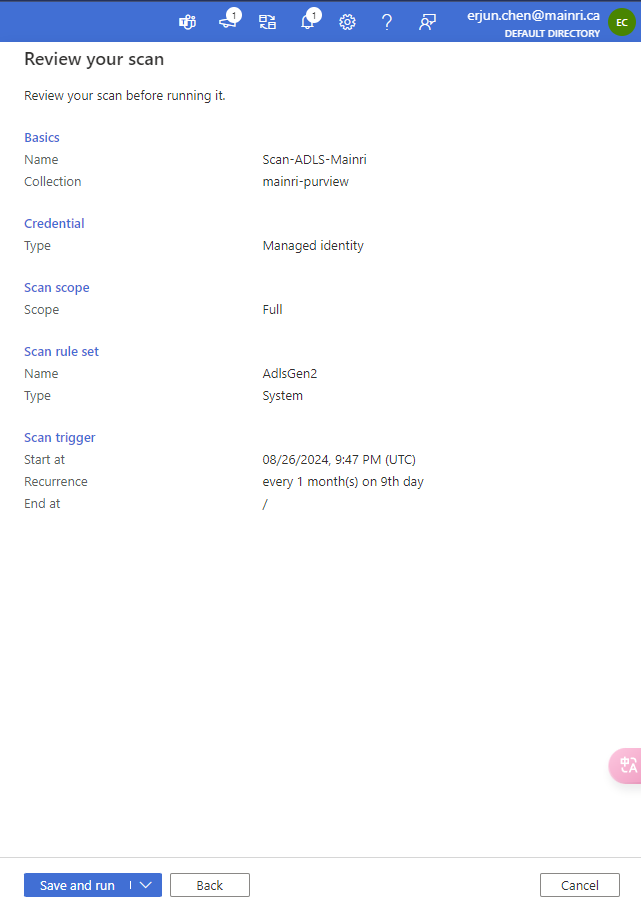
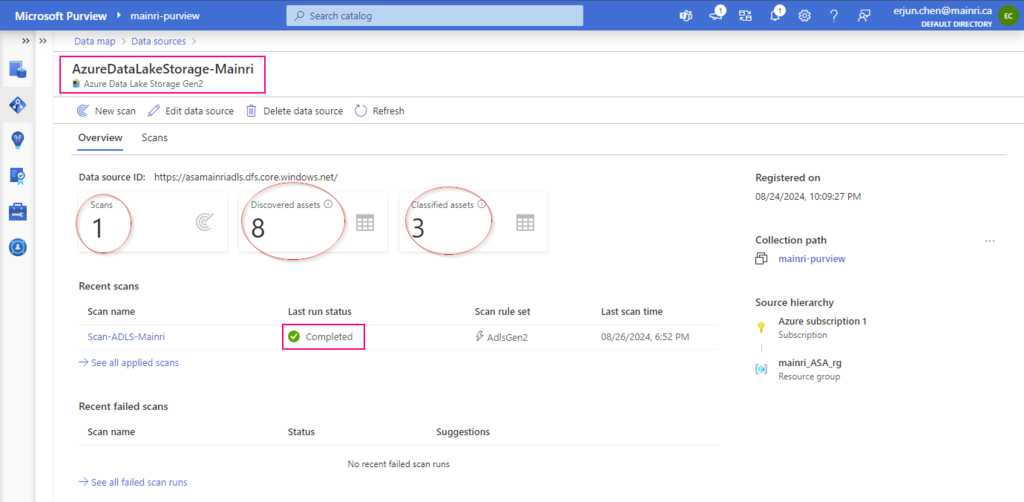
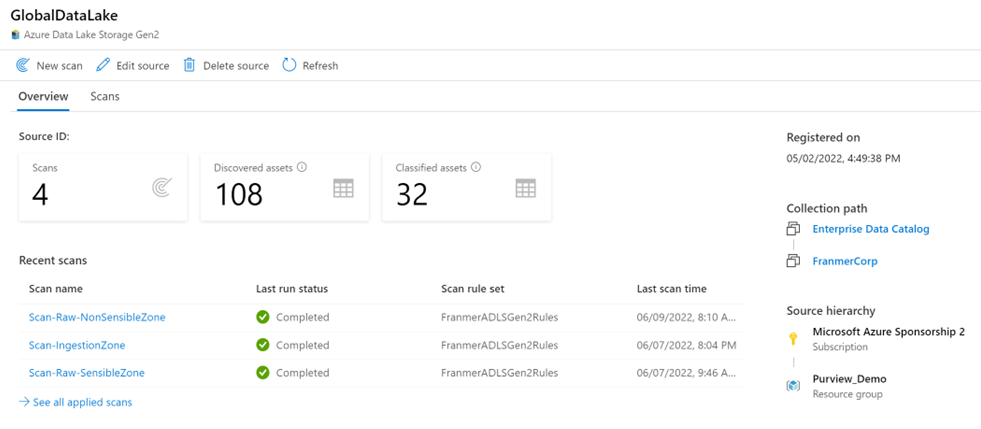
We complete the scan configuration. We have chance to review the configuration if ok save and run the scan progress or back to change it.
You can see this by clicking “view detail”
You will see this once the scan progress completed.
Purview provides a robust platform for organizations to govern their data effectively, ensuring data quality, compliance, and accessibility across the enterprise.
In this article, will not discuss creating Azure Purview account, services, open purview UI … etc. Although they are important, they are not having special than subscripting, creating, opening those things for other services in Azure environment. Simply sign in Azure portal, find out purview service, follow guide on the azure portal UI, I strongly believe you will not meet challenge.
Roughly says, Purview has two key steps:
Load data in the data map
Browse and search information in the data catalog
Load data in the data map
Connect to Data Sources: Administrators connect Microsoft Purview to various data sources within their organization, setting up scanning schedules.
Scan and Classify Data: Purview scans these sources, discovers data assets, and classifies them automatically or based on custom rules.
Browse and search information in the data catalog.
View and Manage Data Catalog: Users access the Purview data catalog to search for and manage data assets, using the business glossary to understand the data in context.
Track Lineage and Ensure Compliance: Data lineage is visualized to understand data flow, and governance policies are enforced to ensure data is handled correctly.
Leverage Insights for Decision-Making: The insights provided by Purview help data stewards, analysts, and business users make informed decisions based on governed, trusted data.
Of course, this is too general to let users understand and catch up in detail.
Load data in the data map
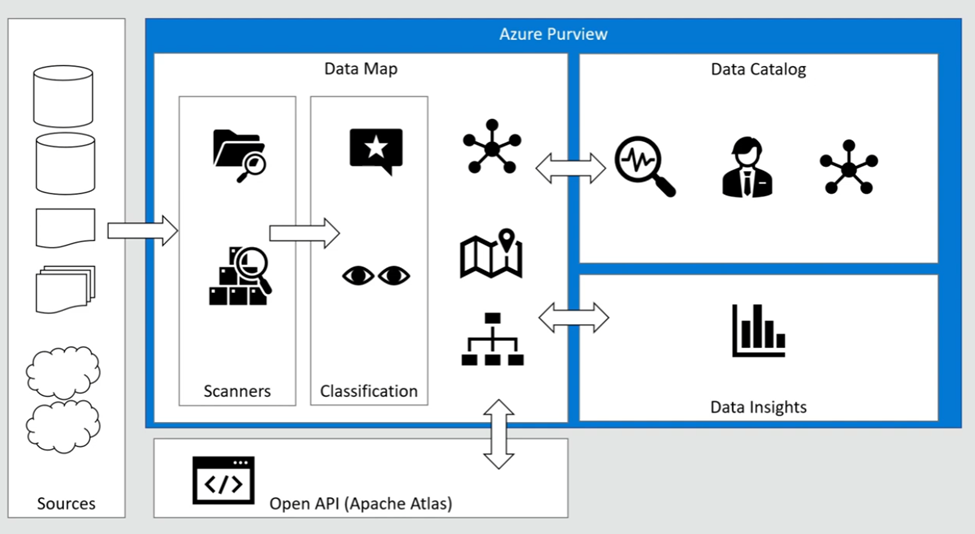
Purview Data Map is a unified map of your data assets and their relationships. It’s easier for you and your users to visualize and govern. It also houses the metadata that underpins the Microsoft Purview Data Catalog and Data Estate Insights. You can use it to govern your data estate in a way that makes the most sense for your business.
Map Data
The data map is the foundational platform for Microsoft Purview. The data map consists of:
Data assets.
Data lineage.
Data classifications.
Business context.
Customers create a knowledge graph of data that comes in from a range of sources. Microsoft Purview makes it easy to register and automatically scan and classify data at scale. Within a data map, you can identify the type of data source, along with other details around security and scanning.
The data map uses collections to organize these details.
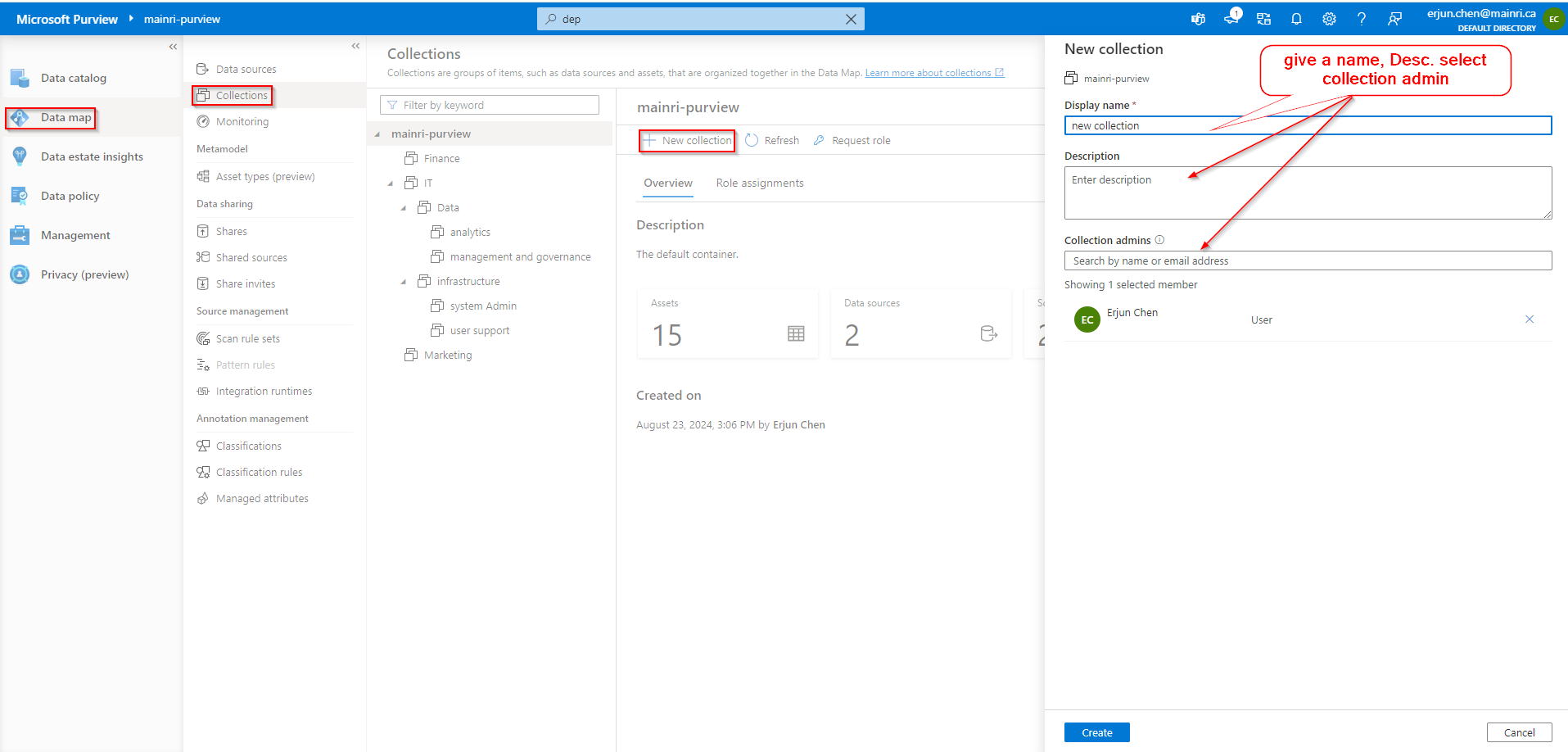
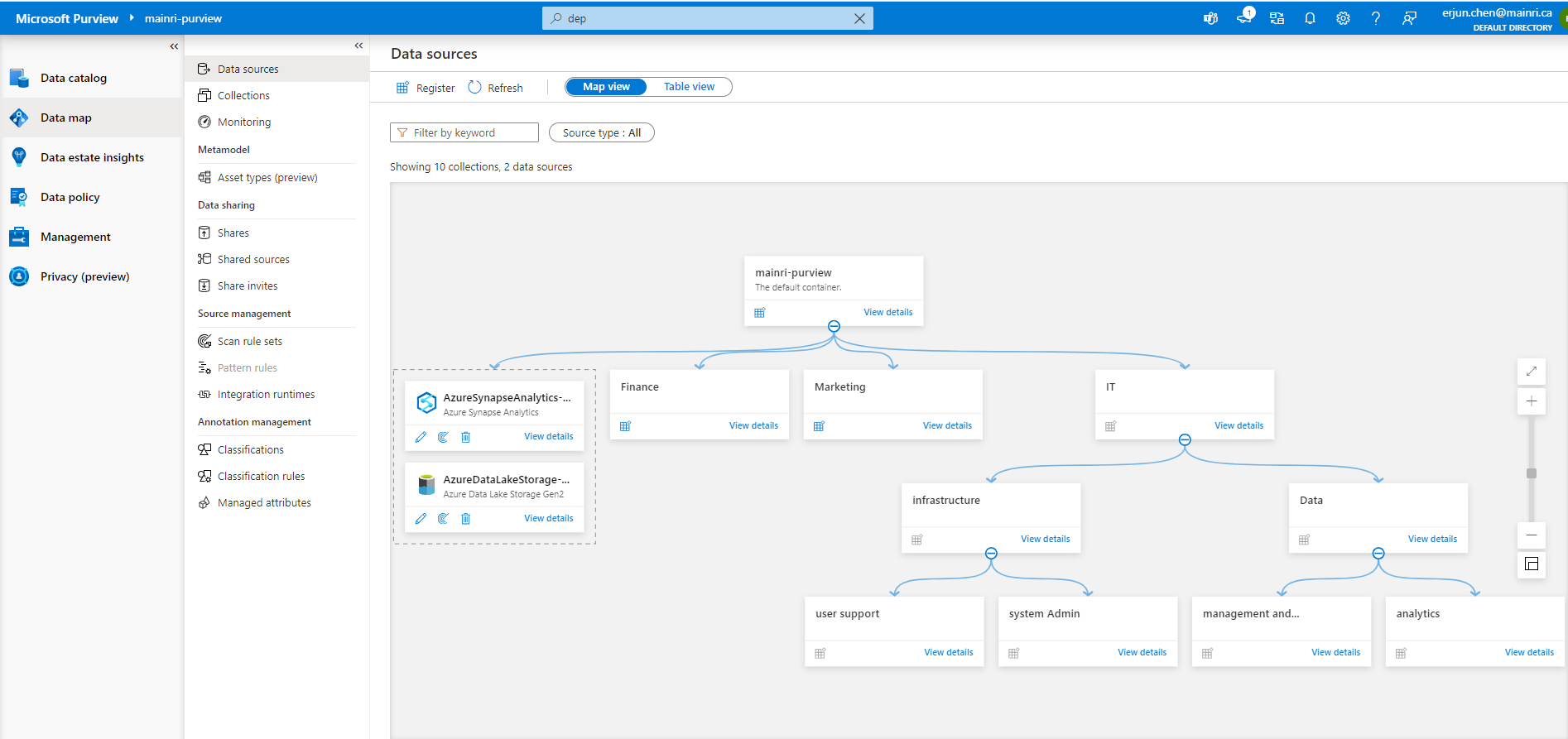
Collection
Collections are groups of items, such as data sources and assets, that are organized together in the Data Map. It is a way of grouping data assets into logical categories to simplify management and discovery of assets within the catalog. You also use collections to manage access to the metadata that’s available in the data map.
now, collections are created, looks like
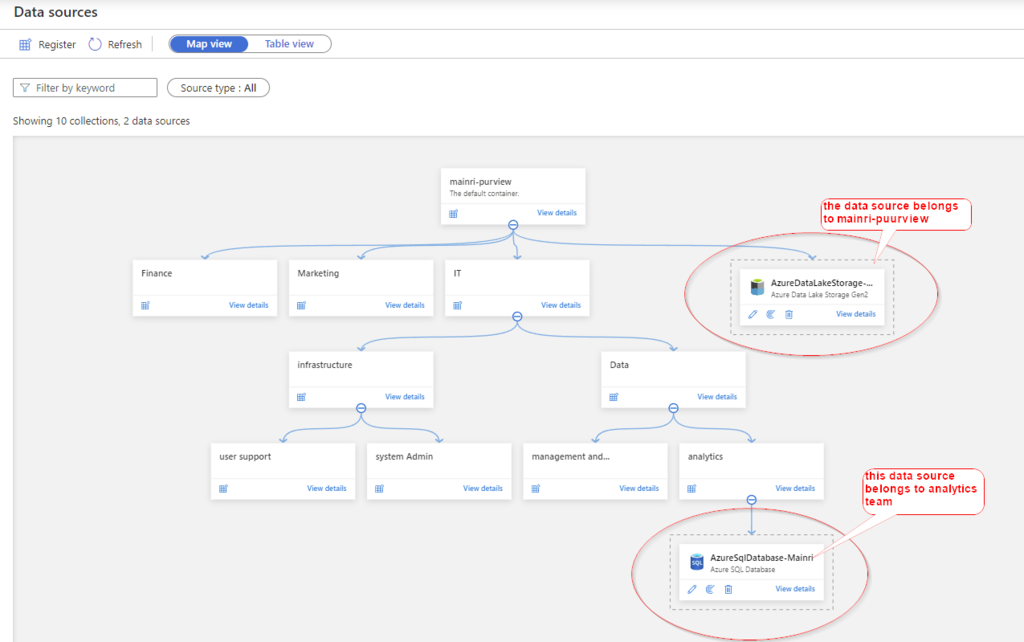
Source data
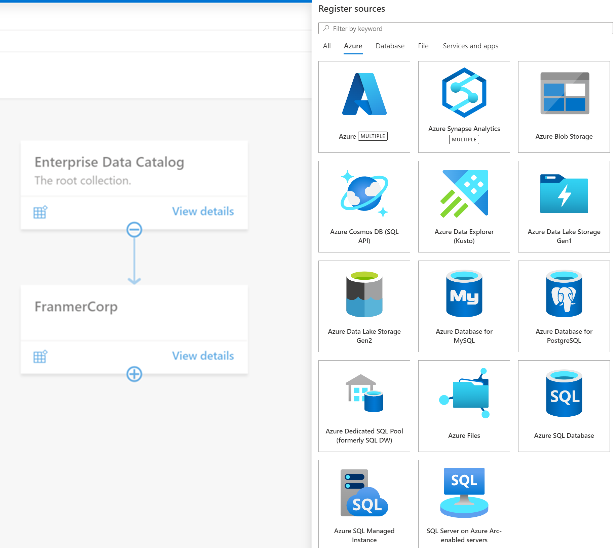
Sourcing your data starts with a process where you register data sources. Microsoft Purview supports an array of data sources that span on-premises, multi-cloud, and software-as-a-service (SaaS) options. You register the various data sources so that Microsoft Purview is aware of them. The data remains in its location and isn’t migrated to any other platform.
Each type of data source you choose requires specific information to complete the registration.
Below is a small sample of available connectors in Microsoft Purview Data Catalog. See supported data sources and file types for an up-to-date list of supported data sources and connectors.
The same way creates another data source – AzureSQLDatabase that belongs to “analytics team”
Rule Sets
After we register our data sources, we will need to run a scan to access their metadata and browse the asset information.
Before you can scan the data sources, you’re required to enter the credentials for these sources. You can use Azure Key Vault to store the credentials for security and ease of access by your scan rules. The Microsoft Purview governance portal comes with existing system scan rule sets that you can select when you create a new scan rule. You can also specify a custom scan rule set.
A scan rule set is a container for grouping scan rules together to use the same rules repeatedly. A scan rule set lets you select file types for schema extraction and classification. It also lets you define new custom file types. You might create a default scan rule set for each of your data source types. Then you can use these scan rule sets by default for all scans within your company.
For example, you might want to scan only the .csv files in an Azure Data Lake Storage account. Or you might want to check your data only for credit card numbers rather than all the possible classifications. You might also want users with the right permissions to create other scan rule sets with different configurations based on business needs.
Scan
Once you have data sources registered in the Microsoft Purview governance portal and displayed in the data map, you can set up scanning. The scanning process can be triggered to run immediately or can be scheduled to run on a periodic basis to keep your Microsoft Purview account up to date.
Scanning assets is as simple as selecting New scan from the resource as displayed in the data map.
You’ll now need to configure your scan and assign the following details:
Once a scan is complete, you can refer to the scan details to view information about the number of scans completed, assets detected, assets classified, Scan information. It’s a good place to monitor scan progress, including success or failure.
Recap,
Purview Scan means:
Where to scan
Scan rule set
Type (Full, Increments)
Schedule
Scan Rule Set means:
What to scan (txt, json, parquet,,,,,)?
What to look for (classification rules)?
Specific to source type (ADLS, Database,,,,,)?
System defined ones
Custom
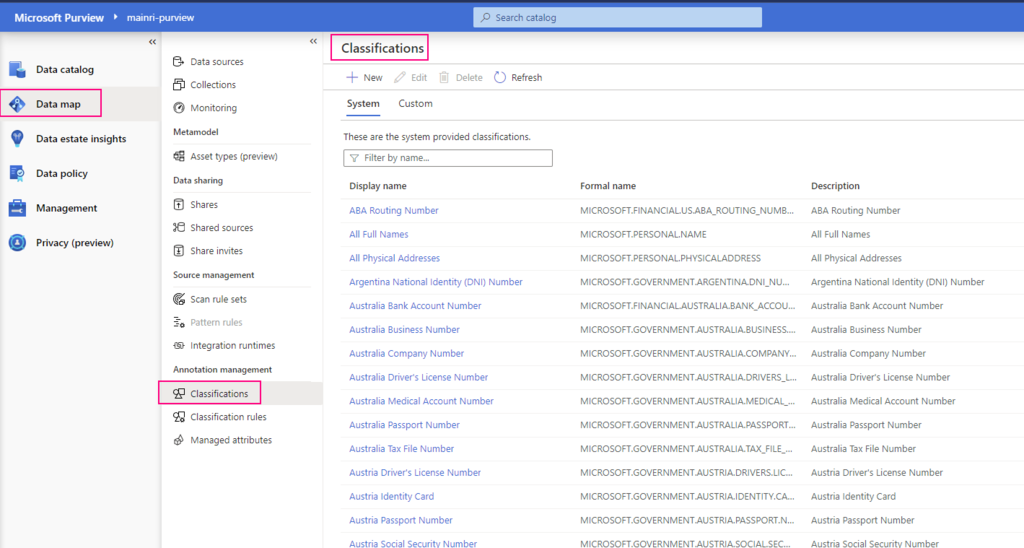
Classification
Metadata is used to help describe the data that’s being scanned and made available in the catalog. During the configuration of a scan set, you can specify classification rules to apply during the scan that also serve as metadata. The classification rules fall under five major categories:
Government: Attributes such as government identity cards, driver license numbers, and passport numbers.
Financial: Attributes such as bank account numbers or credit card numbers.
Personal: Personal information such as a person’s age, date of birth, email address, and phone number.
Security: Attributes like passwords that can be stored.
Miscellaneous: Attributes not included in the other categories.
You can use several system classifications to classify your data. These classifications align with the sensitive information types in the Microsoft Purview compliance portal. You can also create custom classifications to identify other important or sensitive information types in your data estate.
After you register a data source, you can enrich its metadata. With proper access, you can annotate a data source by providing descriptions, ratings, tags, glossary terms, identifying experts, or other metadata for requesting data-source access. This descriptive metadata supplements the structural metadata, such as column names and data types, that’s registered from the data source.
Discovering and understanding data sources and their use is the primary purpose of registering the sources. If you’re an enterprise user, you might need data for business intelligence, application development, data science, or any other task where the right data is required. You can use the data catalog discovery experience to quickly find data that matches your needs. You can evaluate the data for its fitness for the purpose and then open the data source in your tool of choice.
At the same time, you can contribute to the catalog by tagging, documenting, and annotating data sources that have already been registered. You can also register new data sources, which are then discovered, evaluated, and used by the community of catalog users.
In the following separate articles, I would like to use ADLS, Azure SQL Database and Azure Synapse Analytics as examples to step by step show you how to register and scan data source in Purview.
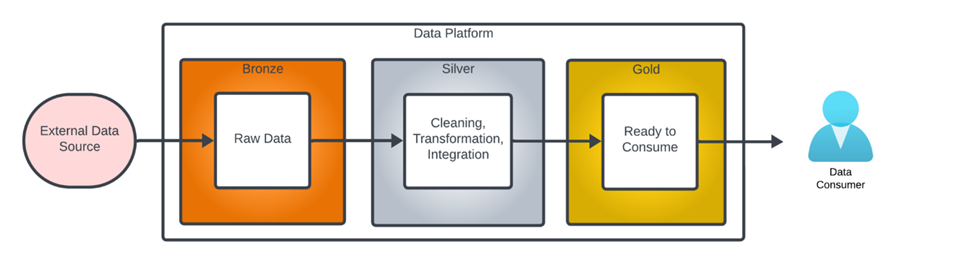
The term “Medallion Data Architecture” was first called by databricks. It is a data design pattern used to logically organize data in a lakehouse. It describes data at different stages of processing as being “bronze,” “silver” or “gold” level data. with the goal of incrementally and progressively improving the structure and quality of data as it flows through each layer of the architecture.
Bronze ⇒ Silver ⇒ Gold layer tables
Bronze data refers to data in its unprocessed state, exactly as loaded from the data source.
Silver data refers to data at various stages of intermediate processing.
Gold level data is fully cleaned and prepared ready for use by a data consumer.
Bronze zone/layer
Data in bronze is raw, unprocessed data. It acts as a landing zone including structured, semi-structured, and unstructured data. Data in this layer is ingested as-is, it is a copy of the data exactly as it was loaded from the data source. meaning it’s often messy, unclean, and can include duplicates.
If a fault occurs, it allows you to quickly determine if the the problem is related to source data or processing within the data platform.
Gold zone
Sometimes it is also called Curated zone/layer.
Data in this layer is fully cleaned, secured and maybe pre-aggregated data. All data is ready for access. contains highly curated, aggregated. data usually tailored for specific use cases, such as reporting, business intelligence, or machine learning.and often ready-for-consumption data.
Silver Layer (Cleaned Data)
There is layer between the Bronze and Gold layer, it is called Silver Layer. The silver layer is where data is cleaned, transformed, and often enriched. It’s meant to be a more refined version of the bronze layer, ready for further analysis or use in applications. Data in this layer is typically free of duplicates, missing values are handled, and unnecessary data is filtered out. The transformations applied here make the data more structured and reliable.
Why use Medallion Architecture
Many software engineers are familiar the “multiple tiers architecture” in software development. Medallion Architecture has the same meaning “multiple architectures”.
Scalability: The layered approach allows for scaling each part of the data pipeline independently.
Flexibility: It provides flexibility in data processing and the ability to handle different data types and sources.
Data Quality: By progressing data through these layers, the architecture naturally enforces data quality and consistency.
Ease of Use: It simplifies data management by organizing the data into distinct stages, making it easier to understand and manage.
Conclusion
Overall, the Medallion Architecture is a powerful pattern for managing data lifecycle, from raw ingestion to refined, consumable datasets. It often use in data engineering project. such as Data Lakes, Big Data Processing, ETL/ELT Pipelines etc.
Please do not hesitate to contact me if you have any questions at William . chen @mainri.ca